
[TOC]
## Kafka面試題總結
### Kafka 是什么?主要應用場景有哪些?
Kafka 是一個分布式流式處理平臺。這到底是什么意思呢?
流平臺具有三個關鍵功能:
1. **消息隊列**:發布和訂閱消息流,這個功能類似于消息隊列,這也是 Kafka 也被歸類為消息隊列的原因。
2. **容錯的持久方式存儲記錄消息流**: Kafka 會把消息持久化到磁盤,有效避免了消息丟失的風險·。
3. **流式處理平臺:** 在消息發布的時候進行處理,Kafka 提供了一個完整的流式處理類庫。
Kafka 主要有兩大應用場景:
1. **消息隊列** :建立實時流數據管道,以可靠地在系統或應用程序之間獲取數據。
2. **數據處理:** 構建實時的流數據處理程序來轉換或處理數據流。
### 和其他消息隊列相比,Kafka的優勢在哪里?
我們現在經常提到 Kafka 的時候就已經默認它是一個非常優秀的消息隊列了,我們也會經常拿它給 RocketMQ、RabbitMQ 對比。我覺得 Kafka 相比其他消息隊列主要的優勢如下:
1. **極致的性能** :基于 Scala 和 Java 語言開發,設計中大量使用了批量處理和異步的思想,最高可以每秒處理千萬級別的消息。
2. **生態系統兼容性無可匹敵** :Kafka 與周邊生態系統的兼容性是最好的沒有之一,尤其在大數據和流計算領域。
實際上在早期的時候 Kafka 并不是一個合格的消息隊列,早期的 Kafka 在消息隊列領域就像是一個衣衫襤褸的孩子一樣,功能不完備并且有一些小問題比如丟失消息、不保證消息可靠性等等。當然,這也和 LinkedIn 最早開發 Kafka 用于處理海量的日志有很大關系,哈哈哈,人家本來最開始就不是為了作為消息隊列滴,誰知道后面誤打誤撞在消息隊列領域占據了一席之地。
隨著后續的發展,這些短板都被 Kafka 逐步修復完善。所以,**Kafka 作為消息隊列不可靠這個說法已經過時!**
### 隊列模型了解嗎?Kafka 的消息模型知道嗎?
*****
題外話:早期的 JMS 和 AMQP 屬于消息服務領域權威組織所做的相關的標準,我在 [JavaGuide](https://github.com/Snailclimb/JavaGuide)的 [《消息隊列其實很簡單》](https://github.com/Snailclimb/JavaGuide#%E6%95%B0%E6%8D%AE%E9%80%9A%E4%BF%A1%E4%B8%AD%E9%97%B4%E4%BB%B6)這篇文章中介紹過。但是,這些標準的進化跟不上消息隊列的演進速度,這些標準實際上已經屬于廢棄狀態。所以,可能存在的情況是:不同的消息隊列都有自己的一套消息模型。
*****
### 隊列模型:早期的消息模型

**使用隊列(Queue)作為消息通信載體,滿足生產者與消費者模式,一條消息只能被一個消費者使用,未被消費的消息在隊列中保留直到被消費或超時。** 比如:我們生產者發送 100 條消息的話,兩個消費者來消費一般情況下兩個消費者會按照消息發送的順序各自消費一半(也就是你一個我一個的消費。)
**隊列模型存在的問題:**
假如我們存在這樣一種情況:我們需要將生產者產生的消息分發給多個消費者,并且每個消費者都能接收到完成的消息內容。
這種情況,隊列模型就不好解決了。很多比較杠精的人就說:我們可以為每個消費者創建一個單獨的隊列,讓生產者發送多份。這是一種非常愚蠢的做法,浪費資源不說,還違背了使用消息隊列的目的。
### 發布-訂閱模型:Kafka 消息模型
發布-訂閱模型主要是為了解決隊列模型存在的問題。

發布訂閱模型(Pub-Sub) 使用**主題(Topic)** 作為消息通信載體,類似于**廣播模式**;發布者發布一條消息,該消息通過主題傳遞給所有的訂閱者,**在一條消息廣播之后才訂閱的用戶則是收不到該條消息的**。
**在發布 - 訂閱模型中,如果只有一個訂閱者,那它和隊列模型就基本是一樣的了。所以說,發布 - 訂閱模型在功能層面上是可以兼容隊列模型的。**
**Kafka 采用的就是發布 - 訂閱模型。**
**RocketMQ 的消息模型和 Kafka 基本是完全一樣的。唯一的區別是 Kafka 中沒有隊列這個概念,與之對應的是 Partition(分區)。**
### 什么是Producer、Consumer、Broker、Topic、Partition?
Kafka 將生產者發布的消息發送到 **Topic(主題)** 中,需要這些消息的消費者可以訂閱這些 **Topic(主題)**,如下圖所示:
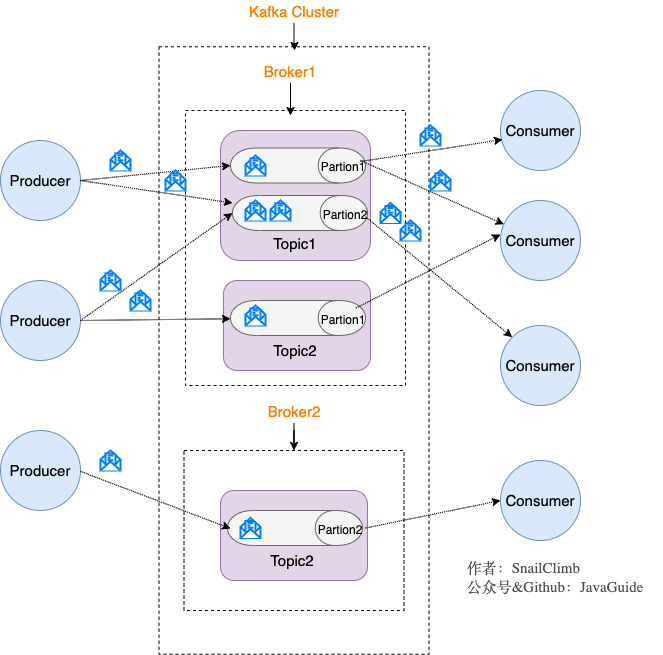
上面這張圖也為我們引出了,Kafka 比較重要的幾個概念:
1. **Producer(生產者)** : 產生消息的一方。
2. **Consumer(消費者)** : 消費消息的一方。
3. **Broker(代理)** : 可以看作是一個獨立的 Kafka 實例。多個 Kafka Broker 組成一個 Kafka Cluster。
同時,你一定也注意到每個 Broker 中又包含了 Topic 以及 Partition 這兩個重要的概念:
- **Topic(主題)** : Producer 將消息發送到特定的主題,Consumer 通過訂閱特定的 Topic(主題) 來消費消息。
- **Partition(分區)** : Partition 屬于 Topic 的一部分。一個 Topic 可以有多個 Partition ,并且同一 Topic 下的 Partition 可以分布在不同的 Broker 上,這也就表明一個 Topic 可以橫跨多個 Broker 。這正如我上面所畫的圖一樣。
劃重點:**Kafka 中的 Partition(分區) 實際上可以對應成為消息隊列中的隊列。這樣是不是更好理解一點?**
### Kafka 的多副本機制了解嗎?帶來了什么好處?
還有一點我覺得比較重要的是 Kafka 為分區(Partition)引入了多副本(Replica)機制。分區(Partition)中的多個副本之間會有一個叫做 leader 的家伙,其他副本稱為 follower。我們發送的消息會被發送到 leader 副本,然后 follower 副本才能從 leader 副本中拉取消息進行同步。
生產者和消費者只與 leader 副本交互。你可以理解為其他副本只是 leader 副本的拷貝,它們的存在只是為了保證消息存儲的安全性。當 leader 副本發生故障時會從 follower 中選舉出一個 leader,但是 follower 中如果有和 leader 同步程度達不到要求的參加不了 leader 的競選。
**Kafka 的多分區(Partition)以及多副本(Replica)機制有什么好處呢?**
1. Kafka 通過給特定 Topic 指定多個 Partition, 而各個 Partition 可以分布在不同的 Broker 上, 這樣便能提供比較好的并發能力(負載均衡)。
2. Partition 可以指定對應的 Replica 數, 這也極大地提高了消息存儲的安全性, 提高了容災能力,不過也相應的增加了所需要的存儲空間。
### Zookeeper 在 Kafka 中的作用知道嗎?
*****
要想搞懂 zookeeper 在 Kafka 中的作用 一定要自己搭建一個 Kafka 環境然后自己進 zookeeper 去看一下有哪些文件夾和 Kafka 有關,每個節點又保存了什么信息。** 一定不要光看不實踐,這樣學來的也終會忘記!這部分內容參考和借鑒了這篇文章:https://www.jianshu.com/p/a036405f989c 。
下圖就是我的本地 Zookeeper ,它成功和我本地的 Kafka 關聯上(以下文件夾結構借助 idea 插件 Zookeeper tool 實現)。
*****
ZooKeeper 主要為 Kafka 提供元數據的管理的功能。
從圖中我們可以看出,Zookeeper 主要為 Kafka 做了下面這些事情:
1. **Broker 注冊** :在 Zookeeper 上會有一個專門**用來進行 Broker 服務器列表記錄**的節點。每個 Broker 在啟動時,都會到 Zookeeper 上進行注冊,即到/brokers/ids 下創建屬于自己的節點。每個 Broker 就會將自己的 IP 地址和端口等信息記錄到該節點中去
2. **Topic 注冊** : 在 Kafka 中,同一個**Topic 的消息會被分成多個分區**并將其分布在多個 Broker 上,**這些分區信息及與 Broker 的對應關系**也都是由 Zookeeper 在維護。比如我創建了一個名字為 my-topic 的主題并且它有兩個分區,對應到 zookeeper 中會創建這些文件夾:`/brokers/topics/my-topic/Partitions/0`、`/brokers/topics/my-topic/Partitions/1`
3. **負載均衡** :上面也說過了 Kafka 通過給特定 Topic 指定多個 Partition, 而各個 Partition 可以分布在不同的 Broker 上, 這樣便能提供比較好的并發能力。 對于同一個 Topic 的不同 Partition,Kafka 會盡力將這些 Partition 分布到不同的 Broker 服務器上。當生產者產生消息后也會盡量投遞到不同 Broker 的 Partition 里面。當 Consumer 消費的時候,Zookeeper 可以根據當前的 Partition 數量以及 Consumer 數量來實現動態負載均衡。
4. ......
### Kafka 如何保證消息的消費順序?
我們在使用消息隊列的過程中經常有業務場景需要嚴格保證消息的消費順序,比如我們同時發了 2 個消息,這 2 個消息對應的操作分別對應的數據庫操作是:更改用戶會員等級、根據會員等級計算訂單價格。假如這兩條消息的消費順序不一樣造成的最終結果就會截然不同。
我們知道 Kafka 中 Partition(分區)是真正保存消息的地方,我們發送的消息都被放在了這里。而我們的 Partition(分區) 又存在于 Topic(主題) 這個概念中,并且我們可以給特定 Topic 指定多個 Partition。

每次添加消息到 Partition(分區) 的時候都會采用尾加法,如上圖所示。Kafka 只能為我們保證 Partition(分區) 中的消息有序,而不能保證 Topic(主題) 中的 Partition(分區) 的有序。
> 消息在被追加到 Partition(分區)的時候都會分配一個特定的偏移量(offset)。Kafka 通過偏移量(offset)來保證消息在分區內的順序性。
所以,我們就有一種很簡單的保證消息消費順序的方法:**1 個 Topic 只對應一個 Partition**。這樣當然可以解決問題,但是破壞了 Kafka 的設計初衷。
Kafka 中發送 1 條消息的時候,可以指定 topic, partition, key,data(數據) 4 個參數。如果你發送消息的時候指定了 Partition 的話,所有消息都會被發送到指定的 Partition。并且,同一個 key 的消息可以保證只發送到同一個 partition,這個我們可以采用表/對象的 id 來作為 key 。
總結一下,對于如何保證 Kafka 中消息消費的順序,有了下面兩種方法:
1. 1 個 Topic 只對應一個 Partition。
2. (推薦)發送消息的時候指定 key/Partition。
當然不僅僅只有上面兩種方法,上面兩種方法是我覺得比較好理解的,
### Kafka 如何保證消息不丟失
### 生產者丟失消息的情況
生產者(Producer) 調用`send`方法發送消息之后,消息可能因為網絡問題并沒有發送過去。
所以,我們不能默認在調用`send`方法發送消息之后消息消息發送成功了。為了確定消息是發送成功,我們要判斷消息發送的結果。但是要注意的是 Kafka 生產者(Producer) 使用 `send` 方法發送消息實際上是異步的操作,我們可以通過 `get()`方法獲取調用結果,但是這樣也讓它變為了同步操作,示例代碼如下:
**詳細代碼見我的這篇文章:[Kafka系列第三篇!10 分鐘學會如何在 Spring Boot 程序中使用 Kafka 作為消息隊列?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486269&idx=2&sn=ec00417ad641dd8c3d145d74cafa09ce&chksm=cea244f6f9d5cde0c8eb233fcc4cf82e11acd06446719a7af55230649863a3ddd95f78d111de&token=1633957262&lang=zh_CN#rd)**
```java
SendResult<String, Object> sendResult = kafkaTemplate.send(topic, o).get();
if (sendResult.getRecordMetadata() != null) {
logger.info("生產者成功發送消息到" + sendResult.getProducerRecord().topic() + "-> " + sendRe
sult.getProducerRecord().value().toString());
}
```
但是一般不推薦這么做!可以采用為其添加回調函數的形式,示例代碼如下:
````java
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, o);
future.addCallback(result -> logger.info("生產者成功發送消息到topic:{} partition:{}的消息", result.getRecordMetadata().topic(), result.getRecordMetadata().partition()),
ex -> logger.error("生產者發送消失敗,原因:{}", ex.getMessage()));
````
如果消息發送失敗的話,我們檢查失敗的原因之后重新發送即可!
**另外這里推薦為 Producer 的`retries `(重試次數)設置一個比較合理的值,一般是 3 ,但是為了保證消息不丟失的話一般會設置比較大一點。設置完成之后,當出現網絡問題之后能夠自動重試消息發送,避免消息丟失。另外,建議還要設置重試間隔,因為間隔太小的話重試的效果就不明顯了,網絡波動一次你3次一下子就重試完了**
### 消費者丟失消息的情況
我們知道消息在被追加到 Partition(分區)的時候都會分配一個特定的偏移量(offset)。偏移量(offset)表示 Consumer 當前消費到的 Partition(分區)的所在的位置。Kafka 通過偏移量(offset)可以保證消息在分區內的順序性。
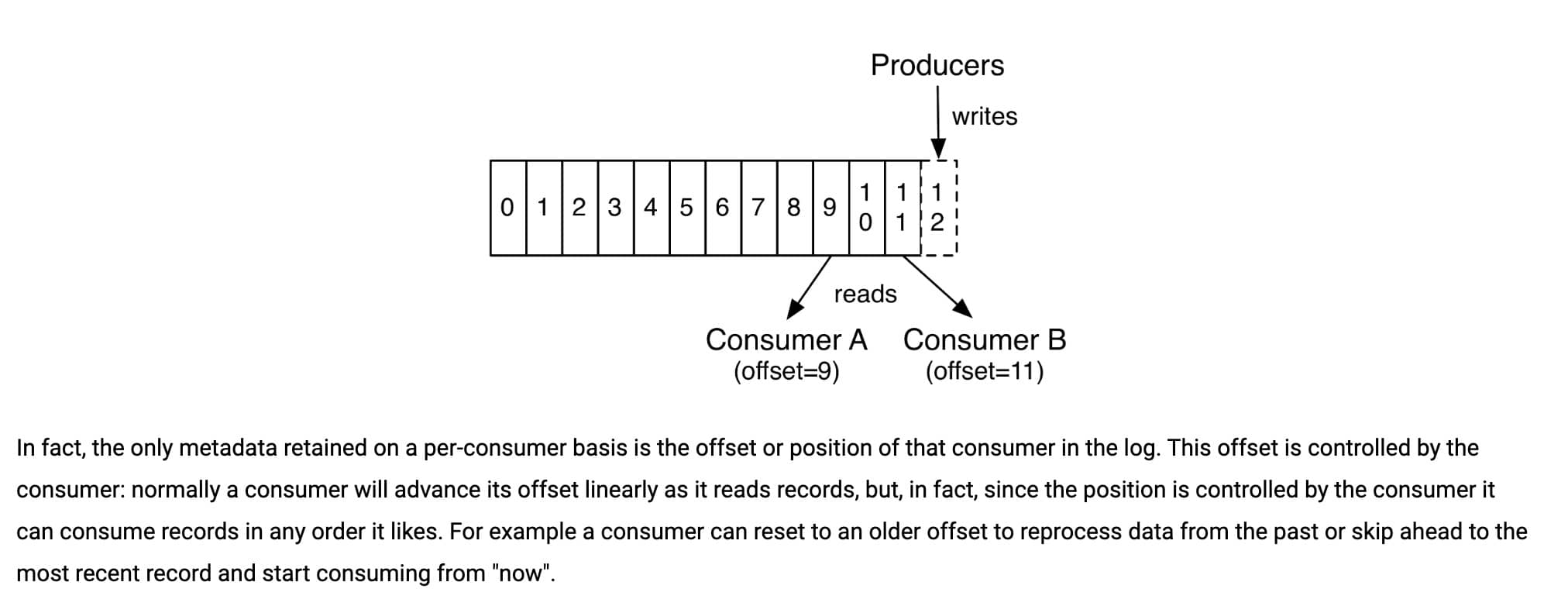
當消費者拉取到了分區的某個消息之后,消費者會自動提交了 offset。自動提交的話會有一個問題,試想一下,當消費者剛拿到這個消息準備進行真正消費的時候,突然掛掉了,消息實際上并沒有被消費,但是 offset 卻被自動提交了。
**解決辦法也比較粗暴,我們手動關閉閉自動提交 offset,每次在真正消費完消息之后之后再自己手動提交 offset 。** 但是,細心的朋友一定會發現,這樣會帶來消息被重新消費的問題。比如你剛剛消費完消息之后,還沒提交 offset,結果自己掛掉了,那么這個消息理論上就會被消費兩次。
### Kafka 弄丟了消息
我們知道 Kafka 為分區(Partition)引入了多副本(Replica)機制。分區(Partition)中的多個副本之間會有一個叫做 leader 的家伙,其他副本稱為 follower。我們發送的消息會被發送到 leader 副本,然后 follower 副本才能從 leader 副本中拉取消息進行同步。生產者和消費者只與 leader 副本交互。你可以理解為其他副本只是 leader 副本的拷貝,它們的存在只是為了保證消息存儲的安全性。
**試想一種情況:假如 leader 副本所在的 broker 突然掛掉,那么就要從 follower 副本重新選出一個 leader ,但是 leader 的數據還有一些沒有被 follower 副本的同步的話,就會造成消息丟失。**
**設置 acks = all**
解決辦法就是我們設置 **acks = all**。acks 是 Kafka 生產者(Producer) 很重要的一個參數。
acks 的默認值即為1,代表我們的消息被leader副本接收之后就算被成功發送。當我們配置 **acks = all** 代表則所有副本都要接收到該消息之后該消息才算真正成功被發送。
**設置 replication.factor >= 3**
為了保證 leader 副本能有 follower 副本能同步消息,我們一般會為 topic 設置 **replication.factor >= 3**。這樣就可以保證每個 分區(partition) 至少有 3 個副本。雖然造成了數據冗余,但是帶來了數據的安全性。
**設置 min.insync.replicas > 1**
一般情況下我們還需要設置 **min.insync.replicas> 1** ,這樣配置代表消息至少要被寫入到 2 個副本才算是被成功發送。**min.insync.replicas** 的默認值為 1 ,在實際生產中應盡量避免默認值 1。
但是,為了保證整個 Kafka 服務的高可用性,你需要確保 **replication.factor > min.insync.replicas** 。為什么呢?設想一下假如兩者相等的話,只要是有一個副本掛掉,整個分區就無法正常工作了。這明顯違反高可用性!一般推薦設置成 **replication.factor = min.insync.replicas + 1**。
**設置 unclean.leader.election.enable = false**
**Kafka 0.11.0.0版本開始 unclean.leader.election.enable 參數的默認值由原來的true 改為false**
我們最開始也說了我們發送的消息會被發送到 leader 副本,然后 follower 副本才能從 leader 副本中拉取消息進行同步。多個 follower 副本之間的消息同步情況不一樣,當我們配置了 **unclean.leader.election.enable = false** 的話,當 leader 副本發生故障時就不會從 follower 副本中和 leader 同步程度達不到要求的副本中選擇出 leader ,這樣降低了消息丟失的可能性。
### Reference
- 本文轉載至[ javaguide-Kafka常見面試題總結]([https://github.com/Snailclimb/JavaGuide/edit/master/docs/system-design/distributed-system/message-queue/Kafka%E5%B8%B8%E8%A7%81%E9%9D%A2%E8%AF%95%E9%A2%98%E6%80%BB%E7%BB%93.md](https://github.com/Snailclimb/JavaGuide/edit/master/docs/system-design/distributed-system/message-queue/Kafka%E5%B8%B8%E8%A7%81%E9%9D%A2%E8%AF%95%E9%A2%98%E6%80%BB%E7%BB%93.md))
- Kafka 官方文檔: https://kafka.apache.org/documentation/
- 極客時間—《Kafka核心技術與實戰》第11節:無消息丟失配置怎么實現?
- 一.JVM
- 1.1 java代碼是怎么運行的
- 1.2 JVM的內存區域
- 1.3 JVM運行時內存
- 1.4 JVM內存分配策略
- 1.5 JVM類加載機制與對象的生命周期
- 1.6 常用的垃圾回收算法
- 1.7 JVM垃圾收集器
- 1.8 CMS垃圾收集器
- 1.9 G1垃圾收集器
- 2.面試相關文章
- 2.1 可能是把Java內存區域講得最清楚的一篇文章
- 2.0 GC調優參數
- 2.1GC排查系列
- 2.2 內存泄漏和內存溢出
- 2.2.3 深入理解JVM-hotspot虛擬機對象探秘
- 1.10 并發的可達性分析相關問題
- 二.Java集合架構
- 1.ArrayList深入源碼分析
- 2.Vector深入源碼分析
- 3.LinkedList深入源碼分析
- 4.HashMap深入源碼分析
- 5.ConcurrentHashMap深入源碼分析
- 6.HashSet,LinkedHashSet 和 LinkedHashMap
- 7.容器中的設計模式
- 8.集合架構之面試指南
- 9.TreeSet和TreeMap
- 三.Java基礎
- 1.基礎概念
- 1.1 Java程序初始化的順序是怎么樣的
- 1.2 Java和C++的區別
- 1.3 反射
- 1.4 注解
- 1.5 泛型
- 1.6 字節與字符的區別以及訪問修飾符
- 1.7 深拷貝與淺拷貝
- 1.8 字符串常量池
- 2.面向對象
- 3.關鍵字
- 4.基本數據類型與運算
- 5.字符串與數組
- 6.異常處理
- 7.Object 通用方法
- 8.Java8
- 8.1 Java 8 Tutorial
- 8.2 Java 8 數據流(Stream)
- 8.3 Java 8 并發教程:線程和執行器
- 8.4 Java 8 并發教程:同步和鎖
- 8.5 Java 8 并發教程:原子變量和 ConcurrentMap
- 8.6 Java 8 API 示例:字符串、數值、算術和文件
- 8.7 在 Java 8 中避免 Null 檢查
- 8.8 使用 Intellij IDEA 解決 Java 8 的數據流問題
- 四.Java 并發編程
- 1.線程的實現/創建
- 2.線程生命周期/狀態轉換
- 3.線程池
- 4.線程中的協作、中斷
- 5.Java鎖
- 5.1 樂觀鎖、悲觀鎖和自旋鎖
- 5.2 Synchronized
- 5.3 ReentrantLock
- 5.4 公平鎖和非公平鎖
- 5.3.1 說說ReentrantLock的實現原理,以及ReentrantLock的核心源碼是如何實現的?
- 5.5 鎖優化和升級
- 6.多線程的上下文切換
- 7.死鎖的產生和解決
- 8.J.U.C(java.util.concurrent)
- 0.簡化版(快速復習用)
- 9.鎖優化
- 10.Java 內存模型(JMM)
- 11.ThreadLocal詳解
- 12 CAS
- 13.AQS
- 0.ArrayBlockingQueue和LinkedBlockingQueue的實現原理
- 1.DelayQueue的實現原理
- 14.Thread.join()實現原理
- 15.PriorityQueue 的特性和原理
- 16.CyclicBarrier的實際使用場景
- 五.Java I/O NIO
- 1.I/O模型簡述
- 2.Java NIO之緩沖區
- 3.JAVA NIO之文件通道
- 4.Java NIO之套接字通道
- 5.Java NIO之選擇器
- 6.基于 Java NIO 實現簡單的 HTTP 服務器
- 7.BIO-NIO-AIO
- 8.netty(一)
- 9.NIO面試題
- 六.Java設計模式
- 1.單例模式
- 2.策略模式
- 3.模板方法
- 4.適配器模式
- 5.簡單工廠
- 6.門面模式
- 7.代理模式
- 七.數據結構和算法
- 1.什么是紅黑樹
- 2.二叉樹
- 2.1 二叉樹的前序、中序、后序遍歷
- 3.排序算法匯總
- 4.java實現鏈表及鏈表的重用操作
- 4.1算法題-鏈表反轉
- 5.圖的概述
- 6.常見的幾道字符串算法題
- 7.幾道常見的鏈表算法題
- 8.leetcode常見算法題1
- 9.LRU緩存策略
- 10.二進制及位運算
- 10.1.二進制和十進制轉換
- 10.2.位運算
- 11.常見鏈表算法題
- 12.算法好文推薦
- 13.跳表
- 八.Spring 全家桶
- 1.Spring IOC
- 2.Spring AOP
- 3.Spring 事務管理
- 4.SpringMVC 運行流程和手動實現
- 0.Spring 核心技術
- 5.spring如何解決循環依賴問題
- 6.springboot自動裝配原理
- 7.Spring中的循環依賴解決機制中,為什么要三級緩存,用二級緩存不夠嗎
- 8.beanFactory和factoryBean有什么區別
- 九.數據庫
- 1.mybatis
- 1.1 MyBatis-# 與 $ 區別以及 sql 預編譯
- Mybatis系列1-Configuration
- Mybatis系列2-SQL執行過程
- Mybatis系列3-之SqlSession
- Mybatis系列4-之Executor
- Mybatis系列5-StatementHandler
- Mybatis系列6-MappedStatement
- Mybatis系列7-參數設置揭秘(ParameterHandler)
- Mybatis系列8-緩存機制
- 2.淺談聚簇索引和非聚簇索引的區別
- 3.mysql 證明為什么用limit時,offset很大會影響性能
- 4.MySQL中的索引
- 5.數據庫索引2
- 6.面試題收集
- 7.MySQL行鎖、表鎖、間隙鎖詳解
- 8.數據庫MVCC詳解
- 9.一條SQL查詢語句是如何執行的
- 10.MySQL 的 crash-safe 原理解析
- 11.MySQL 性能優化神器 Explain 使用分析
- 12.mysql中,一條update語句執行的過程是怎么樣的?期間用到了mysql的哪些log,分別有什么作用
- 十.Redis
- 0.快速復習回顧Redis
- 1.通俗易懂的Redis數據結構基礎教程
- 2.分布式鎖(一)
- 3.分布式鎖(二)
- 4.延時隊列
- 5.位圖Bitmaps
- 6.Bitmaps(位圖)的使用
- 7.Scan
- 8.redis緩存雪崩、緩存擊穿、緩存穿透
- 9.Redis為什么是單線程、及高并發快的3大原因詳解
- 10.布隆過濾器你值得擁有的開發利器
- 11.Redis哨兵、復制、集群的設計原理與區別
- 12.redis的IO多路復用
- 13.相關redis面試題
- 14.redis集群
- 十一.中間件
- 1.RabbitMQ
- 1.1 RabbitMQ實戰,hello world
- 1.2 RabbitMQ 實戰,工作隊列
- 1.3 RabbitMQ 實戰, 發布訂閱
- 1.4 RabbitMQ 實戰,路由
- 1.5 RabbitMQ 實戰,主題
- 1.6 Spring AMQP 的 AMQP 抽象
- 1.7 Spring AMQP 實戰 – 整合 RabbitMQ 發送郵件
- 1.8 RabbitMQ 的消息持久化與 Spring AMQP 的實現剖析
- 1.9 RabbitMQ必備核心知識
- 2.RocketMQ 的幾個簡單問題與答案
- 2.Kafka
- 2.1 kafka 基礎概念和術語
- 2.2 Kafka的重平衡(Rebalance)
- 2.3.kafka日志機制
- 2.4 kafka是pull還是push的方式傳遞消息的?
- 2.5 Kafka的數據處理流程
- 2.6 Kafka的腦裂預防和處理機制
- 2.7 Kafka中partition副本的Leader選舉機制
- 2.8 如果Leader掛了的時候,follower沒來得及同步,是否會出現數據不一致
- 2.9 kafka的partition副本是否會出現腦裂情況
- 十二.Zookeeper
- 0.什么是Zookeeper(漫畫)
- 1.使用docker安裝Zookeeper偽集群
- 3.ZooKeeper-Plus
- 4.zk實現分布式鎖
- 5.ZooKeeper之Watcher機制
- 6.Zookeeper之選舉及數據一致性
- 十三.計算機網絡
- 1.進制轉換:二進制、八進制、十六進制、十進制之間的轉換
- 2.位運算
- 3.計算機網絡面試題匯總1
- 十四.Docker
- 100.面試題收集合集
- 1.美團面試常見問題總結
- 2.b站部分面試題
- 3.比心面試題
- 4.騰訊面試題
- 5.哈羅部分面試
- 6.筆記
- 十五.Storm
- 1.Storm和流處理簡介
- 2.Storm 核心概念詳解
- 3.Storm 單機版本環境搭建
- 4.Storm 集群環境搭建
- 5.Storm 編程模型詳解
- 6.Storm 項目三種打包方式對比分析
- 7.Storm 集成 Redis 詳解
- 8.Storm 集成 HDFS 和 HBase
- 9.Storm 集成 Kafka
- 十六.Elasticsearch
- 1.初識ElasticSearch
- 2.文檔基本CRUD、集群健康檢查
- 3.shard&replica
- 4.document核心元數據解析及ES的并發控制
- 5.document的批量操作及數據路由原理
- 6.倒排索引
- 十七.分布式相關
- 1.分布式事務解決方案一網打盡
- 2.關于xxx怎么保證高可用的問題
- 3.一致性hash原理與實現
- 4.微服務注冊中心 Nacos 比 Eureka的優勢
- 5.Raft 協議算法
- 6.為什么微服務架構中需要網關
- 0.CAP與BASE理論
- 十八.Dubbo
- 1.快速掌握Dubbo常規應用
- 2.Dubbo應用進階
- 3.Dubbo調用模塊詳解
- 4.Dubbo調用模塊源碼分析
- 6.Dubbo協議模塊