
[TOC]
# 前言
在本文將討論數據庫原理和 MySQL 核心知識,MySQL 性能優化等,包含**MySQL基礎**和**高性能MySQL實踐**兩部分。
參考資料:
* 《高性能MySQL》第三版
* 部分參考:[CyC2018/Interview-Notebook](https://github.com/CyC2018/Interview-Notebook/blob/master/notes/MySQL.md),特別鳴謝作者 @CyC2018
學習資料:
* 【慕課網】MySQL性能管理及架構設計
* 【龍果學院】MySQL大型分布式集群
* 【咕泡學院】性能分析—MySQL部分
# 第一部分:MySQL基礎
## MySQL的多存儲引擎架構
[](https://github.com/frank-lam/fullstack-tutorial/blob/master/notes/assets/MySQL.png)
這里先有個整體的MySQL Server的整體概念,詳情轉向:[MySQL的多存儲引擎架構](http://zhaox.github.io/2016/06/24/mysql-architecture)
## 1\. 什么是事務
[](https://github.com/frank-lam/fullstack-tutorial/blob/master/notes/assets/185b9c49-4c13-4241-a848-fbff85c03a64.png)
事務指的是滿足 ACID 特性的一組操作,可以通過 Commit 提交一個事務,也可以使用 Rollback 進行回滾。
### AUTOCOMMIT
MySQL 默認采用自動提交模式。也就是說,如果不顯式使用`START TRANSACTION`語句來開始一個事務,那么每個查詢都會被當做一個事務自動提交
## 2\. 數據庫ACID
### 1\. 原子性(Atomicity)
原子性是指事務是一個不可分割的工作單位,事務中的操作要么全部成功,要么全部失敗。比如在同一個事務中的SQL語句,要么全部執行成功,要么全部執行失敗。
回滾可以用日志來實現,日志記錄著事務所執行的修改操作,在回滾時反向執行這些修改操作即可。
### 2\. 一致性(Consistency)
事務必須使數據庫從一個一致性狀態變換到另外一個一致性狀態。以轉賬為例子,A向B轉賬,假設轉賬之前這兩個用戶的錢加起來總共是2000,那么A向B轉賬之后,不管這兩個賬戶怎么轉,A用戶的錢和B用戶的錢加起來的總額還是2000,這個就是事務的一致性。
### 3\. 隔離性(Isolation)
隔離性是當多個用戶并發訪問數據庫時,比如操作同一張表時,數據庫為每一個用戶開啟的事務,不能被其他事務的操作所干擾,多個并發事務之間要相互隔離。
即要達到這么一種效果:對于任意兩個并發的事務 T1 和 T2,在事務 T1 看來,T2 要么在 T1 開始之前就已經結束,要么在 T1 結束之后才開始,這樣每個事務都感覺不到有其他事務在并發地執行。
### 4\. 持久性(Durability)
一旦事務提交,則其所做的修改將會永遠保存到數據庫中。即使系統發生崩潰,事務執行的結果也不能丟失。
可以通過數據庫備份和恢復來實現,在系統發生奔潰時,使用備份的數據庫進行數據恢復。
事務的 ACID 特性概念簡單,但不是很好理解,主要是因為這幾個特性不是一種平級關系:
* 只有滿足一致性,事務的執行結果才是正確的。
* 在無并發的情況下,事務串行執行,隔離性一定能夠滿足。此時要只要能滿足原子性,就一定能滿足一致性。
* 在并發的情況下,多個事務并發執行,事務不僅要滿足原子性,還需要滿足隔離性,才能滿足一致性。
* 事務滿足持久化是為了能應對數據庫奔潰的情況。
[](https://github.com/frank-lam/fullstack-tutorial/blob/master/notes/assets/a58e294a-615d-4ea0-9fbf-064a6daec4b2-1534474592177.png)
## 3\. 數據庫中的范式
滿足最低要求的范式是第一范式(1NF)。在第一范式的基礎上進一步滿足更多規范要求的稱為第二范式(2NF),其余范式以次類推。一般說來,數據庫只需滿足第三范式 (3NF)就行了。
范式的包含關系。一個數據庫設計如果符合第二范式,一定也符合第一范式。如果符合第三范式,一定也符合第二范式…
* 1NF:屬性不可分
* 2NF:屬性完全依賴于主鍵 \[消除部分子函數依賴\]
* 3NF:屬性不依賴于其它非主屬性 \[消除傳遞依賴\]
* BCNF(巴斯-科德范式):在1NF基礎上,任何非主屬性不能對主鍵子集依賴\[在3NF基礎上消除對主碼子集的依賴\]
* 4NF:要求把同一表內的多對多關系刪除。
* 5NF(完美范式):從最終結構重新建立原始結構。
范式理論是為了解決以上提到四種異常。
高級別范式的依賴于低級別的范式,1NF 是最低級別的范式。
[](https://github.com/frank-lam/fullstack-tutorial/blob/master/notes/assets/c2d343f7-604c-4856-9a3c-c71d6f67fecc.png)
### 1\. 第一范式 (1NF)
屬性不可分。
### 2\. 第二范式 (2NF)
每個非主屬性完全函數依賴于鍵碼。
可以通過分解來滿足。
**分解前**
| Sno | Sname | Sdept | Mname | Cname | Grade |
| --- | --- | --- | --- | --- | --- |
| 1 | 學生-1 | 學院-1 | 院長-1 | 課程-1 | 90 |
| 2 | 學生-2 | 學院-2 | 院長-2 | 課程-2 | 80 |
| 2 | 學生-2 | 學院-2 | 院長-2 | 課程-1 | 100 |
| 3 | 學生-3 | 學院-2 | 院長-2 | 課程-2 | 95 |
以上學生課程關系中,{Sno, Cname} 為鍵碼,有如下函數依賴:
* Sno -> Sname, Sdept
* Sdept -> Mname
* Sno, Cname-> Grade
Grade 完全函數依賴于鍵碼,它沒有任何冗余數據,每個學生的每門課都有特定的成績。
Sname, Sdept 和 Mname 都部分依賴于鍵碼,當一個學生選修了多門課時,這些數據就會出現多次,造成大量冗余數據。
**分解后**
關系-1
| Sno | Sname | Sdept | Mname |
| --- | --- | --- | --- |
| 1 | 學生-1 | 學院-1 | 院長-1 |
| 2 | 學生-2 | 學院-2 | 院長-2 |
| 3 | 學生-3 | 學院-2 | 院長-2 |
有以下函數依賴:
* Sno -> Sname, Sdept
* Sdept -> Mname
關系-2
| Sno | Cname | Grade |
| --- | --- | --- |
| 1 | 課程-1 | 90 |
| 2 | 課程-2 | 80 |
| 2 | 課程-1 | 100 |
| 3 | 課程-2 | 95 |
有以下函數依賴:
* Sno, Cname -> Grade
### 3\. 第三范式 (3NF)
非主屬性不傳遞函數依賴于鍵碼。
上面的 關系-1 中存在以下傳遞函數依賴:
* Sno -> Sdept -> Mname
可以進行以下分解:
關系-11
| Sno | Sname | Sdept |
| --- | --- | --- |
| 1 | 學生-1 | 學院-1 |
| 2 | 學生-2 | 學院-2 |
| 3 | 學生-3 | 學院-2 |
關系-12
| Sdept | Mname |
| --- | --- |
| 學院-1 | 院長-1 |
| 學院-2 | 院長-2 |
## 4\. 并發一致性問題
### 1\. 丟失修改
T1 和 T2 兩個事務都對一個數據進行修改,T1 先修改,T2 隨后修改,T2 的修改覆蓋了 T1 的修改。
[](https://github.com/frank-lam/fullstack-tutorial/blob/master/notes/assets/88ff46b3-028a-4dbb-a572-1f062b8b96d3.png)
### 2\. 臟讀
(針對未提交數據)如果一個事務中對數據進行了更新,但**事務還沒有提交**,另一個事務可以 “看到” 該事務沒有提交的更新結果,這樣造成的問題就是,如果第一個事務回滾,那么,第二個事務在此之前所 “看到” 的數據就是一筆臟數據。**(臟讀又稱無效數據讀出。一個事務讀取另外一個事務還沒有提交的數據叫臟讀。 )**
**例子:**
Mary 的原工資為 1000, 財務人員將 Mary 的工資改為了 8000 (但未提交事務)
Mary 讀取自己的工資,發現自己的工資變為了 8000,歡天喜地!
而財務發現操作有誤,回滾了事務,Mary 的工資又變為了1000
像這樣,Mary記取的工資數8000是一個臟數據。
**解決辦法**:
把數據庫的事務隔離級別調整到 READ\_COMMITTED
**圖解:**
T1 修改一個數據,T2 隨后讀取這個數據。如果 T1 撤銷了這次修改,那么 T2 讀取的數據是臟數據。
[](https://github.com/frank-lam/fullstack-tutorial/blob/master/notes/assets/dd782132-d830-4c55-9884-cfac0a541b8e.png)
### 3\. 不可重復讀
是指在一個事務內,多次讀同一數據。在這個事務還沒有結束時,另外一個事務也訪問該同一數據。那么,在第一個事務中的兩次讀數據之間,由于第二個事務的修改,那么第一個事務兩次讀到的的數據可能是不一樣的。這樣在一個事務內兩次讀到的數據是不一樣的,因此稱為是不可重復讀。**(同時操作,事務1分別讀取事務2操作時和提交后的數據,讀取的記錄內容不一致。不可重復讀是指在同一個事務內,兩個相同的查詢返回了不同的結果。 )**
**例子:**
(1)在事務1中,Mary 讀取了自己的工資為1000,操作并沒有完成
~~~sql
con1 = getConnection();
select salary from employee empId ="Mary";
~~~
(2)在事務2中,這時財務人員修改了 Mary 的工資為 2000,并提交了事務.
~~~sql
con2 = getConnection();
update employee set salary = 2000;
con2.commit();
~~~
(3)在事務1中,Mary 再次讀取自己的工資時,工資變為了2000
~~~sql
//con1
select salary from employee empId ="Mary";
~~~
在一個事務中前后兩次讀取的結果并不致,導致了不可重復讀。
**解決辦法**:
如果只有在修改事務完全提交之后才可以讀取數據,則可以避免該問題。把數據庫的事務隔離級別調整到REPEATABLE\_READ
**圖解:**
T2 讀取一個數據,T1 對該數據做了修改。如果 T2 再次讀取這個數據,此時讀取的結果和第一次讀取的結果不同。
[](https://github.com/frank-lam/fullstack-tutorial/blob/master/notes/assets/c8d18ca9-0b09-441a-9a0c-fb063630d708-1534474726485.png)
### 4\. 幻讀
事務 T1 讀取一條指定的 Where 子句所返回的結果集,然后 T2 事務新插入一行記錄,這行記錄恰好可以滿足T1 所使用的查詢條件。然后 T1 再次對表進行檢索,但又看到了 T2 插入的數據。**(和可重復讀類似,但是事務 T2 的數據操作僅僅是插入和刪除,不是修改數據,讀取的記錄數量前后不一致)**
幻讀的重點在于新增或者刪除 (數據條數變化)
同樣的條件,第1次和第2次讀出來的記錄數不一樣
**例子:**
目前工資為1000的員工有10人。 (1)事務1,讀取所有工資為 1000 的員工(共讀取 10 條記錄 )
~~~sql
con1 = getConnection();
Select * from employee where salary =1000;
~~~
(2)這時另一個事務向 employee 表插入了一條員工記錄,工資也為 1000
~~~sql
con2 = getConnection();
Insert into employee(empId,salary) values("Lili",1000);
con2.commit();
~~~
事務1再次讀取所有工資為 1000的 員工(共讀取到了 11 條記錄,這就像產生了幻讀)
~~~sql
//con1
select * from employee where salary =1000;
~~~
**解決辦法:**
如果在操作事務完成數據處理之前,任何其他事務都不可以添加新數據,則可避免該問題。把數據庫的事務隔離級別調整到 SERIALIZABLE\_READ
**圖解:**
T1 讀取某個范圍的數據,T2 在這個范圍內插入新的數據,T1 再次讀取這個范圍的數據,此時讀取的結果和和第一次讀取的結果不同。
[](https://github.com/frank-lam/fullstack-tutorial/blob/master/notes/assets/72fe492e-f1cb-4cfc-92f8-412fb3ae6fec.png)
## 5\. 事務隔離級別
### 1\. 串行化 (Serializable)
所有事務一個接著一個的執行,這樣可以避免幻讀 (phantom read),對于基于鎖來實現并發控制的數據庫來說,串行化要求在執行范圍查詢的時候,需要獲取范圍鎖,如果不是基于鎖實現并發控制的數據庫,則檢查到有違反串行操作的事務時,需回滾該事務。
### 2\. 可重復讀 (Repeated Read)
所有被 Select 獲取的數據都不能被修改,這樣就可以避免一個事務前后讀取數據不一致的情況。但是卻沒有辦法控制幻讀,因為這個時候其他事務不能更改所選的數據,但是可以增加數據,即前一個事務有讀鎖但是沒有范圍鎖,為什么叫做可重復讀等級呢?那是因為該等級解決了下面的不可重復讀問題。
引申:現在主流數據庫都使用 MVCC 并發控制,使用之后RR(可重復讀)隔離級別下是不會出現幻讀的現象。
### 3\. 讀已提交 (Read Committed)
被讀取的數據可以被其他事務修改,這樣可能導致不可重復讀。也就是說,事務讀取的時候獲取讀鎖,但是在讀完之后立即釋放(不需要等事務結束),而寫鎖則是事務提交之后才釋放,釋放讀鎖之后,就可能被其他事務修改數據。該等級也是 SQL Server 默認的隔離等級。
### 4\. 讀未提交 (Read Uncommitted)
最低的隔離等級,允許其他事務看到沒有提交的數據,會導致臟讀。
**總結**
* 四個級別逐漸增強,每個級別解決一個問題,每個級別解決一個問題,事務級別遇到,性能越差,大多數環境(Read committed 就可以用了)
| 隔離級別 | 臟讀 | 不可重復讀 | 幻影讀 |
| --- | --- | --- | --- |
| 未提交讀 | √ | √ | √ |
| 提交讀 | × | √ | √ |
| 可重復讀 | × | × | √ |
| 可串行化 | × | × | × |
## 6\. 存儲引擎
對于初學者來說我們通常不關注存儲引擎,但是 MySQL 提供了多個存儲引擎,包括處理事務安全表的引擎和處理非事務安全表的引擎。在 MySQL 中,不需要在整個服務器中使用同一種存儲引擎,針對具體的要求,可以對每一個表使用不同的存儲引擎。
### 簡介
MySQL 中的數據用各種不同的技術存儲在文件(或者內存)中。這些技術中的每一種技術都使用不同的存儲機制、索引技巧、鎖定水平并且最終提供廣泛的不同的功能和能力。通過選擇不同的技術,你能夠獲得額外的速度或者功能,從而改善你的應用的整體功能。存儲引擎說白了就是如何存儲數據、如何為存儲的數據建立索引和如何更新、查詢數據等技術的實現方法。
例如,如果你在研究大量的臨時數據,你也許需要使用內存存儲引擎。內存存儲引擎能夠在內存中存儲所有的表格數據。又或者,你也許需要一個支持事務處理的數據庫(以確保事務處理不成功時數據的回退能力)。
> 在MySQL中有很多存儲引擎,每種存儲引擎大相徑庭,那么又改如何選擇呢?
`MySQL 5.5`以前的默認存儲引擎是`MyISAM`,`MySQL 5.5`之后的默認存儲引擎是`InnoDB`
不同存儲引起都有各自的特點,為適應不同的需求,需要選擇不同的存儲引擎,所以首先考慮這些存儲引擎各自的功能和兼容。
### 1\. MyISAM
MySQL 5.5 版本之前的默認存儲引擎,在`5.0`以前最大表存儲空間最大`4G`,`5.0`以后最大`256TB`。
Myisam 存儲引擎由`.myd`(數據)和`.myi`(索引文件)組成,`.frm`文件存儲表結構(所以存儲引擎都有)
**特性**
* 并發性和鎖級別 (對于讀寫混合的操作不好,為表級鎖,寫入和讀互斥)
* 表損壞修復
* Myisam 表支持的索引類型(全文索引)
* Myisam 支持表壓縮(壓縮后,此表為只讀,不可以寫入。使用 myisampack 壓縮)
**應用場景**
* 沒有事務
* 只讀類應用(插入不頻繁,查詢非常頻繁)
* 空間類應用(唯一支持空間函數的引擎)
* 做很多 count 的計算
### 2\. InnoDB
MySQL 5.5 及之后版本的默認存儲引擎
**特性**
* InnoDB為事務性存儲引擎
* 完全支持事物的 ACID 特性
* Redo log (實現事務的持久性) 和 Undo log(為了實現事務的原子性,存儲未完成事務log,用于回滾)
* InnoDB支持行級鎖
* 行級鎖可以最大程度的支持并發
* 行級鎖是由存儲引擎層實現的
**應用場景**
* 可靠性要求比較高,或者要求事務
* 表更新和查詢都相當的頻繁,并且行鎖定的機會比較大的情況。
**并發特性**
* s
### 3\. CSV
**文件系統存儲特點**
* 數據以文本方式存儲在文件中
* `.csv`文件存儲表內容
* `.csm`文件存儲表的元數據,如表狀態和數據量
* `.frm`存儲表的結構
**CSV存儲引擎特點**
* 以 CSV 格式進行數據存儲
* 所有列必須都是不能為 NULL
* 不支持索引
* 可以對數據文件直接編輯(其他引擎是二進制存儲,不可編輯)
**引用場景**
* 作為數據交換的中間表
### 4\. Archive
**特性**
* 以 zlib 對表數據進行壓縮,磁盤 I/O 更少
* 數據存儲在ARZ為后綴的文件中(表文件為`a.arz`,`a.frm`)
* 只支持 insert 和 select 操作(不可以 delete 和 update,會提示沒有這個功能)
* 只允許在自增ID列上加索引
**應用場景**
* 日志和數據采集類應用
### 5\. Memory
特性
* 也稱為 HEAP 存儲引擎,所以數據保存在內存中(數據庫重啟后會導致數據丟失)
* 支持 HASH 索引(等值查找應選擇 HASH)和 BTree 索引(范圍查找應選擇)
* 所有字段都為固定長度,varchar(10) == char(10)
* 不支持 BLOG 和 TEXT 等大字段
* Memory 存儲使用表級鎖(性能可能不如 innodb)
* 最大大小由`max_heap_table_size`參數決定
* Memory存儲引擎默認表大小只有`16M`,可以通過調整`max_heap_table_size`參數
應用場景
* 用于查找或是映射表,例如右邊和地區的對應表
* 用于保存數據分析中產生的中間表
* 用于緩存周期性聚合數據的結果表
**注意:**Memory 數據易丟失,所以要求數據可再生
### 6\. Federated
**特性**
* 提供了訪問遠程 MySQL 服務器上表的方法
* 本地不存儲數據,數據全部放在遠程服務器上
**使用 Federated**
默認是禁止的。如果需要啟用,需要在啟動時增加Federated參數
### 問:獨立表空間和系統表空間應該如何抉擇
**兩者比較**
* 系統表空間:無法簡單的收縮大小(這很恐怖,會導致 ibdata1 一直增大,即使刪除了數據也不會變小)
* 獨立表空間:可以通過 optimize table 命令收縮系統文件
* 系統表空間:會產生I/O瓶頸(因為只有一個文件)
* 獨立表空間:可以向多個文件刷新數據
**總結**強烈建議:對Innodb引擎使用獨立表空間(mysql5.6版本以后默認是獨立表空間)
**系統表轉移為獨立表的步驟(非常繁瑣)**
* 使用 mysqldump 導出所有數據庫表數據
* 停止 mysql 服務,修改參數,并且刪除Innodb相關文件
* 重啟 mysql 服務,重建mysql系統表空間
* 重新導入數據
### 問:如何選擇存儲引擎
**參考條件:**
* 是否需要事務
* 是否可以熱備份
* 崩潰恢復
* 存儲引擎的特有特性
**重要一點:**不要混合使用存儲引擎**強烈推薦:**Innodb
### 問:MyISAM和InnoDB引擎的區別
**區別:**
* MyISAM 不支持外鍵,而 InnoDB 支持
* MyISAM 是非事務安全型的,而 InnoDB 是事務安全型的。
* MyISAM 鎖的粒度是表級,而 InnoDB 支持行級鎖定。
* MyISAM 支持全文類型索引,而 InnoDB 不支持全文索引。
* MyISAM 相對簡單,所以在效率上要優于 InnoDB,小型應用可以考慮使用 MyISAM。
* MyISAM 表是保存成文件的形式,在跨平臺的數據轉移中使用 MyISAM 存儲會省去不少的麻煩。
* InnoDB 表比 MyISAM 表更安全,可以在保證數據不會丟失的情況下,切換非事務表到事務表(alter table tablename type=innodb)。
**應用場景:**
* MyISAM 管理非事務表。它提供高速存儲和檢索,以及全文搜索能力。如果應用中需要執行大量的 SELECT 查詢,那么 MyISAM 是更好的選擇。
* InnoDB 用于事務處理應用程序,具有眾多特性,包括 ACID 事務支持。如果應用中需要執行大量的 INSERT 或 UPDATE 操作,則應該使用 InnoDB,這樣可以提高多用戶并發操作的性能。
### 問:為什么不建議 InnoDB 使用億級大表
僅作拓展延伸,詳情請轉向:[為什么不建議innodb使用億級大表 | 峰云就她了](http://xiaorui.cc/2016/12/08/%E4%B8%BA%E4%BB%80%E4%B9%88%E4%B8%8D%E5%BB%BA%E8%AE%AEinnodb%E4%BD%BF%E7%94%A8%E4%BA%BF%E7%BA%A7%E5%A4%A7%E8%A1%A8/)
## 7\. MySQL數據類型
### 1\. 整型
| 類型 | 存儲 | 存儲 | 最小值 | 最大值 |
| --- | --- | --- | --- | --- |
| | byte | bit | signed | signed |
| TINYINT | 1 | 8 | \-27\= -128 | 27\-1 = 127 |
| SMALLINT | 2 | 16 | | |
| MEDIUMINT | 3 | 24 | | |
| INT | 4 | 32 | \-231\= -2147483648 | 231\-1 = 2147483647 |
| BIGINT | 8 | 64 | | |
TINYINT, SMALLINT, MEDIUMINT, INT, BIGINT 分別使用 8, 16, 24, 32, 64 位存儲空間,一般情況下越小的列越好。
INT(11) 中的數字只是規定了交互工具顯示字符的個數,對于存儲和計算來說是沒有意義的。
### 2\. 浮點數
FLOAT 和 DOUBLE 為浮點類型,DECIMAL 為高精度小數類型。CPU 原生支持浮點運算,但是不支持 DECIMAl 類型的計算,因此 DECIMAL 的計算比浮點類型需要更高的代價。
FLOAT、DOUBLE 和 DECIMAL 都可以指定列寬,例如 DECIMAL(18, 9) 表示總共 18 位,取 9 位存儲小數部分,剩下 9 位存儲整數部分。
### 3\. 字符串
主要有 CHAR 和 VARCHAR 兩種類型,一種是定長的,一種是變長的。
VARCHAR 這種變長類型能夠節省空間,因為只需要存儲必要的內容。但是在執行 UPDATE 時可能會使行變得比原來長,當超出一個頁所能容納的大小時,就要執行額外的操作。MyISAM 會將行拆成不同的片段存儲,而 InnoDB 則需要分裂頁來使行放進頁內。
VARCHAR 會保留字符串末尾的空格,而 CHAR 會刪除。
### 4\. 時間和日期
MySQL 提供了兩種相似的日期時間類型:DATATIME 和 TIMESTAMP。
#### DATATIME
能夠保存從 1001 年到 9999 年的日期和時間,精度為秒,使用 8 字節的存儲空間。
它與時區無關。
默認情況下,MySQL 以一種可排序的、無歧義的格式顯示 DATATIME 值,例如“2008-01-16 22:37:08”,這是 ANSI 標準定義的日期和時間表示方法。
#### TIMESTAMP
和 UNIX 時間戳相同,保存從 1970 年 1 月 1 日午夜(格林威治時間)以來的秒數,使用 4 個字節,只能表示從 1970 年 到 2038 年。
它和時區有關,也就是說一個時間戳在不同的時區所代表的具體時間是不同的。
MySQL 提供了 FROM\_UNIXTIME() 函數把 UNIX 時間戳轉換為日期,并提供了 UNIX\_TIMESTAMP() 函數把日期轉換為 UNIX 時間戳。
默認情況下,如果插入時沒有指定 TIMESTAMP 列的值,會將這個值設置為當前時間。
應該盡量使用 TIMESTAMP,因為它比 DATETIME 空間效率更高。
## 8\. 索引
### 1\. 索引使用的場景
索引能夠輕易將查詢性能提升幾個數量級。
1. 對于非常小的表、大部分情況下簡單的全表掃描比建立索引更高效。
2. 對于中到大型的表,索引就非常有效。
3. 但是對于特大型的表,建立和維護索引的代價將會隨之增長。這種情況下,需要用到一種技術可以直接區分出需要查詢的一組數據,而不是一條記錄一條記錄地匹配,例如可以使用分區技術。
索引是在存儲引擎層實現的,而不是在服務器層實現的,所以不同存儲引擎具有不同的索引類型和實現。
##### B、B+樹參考資料 [https://juejin.cn/post/6844903613915987975](https://juejin.cn/post/6844903613915987975)
### 2\. B Tree 原理
#### B-Tree
[](https://github.com/frank-lam/fullstack-tutorial/blob/master/notes/assets/06976908-98ab-46e9-a632-f0c2760ec46c.png)
定義一條數據記錄為一個二元組 \[key, data\],B-Tree 是滿足下列條件的數據結構:
* 所有葉節點具有相同的深度,也就是說 B-Tree 是平衡的;
* 一個節點中的 key 從左到右非遞減排列;
* 如果某個指針的左右相鄰 key 分別是 keyi 和 keyi+1,且不為 null,則該指針指向節點的(所有 key ≥ keyi) 且(key ≤ keyi+1)。
查找算法:首先在根節點進行二分查找,如果找到則返回對應節點的 data,否則在相應區間的指針指向的節點遞歸進行查找。
由于插入刪除新的數據記錄會破壞 B-Tree 的性質,因此在插入刪除時,需要對樹進行一個分裂、合并、旋轉等操作以保持 B-Tree 性質。
#### B+Tree
[](https://github.com/frank-lam/fullstack-tutorial/blob/master/notes/assets/7299afd2-9114-44e6-9d5e-4025d0b2a541.png)
與 B-Tree 相比,B+Tree 有以下不同點:
* 每個節點的指針上限為 2d 而不是 2d+1(d 為節點的出度);
* 內節點不存儲 data,只存儲 key;
* 葉子節點不存儲指針。
#### 順序訪問指針
[](https://github.com/frank-lam/fullstack-tutorial/blob/master/notes/assets/061c88c1-572f-424f-b580-9cbce903a3fe.png)
一般在數據庫系統或文件系統中使用的 B+Tree 結構都在經典 B+Tree 基礎上進行了優化,在葉子節點增加了順序訪問指針,做這個優化的目的是為了提高區間訪問的性能。
#### 優勢
紅黑樹等平衡樹也可以用來實現索引,但是文件系統及數據庫系統普遍采用 B Tree 作為索引結構,主要有以下兩個原因:
**(一)更少的檢索次數**
平衡樹檢索數據的時間復雜度等于樹高 h,而樹高大致為 O(h)=O(logdN),其中 d 為每個節點的出度。
紅黑樹的出度為 2,而 B Tree 的出度一般都非常大。紅黑樹的樹高 h 很明顯比 B Tree 大非常多,因此檢索的次數也就更多。
B+Tree 相比于 B-Tree 更適合外存索引,因為 B+Tree 內節點去掉了 data 域,因此可以擁有更大的出度,檢索效率會更高。
**(二)利用計算機預讀特性**
為了減少磁盤 I/O,磁盤往往不是嚴格按需讀取,而是每次都會預讀。這樣做的理論依據是計算機科學中著名的局部性原理:當一個數據被用到時,其附近的數據也通常會馬上被使用。預讀過程中,磁盤進行順序讀取,順序讀取不需要進行磁盤尋道,并且只需要很短的旋轉時間,因此速度會非常快。
操作系統一般將內存和磁盤分割成固態大小的塊,每一塊稱為一頁,內存與磁盤以頁為單位交換數據。數據庫系統將索引的一個節點的大小設置為頁的大小,使得一次 I/O 就能完全載入一個節點,并且可以利用預讀特性,相鄰的節點也能夠被預先載入。
更多內容請參考:[MySQL 索引背后的數據結構及算法原理](http://blog.codinglabs.org/articles/theory-of-mysql-index.html)
### 3\. 索引分類
| 特性 | 說明 | InnoDB | MyISAM | MEMORY |
| --- | --- | --- | --- | --- |
| B樹索引 (B-tree indexes) | 自增ID物理連續性更高,
二叉樹,紅黑樹高度不可控 | √ | √ | √ |
| R樹索引 (R-tree indexes) | 空間索引 | | √ | |
| 哈希索引 (Hash indexes) | 無法做范圍查詢 | √ | | √ |
| 全文索引 (Full-text indexes) | | √ | √ | |
#### B+Tree 索引
B+Tree 索引是大多數 MySQL 存儲引擎的默認索引類型。
因為不再需要進行全表掃描,只需要對樹進行搜索即可,因此查找速度快很多。除了用于查找,還可以用于排序和分組。
可以指定多個列作為索引列,多個索引列共同組成鍵。
B+Tree 索引適用于全鍵值、鍵值范圍和鍵前綴查找,其中鍵前綴查找只適用于最左前綴查找。
如果不是按照索引列的順序進行查找,則無法使用索引。
InnoDB 的 B+Tree 索引分為**主索引**和**輔助索引**。
主索引的葉子節點 data 域記錄著完整的數據記錄,這種索引方式被稱為聚簇索引。因為無法把數據行存放在兩個不同的地方,所以一個表只能有一個聚簇索引。
[](https://github.com/frank-lam/fullstack-tutorial/blob/master/notes/assets/c28c6fbc-2bc1-47d9-9b2e-cf3d4034f877.jpg)
輔助索引的葉子節點的 data 域記錄著主鍵的值,因此在使用輔助索引進行查找時,需要先查找到主鍵值,然后再到主索引中進行查找。
[](https://github.com/frank-lam/fullstack-tutorial/blob/master/notes/assets/7ab8ca28-2a41-4adf-9502-cc0a21e63b51.jpg)
#### 哈希索引
InnoDB 引擎有一個特殊的功能叫 “自適應哈希索引”,當某個索引值被使用的非常頻繁時,會在 B+Tree 索引之上再創建一個哈希索引,這樣就讓 B+Tree 索引具有哈希索引的一些優點,比如快速的哈希查找。
哈希索引能以 O(1) 時間進行查找,但是失去了有序性,它具有以下限制:
* 無法用于排序與分組;
* 只支持精確查找,無法用于部分查找和范圍查找;
#### 全文索引
MyISAM 存儲引擎支持全文索引,用于查找文本中的關鍵詞,而不是直接比較是否相等。查找條件使用 MATCH AGAINST,而不是普通的 WHERE。
全文索引一般使用倒排索引實現,它記錄著關鍵詞到其所在文檔的映射。
InnoDB 存儲引擎在 MySQL 5.6.4 版本中也開始支持全文索引。
#### 空間數據索引(R-Tree)
MyISAM 存儲引擎支持空間數據索引,可以用于地理數據存儲。空間數據索引會從所有維度來索引數據,可以有效地使用任意維度來進行組合查詢。
必須使用 GIS 相關的函數來維護數據。
### 4\. 索引的特點
* 可以加快數據庫的檢索速度
* 降低數據庫插入、修改、刪除等維護的速度
* 只能創建在表上,不能創建到視圖上
* 既可以直接創建又可以間接創建
* 可以在優化隱藏中使用索引
* 使用查詢處理器執行SQL語句,在一個表上,一次只能使用一個索引
### 5\. 索引的優點
* 創建唯一性索引,保證數據庫表中每一行數據的唯一性
* 大大加快數據的檢索速度,這是創建索引的最主要的原因
* 加速數據庫表之間的連接,特別是在實現數據的參考完整性方面特別有意義
* 在使用分組和排序子句進行數據檢索時,同樣可以顯著減少查詢中分組和排序的時間
* 通過使用索引,可以在查詢中使用優化隱藏器,提高系統的性能
### 6\. 索引的缺點
* 創建索引和維護索引要耗費時間,這種時間隨著數據量的增加而增加
* 索引需要占用物理空間,除了數據表占用數據空間之外,每一個索引還要占一定的物理空間,如果建立聚簇索引,那么需要的空間就會更大
* 當對表中的數據進行增加、刪除和修改的時候,索引也需要維護,降低數據維護的速度
### 7\. 索引失效
> 美團面經:哪些情況下不會使用索引?
* 如果MySQL估計使用**全表掃秒比使用索引快**,則不適用索引。
例如,如果列key均勻分布在1和100之間,下面的查詢使用索引就不是很好:select \* from table\_name where key>1 and key<90;
* 如果**條件中有or**,即使其中有條件帶索引也不會使用
例如:select \* from table\_name where key1='a' or key2='b';如果在key1上有索引而在key2上沒有索引,則該查詢也不會走索引
* 復合索引,如果索引列**不是復合索引的第一部分**,則不使用索引(即不符合最左前綴)
例如,復合索引為(key1,key2),則查詢select \* from table\_name where key2='b';將不會使用索引
* 如果**like是以 % 開始的**,則該列上的索引不會被使用。
例如select \* from table\_name where key1 like '%a';該查詢即使key1上存在索引,也不會被使用如果列類型是字符串,那一定要在條件中使用引號引起來,否則不會使用索引
* 如果列為字符串,則where條件中必須將字符常量值加引號,否則即使該列上存在索引,也不會被使用。
例如,select \* from table\_name where key1=1;如果key1列保存的是字符串,即使key1上有索引,也不會被使用。
* 如果使用MEMORY/HEAP表,并且where條件中不使用“=”進行索引列,那么不會用到索引,head表只有在“=”的條件下才會使用索引
### 8\. 在什么情況下適合建立索引
* 為經常出現在關鍵字order by、group by、distinct后面的字段,建立索引。
* 在union等集合操作的結果集字段上,建立索引。其建立索引的目的同上。
* 為經常用作查詢選擇 where 后的字段,建立索引。
* 在經常用作表連接 join 的屬性上,建立索引。
* 考慮使用索引覆蓋。對數據很少被更新的表,如果用戶經常只查詢其中的幾個字段,可以考慮在這幾個字段上建立索引,從而將表的掃描改變為索引的掃描。
更多資料:[MySQL索引背后的數據結構及算法原理](http://www.hmoore.net/kancloud/theory-of-mysql-index/41846)
## 9\. 為什么用B+樹做索引而不用B-樹或紅黑樹
B+ 樹只有葉節點存放數據,其余節點用來索引,而 B- 樹是每個索引節點都會有 Data 域。所以從 InooDB 的角度來看,B+ 樹是用來充當索引的,一般來說索引非常大,尤其是關系性數據庫這種數據量大的索引能達到億級別,所以為了減少內存的占用,索引也會被存儲在磁盤上。
* 那么 MySQL如何衡量查詢效率呢?答:磁盤 IO 次數
* B- 樹 / B+ 樹 的特點就是每層節點數目非常多,層數很少,目的就是為了就少磁盤 IO 次數,但是 B- 樹的每個節點都有 data 域(指針),這無疑增大了節點大小,說白了增加了磁盤 IO 次數(磁盤 IO 一次讀出的數據量大小是固定的,單個數據變大,每次讀出的就少,IO 次數增多,一次 IO 多耗時),而 B+ 樹除了葉子節點其它節點并不存儲數據,節點小,磁盤 IO 次數就少。
* B+ 樹所有的 Data 域在葉子節點,一般來說都會進行一個優化,就是**將所有的葉子節點用指針串起來**。這樣遍歷葉子節點就能獲得全部數據,這樣就能進行區間訪問啦。在數據庫中基于范圍的查詢是非常頻繁的,而 B 樹不支持這樣的遍歷操作。
* B 樹相對于紅黑樹的區別
* **AVL 樹和紅黑樹基本都是存儲在內存中才會使用的數據結構**。在大規模數據存儲的時候,紅黑樹往往出現由于**樹的深度過大**而造成磁盤 IO 讀寫過于頻繁,進而導致效率低下的情況。為什么會出現這樣的情況,我們知道要獲取磁盤上數據,必須先通過磁盤移動臂移動到數據所在的柱面,然后找到指定盤面,接著旋轉盤面找到數據所在的磁道,最后對數據進行讀寫。磁盤IO代價主要花費在查找所需的柱面上,樹的深度過大會造成磁盤IO頻繁讀寫。根據**磁盤查找存取的次數往往由樹的高度所決定**,所以,只要我們通過某種較好的樹結構減少樹的結構盡量減少樹的高度,B樹可以有多個子女,從幾十到上千,可以降低樹的高度。
* **數據庫系統的設計者巧妙利用了磁盤預讀原理**,將一個節點的大小設為等于一個頁,這樣每個節點只需要一次 I/O 就可以完全載入。為了達到這個目的,在實際實現 B-Tree 還需要使用如下技巧:每次新建節點時,直接申請一個頁的空間,這樣就保證**一個節點物理上也存儲在一個頁里**,加之計算機存儲分配都是按頁對齊的,就實現了一個 node 只需一次 I/O。
## 10\. 聯合索引
### 1\. 什么是聯合索引
兩個或更多個列上的索引被稱作聯合索引,聯合索引又叫復合索引。對于復合索引:Mysql 從左到右的使用索引中的字段,一個查詢可以只使用索引中的一部份,但只能是最左側部分。
例如索引是key index (a,b,c),可以支持\[a\]、\[a,b\]、\[a,b,c\] 3種組合進行查找,但不支 \[b,c\] 進行查找。當最左側字段是常量引用時,索引就十分有效。
### 2\. 命名規則
1. 需要加索引的字段,要在 where 條件中
2. 數據量少的字段不需要加索引
3. 如果 where 條件中是OR關系,加索引不起作用
4. 符合最左原則
### 3\. 創建索引
在執行 CREATE TABLE 語句時可以創建索引,也可以單獨用 CREATE INDEX 或 ALTER TABLE 來為表增加索引。
**ALTER TABLE**
ALTER TABLE 用來創建普通索引、UNIQUE 索引或 PRIMARY KEY 索引。
例如:
~~~sql
ALTER TABLE table_name ADD INDEX index_name (column_list)
ALTER TABLE table_name ADD UNIQUE (column_list)
ALTER TABLE table_name ADD PRIMARY KEY (column_list)
~~~
其中 table\_name 是要增加索引的表名,column\_list 指出對哪些列進行索引,多列時各列之間用逗號分隔。索引名 index\_name 可選,缺省時,MySQL將根據第一個索引列賦一個名稱。另外,ALTER TABLE 允許在單個語句中更改多個表,因此可以在同時創建多個索引。
**CREATE INDEX**
CREATE INDEX 可對表增加普通索引或 UNIQUE 索引。
例如:
~~~sql
CREATE INDEX index_name ON table_name (column_list)
CREATE UNIQUE INDEX index_name ON table_name (column_list)
~~~
table\_name、index\_name 和 column\_list 具有與 ALTER TABLE 語句中相同的含義,索引名不可選。另外,不能用 CREATE INDEX 語句創建 PRIMARY KEY 索引。
### 4\. 索引類型
在創建索引時,可以規定索引能否包含重復值。如果不包含,則索引應該創建為 PRIMARY KEY 或 UNIQUE 索引。對于單列惟一性索引,這保證單列不包含重復的值。對于多列惟一性索引,保證多個值的組合不重復。 PRIMARY KEY 索引和 UNIQUE 索引非常類似。
事實上,PRIMARY KEY 索引僅是一個具有名稱 PRIMARY 的 UNIQUE 索引。這表示一個表只能包含一個 PRIMARY KEY,因為一個表中不可能具有兩個同名的索引。 下面的SQL語句對 students 表在 sid 上添加 PRIMARY KEY 索引。 ? ALTER TABLE students ADD PRIMARY KEY (sid)
### 5\. 刪除索引
可利用 ALTER TABLE 或 DROP INDEX 語句來刪除索引。類似于 CREATE INDEX 語句,DROP INDEX 可以在 ALTER TABLE 內部作為一條語句處理,語法如下。
~~~sql
DROP INDEX index_name ON talbe_name
ALTER TABLE table_name DROP INDEX index_name
ALTER TABLE table_name DROP PRIMARY KEY
~~~
其中,前兩條語句是等價的,刪除掉 table\_name 中的索引 index\_name。
第3條語句只在刪除 PRIMARY KEY 索引時使用,因為一個表只可能有一個 PRIMARY KEY 索引,因此不需要指定索引名。如果沒有創建 PRIMARY KEY 索引,但表具有一個或多個 UNIQUE 索引,則 MySQL 將刪除第一個 UNIQUE 索引。
如果從表中刪除了某列,則索引會受到影響。對于多列組合的索引,如果刪除其中的某列,則該列也會從索引中刪除。如果刪除組成索引的所有列,則整個索引將被刪除。
### 6\. 什么情況下使用索引
1. 為了快速查找匹配WHERE條件的行。
2. 為了從考慮的條件中消除行。
3. 如果表有一個multiple-column索引,任何一個索引的最左前綴可以通過使用優化器來查找行。
4. 查詢中與其它表關聯的字,字段常常建立了外鍵關系
5. 查詢中統計或分組統計的字段
* select max(hbs\_bh) from zl\_yhjbqk
* select qc\_bh,count(\*) from zl\_yhjbqk group by qc\_bh
更多請轉向:[MySQL-聯合索引 - 簡書](https://www.jianshu.com/p/f65be52d5e2b)
## 11\. 主鍵、外鍵和索引的區別
| | 定義 | 作用 | 個數 |
| --- | --- | --- | --- |
| **主鍵** | 唯一標識一條記錄,不能有重復的,不允許為空 | 用來保證數據完整性 | 主鍵只能有一個 |
| **外鍵** | 表的外鍵是另一表的主鍵,外鍵可以有重復的,可以是空值 | 用來和其他表建立聯系用的 | 一個表可以有多個外鍵 |
| **索引** | 該字段沒有重復值,但可以有一個空值 | 是提高查詢排序的速度 | 一個表可以有多個惟一索引 |
## 12\. 聚集索引與非聚集索引
[https://www.cnblogs.com/s-b-b/p/8334593.html](https://www.cnblogs.com/s-b-b/p/8334593.html)
聚集索引一定是唯一索引。但唯一索引不一定是聚集索引。
聚集索引,在索引頁里直接存放數據,而非聚集索引在索引頁里存放的是索引,這些索引指向專門的數據頁的數據。
##13\. 數據庫中的分頁查詢語句怎么寫,如何優化
* Mysql 的 limit 用法
* SELECT \* FROM table LIMIT \[offset,\] rows | rows OFFSET offset
* LIMIT 接受一個或兩個數字參數。參數必須是一個整數常量。如果給定兩個參數,第一個參數指定第一個返回記錄行的偏移量,第二個參數指定返回記錄行的最大數目。初始記錄行的偏移量是 0(而不是 1)
* 最基本的分頁方式:SELECT ... FROM ... WHERE ... ORDER BY ... LIMIT ...
## 14\. 常用的數據庫有哪些?Redis用過嗎?
* 常用的數據庫有哪些?Redis用過嗎?
* 常用的數據庫
* MySQL
* SQLServer
* Redis
* Redis 是一個速度非常快的非關系型數據庫,他可以存儲鍵(key)與5種不同類型的值(value)之間的映射,可以將存儲在內存中的鍵值對數據持久化到硬盤中。
* 與 Memcached 相比
* 兩者都可用于存儲鍵值映射,彼此性能也相差無幾
* Redis 能夠自動以兩種不同的方式將數據寫入硬盤
* Redis 除了能存儲普通的字符串鍵之外,還可以存儲其他4種數據結構,memcached 只能存儲字符串鍵
* Redis 既能用作主數據庫,由可以作為其他存儲系統的輔助數據庫
* Redis應用場景
* 緩存、任務隊列、應用排行榜、網站訪問統計、數據過期處理、分布式集群架構中的session分離
* Redis特點
* 高并發讀寫
* 海量數據的高效存儲和訪問
* 高可擴展性和高可用性
## 15\. Redis的數據結構
* STRING:可以是字符串、整數或者浮點數
* LIST:一個鏈表,鏈表上的每個節點都包含了一個字符串
* SET:包含字符串的無序收集器(unordered collection),并且被包含的每個字符串都是獨一無二、各不相同的
* HAST:包含鍵值對的無序散列表
* ZSET:字符串成員(member)與浮點數分值(score)之間的有序映射,元素的排列順序由分值的大小決定
[](https://github.com/frank-lam/fullstack-tutorial/blob/master/notes/pics/redis-data-structure-types.jpeg)
注:更多 Redis 相關內容將在[Redis](https://github.com/frank-lam/fullstack-tutorial/blob/master/notes/redis.md)中進行展開,請轉向。
## 16\. 分庫分表
簡單來說,數據的切分就是通過某種特定的條件,將我們存放在同一個數據庫中的數據分散存放到多個數據庫(主機)中,以達到分散單臺設備負載的效果,即分庫分表。
數據的切分根據其切分規則的類型,可以分為如下兩種切分模式。
* 垂直(縱向)切分:把單一的表拆分成多個表,并分散到不同的數據庫(主機)上。
* 水平(橫向)切分:根據表中數據的邏輯關系,將同一個表中的數據按照某種條件拆分到多臺數據庫(主機)上。
### 1\. 垂直切分
[](https://github.com/frank-lam/fullstack-tutorial/blob/master/notes/assets/e130e5b8-b19a-4f1e-b860-223040525cf6.jpg)
垂直切分是將一張表按列切分成多個表,通常是按照列的關系密集程度進行切分,也可以利用垂直切分將經常被使用的列和不經常被使用的列切分到不同的表中。
在數據庫的層面使用垂直切分將按數據庫中表的密集程度部署到不同的庫中,例如將原來的電商數據庫垂直切分成商品數據庫 payDB、用戶數據庫 userBD 等。
#### 垂直切分的優點
* 拆分后業務清晰,拆分規則明確
* 系統之間進行整合或擴展很容易
* 按照成本、應用的等級、應用的類型等將表放到不同的機器上,便于管理
* 便于實現**動靜分離**、**冷熱分離**的數據庫表的設計模式
* 數據維護簡單
#### 垂直切分的缺點
* 部分業務表無法關聯(Join),只能通過接口方式解決,提高了系統的復雜度
* 受每種業務的不同限制,存在單庫性能瓶頸,不易進行數據擴展和提升性能
* 事務處理復雜
### 2\. 水平切分
[](https://github.com/frank-lam/fullstack-tutorial/blob/master/notes/assets/63c2909f-0c5f-496f-9fe5-ee9176b31aba.jpg)
水平切分又稱為 Sharding,它是將同一個表中的記錄拆分到多個結構相同的表中。
當一個表的數據不斷增多時,Sharding 是必然的選擇,它可以將數據分布到集群的不同節點上,從而緩存單個數據庫的壓力。
#### 水平切分的優點
* 單庫單表的數據保持在一定的量級,有助于性能的提高
* 切分的表的結構相同,應用層改造較少,只需要增加路由規則即可
* 提高了系統的穩定性和負載能力
#### 水平切分的缺點
* 切分后,數據是分散的,很難利用數據庫的Join操作,跨庫Join性能較差
* 拆分規則難以抽象
* 分片事務的一致性難以解決
* 數據擴容的難度和維護量極大
#### [](https://github.com/frank-lam/fullstack-tutorial/blob/master/notes/MySQL.md#垂直切分和水垂直切分和水平切分的共同點
* 存在分布式事務的問題
* 存在跨節點Join的問題
* 存在跨節點合并排序、分頁的問題
* 存在多數據源管理的問題
### 3\. Sharding 策略
* 哈希取模:hash(key) % NUM\_DB
* 比如按照 userId mod 64.將數據分布在64個服務器上
* 范圍:可以是 ID 范圍也可以是時間范圍
* 比如每臺服務器計劃存放一個億的數據,先將數據寫入服務器A.一旦服務器A寫滿,則將數據寫入服務器B,以此類推. 這種方式的好處是擴展方便.數據在各個服務器上分布均勻.
* 映射表:使用單獨的一個數據庫來存儲映射關系
### 4\. Sharding 存在的問題及解決方案
#### 事務問題
使用分布式事務來解決,比如 XA 接口。
#### JOIN
可以將原來的 JOIN 查詢分解成多個單表查詢,然后在用戶程序中進行 JOIN。
#### ID 唯一性
* 使用全局唯一 ID:GUID。
* 為每個分片指定一個 ID 范圍。
* 分布式 ID 生成器 (如 Twitter 的 Snowflake 算法)。
## 17\. 主從復制與讀寫分離
### 主從復制
主要涉及三個線程:binlog 線程、I/O 線程和 SQL 線程。
* **binlog 線程**:負責將主服務器上的數據更改寫入二進制文件(binlog)中。
* **I/O 線程**:負責從主服務器上讀取二進制日志文件,并寫入從服務器的中繼日志中。
* **SQL 線程**:負責讀取中繼日志并重放其中的 SQL 語句。
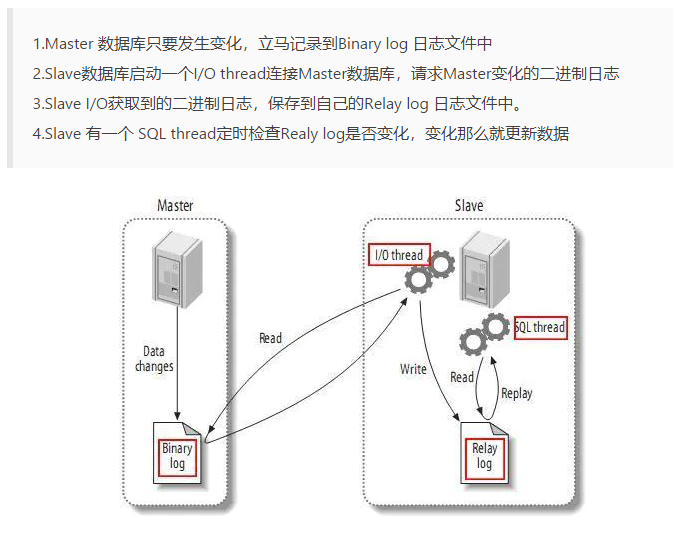
[](https://github.com/frank-lam/fullstack-tutorial/blob/master/notes/assets/master-slave.png)
### 讀寫分離
主服務器用來處理寫操作以及實時性要求比較高的讀操作,而從服務器用來處理讀操作。
讀寫分離常用代理方式來實現,代理服務器接收應用層傳來的讀寫請求,然后決定轉發到哪個服務器。
MySQL 讀寫分離能提高性能的原因在于:
* 主從服務器負責各自的讀和寫,極大程度緩解了鎖的爭用;
* 從服務器可以配置 MyISAM 引擎,提升查詢性能以及節約系統開銷;
* 增加冗余,提高可用性。
[](https://github.com/frank-lam/fullstack-tutorial/blob/master/notes/assets/master-slave-proxy.png)
## 18\. 查詢性能優化
### 1\. 使用 Explain 進行分析
Explain 用來分析 SELECT 查詢語句,開發人員可以通過分析 Explain 結果來優化查詢語句。
比較重要的字段有:
* **select\_type**: 查詢類型,有簡單查詢、聯合查詢、子查詢等
* **key**: 使用的索引
* **rows**: 掃描的行數
~~~sql
mysql> explain select * from user_info where id = 2\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: user_info
partitions: NULL
type: const
possible_keys: PRIMARY
key: PRIMARY
key_len: 8
ref: const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)
~~~
更多內容請參考:[MySQL 性能優化神器 Explain 使用分析](https://segmentfault.com/a/1190000008131735)
### 2\. 優化數據訪問
#### 1\. 減少請求的數據量
(一)只返回必要的列
最好不要使用 SELECT \* 語句。
(二)只返回必要的行
使用 WHERE 語句進行查詢過濾,有時候也需要使用 LIMIT 語句來限制返回的數據。
(三)緩存重復查詢的數據
使用緩存可以避免在數據庫中進行查詢,特別要查詢的數據經常被重復查詢,緩存可以帶來的查詢性能提升將會是非常明顯的。
#### 2\. 減少服務器端掃描的行數
最有效的方式是使用索引來覆蓋查詢。
### 3\. 重構查詢方式
#### 1\. 切分大查詢
一個大查詢如果一次性執行的話,可能一次鎖住很多數據、占滿整個事務日志、耗盡系統資源、阻塞很多小的但重要的查詢。
~~~sql
DELEFT FROM messages WHERE create < DATE_SUB(NOW(), INTERVAL 3 MONTH);
~~~
~~~sql
rows_affected = 0
do {
rows_affected = do_query(
"DELETE FROM messages WHERE create < DATE_SUB(NOW(), INTERVAL 3 MONTH) LIMIT 10000")
} while rows_affected > 0
~~~
#### 2\. 分解大連接查詢
將一個大連接查詢(JOIN)分解成對每一個表進行一次單表查詢,然后將結果在應用程序中進行關聯,這樣做的好處有:
* 讓緩存更高效。對于連接查詢,如果其中一個表發生變化,那么整個查詢緩存就無法使用。而分解后的多個查詢,即使其中一個表發生變化,對其它表的查詢緩存依然可以使用。
* 分解成多個單表查詢,這些單表查詢的緩存結果更可能被其它查詢使用到,從而減少冗余記錄的查詢。
* 減少鎖競爭;
* 在應用層進行連接,可以更容易對數據庫進行拆分,從而更容易做到高性能和可擴展。
* 查詢本身效率也可能會有所提升。例如下面的例子中,使用 IN() 代替連接查詢,可以讓 MySQL 按照 ID 順序進行查詢,這可能比隨機的連接要更高效。
~~~sql
SELECT * FROM tab
JOIN tag_post ON tag_post.tag_id=tag.id
JOIN post ON tag_post.post_id=post.id
WHERE tag.tag='mysql';
SELECT * FROM tag WHERE tag='mysql';
SELECT * FROM tag_post WHERE tag_id=1234;
SELECT * FROM post WHERE post.id IN (123,456,567,9098,8904);
~~~
## 19\. 鎖類型
MySQL/InnoDB 的加鎖,一直是一個面試中常問的話題。例如,數據庫如果有高并發請求,如何保證數據完整性?產生死鎖問題如何排查并解決?在工作過程中,也會經常用到,樂觀鎖,排它鎖等。
注:MySQL 是一個支持插件式存儲引擎的數據庫系統。下面的所有介紹,都是基于 InnoDB 存儲引擎,其他引擎的表現,會有較大的區別。
**版本查看**
~~~sql
select version();
~~~
**存儲引擎查看**
MySQL 給開發者提供了查詢存儲引擎的功能,我這里使用的是 MySQL5.6.4,可以使用:
~~~sql
SHOW ENGINES
~~~
### 1\. 樂觀鎖
用數據版本(Version)記錄機制實現,這是樂觀鎖最常用的一種實現方式。何謂數據版本?即為數據增加一個版本標識,一般是通過為數據庫表增加一個數字類型的 “version” 字段來實現。當讀取數據時,將version字段的值一同讀出,數據每更新一次,對此version值加1。當我們提交更新的時候,判斷數據庫表對應記錄的當前版本信息與第一次取出來的version值進行比對,如果數據庫表當前版本號與第一次取出來的version值相等,則予以更新,否則認為是過期數據。
**舉例**
1、數據庫表設計
三個字段,分別是 id,value,version
~~~sql
select id,value,version from TABLE where id=#{id}
~~~
2、每次更新表中的value字段時,為了防止發生沖突,需要這樣操作
~~~sql
update TABLE
set value=2,version=version+1
where id=#{id} and version=#{version};
~~~
### 2\. 悲觀鎖
與樂觀鎖相對應的就是悲觀鎖了。悲觀鎖就是在操作數據時,認為此操作會出現數據沖突,所以在進行每次操作時都要通過獲取鎖才能進行對相同數據的操作,這點跟 Java 中的 synchronized 很相似,所以悲觀鎖需要耗費較多的時間。另外與樂觀鎖相對應的,悲觀鎖是由數據庫自己實現了的,要用的時候,我們直接調用數據庫的相關語句就可以了。
說到這里,由悲觀鎖涉及到的另外兩個鎖概念就出來了,它們就是**共享鎖**與**排它鎖**。**共享鎖和排它鎖是悲觀鎖的不同的實現**,它倆都屬于悲觀鎖的范疇。
以排它鎖為例:
要使用悲觀鎖,我們必須關閉 mysql 數據庫的自動提交屬性,因為 MySQL 默認使用 autocommit 模式,也就是說,當你執行一個更新操作后,MySQL 會立刻將結果進行提交。
我們可以使用命令設置 MySQL 為非 autocommit 模式:
~~~sql
set autocommit=0;
# 設置完autocommit后,我們就可以執行我們的正常業務了。具體如下:
# 1. 開始事務 (三者選一就可以)
begin; / begin work; / start transaction;
# 2. 查詢表信息
select status from TABLE where id=1 for update;
# 3. 插入一條數據
insert into TABLE (id,value) values (2,2);
# 4. 修改數據為
update TABLE set value=2 where id=1;
# 5. 提交事務
commit;/commit work;
~~~
### 3\. 共享鎖
共享鎖又稱**讀鎖**(read lock),是讀取操作創建的鎖。其他用戶可以并發讀取數據,但任何事務都不能對數據進行修改(獲取數據上的排他鎖),直到已釋放所有共享鎖。
如果事務 T 對數據 A 加上共享鎖后,則其他事務只能對 A 再加共享鎖,不能加排他鎖。獲得共享鎖的事務只能讀數據,不能修改數據
打開第一個查詢窗口
~~~sql
#三者選一就可以
begin; / begin work; / start transaction;
SELECT * from TABLE where id = 1 lock in share mode;
~~~
然后在另一個查詢窗口中,對 id 為 1 的數據進行更新
~~~sql
update TABLE set name="www.souyunku.com" where id =1;
~~~
此時,操作界面進入了卡頓狀態,過了超時間,提示錯誤信息
如果在超時前,執行`commit`,此更新語句就會成功。
~~~sql
[SQL]update test_one set name="www.souyunku.com" where id =1;
[Err] 1205 - Lock wait timeout exceeded; try restarting transaction
~~~
加上共享鎖后,也提示錯誤信息
~~~sql
update test_one set name="www.souyunku.com" where id =1 lock in share mode;
[SQL]update test_one set name="www.souyunku.com" where id =1 lock in share mode;
[Err] 1064 - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'lock in share mode' at line 1
~~~
在查詢語句后面增加`lock in share mode`,MySQL 會對查詢結果中的每行都加共享鎖,當沒有其他線程對查詢結果集中的任何一行使用排他鎖時,可以成功申請共享鎖,否則會被阻塞。其他線程也可以讀取使用了共享鎖的表,而且這些線程讀取的是同一個版本的數據。
加上共享鎖后,對于`update,insert,delete`語句會自動加排它鎖。
### 4\. 排它鎖
排他鎖 exclusive lock(也叫 writer lock)又稱**寫鎖**。
**排它鎖是悲觀鎖的一種實現,在上面悲觀鎖也介紹過**。
若事務 1 對數據對象 A 加上 X 鎖,事務 1 可以讀 A 也可以修改 A,其他事務不能再對 A 加任何鎖,直到事物 1 釋放 A 上的鎖。這保證了其他事務在事物 1 釋放 A 上的鎖之前不能再讀取和修改 A。排它鎖會阻塞所有的排它鎖和共享鎖
讀取為什么要加讀鎖呢:防止數據在被讀取的時候被別的線程加上寫鎖
使用方式:在需要執行的語句后面加上`for update`就可以了
### 5\. 行鎖
行鎖又分**共享鎖**和**排他鎖**,由字面意思理解,就是給某一行加上鎖,也就是一條記錄加上鎖。
**注意**:行級鎖都是基于索引的,如果一條SQL語句用不到索引是不會使用行級鎖的,會使用表級鎖。
**共享鎖:**
名詞解釋:共享鎖又叫做讀鎖,所有的事務只能對其進行讀操作不能寫操作,加上共享鎖后在事務結束之前其他事務只能再加共享鎖,除此之外其他任何類型的鎖都不能再加了。
~~~sql
#結果集的數據都會加共享鎖
SELECT * from TABLE where id = "1" lock in share mode;
~~~
**排他鎖:**
名詞解釋:若某個事物對某一行加上了排他鎖,只能這個事務對其進行讀寫,在此事務結束之前,其他事務不能對其進行加任何鎖,其他進程可以讀取,不能進行寫操作,需等待其釋放。
~~~sql
select status from TABLE where id=1 for update;
~~~
可以參考之前演示的共享鎖,排它鎖語句
由于對于表中 id 字段為主鍵,就也相當于索引。執行加鎖時,會將 id 這個索引為 1 的記錄加上鎖,那么這個鎖就是行鎖。
### 6\. 表鎖
如何加表鎖
innodb 的行鎖是在有索引的情況下,沒有索引的表是鎖定全表的.
**Innodb中的行鎖與表鎖**
前面提到過,在 Innodb 引擎中既支持行鎖也支持表鎖,那么什么時候會鎖住整張表,什么時候或只鎖住一行呢? 只有通過索引條件檢索數據,InnoDB 才使用行級鎖,否則,InnoDB 將使用表鎖!
在實際應用中,要特別注意 InnoDB 行鎖的這一特性,不然的話,可能導致大量的鎖沖突,從而影響并發性能。
行級鎖都是基于索引的,如果一條 SQL 語句用不到索引是不會使用行級鎖的,會使用表級鎖。行級鎖的缺點是:由于需要請求大量的鎖資源,所以速度慢,內存消耗大。
### 7\. 死鎖
死鎖(Deadlock) 所謂死鎖:是指兩個或兩個以上的進程在執行過程中,因爭奪資源而造成的一種互相等待的現象,若無外力作用,它們都將無法推進下去。此時稱系統處于死鎖狀態或系統產生了死鎖,這些永遠在互相等待的進程稱為死鎖進程。由于資源占用是互斥的,當某個進程提出申請資源后,使得有關進程在無外力協助下,永遠分配不到必需的資源而無法繼續運行,這就產生了一種特殊現象死鎖。
解除正在死鎖的狀態有兩種方法:
**第一種**:
1. 查詢是否鎖表
~~~sql
show OPEN TABLES where In_use > 0;
~~~
2. 查詢進程(如果您有SUPER權限,您可以看到所有線程。否則,您只能看到您自己的線程)
~~~sql
show processlist
~~~
3. 殺死進程id(就是上面命令的id列)
~~~sql
kill id
~~~
**第二種**:
1. 查看當前的事務
~~~sql
SELECT * FROM INFORMATION_SCHEMA.INNODB_TRX;
~~~
2. 查看當前鎖定的事務
~~~sql
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS;
~~~
3. 查看當前等鎖的事務
~~~sql
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
~~~
**殺死進程**
~~~sql
kill 進程ID
~~~
如果系統資源充足,進程的資源請求都能夠得到滿足,死鎖出現的可能性就很低,否則就會因爭奪有限的資源而陷入死鎖。其次,進程運行推進順序與速度不同,也可能產生死鎖。 產生死鎖的四個必要條件:
1. 互斥條件:一個資源每次只能被一個進程使用。
2. 請求與保持條件:一個進程因請求資源而阻塞時,對已獲得的資源保持不放。
3. 不剝奪條件:進程已獲得的資源,在末使用完之前,不能強行剝奪。
4. 循環等待條件:若干進程之間形成一種頭尾相接的循環等待資源關系。
雖然不能完全避免死鎖,但可以使死鎖的數量減至最少。將死鎖減至最少可以增加事務的吞吐量并減少系統開銷,因為只有很少的事務回滾,而回滾會取消事務執行的所有工作。由于死鎖時回滾而由應用程序重新提交。
**下列方法有助于最大限度地降低死鎖:**
1. 按同一順序訪問對象
2. 避免事務中的用戶交互
3. 保持事務簡短并在一個批處理中
4. 使用低隔離級別
5. 使用綁定連接
說明:間隙鎖相關鎖知識待補充
參考資料:
* [Mysql鎖機制簡單了解一下 - Java面試通關手冊 - SegmentFault 思否](https://segmentfault.com/a/1190000015219003#articleHeader0)
* [鎖概念的理解 - 搜云庫 - SegmentFault 思否](https://segmentfault.com/a/1190000015815061#articleHeader7)
# 第二部分:高性能MySQL實踐
## 1\. 如何解決秒殺的性能問題和超賣的討論
搶訂單環節一般會帶來2個問題:
1、高并發
比較火熱的秒殺在線人數都是10w起的,如此之高的在線人數對于網站架構從前到后都是一種考驗。
2、超賣
任何商品都會有數量上限,如何避免成功下訂單買到商品的人數不超過商品數量的上限,這是每個搶購活動都要面臨的難題。
### 解決方案1
將存庫MySQL前移到Redis中,所有的寫操作放到內存中,由于Redis中不存在鎖故不會出現互相等待,并且由于Redis的寫性能和讀性能都遠高于MySQL,這就解決了高并發下的性能問題。然后通過隊列等異步手段,將變化的數據異步寫入到DB中。
優點:解決性能問題
缺點:沒有解決超賣問題,同時由于異步寫入DB,存在某一時刻DB和Redis中數據不一致的風險。
### 解決方案2
**引入隊列,然后將所有寫DB操作在單隊列中排隊,完全串行處理。當達到庫存閥值的時候就不在消費隊列,并關閉購買功能。這就解決了超賣問題。**
優點:解決超賣問題,略微提升性能。
缺點:性能受限于隊列處理機處理性能和DB的寫入性能中最短的那個,另外多商品同時搶購的時候需要準備多條隊列。
### 解決方案3
\*\*將提交操作變成兩段式,先申請后確認。然后利用Redis的原子自增操作(相比較MySQL的自增來說沒有空洞),同時利用Redis的事務特性來發號,保證拿到小于等于庫存閥值的號的人都可以成功提交訂單。\*\*然后數據異步更新到DB中。
優點:解決超賣問題,庫存讀寫都在內存中,故同時解決性能問題。
缺點:由于異步寫入DB,可能存在數據不一致。另可能存在少買,也就是如果拿到號的人不真正下訂單,可能庫存減為0,但是訂單數并沒有達到庫存閥值。
參考資料:
* [庫存扣多了,到底怎么整 | 架構師之路](https://mp.weixin.qq.com/s/waGRvyhab2z8b-BIw9bJeA)
* [如何解決秒殺的性能問題和超賣的討論 - CSDN博客](https://blog.csdn.net/zhoudaxia/article/details/38067003)
## 2\. 數據庫主從不一致,怎么解
數據庫主庫和從庫不一致,常見有這么幾種優化方案:
(1)業務可以接受,系統不優化
(2)強制讀主,高可用主庫,用緩存提高讀性能
(3)在cache里記錄哪些記錄發生過寫請求,來路由讀主還是讀從
參考資料:
* [數據庫主從不一致,怎么解?](https://mp.weixin.qq.com/s/5JYtta9aMGcic7o_ejna-A)
# 附錄:參考資料
* [視頻:MySQL 事務的隔離級別與鎖-極客學院](http://www.jikexueyuan.com/course/1524.html)
* [mysql-tutorial/3.5.md at master · jaywcjlove/mysql-tutorial](https://github.com/jaywcjlove/mysql-tutorial/blob/master/chapter3/3.5.md)
* [大神帶你剖析Mysql索引底層數據結構\_嗶哩嗶哩 (゜-゜)つロ 干杯~-bilibili](https://www.bilibili.com/video/av17252271?from=search&seid=3701018912873961528)
* [大眾點評訂單系統分庫分表實踐](https://tech.meituan.com/dianping_order_db_sharding.html)
* [庫存扣減還有這么多方案? | 架構師之路](https://mp.weixin.qq.com/s/Lfy7ek-vArVBTaUYfl64Bg)
* [關于分庫分表,這有一套大而全的輕量級架構設計思路(螞蟻金服技術專家)](https://www.toutiao.com/a6545626478447428103/?tt_from=weixin&article_category=stock×tamp=1524029012&app=news_article&iid=26214166927&wxshare_count=1)
* [Java大型互聯網架構-快速搞定大型互聯網網站分庫分表方案\_嗶哩嗶哩 (゜-゜)つロ 干杯~-bilibili](https://www.bilibili.com/video/av20966672?from=search&seid=6900253656657206494)
* [MySQL分庫分表\_ITPUB博客](http://blog.itpub.net/29254281/viewspace-1819422/)
- 一.JVM
- 1.1 java代碼是怎么運行的
- 1.2 JVM的內存區域
- 1.3 JVM運行時內存
- 1.4 JVM內存分配策略
- 1.5 JVM類加載機制與對象的生命周期
- 1.6 常用的垃圾回收算法
- 1.7 JVM垃圾收集器
- 1.8 CMS垃圾收集器
- 1.9 G1垃圾收集器
- 2.面試相關文章
- 2.1 可能是把Java內存區域講得最清楚的一篇文章
- 2.0 GC調優參數
- 2.1GC排查系列
- 2.2 內存泄漏和內存溢出
- 2.2.3 深入理解JVM-hotspot虛擬機對象探秘
- 1.10 并發的可達性分析相關問題
- 二.Java集合架構
- 1.ArrayList深入源碼分析
- 2.Vector深入源碼分析
- 3.LinkedList深入源碼分析
- 4.HashMap深入源碼分析
- 5.ConcurrentHashMap深入源碼分析
- 6.HashSet,LinkedHashSet 和 LinkedHashMap
- 7.容器中的設計模式
- 8.集合架構之面試指南
- 9.TreeSet和TreeMap
- 三.Java基礎
- 1.基礎概念
- 1.1 Java程序初始化的順序是怎么樣的
- 1.2 Java和C++的區別
- 1.3 反射
- 1.4 注解
- 1.5 泛型
- 1.6 字節與字符的區別以及訪問修飾符
- 1.7 深拷貝與淺拷貝
- 1.8 字符串常量池
- 2.面向對象
- 3.關鍵字
- 4.基本數據類型與運算
- 5.字符串與數組
- 6.異常處理
- 7.Object 通用方法
- 8.Java8
- 8.1 Java 8 Tutorial
- 8.2 Java 8 數據流(Stream)
- 8.3 Java 8 并發教程:線程和執行器
- 8.4 Java 8 并發教程:同步和鎖
- 8.5 Java 8 并發教程:原子變量和 ConcurrentMap
- 8.6 Java 8 API 示例:字符串、數值、算術和文件
- 8.7 在 Java 8 中避免 Null 檢查
- 8.8 使用 Intellij IDEA 解決 Java 8 的數據流問題
- 四.Java 并發編程
- 1.線程的實現/創建
- 2.線程生命周期/狀態轉換
- 3.線程池
- 4.線程中的協作、中斷
- 5.Java鎖
- 5.1 樂觀鎖、悲觀鎖和自旋鎖
- 5.2 Synchronized
- 5.3 ReentrantLock
- 5.4 公平鎖和非公平鎖
- 5.3.1 說說ReentrantLock的實現原理,以及ReentrantLock的核心源碼是如何實現的?
- 5.5 鎖優化和升級
- 6.多線程的上下文切換
- 7.死鎖的產生和解決
- 8.J.U.C(java.util.concurrent)
- 0.簡化版(快速復習用)
- 9.鎖優化
- 10.Java 內存模型(JMM)
- 11.ThreadLocal詳解
- 12 CAS
- 13.AQS
- 0.ArrayBlockingQueue和LinkedBlockingQueue的實現原理
- 1.DelayQueue的實現原理
- 14.Thread.join()實現原理
- 15.PriorityQueue 的特性和原理
- 16.CyclicBarrier的實際使用場景
- 五.Java I/O NIO
- 1.I/O模型簡述
- 2.Java NIO之緩沖區
- 3.JAVA NIO之文件通道
- 4.Java NIO之套接字通道
- 5.Java NIO之選擇器
- 6.基于 Java NIO 實現簡單的 HTTP 服務器
- 7.BIO-NIO-AIO
- 8.netty(一)
- 9.NIO面試題
- 六.Java設計模式
- 1.單例模式
- 2.策略模式
- 3.模板方法
- 4.適配器模式
- 5.簡單工廠
- 6.門面模式
- 7.代理模式
- 七.數據結構和算法
- 1.什么是紅黑樹
- 2.二叉樹
- 2.1 二叉樹的前序、中序、后序遍歷
- 3.排序算法匯總
- 4.java實現鏈表及鏈表的重用操作
- 4.1算法題-鏈表反轉
- 5.圖的概述
- 6.常見的幾道字符串算法題
- 7.幾道常見的鏈表算法題
- 8.leetcode常見算法題1
- 9.LRU緩存策略
- 10.二進制及位運算
- 10.1.二進制和十進制轉換
- 10.2.位運算
- 11.常見鏈表算法題
- 12.算法好文推薦
- 13.跳表
- 八.Spring 全家桶
- 1.Spring IOC
- 2.Spring AOP
- 3.Spring 事務管理
- 4.SpringMVC 運行流程和手動實現
- 0.Spring 核心技術
- 5.spring如何解決循環依賴問題
- 6.springboot自動裝配原理
- 7.Spring中的循環依賴解決機制中,為什么要三級緩存,用二級緩存不夠嗎
- 8.beanFactory和factoryBean有什么區別
- 九.數據庫
- 1.mybatis
- 1.1 MyBatis-# 與 $ 區別以及 sql 預編譯
- Mybatis系列1-Configuration
- Mybatis系列2-SQL執行過程
- Mybatis系列3-之SqlSession
- Mybatis系列4-之Executor
- Mybatis系列5-StatementHandler
- Mybatis系列6-MappedStatement
- Mybatis系列7-參數設置揭秘(ParameterHandler)
- Mybatis系列8-緩存機制
- 2.淺談聚簇索引和非聚簇索引的區別
- 3.mysql 證明為什么用limit時,offset很大會影響性能
- 4.MySQL中的索引
- 5.數據庫索引2
- 6.面試題收集
- 7.MySQL行鎖、表鎖、間隙鎖詳解
- 8.數據庫MVCC詳解
- 9.一條SQL查詢語句是如何執行的
- 10.MySQL 的 crash-safe 原理解析
- 11.MySQL 性能優化神器 Explain 使用分析
- 12.mysql中,一條update語句執行的過程是怎么樣的?期間用到了mysql的哪些log,分別有什么作用
- 十.Redis
- 0.快速復習回顧Redis
- 1.通俗易懂的Redis數據結構基礎教程
- 2.分布式鎖(一)
- 3.分布式鎖(二)
- 4.延時隊列
- 5.位圖Bitmaps
- 6.Bitmaps(位圖)的使用
- 7.Scan
- 8.redis緩存雪崩、緩存擊穿、緩存穿透
- 9.Redis為什么是單線程、及高并發快的3大原因詳解
- 10.布隆過濾器你值得擁有的開發利器
- 11.Redis哨兵、復制、集群的設計原理與區別
- 12.redis的IO多路復用
- 13.相關redis面試題
- 14.redis集群
- 十一.中間件
- 1.RabbitMQ
- 1.1 RabbitMQ實戰,hello world
- 1.2 RabbitMQ 實戰,工作隊列
- 1.3 RabbitMQ 實戰, 發布訂閱
- 1.4 RabbitMQ 實戰,路由
- 1.5 RabbitMQ 實戰,主題
- 1.6 Spring AMQP 的 AMQP 抽象
- 1.7 Spring AMQP 實戰 – 整合 RabbitMQ 發送郵件
- 1.8 RabbitMQ 的消息持久化與 Spring AMQP 的實現剖析
- 1.9 RabbitMQ必備核心知識
- 2.RocketMQ 的幾個簡單問題與答案
- 2.Kafka
- 2.1 kafka 基礎概念和術語
- 2.2 Kafka的重平衡(Rebalance)
- 2.3.kafka日志機制
- 2.4 kafka是pull還是push的方式傳遞消息的?
- 2.5 Kafka的數據處理流程
- 2.6 Kafka的腦裂預防和處理機制
- 2.7 Kafka中partition副本的Leader選舉機制
- 2.8 如果Leader掛了的時候,follower沒來得及同步,是否會出現數據不一致
- 2.9 kafka的partition副本是否會出現腦裂情況
- 十二.Zookeeper
- 0.什么是Zookeeper(漫畫)
- 1.使用docker安裝Zookeeper偽集群
- 3.ZooKeeper-Plus
- 4.zk實現分布式鎖
- 5.ZooKeeper之Watcher機制
- 6.Zookeeper之選舉及數據一致性
- 十三.計算機網絡
- 1.進制轉換:二進制、八進制、十六進制、十進制之間的轉換
- 2.位運算
- 3.計算機網絡面試題匯總1
- 十四.Docker
- 100.面試題收集合集
- 1.美團面試常見問題總結
- 2.b站部分面試題
- 3.比心面試題
- 4.騰訊面試題
- 5.哈羅部分面試
- 6.筆記
- 十五.Storm
- 1.Storm和流處理簡介
- 2.Storm 核心概念詳解
- 3.Storm 單機版本環境搭建
- 4.Storm 集群環境搭建
- 5.Storm 編程模型詳解
- 6.Storm 項目三種打包方式對比分析
- 7.Storm 集成 Redis 詳解
- 8.Storm 集成 HDFS 和 HBase
- 9.Storm 集成 Kafka
- 十六.Elasticsearch
- 1.初識ElasticSearch
- 2.文檔基本CRUD、集群健康檢查
- 3.shard&replica
- 4.document核心元數據解析及ES的并發控制
- 5.document的批量操作及數據路由原理
- 6.倒排索引
- 十七.分布式相關
- 1.分布式事務解決方案一網打盡
- 2.關于xxx怎么保證高可用的問題
- 3.一致性hash原理與實現
- 4.微服務注冊中心 Nacos 比 Eureka的優勢
- 5.Raft 協議算法
- 6.為什么微服務架構中需要網關
- 0.CAP與BASE理論
- 十八.Dubbo
- 1.快速掌握Dubbo常規應用
- 2.Dubbo應用進階
- 3.Dubbo調用模塊詳解
- 4.Dubbo調用模塊源碼分析
- 6.Dubbo協議模塊