
# 使用 Keras 中的再訓練 VGG16 進行圖像分類
讓我們使用 COCO 圖像數據集來再訓練模型以微調分類任務。我們將刪除 Keras 模型中的最后一層,并添加我們自己的完全連接層,其中`softmax`激活 8 個類。我們還將通過將前 15 層的`trainable`屬性設置為`False`來演示凍結前幾層。
1. 首先導入 VGG16 模型而不使用頂層變量,方法是將`include_top`設置為`False`:
```py
# load the vgg model
from keras.applications import VGG16
base_model=VGG16(weights='imagenet',include_top=False, input_shape=(224,224,3))
```
我們還在上面的代碼中指定了`input_shape`,否則 Keras 會在以后拋出異常。
1. 現在我們構建分類器模型以置于導入的 VGG 模型之上:
```py
top_model = Sequential()
top_model.add(Flatten(input_shape=base_model.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(coco.n_classes, activation='softmax'))
```
1. 接下來,在 VGG 基礎之上添加模型:
```py
model=Model(inputs=base_model.input, outputs=top_model(base_model.output))
```
1. 凍結前 15 層:
```py
for layer in model.layers[:15]:
layer.trainable = False
```
1. 我們隨機挑選了 15 層凍結,你可能想要玩這個數字。讓我們編譯模型并打印模型摘要:
```py
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
model.summary()
```
```py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 224, 224, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
sequential_1 (Sequential) (None, 8) 6424840
=================================================================
Total params: 21,139,528
Trainable params: 13,504,264
Non-trainable params: 7,635,264
```
我們看到近 40%的參數是凍結的和不可訓練的。
1. 接下來,訓練 Keras 模型 20 個周期,批量大小為 32:
```py
from keras.utils import np_utils
batch_size=32
n_epochs=20
total_images = len(x_train_files)
n_batches = total_images // batch_size
for epoch in range(n_epochs):
print('Starting epoch ',epoch)
coco.reset_index_in_epoch()
for batch in range(n_batches):
try:
x_batch, y_batch = coco.next_batch(batch_size=batch_size)
images=np.array([coco.preprocess_image(x) for x in x_batch])
y_onehot = np_utils.to_categorical(y_batch,
num_classes=coco.n_classes)
model.fit(x=images,y=y_onehot,verbose=0)
except Exception as ex:
print('error in epoch {} batch {}'.format(epoch,batch))
print(ex)
```
1. 讓我們使用新再訓練的模型對圖像進行分類:
```py
probs = model.predict(images_test)
```
以下是分類結果:
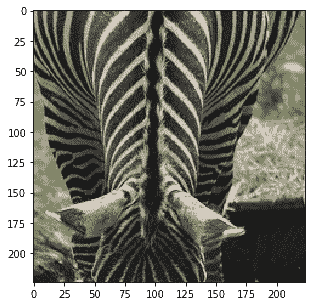
```py
Probability 100.00% of [zebra]
Probability 0.00% of [dog]
Probability 0.00% of [horse]
Probability 0.00% of [giraffe]
Probability 0.00% of [bear]
```
---
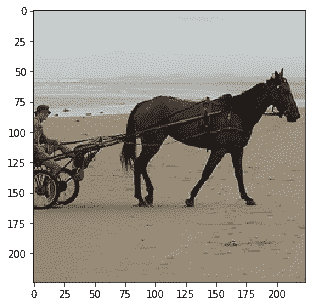
```py
Probability 96.11% of [horse]
Probability 1.85% of [cat]
Probability 0.77% of [bird]
Probability 0.43% of [giraffe]
Probability 0.40% of [sheep]
```
---
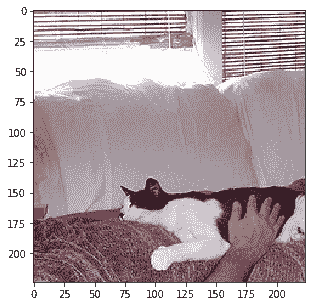
```py
Probability 99.75% of [dog] Probability 0.22% of [cat] Probability 0.03% of [horse] Probability 0.00% of [bear] Probability 0.00% of [zebra]
```
---
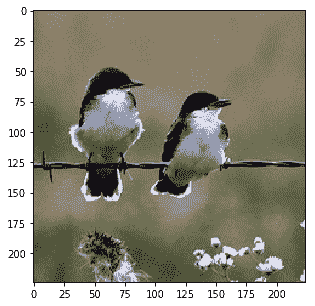
```py
Probability 99.88% of [bird]
Probability 0.11% of [horse]
Probability 0.00% of [giraffe]
Probability 0.00% of [bear]
Probability 0.00% of [cat]
```
---
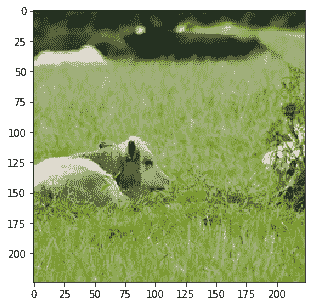
```py
Probability 65.28% of [bear]
Probability 27.09% of [sheep]
Probability 4.34% of [bird]
Probability 1.71% of [giraffe]
Probability 0.63% of [dog]
```
---
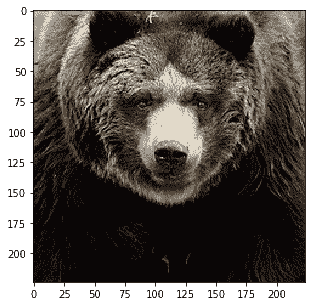
```py
Probability 100.00% of [bear]
Probability 0.00% of [sheep]
Probability 0.00% of [dog]
Probability 0.00% of [cat]
Probability 0.00% of [giraffe]
```
---
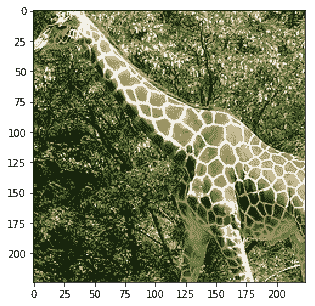
```py
Probability 100.00% of [giraffe]
Probability 0.00% of [bird]
Probability 0.00% of [bear]
Probability 0.00% of [sheep]
Probability 0.00% of [zebra]
```
---

```py
Probability 81.05% of [cat]
Probability 15.68% of [dog]
Probability 1.64% of [bird]
Probability 0.90% of [horse]
Probability 0.43% of [bear]
```
除了最后的嘈雜圖像外,所有類別都已正確識別。通過適當的超參數調整,也可以進行改進。
到目前為止,您已經看到了使用預訓練模型進行分類并對預訓練模型進行微調的示例。接下來,我們將使用 Inception v3 模型顯示分類示例。
- TensorFlow 101
- 什么是 TensorFlow?
- TensorFlow 核心
- 代碼預熱 - Hello TensorFlow
- 張量
- 常量
- 操作
- 占位符
- 從 Python 對象創建張量
- 變量
- 從庫函數生成的張量
- 使用相同的值填充張量元素
- 用序列填充張量元素
- 使用隨機分布填充張量元素
- 使用tf.get_variable()獲取變量
- 數據流圖或計算圖
- 執行順序和延遲加載
- 跨計算設備執行圖 - CPU 和 GPU
- 將圖節點放置在特定的計算設備上
- 簡單放置
- 動態展示位置
- 軟放置
- GPU 內存處理
- 多個圖
- TensorBoard
- TensorBoard 最小的例子
- TensorBoard 詳情
- 總結
- TensorFlow 的高級庫
- TF Estimator - 以前的 TF 學習
- TF Slim
- TFLearn
- 創建 TFLearn 層
- TFLearn 核心層
- TFLearn 卷積層
- TFLearn 循環層
- TFLearn 正則化層
- TFLearn 嵌入層
- TFLearn 合并層
- TFLearn 估計層
- 創建 TFLearn 模型
- TFLearn 模型的類型
- 訓練 TFLearn 模型
- 使用 TFLearn 模型
- PrettyTensor
- Sonnet
- 總結
- Keras 101
- 安裝 Keras
- Keras 中的神經網絡模型
- 在 Keras 建立模型的工作流程
- 創建 Keras 模型
- 用于創建 Keras 模型的順序 API
- 用于創建 Keras 模型的函數式 API
- Keras 層
- Keras 核心層
- Keras 卷積層
- Keras 池化層
- Keras 本地連接層
- Keras 循環層
- Keras 嵌入層
- Keras 合并層
- Keras 高級激活層
- Keras 正則化層
- Keras 噪音層
- 將層添加到 Keras 模型
- 用于將層添加到 Keras 模型的順序 API
- 用于向 Keras 模型添加層的函數式 API
- 編譯 Keras 模型
- 訓練 Keras 模型
- 使用 Keras 模型進行預測
- Keras 的附加模塊
- MNIST 數據集的 Keras 序列模型示例
- 總結
- 使用 TensorFlow 進行經典機器學習
- 簡單的線性回歸
- 數據準備
- 構建一個簡單的回歸模型
- 定義輸入,參數和其他變量
- 定義模型
- 定義損失函數
- 定義優化器函數
- 訓練模型
- 使用訓練的模型進行預測
- 多元回歸
- 正則化回歸
- 套索正則化
- 嶺正則化
- ElasticNet 正則化
- 使用邏輯回歸進行分類
- 二分類的邏輯回歸
- 多類分類的邏輯回歸
- 二分類
- 多類分類
- 總結
- 使用 TensorFlow 和 Keras 的神經網絡和 MLP
- 感知機
- 多層感知機
- 用于圖像分類的 MLP
- 用于 MNIST 分類的基于 TensorFlow 的 MLP
- 用于 MNIST 分類的基于 Keras 的 MLP
- 用于 MNIST 分類的基于 TFLearn 的 MLP
- 使用 TensorFlow,Keras 和 TFLearn 的 MLP 總結
- 用于時間序列回歸的 MLP
- 總結
- 使用 TensorFlow 和 Keras 的 RNN
- 簡單循環神經網絡
- RNN 變種
- LSTM 網絡
- GRU 網絡
- TensorFlow RNN
- TensorFlow RNN 單元類
- TensorFlow RNN 模型構建類
- TensorFlow RNN 單元包裝器類
- 適用于 RNN 的 Keras
- RNN 的應用領域
- 用于 MNIST 數據的 Keras 中的 RNN
- 總結
- 使用 TensorFlow 和 Keras 的時間序列數據的 RNN
- 航空公司乘客數據集
- 加載 airpass 數據集
- 可視化 airpass 數據集
- 使用 TensorFlow RNN 模型預處理數據集
- TensorFlow 中的簡單 RNN
- TensorFlow 中的 LSTM
- TensorFlow 中的 GRU
- 使用 Keras RNN 模型預處理數據集
- 使用 Keras 的簡單 RNN
- 使用 Keras 的 LSTM
- 使用 Keras 的 GRU
- 總結
- 使用 TensorFlow 和 Keras 的文本數據的 RNN
- 詞向量表示
- 為 word2vec 模型準備數據
- 加載和準備 PTB 數據集
- 加載和準備 text8 數據集
- 準備小驗證集
- 使用 TensorFlow 的 skip-gram 模型
- 使用 t-SNE 可視化單詞嵌入
- keras 的 skip-gram 模型
- 使用 TensorFlow 和 Keras 中的 RNN 模型生成文本
- TensorFlow 中的 LSTM 文本生成
- Keras 中的 LSTM 文本生成
- 總結
- 使用 TensorFlow 和 Keras 的 CNN
- 理解卷積
- 了解池化
- CNN 架構模式 - LeNet
- 用于 MNIST 數據的 LeNet
- 使用 TensorFlow 的用于 MNIST 的 LeNet CNN
- 使用 Keras 的用于 MNIST 的 LeNet CNN
- 用于 CIFAR10 數據的 LeNet
- 使用 TensorFlow 的用于 CIFAR10 的 ConvNets
- 使用 Keras 的用于 CIFAR10 的 ConvNets
- 總結
- 使用 TensorFlow 和 Keras 的自編碼器
- 自編碼器類型
- TensorFlow 中的棧式自編碼器
- Keras 中的棧式自編碼器
- TensorFlow 中的去噪自編碼器
- Keras 中的去噪自編碼器
- TensorFlow 中的變分自編碼器
- Keras 中的變分自編碼器
- 總結
- TF 服務:生產中的 TensorFlow 模型
- 在 TensorFlow 中保存和恢復模型
- 使用保護程序類保存和恢復所有圖變量
- 使用保護程序類保存和恢復所選變量
- 保存和恢復 Keras 模型
- TensorFlow 服務
- 安裝 TF 服務
- 保存 TF 服務的模型
- 提供 TF 服務模型
- 在 Docker 容器中提供 TF 服務
- 安裝 Docker
- 為 TF 服務構建 Docker 鏡像
- 在 Docker 容器中提供模型
- Kubernetes 中的 TensorFlow 服務
- 安裝 Kubernetes
- 將 Docker 鏡像上傳到 dockerhub
- 在 Kubernetes 部署
- 總結
- 遷移學習和預訓練模型
- ImageNet 數據集
- 再訓練或微調模型
- COCO 動物數據集和預處理圖像
- TensorFlow 中的 VGG16
- 使用 TensorFlow 中預訓練的 VGG16 進行圖像分類
- TensorFlow 中的圖像預處理,用于預訓練的 VGG16
- 使用 TensorFlow 中的再訓練的 VGG16 進行圖像分類
- Keras 的 VGG16
- 使用 Keras 中預訓練的 VGG16 進行圖像分類
- 使用 Keras 中再訓練的 VGG16 進行圖像分類
- TensorFlow 中的 Inception v3
- 使用 TensorFlow 中的 Inception v3 進行圖像分類
- 使用 TensorFlow 中的再訓練的 Inception v3 進行圖像分類
- 總結
- 深度強化學習
- OpenAI Gym 101
- 將簡單的策略應用于 cartpole 游戲
- 強化學習 101
- Q 函數(在模型不可用時學習優化)
- RL 算法的探索與開發
- V 函數(模型可用時學習優化)
- 強化學習技巧
- 強化學習的樸素神經網絡策略
- 實現 Q-Learning
- Q-Learning 的初始化和離散化
- 使用 Q-Table 進行 Q-Learning
- Q-Network 或深 Q 網絡(DQN)的 Q-Learning
- 總結
- 生成性對抗網絡
- 生成性對抗網絡 101
- 建立和訓練 GAN 的最佳實踐
- 使用 TensorFlow 的簡單的 GAN
- 使用 Keras 的簡單的 GAN
- 使用 TensorFlow 和 Keras 的深度卷積 GAN
- 總結
- 使用 TensorFlow 集群的分布式模型
- 分布式執行策略
- TensorFlow 集群
- 定義集群規范
- 創建服務器實例
- 定義服務器和設備之間的參數和操作
- 定義并訓練圖以進行異步更新
- 定義并訓練圖以進行同步更新
- 總結
- 移動和嵌入式平臺上的 TensorFlow 模型
- 移動平臺上的 TensorFlow
- Android 應用中的 TF Mobile
- Android 上的 TF Mobile 演示
- iOS 應用中的 TF Mobile
- iOS 上的 TF Mobile 演示
- TensorFlow Lite
- Android 上的 TF Lite 演示
- iOS 上的 TF Lite 演示
- 總結
- R 中的 TensorFlow 和 Keras
- 在 R 中安裝 TensorFlow 和 Keras 軟件包
- R 中的 TF 核心 API
- R 中的 TF 估計器 API
- R 中的 Keras API
- R 中的 TensorBoard
- R 中的 tfruns 包
- 總結
- 調試 TensorFlow 模型
- 使用tf.Session.run()獲取張量值
- 使用tf.Print()打印張量值
- 用tf.Assert()斷言條件
- 使用 TensorFlow 調試器(tfdbg)進行調試
- 總結
- 張量處理單元