
` `Zynq7021有1G的DDR,PS和PL都可以對DDR進行訪問。PS端對DDR的讀寫,在Xil_io.h文件中,使用Xil_Out函數可以向 DDR寫入數據,使用Xil_In函數可以從DDR讀取數據。但是要注意ARM的二級緩存問題。
## 大端存儲和小端存儲
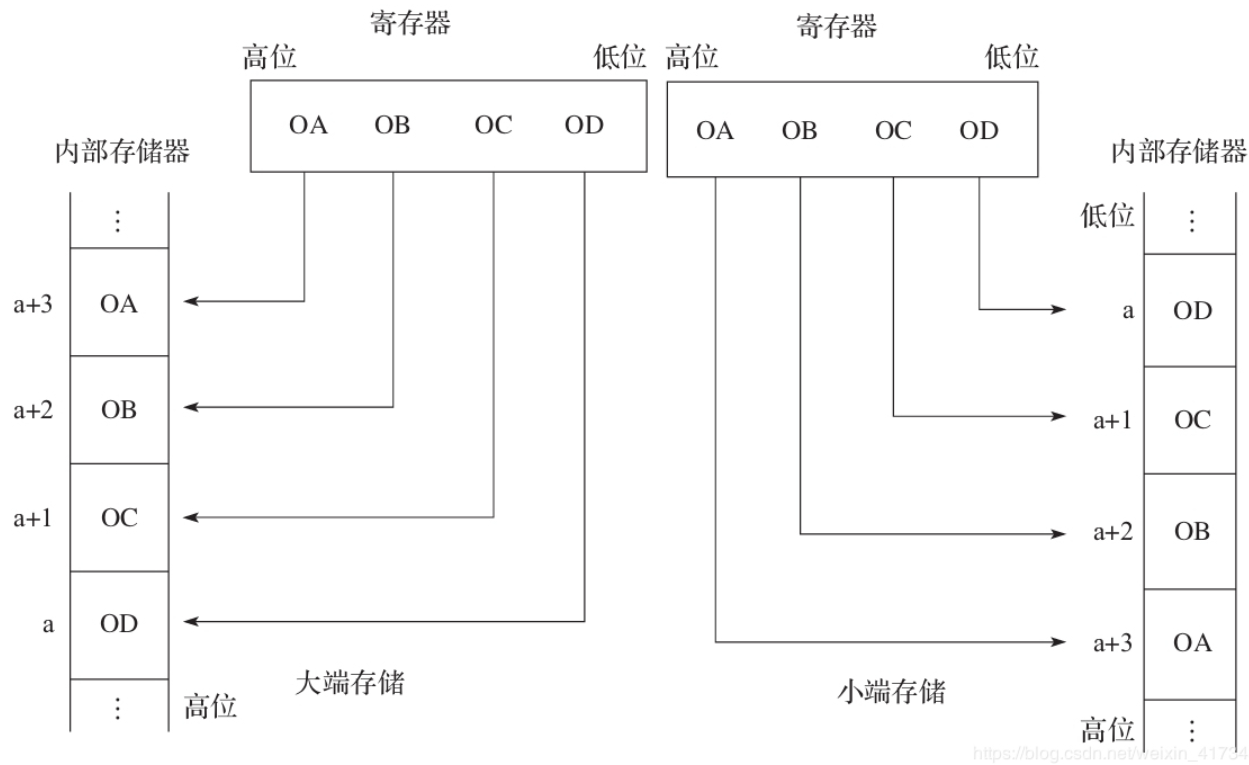
` `在CPU內部的地址總線和數據總線是與內存的地址總線和數據總線連接在一起的。當一個數從內存中向CPU傳送時,有時是以字節為單位,有時又以字(4字節)為單位。傳過來是放在寄存器里(一般是32字節),在寄存器中,一個字的表示是右邊應該屬于低位,左邊屬于高位,如果寄存器的高位和內存中的高地址相對應,低位和內存的低地址相對應,這就屬于小端存儲。反之則稱為大端存儲。大部分處理器都是小端存儲的。
` `因為十六進制的2位正好是1字節,所以選十六進制0x0A0B0C0D為例,如圖2-1所示,對小端存儲,低位是0x0D,應存入低位地址,所以存入的順序是`0x0D 0x0C 0x0B 0x0A
`。反之,對于大端存儲則為`0x0A 0x0B 0x0C 0x0D
`。
## zynq的存儲方式
` `驗證zynq存儲方式:
```
/**
* PS對DDR的讀寫,以及驗證設備是屬于大端存儲還是小端存儲
*/
void DDR_PS_TEST()
{
Xil_Out32(0x30000000,0x12345678);
u32 data1 = Xil_In8(0x30000000);
u32 data2 = Xil_In8(0x30000000 + 1);
u32 data3 = Xil_In8(0x30000000 + 2);
u32 data4 = Xil_In8(0x30000000 + 3);
printf("地址:%x 8位數據:%x\n",0x30000000,data1);
printf("地址:%x 8位數據:%x\n",0x30000001,data2);
printf("地址:%x 8位數據:%x\n",0x30000002,data3);
printf("地址:%x 8位數據:%x\n",0x30000003,data4);
while(1)usleep(1000000);
}
```
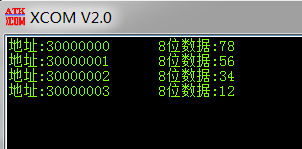
` `可以看到在zynq中是屬于小端存儲。因此使用PL端AXI總線實現寫入8位的數據的示例代碼:
```
module module
(
input clk,
output reg [31:0]addr,
output reg [31:0]data
);
reg [7:0]new_byte;
always@(posedge clk)
begin
data <= data{data[23:0],new_byte};
addr <= addr + 1;
new_byte <= new_byte + 1'b1;
end
endmodule
```
` ` 同理可得,寫入16位的數據如下:
```
module
(
input clk,
output reg [31:0]addr,
output reg [31:0]data
);
reg [15:0]new_word;
always@(posedge clk)
begin
data <= data{data[15:0],new_word};
addr <= addr + 2;
new_word <= new_word + 1'b1;
end
endmodule
```
` `采用這種方式,必須在一種數據類型的最高地址后空出3的地址,避免后續數據被覆蓋。
## C語言中與存儲有關的情況
` `下面,分享一道有趣的編程題,加深印象,此題來自>
在32位的X86系統下,輸出的值為:
```
#include <stdio.h>
int main()
{
int a[5]={1,2,3,4,5}; //A
int *ptr1=(int *)(&a+1); //B
int *ptr2=(int *)((int)a+1); //C
printf("%x,%x",ptr1[-1],*ptr2); //D
return 0;
}
```
` `首先,由題目可知32位的X86系統是采用小端存儲的,即高位放高地址,低位放地址。執行完A語句后,假設該數組是放在0起始地址上。
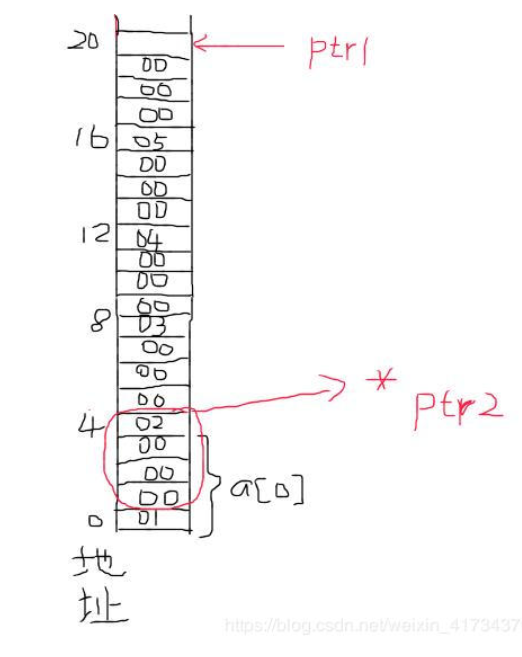
` `&a+1是整個數組長度再加1,指向20地址,而&a\[0\]+1則是指向2地址,雖然&a與&a\[0\]地址一樣,但是有著本質的不同。ptr1\[-1\]被解析成\*(ptr1-1),即ptr1往后退四字節,所以ptr1\[-1\]十六進制為5。對于C賦值語句,(int)a+1指向的地址為1,因為是低端存儲,所以\*ptr2=2000000,以上,完畢。
答案:5,2000000
- 序
- 第1章 Linux下開發FPGA
- 1.1 Linux下安裝diamond
- 1.2 使用輕量級linux仿真工具iverilog
- 1.3 使用linux shell來讀寫串口
- 1.4 嵌入式上的linux
- 設備數教程
- linux C 標準庫文檔
- linux 網絡編程
- 開機啟動流程
- 1.5 linux上實現與樹莓派,FPGA等通信的串口腳本
- 第2章 Intel FPGA的使用
- 2.1 特別注意
- 2.2 高級應用開發流程
- 2.2.1 生成二進制bit流rbf
- 2.2.2 制作Preloader Image
- 2.2.2.1 生成BSP文件
- 2.2.2.2 編譯preloader和uboot
- 2.2.2.3 更新SD的preloader和uboot
- 2.3 HPS使用
- 2.3.1 通過JTAG下載代碼
- 2.3.2 HPS軟件部分開發
- 2.3 quartus中IP核的使用
- 2.3.1 Intel中RS232串口IP的使用
- 2.4 一些問題的解決方法
- 2.4.1 關于引腳的復用的綜合出錯
- 第3章 關于C/C++的一些語法
- 3.1 C中數組作為形參不傳長度
- 3.2 匯編中JUMP和CALL的區別
- 3.3 c++中map的使用
- 3.4 鏈表的一些應用
- 3.5 vector的使用
- 3.6 使用C實現一個簡單的FIFO
- 3.6.1 循環隊列
- 3.7 C語言不定長參數
- 3.8 AD采樣計算同頻信號的相位差
- 3.9 使用C實現棧
- 3.10 增量式PID
- 第4章 Xilinx的FPGA使用
- 4.1 Alinx使用中的一些問題及解決方法
- 4.1.1 在Genarate Bitstream時提示沒有name.tcl
- 4.1.2 利用verilog求位寬
- 4.1.3 vivado中AXI寫DDR說明
- 4.1.4 zynq中AXI GPIO中斷問題
- 4.1.5 關于時序約束
- 4.1.6 zynq的PS端利用串口接收電腦的數據
- 4.1.7 SDK啟動出錯的解決方法
- 4.1.8 讓工具綜合是不優化某一模塊的方法
- 4.1.9 固化程序(雙核)
- 4.1.10 分配引腳時的問題
- 4.1.11 vivado仿真時相對文件路徑的問題
- 4.2 GCC使用Attribute分配空間給變量
- 4.3 關于Zynq的DDR寫入byte和word的方法
- 4.4 常用模塊
- 4.4.1 I2S接收串轉并
- 4.5 時鐘約束
- 4.5.1 時鐘約束
- 4.6 VIVADO使用
- 4.6.1 使用vivado進行仿真
- 4.7 關于PicoBlaze軟核的使用
- 4.8 vivado一些IP的使用
- 4.8.1 float-point浮點單元的使用
- 4.10 zynq的雙核中斷
- 第5章 FPGA的那些好用的工具
- 5.1 iverilog
- 5.2 Arduino串口繪圖器工具
- 5.3 LabVIEW
- 5.4 FPGA開發實用小工具
- 5.5 Linux下繪制時序圖軟件
- 5.6 verilog和VHDL相互轉換工具
- 5.7 linux下搭建輕量易用的verilog仿真環境
- 5.8 VCS仿真verilog并查看波形
- 5.9 Verilog開源的綜合工具-Yosys
- 5.10 sublim text3編輯器配置verilog編輯環境
- 5.11 在線工具
- 真值表 -> 邏輯表達式
- 5.12 Modelsim使用命令仿真
- 5.13 使用TCL實現的個人仿真腳本
- 5.14 在cygwin下使用命令行下載arduino代碼到開發板
- 5.15 STM32開發
- 5.15.1 安裝Atollic TrueSTUDIO for STM32
- 5.15.2 LED閃爍吧
- 5.15.3 模擬U盤
- 第6章 底層實現
- 6.1 硬件實現加法的流程
- 6.2 硬件實現乘法器
- 6.3 UART實現
- 6.3.1 通用串口發送模塊
- 6.4 二進制數轉BCD碼
- 6.5 基本開源資源
- 6.5.1 深度資源
- 6.5.2 FreeCore資源集合
- 第7章 常用模塊
- 7.1 溫濕度傳感器DHT11的verilog驅動
- 7.2 DAC7631驅動(verilog)
- 7.3 按鍵消抖
- 7.4 小腳丫數碼管顯示
- 7.5 verilog實現任意人數表決器
- 7.6 基本模塊head.v
- 7.7 四相八拍步進電機驅動
- 7.8 單片機部分
- 7.8.1 I2C OLED驅動
- 第8章 verilog 掃盲區
- 8.1 時序電路中數據的讀寫
- 8.2 從RTL角度來看verilog中=和<=的區別
- 8.3 case和casez的區別
- 8.4 關于參數的傳遞與讀取(paramter)
- 8.5 關于符號優先級
- 第9章 verilog中的一些語法使用
- 9.1 可綜合的repeat
- 第10章 system verilog
- 10.1 簡介
- 10.2 推薦demo學習網址
- 10.3 VCS在linux上環境的搭建
- 10.4 deepin15.11(linux)下搭建system verilog的vcs仿真環境
- 10.5 linux上使用vcs寫的腳本仿真管理
- 10.6 system verilog基本語法
- 10.6.1 數據類型
- 10.6.2 枚舉與字符串
- 第11章 tcl/tk的使用
- 11.1 使用Tcl/Tk
- 11.2 tcl基本語法教程
- 11.3 Tk的基本語法
- 11.3.1 建立按鈕
- 11.3.2 復選框
- 11.3.3 單選框
- 11.3.4 標簽
- 11.3.5 建立信息
- 11.3.6 建立輸入框
- 11.3.7 旋轉框
- 11.3.8 框架
- 11.3.9 標簽框架
- 11.3.10 將窗口小部件分配到框架/標簽框架
- 11.3.11 建立新的上層窗口
- 11.3.12 建立菜單
- 11.3.13 上層窗口建立菜單
- 11.3.14 建立滾動條
- 11.4 窗口管理器
- 11.5 一些學習的腳本
- 11.6 一些常用的操作語法實現
- 11.6.1 刪除同一后綴的文件
- 11.7 在Lattice的Diamond中使用tcl
- 第12章 FPGA的重要知識
- 12.1 面積與速度的平衡與互換
- 12.2 硬件原則
- 12.3 系統原則
- 12.4 同步設計原則
- 12.5 乒乓操作
- 12.6 串并轉換設計技巧
- 12.7 流水線操作設計思想
- 12.8 數據接口的同步方法
- 第13章 小項目
- 13.1 數字濾波器
- 13.2 FIFO
- 13.3 一個精簡的CPU( mini-mcu )
- 13.3.1 基本功能實現
- 13.3.2 中斷添加
- 13.3.3 使用中斷實現流水燈(實際硬件驗證)
- 13.3.4 綜合一點的應用示例
- 13.4.5 使用flex開發匯編編譯器
- 13.4.5 linux--Flex and Bison
- 13.4 有符號數轉單精度浮點數
- 13.5 串口調試FPGA模板