數據結構一向是找工作時的考點及難點,在此我們簡單以實例來簡單對HashMap及LinkHashMap進行說明。
# 前言(fei hua)
其實所有的數據結構最終都是在解決**取數**的問題,而如何能夠按照要求要**取數**,則需要有一個良好的**存數**機制,現實生活中最典型的數據結構就是我們身邊的圖書館了,圖書館那規則對圖書進行編碼,比如我們查詢某本圖書得到以下信息:
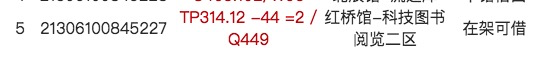
我們按此提示信息,來到紅橋管閱覽二區找到**分類號**TP314.12對應的圖書區,然后在按該索引號的**字順**逐漸的找到我們想借閱的書籍。只所以能夠按上述的規則找到相關的書籍,是由于在進行圖書上架時先對圖片進行了分類、編碼,然后按分類編碼進行了相應的存放。這其實就是一種數據結構,數據結構規定了如果存數據,同時又按存數據的規則來規定了如何取數據。
回想一下第一次去圖書館的經歷是非常痛苦的,雖然可以根據索引號來快速的獲取分類號,但TP31X的圖書真是太多了。按**字順**索引的方式,很難由TP311(程序設計、軟件工程)、TP312(程序語言、算法語言)等熱門的書籍中快速找到我們想到的那本。
# HashMap
HashMap的出現,便很好的解決當前了問題。關于HashMap的文章google一搜一大把,具體的原理層面的就是不在這里重復講了。在此,我們舉個小例子來幫助大家來理解這個HashMap。
## 情景模擬
我們假設以下情景:
* [ ] 你有90張銀行卡片,這些銀行卡片的尾號是隨機的
* [ ] 你有很多張小卡片,每張小卡片僅可記錄1個兩位數
* [ ] 你家中有100個可以存放銀行卡片的儲物格,每個儲物格均存放了一張銀行卡片和一張小卡片
* [ ] 對100個儲物格進行編號,范圍為0-99。
## 問題
你每天都需要隨機的由支付定綁定的銀行卡列表中找一張銀行卡,進而去ATM機提現,那你如何能夠快速的由儲物格中找到這張卡片。
## 解決方案
HashMap是解決方案的一種,它的解決方案大體如下:
首先,拿出10個小卡片順序排列(0-9號),并將每個儲物格內內置一張小卡片:
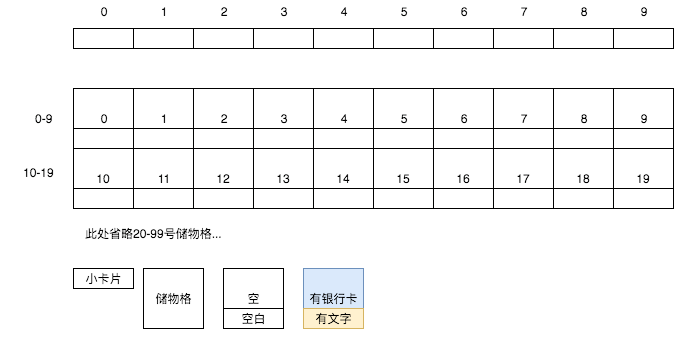
然后假設依次裝入100張銀行卡,前10張卡的卡號分別為:
```
xxxxxxxxx1025
xxxxxxxxx7842
xxxxxxxxx9863
xxxxxxxxx5625
xxxxxxxxx2324
xxxxxxxxx6532
xxxxxxxxx3699
xxxxxxxxx9845
xxxxxxxxx6242
```
### 存數據
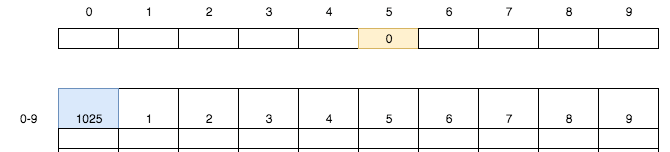
第銀行卡102`5`裝入`0`號儲物格,同時將第`5`號小卡片的值設置為`0`
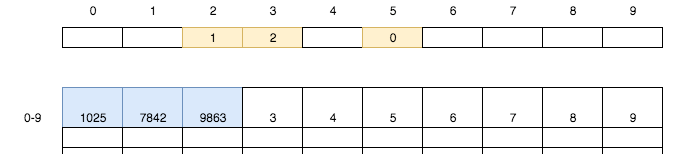
將銀行卡784`2`裝入`1`號儲物格,同時將第`2`號小卡片的值設置為`1`;將銀行卡986`3`裝入第`2`號儲物格,同時將第`3`號小卡片的值設置為`2`。
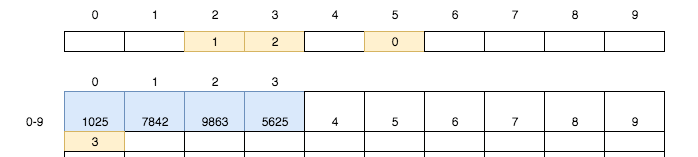
將銀行卡562`5`裝入第`3`號儲物格。同時嘗試將第`5`號小卡片的值設置為`3`:
* [ ] 1. 如果該小卡片空白,則寫入`3`,程序終止
* [ ] 2. 否則獲取小卡片上的值
* [ ] 3. 找到該值對應的儲物格中的小卡片
* [ ] 4. 重復1
所以我們獲取到了5號小卡片上的值0,來到了0號儲物格并取出其小卡片,并寫入3.
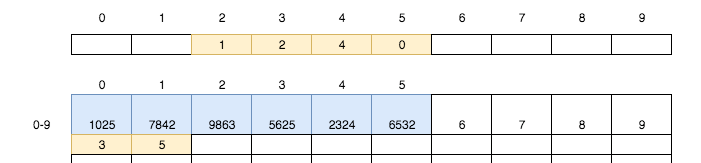
繼續按上述規則存入2324、6532兩張銀行卡:
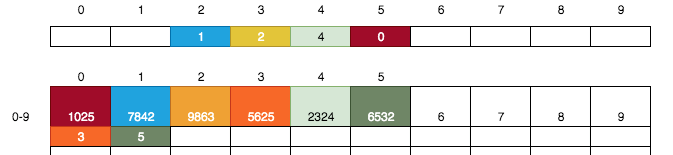
仔細的觀察上圖,我們好像發現了一個規律,那就是小卡片上記錄的文字即是儲物格的編號。如果將小卡片與儲物格用顏色進行關聯,則將得到下圖:
我們剛剛順序的存放了幾張銀行卡,其實這并不是必須的,比如我們可以將下一張3699尾號的銀行卡直接放到7號儲物格中:
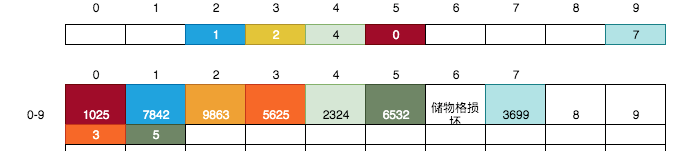
這完全沒有任何問題,我們繼續按上面的規則將9845放到第10號儲物格(假設第8,9號儲物格暫不可用)中:
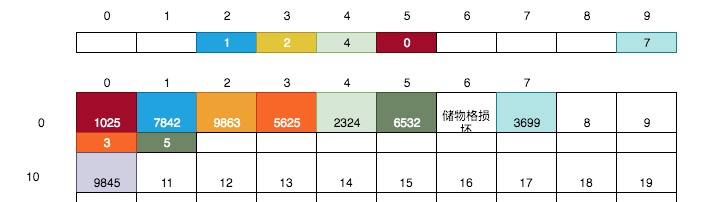
其尾號為5,則找第5號卡片,得到值0 -> 繼續找第0號儲物格,得到0號儲物格的小卡片的值3 -> 繼續找第3號儲物格, 得到該儲物格中的空白小卡片,于是將10寫入到該卡片上。

> 最后一張銀行卡,你來放吧。
### 取數據
數據存好了,取就簡單了。假設我們要取7842的銀行卡。
* 9842的尾號為2
* 找到第2號小卡片,獲取值1
* 找到1號儲物格,該銀行卡即為我們想要的9842
假設我們要找9845號銀行卡:
* 9845的尾號為5
* 找到第5號小卡,獲取值0
* 找到第0號儲物格,獲取銀行卡1025,不是我們要找的9845,則讀取該儲物盒中的小卡片的值3
* 找到第3號儲物格,獲取銀行卡5825,不是我們要找的9845,則讀取該儲物盒中的小卡片的值10
* 找到第10號儲物格,獲取銀行卡9845,返回。
假設我們要找9999號銀行卡
* 9999的尾號為9
* 找到第9號小卡,獲取值7
* 找到第7號儲物格,獲取銀行卡3699,不是我們要找的9999,則讀取該儲物盒中的小卡片的值
* 該卡片無值,表明我們未存儲尾號為9999的銀行卡,返回null
以上存銀行卡的過程,即是HaspMap的存值和取值過程,刪除數據的過程也不復雜,主要是要考慮刪除數據不能對歷史的數據查詢造成影響。比如我們想刪除1025這個銀行卡,則:
* [ ] 通過小卡片A找到該銀行卡所在的儲物格
* [ ] 獲取該儲物格的小卡片B
* [ ] 將小卡片B移到小卡片A的位置
* [ ] 清空該儲物格(移除銀行卡、放置新的小卡片)
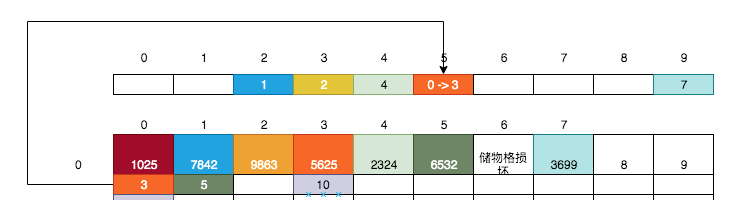
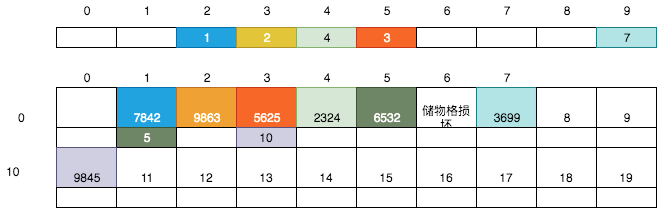
將小卡片B(數值為3)移到小卡片A(數值為0)的位置,清空0號儲物格中后:
# 圖的認讀
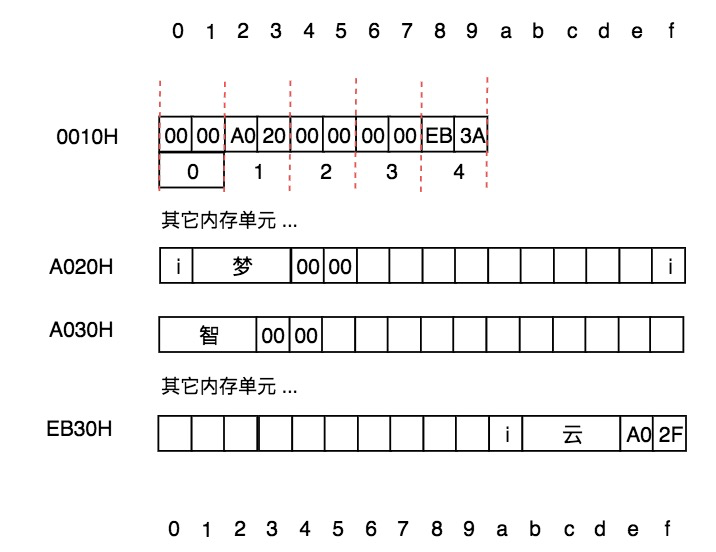
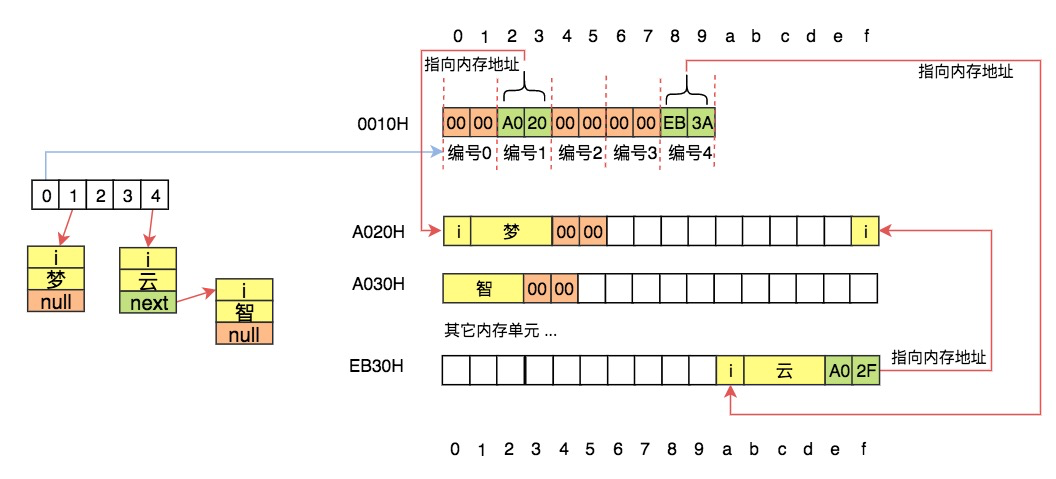
在計算機中,無論是小卡片還是儲物格,對應的都是**內存**,內存是連續的存儲空間,就像我們剛剛看到的連續的儲物格。我們常說計算機是**內存**最小的單元是位bit,每位可以存儲一個二進制0或1。對內存操作時,往往會把8位看做一個整體來進行集中操作,這是由于`位`的粒度實在是太小了,就像現實生活中我們無法購買一粒瓜子以及無法購法1ml的牛奶是一個道理。在計算機中,把8個位組成的連續存儲單元稱為1個字節,這便是內存單元的最小粒度,也是我們在學習相關的理論課時1Byte = 8bit的根本原因。前面我們學習過了字符的編碼,經查詢在UTF-8編碼中`夢`的編碼為:`0xE6 0xA2 0xA6 (e6a2a6)`;也學習過ascii編碼,經查詢`i`的編碼為`0x69`。則在內存中是如下存儲`i夢`這兩個字符的:
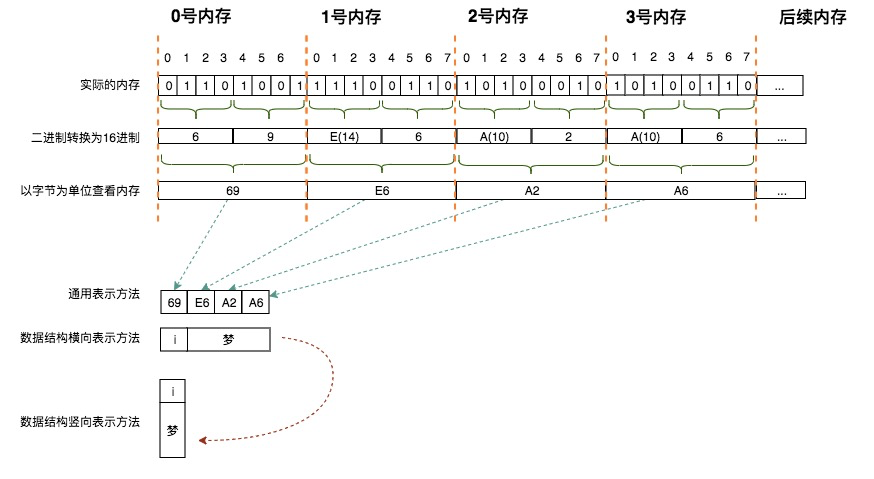
由于4個二進制(位)恰好可以用1個16進制來表示,所以為了易于交流、閱讀,我們通常會將二進制轉換為16進制。進而在一個內存單元中,便由8個二制進的位變為2個16進制的字符了。比如我們在手機中查看硬件信息(ios中請依次點擊:通用 -> 關于本機),會發現無線局域網地址、藍牙設置的信息。該信息即是用16進制來表示的二進制,比如我的手機無線局域網地址為:`80:82:D5:...`,每兩位16進制為1組,這2個16進制共同表示了一個字節的內容;在比如我們進行IP地址設置時,假設設定值為:`192.168.0.1`,中間之所以用`.`進行分離,也是由于每個分隔的數字代表了一個字節,8個二進制(1個字節)在無符號數中的取值范圍是0-255,所以當我們設置IP地址的相關參數時,最大值不會超出255,也就是16進制的FF,如果超出這個值,1個字節就放不下了,所以當我們嘗試使用大于255的值設置IP地址的相關值時,操作系統會使用自己的錯誤提醒機制來提醒我們。
我們在計算機專業課的學習過程中,常常會看到這樣表示內存:

每個內存單元均表示8個二進制數,即一個字節。在表示過程中,常用兩個16進制數來表示:

內存是連續的存儲空間,但由于印刷方便的原因,在進行一些內存展示的時候,我們無法在一行中將所有的內存單元一字排開。所以才采用了上面的展示方法,也就是說每行的最后一個內存單元與下一行的第一個內存單元實際上是鄰居:
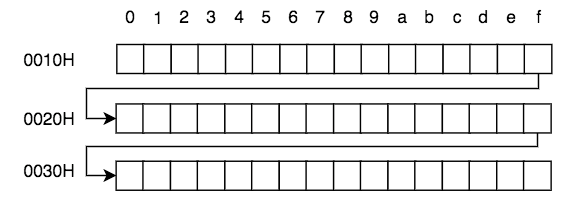
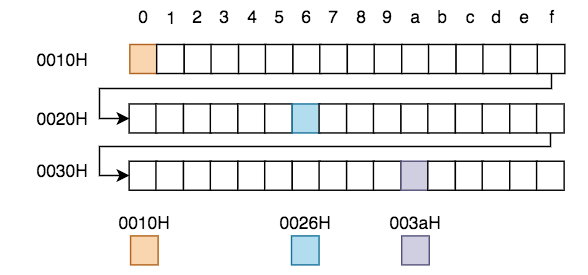
左側與上側的數字共同決定了某塊內存單元的編號,此編號的最小值為0,最大為FFFFH(16位機)或FFFF FFFFH (32位機)或FFFF FFFF FFFF FFFFH(64位機)。在各種演示及圖表中,我們更喜歡使用位數更少的16位機地址來做示例,16位機較32、64位機而言除了長度不同以外,其它的均相同。隨便找3個內存單元,他們地址如下:
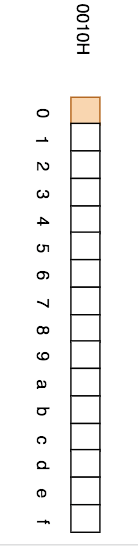
有部分圖解中,也會用豎直的方式來表示內存:
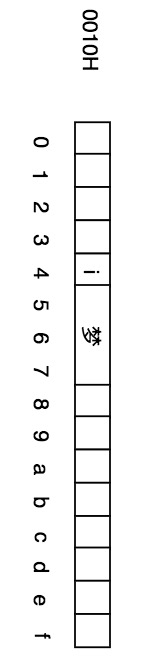
這與橫向使用完全相同,只所以豎著用也是完全出于印刷的角度。如果使用此段內存的4-7號來存儲`i夢`,則在數據結構中相應圖表中,會如下表示:
## 計算機中的HASHMAP
有了前面看圖表的基礎知識,結合google再理解hashMap就不難了,由網上找到了一張原圖如下:
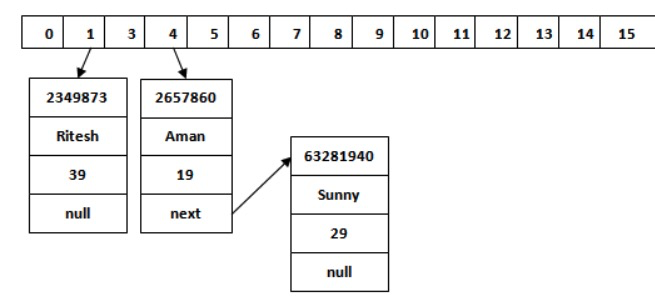
加入圖解后:
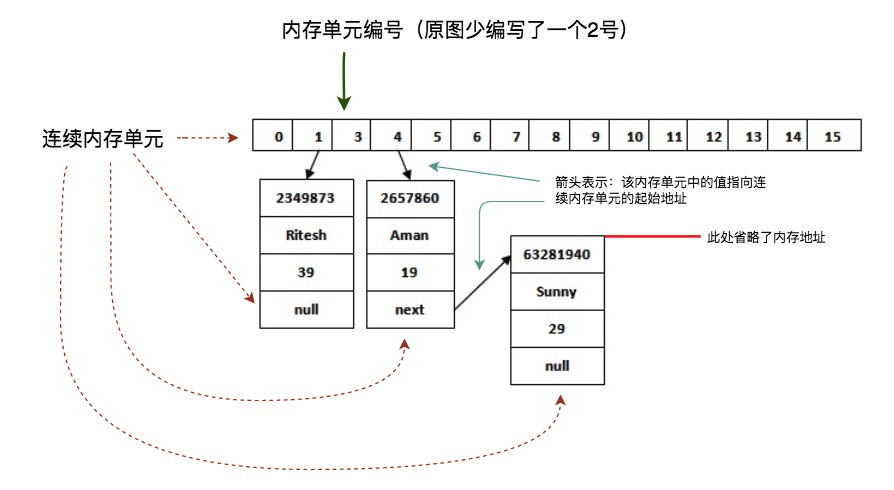
計算機的HashMap存數據與我們的在存儲格中存銀行卡大同小異,它大概經歷這么4個步驟。
* [ ] 拿出16個小卡片(連續的內存單元)
* [ ] 隨便找塊連續內存,存對象(實際上為對象的引用)以及next小卡片,并記錄該連續內存的**起始地址**。
* [ ] 獲取存入對象的hash值(JVM提供,基于內存地址),比如獲取到的值為2657860
* [ ] 使用對象的hash值與(16 - 1)相與,得到一個0 - 15之間的值,比如 `2657860?&?(16-1)?=?4`,結果為4
* [ ] 去4號卡片找值,該卡片如果無值,則將**起始地址**存入;如果有值,則按該值去找連續內存單元中的next;next無值,便存入**起始地址**,有值則繼續向下找。
我們以16位機為例,在上圖的基礎上存入`i夢`、`i云`、`i智`:
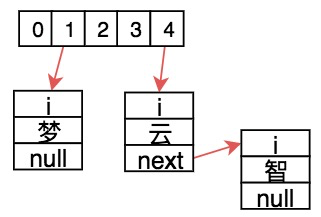
則表示實際在內存中如下進行存儲:
它們間的對應關系為:
# LinkedHashMap
LInkedHashMap結合了HashMap及雙向鏈表,它犧牲了部分查詢效率,多占用了一些內存空間,但解決了HashMap無序的特點。
> 在獲取HaspMap中的全部數據時,它輸出數據的順序并不取決于輸入數據的順序。也就是說,同是一組數據輸入HashMap,無論你的輸入順序是什么,最終循環獲取HashMap中的值時,得到的輸出順序都是一致的。
## 基礎數據結構
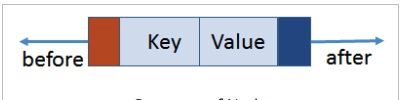
在儲物格中又增加了一張卡片來記錄上一條數據的位置。
* before 上一條數據的位置(連續內存存儲起始位置)
* key、value兩個數據項
* after 下一條數據的位置
## 第一次添加數據
`put(cbr250r, null)`,計算cbr250的hash值與15相與的值為10
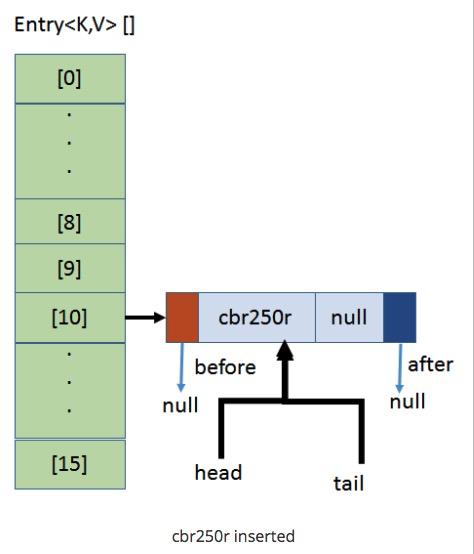
* 與HashMap相同,LinkHashMap先創建了大小為16的連續內存空間,并添加數據
* 增加了兩個屬性head與tail分別記錄頭與尾,并將這兩個屬性同時指向了該數據。
> 其實16這個數字并不準確,相對于8位機,它的大小就是16;但相對于16位機,我們則需要2個字節( 2 * 8 = 16 ) 來存儲內存地址,所以它的大小應該是`16 * 2 = 32`,然后每2個連續的內存單元來共同存儲一個內存地址;32位機則需要4個字節,64位機則需要8個字節。
## 第二次添加數據
`put(cbr1000rr, null);` ,計算cbr1000rr的hash值與15相與的值為8
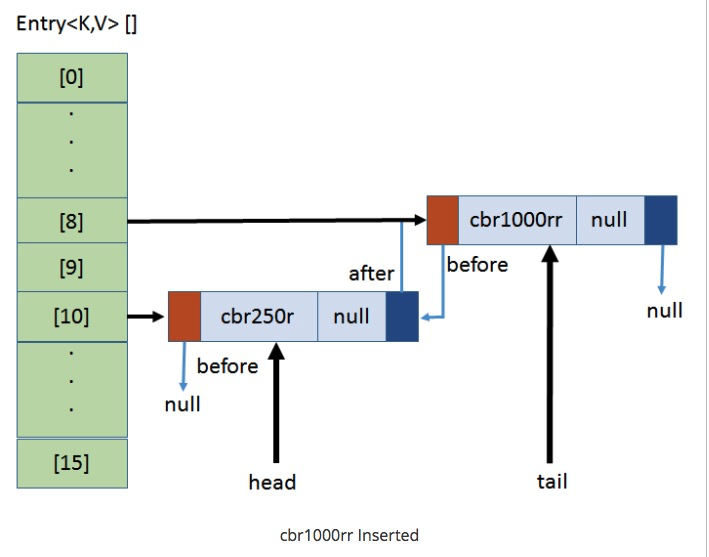
* head不變,tail指向了新的數據。同時更新原數據的after及新數據的before,達到首尾互聯的目的。
## 第三次添加數據
`put(ninja250r, null);`,計算ninja250r的hash值與15相與的值為10
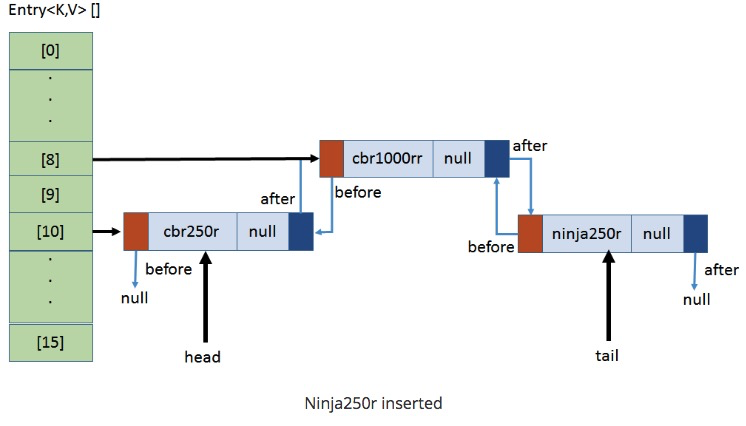
* 原10號小卡片有值,則找tail指向的數據,并將新數據的起始內存位置加入到該數據的next上。
## 第四次添加數據
`put(ninja1000rr, null);`,計算ninja1000rr的hash值與15相與的值為8
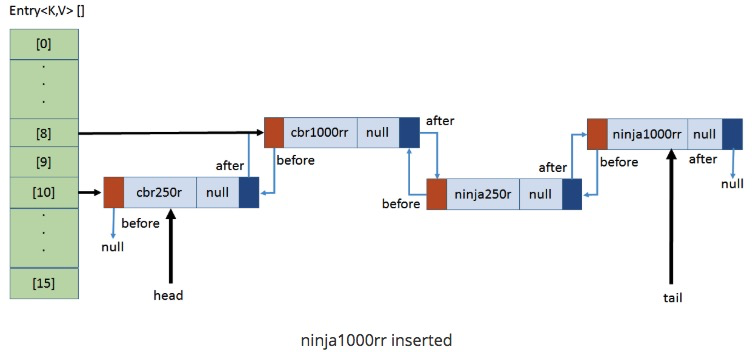
* 原8號小卡片有值,則找tail指向的數據,并將新數據的起始內存位置加入到該數據的next上。
此時,當我們需要對LinkedHashMap中的值進行便歷時,便可以由head入手,一直查到tail了,而且輸入的順序與輸入的順序保持了一致。
# 其它
以上理論均基于以下現實:
* 計算機具有非凡的計算能力,特別是進行位操作,比如`與`運算
* 計算機具有直接尋址的能力,只要你告訴它內存的編號,它便可以直接定位到該內存
# 參考文檔
| 名稱 | 鏈接 | 預計學習時長(分) |
| --- | --- | --- |
| Working of LinkedHashMap | [http://www.thejavageek.com/2016/06/05/working-linkedhashmap-java/](http://www.thejavageek.com/2016/06/05/working-linkedhashmap-java/) | - |
- 序言
- 第一章:Hello World
- 第一節:Angular準備工作
- 1 Node.js
- 2 npm
- 3 WebStorm
- 第二節:Hello Angular
- 第三節:Spring Boot準備工作
- 1 JDK
- 2 MAVEN
- 3 IDEA
- 第四節:Hello Spring Boot
- 1 Spring Initializr
- 2 Hello Spring Boot!
- 3 maven國內源配置
- 4 package與import
- 第五節:Hello Spring Boot + Angular
- 1 依賴注入【前】
- 2 HttpClient獲取數據【前】
- 3 數據綁定【前】
- 4 回調函數【選學】
- 第二章 教師管理
- 第一節 數據庫初始化
- 第二節 CRUD之R查數據
- 1 原型初始化【前】
- 2 連接數據庫【后】
- 3 使用JDBC讀取數據【后】
- 4 前后臺對接
- 5 ng-if【前】
- 6 日期管道【前】
- 第三節 CRUD之C增數據
- 1 新建組件并映射路由【前】
- 2 模板驅動表單【前】
- 3 httpClient post請求【前】
- 4 保存數據【后】
- 5 組件間調用【前】
- 第四節 CRUD之U改數據
- 1 路由參數【前】
- 2 請求映射【后】
- 3 前后臺對接【前】
- 4 更新數據【前】
- 5 更新某個教師【后】
- 6 路由器鏈接【前】
- 7 觀察者模式【前】
- 第五節 CRUD之D刪數據
- 1 綁定到用戶輸入事件【前】
- 2 刪除某個教師【后】
- 第六節 代碼重構
- 1 文件夾化【前】
- 2 優化交互體驗【前】
- 3 相對與絕對地址【前】
- 第三章 班級管理
- 第一節 JPA初始化數據表
- 第二節 班級列表
- 1 新建模塊【前】
- 2 初識單元測試【前】
- 3 初始化原型【前】
- 4 面向對象【前】
- 5 測試HTTP請求【前】
- 6 測試INPUT【前】
- 7 測試BUTTON【前】
- 8 @RequestParam【后】
- 9 Repository【后】
- 10 前后臺對接【前】
- 第三節 新增班級
- 1 初始化【前】
- 2 響應式表單【前】
- 3 測試POST請求【前】
- 4 JPA插入數據【后】
- 5 單元測試【后】
- 6 惰性加載【前】
- 7 對接【前】
- 第四節 編輯班級
- 1 FormGroup【前】
- 2 x、[x]、{{x}}與(x)【前】
- 3 模擬路由服務【前】
- 4 測試間諜spy【前】
- 5 使用JPA更新數據【后】
- 6 分層開發【后】
- 7 前后臺對接
- 8 深入imports【前】
- 9 深入exports【前】
- 第五節 選擇教師組件
- 1 初始化【前】
- 2 動態數據綁定【前】
- 3 初識泛型
- 4 @Output()【前】
- 5 @Input()【前】
- 6 再識單元測試【前】
- 7 其它問題
- 第六節 刪除班級
- 1 TDD【前】
- 2 TDD【后】
- 3 前后臺對接
- 第四章 學生管理
- 第一節 引入Bootstrap【前】
- 第二節 NAV導航組件【前】
- 1 初始化
- 2 Bootstrap格式化
- 3 RouterLinkActive
- 第三節 footer組件【前】
- 第四節 歡迎界面【前】
- 第五節 新增學生
- 1 初始化【前】
- 2 選擇班級組件【前】
- 3 復用選擇組件【前】
- 4 完善功能【前】
- 5 MVC【前】
- 6 非NULL校驗【后】
- 7 唯一性校驗【后】
- 8 @PrePersist【后】
- 9 CM層開發【后】
- 10 集成測試
- 第六節 學生列表
- 1 分頁【后】
- 2 HashMap與LinkedHashMap
- 3 初識綜合查詢【后】
- 4 綜合查詢進階【后】
- 5 小試綜合查詢【后】
- 6 初始化【前】
- 7 M層【前】
- 8 單元測試與分頁【前】
- 9 單選與多選【前】
- 10 集成測試
- 第七節 編輯學生
- 1 初始化【前】
- 2 嵌套組件測試【前】
- 3 功能開發【前】
- 4 JsonPath【后】
- 5 spyOn【后】
- 6 集成測試
- 7 @Input 異步傳值【前】
- 8 值傳遞與引入傳遞
- 9 @PreUpdate【后】
- 10 表單驗證【前】
- 第八節 刪除學生
- 1 CSS選擇器【前】
- 2 confirm【前】
- 3 功能開發與測試【后】
- 4 集成測試
- 5 定制提示框【前】
- 6 引入圖標庫【前】
- 第九節 集成測試
- 第五章 登錄與注銷
- 第一節:普通登錄
- 1 原型【前】
- 2 功能設計【前】
- 3 功能設計【后】
- 4 應用登錄組件【前】
- 5 注銷【前】
- 6 保留登錄狀態【前】
- 第二節:你是誰
- 1 過濾器【后】
- 2 令牌機制【后】
- 3 裝飾器模式【后】
- 4 攔截器【前】
- 5 RxJS操作符【前】
- 6 用戶登錄與注銷【后】
- 7 個人中心【前】
- 8 攔截器【后】
- 9 集成測試
- 10 單例模式
- 第六章 課程管理
- 第一節 新增課程
- 1 初始化【前】
- 2 嵌套組件測試【前】
- 3 async管道【前】
- 4 優雅的測試【前】
- 5 功能開發【前】
- 6 實體監聽器【后】
- 7 @ManyToMany【后】
- 8 集成測試【前】
- 9 異步驗證器【前】
- 10 詳解CORS【前】
- 第二節 課程列表
- 第三節 果斷
- 1 初始化【前】
- 2 分頁組件【前】
- 2 分頁組件【前】
- 3 綜合查詢【前】
- 4 綜合查詢【后】
- 4 綜合查詢【后】
- 第節 班級列表
- 第節 教師列表
- 第節 編輯課程
- TODO返回機制【前】
- 4 彈出框組件【前】
- 5 多路由出口【前】
- 第節 刪除課程
- 第七章 權限管理
- 第一節 AOP
- 總結
- 開發規范
- 備用