
## RabbitMQ 是什么?
[](https://github.com/Snailclimb/JavaGuide/blob/main/docs/high-performance/message-queue/rabbitmq-questions.md#rabbitmq-%E6%98%AF%E4%BB%80%E4%B9%88)
RabbitMQ 是一個在 AMQP(Advanced Message Queuing Protocol )基礎上實現的,可復用的企業消息系統。它可以用于大型軟件系統各個模塊之間的高效通信,支持高并發,支持可擴展。它支持多種客戶端如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP 等,支持 AJAX,持久化,用于在分布式系統中存儲轉發消息,在易用性、擴展性、高可用性等方面表現不俗。
RabbitMQ 是使用 Erlang 編寫的一個開源的消息隊列,本身支持很多的協議:AMQP,XMPP, SMTP, STOMP,也正是如此,使的它變的非常重量級,更適合于企業級的開發。它同時實現了一個 Broker 構架,這意味著消息在發送給客戶端時先在中心隊列排隊,對路由(Routing)、負載均衡(Load balance)或者數據持久化都有很好的支持。
PS:也可能直接問什么是消息隊列?消息隊列就是一個使用隊列來通信的組件。
## RabbitMQ 特點?
[](https://github.com/Snailclimb/JavaGuide/blob/main/docs/high-performance/message-queue/rabbitmq-questions.md#rabbitmq-%E7%89%B9%E7%82%B9)
* **可靠性**: RabbitMQ 使用一些機制來保證可靠性, 如持久化、傳輸確認及發布確認等。
* **靈活的路由**: 在消息進入隊列之前,通過交換器來路由消息。對于典型的路由功能, RabbitMQ 己經提供了一些內置的交換器來實現。針對更復雜的路由功能,可以將多個交換器綁定在一起, 也可以通過插件機制來實現自己的交換器。
* **擴展性**: 多個 RabbitMQ 節點可以組成一個集群,也可以根據實際業務情況動態地擴展 集群中節點。
* **高可用性**: 隊列可以在集群中的機器上設置鏡像,使得在部分節點出現問題的情況下隊 列仍然可用。
* **多種協議**: RabbitMQ 除了原生支持 AMQP 協議,還支持 STOMP, MQTT 等多種消息 中間件協議。
* **多語言客戶端**:RabbitMQ 幾乎支持所有常用語言,比如 Java、 Python、 Ruby、 PHP、 C#、 JavaScript 等。
* **管理界面**: RabbitMQ 提供了一個易用的用戶界面,使得用戶可以監控和管理消息、集 群中的節點等。
* **插件機制**: RabbitMQ 提供了許多插件 , 以實現從多方面進行擴展,當然也可以編寫自 己的插件。
## RabbitMQ 核心概念?
[](https://github.com/Snailclimb/JavaGuide/blob/main/docs/high-performance/message-queue/rabbitmq-questions.md#rabbitmq-%E6%A0%B8%E5%BF%83%E6%A6%82%E5%BF%B5)
RabbitMQ 整體上是一個生產者與消費者模型,主要負責接收、存儲和轉發消息。可以把消息傳遞的過程想象成:當你將一個包裹送到郵局,郵局會暫存并最終將郵件通過郵遞員送到收件人的手上,RabbitMQ 就好比由郵局、郵箱和郵遞員組成的一個系統。從計算機術語層面來說,RabbitMQ 模型更像是一種交換機模型。
RabbitMQ 的整體模型架構如下:
[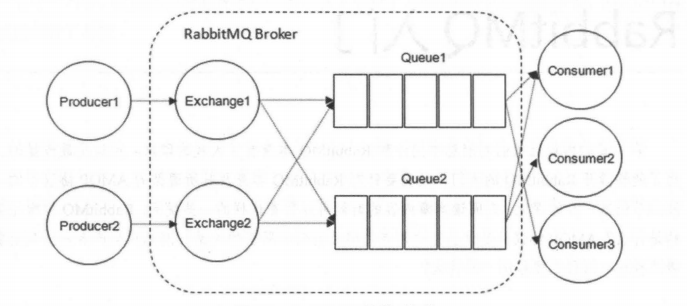](https://camo.githubusercontent.com/2149b6094cabfd3003238890bbbe17f9b46844cecfa459ceecc196648af9228a/68747470733a2f2f6f73732e6a61766167756964652e636e2f6769746875622f6a61766167756964652f7261626269746d712f39363338383534362e6a7067)
下面我會一一介紹上圖中的一些概念。
### Producer(生產者) 和 Consumer(消費者)
[](https://github.com/Snailclimb/JavaGuide/blob/main/docs/high-performance/message-queue/rabbitmq-questions.md#producer%E7%94%9F%E4%BA%A7%E8%80%85-%E5%92%8C-consumer%E6%B6%88%E8%B4%B9%E8%80%85)
* **Producer(生產者)**:生產消息的一方(郵件投遞者)
* **Consumer(消費者)**:消費消息的一方(郵件收件人)
消息一般由 2 部分組成:**消息頭**(或者說是標簽 Label)和**消息體**。消息體也可以稱為 payLoad ,消息體是不透明的,而消息頭則由一系列的可選屬性組成,這些屬性包括 routing-key(路由鍵)、priority(相對于其他消息的優先權)、delivery-mode(指出該消息可能需要持久性存儲)等。生產者把消息交由 RabbitMQ 后,RabbitMQ 會根據消息頭把消息發送給感興趣的 Consumer(消費者)。
### Exchange(交換器)
[](https://github.com/Snailclimb/JavaGuide/blob/main/docs/high-performance/message-queue/rabbitmq-questions.md#exchange%E4%BA%A4%E6%8D%A2%E5%99%A8)
在 RabbitMQ 中,消息并不是直接被投遞到**Queue(消息隊列)**中的,中間還必須經過**Exchange(交換器)**這一層,**Exchange(交換器)**會把我們的消息分配到對應的**Queue(消息隊列)**中。
**Exchange(交換器)**用來接收生產者發送的消息并將這些消息路由給服務器中的隊列中,如果路由不到,或許會返回給**Producer(生產者)**,或許會被直接丟棄掉 。這里可以將 RabbitMQ 中的交換器看作一個簡單的實體。
**RabbitMQ 的 Exchange(交換器) 有 4 種類型,不同的類型對應著不同的路由策略**:**direct(默認)**,**fanout**,**topic**, 和**headers**,不同類型的 Exchange 轉發消息的策略有所區別。這個會在介紹**Exchange Types(交換器類型)**的時候介紹到。
Exchange(交換器) 示意圖如下:
[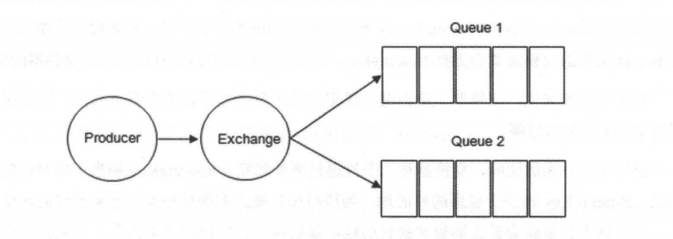](https://camo.githubusercontent.com/c8672a4a20d12c5f4698437b4311d7fcf30392a0be9a69d09909af40edd2edb1/68747470733a2f2f6f73732e6a61766167756964652e636e2f6769746875622f6a61766167756964652f7261626269746d712f32343030373839392e6a7067)
生產者將消息發給交換器的時候,一般會指定一個**RoutingKey(路由鍵)**,用來指定這個消息的路由規則,而這個**RoutingKey 需要與交換器類型和綁定鍵(BindingKey)聯合使用才能最終生效**。
RabbitMQ 中通過**Binding(綁定)**將**Exchange(交換器)**與**Queue(消息隊列)**關聯起來,在綁定的時候一般會指定一個**BindingKey(綁定建)**,這樣 RabbitMQ 就知道如何正確將消息路由到隊列了,如下圖所示。一個綁定就是基于路由鍵將交換器和消息隊列連接起來的路由規則,所以可以將交換器理解成一個由綁定構成的路由表。Exchange 和 Queue 的綁定可以是多對多的關系。
Binding(綁定) 示意圖:
[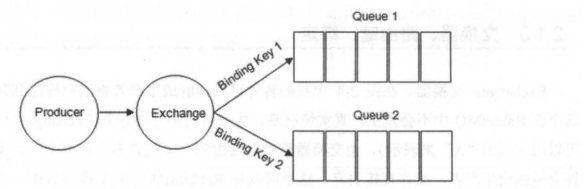](https://camo.githubusercontent.com/6753e9ff79bbd8802117e64288f45eba2aefa70a52e316cf31639fc505f36f45/68747470733a2f2f6f73732e6a61766167756964652e636e2f6769746875622f6a61766167756964652f7261626269746d712f37303535333133342e6a7067)
生產者將消息發送給交換器時,需要一個 RoutingKey,當 BindingKey 和 RoutingKey 相匹配時,消息會被路由到對應的隊列中。在綁定多個隊列到同一個交換器的時候,這些綁定允許使用相同的 BindingKey。BindingKey 并不是在所有的情況下都生效,它依賴于交換器類型,比如 fanout 類型的交換器就會無視,而是將消息路由到所有綁定到該交換器的隊列中。
### Queue(消息隊列)
[](https://github.com/Snailclimb/JavaGuide/blob/main/docs/high-performance/message-queue/rabbitmq-questions.md#queue%E6%B6%88%E6%81%AF%E9%98%9F%E5%88%97)
**Queue(消息隊列)**用來保存消息直到發送給消費者。它是消息的容器,也是消息的終點。一個消息可投入一個或多個隊列。消息一直在隊列里面,等待消費者連接到這個隊列將其取走。
**RabbitMQ**中消息只能存儲在**隊列**中,這一點和**Kafka**這種消息中間件相反。Kafka 將消息存儲在**topic(主題)**這個邏輯層面,而相對應的隊列邏輯只是 topic 實際存儲文件中的位移標識。 RabbitMQ 的生產者生產消息并最終投遞到隊列中,消費者可以從隊列中獲取消息并消費。
**多個消費者可以訂閱同一個隊列**,這時隊列中的消息會被平均分攤(Round-Robin,即輪詢)給多個消費者進行處理,而不是每個消費者都收到所有的消息并處理,這樣避免消息被重復消費。
**RabbitMQ**不支持隊列層面的廣播消費,如果有廣播消費的需求,需要在其上進行二次開發,這樣會很麻煩,不建議這樣做。
### Broker(消息中間件的服務節點)
[](https://github.com/Snailclimb/JavaGuide/blob/main/docs/high-performance/message-queue/rabbitmq-questions.md#broker%E6%B6%88%E6%81%AF%E4%B8%AD%E9%97%B4%E4%BB%B6%E7%9A%84%E6%9C%8D%E5%8A%A1%E8%8A%82%E7%82%B9)
對于 RabbitMQ 來說,一個 RabbitMQ Broker 可以簡單地看作一個 RabbitMQ 服務節點,或者 RabbitMQ 服務實例。大多數情況下也可以將一個 RabbitMQ Broker 看作一臺 RabbitMQ 服務器。
下圖展示了生產者將消息存入 RabbitMQ Broker,以及消費者從 Broker 中消費數據的整個流程。
[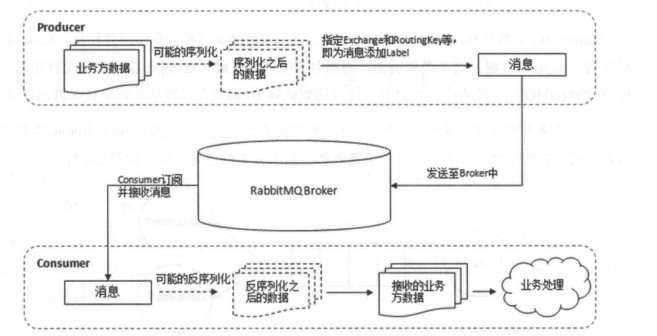](https://camo.githubusercontent.com/a2f5a9603117f9ee25b4e54016ebc0069f1a7f41519212f8bda1f9aa1a81ef2e/68747470733a2f2f6f73732e6a61766167756964652e636e2f6769746875622f6a61766167756964652f7261626269746d712f36373935323932322e6a7067)
這樣圖 1 中的一些關于 RabbitMQ 的基本概念我們就介紹完畢了,下面再來介紹一下**Exchange Types(交換器類型)**。
### Exchange Types(交換器類型)
[](https://github.com/Snailclimb/JavaGuide/blob/main/docs/high-performance/message-queue/rabbitmq-questions.md#exchange-types%E4%BA%A4%E6%8D%A2%E5%99%A8%E7%B1%BB%E5%9E%8B)
RabbitMQ 常用的 Exchange Type 有**fanout**、**direct**、**topic**、**headers**這四種(AMQP 規范里還提到兩種 Exchange Type,分別為 system 與 自定義,這里不予以描述)。
**1、fanout**
fanout 類型的 Exchange 路由規則非常簡單,它會把所有發送到該 Exchange 的消息路由到所有與它綁定的 Queue 中,不需要做任何判斷操作,所以 fanout 類型是所有的交換機類型里面速度最快的。fanout 類型常用來廣播消息。
**2、direct**
direct 類型的 Exchange 路由規則也很簡單,它會把消息路由到那些 Bindingkey 與 RoutingKey 完全匹配的 Queue 中。
[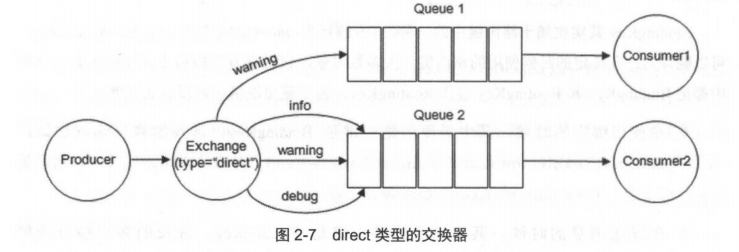](https://camo.githubusercontent.com/fab5afe3ff697fbd3af57175f22576dc901d31dbaab5871068108d9bf8cbe035/68747470733a2f2f6f73732e6a61766167756964652e636e2f6769746875622f6a61766167756964652f7261626269746d712f33373030383032312e6a7067)
以上圖為例,如果發送消息的時候設置路由鍵為“warning”,那么消息會路由到 Queue1 和 Queue2。如果在發送消息的時候設置路由鍵為"Info”或者"debug”,消息只會路由到 Queue2。如果以其他的路由鍵發送消息,則消息不會路由到這兩個隊列中。
direct 類型常用在處理有優先級的任務,根據任務的優先級把消息發送到對應的隊列,這樣可以指派更多的資源去處理高優先級的隊列。
**3、topic**
前面講到 direct 類型的交換器路由規則是完全匹配 BindingKey 和 RoutingKey ,但是這種嚴格的匹配方式在很多情況下不能滿足實際業務的需求。topic 類型的交換器在匹配規則上進行了擴展,它與 direct 類型的交換器相似,也是將消息路由到 BindingKey 和 RoutingKey 相匹配的隊列中,但這里的匹配規則有些不同,它約定:
* RoutingKey 為一個點號“.”分隔的字符串(被點號“.”分隔開的每一段獨立的字符串稱為一個單詞),如 “com.rabbitmq.client”、“java.util.concurrent”、“com.hidden.client”;
* BindingKey 和 RoutingKey 一樣也是點號“.”分隔的字符串;
* BindingKey 中可以存在兩種特殊字符串“\*”和“#”,用于做模糊匹配,其中“\*”用于匹配一個單詞,“#”用于匹配多個單詞(可以是零個)。
[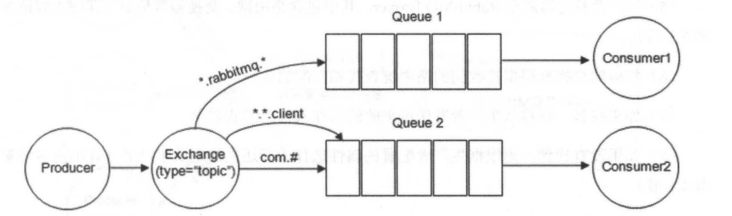](https://camo.githubusercontent.com/ac4dad70fbfde9178a983b99d35354d98f835981fc652194936c24aa4e3a6626/68747470733a2f2f6f73732e6a61766167756964652e636e2f6769746875622f6a61766167756964652f7261626269746d712f37333834332e6a7067)
以上圖為例:
* 路由鍵為 “com.rabbitmq.client” 的消息會同時路由到 Queue1 和 Queue2;
* 路由鍵為 “com.hidden.client” 的消息只會路由到 Queue2 中;
* 路由鍵為 “com.hidden.demo” 的消息只會路由到 Queue2 中;
* 路由鍵為 “java.rabbitmq.demo” 的消息只會路由到 Queue1 中;
* 路由鍵為 “java.util.concurrent” 的消息將會被丟棄或者返回給生產者(需要設置 mandatory 參數),因為它沒有匹配任何路由鍵。
**4、headers(不推薦)**
headers 類型的交換器不依賴于路由鍵的匹配規則來路由消息,而是根據發送的消息內容中的 headers 屬性進行匹配。在綁定隊列和交換器時指定一組鍵值對,當發送消息到交換器時,RabbitMQ 會獲取到該消息的 headers(也是一個鍵值對的形式),對比其中的鍵值對是否完全匹配隊列和交換器綁定時指定的鍵值對,如果完全匹配則消息會路由到該隊列,否則不會路由到該隊列。headers 類型的交換器性能會很差,而且也不實用,基本上不會看到它的存在。
## AMQP 是什么?
[](https://github.com/Snailclimb/JavaGuide/blob/main/docs/high-performance/message-queue/rabbitmq-questions.md#amqp-%E6%98%AF%E4%BB%80%E4%B9%88)
RabbitMQ 就是 AMQP 協議的`Erlang`的實現(當然 RabbitMQ 還支持`STOMP2`、`MQTT3`等協議 ) AMQP 的模型架構 和 RabbitMQ 的模型架構是一樣的,生產者將消息發送給交換器,交換器和隊列綁定 。
RabbitMQ 中的交換器、交換器類型、隊列、綁定、路由鍵等都是遵循的 AMQP 協議中相 應的概念。目前 RabbitMQ 最新版本默認支持的是 AMQP 0-9-1。
**AMQP 協議的三層**:
* **Module Layer**:協議最高層,主要定義了一些客戶端調用的命令,客戶端可以用這些命令實現自己的業務邏輯。
* **Session Layer**:中間層,主要負責客戶端命令發送給服務器,再將服務端應答返回客戶端,提供可靠性同步機制和錯誤處理。
* **TransportLayer**:最底層,主要傳輸二進制數據流,提供幀的處理、信道復用、錯誤檢測和數據表示等。
**AMQP 模型的三大組件**:
* **交換器 (Exchange)**:消息代理服務器中用于把消息路由到隊列的組件。
* **隊列 (Queue)**:用來存儲消息的數據結構,位于硬盤或內存中。
* **綁定 (Binding)**:一套規則,告知交換器消息應該將消息投遞給哪個隊列。
## **說說生產者 Producer 和消費者 Consumer?**
[](https://github.com/Snailclimb/JavaGuide/blob/main/docs/high-performance/message-queue/rabbitmq-questions.md#%E8%AF%B4%E8%AF%B4%E7%94%9F%E4%BA%A7%E8%80%85-producer-%E5%92%8C%E6%B6%88%E8%B4%B9%E8%80%85-consumer)
**生產者**:
* 消息生產者,就是投遞消息的一方。
* 消息一般包含兩個部分:消息體(`payload`)和標簽(`Label`)。
**消費者**:
* 消費消息,也就是接收消息的一方。
* 消費者連接到 RabbitMQ 服務器,并訂閱到隊列上。消費消息時只消費消息體,丟棄標簽。
## 說說 Broker 服務節點、Queue 隊列、Exchange 交換器?
[](https://github.com/Snailclimb/JavaGuide/blob/main/docs/high-performance/message-queue/rabbitmq-questions.md#%E8%AF%B4%E8%AF%B4-broker-%E6%9C%8D%E5%8A%A1%E8%8A%82%E7%82%B9queue-%E9%98%9F%E5%88%97exchange-%E4%BA%A4%E6%8D%A2%E5%99%A8)
* **Broker**:可以看做 RabbitMQ 的服務節點。一般情況下一個 Broker 可以看做一個 RabbitMQ 服務器。
* **Queue**:RabbitMQ 的內部對象,用于存儲消息。多個消費者可以訂閱同一隊列,這時隊列中的消息會被平攤(輪詢)給多個消費者進行處理。
* **Exchange**:生產者將消息發送到交換器,由交換器將消息路由到一個或者多個隊列中。當路由不到時,或返回給生產者或直接丟棄。
## 什么是死信隊列?如何導致的?
[](https://github.com/Snailclimb/JavaGuide/blob/main/docs/high-performance/message-queue/rabbitmq-questions.md#%E4%BB%80%E4%B9%88%E6%98%AF%E6%AD%BB%E4%BF%A1%E9%98%9F%E5%88%97%E5%A6%82%E4%BD%95%E5%AF%BC%E8%87%B4%E7%9A%84)
DLX,全稱為`Dead-Letter-Exchange`,死信交換器,死信郵箱。當消息在一個隊列中變成死信 (`dead message`) 之后,它能被重新發送到另一個交換器中,這個交換器就是 DLX,綁定 DLX 的隊列就稱之為死信隊列。
**導致的死信的幾種原因**:
* 消息被拒(`Basic.Reject /Basic.Nack`) 且`requeue = false`。
* 消息 TTL 過期。
* 隊列滿了,無法再添加。
## 什么是延遲隊列?RabbitMQ 怎么實現延遲隊列?
[](https://github.com/Snailclimb/JavaGuide/blob/main/docs/high-performance/message-queue/rabbitmq-questions.md#%E4%BB%80%E4%B9%88%E6%98%AF%E5%BB%B6%E8%BF%9F%E9%98%9F%E5%88%97rabbitmq-%E6%80%8E%E4%B9%88%E5%AE%9E%E7%8E%B0%E5%BB%B6%E8%BF%9F%E9%98%9F%E5%88%97)
延遲隊列指的是存儲對應的延遲消息,消息被發送以后,并不想讓消費者立刻拿到消息,而是等待特定時間后,消費者才能拿到這個消息進行消費。
RabbitMQ 本身是沒有延遲隊列的,要實現延遲消息,一般有兩種方式:
1. 通過 RabbitMQ 本身隊列的特性來實現,需要使用 RabbitMQ 的死信交換機(Exchange)和消息的存活時間 TTL(Time To Live)。
2. 在 RabbitMQ 3.5.7 及以上的版本提供了一個插件(rabbitmq-delayed-message-exchange)來實現延遲隊列功能。同時,插件依賴 Erlang/OPT 18.0 及以上。
也就是說,AMQP 協議以及 RabbitMQ 本身沒有直接支持延遲隊列的功能,但是可以通過 TTL 和 DLX 模擬出延遲隊列的功能。
## 什么是優先級隊列?
[](https://github.com/Snailclimb/JavaGuide/blob/main/docs/high-performance/message-queue/rabbitmq-questions.md#%E4%BB%80%E4%B9%88%E6%98%AF%E4%BC%98%E5%85%88%E7%BA%A7%E9%98%9F%E5%88%97)
RabbitMQ 自 V3.5.0 有優先級隊列實現,優先級高的隊列會先被消費。
可以通過`x-max-priority`參數來實現優先級隊列。不過,當消費速度大于生產速度且 Broker 沒有堆積的情況下,優先級顯得沒有意義。
## RabbitMQ 有哪些工作模式?
[](https://github.com/Snailclimb/JavaGuide/blob/main/docs/high-performance/message-queue/rabbitmq-questions.md#rabbitmq-%E6%9C%89%E5%93%AA%E4%BA%9B%E5%B7%A5%E4%BD%9C%E6%A8%A1%E5%BC%8F)
* 簡單模式
* work 工作模式
* pub/sub 發布訂閱模式
* Routing 路由模式
* Topic 主題模式
## RabbitMQ 消息怎么傳輸?
[](https://github.com/Snailclimb/JavaGuide/blob/main/docs/high-performance/message-queue/rabbitmq-questions.md#rabbitmq-%E6%B6%88%E6%81%AF%E6%80%8E%E4%B9%88%E4%BC%A0%E8%BE%93)
由于 TCP 鏈接的創建和銷毀開銷較大,且并發數受系統資源限制,會造成性能瓶頸,所以 RabbitMQ 使用信道的方式來傳輸數據。信道(Channel)是生產者、消費者與 RabbitMQ 通信的渠道,信道是建立在 TCP 鏈接上的虛擬鏈接,且每條 TCP 鏈接上的信道數量沒有限制。就是說 RabbitMQ 在一條 TCP 鏈接上建立成百上千個信道來達到多個線程處理,這個 TCP 被多個線程共享,每個信道在 RabbitMQ 都有唯一的 ID,保證了信道私有性,每個信道對應一個線程使用。
## **如何保證消息的可靠性?**
[](https://github.com/Snailclimb/JavaGuide/blob/main/docs/high-performance/message-queue/rabbitmq-questions.md#%E5%A6%82%E4%BD%95%E4%BF%9D%E8%AF%81%E6%B6%88%E6%81%AF%E7%9A%84%E5%8F%AF%E9%9D%A0%E6%80%A7)
消息到 MQ 的過程中搞丟,MQ 自己搞丟,MQ 到消費過程中搞丟。
* 生產者到 RabbitMQ:事務機制和 Confirm 機制,注意:事務機制和 Confirm 機制是互斥的,兩者不能共存,會導致 RabbitMQ 報錯。
* RabbitMQ 自身:持久化、集群、普通模式、鏡像模式。
* RabbitMQ 到消費者:basicAck 機制、死信隊列、消息補償機制。
## 如何保證 RabbitMQ 消息的順序性?
[](https://github.com/Snailclimb/JavaGuide/blob/main/docs/high-performance/message-queue/rabbitmq-questions.md#%E5%A6%82%E4%BD%95%E4%BF%9D%E8%AF%81-rabbitmq-%E6%B6%88%E6%81%AF%E7%9A%84%E9%A1%BA%E5%BA%8F%E6%80%A7)
* 拆分多個 queue(消息隊列),每個 queue(消息隊列) 一個 consumer(消費者),就是多一些 queue (消息隊列)而已,確實是麻煩點;
* 或者就一個 queue (消息隊列)但是對應一個 consumer(消費者),然后這個 consumer(消費者)內部用內存隊列做排隊,然后分發給底層不同的 worker 來處理。
## 如何保證 RabbitMQ 高可用的?
[](https://github.com/Snailclimb/JavaGuide/blob/main/docs/high-performance/message-queue/rabbitmq-questions.md#%E5%A6%82%E4%BD%95%E4%BF%9D%E8%AF%81-rabbitmq-%E9%AB%98%E5%8F%AF%E7%94%A8%E7%9A%84)
RabbitMQ 是比較有代表性的,因為是基于主從(非分布式)做高可用性的,我們就以 RabbitMQ 為例子講解第一種 MQ 的高可用性怎么實現。RabbitMQ 有三種模式:單機模式、普通集群模式、鏡像集群模式。
**單機模式**
Demo 級別的,一般就是你本地啟動了玩玩兒的?,沒人生產用單機模式。
**普通集群模式**
意思就是在多臺機器上啟動多個 RabbitMQ 實例,每個機器啟動一個。你創建的 queue,只會放在一個 RabbitMQ 實例上,但是每個實例都同步 queue 的元數據(元數據可以認為是 queue 的一些配置信息,通過元數據,可以找到 queue 所在實例)。
你消費的時候,實際上如果連接到了另外一個實例,那么那個實例會從 queue 所在實例上拉取數據過來。這方案主要是提高吞吐量的,就是說讓集群中多個節點來服務某個 queue 的讀寫操作。
**鏡像集群模式**
這種模式,才是所謂的 RabbitMQ 的高可用模式。跟普通集群模式不一樣的是,在鏡像集群模式下,你創建的 queue,無論元數據還是 queue 里的消息都會存在于多個實例上,就是說,每個 RabbitMQ 節點都有這個 queue 的一個完整鏡像,包含 queue 的全部數據的意思。然后每次你寫消息到 queue 的時候,都會自動把消息同步到多個實例的 queue 上。RabbitMQ 有很好的管理控制臺,就是在后臺新增一個策略,這個策略是鏡像集群模式的策略,指定的時候是可以要求數據同步到所有節點的,也可以要求同步到指定數量的節點,再次創建 queue 的時候,應用這個策略,就會自動將數據同步到其他的節點上去了。
這樣的好處在于,你任何一個機器宕機了,沒事兒,其它機器(節點)還包含了這個 queue 的完整數據,別的 consumer 都可以到其它節點上去消費數據。壞處在于,第一,這個性能開銷也太大了吧,消息需要同步到所有機器上,導致網絡帶寬壓力和消耗很重!RabbitMQ 一個 queue 的數據都是放在一個節點里的,鏡像集群下,也是每個節點都放這個 queue 的完整數據。
## 如何解決消息隊列的延時以及過期失效問題?
[](https://github.com/Snailclimb/JavaGuide/blob/main/docs/high-performance/message-queue/rabbitmq-questions.md#%E5%A6%82%E4%BD%95%E8%A7%A3%E5%86%B3%E6%B6%88%E6%81%AF%E9%98%9F%E5%88%97%E7%9A%84%E5%BB%B6%E6%97%B6%E4%BB%A5%E5%8F%8A%E8%BF%87%E6%9C%9F%E5%A4%B1%E6%95%88%E9%97%AE%E9%A2%98)
RabbtiMQ 是可以設置過期時間的,也就是 TTL。如果消息在 queue 中積壓超過一定的時間就會被 RabbitMQ 給清理掉,這個數據就沒了。那這就是第二個坑了。這就不是說數據會大量積壓在 mq 里,而是大量的數據會直接搞丟。我們可以采取一個方案,就是批量重導,這個我們之前線上也有類似的場景干過。就是大量積壓的時候,我們當時就直接丟棄數據了,然后等過了高峰期以后,比如大家一起喝咖啡熬夜到晚上 12 點以后,用戶都睡覺了。這個時候我們就開始寫程序,將丟失的那批數據,寫個臨時程序,一點一點的查出來,然后重新灌入 mq 里面去,把白天丟的數據給他補回來。也只能是這樣了。假設 1 萬個訂單積壓在 mq 里面,沒有處理,其中 1000 個訂單都丟了,你只能手動寫程序把那 1000 個訂單給查出來,手動發到 mq 里去再補一次。
參考文章鏈接:
http://www.hmoore.net/longxuan/rabbitmq-arron/117518
http://cmsblogs.com/?p=2786
- 一.JVM
- 1.1 java代碼是怎么運行的
- 1.2 JVM的內存區域
- 1.3 JVM運行時內存
- 1.4 JVM內存分配策略
- 1.5 JVM類加載機制與對象的生命周期
- 1.6 常用的垃圾回收算法
- 1.7 JVM垃圾收集器
- 1.8 CMS垃圾收集器
- 1.9 G1垃圾收集器
- 2.面試相關文章
- 2.1 可能是把Java內存區域講得最清楚的一篇文章
- 2.0 GC調優參數
- 2.1GC排查系列
- 2.2 內存泄漏和內存溢出
- 2.2.3 深入理解JVM-hotspot虛擬機對象探秘
- 1.10 并發的可達性分析相關問題
- 二.Java集合架構
- 1.ArrayList深入源碼分析
- 2.Vector深入源碼分析
- 3.LinkedList深入源碼分析
- 4.HashMap深入源碼分析
- 5.ConcurrentHashMap深入源碼分析
- 6.HashSet,LinkedHashSet 和 LinkedHashMap
- 7.容器中的設計模式
- 8.集合架構之面試指南
- 9.TreeSet和TreeMap
- 三.Java基礎
- 1.基礎概念
- 1.1 Java程序初始化的順序是怎么樣的
- 1.2 Java和C++的區別
- 1.3 反射
- 1.4 注解
- 1.5 泛型
- 1.6 字節與字符的區別以及訪問修飾符
- 1.7 深拷貝與淺拷貝
- 1.8 字符串常量池
- 2.面向對象
- 3.關鍵字
- 4.基本數據類型與運算
- 5.字符串與數組
- 6.異常處理
- 7.Object 通用方法
- 8.Java8
- 8.1 Java 8 Tutorial
- 8.2 Java 8 數據流(Stream)
- 8.3 Java 8 并發教程:線程和執行器
- 8.4 Java 8 并發教程:同步和鎖
- 8.5 Java 8 并發教程:原子變量和 ConcurrentMap
- 8.6 Java 8 API 示例:字符串、數值、算術和文件
- 8.7 在 Java 8 中避免 Null 檢查
- 8.8 使用 Intellij IDEA 解決 Java 8 的數據流問題
- 四.Java 并發編程
- 1.線程的實現/創建
- 2.線程生命周期/狀態轉換
- 3.線程池
- 4.線程中的協作、中斷
- 5.Java鎖
- 5.1 樂觀鎖、悲觀鎖和自旋鎖
- 5.2 Synchronized
- 5.3 ReentrantLock
- 5.4 公平鎖和非公平鎖
- 5.3.1 說說ReentrantLock的實現原理,以及ReentrantLock的核心源碼是如何實現的?
- 5.5 鎖優化和升級
- 6.多線程的上下文切換
- 7.死鎖的產生和解決
- 8.J.U.C(java.util.concurrent)
- 0.簡化版(快速復習用)
- 9.鎖優化
- 10.Java 內存模型(JMM)
- 11.ThreadLocal詳解
- 12 CAS
- 13.AQS
- 0.ArrayBlockingQueue和LinkedBlockingQueue的實現原理
- 1.DelayQueue的實現原理
- 14.Thread.join()實現原理
- 15.PriorityQueue 的特性和原理
- 16.CyclicBarrier的實際使用場景
- 五.Java I/O NIO
- 1.I/O模型簡述
- 2.Java NIO之緩沖區
- 3.JAVA NIO之文件通道
- 4.Java NIO之套接字通道
- 5.Java NIO之選擇器
- 6.基于 Java NIO 實現簡單的 HTTP 服務器
- 7.BIO-NIO-AIO
- 8.netty(一)
- 9.NIO面試題
- 六.Java設計模式
- 1.單例模式
- 2.策略模式
- 3.模板方法
- 4.適配器模式
- 5.簡單工廠
- 6.門面模式
- 7.代理模式
- 七.數據結構和算法
- 1.什么是紅黑樹
- 2.二叉樹
- 2.1 二叉樹的前序、中序、后序遍歷
- 3.排序算法匯總
- 4.java實現鏈表及鏈表的重用操作
- 4.1算法題-鏈表反轉
- 5.圖的概述
- 6.常見的幾道字符串算法題
- 7.幾道常見的鏈表算法題
- 8.leetcode常見算法題1
- 9.LRU緩存策略
- 10.二進制及位運算
- 10.1.二進制和十進制轉換
- 10.2.位運算
- 11.常見鏈表算法題
- 12.算法好文推薦
- 13.跳表
- 八.Spring 全家桶
- 1.Spring IOC
- 2.Spring AOP
- 3.Spring 事務管理
- 4.SpringMVC 運行流程和手動實現
- 0.Spring 核心技術
- 5.spring如何解決循環依賴問題
- 6.springboot自動裝配原理
- 7.Spring中的循環依賴解決機制中,為什么要三級緩存,用二級緩存不夠嗎
- 8.beanFactory和factoryBean有什么區別
- 九.數據庫
- 1.mybatis
- 1.1 MyBatis-# 與 $ 區別以及 sql 預編譯
- Mybatis系列1-Configuration
- Mybatis系列2-SQL執行過程
- Mybatis系列3-之SqlSession
- Mybatis系列4-之Executor
- Mybatis系列5-StatementHandler
- Mybatis系列6-MappedStatement
- Mybatis系列7-參數設置揭秘(ParameterHandler)
- Mybatis系列8-緩存機制
- 2.淺談聚簇索引和非聚簇索引的區別
- 3.mysql 證明為什么用limit時,offset很大會影響性能
- 4.MySQL中的索引
- 5.數據庫索引2
- 6.面試題收集
- 7.MySQL行鎖、表鎖、間隙鎖詳解
- 8.數據庫MVCC詳解
- 9.一條SQL查詢語句是如何執行的
- 10.MySQL 的 crash-safe 原理解析
- 11.MySQL 性能優化神器 Explain 使用分析
- 12.mysql中,一條update語句執行的過程是怎么樣的?期間用到了mysql的哪些log,分別有什么作用
- 十.Redis
- 0.快速復習回顧Redis
- 1.通俗易懂的Redis數據結構基礎教程
- 2.分布式鎖(一)
- 3.分布式鎖(二)
- 4.延時隊列
- 5.位圖Bitmaps
- 6.Bitmaps(位圖)的使用
- 7.Scan
- 8.redis緩存雪崩、緩存擊穿、緩存穿透
- 9.Redis為什么是單線程、及高并發快的3大原因詳解
- 10.布隆過濾器你值得擁有的開發利器
- 11.Redis哨兵、復制、集群的設計原理與區別
- 12.redis的IO多路復用
- 13.相關redis面試題
- 14.redis集群
- 十一.中間件
- 1.RabbitMQ
- 1.1 RabbitMQ實戰,hello world
- 1.2 RabbitMQ 實戰,工作隊列
- 1.3 RabbitMQ 實戰, 發布訂閱
- 1.4 RabbitMQ 實戰,路由
- 1.5 RabbitMQ 實戰,主題
- 1.6 Spring AMQP 的 AMQP 抽象
- 1.7 Spring AMQP 實戰 – 整合 RabbitMQ 發送郵件
- 1.8 RabbitMQ 的消息持久化與 Spring AMQP 的實現剖析
- 1.9 RabbitMQ必備核心知識
- 2.RocketMQ 的幾個簡單問題與答案
- 2.Kafka
- 2.1 kafka 基礎概念和術語
- 2.2 Kafka的重平衡(Rebalance)
- 2.3.kafka日志機制
- 2.4 kafka是pull還是push的方式傳遞消息的?
- 2.5 Kafka的數據處理流程
- 2.6 Kafka的腦裂預防和處理機制
- 2.7 Kafka中partition副本的Leader選舉機制
- 2.8 如果Leader掛了的時候,follower沒來得及同步,是否會出現數據不一致
- 2.9 kafka的partition副本是否會出現腦裂情況
- 十二.Zookeeper
- 0.什么是Zookeeper(漫畫)
- 1.使用docker安裝Zookeeper偽集群
- 3.ZooKeeper-Plus
- 4.zk實現分布式鎖
- 5.ZooKeeper之Watcher機制
- 6.Zookeeper之選舉及數據一致性
- 十三.計算機網絡
- 1.進制轉換:二進制、八進制、十六進制、十進制之間的轉換
- 2.位運算
- 3.計算機網絡面試題匯總1
- 十四.Docker
- 100.面試題收集合集
- 1.美團面試常見問題總結
- 2.b站部分面試題
- 3.比心面試題
- 4.騰訊面試題
- 5.哈羅部分面試
- 6.筆記
- 十五.Storm
- 1.Storm和流處理簡介
- 2.Storm 核心概念詳解
- 3.Storm 單機版本環境搭建
- 4.Storm 集群環境搭建
- 5.Storm 編程模型詳解
- 6.Storm 項目三種打包方式對比分析
- 7.Storm 集成 Redis 詳解
- 8.Storm 集成 HDFS 和 HBase
- 9.Storm 集成 Kafka
- 十六.Elasticsearch
- 1.初識ElasticSearch
- 2.文檔基本CRUD、集群健康檢查
- 3.shard&replica
- 4.document核心元數據解析及ES的并發控制
- 5.document的批量操作及數據路由原理
- 6.倒排索引
- 十七.分布式相關
- 1.分布式事務解決方案一網打盡
- 2.關于xxx怎么保證高可用的問題
- 3.一致性hash原理與實現
- 4.微服務注冊中心 Nacos 比 Eureka的優勢
- 5.Raft 協議算法
- 6.為什么微服務架構中需要網關
- 0.CAP與BASE理論
- 十八.Dubbo
- 1.快速掌握Dubbo常規應用
- 2.Dubbo應用進階
- 3.Dubbo調用模塊詳解
- 4.Dubbo調用模塊源碼分析
- 6.Dubbo協議模塊