
[TOC]
## **RPC協議基本組成**
---
### **RPC 協議名詞解釋**
在一個典型RPC的使用場景中,包含了服務發現、負載、容錯、網絡傳輸、序列化等組件,其中RPC協議就指明了程序如何進行網絡傳輸和序列化 。也就是說一個RPC協議的實現就等于一個非透明的遠程調用實現,如何做到的的呢?
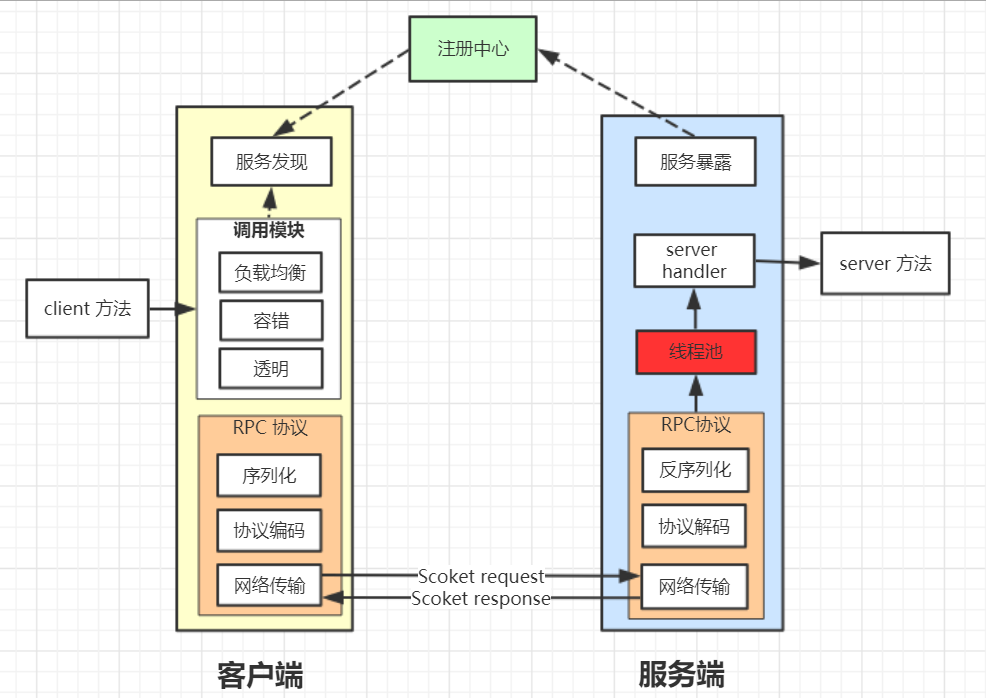
### **協議基本組成:**
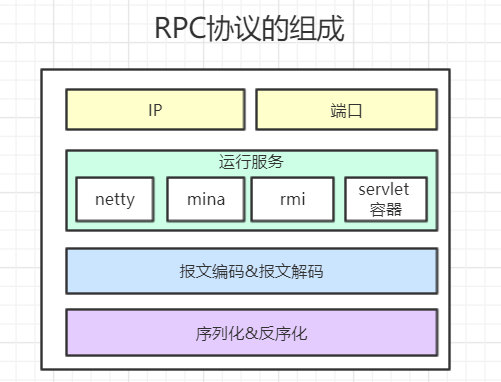
1. 地址:服務提供者地址
2. 端口:協議指定開放的端口
3. 報文編碼:協議報文編碼 ,分為請求頭和請求體兩部分。
4. 序列化方式:將請求體序列化成對象
1. Hessian2Serialization、
2. DubboSerialization、
3. JavaSerialization
4. JsonSerialization
5. 運行服務: 網絡傳輸實現
1. netty
2. mina
3. RMI 服務
4. servlet 容器(jetty、Tomcat、Jboss)?
## **Dubbo中所支持RPC協議使用**
---
**dubbo 支持的RPC協議列表**
| **名稱** | **實現描述** | **連接描述** | **適用場景** |
|:----|:----|:----|:----|
| **dubbo** | 傳輸服務: mina, netty(默認), grizzy序列化: hessian2(默認), java, fastjson自定義報文 | 單個長連接NIO異步傳輸 | 1、常規RPC調用2、傳輸數據量小3、提供者少于消費者 |
| **rmi** | 傳輸:java rmi 服務序列化:java原生二進制序列化 | 多個短連接BIO同步傳輸 | 1、常規RPC調用 2、與原RMI客戶端集成 3、可傳少量文件 4、不防火墻穿透 |
| **hessian** | 傳輸服務:servlet容器序列化:hessian二進制序列化 | 基于Http 協議傳輸,依懶servlet容器配置 | 1、提供者多于消費者 2、可傳大字段和文件 ~~3、跨語言調用~~ |
| **http** | 傳輸服務:servlet容器序列化:java原生二進制序列化 | 依懶servlet容器配置 | 1、數據包大小混合 |
| **thrift** | 與thrift RPC 實現集成,并在其基礎上修改了報文頭 | 長連接、NIO異步傳輸 | |
***關于RMI不支持防火墻穿透的補充說明:***
原因在于RMI 底層實現中會有兩個端口,一個是固定的用于服務發現的注冊端口,另外會生成一個***隨機***端口用于網絡傳輸。因為這個隨機端口就不能在防火墻中提前設置開放開。所以存在*防火墻穿透問題*
### **協議的使用與配置:**
Dubbo框架配置協議非常方便,用戶只需要在? provider 應用中 配置*<**dubbo:protocol>*?元素即可。
```
?<!--
?? name: 協議名稱 dubbo|rmi|hessian|http|
?? host:本機IP可不填,則系統自動獲取
?? port:端口、填-1表示系統自動選擇
?? server:運行服務? mina|netty|grizzy|servlet|jetty
?? serialization:序列化方式 hessian2|java|compactedjava|fastjson
?? 詳細配置參見dubbo 官網 dubbo.io
?-->
?<dubbo:protocol name="dubbo" host="192.168.0.11" port="20880" server="netty"?
? serialization=“hessian2” charset=“UTF-8” />
??
```
#TODO 演示采用其它協議來配置Dubbo
- [ ] dubbo 協議采用 json 進行序列化??(源碼參見:com.alibaba.dubbo.rpc.protocol.dubbo.DubboProtocol*)*
- [ ] 采用RMI協議?(源碼參見:*com.alibaba.dubbo.rpc.protocol.rmi.RmiProtocol)*
- [ ] 采用Http協議?(源碼參見:*com.alibaba.dubbo.rpc.protocol.http.HttpProtocol.InternalHandler)*
- [ ] 采用Heason協議?(源碼參見:com.alibaba.dubbo.rpc.protocol.hessian.HessianProtocol.HessianHandler)
new PrintWriter(System.out)
```
netstat -aon|findstr "17732"
```
序列化:
| | 特點 |
|:----|:----|
| fastjson | 文本型:體積較大,性能慢、跨語言、可讀性高 |
| fst | 二進制型:體積小、兼容 JDK 原生的序列化。要求 JDK 1.7 支持。 |
| hessian2 | 二進制型:跨語言、容錯性高、體積小 |
| java | 二進制型:在JAVA原生的基礎上 可以寫入Null |
| compactedjava | 二進制型:與java 類似,內容做了壓縮 |
| nativejava | 二進制型:原生的JAVA 序列化 |
| kryo | 二進制型:體積比hessian2 還要小,但容錯性 沒有hessian2 好 |
### Hessian 序列化:
* 參數及返回值需實現?Serializable?接口
* 參數及返回值不能自定義實現?List,?Map,?Number,?Date,?Calendar?等接口,只能用 JDK 自帶的實現,因為 hessian 會做特殊處理,自定義實現類中的屬性值都會丟失。
* Hessian 序列化,只傳成員屬性值和值的類型,不傳方法或靜態變量,兼容情況?[[1]](http://dubbo.apache.org/zh-cn/docs/user/references/protocol/dubbo.html#fn1)[[2]](http://dubbo.apache.org/zh-cn/docs/user/references/protocol/dubbo.html#fn2):
| **數據通訊** | **情況** | **結果** |
|:----|:----|:----|
| A->B | 類A多一種 屬性(或者說類B少一種 屬性) | 不拋異常,A多的那 個屬性的值,B沒有, 其他正常 |
| A->B | 枚舉A多一種 枚舉(或者說B少一種 枚舉),A使用多 出來的枚舉進行傳輸 | 拋異常 |
| A->B | 枚舉A多一種 枚舉(或者說B少一種 枚舉),A不使用 多出來的枚舉進行傳輸 | 不拋異常,B正常接 收數據 |
| A->B | A和B的屬性 名相同,但類型不相同 | 拋異常 |
| A->B | serialId 不相同 | 正常傳輸 |
接口增加方法,對客戶端無影響,如果該方法不是客戶端需要的,客戶端不需要重新部署。輸入參數和結果集中增加屬性,對客戶端無影響,如果客戶端并不需要新屬性,不用重新部署。
輸入參數和結果集屬性名變化,對客戶端序列化無影響,但是如果客戶端不重新部署,不管輸入還是輸出,屬性名變化的屬性值是獲取不到的。
總結:服務器端和客戶端對領域對象并不需要完全一致,而是按照最大匹配原則。
- [ ] 演示Hession2 序列化的容錯性
## **三 、RPC協議報文編碼與實現詳解**
---
### **RPC 傳輸實現:**
RPC的協議的傳輸是基于 TCP/IP 做為基礎使用Socket 或Netty、mina等網絡編程組件實現。但有個問題是TCP是面向字節流的無邊邊界協議,其只管負責數據傳輸并不會區分每次請求所對應的消息,這樣就會出現TCP協義傳輸當中的拆包與粘包問題
### **拆包與粘包產生的原因:**
我們知道tcp是以流動的方式傳輸數據,傳輸的最小單位為一個報文段(segment)。tcp Header中有個Options標識位,常見的標識為mss(Maximum Segment Size)指的是,連接層每次傳輸的數據有個最大限制MTU(Maximum Transmission Unit),一般是1500比特,超過這個量要分成多個報文段,mss則是這個最大限制減去TCP的header,光是要傳輸的數據的大小,一般為1460比特。換算成字節,也就是180多字節。
tcp為提高性能,發送端會將需要發送的數據發送到緩沖區,等待緩沖區滿了之后,再將緩沖中的數據發送到接收方。同理,接收方也有緩沖區這樣的機制,來接收數據。這時就會出現以下情況:
1. 應用程序寫入的數據大于MSS大小,這將會發生拆包。
2. 應用程序寫入數據小于MSS大小,這將會發生粘包。
3. 接收方法不及時讀取套接字緩沖區數據,這將發生粘包。
### **拆包與粘包解決辦法:**
1. 設置定長消息,服務端每次讀取既定長度的內容作為一條完整消息。
2. {"type":"message","content":"hello"}\n
3. 使用帶消息頭的協議、消息頭存儲消息開始標識及消息長度信息,服務端獲取消息頭的時候解析出消息長度,然后向后讀取該長度的內容。
**比如:** Http協議 heade 中的 Content-Length 就表示消息體的大小。
?????

??????
(注①:http 報文編碼)
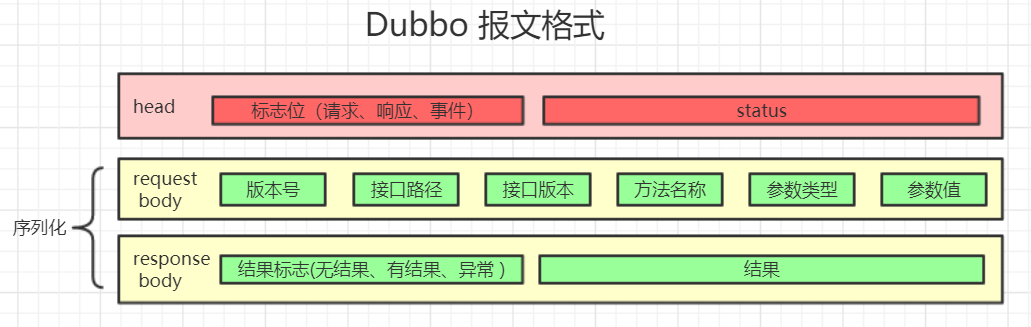
### Dubbo 協議報文編碼:
**注②Dubbo? 協議報文編碼:**
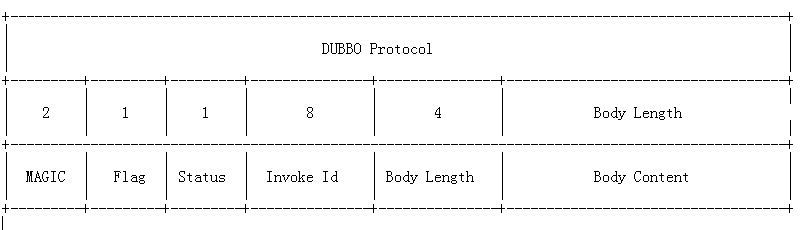
* **magic**:類似java字節碼文件里的魔數,用來判斷是不是dubbo協議的數據包。魔數是常量0xdabb,用于判斷報文的開始。
* **flag**:標志位, 一共8個地址位。低四位用來表示消息體數據用的序列化工具的類型(默認hessian),高四位中,第一位為1表示是request請求,第二位為1表示雙向傳輸(即有返回response),第三位為1表示是心跳ping事件。
* **status**:狀態位, 設置請求響應狀態,dubbo定義了一些響應的類型。具體類型見 com.alibaba.dubbo.remoting.exchange.Response
* **invoke id:**消息id, long 類型。每一個請求的唯一識別id(由于采用異步通訊的方式,用來把請求request和返回的response對應上)
* **body length:**消息體 body 長度, int 類型,即記錄Body Content有多少個字節。
*(注:相關源碼參見?**c**om.alibaba.dubbo.rpc.protocol.dubbo.DubboCodec**)*
### ***Dubbo協議的編解碼過程:***
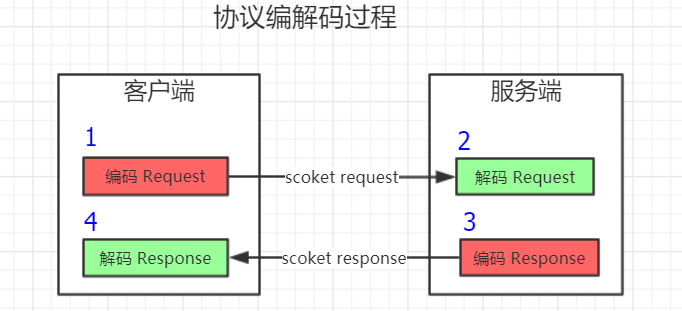
**Dubbo 協議編解碼實現過程**?*(源碼來源于**dubbo2.5.8? )*
```
1、DubboCodec.encodeRequestData() 116L // 編碼request
2、DecodeableRpcInvocation.decode() 89L // 解碼request
3、DubboCodec.encodeResponseData() 184L // 編碼response
4、DecodeableRpcResult.decode() 73L // 解碼response
```
**?**
- 一.JVM
- 1.1 java代碼是怎么運行的
- 1.2 JVM的內存區域
- 1.3 JVM運行時內存
- 1.4 JVM內存分配策略
- 1.5 JVM類加載機制與對象的生命周期
- 1.6 常用的垃圾回收算法
- 1.7 JVM垃圾收集器
- 1.8 CMS垃圾收集器
- 1.9 G1垃圾收集器
- 2.面試相關文章
- 2.1 可能是把Java內存區域講得最清楚的一篇文章
- 2.0 GC調優參數
- 2.1GC排查系列
- 2.2 內存泄漏和內存溢出
- 2.2.3 深入理解JVM-hotspot虛擬機對象探秘
- 1.10 并發的可達性分析相關問題
- 二.Java集合架構
- 1.ArrayList深入源碼分析
- 2.Vector深入源碼分析
- 3.LinkedList深入源碼分析
- 4.HashMap深入源碼分析
- 5.ConcurrentHashMap深入源碼分析
- 6.HashSet,LinkedHashSet 和 LinkedHashMap
- 7.容器中的設計模式
- 8.集合架構之面試指南
- 9.TreeSet和TreeMap
- 三.Java基礎
- 1.基礎概念
- 1.1 Java程序初始化的順序是怎么樣的
- 1.2 Java和C++的區別
- 1.3 反射
- 1.4 注解
- 1.5 泛型
- 1.6 字節與字符的區別以及訪問修飾符
- 1.7 深拷貝與淺拷貝
- 1.8 字符串常量池
- 2.面向對象
- 3.關鍵字
- 4.基本數據類型與運算
- 5.字符串與數組
- 6.異常處理
- 7.Object 通用方法
- 8.Java8
- 8.1 Java 8 Tutorial
- 8.2 Java 8 數據流(Stream)
- 8.3 Java 8 并發教程:線程和執行器
- 8.4 Java 8 并發教程:同步和鎖
- 8.5 Java 8 并發教程:原子變量和 ConcurrentMap
- 8.6 Java 8 API 示例:字符串、數值、算術和文件
- 8.7 在 Java 8 中避免 Null 檢查
- 8.8 使用 Intellij IDEA 解決 Java 8 的數據流問題
- 四.Java 并發編程
- 1.線程的實現/創建
- 2.線程生命周期/狀態轉換
- 3.線程池
- 4.線程中的協作、中斷
- 5.Java鎖
- 5.1 樂觀鎖、悲觀鎖和自旋鎖
- 5.2 Synchronized
- 5.3 ReentrantLock
- 5.4 公平鎖和非公平鎖
- 5.3.1 說說ReentrantLock的實現原理,以及ReentrantLock的核心源碼是如何實現的?
- 5.5 鎖優化和升級
- 6.多線程的上下文切換
- 7.死鎖的產生和解決
- 8.J.U.C(java.util.concurrent)
- 0.簡化版(快速復習用)
- 9.鎖優化
- 10.Java 內存模型(JMM)
- 11.ThreadLocal詳解
- 12 CAS
- 13.AQS
- 0.ArrayBlockingQueue和LinkedBlockingQueue的實現原理
- 1.DelayQueue的實現原理
- 14.Thread.join()實現原理
- 15.PriorityQueue 的特性和原理
- 16.CyclicBarrier的實際使用場景
- 五.Java I/O NIO
- 1.I/O模型簡述
- 2.Java NIO之緩沖區
- 3.JAVA NIO之文件通道
- 4.Java NIO之套接字通道
- 5.Java NIO之選擇器
- 6.基于 Java NIO 實現簡單的 HTTP 服務器
- 7.BIO-NIO-AIO
- 8.netty(一)
- 9.NIO面試題
- 六.Java設計模式
- 1.單例模式
- 2.策略模式
- 3.模板方法
- 4.適配器模式
- 5.簡單工廠
- 6.門面模式
- 7.代理模式
- 七.數據結構和算法
- 1.什么是紅黑樹
- 2.二叉樹
- 2.1 二叉樹的前序、中序、后序遍歷
- 3.排序算法匯總
- 4.java實現鏈表及鏈表的重用操作
- 4.1算法題-鏈表反轉
- 5.圖的概述
- 6.常見的幾道字符串算法題
- 7.幾道常見的鏈表算法題
- 8.leetcode常見算法題1
- 9.LRU緩存策略
- 10.二進制及位運算
- 10.1.二進制和十進制轉換
- 10.2.位運算
- 11.常見鏈表算法題
- 12.算法好文推薦
- 13.跳表
- 八.Spring 全家桶
- 1.Spring IOC
- 2.Spring AOP
- 3.Spring 事務管理
- 4.SpringMVC 運行流程和手動實現
- 0.Spring 核心技術
- 5.spring如何解決循環依賴問題
- 6.springboot自動裝配原理
- 7.Spring中的循環依賴解決機制中,為什么要三級緩存,用二級緩存不夠嗎
- 8.beanFactory和factoryBean有什么區別
- 九.數據庫
- 1.mybatis
- 1.1 MyBatis-# 與 $ 區別以及 sql 預編譯
- Mybatis系列1-Configuration
- Mybatis系列2-SQL執行過程
- Mybatis系列3-之SqlSession
- Mybatis系列4-之Executor
- Mybatis系列5-StatementHandler
- Mybatis系列6-MappedStatement
- Mybatis系列7-參數設置揭秘(ParameterHandler)
- Mybatis系列8-緩存機制
- 2.淺談聚簇索引和非聚簇索引的區別
- 3.mysql 證明為什么用limit時,offset很大會影響性能
- 4.MySQL中的索引
- 5.數據庫索引2
- 6.面試題收集
- 7.MySQL行鎖、表鎖、間隙鎖詳解
- 8.數據庫MVCC詳解
- 9.一條SQL查詢語句是如何執行的
- 10.MySQL 的 crash-safe 原理解析
- 11.MySQL 性能優化神器 Explain 使用分析
- 12.mysql中,一條update語句執行的過程是怎么樣的?期間用到了mysql的哪些log,分別有什么作用
- 十.Redis
- 0.快速復習回顧Redis
- 1.通俗易懂的Redis數據結構基礎教程
- 2.分布式鎖(一)
- 3.分布式鎖(二)
- 4.延時隊列
- 5.位圖Bitmaps
- 6.Bitmaps(位圖)的使用
- 7.Scan
- 8.redis緩存雪崩、緩存擊穿、緩存穿透
- 9.Redis為什么是單線程、及高并發快的3大原因詳解
- 10.布隆過濾器你值得擁有的開發利器
- 11.Redis哨兵、復制、集群的設計原理與區別
- 12.redis的IO多路復用
- 13.相關redis面試題
- 14.redis集群
- 十一.中間件
- 1.RabbitMQ
- 1.1 RabbitMQ實戰,hello world
- 1.2 RabbitMQ 實戰,工作隊列
- 1.3 RabbitMQ 實戰, 發布訂閱
- 1.4 RabbitMQ 實戰,路由
- 1.5 RabbitMQ 實戰,主題
- 1.6 Spring AMQP 的 AMQP 抽象
- 1.7 Spring AMQP 實戰 – 整合 RabbitMQ 發送郵件
- 1.8 RabbitMQ 的消息持久化與 Spring AMQP 的實現剖析
- 1.9 RabbitMQ必備核心知識
- 2.RocketMQ 的幾個簡單問題與答案
- 2.Kafka
- 2.1 kafka 基礎概念和術語
- 2.2 Kafka的重平衡(Rebalance)
- 2.3.kafka日志機制
- 2.4 kafka是pull還是push的方式傳遞消息的?
- 2.5 Kafka的數據處理流程
- 2.6 Kafka的腦裂預防和處理機制
- 2.7 Kafka中partition副本的Leader選舉機制
- 2.8 如果Leader掛了的時候,follower沒來得及同步,是否會出現數據不一致
- 2.9 kafka的partition副本是否會出現腦裂情況
- 十二.Zookeeper
- 0.什么是Zookeeper(漫畫)
- 1.使用docker安裝Zookeeper偽集群
- 3.ZooKeeper-Plus
- 4.zk實現分布式鎖
- 5.ZooKeeper之Watcher機制
- 6.Zookeeper之選舉及數據一致性
- 十三.計算機網絡
- 1.進制轉換:二進制、八進制、十六進制、十進制之間的轉換
- 2.位運算
- 3.計算機網絡面試題匯總1
- 十四.Docker
- 100.面試題收集合集
- 1.美團面試常見問題總結
- 2.b站部分面試題
- 3.比心面試題
- 4.騰訊面試題
- 5.哈羅部分面試
- 6.筆記
- 十五.Storm
- 1.Storm和流處理簡介
- 2.Storm 核心概念詳解
- 3.Storm 單機版本環境搭建
- 4.Storm 集群環境搭建
- 5.Storm 編程模型詳解
- 6.Storm 項目三種打包方式對比分析
- 7.Storm 集成 Redis 詳解
- 8.Storm 集成 HDFS 和 HBase
- 9.Storm 集成 Kafka
- 十六.Elasticsearch
- 1.初識ElasticSearch
- 2.文檔基本CRUD、集群健康檢查
- 3.shard&replica
- 4.document核心元數據解析及ES的并發控制
- 5.document的批量操作及數據路由原理
- 6.倒排索引
- 十七.分布式相關
- 1.分布式事務解決方案一網打盡
- 2.關于xxx怎么保證高可用的問題
- 3.一致性hash原理與實現
- 4.微服務注冊中心 Nacos 比 Eureka的優勢
- 5.Raft 協議算法
- 6.為什么微服務架構中需要網關
- 0.CAP與BASE理論
- 十八.Dubbo
- 1.快速掌握Dubbo常規應用
- 2.Dubbo應用進階
- 3.Dubbo調用模塊詳解
- 4.Dubbo調用模塊源碼分析
- 6.Dubbo協議模塊