
# 定義并訓練圖以進行異步更新
如前所述,并在此處的圖中顯示,在異步更新中,所有工作任務在準備就緒時發送參數更新,參數服務器更新參數并發回參數。參數更新沒有同步或等待或聚合:
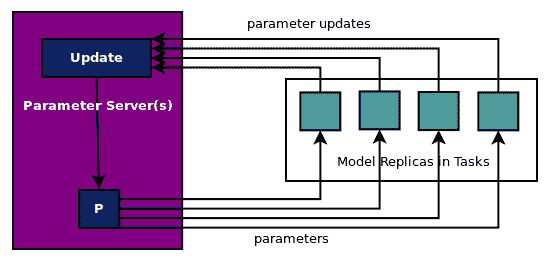The full code for this example is in?`ch-15_mnist_dist_async.py`. You are encouraged to modify and explore the code with your own datasets.
對于異步更新,將使用以下步驟創建和訓練圖:
1. 圖的定義在`with`塊內完成:
```py
with tf.device(device_func):
```
1. 使用內置的 TensorFlow 函數創建全局步驟變量:
```py
global_step = tf.train.get_or_create_global_step()
```
1. 此變量也可以定義為:
```py
tf.Variable(0,name='global_step',trainable=False)
```
1. 像往常一樣定義數據集,參數和超參數:
```py
x_test = mnist.test.images
y_test = mnist.test.labels
n_outputs = 10 # 0-9 digits
n_inputs = 784 # total pixels
learning_rate = 0.01
n_epochs = 50
batch_size = 100
n_batches = int(mnist.train.num_examples/batch_size)
n_epochs_print=10
```
1. 像往常一樣定義占位符,權重,偏差,logits,交叉熵,損失操作,訓練操作,準確率:
```py
# input images
x_p = tf.placeholder(dtype=tf.float32,
name='x_p',
shape=[None, n_inputs])
# target output
y_p = tf.placeholder(dtype=tf.float32,
name='y_p',
shape=[None, n_outputs])
w = tf.Variable(tf.random_normal([n_inputs, n_outputs],
name='w'
)
)
b = tf.Variable(tf.random_normal([n_outputs],
name='b'
)
)
logits = tf.matmul(x_p,w) + b
entropy_op = tf.nn.softmax_cross_entropy_with_logits(labels=y_p,
logits=logits
)
loss_op = tf.reduce_mean(entropy_op)
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
train_op = optimizer.minimize(loss_op,global_step=global_step)
correct_pred = tf.equal(tf.argmax(logits, 1), tf.argmax(y_p, 1))
accuracy_op = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
```
當我們學習如何構建同步更新時,這些定義將會改變。
1. TensorFlow 提供了一個主管類,可以幫助創建訓練會話,在分布式訓練設置中非常有用。創建一個 supervisor 對象,如下所示:
```py
init_op = tf.global_variables_initializer
sv = tf.train.Supervisor(is_chief=is_chief,
init_op = init_op(),
global_step=global_step)
```
1. 使用 supervisor 對象創建會話并像往常一樣在此會話塊下運行訓練:
```py
with sv.prepare_or_wait_for_session(server.target) as mts:
lstep = 0
for epoch in range(n_epochs):
for batch in range(n_batches):
x_batch, y_batch = mnist.train.next_batch(batch_size)
feed_dict={x_p:x_batch,y_p:y_batch}
_,loss,gstep=mts.run([train_op,loss_op,global_step],
feed_dict=feed_dict)
lstep +=1
if (epoch+1)%n_epochs_print==0:
print('worker={},epoch={},global_step={}, \
local_step={},loss={}'.
format(FLAGS.task_index,epoch,gstep,lstep,loss))
feed_dict={x_p:x_test,y_p:y_test}
accuracy = mts.run(accuracy_op, feed_dict=feed_dict)
print('worker={}, final accuracy = {}'
.format(FLAGS.task_index,accuracy))
```
在啟動參數服務器時,我們得到以下輸出:
```py
$ python3 ch-15_mnist_dist_async.py --job_name='ps' --task_index=**0**
I tensorflow/core/common_runtime/gpu/gpu_device.cc:1030] Found device 0 with properties:
name: Quadro P5000 major: 6 minor: 1 memoryClockRate(GHz): 1.506
pciBusID: 0000:01:00.0
totalMemory: 15.89GiB freeMemory: 15.79GiB
I tensorflow/core/common_runtime/gpu/gpu_device.cc:1120] Creating TensorFlow device (/device:GPU:0) -> (device: 0, name: Quadro P5000, pci bus id: 0000:01:00.0, compute capability: 6.1)
E1213 16:50:14.023235178 27224 ev_epoll1_linux.c:1051] grpc epoll fd: 23
I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize GrpcChannelCache for job ps -> {0 -> localhost:9001}
I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize GrpcChannelCache for job worker -> {0 -> localhost:9002, 1 -> localhost:9003, 2 -> localhost:9004}
I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:324] Started server with target: grpc://localhost:9001
```
在啟動工作任務時,我們得到以下三個輸出:
工作器 1 的輸出:
```py
$ python3 ch-15_mnist_dist_async.py --job_name='worker' --task_index=**0**
I tensorflow/core/common_runtime/gpu/gpu_device.cc:1030] Found device 0 with properties:
name: Quadro P5000 major: 6 minor: 1 memoryClockRate(GHz): 1.506
pciBusID: 0000:01:00.0
totalMemory: 15.89GiB freeMemory: 9.16GiB
I tensorflow/core/common_runtime/gpu/gpu_device.cc:1120] Creating TensorFlow device (/device:GPU:0) -> (device: 0, name: Quadro P5000, pci bus id: 0000:01:00.0, compute capability: 6.1)
E1213 16:50:37.516609689 27507 ev_epoll1_linux.c:1051] grpc epoll fd: 23
I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize GrpcChannelCache for job ps -> {0 -> localhost:9001}
I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize GrpcChannelCache for job worker -> {0 -> localhost:9002, 1 -> localhost:9003, 2 -> localhost:9004}
I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:324] Started server with target: grpc://localhost:9002
I tensorflow/core/distributed_runtime/master_session.cc:1004] Start master session 1421824c3df413b5 with config: gpu_options { per_process_gpu_memory_fraction: 0.2 } allow_soft_placement: true
worker=0,epoch=9,global_step=10896, local_step=5500, loss = 1.2575616836547852
worker=0,epoch=19,global_step=22453, local_step=11000, loss = 0.7158586382865906
worker=0,epoch=29,global_step=39019, local_step=16500, loss = 0.43712112307548523
worker=0,epoch=39,global_step=55513, local_step=22000, loss = 0.3935799300670624
worker=0,epoch=49,global_step=72002, local_step=27500, loss = 0.3877961337566376
worker=0, final accuracy = 0.8865000009536743
```
工作器 2 的輸出:
```py
$ python3 ch-15_mnist_dist_async.py --job_name='worker' --task_index=**1**
I tensorflow/core/common_runtime/gpu/gpu_device.cc:1030] Found device 0 with properties:
name: Quadro P5000 major: 6 minor: 1 memoryClockRate(GHz): 1.506
pciBusID: 0000:01:00.0
totalMemory: 15.89GiB freeMemory: 12.43GiB
I tensorflow/core/common_runtime/gpu/gpu_device.cc:1120] Creating TensorFlow device (/device:GPU:0) -> (device: 0, name: Quadro P5000, pci bus id: 0000:01:00.0, compute capability: 6.1)
E1213 16:50:36.684334877 27461 ev_epoll1_linux.c:1051] grpc epoll fd: 23
I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize GrpcChannelCache for job ps -> {0 -> localhost:9001}
I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize GrpcChannelCache for job worker -> {0 -> localhost:9002, 1 -> localhost:9003, 2 -> localhost:9004}
I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:324] Started server with target: grpc://localhost:9003
I tensorflow/core/distributed_runtime/master_session.cc:1004] Start master session 2bd8a136213a1fce with config: gpu_options { per_process_gpu_memory_fraction: 0.2 } allow_soft_placement: true
worker=1,epoch=9,global_step=11085, local_step=5500, loss = 0.6955764889717102
worker=1,epoch=19,global_step=22728, local_step=11000, loss = 0.5891970992088318
worker=1,epoch=29,global_step=39074, local_step=16500, loss = 0.4183048903942108
worker=1,epoch=39,global_step=55599, local_step=22000, loss = 0.32243454456329346
worker=1,epoch=49,global_step=72105, local_step=27500, loss = 0.5384714007377625
worker=1, final accuracy = 0.8866000175476074
```
工作器 3 的輸出:
```py
$ python3 ch-15_mnist_dist_async.py --job_name='worker' --task_index=**2**
I tensorflow/core/common_runtime/gpu/gpu_device.cc:1030] Found device 0 with properties:
name: Quadro P5000 major: 6 minor: 1 memoryClockRate(GHz): 1.506
pciBusID: 0000:01:00.0
totalMemory: 15.89GiB freeMemory: 15.70GiB
I tensorflow/core/common_runtime/gpu/gpu_device.cc:1120] Creating TensorFlow device (/device:GPU:0) -> (device: 0, name: Quadro P5000, pci bus id: 0000:01:00.0, compute capability: 6.1)
E1213 16:50:35.568349791 27449 ev_epoll1_linux.c:1051] grpc epoll fd: 23
I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize GrpcChannelCache for job ps -> {0 -> localhost:9001}
I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize GrpcChannelCache for job worker -> {0 -> localhost:9002, 1 -> localhost:9003, 2 -> localhost:9004}
I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:324] Started server with target: grpc://The full code for this example is in ch-15_mnist_dist_sync.py. You are encouraged to modify and explore the code with your own datasets.localhost:9004
I tensorflow/core/distributed_runtime/master_session.cc:1004] Start master session cb0749c9f5fc163e with config: gpu_options { per_process_gpu_memory_fraction: 0.2 } allow_soft_placement: true
I tensorflow/core/distributed_runtime/master_session.cc:1004] Start master session 55bf9a2b9718a571 with config: gpu_options { per_process_gpu_memory_fraction: 0.2 } allow_soft_placement: true
worker=2,epoch=9,global_step=37367, local_step=5500, loss = 0.8077645301818848
worker=2,epoch=19,global_step=53859, local_step=11000, loss = 0.26333487033843994
worker=2,epoch=29,global_step=70299, local_step=16500, loss = 0.6506651043891907
worker=2,epoch=39,global_step=76999, local_step=22000, loss = 0.20321622490882874
worker=2,epoch=49,global_step=82499, local_step=27500, loss = 0.4170967936515808
worker=2, final accuracy = 0.8894000053405762
```
我們打印了全球步驟和本地步驟。全局步驟表示所有工作器任務的步數,而本地步驟是該工作器任務中的計數,這就是為什么本地任務計數高達 27,500 并且每個工作器的每個周期都相同,但是因為工作器正在做按照自己的步伐采取全球性措施,全球步驟的數量在周期或工作器之間沒有對稱性或模式。此外,我們發現每個工作器的最終準確率是不同的,因為每個工作器在不同的時間執行最終的準確性,當時有不同的參數。
- TensorFlow 101
- 什么是 TensorFlow?
- TensorFlow 核心
- 代碼預熱 - Hello TensorFlow
- 張量
- 常量
- 操作
- 占位符
- 從 Python 對象創建張量
- 變量
- 從庫函數生成的張量
- 使用相同的值填充張量元素
- 用序列填充張量元素
- 使用隨機分布填充張量元素
- 使用tf.get_variable()獲取變量
- 數據流圖或計算圖
- 執行順序和延遲加載
- 跨計算設備執行圖 - CPU 和 GPU
- 將圖節點放置在特定的計算設備上
- 簡單放置
- 動態展示位置
- 軟放置
- GPU 內存處理
- 多個圖
- TensorBoard
- TensorBoard 最小的例子
- TensorBoard 詳情
- 總結
- TensorFlow 的高級庫
- TF Estimator - 以前的 TF 學習
- TF Slim
- TFLearn
- 創建 TFLearn 層
- TFLearn 核心層
- TFLearn 卷積層
- TFLearn 循環層
- TFLearn 正則化層
- TFLearn 嵌入層
- TFLearn 合并層
- TFLearn 估計層
- 創建 TFLearn 模型
- TFLearn 模型的類型
- 訓練 TFLearn 模型
- 使用 TFLearn 模型
- PrettyTensor
- Sonnet
- 總結
- Keras 101
- 安裝 Keras
- Keras 中的神經網絡模型
- 在 Keras 建立模型的工作流程
- 創建 Keras 模型
- 用于創建 Keras 模型的順序 API
- 用于創建 Keras 模型的函數式 API
- Keras 層
- Keras 核心層
- Keras 卷積層
- Keras 池化層
- Keras 本地連接層
- Keras 循環層
- Keras 嵌入層
- Keras 合并層
- Keras 高級激活層
- Keras 正則化層
- Keras 噪音層
- 將層添加到 Keras 模型
- 用于將層添加到 Keras 模型的順序 API
- 用于向 Keras 模型添加層的函數式 API
- 編譯 Keras 模型
- 訓練 Keras 模型
- 使用 Keras 模型進行預測
- Keras 的附加模塊
- MNIST 數據集的 Keras 序列模型示例
- 總結
- 使用 TensorFlow 進行經典機器學習
- 簡單的線性回歸
- 數據準備
- 構建一個簡單的回歸模型
- 定義輸入,參數和其他變量
- 定義模型
- 定義損失函數
- 定義優化器函數
- 訓練模型
- 使用訓練的模型進行預測
- 多元回歸
- 正則化回歸
- 套索正則化
- 嶺正則化
- ElasticNet 正則化
- 使用邏輯回歸進行分類
- 二分類的邏輯回歸
- 多類分類的邏輯回歸
- 二分類
- 多類分類
- 總結
- 使用 TensorFlow 和 Keras 的神經網絡和 MLP
- 感知機
- 多層感知機
- 用于圖像分類的 MLP
- 用于 MNIST 分類的基于 TensorFlow 的 MLP
- 用于 MNIST 分類的基于 Keras 的 MLP
- 用于 MNIST 分類的基于 TFLearn 的 MLP
- 使用 TensorFlow,Keras 和 TFLearn 的 MLP 總結
- 用于時間序列回歸的 MLP
- 總結
- 使用 TensorFlow 和 Keras 的 RNN
- 簡單循環神經網絡
- RNN 變種
- LSTM 網絡
- GRU 網絡
- TensorFlow RNN
- TensorFlow RNN 單元類
- TensorFlow RNN 模型構建類
- TensorFlow RNN 單元包裝器類
- 適用于 RNN 的 Keras
- RNN 的應用領域
- 用于 MNIST 數據的 Keras 中的 RNN
- 總結
- 使用 TensorFlow 和 Keras 的時間序列數據的 RNN
- 航空公司乘客數據集
- 加載 airpass 數據集
- 可視化 airpass 數據集
- 使用 TensorFlow RNN 模型預處理數據集
- TensorFlow 中的簡單 RNN
- TensorFlow 中的 LSTM
- TensorFlow 中的 GRU
- 使用 Keras RNN 模型預處理數據集
- 使用 Keras 的簡單 RNN
- 使用 Keras 的 LSTM
- 使用 Keras 的 GRU
- 總結
- 使用 TensorFlow 和 Keras 的文本數據的 RNN
- 詞向量表示
- 為 word2vec 模型準備數據
- 加載和準備 PTB 數據集
- 加載和準備 text8 數據集
- 準備小驗證集
- 使用 TensorFlow 的 skip-gram 模型
- 使用 t-SNE 可視化單詞嵌入
- keras 的 skip-gram 模型
- 使用 TensorFlow 和 Keras 中的 RNN 模型生成文本
- TensorFlow 中的 LSTM 文本生成
- Keras 中的 LSTM 文本生成
- 總結
- 使用 TensorFlow 和 Keras 的 CNN
- 理解卷積
- 了解池化
- CNN 架構模式 - LeNet
- 用于 MNIST 數據的 LeNet
- 使用 TensorFlow 的用于 MNIST 的 LeNet CNN
- 使用 Keras 的用于 MNIST 的 LeNet CNN
- 用于 CIFAR10 數據的 LeNet
- 使用 TensorFlow 的用于 CIFAR10 的 ConvNets
- 使用 Keras 的用于 CIFAR10 的 ConvNets
- 總結
- 使用 TensorFlow 和 Keras 的自編碼器
- 自編碼器類型
- TensorFlow 中的棧式自編碼器
- Keras 中的棧式自編碼器
- TensorFlow 中的去噪自編碼器
- Keras 中的去噪自編碼器
- TensorFlow 中的變分自編碼器
- Keras 中的變分自編碼器
- 總結
- TF 服務:生產中的 TensorFlow 模型
- 在 TensorFlow 中保存和恢復模型
- 使用保護程序類保存和恢復所有圖變量
- 使用保護程序類保存和恢復所選變量
- 保存和恢復 Keras 模型
- TensorFlow 服務
- 安裝 TF 服務
- 保存 TF 服務的模型
- 提供 TF 服務模型
- 在 Docker 容器中提供 TF 服務
- 安裝 Docker
- 為 TF 服務構建 Docker 鏡像
- 在 Docker 容器中提供模型
- Kubernetes 中的 TensorFlow 服務
- 安裝 Kubernetes
- 將 Docker 鏡像上傳到 dockerhub
- 在 Kubernetes 部署
- 總結
- 遷移學習和預訓練模型
- ImageNet 數據集
- 再訓練或微調模型
- COCO 動物數據集和預處理圖像
- TensorFlow 中的 VGG16
- 使用 TensorFlow 中預訓練的 VGG16 進行圖像分類
- TensorFlow 中的圖像預處理,用于預訓練的 VGG16
- 使用 TensorFlow 中的再訓練的 VGG16 進行圖像分類
- Keras 的 VGG16
- 使用 Keras 中預訓練的 VGG16 進行圖像分類
- 使用 Keras 中再訓練的 VGG16 進行圖像分類
- TensorFlow 中的 Inception v3
- 使用 TensorFlow 中的 Inception v3 進行圖像分類
- 使用 TensorFlow 中的再訓練的 Inception v3 進行圖像分類
- 總結
- 深度強化學習
- OpenAI Gym 101
- 將簡單的策略應用于 cartpole 游戲
- 強化學習 101
- Q 函數(在模型不可用時學習優化)
- RL 算法的探索與開發
- V 函數(模型可用時學習優化)
- 強化學習技巧
- 強化學習的樸素神經網絡策略
- 實現 Q-Learning
- Q-Learning 的初始化和離散化
- 使用 Q-Table 進行 Q-Learning
- Q-Network 或深 Q 網絡(DQN)的 Q-Learning
- 總結
- 生成性對抗網絡
- 生成性對抗網絡 101
- 建立和訓練 GAN 的最佳實踐
- 使用 TensorFlow 的簡單的 GAN
- 使用 Keras 的簡單的 GAN
- 使用 TensorFlow 和 Keras 的深度卷積 GAN
- 總結
- 使用 TensorFlow 集群的分布式模型
- 分布式執行策略
- TensorFlow 集群
- 定義集群規范
- 創建服務器實例
- 定義服務器和設備之間的參數和操作
- 定義并訓練圖以進行異步更新
- 定義并訓練圖以進行同步更新
- 總結
- 移動和嵌入式平臺上的 TensorFlow 模型
- 移動平臺上的 TensorFlow
- Android 應用中的 TF Mobile
- Android 上的 TF Mobile 演示
- iOS 應用中的 TF Mobile
- iOS 上的 TF Mobile 演示
- TensorFlow Lite
- Android 上的 TF Lite 演示
- iOS 上的 TF Lite 演示
- 總結
- R 中的 TensorFlow 和 Keras
- 在 R 中安裝 TensorFlow 和 Keras 軟件包
- R 中的 TF 核心 API
- R 中的 TF 估計器 API
- R 中的 Keras API
- R 中的 TensorBoard
- R 中的 tfruns 包
- 總結
- 調試 TensorFlow 模型
- 使用tf.Session.run()獲取張量值
- 使用tf.Print()打印張量值
- 用tf.Assert()斷言條件
- 使用 TensorFlow 調試器(tfdbg)進行調試
- 總結
- 張量處理單元