
[TOC]
## 一、簡介
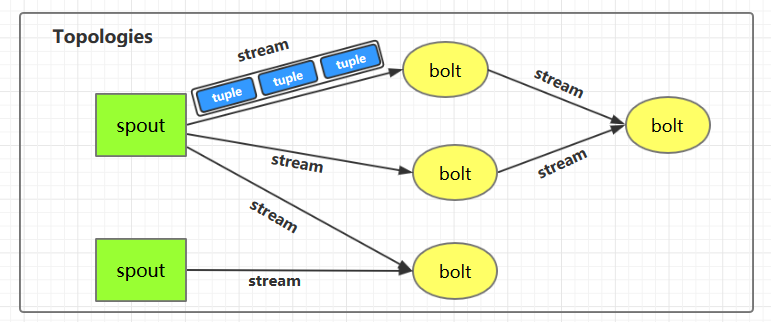
下圖為 Strom 的運行流程圖,在開發 Storm 流處理程序時,我們需要采用內置或自定義實現 `spout`(數據源) 和 `bolt`(處理單元),并通過 `TopologyBuilder` 將它們之間進行關聯,形成 `Topology`。
## 二、IComponent接口
`IComponent` 接口定義了 Topology 中所有組件 (spout/bolt) 的公共方法,自定義的 spout 或 bolt 必須直接或間接實現這個接口。
~~~
public interface IComponent extends Serializable {
/**
* 聲明此拓撲的所有流的輸出模式。
* @param declarer 這用于聲明輸出流 id,輸出字段以及每個輸出流是否是直接流(direct stream)
*/
void declareOutputFields(OutputFieldsDeclarer declarer);
/**
* 聲明此組件的配置。
*
*/
Map<String, Object> getComponentConfiguration();
}
復制代碼
~~~
## 三、Spout
### 3.1 ISpout接口
自定義的 spout 需要實現 `ISpout` 接口,它定義了 spout 的所有可用方法:
~~~
public interface ISpout extends Serializable {
/**
* 組件初始化時候被調用
*
* @param conf ISpout 的配置
* @param context 應用上下文,可以通過其獲取任務 ID 和組件 ID,輸入和輸出信息等。
* @param collector 用來發送 spout 中的 tuples,它是線程安全的,建議保存為此 spout 對象的實例變量
*/
void open(Map conf, TopologyContext context, SpoutOutputCollector collector);
/**
* ISpout 將要被關閉的時候調用。但是其不一定會被執行,如果在集群環境中通過 kill -9 殺死進程時其就無法被執行。
*/
void close();
/**
* 當 ISpout 從停用狀態激活時被調用
*/
void activate();
/**
* 當 ISpout 停用時候被調用
*/
void deactivate();
/**
* 這是一個核心方法,主要通過在此方法中調用 collector 將 tuples 發送給下一個接收器,這個方法必須是非阻塞的。
* nextTuple/ack/fail/是在同一個線程中執行的,所以不用考慮線程安全方面。當沒有 tuples 發出時應該讓
* nextTuple 休眠 (sleep) 一下,以免浪費 CPU。
*/
void nextTuple();
/**
* 通過 msgId 進行 tuples 處理成功的確認,被確認后的 tuples 不會再次被發送
*/
void ack(Object msgId);
/**
* 通過 msgId 進行 tuples 處理失敗的確認,被確認后的 tuples 會再次被發送進行處理
*/
void fail(Object msgId);
}
復制代碼
~~~
### 3.2 BaseRichSpout抽象類
**通常情況下,我們實現自定義的 Spout 時不會直接去實現 `ISpout` 接口,而是繼承 `BaseRichSpout`。**`BaseRichSpout` 繼承自 `BaseCompont`,同時實現了 `IRichSpout` 接口。
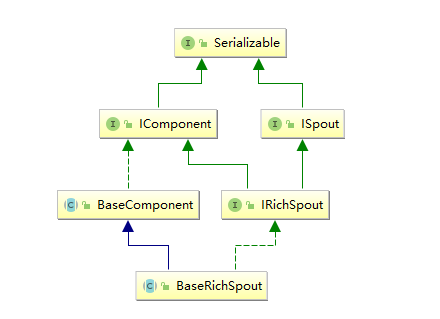
`IRichSpout` 接口繼承自 `ISpout` 和 `IComponent`,自身并沒有定義任何方法:
~~~
public interface IRichSpout extends ISpout, IComponent {
}
~~~
`BaseComponent` 抽象類空實現了 `IComponent` 中 `getComponentConfiguration` 方法:
~~~
public abstract class BaseComponent implements IComponent {
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}
~~~
`BaseRichSpout` 繼承自 `BaseCompont` 類并實現了 `IRichSpout` 接口,并且空實現了其中部分方法:
~~~
public abstract class BaseRichSpout extends BaseComponent implements IRichSpout {
@Override
public void close() {}
@Override
public void activate() {}
@Override
public void deactivate() {}
@Override
public void ack(Object msgId) {}
@Override
public void fail(Object msgId) {}
}
~~~
通過這樣的設計,我們在繼承 `BaseRichSpout` 實現自定義 spout 時,就只有三個方法必須實現:
* **open** : 來源于 ISpout,可以通過此方法獲取用來發送 tuples 的 `SpoutOutputCollector`;
* **nextTuple** :來源于 ISpout,必須在此方法內部發送 tuples;
* **declareOutputFields** :來源于 IComponent,聲明發送的 tuples 的名稱,這樣下一個組件才能知道如何接受。
## 四、Bolt
bolt 接口的設計與 spout 的類似:
### 4.1 IBolt 接口
~~~
/**
* 在客戶端計算機上創建的 IBolt 對象。會被被序列化到 topology 中(使用 Java 序列化),并提交給集群的主機(Nimbus)。
* Nimbus 啟動 workers 反序列化對象,調用 prepare,然后開始處理 tuples。
*/
public interface IBolt extends Serializable {
/**
* 組件初始化時候被調用
*
* @param conf storm 中定義的此 bolt 的配置
* @param context 應用上下文,可以通過其獲取任務 ID 和組件 ID,輸入和輸出信息等。
* @param collector 用來發送 spout 中的 tuples,它是線程安全的,建議保存為此 spout 對象的實例變量
*/
void prepare(Map stormConf, TopologyContext context, OutputCollector collector);
/**
* 處理單個 tuple 輸入。
*
* @param Tuple 對象包含關于它的元數據(如來自哪個組件/流/任務)
*/
void execute(Tuple input);
/**
* IBolt 將要被關閉的時候調用。但是其不一定會被執行,如果在集群環境中通過 kill -9 殺死進程時其就無法被執行。
*/
void cleanup();
~~~
### 4.2 BaseRichBolt抽象類
同樣的,在實現自定義 bolt 時,通常是繼承 `BaseRichBolt` 抽象類來實現。`BaseRichBolt` 繼承自 `BaseComponent` 抽象類并實現了 `IRichBolt` 接口。
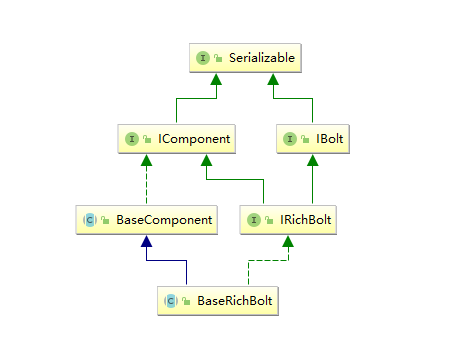
`IRichBolt` 接口繼承自 `IBolt` 和 `IComponent`,自身并沒有定義任何方法:
~~~
public interface IRichBolt extends IBolt, IComponent {
}
~~~
通過這樣的設計,在繼承 `BaseRichBolt` 實現自定義 bolt 時,就只需要實現三個必須的方法:
* **prepare**: 來源于 IBolt,可以通過此方法獲取用來發送 tuples 的 `OutputCollector`;
* **execute**:來源于 IBolt,處理 tuples 和發送處理完成的 tuples;
* **declareOutputFields** :來源于 IComponent,聲明發送的 tuples 的名稱,這樣下一個組件才能知道如何接收。
## 五、詞頻統計案例
### 5.1 案例簡介
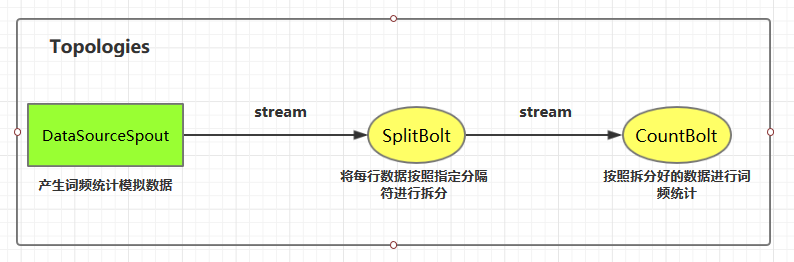
這里我們使用自定義的 `DataSourceSpout` 產生詞頻數據,然后使用自定義的 `SplitBolt` 和 `CountBolt` 來進行詞頻統計。
> 案例源碼下載地址:[storm-word-count](https://github.com/heibaiying/BigData-Notes/tree/master/code/Storm/storm-word-count)
### 5.2 代碼實現
#### 1\. 項目依賴
~~~
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>1.2.2</version>
</dependency>
~~~
#### 2\. DataSourceSpout
~~~
public class DataSourceSpout extends BaseRichSpout {
private List<String> list = Arrays.asList("Spark", "Hadoop", "HBase", "Storm", "Flink", "Hive");
private SpoutOutputCollector spoutOutputCollector;
@Override
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
this.spoutOutputCollector = spoutOutputCollector;
}
@Override
public void nextTuple() {
// 模擬產生數據
String lineData = productData();
spoutOutputCollector.emit(new Values(lineData));
Utils.sleep(1000);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("line"));
}
/**
* 模擬數據
*/
private String productData() {
Collections.shuffle(list);
Random random = new Random();
int endIndex = random.nextInt(list.size()) % (list.size()) + 1;
return StringUtils.join(list.toArray(), "\t", 0, endIndex);
}
}
~~~
上面類使用 `productData` 方法來產生模擬數據,產生數據的格式如下:
~~~
Spark HBase
Hive Flink Storm Hadoop HBase Spark
Flink
HBase Storm
HBase Hadoop Hive Flink
HBase Flink Hive Storm
Hive Flink Hadoop
HBase Hive
Hadoop Spark HBase Storm
~~~
#### 3\. SplitBolt
~~~
public class SplitBolt extends BaseRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector=collector;
}
@Override
public void execute(Tuple input) {
String line = input.getStringByField("line");
String[] words = line.split("\t");
for (String word : words) {
collector.emit(new Values(word));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
~~~
#### 4\. CountBolt
~~~
public class CountBolt extends BaseRichBolt {
private Map<String, Integer> counts = new HashMap<>();
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
}
@Override
public void execute(Tuple input) {
String word = input.getStringByField("word");
Integer count = counts.get(word);
if (count == null) {
count = 0;
}
count++;
counts.put(word, count);
// 輸出
System.out.print("當前實時統計結果:");
counts.forEach((key, value) -> System.out.print(key + ":" + value + "; "));
System.out.println();
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
~~~
#### 5\. LocalWordCountApp
通過 TopologyBuilder 將上面定義好的組件進行串聯形成 Topology,并提交到本地集群(LocalCluster)運行。通常在開發中,可先用本地模式進行測試,測試完成后再提交到服務器集群運行。
~~~
public class LocalWordCountApp {
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("DataSourceSpout", new DataSourceSpout());
// 指明將 DataSourceSpout 的數據發送到 SplitBolt 中處理
builder.setBolt("SplitBolt", new SplitBolt()).shuffleGrouping("DataSourceSpout");
// 指明將 SplitBolt 的數據發送到 CountBolt 中 處理
builder.setBolt("CountBolt", new CountBolt()).shuffleGrouping("SplitBolt");
// 創建本地集群用于測試 這種模式不需要本機安裝 storm,直接運行該 Main 方法即可
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LocalWordCountApp",
new Config(), builder.createTopology());
}
}
~~~
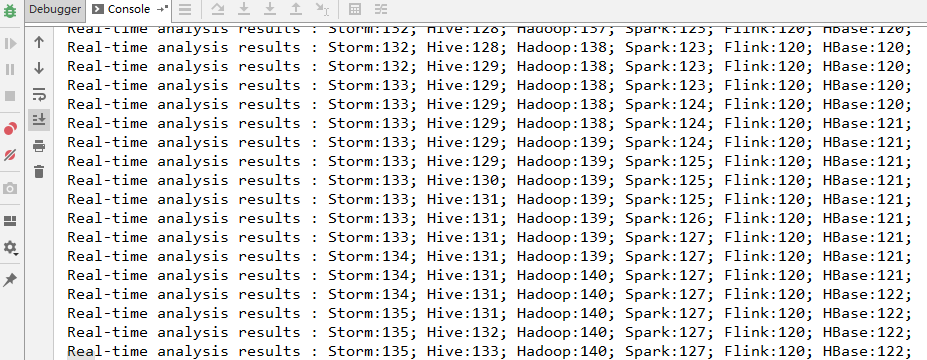
#### 6\. 運行結果
啟動 `WordCountApp` 的 main 方法即可運行,采用本地模式 Storm 會自動在本地搭建一個集群,所以啟動的過程會稍慢一點,啟動成功后即可看到輸出日志。
## 六、提交到服務器集群運行
### 6.1 代碼更改
提交到服務器的代碼和本地代碼略有不同,提交到服務器集群時需要使用 `StormSubmitter` 進行提交。主要代碼如下:
> 為了結構清晰,這里新建 ClusterWordCountApp 類來演示集群模式的提交。實際開發中可以將兩種模式的代碼寫在同一個類中,通過外部傳參來決定啟動何種模式。
~~~
public class ClusterWordCountApp {
public static void main(String[] args) {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("DataSourceSpout", new DataSourceSpout());
// 指明將 DataSourceSpout 的數據發送到 SplitBolt 中處理
builder.setBolt("SplitBolt", new SplitBolt()).shuffleGrouping("DataSourceSpout");
// 指明將 SplitBolt 的數據發送到 CountBolt 中 處理
builder.setBolt("CountBolt", new CountBolt()).shuffleGrouping("SplitBolt");
// 使用 StormSubmitter 提交 Topology 到服務器集群
try {
StormSubmitter.submitTopology("ClusterWordCountApp", new Config(), builder.createTopology());
} catch (AlreadyAliveException | InvalidTopologyException | AuthorizationException e) {
e.printStackTrace();
}
}
}
~~~
### 6.2 打包上傳
打包后上傳到服務器任意位置,這里我打包后的名稱為 `storm-word-count-1.0.jar`
~~~
# mvn clean package -Dmaven.test.skip=true
~~~
### 6.3 提交Topology
使用以下命令提交 Topology 到集群:
~~~
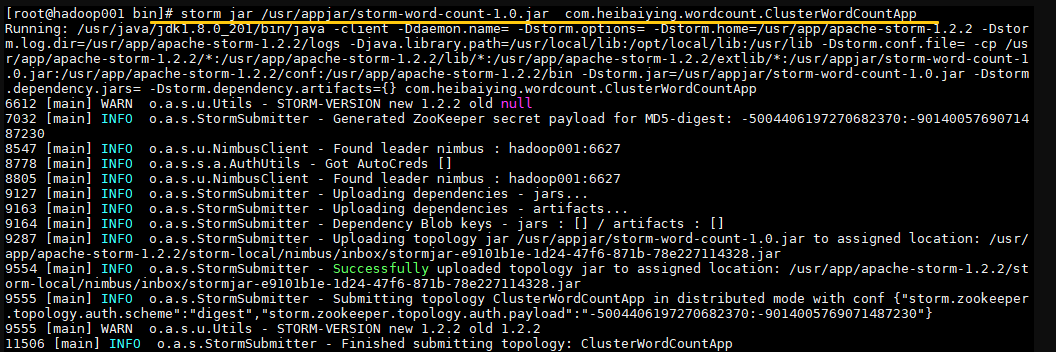
# 命令格式: storm jar jar包位置 主類的全路徑 ...可選傳參
storm jar /usr/appjar/storm-word-count-1.0.jar com.heibaiying.wordcount.ClusterWordCountApp
~~~
出現 `successfully` 則代表提交成功:
### 6.4 查看Topology與停止Topology(命令行方式)
~~~
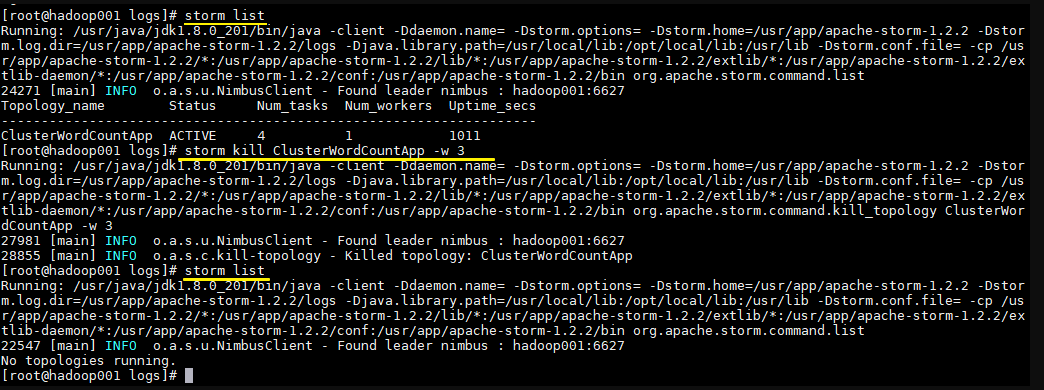
# 查看所有Topology
storm list
# 停止 storm kill topology-name [-w wait-time-secs]
storm kill ClusterWordCountApp -w 3
~~~
### 6.5 查看Topology與停止Topology(界面方式)
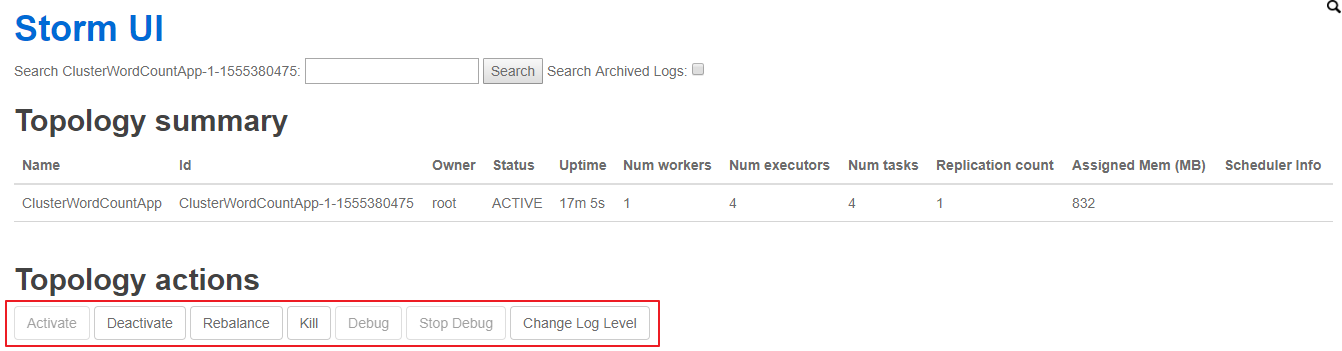
使用 UI 界面同樣也可進行停止操作,進入 WEB UI 界面(8080 端口),在 `Topology Summary` 中點擊對應 Topology 即可進入詳情頁面進行操作。
## 七、關于項目打包的擴展說明
### mvn package的局限性
在上面的步驟中,我們沒有在 POM 中配置任何插件,就直接使用 `mvn package` 進行項目打包,這對于沒有使用外部依賴包的項目是可行的。但如果項目中使用了第三方 JAR 包,就會出現問題,因為 `package` 打包后的 JAR 中是不含有依賴包的,如果此時你提交到服務器上運行,就會出現找不到第三方依賴的異常。
這時候可能大家會有疑惑,在我們的項目中不是使用了 `storm-core` 這個依賴嗎?其實上面之所以我們能運行成功,是因為在 Storm 的集群環境中提供了這個 JAR 包,在安裝目錄的 lib 目錄下:
為了說明這個問題我在 Maven 中引入了一個第三方的 JAR 包,并修改產生數據的方法:
~~~
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.8.1</version>
</dependency>
~~~
`StringUtils.join()` 這個方法在 `commons.lang3` 和 `storm-core` 中都有,原來的代碼無需任何更改,只需要在 `import` 時指明使用 `commons.lang3`。
~~~
import org.apache.commons.lang3.StringUtils;
private String productData() {
Collections.shuffle(list);
Random random = new Random();
int endIndex = random.nextInt(list.size()) % (list.size()) + 1;
return StringUtils.join(list.toArray(), "\t", 0, endIndex);
}
~~~
此時直接使用 `mvn clean package` 打包運行,就會拋出下圖的異常。因此這種直接打包的方式并不適用于實際的開發,因為實際開發中通常都是需要第三方的 JAR 包。
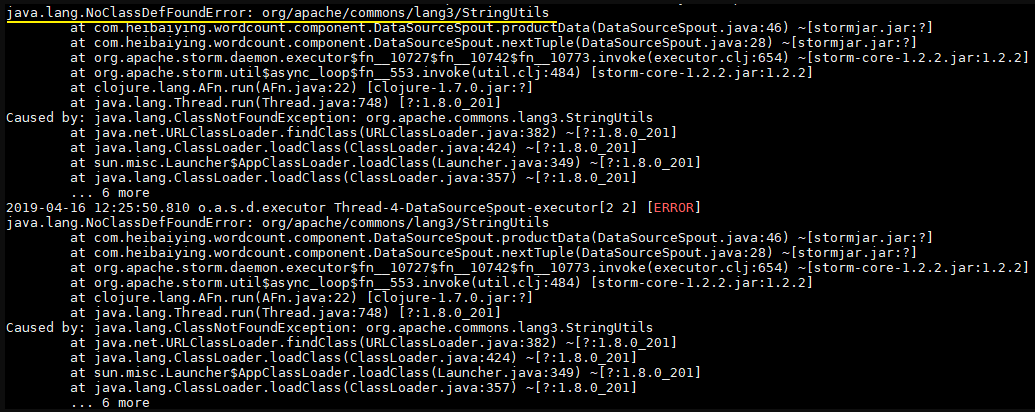
想把依賴包一并打入最后的 JAR 中,maven 提供了兩個插件來實現,分別是 `maven-assembly-plugin` 和 `maven-shade-plugin`。鑒于本篇文章篇幅已經比較長,且關于 Storm 打包還有很多需要說明的地方,所以關于 Storm 的打包方式單獨整理至下一篇文章
作者:heibaiying
鏈接:https://juejin.cn/post/6844903950034960391
來源:掘金
著作權歸作者所有。商業轉載請聯系作者獲得授權,非商業轉載請注明出處。
- 一.JVM
- 1.1 java代碼是怎么運行的
- 1.2 JVM的內存區域
- 1.3 JVM運行時內存
- 1.4 JVM內存分配策略
- 1.5 JVM類加載機制與對象的生命周期
- 1.6 常用的垃圾回收算法
- 1.7 JVM垃圾收集器
- 1.8 CMS垃圾收集器
- 1.9 G1垃圾收集器
- 2.面試相關文章
- 2.1 可能是把Java內存區域講得最清楚的一篇文章
- 2.0 GC調優參數
- 2.1GC排查系列
- 2.2 內存泄漏和內存溢出
- 2.2.3 深入理解JVM-hotspot虛擬機對象探秘
- 1.10 并發的可達性分析相關問題
- 二.Java集合架構
- 1.ArrayList深入源碼分析
- 2.Vector深入源碼分析
- 3.LinkedList深入源碼分析
- 4.HashMap深入源碼分析
- 5.ConcurrentHashMap深入源碼分析
- 6.HashSet,LinkedHashSet 和 LinkedHashMap
- 7.容器中的設計模式
- 8.集合架構之面試指南
- 9.TreeSet和TreeMap
- 三.Java基礎
- 1.基礎概念
- 1.1 Java程序初始化的順序是怎么樣的
- 1.2 Java和C++的區別
- 1.3 反射
- 1.4 注解
- 1.5 泛型
- 1.6 字節與字符的區別以及訪問修飾符
- 1.7 深拷貝與淺拷貝
- 1.8 字符串常量池
- 2.面向對象
- 3.關鍵字
- 4.基本數據類型與運算
- 5.字符串與數組
- 6.異常處理
- 7.Object 通用方法
- 8.Java8
- 8.1 Java 8 Tutorial
- 8.2 Java 8 數據流(Stream)
- 8.3 Java 8 并發教程:線程和執行器
- 8.4 Java 8 并發教程:同步和鎖
- 8.5 Java 8 并發教程:原子變量和 ConcurrentMap
- 8.6 Java 8 API 示例:字符串、數值、算術和文件
- 8.7 在 Java 8 中避免 Null 檢查
- 8.8 使用 Intellij IDEA 解決 Java 8 的數據流問題
- 四.Java 并發編程
- 1.線程的實現/創建
- 2.線程生命周期/狀態轉換
- 3.線程池
- 4.線程中的協作、中斷
- 5.Java鎖
- 5.1 樂觀鎖、悲觀鎖和自旋鎖
- 5.2 Synchronized
- 5.3 ReentrantLock
- 5.4 公平鎖和非公平鎖
- 5.3.1 說說ReentrantLock的實現原理,以及ReentrantLock的核心源碼是如何實現的?
- 5.5 鎖優化和升級
- 6.多線程的上下文切換
- 7.死鎖的產生和解決
- 8.J.U.C(java.util.concurrent)
- 0.簡化版(快速復習用)
- 9.鎖優化
- 10.Java 內存模型(JMM)
- 11.ThreadLocal詳解
- 12 CAS
- 13.AQS
- 0.ArrayBlockingQueue和LinkedBlockingQueue的實現原理
- 1.DelayQueue的實現原理
- 14.Thread.join()實現原理
- 15.PriorityQueue 的特性和原理
- 16.CyclicBarrier的實際使用場景
- 五.Java I/O NIO
- 1.I/O模型簡述
- 2.Java NIO之緩沖區
- 3.JAVA NIO之文件通道
- 4.Java NIO之套接字通道
- 5.Java NIO之選擇器
- 6.基于 Java NIO 實現簡單的 HTTP 服務器
- 7.BIO-NIO-AIO
- 8.netty(一)
- 9.NIO面試題
- 六.Java設計模式
- 1.單例模式
- 2.策略模式
- 3.模板方法
- 4.適配器模式
- 5.簡單工廠
- 6.門面模式
- 7.代理模式
- 七.數據結構和算法
- 1.什么是紅黑樹
- 2.二叉樹
- 2.1 二叉樹的前序、中序、后序遍歷
- 3.排序算法匯總
- 4.java實現鏈表及鏈表的重用操作
- 4.1算法題-鏈表反轉
- 5.圖的概述
- 6.常見的幾道字符串算法題
- 7.幾道常見的鏈表算法題
- 8.leetcode常見算法題1
- 9.LRU緩存策略
- 10.二進制及位運算
- 10.1.二進制和十進制轉換
- 10.2.位運算
- 11.常見鏈表算法題
- 12.算法好文推薦
- 13.跳表
- 八.Spring 全家桶
- 1.Spring IOC
- 2.Spring AOP
- 3.Spring 事務管理
- 4.SpringMVC 運行流程和手動實現
- 0.Spring 核心技術
- 5.spring如何解決循環依賴問題
- 6.springboot自動裝配原理
- 7.Spring中的循環依賴解決機制中,為什么要三級緩存,用二級緩存不夠嗎
- 8.beanFactory和factoryBean有什么區別
- 九.數據庫
- 1.mybatis
- 1.1 MyBatis-# 與 $ 區別以及 sql 預編譯
- Mybatis系列1-Configuration
- Mybatis系列2-SQL執行過程
- Mybatis系列3-之SqlSession
- Mybatis系列4-之Executor
- Mybatis系列5-StatementHandler
- Mybatis系列6-MappedStatement
- Mybatis系列7-參數設置揭秘(ParameterHandler)
- Mybatis系列8-緩存機制
- 2.淺談聚簇索引和非聚簇索引的區別
- 3.mysql 證明為什么用limit時,offset很大會影響性能
- 4.MySQL中的索引
- 5.數據庫索引2
- 6.面試題收集
- 7.MySQL行鎖、表鎖、間隙鎖詳解
- 8.數據庫MVCC詳解
- 9.一條SQL查詢語句是如何執行的
- 10.MySQL 的 crash-safe 原理解析
- 11.MySQL 性能優化神器 Explain 使用分析
- 12.mysql中,一條update語句執行的過程是怎么樣的?期間用到了mysql的哪些log,分別有什么作用
- 十.Redis
- 0.快速復習回顧Redis
- 1.通俗易懂的Redis數據結構基礎教程
- 2.分布式鎖(一)
- 3.分布式鎖(二)
- 4.延時隊列
- 5.位圖Bitmaps
- 6.Bitmaps(位圖)的使用
- 7.Scan
- 8.redis緩存雪崩、緩存擊穿、緩存穿透
- 9.Redis為什么是單線程、及高并發快的3大原因詳解
- 10.布隆過濾器你值得擁有的開發利器
- 11.Redis哨兵、復制、集群的設計原理與區別
- 12.redis的IO多路復用
- 13.相關redis面試題
- 14.redis集群
- 十一.中間件
- 1.RabbitMQ
- 1.1 RabbitMQ實戰,hello world
- 1.2 RabbitMQ 實戰,工作隊列
- 1.3 RabbitMQ 實戰, 發布訂閱
- 1.4 RabbitMQ 實戰,路由
- 1.5 RabbitMQ 實戰,主題
- 1.6 Spring AMQP 的 AMQP 抽象
- 1.7 Spring AMQP 實戰 – 整合 RabbitMQ 發送郵件
- 1.8 RabbitMQ 的消息持久化與 Spring AMQP 的實現剖析
- 1.9 RabbitMQ必備核心知識
- 2.RocketMQ 的幾個簡單問題與答案
- 2.Kafka
- 2.1 kafka 基礎概念和術語
- 2.2 Kafka的重平衡(Rebalance)
- 2.3.kafka日志機制
- 2.4 kafka是pull還是push的方式傳遞消息的?
- 2.5 Kafka的數據處理流程
- 2.6 Kafka的腦裂預防和處理機制
- 2.7 Kafka中partition副本的Leader選舉機制
- 2.8 如果Leader掛了的時候,follower沒來得及同步,是否會出現數據不一致
- 2.9 kafka的partition副本是否會出現腦裂情況
- 十二.Zookeeper
- 0.什么是Zookeeper(漫畫)
- 1.使用docker安裝Zookeeper偽集群
- 3.ZooKeeper-Plus
- 4.zk實現分布式鎖
- 5.ZooKeeper之Watcher機制
- 6.Zookeeper之選舉及數據一致性
- 十三.計算機網絡
- 1.進制轉換:二進制、八進制、十六進制、十進制之間的轉換
- 2.位運算
- 3.計算機網絡面試題匯總1
- 十四.Docker
- 100.面試題收集合集
- 1.美團面試常見問題總結
- 2.b站部分面試題
- 3.比心面試題
- 4.騰訊面試題
- 5.哈羅部分面試
- 6.筆記
- 十五.Storm
- 1.Storm和流處理簡介
- 2.Storm 核心概念詳解
- 3.Storm 單機版本環境搭建
- 4.Storm 集群環境搭建
- 5.Storm 編程模型詳解
- 6.Storm 項目三種打包方式對比分析
- 7.Storm 集成 Redis 詳解
- 8.Storm 集成 HDFS 和 HBase
- 9.Storm 集成 Kafka
- 十六.Elasticsearch
- 1.初識ElasticSearch
- 2.文檔基本CRUD、集群健康檢查
- 3.shard&replica
- 4.document核心元數據解析及ES的并發控制
- 5.document的批量操作及數據路由原理
- 6.倒排索引
- 十七.分布式相關
- 1.分布式事務解決方案一網打盡
- 2.關于xxx怎么保證高可用的問題
- 3.一致性hash原理與實現
- 4.微服務注冊中心 Nacos 比 Eureka的優勢
- 5.Raft 協議算法
- 6.為什么微服務架構中需要網關
- 0.CAP與BASE理論
- 十八.Dubbo
- 1.快速掌握Dubbo常規應用
- 2.Dubbo應用進階
- 3.Dubbo調用模塊詳解
- 4.Dubbo調用模塊源碼分析
- 6.Dubbo協議模塊