
[TOC]
## 1. 好久不見
離上一篇文章的發布也快一個月了,想想已經快一個月沒寫東西了,其中可能有期末考試、課程設計和駕照考試,但這都不是借口!
一到冬天就懶的不行,望廣大掘友督促我????????。
> 文章很長,先贊后看,養成習慣。?? ?? ?? ?? ?? ??
## 2. 什么是ZooKeeper
`ZooKeeper` 由 `Yahoo` 開發,后來捐贈給了 `Apache` ,現已成為 `Apache` 頂級項目。`ZooKeeper` 是一個開源的分布式應用程序協調服務器,其為分布式系統提供一致性服務。其一致性是通過基于 `Paxos` 算法的 `ZAB` 協議完成的。其主要功能包括:配置維護、分布式同步、集群管理、分布式事務等。

簡單來說, `ZooKeeper` 是一個 **分布式協調服務框架** 。分布式?協調服務?這啥玩意?????
其實解釋到分布式這個概念的時候,我發現有些同學并不是能把 **分布式和集群 **這兩個概念很好的理解透。前段時間有同學和我探討起分布式的東西,他說分布式不就是加機器嗎?一臺機器不夠用再加一臺抗壓唄。當然加機器這種說法也無可厚非,你一個分布式系統必定涉及到多個機器,但是你別忘了,計算機學科中還有一個相似的概念—— `Cluster` ,集群不也是加機器嗎?但是 集群 和 分布式 其實就是兩個完全不同的概念。
比如,我現在有一個秒殺服務,并發量太大單機系統承受不住,那我加幾臺服務器也 **一樣** 提供秒殺服務,這個時候就是 **`Cluster` 集群** 。
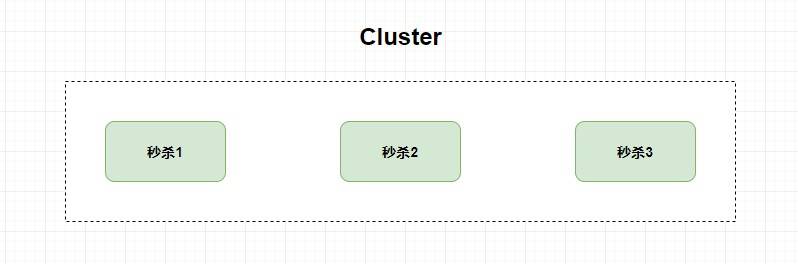
但是,我現在換一種方式,我將一個秒殺服務 **拆分成多個子服務** ,比如創建訂單服務,增加積分服務,扣優惠券服務等等,**然后我將這些子服務都部署在不同的服務器上** ,這個時候就是 **`Distributed` 分布式** 。

而我為什么反駁同學所說的分布式就是加機器呢?因為我認為加機器更加適用于構建集群,因為它真是只有加機器。而對于分布式來說,你首先需要將業務進行拆分,然后再加機器(不僅僅是加機器那么簡單),同時你還要去解決分布式帶來的一系列問題。

比如各個分布式組件如何協調起來,如何減少各個系統之間的耦合度,分布式事務的處理,如何去配置整個分布式系統等等。`ZooKeeper` 主要就是解決這些問題的。
## 3. 一致性問題
設計一個分布式系統必定會遇到一個問題—— **因為分區容忍性(partition tolerance)的存在,就必定要求我們需要在系統可用性(availability)和數據一致性(consistency)中做出權衡** 。這就是著名的 `CAP` 定理。
理解起來其實很簡單,比如說把一個班級作為整個系統,而學生是系統中的一個個獨立的子系統。這個時候班里的小紅小明偷偷談戀愛被班里的大嘴巴小花發現了,小花欣喜若狂告訴了周圍的人,然后小紅小明談戀愛的消息在班級里傳播起來了。當在消息的傳播(散布)過程中,你抓到一個同學問他們的情況,如果回答你不知道,那么說明整個班級系統出現了數據不一致的問題(因為小花已經知道這個消息了)。而如果他直接不回答你,因為整個班級有消息在進行傳播(為了保證一致性,需要所有人都知道才可提供服務),這個時候就出現了系統的可用性問題。

而上述前者就是 `Eureka` 的處理方式,它保證了AP(可用性),后者就是我們今天所要講的 `ZooKeeper` 的處理方式,它保證了CP(數據一致性)。
## 4. 一致性協議和算法
而為了解決數據一致性問題,在科學家和程序員的不斷探索中,就出現了很多的一致性協議和算法。比如 2PC(兩階段提交),3PC(三階段提交),Paxos算法等等。
這時候請你思考一個問題,同學之間如果采用傳紙條的方式去傳播消息,那么就會出現一個問題——我咋知道我的小紙條有沒有傳到我想要傳遞的那個人手中呢?萬一被哪個小家伙給劫持篡改了呢,對吧?

這個時候就引申出一個概念—— **拜占庭將軍問題** 。它意指 **在不可靠信道上試圖通過消息傳遞的方式達到一致性是不可能的**, 所以所有的一致性算法的 **必要前提** 就是安全可靠的消息通道。
而為什么要去解決數據一致性的問題?你想想,如果一個秒殺系統將服務拆分成了下訂單和加積分服務,這兩個服務部署在不同的機器上了,萬一在消息的傳播過程中積分系統宕機了,總不能你這邊下了訂單卻沒加積分吧?你總得保證兩邊的數據需要一致吧?
### 4.1. 2PC(兩階段提交)
兩階段提交是一種保證分布式系統數據一致性的協議,現在很多數據庫都是采用的兩階段提交協議來完成 **分布式事務** 的處理。
在介紹2PC之前,我們先來想想分布式事務到底有什么問題呢?
還拿秒殺系統的下訂單和加積分兩個系統來舉例吧(我想你們可能都吐了??????),我們此時下完訂單會發個消息給積分系統告訴它下面該增加積分了。如果我們僅僅是發送一個消息也不收回復,那么我們的訂單系統怎么能知道積分系統的收到消息的情況呢?如果我們增加一個收回復的過程,那么當積分系統收到消息后返回給訂單系統一個 `Response` ,但在中間出現了網絡波動,那個回復消息沒有發送成功,訂單系統是不是以為積分系統消息接收失敗了?它是不是會回滾事務?但此時積分系統是成功收到消息的,它就會去處理消息然后給用戶增加積分,這個時候就會出現積分加了但是訂單沒下成功。
所以我們所需要解決的是在分布式系統中,整個調用鏈中,我們所有服務的數據處理要么都成功要么都失敗,即所有服務的 **原子性問題** 。
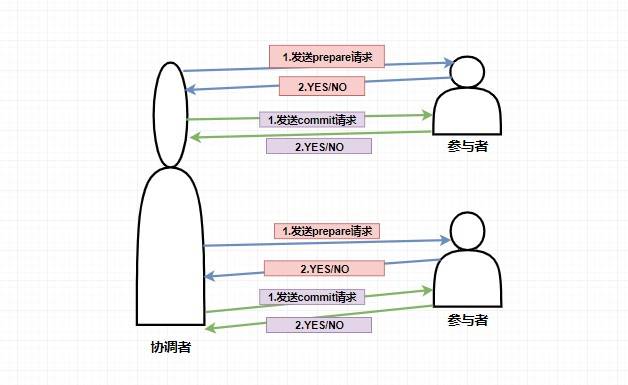
在兩階段提交中,主要涉及到兩個角色,分別是協調者和參與者。
第一階段:當要執行一個分布式事務的時候,事務發起者首先向協調者發起事務請求,然后協調者會給所有參與者發送 `prepare` 請求(其中包括事務內容)告訴參與者你們需要執行事務了,如果能執行我發的事務內容那么就先執行但不提交,執行后請給我回復。然后參與者收到 `prepare` 消息后,他們會開始執行事務(但不提交),并將 `Undo` 和 `Redo` 信息記入事務日志中,之后參與者就向協調者反饋是否準備好了。
第二階段:第二階段主要是協調者根據參與者反饋的情況來決定接下來是否可以進行事務的提交操作,即提交事務或者回滾事務。
比如這個時候 **所有的參與者** 都返回了準備好了的消息,這個時候就進行事務的提交,協調者此時會給所有的參與者發送 **`Commit` 請求** ,當參與者收到 `Commit` 請求的時候會執行前面執行的事務的 **提交操作** ,提交完畢之后將給協調者發送提交成功的響應。
而如果在第一階段并不是所有參與者都返回了準備好了的消息,那么此時協調者將會給所有參與者發送 **回滾事務的 `rollback` 請求**,參與者收到之后將會 **回滾它在第一階段所做的事務處理** ,然后再將處理情況返回給協調者,最終協調者收到響應后便給事務發起者返回處理失敗的結果。
個人覺得 2PC 實現得還是比較雞肋的,因為事實上它只解決了各個事務的原子性問題,隨之也帶來了很多的問題。

* **單點故障問題**,如果協調者掛了那么整個系統都處于不可用的狀態了。
* **阻塞問題**,即當協調者發送 `prepare` 請求,參與者收到之后如果能處理那么它將會進行事務的處理但并不提交,這個時候會一直占用著資源不釋放,如果此時協調者掛了,那么這些資源都不會再釋放了,這會極大影響性能。
* **數據不一致問題**,比如當第二階段,協調者只發送了一部分的 `commit` 請求就掛了,那么也就意味著,收到消息的參與者會進行事務的提交,而后面沒收到的則不會進行事務提交,那么這時候就會產生數據不一致性問題。
### 4.2. 3PC(三階段提交)
因為2PC存在的一系列問題,比如單點,容錯機制缺陷等等,從而產生了 **3PC(三階段提交)** 。那么這三階段又分別是什么呢?
> 千萬不要吧PC理解成個人電腦了,其實他們是 phase-commit 的縮寫,即階段提交。
1. **CanCommit階段**:協調者向所有參與者發送 `CanCommit` 請求,參與者收到請求后會根據自身情況查看是否能執行事務,如果可以則返回 YES 響應并進入預備狀態,否則返回 NO 。
2. **PreCommit階段**:協調者根據參與者返回的響應來決定是否可以進行下面的 `PreCommit` 操作。如果上面參與者返回的都是 YES,那么協調者將向所有參與者發送 `PreCommit` 預提交請求,**參與者收到預提交請求后,會進行事務的執行操作,并將 `Undo` 和 `Redo` 信息寫入事務日志中** ,最后如果參與者順利執行了事務則給協調者返回成功的響應。如果在第一階段協調者收到了 **任何一個 NO** 的信息,或者 **在一定時間內** 并沒有收到全部的參與者的響應,那么就會中斷事務,它會向所有參與者發送中斷請求(abort),參與者收到中斷請求之后會立即中斷事務,或者在一定時間內沒有收到協調者的請求,它也會中斷事務。
3. **DoCommit階段**:這個階段其實和 `2PC` 的第二階段差不多,如果協調者收到了所有參與者在 `PreCommit` 階段的 YES 響應,那么協調者將會給所有參與者發送 `DoCommit` 請求,**參與者收到 `DoCommit` 請求后則會進行事務的提交工作**,完成后則會給協調者返回響應,協調者收到所有參與者返回的事務提交成功的響應之后則完成事務。若協調者在 `PreCommit` 階段 **收到了任何一個 NO 或者在一定時間內沒有收到所有參與者的響應** ,那么就會進行中斷請求的發送,參與者收到中斷請求后則會 **通過上面記錄的回滾日志** 來進行事務的回滾操作,并向協調者反饋回滾狀況,協調者收到參與者返回的消息后,中斷事務。
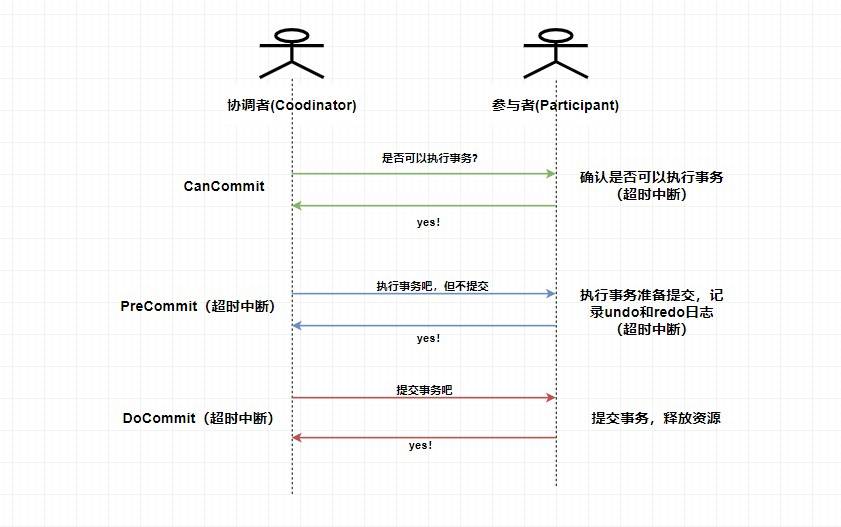
> 這里是 `3PC` 在成功的環境下的流程圖,你可以看到 `3PC` 在很多地方進行了超時中斷的處理,比如協調者在指定時間內為收到全部的確認消息則進行事務中斷的處理,這樣能 **減少同步阻塞的時間** 。還有需要注意的是,**`3PC` 在 `DoCommit` 階段參與者如未收到協調者發送的提交事務的請求,它會在一定時間內進行事務的提交**。為什么這么做呢?是因為這個時候我們肯定**保證了在第一階段所有的協調者全部返回了可以執行事務的響應**,這個時候我們有理由**相信其他系統都能進行事務的執行和提交**,所以**不管**協調者有沒有發消息給參與者,進入第三階段參與者都會進行事務的提交操作。
總之,`3PC` 通過一系列的超時機制很好的緩解了阻塞問題,但是最重要的一致性并沒有得到根本的解決,比如在 `PreCommit` 階段,當一個參與者收到了請求之后其他參與者和協調者掛了或者出現了網絡分區,這個時候收到消息的參與者都會進行事務提交,這就會出現數據不一致性問題。
所以,要解決一致性問題還需要靠 `Paxos` 算法?? ?? ?? 。
### 4.3. `Paxos` 算法
`Paxos` 算法是基于**消息傳遞且具有高度容錯特性的一致性算法**,是目前公認的解決分布式一致性問題最有效的算法之一,**其解決的問題就是在分布式系統中如何就某個值(決議)達成一致** 。
在 `Paxos` 中主要有三個角色,分別為 `Proposer提案者`、`Acceptor表決者`、`Learner學習者`。`Paxos` 算法和 `2PC` 一樣,也有兩個階段,分別為 `Prepare` 和 `accept` 階段。
#### 4.3.1. prepare 階段
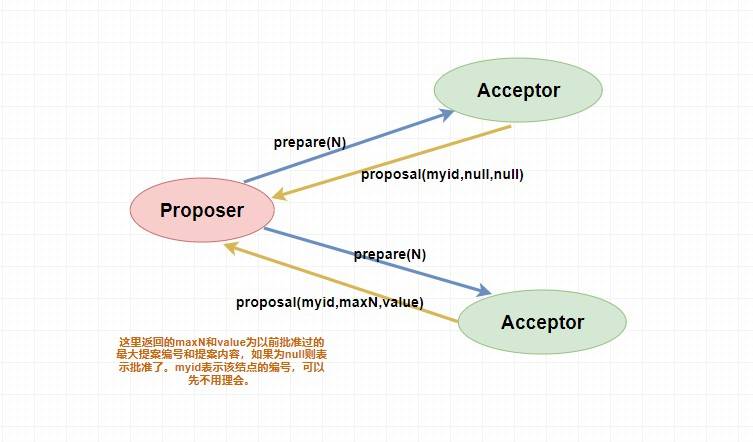
* `Proposer提案者`:負責提出 `proposal`,每個提案者在提出提案時都會首先獲取到一個 **具有全局唯一性的、遞增的提案編號N**,即在整個集群中是唯一的編號 N,然后將該編號賦予其要提出的提案,在**第一階段是只將提案編號發送給所有的表決者**。
* `Acceptor表決者`:每個表決者在 `accept` 某提案后,會將該提案編號N記錄在本地,這樣每個表決者中保存的已經被 accept 的提案中會存在一個**編號最大的提案**,其編號假設為 `maxN`。每個表決者僅會 `accept` 編號大于自己本地 `maxN` 的提案,在批準提案時表決者會將以前接受過的最大編號的提案作為響應反饋給 `Proposer` 。
> 下面是 `prepare` 階段的流程圖,你可以對照著參考一下。
#### 4.3.2. accept 階段
當一個提案被 `Proposer` 提出后,如果 `Proposer` 收到了超過半數的 `Acceptor` 的批準(`Proposer` 本身同意),那么此時 `Proposer` 會給所有的 `Acceptor` 發送真正的提案(你可以理解為第一階段為試探),這個時候 `Proposer` 就會發送提案的內容和提案編號。
表決者收到提案請求后會再次比較本身已經批準過的最大提案編號和該提案編號,如果該提案編號 **大于等于** 已經批準過的最大提案編號,那么就 `accept` 該提案(此時執行提案內容但不提交),隨后將情況返回給 `Proposer` 。如果不滿足則不回應或者返回 NO 。

當 `Proposer` 收到超過半數的 `accept` ,那么它這個時候會向所有的 `acceptor` 發送提案的提交請求。需要注意的是,因為上述僅僅是超過半數的 `acceptor` 批準執行了該提案內容,其他沒有批準的并沒有執行該提案內容,所以這個時候需要**向未批準的 `acceptor` 發送提案內容和提案編號并讓它無條件執行和提交**,而對于前面已經批準過該提案的 `acceptor` 來說 **僅僅需要發送該提案的編號** ,讓 `acceptor` 執行提交就行了。
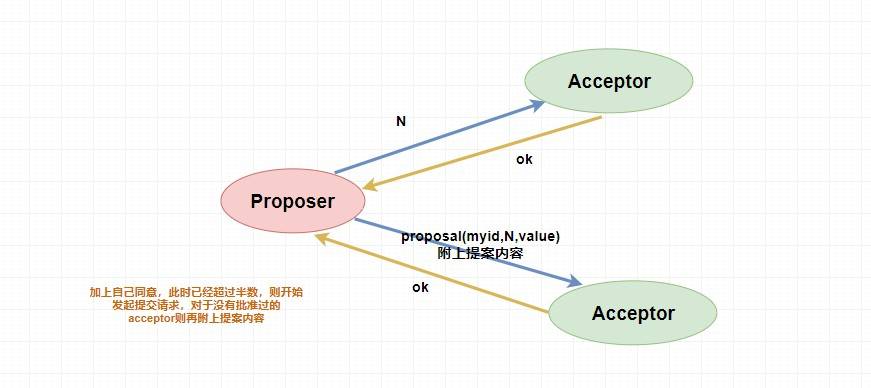
而如果 `Proposer` 如果沒有收到超過半數的 `accept` 那么它將會將 **遞增** 該 `Proposal` 的編號,然后 **重新進入 `Prepare` 階段** 。
> 對于 `Learner` 來說如何去學習 `Acceptor` 批準的提案內容,這有很多方式,讀者可以自己去了解一下,這里不做過多解釋。
#### 4.3.3. `paxos` 算法的死循環問題
其實就有點類似于兩個人吵架,小明說我是對的,小紅說我才是對的,兩個人據理力爭的誰也不讓誰????。
比如說,此時提案者 P1 提出一個方案 M1,完成了 `Prepare` 階段的工作,這個時候 `acceptor` 則批準了 M1,但是此時提案者 P2 同時也提出了一個方案 M2,它也完成了 `Prepare` 階段的工作。然后 P1 的方案已經不能在第二階段被批準了(因為 `acceptor` 已經批準了比 M1 更大的 M2),所以 P1 自增方案變為 M3 重新進入 `Prepare` 階段,然后 `acceptor` ,又批準了新的 M3 方案,它又不能批準 M2 了,這個時候 M2 又自增進入 `Prepare` 階段。。。
就這樣無休無止的永遠提案下去,這就是 `paxos` 算法的死循環問題。

那么如何解決呢?很簡單,人多了容易吵架,我現在 **就允許一個能提案** 就行了。
## 5. 引出 `ZAB`
### 5.1. `Zookeeper` 架構
作為一個優秀高效且可靠的分布式協調框架,`ZooKeeper` 在解決分布式數據一致性問題時并沒有直接使用 `Paxos` ,而是專門定制了一致性協議叫做 `ZAB(ZooKeeper Automic Broadcast)` 原子廣播協議,該協議能夠很好地支持 **崩潰恢復** 。
### 5.2. `ZAB` 中的三個角色
和介紹 `Paxos` 一樣,在介紹 `ZAB` 協議之前,我們首先來了解一下在 `ZAB` 中三個主要的角色,`Leader 領導者`、`Follower跟隨者`、`Observer觀察者` 。
* `Leader` :集群中 **唯一的寫請求處理者** ,能夠發起投票(投票也是為了進行寫請求)。
* `Follower`:能夠接收客戶端的請求,如果是讀請求則可以自己處理,**如果是寫請求則要轉發給 `Leader`** 。在選舉過程中會參與投票,**有選舉權和被選舉權** 。
* `Observer` :就是沒有選舉權和被選舉權的 `Follower` 。
在 `ZAB` 協議中對 `zkServer`(即上面我們說的三個角色的總稱) 還有兩種模式的定義,分別是 **消息廣播** 和 **崩潰恢復** 。
### 5.3. 消息廣播模式
說白了就是 `ZAB` 協議是如何處理寫請求的,上面我們不是說只有 `Leader` 能處理寫請求嘛?那么我們的 `Follower` 和 `Observer` 是不是也需要 **同步更新數據** 呢?總不能數據只在 `Leader` 中更新了,其他角色都沒有得到更新吧?
不就是 **在整個集群中保持數據的一致性** 嘛?如果是你,你會怎么做呢?

廢話,第一步肯定需要 `Leader` 將寫請求 **廣播** 出去呀,讓 `Leader` 問問 `Followers` 是否同意更新,如果超過半數以上的同意那么就進行 `Follower` 和 `Observer` 的更新(和 `Paxos` 一樣)。當然這么說有點虛,畫張圖理解一下。
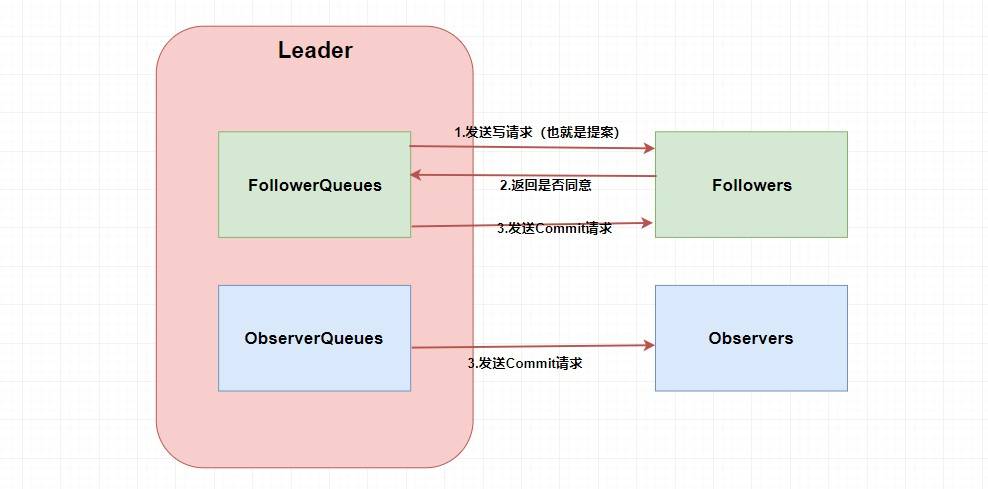
嗯。。。看起來很簡單,貌似懂了??????。這兩個 `Queue` 哪冒出來的?答案是 **`ZAB` 需要讓 `Follower` 和 `Observer` 保證順序性** 。何為順序性,比如我現在有一個寫請求A,此時 `Leader` 將請求A廣播出去,因為只需要半數同意就行,所以可能這個時候有一個 `Follower` F1因為網絡原因沒有收到,而 `Leader` 又廣播了一個請求B,因為網絡原因,F1竟然先收到了請求B然后才收到了請求A,這個時候請求處理的順序不同就會導致數據的不同,從而 **產生數據不一致問題** 。
所以在 `Leader` 這端,它為每個其他的 `zkServer` 準備了一個 **隊列** ,采用先進先出的方式發送消息。由于協議是 **通過 `TCP` **來進行網絡通信的,保證了消息的發送順序性,接受順序性也得到了保證。
除此之外,在 `ZAB` 中還定義了一個 **全局單調遞增的事務ID `ZXID`** ,它是一個64位long型,其中高32位表示 `epoch` 年代,低32位表示事務id。`epoch` 是會根據 `Leader` 的變化而變化的,當一個 `Leader` 掛了,新的 `Leader` 上位的時候,年代(`epoch`)就變了。而低32位可以簡單理解為遞增的事務id。
定義這個的原因也是為了順序性,每個 `proposal` 在 `Leader` 中生成后需要 **通過其 `ZXID` 來進行排序** ,才能得到處理。
### 5.4. 崩潰恢復模式
說到崩潰恢復我們首先要提到 `ZAB` 中的 `Leader` 選舉算法,當系統出現崩潰影響最大應該是 `Leader` 的崩潰,因為我們只有一個 `Leader` ,所以當 `Leader` 出現問題的時候我們勢必需要重新選舉 `Leader` 。
`Leader` 選舉可以分為兩個不同的階段,第一個是我們提到的 `Leader` 宕機需要重新選舉,第二則是當 `Zookeeper` 啟動時需要進行系統的 `Leader` 初始化選舉。下面我先來介紹一下 `ZAB` 是如何進行初始化選舉的。
假設我們集群中有3臺機器,那也就意味著我們需要兩臺以上同意(超過半數)。比如這個時候我們啟動了 `server1` ,它會首先 **投票給自己** ,投票內容為服務器的 `myid` 和 `ZXID` ,因為初始化所以 `ZXID` 都為0,此時 `server1` 發出的投票為 (1,0)。但此時 `server1` 的投票僅為1,所以不能作為 `Leader` ,此時還在選舉階段所以整個集群處于 **`Looking` 狀態**。
接著 `server2` 啟動了,它首先也會將投票選給自己(2,0),并將投票信息廣播出去(`server1`也會,只是它那時沒有其他的服務器了),`server1` 在收到 `server2` 的投票信息后會將投票信息與自己的作比較。**首先它會比較 `ZXID` ,`ZXID` 大的優先為 `Leader`,如果相同則比較 `myid`,`myid` 大的優先作為 `Leader`**。所以此時`server1` 發現 `server2` 更適合做 `Leader`,它就會將自己的投票信息更改為(2,0)然后再廣播出去,之后`server2` 收到之后發現和自己的一樣無需做更改,并且自己的 **投票已經超過半數** ,則 **確定 `server2` 為 `Leader`**,`server1` 也會將自己服務器設置為 `Following` 變為 `Follower`。整個服務器就從 `Looking` 變為了正常狀態。
當 `server3` 啟動發現集群沒有處于 `Looking` 狀態時,它會直接以 `Follower` 的身份加入集群。
還是前面三個 `server` 的例子,如果在整個集群運行的過程中 `server2` 掛了,那么整個集群會如何重新選舉 `Leader` 呢?其實和初始化選舉差不多。
首先毫無疑問的是剩下的兩個 `Follower` 會將自己的狀態 **從 `Following` 變為 `Looking` 狀態** ,然后每個 `server` 會向初始化投票一樣首先給自己投票(這不過這里的 `zxid` 可能不是0了,這里為了方便隨便取個數字)。
假設 `server1` 給自己投票為(1,99),然后廣播給其他 `server`,`server3` 首先也會給自己投票(3,95),然后也廣播給其他 `server`。`server1` 和 `server3` 此時會收到彼此的投票信息,和一開始選舉一樣,他們也會比較自己的投票和收到的投票(`zxid` 大的優先,如果相同那么就 `myid` 大的優先)。這個時候 `server1` 收到了 `server3` 的投票發現沒自己的合適故不變,`server3` 收到 `server1` 的投票結果后發現比自己的合適于是更改投票為(1,99)然后廣播出去,最后 `server1` 收到了發現自己的投票已經超過半數就把自己設為 `Leader`,`server3` 也隨之變為 `Follower`。
> 請注意 `ZooKeeper` 為什么要設置奇數個結點?比如這里我們是三個,掛了一個我們還能正常工作,掛了兩個我們就不能正常工作了(已經沒有超過半數的節點數了,所以無法進行投票等操作了)。而假設我們現在有四個,掛了一個也能工作,**但是掛了兩個也不能正常工作了**,這是和三個一樣的,而三個比四個還少一個,帶來的效益是一樣的,所以 `Zookeeper` 推薦奇數個 `server` 。
那么說完了 `ZAB` 中的 `Leader` 選舉方式之后我們再來了解一下 **崩潰恢復** 是什么玩意?
其實主要就是 **當集群中有機器掛了,我們整個集群如何保證數據一致性?**
如果只是 `Follower` 掛了,而且掛的沒超過半數的時候,因為我們一開始講了在 `Leader` 中會維護隊列,所以不用擔心后面的數據沒接收到導致數據不一致性。
如果 `Leader` 掛了那就麻煩了,我們肯定需要先暫停服務變為 `Looking` 狀態然后進行 `Leader` 的重新選舉(上面我講過了),但這個就要分為兩種情況了,分別是 **確保已經被Leader提交的提案最終能夠被所有的Follower提交** 和 **跳過那些已經被丟棄的提案** 。
確保已經被Leader提交的提案最終能夠被所有的Follower提交是什么意思呢?
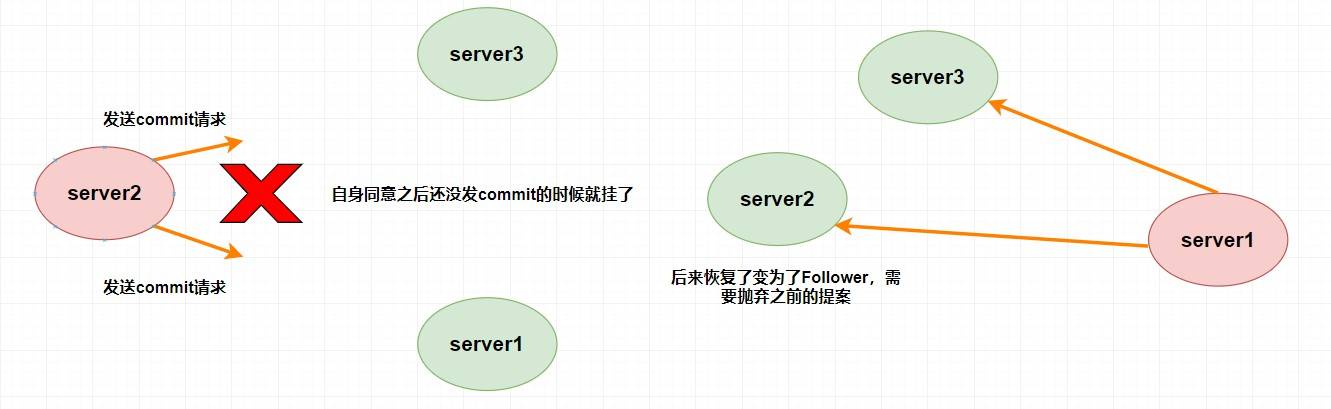
假設 `Leader (server2)` 發送 `commit` 請求(忘了請看上面的消息廣播模式),他發送給了 `server3`,然后要發給 `server1` 的時候突然掛了。這個時候重新選舉的時候我們如果把 `server1` 作為 `Leader` 的話,那么肯定會產生數據不一致性,因為 `server3` 肯定會提交剛剛 `server2` 發送的 `commit` 請求的提案,而 `server1` 根本沒收到所以會丟棄。
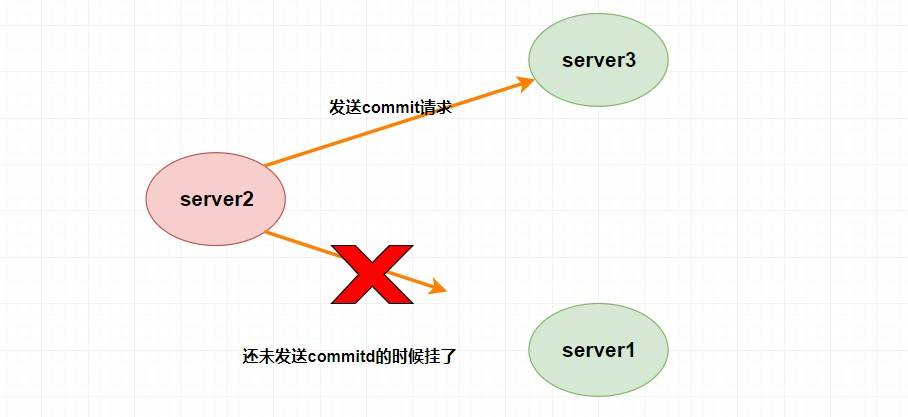
那怎么解決呢?
聰明的同學肯定會質疑,**這個時候 `server1` 已經不可能成為 `Leader` 了,因為 `server1` 和 `server3` 進行投票選舉的時候會比較 `ZXID` ,而此時 `server3` 的 `ZXID` 肯定比 `server1` 的大了**。(不理解可以看前面的選舉算法)
那么跳過那些已經被丟棄的提案又是什么意思呢?
假設 `Leader (server2)` 此時同意了提案N1,自身提交了這個事務并且要發送給所有 `Follower` 要 `commit` 的請求,卻在這個時候掛了,此時肯定要重新進行 `Leader` 的選舉,比如說此時選 `server1` 為 `Leader` (這無所謂)。但是過了一會,這個 **掛掉的 `Leader` 又重新恢復了** ,此時它肯定會作為 `Follower` 的身份進入集群中,需要注意的是剛剛 `server2` 已經同意提交了提案N1,但其他 `server` 并沒有收到它的 `commit` 信息,所以其他 `server` 不可能再提交這個提案N1了,這樣就會出現數據不一致性問題了,所以 **該提案N1最終需要被拋棄掉** 。
## 6. Zookeeper的幾個理論知識
了解了 `ZAB` 協議還不夠,它僅僅是 `Zookeeper` 內部實現的一種方式,而我們如何通過 `Zookeeper` 去做一些典型的應用場景呢?比如說集群管理,分布式鎖,`Master` 選舉等等。
這就涉及到如何使用 `Zookeeper` 了,但在使用之前我們還需要掌握幾個概念。比如 `Zookeeper` 的 **數據模型** 、**會話機制**、**ACL**、**Watcher機制** 等等。
### 6.1. 數據模型
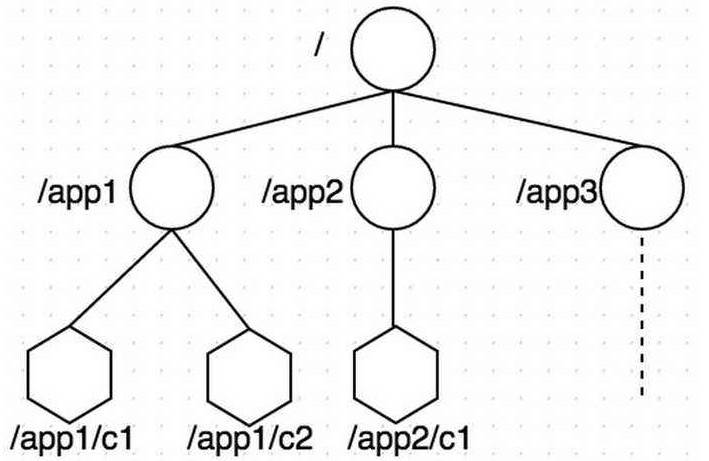
`zookeeper` 數據存儲結構與標準的 `Unix` 文件系統非常相似,都是在根節點下掛很多子節點(樹型)。但是 `zookeeper` 中沒有文件系統中目錄與文件的概念,而是 **使用了 `znode` 作為數據節點** 。`znode` 是 `zookeeper` 中的最小數據單元,每個 `znode` 上都可以保存數據,同時還可以掛載子節點,形成一個樹形化命名空間。
每個 `znode` 都有自己所屬的 **節點類型** 和 **節點狀態**。
其中節點類型可以分為 **持久節點**、**持久順序節點**、**臨時節點** 和 **臨時順序節點**。
* 持久節點:一旦創建就一直存在,直到將其刪除。
* 持久順序節點:一個父節點可以為其子節點 **維護一個創建的先后順序** ,這個順序體現在 **節點名稱** 上,是節點名稱后自動添加一個由 10 位數字組成的數字串,從 0 開始計數。
* 臨時節點:臨時節點的生命周期是與 **客戶端會話** 綁定的,**會話消失則節點消失** 。臨時節點 **只能做葉子節點** ,不能創建子節點。
* 臨時順序節點:父節點可以創建一個維持了順序的臨時節點(和前面的持久順序性節點一樣)。
節點狀態中包含了很多節點的屬性比如 `czxid` 、`mzxid` 等等,在 `zookeeper` 中是使用 `Stat` 這個類來維護的。下面我列舉一些屬性解釋。
* `czxid`:`Created ZXID`,該數據節點被 **創建** 時的事務ID。
* `mzxid`:`Modified ZXID`,節點 **最后一次被更新時** 的事務ID。
* `ctime`:`Created Time`,該節點被創建的時間。
* `mtime`: `Modified Time`,該節點最后一次被修改的時間。
* `version`:節點的版本號。
* `cversion`:**子節點** 的版本號。
* `aversion`:節點的 `ACL` 版本號。
* `ephemeralOwner`:創建該節點的會話的 `sessionID` ,如果該節點為持久節點,該值為0。
* `dataLength`:節點數據內容的長度。
* `numChildre`:該節點的子節點個數,如果為臨時節點為0。
* `pzxid`:該節點子節點列表最后一次被修改時的事務ID,注意是子節點的 **列表** ,不是內容。
### 6.2. 會話
我想這個對于后端開發的朋友肯定不陌生,不就是 `session` 嗎?只不過 `zk` 客戶端和服務端是通過 **`TCP` 長連接** 維持的會話機制,其實對于會話來說你可以理解為 **保持連接狀態** 。
在 `zookeeper` 中,會話還有對應的事件,比如 `CONNECTION_LOSS 連接丟失事件` 、`SESSION_MOVED 會話轉移事件` 、`SESSION_EXPIRED 會話超時失效事件` 。
### 6.3. ACL
`ACL` 為 `Access Control Lists` ,它是一種權限控制。在 `zookeeper` 中定義了5種權限,它們分別為:
* `CREATE` :創建子節點的權限。
* `READ`:獲取節點數據和子節點列表的權限。
* `WRITE`:更新節點數據的權限。
* `DELETE`:刪除子節點的權限。
* `ADMIN`:設置節點 ACL 的權限。
### 6.4. Watcher機制
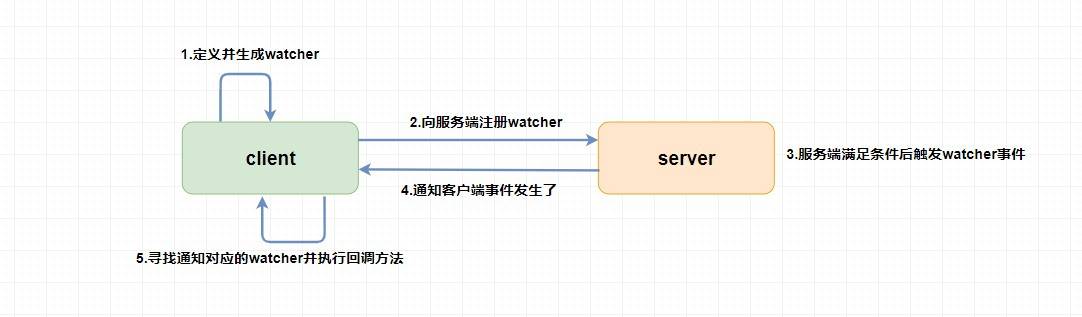
`Watcher` 為事件監聽器,是 `zk` 非常重要的一個特性,很多功能都依賴于它,它有點類似于訂閱的方式,即客戶端向服務端 **注冊** 指定的 `watcher` ,當服務端符合了 `watcher` 的某些事件或要求則會 **向客戶端發送事件通知** ,客戶端收到通知后找到自己定義的 `Watcher` 然后 **執行相應的回調方法** 。
## 7. Zookeeper的幾個典型應用場景
前面說了這么多的理論知識,你可能聽得一頭霧水,這些玩意有啥用?能干啥事?別急,聽我慢慢道來。

### 7.1. 選主
還記得上面我們的所說的臨時節點嗎?因為 `Zookeeper` 的強一致性,能夠很好地在保證 **在高并發的情況下保證節點創建的全局唯一性** (即無法重復創建同樣的節點)。
利用這個特性,我們可以 **讓多個客戶端創建一個指定的節點** ,創建成功的就是 `master`。
但是,如果這個 `master` 掛了怎么辦???
你想想為什么我們要創建臨時節點?還記得臨時節點的生命周期嗎?`master` 掛了是不是代表會話斷了?會話斷了是不是意味著這個節點沒了?還記得 `watcher` 嗎?我們是不是可以 **讓其他不是 `master` 的節點監聽節點的狀態** ,比如說我們監聽這個臨時節點的父節點,如果子節點個數變了就代表 `master` 掛了,這個時候我們 **觸發回調函數進行重新選舉** ,或者我們直接監聽節點的狀態,我們可以通過節點是否已經失去連接來判斷 `master` 是否掛了等等。
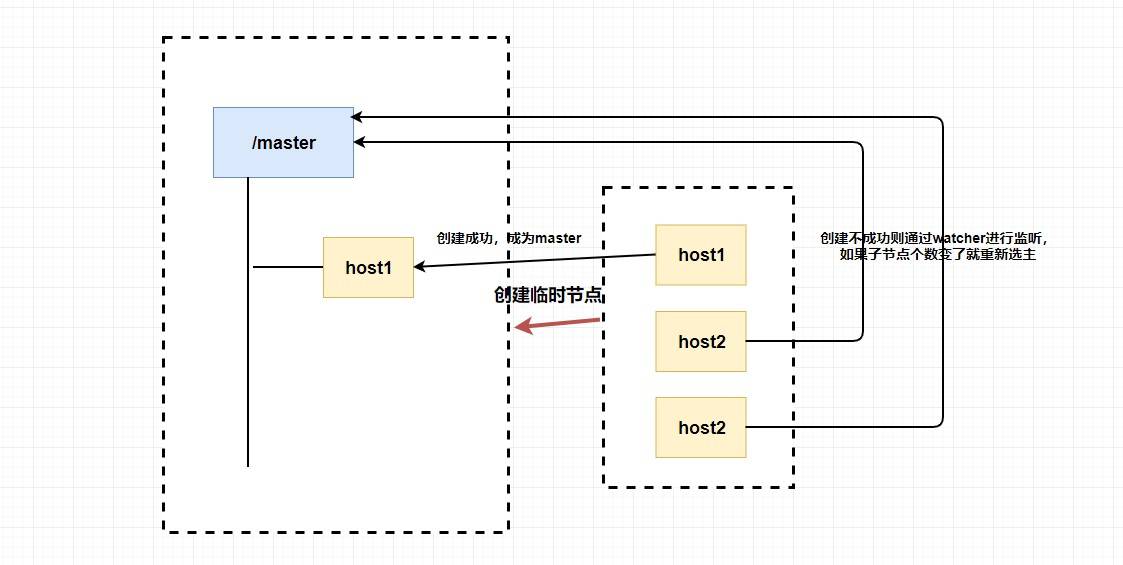
總的來說,我們可以完全 **利用 臨時節點、節點狀態 和 `watcher` 來實現選主的功能**,臨時節點主要用來選舉,節點狀態和`watcher` 可以用來判斷 `master` 的活性和進行重新選舉。
### 7.2. 分布式鎖
分布式鎖的實現方式有很多種,比如 `Redis` 、數據庫 、`zookeeper` 等。個人認為 `zookeeper` 在實現分布式鎖這方面是非常非常簡單的。
上面我們已經提到過了 **zk在高并發的情況下保證節點創建的全局唯一性**,這玩意一看就知道能干啥了。實現互斥鎖唄,又因為能在分布式的情況下,所以能實現分布式鎖唄。
如何實現呢?這玩意其實跟選主基本一樣,我們也可以利用臨時節點的創建來實現。
首先肯定是如何獲取鎖,因為創建節點的唯一性,我們可以讓多個客戶端同時創建一個臨時節點,**創建成功的就說明獲取到了鎖** 。然后沒有獲取到鎖的客戶端也像上面選主的非主節點創建一個 `watcher` 進行節點狀態的監聽,如果這個互斥鎖被釋放了(可能獲取鎖的客戶端宕機了,或者那個客戶端主動釋放了鎖)可以調用回調函數重新獲得鎖。
> `zk` 中不需要向 `redis` 那樣考慮鎖得不到釋放的問題了,因為當客戶端掛了,節點也掛了,鎖也釋放了。是不是很簡答?
那能不能使用 `zookeeper` 同時實現 **共享鎖和獨占鎖** 呢?答案是可以的,不過稍微有點復雜而已。
還記得 **有序的節點** 嗎?
這個時候我規定所有創建節點必須有序,當你是讀請求(要獲取共享鎖)的話,如果 **沒有比自己更小的節點,或比自己小的節點都是讀請求** ,則可以獲取到讀鎖,然后就可以開始讀了。**若比自己小的節點中有寫請求** ,則當前客戶端無法獲取到讀鎖,只能等待前面的寫請求完成。
如果你是寫請求(獲取獨占鎖),若 **沒有比自己更小的節點** ,則表示當前客戶端可以直接獲取到寫鎖,對數據進行修改。若發現 **有比自己更小的節點,無論是讀操作還是寫操作,當前客戶端都無法獲取到寫鎖** ,等待所有前面的操作完成。
這就很好地同時實現了共享鎖和獨占鎖,當然還有優化的地方,比如當一個鎖得到釋放它會通知所有等待的客戶端從而造成 **羊群效應** 。此時你可以通過讓等待的節點只監聽他們前面的節點。
具體怎么做呢?其實也很簡單,你可以讓 **讀請求監聽比自己小的最后一個寫請求節點,寫請求只監聽比自己小的最后一個節點** ,感興趣的小伙伴可以自己去研究一下。
### 7.3. 命名服務
如何給一個對象設置ID,大家可能都會想到 `UUID`,但是 `UUID` 最大的問題就在于它太長了。。。(太長不一定是好事,嘿嘿嘿)。那么在條件允許的情況下,我們能不能使用 `zookeeper` 來實現呢?
我們之前提到過 `zookeeper` 是通過 **樹形結構** 來存儲數據節點的,那也就是說,對于每個節點的 **全路徑**,它必定是唯一的,我們可以使用節點的全路徑作為命名方式了。而且更重要的是,路徑是我們可以自己定義的,這對于我們對有些有語意的對象的ID設置可以更加便于理解。
### 7.4. 集群管理和注冊中心
看到這里是不是覺得 `zookeeper` 實在是太強大了,它怎么能這么能干!
別急,它能干的事情還很多呢。可能我們會有這樣的需求,我們需要了解整個集群中有多少機器在工作,我們想對及群眾的每臺機器的運行時狀態進行數據采集,對集群中機器進行上下線操作等等。
而 `zookeeper` 天然支持的 `watcher` 和 臨時節點能很好的實現這些需求。我們可以為每條機器創建臨時節點,并監控其父節點,如果子節點列表有變動(我們可能創建刪除了臨時節點),那么我們可以使用在其父節點綁定的 `watcher` 進行狀態監控和回調。

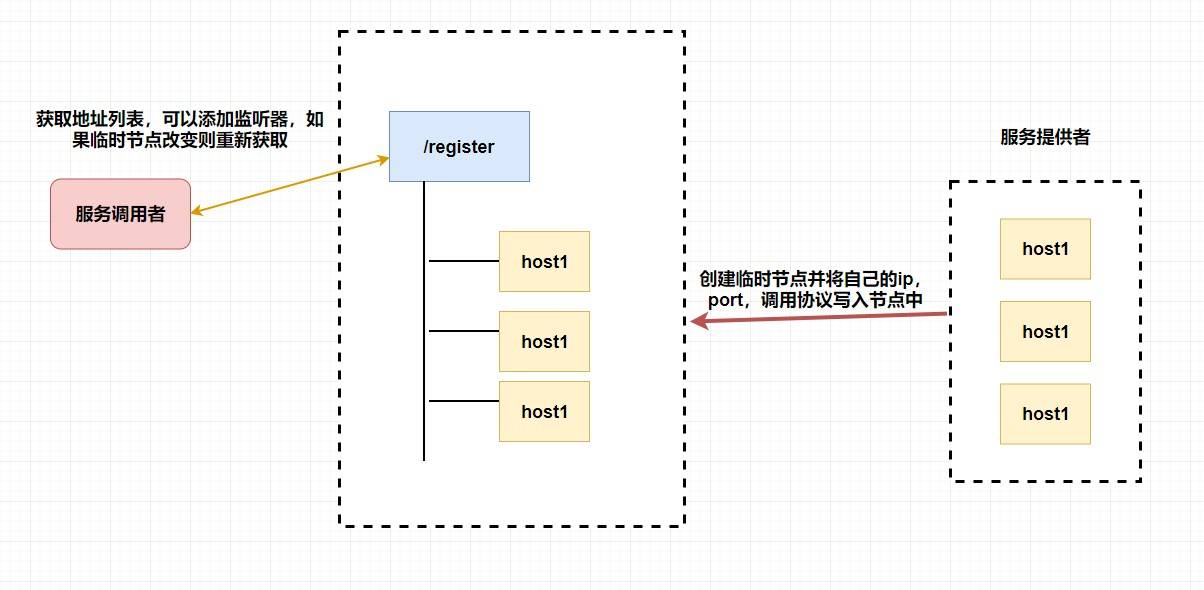
至于注冊中心也很簡單,我們同樣也是讓 **服務提供者** 在 `zookeeper` 中創建一個臨時節點并且將自己的 `ip、port、調用方式` 寫入節點,當 **服務消費者** 需要進行調用的時候會 **通過注冊中心找到相應的服務的地址列表(IP端口什么的)** ,并緩存到本地(方便以后調用),當消費者調用服務時,不會再去請求注冊中心,而是直接通過負載均衡算法從地址列表中取一個服務提供者的服務器調用服務。
當服務提供者的某臺服務器宕機或下線時,相應的地址會從服務提供者地址列表中移除。同時,注冊中心會將新的服務地址列表發送給服務消費者的機器并緩存在消費者本機(當然你可以讓消費者進行節點監聽,我記得 `Eureka` 會先試錯,然后再更新)。
## 8. 總結
看到這里的同學實在是太有耐心了??????,如果覺得我寫得不錯的話點個贊哈。
不知道大家是否還記得我講了什么??。

這篇文章中我帶大家入門了 `zookeeper` 這個強大的分布式協調框架。現在我們來簡單梳理一下整篇文章的內容。
* 分布式與集群的區別
* `2PC` 、`3PC` 以及 `paxos` 算法這些一致性框架的原理和實現。
* `zookeeper` 專門的一致性算法 `ZAB` 原子廣播協議的內容(`Leader` 選舉、崩潰恢復、消息廣播)。
* `zookeeper` 中的一些基本概念,比如 `ACL`,數據節點,會話,`watcher`機制等等。
* `zookeeper` 的典型應用場景,比如選主,注冊中心等等。
=================================
本文轉載至:[JavaGuide-ZooKeeperPlus]([https://github.com/Snailclimb/JavaGuide/blob/master/docs/system-design/distributed-system/zookeeper/zookeeper-plus.md](https://github.com/Snailclimb/JavaGuide/blob/master/docs/system-design/distributed-system/zookeeper/zookeeper-plus.md))
- 一.JVM
- 1.1 java代碼是怎么運行的
- 1.2 JVM的內存區域
- 1.3 JVM運行時內存
- 1.4 JVM內存分配策略
- 1.5 JVM類加載機制與對象的生命周期
- 1.6 常用的垃圾回收算法
- 1.7 JVM垃圾收集器
- 1.8 CMS垃圾收集器
- 1.9 G1垃圾收集器
- 2.面試相關文章
- 2.1 可能是把Java內存區域講得最清楚的一篇文章
- 2.0 GC調優參數
- 2.1GC排查系列
- 2.2 內存泄漏和內存溢出
- 2.2.3 深入理解JVM-hotspot虛擬機對象探秘
- 1.10 并發的可達性分析相關問題
- 二.Java集合架構
- 1.ArrayList深入源碼分析
- 2.Vector深入源碼分析
- 3.LinkedList深入源碼分析
- 4.HashMap深入源碼分析
- 5.ConcurrentHashMap深入源碼分析
- 6.HashSet,LinkedHashSet 和 LinkedHashMap
- 7.容器中的設計模式
- 8.集合架構之面試指南
- 9.TreeSet和TreeMap
- 三.Java基礎
- 1.基礎概念
- 1.1 Java程序初始化的順序是怎么樣的
- 1.2 Java和C++的區別
- 1.3 反射
- 1.4 注解
- 1.5 泛型
- 1.6 字節與字符的區別以及訪問修飾符
- 1.7 深拷貝與淺拷貝
- 1.8 字符串常量池
- 2.面向對象
- 3.關鍵字
- 4.基本數據類型與運算
- 5.字符串與數組
- 6.異常處理
- 7.Object 通用方法
- 8.Java8
- 8.1 Java 8 Tutorial
- 8.2 Java 8 數據流(Stream)
- 8.3 Java 8 并發教程:線程和執行器
- 8.4 Java 8 并發教程:同步和鎖
- 8.5 Java 8 并發教程:原子變量和 ConcurrentMap
- 8.6 Java 8 API 示例:字符串、數值、算術和文件
- 8.7 在 Java 8 中避免 Null 檢查
- 8.8 使用 Intellij IDEA 解決 Java 8 的數據流問題
- 四.Java 并發編程
- 1.線程的實現/創建
- 2.線程生命周期/狀態轉換
- 3.線程池
- 4.線程中的協作、中斷
- 5.Java鎖
- 5.1 樂觀鎖、悲觀鎖和自旋鎖
- 5.2 Synchronized
- 5.3 ReentrantLock
- 5.4 公平鎖和非公平鎖
- 5.3.1 說說ReentrantLock的實現原理,以及ReentrantLock的核心源碼是如何實現的?
- 5.5 鎖優化和升級
- 6.多線程的上下文切換
- 7.死鎖的產生和解決
- 8.J.U.C(java.util.concurrent)
- 0.簡化版(快速復習用)
- 9.鎖優化
- 10.Java 內存模型(JMM)
- 11.ThreadLocal詳解
- 12 CAS
- 13.AQS
- 0.ArrayBlockingQueue和LinkedBlockingQueue的實現原理
- 1.DelayQueue的實現原理
- 14.Thread.join()實現原理
- 15.PriorityQueue 的特性和原理
- 16.CyclicBarrier的實際使用場景
- 五.Java I/O NIO
- 1.I/O模型簡述
- 2.Java NIO之緩沖區
- 3.JAVA NIO之文件通道
- 4.Java NIO之套接字通道
- 5.Java NIO之選擇器
- 6.基于 Java NIO 實現簡單的 HTTP 服務器
- 7.BIO-NIO-AIO
- 8.netty(一)
- 9.NIO面試題
- 六.Java設計模式
- 1.單例模式
- 2.策略模式
- 3.模板方法
- 4.適配器模式
- 5.簡單工廠
- 6.門面模式
- 7.代理模式
- 七.數據結構和算法
- 1.什么是紅黑樹
- 2.二叉樹
- 2.1 二叉樹的前序、中序、后序遍歷
- 3.排序算法匯總
- 4.java實現鏈表及鏈表的重用操作
- 4.1算法題-鏈表反轉
- 5.圖的概述
- 6.常見的幾道字符串算法題
- 7.幾道常見的鏈表算法題
- 8.leetcode常見算法題1
- 9.LRU緩存策略
- 10.二進制及位運算
- 10.1.二進制和十進制轉換
- 10.2.位運算
- 11.常見鏈表算法題
- 12.算法好文推薦
- 13.跳表
- 八.Spring 全家桶
- 1.Spring IOC
- 2.Spring AOP
- 3.Spring 事務管理
- 4.SpringMVC 運行流程和手動實現
- 0.Spring 核心技術
- 5.spring如何解決循環依賴問題
- 6.springboot自動裝配原理
- 7.Spring中的循環依賴解決機制中,為什么要三級緩存,用二級緩存不夠嗎
- 8.beanFactory和factoryBean有什么區別
- 九.數據庫
- 1.mybatis
- 1.1 MyBatis-# 與 $ 區別以及 sql 預編譯
- Mybatis系列1-Configuration
- Mybatis系列2-SQL執行過程
- Mybatis系列3-之SqlSession
- Mybatis系列4-之Executor
- Mybatis系列5-StatementHandler
- Mybatis系列6-MappedStatement
- Mybatis系列7-參數設置揭秘(ParameterHandler)
- Mybatis系列8-緩存機制
- 2.淺談聚簇索引和非聚簇索引的區別
- 3.mysql 證明為什么用limit時,offset很大會影響性能
- 4.MySQL中的索引
- 5.數據庫索引2
- 6.面試題收集
- 7.MySQL行鎖、表鎖、間隙鎖詳解
- 8.數據庫MVCC詳解
- 9.一條SQL查詢語句是如何執行的
- 10.MySQL 的 crash-safe 原理解析
- 11.MySQL 性能優化神器 Explain 使用分析
- 12.mysql中,一條update語句執行的過程是怎么樣的?期間用到了mysql的哪些log,分別有什么作用
- 十.Redis
- 0.快速復習回顧Redis
- 1.通俗易懂的Redis數據結構基礎教程
- 2.分布式鎖(一)
- 3.分布式鎖(二)
- 4.延時隊列
- 5.位圖Bitmaps
- 6.Bitmaps(位圖)的使用
- 7.Scan
- 8.redis緩存雪崩、緩存擊穿、緩存穿透
- 9.Redis為什么是單線程、及高并發快的3大原因詳解
- 10.布隆過濾器你值得擁有的開發利器
- 11.Redis哨兵、復制、集群的設計原理與區別
- 12.redis的IO多路復用
- 13.相關redis面試題
- 14.redis集群
- 十一.中間件
- 1.RabbitMQ
- 1.1 RabbitMQ實戰,hello world
- 1.2 RabbitMQ 實戰,工作隊列
- 1.3 RabbitMQ 實戰, 發布訂閱
- 1.4 RabbitMQ 實戰,路由
- 1.5 RabbitMQ 實戰,主題
- 1.6 Spring AMQP 的 AMQP 抽象
- 1.7 Spring AMQP 實戰 – 整合 RabbitMQ 發送郵件
- 1.8 RabbitMQ 的消息持久化與 Spring AMQP 的實現剖析
- 1.9 RabbitMQ必備核心知識
- 2.RocketMQ 的幾個簡單問題與答案
- 2.Kafka
- 2.1 kafka 基礎概念和術語
- 2.2 Kafka的重平衡(Rebalance)
- 2.3.kafka日志機制
- 2.4 kafka是pull還是push的方式傳遞消息的?
- 2.5 Kafka的數據處理流程
- 2.6 Kafka的腦裂預防和處理機制
- 2.7 Kafka中partition副本的Leader選舉機制
- 2.8 如果Leader掛了的時候,follower沒來得及同步,是否會出現數據不一致
- 2.9 kafka的partition副本是否會出現腦裂情況
- 十二.Zookeeper
- 0.什么是Zookeeper(漫畫)
- 1.使用docker安裝Zookeeper偽集群
- 3.ZooKeeper-Plus
- 4.zk實現分布式鎖
- 5.ZooKeeper之Watcher機制
- 6.Zookeeper之選舉及數據一致性
- 十三.計算機網絡
- 1.進制轉換:二進制、八進制、十六進制、十進制之間的轉換
- 2.位運算
- 3.計算機網絡面試題匯總1
- 十四.Docker
- 100.面試題收集合集
- 1.美團面試常見問題總結
- 2.b站部分面試題
- 3.比心面試題
- 4.騰訊面試題
- 5.哈羅部分面試
- 6.筆記
- 十五.Storm
- 1.Storm和流處理簡介
- 2.Storm 核心概念詳解
- 3.Storm 單機版本環境搭建
- 4.Storm 集群環境搭建
- 5.Storm 編程模型詳解
- 6.Storm 項目三種打包方式對比分析
- 7.Storm 集成 Redis 詳解
- 8.Storm 集成 HDFS 和 HBase
- 9.Storm 集成 Kafka
- 十六.Elasticsearch
- 1.初識ElasticSearch
- 2.文檔基本CRUD、集群健康檢查
- 3.shard&replica
- 4.document核心元數據解析及ES的并發控制
- 5.document的批量操作及數據路由原理
- 6.倒排索引
- 十七.分布式相關
- 1.分布式事務解決方案一網打盡
- 2.關于xxx怎么保證高可用的問題
- 3.一致性hash原理與實現
- 4.微服務注冊中心 Nacos 比 Eureka的優勢
- 5.Raft 協議算法
- 6.為什么微服務架構中需要網關
- 0.CAP與BASE理論
- 十八.Dubbo
- 1.快速掌握Dubbo常規應用
- 2.Dubbo應用進階
- 3.Dubbo調用模塊詳解
- 4.Dubbo調用模塊源碼分析
- 6.Dubbo協議模塊