
## 4.2 使用表格匯總數據
總結數據的一個簡單方法是生成一個表,表示各種類型觀測的計數。這種類型的表已經使用了數千年(見圖[4.1](#fig:salesContract))。

圖 4.1 盧浮宮的蘇美爾平板電腦,顯示房屋和田地的銷售合同。公共領域,通過維基共享資源。
讓我們來看一些使用表的例子,同樣使用 nhanes 數據集。在 rstudio 控制臺中鍵入命令`help(NHANES)`,然后滾動查看幫助頁面,如果使用 rstudio,該頁面將在幫助面板中打開。此頁提供有關數據集的一些信息以及數據集中包含的所有變量的列表。讓我們來看一個簡單的變量,在數據集中稱為“physactive”。此變量包含三個不同值中的一個:“是”或“否”(指示此人是否報告正在進行“中等強度或劇烈強度的運動、健身或娛樂活動”),如果該個人缺少數據,則為“不”。有不同的原因導致數據丟失;例如,這一問題不是針對 12 歲以下的兒童提出的,而在其他情況下,成人可能在采訪期間拒絕回答這個問題。
### 4.2.1 頻率分布
讓我們看看每個類別中有多少人。現在不要擔心 R 到底是怎么做的,我們稍后再談。
```r
# summarize physical activity data
PhysActive_table <- NHANES %>%
dplyr::select(PhysActive) %>%
group_by(PhysActive) %>%
summarize(AbsoluteFrequency = n())
pander(PhysActive_table)
```
<colgroup><col style="width: 18%"> <col style="width: 26%"></colgroup>
| 物理激活 | 絕對頻率 |
| --- | --- |
| 不 | 2473 個 |
| 是的 | 2972 年 |
| 不適用 | 1334 年 |
此單元格中的 r 代碼生成一個表格,顯示每個不同值的頻率;有 2473 名回答“否”的人,2972 名回答“是”,1334 名沒有回答。我們稱之為 _ 頻率分布 _,因為它告訴我們每個值是如何分布在樣本中的。
因為我們只想與回答問題的人一起工作,所以讓我們過濾數據集,使其只包括回答此問題的個人。
```r
# summarize physical activity data after dropping NA values using drop_na()
NHANES %>%
drop_na(PhysActive) %>%
dplyr::select(PhysActive) %>%
group_by(PhysActive) %>%
summarize(AbsoluteFrequency = n()) %>%
pander()
```
<colgroup><col style="width: 18%"> <col style="width: 26%"></colgroup>
| PhysActive | AbsoluteFrequency |
| --- | --- |
| No | 2473 |
| Yes | 2972 |
這向我們展示了兩個響應的絕對頻率,對于每個實際給出響應的人。從這一點上我們可以看出,說“是”的人比說“不”的人多,但從絕對數上很難分辨出差別有多大。因此,我們通常希望使用 _ 相對頻率 _ 來呈現數據,該相對頻率是通過將每個頻率除以所有頻率的和得到的:
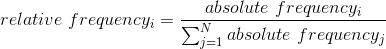
在 R 中我們可以這樣做,如下所示:
```r
# compute relative frequency of physical activity categories
NHANES %>%
drop_na(PhysActive) %>%
dplyr::select(PhysActive) %>%
group_by(PhysActive) %>%
summarize(AbsoluteFrequency = n()) %>%
mutate(RelativeFrequency = AbsoluteFrequency / sum(AbsoluteFrequency)) %>%
pander()
```
<colgroup><col style="width: 18%"> <col style="width: 27%"> <col style="width: 27%"></colgroup>
| PhysActive | AbsoluteFrequency | 相對頻率 |
| --- | --- | --- |
| No | 2473 | 0.454 個 |
| Yes | 2972 | 0.546 個 |
相對頻率提供了一種更簡單的方法來判斷不平衡的程度。我們還可以通過將相對頻率乘以 100 來將其解釋為百分比:
```r
# compute percentages for physical activity categories
PhysActive_table_filtered <- NHANES %>%
drop_na(PhysActive) %>%
dplyr::select(PhysActive) %>%
group_by(PhysActive) %>%
summarize(AbsoluteFrequency = n()) %>%
mutate(
RelativeFrequency = AbsoluteFrequency / sum(AbsoluteFrequency),
Percentage = RelativeFrequency * 100
)
pander(PhysActive_table_filtered)
```
<colgroup><col style="width: 18%"> <col style="width: 27%"> <col style="width: 27%"> <col style="width: 16%"></colgroup>
| PhysActive | AbsoluteFrequency | RelativeFrequency | 百分比 |
| --- | --- | --- | --- |
| No | 2473 | 0.454 | 45.418 美元 |
| Yes | 2972 | 0.546 | 54.582 條 |
這讓我們看到,NHANES 樣本中 45.42%的人說“不”,54.58%的人說“是”。
### 4.2.2 累積分布
我們在上面研究的 physactive 變量只有兩個可能的值,但我們通常希望總結出可以有更多可能值的數據。當這些值至少是序數時,總結它們的一個有用方法是通過我們所稱的 _ 累積 _ 頻率表示:我們不詢問對特定值進行多少觀察,而是詢問有多少個值至少是 _ 某個特定值。_
讓我們看一下 nhanes 數據集中的另一個變量,名為 sleephrsnight,它記錄了參與者在正常工作日報告睡眠的時間。讓我們像上面一樣創建一個頻率表,在刪除了沒有對問題作出響應的任何人之后。
```r
# create summary table for relative frequency of different
# values of SleepHrsNight
NHANES %>%
drop_na(SleepHrsNight) %>%
dplyr::select(SleepHrsNight) %>%
group_by(SleepHrsNight) %>%
summarize(AbsoluteFrequency = n()) %>%
mutate(
RelativeFrequency = AbsoluteFrequency / sum(AbsoluteFrequency),
Percentage = RelativeFrequency * 100
) %>%
pander()
```
<colgroup><col style="width: 22%"> <col style="width: 27%"> <col style="width: 27%"> <col style="width: 16%"></colgroup>
| 睡眠之光 | AbsoluteFrequency | RelativeFrequency | Percentage |
| --- | --- | --- | --- |
| 二 | 9 | 0.002 個 | 0.179 個 |
| 三 | 49 歲 | 0.01 分 | 0.973 個 |
| 4 | 200 個 | 0.04 分 | 3.972 年 |
| 5 個 | 406 個 | 0.081 個 | 8.064 年 |
| 6 | 1172 年 | 0.233 個 | 23.277 頁 |
| 7 | 1394 年 | 0.277 個 | 27.686 年 |
| 8 個 | 1405 年 | 0.279 個 | 27.905 年 |
| 9 | 271 個 | 0.054 個 | 5.382 條 |
| 10 個 | 97 | 0.019 個 | 1.927 個 |
| 11 個 | 15 個 | 0.003 個 | 0.298 個 |
| 12 個 | 17 | 0.003 | 0.338 個 |
我們可以通過查看表開始匯總數據集;例如,我們可以看到大多數人報告睡眠時間在 6 到 8 小時之間。讓我們繪制數據以更清楚地看到這一點。要做到這一點,我們可以繪制一個 _ 柱狀圖 _,它顯示具有每個不同值的事例數;請參見圖[4.2](#fig:sleepHist)的左面板。ggplot2()庫有一個內置的柱狀圖函數(`geom_histogram()`),我們經常使用它。我們還可以繪制相對頻率,我們通常將其稱為 _ 密度 _——參見圖[4.2](#fig:sleepHist)的右面板。
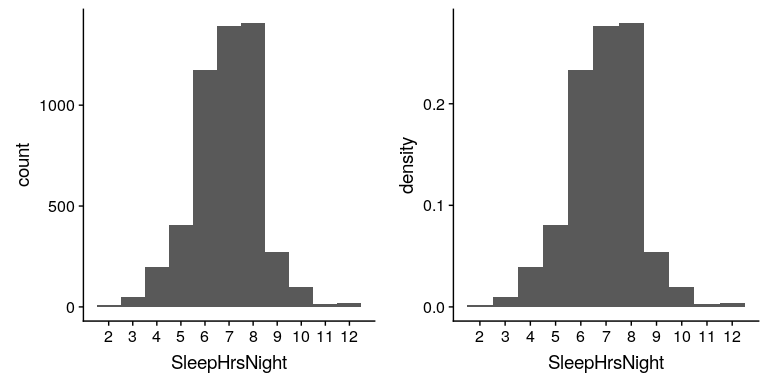
圖 4.2 左:顯示報告 sleephrsnight 變量每個可能值的人數(左)和比例(右)的柱狀圖。
如果我們想知道有多少人報告睡眠 5 小時或更少怎么辦?為了找到這個,我們可以計算一個 _ 累積分布 _:
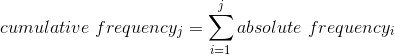
也就是說,為了計算某個值 j 的累積頻率,我們將所有值(包括 j)的頻率相加。讓我們對睡眠變量進行計算,首先對絕對頻率進行計算:
```r
# create cumulative frequency distribution of SleepHrsNight data
SleepHrsNight_cumulative <-
NHANES %>%
drop_na(SleepHrsNight) %>%
dplyr::select(SleepHrsNight) %>%
group_by(SleepHrsNight) %>%
summarize(AbsoluteFrequency = n()) %>%
mutate(CumulativeFrequency = cumsum(AbsoluteFrequency))
pander(SleepHrsNight_cumulative)
```
<colgroup><col style="width: 22%"> <col style="width: 27%"> <col style="width: 29%"></colgroup>
| SleepHrsNight | AbsoluteFrequency | 累積頻率 |
| --- | --- | --- |
| 2 | 9 | 9 |
| 3 | 49 | 58 |
| 4 | 200 | 258 個 |
| 5 | 406 | 664 個 |
| 6 | 1172 | 1836 年 |
| 7 | 1394 | 3230 個 |
| 8 | 1405 | 4635 個 |
| 9 | 271 | 4906 個 |
| 10 | 97 | 5003 個 |
| 11 | 15 | 5018 年 |
| 12 | 17 | 5035 個 |
在圖[4.3](#fig:sleepAbsCumulRelFreq)的左側面板中,我們繪制了數據,以查看這些表示形式的外觀;絕對頻率值以紅色繪制,累積頻率以藍色繪制。我們看到累積頻率是單調遞增的,也就是說,它只能上升或保持不變,但不能下降。同樣,我們通常發現相對頻率比絕對頻率更有用;這些頻率繪制在圖[4.3](#fig:sleepAbsCumulRelFreq)的右面板中。
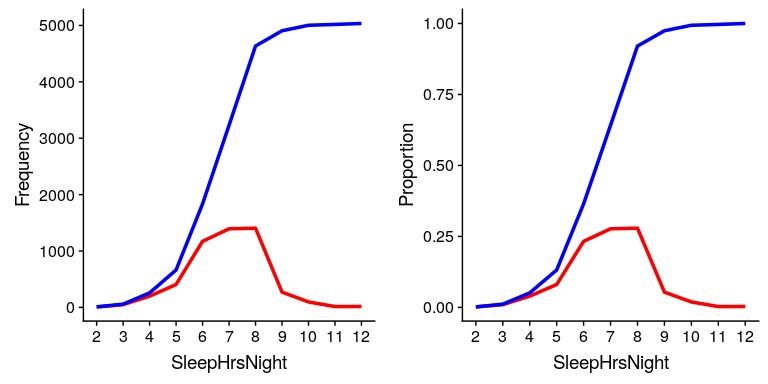
圖 4.3 SleephrsNight 可能值的頻率(左)和比例(右)的相對(紅)和累積相對(藍)值的圖。
### 4.2.3 繪制柱狀圖
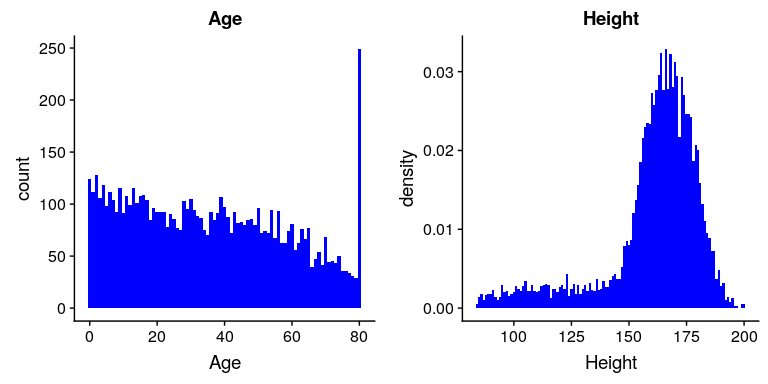
圖 4.4 nhanes 中年齡(左)和身高(右)變量的柱狀圖。
我們在上面研究的變量相當簡單,只有幾個可能的值。現在讓我們來看一個更復雜的變量:年齡。首先,讓我們繪制 nhanes 數據集中所有個體的年齡變量(參見圖[4.4](#fig:ageHist)的左面板)。你看到了什么?首先,你應該注意到每個年齡組的個體數量隨著時間的推移而減少。這是有道理的,因為人口是隨機抽樣的,因此隨著時間的推移死亡導致老年人的數量減少。其次,你可能在 80 歲的時候注意到圖表中有一個大的尖峰。你覺得這是怎么回事?
如果您查看 nhanes 數據集的幫助功能,您將看到以下定義:“研究參與者篩選的年齡(年)。注:80 歲或 80 歲以上的受試者被記錄為 80 歲。“原因在于,年齡很高的受試者數量相對較少,如果你知道他們的確切年齡,就可能更容易在數據集中識別出特定的人;研究人員通常承諾他們的參與螞蟻要對自己的身份保密,這是他們能做的有助于保護研究對象的事情之一。這也突顯了一個事實,即知道一個人的數據來自何處以及如何處理它們總是很重要的;否則,我們可能會不正確地解釋它們。
讓我們看看 nhanes 數據集中另一個更復雜的變量:高度。高度值的柱狀圖繪制在圖[4.4](#fig:ageHist)的右面板中。關于這個分布你首先應該注意的是,它的大部分密度集中在 170 厘米左右,但是分布的左側有一個“尾巴”;有少數個體的高度要小得多。你覺得這是怎么回事?
您可能已經直覺到小高度來自數據集中的子級。檢查這一點的一種方法是為兒童和成人繪制單獨顏色的柱狀圖(圖[4.5](#fig:heightHistSep)的左面板)。這表明,所有非常短的高度確實來自樣本中的兒童。讓我們創建一個新版本的 nhanes,它只包含成年人,然后為他們繪制柱狀圖(圖[4.5](#fig:heightHistSep)的右面板)。在這個圖中,分布看起來更加對稱。正如我們稍后將看到的,這是一個 _ 正態 _(或 _ 高斯 _)分布的很好例子。
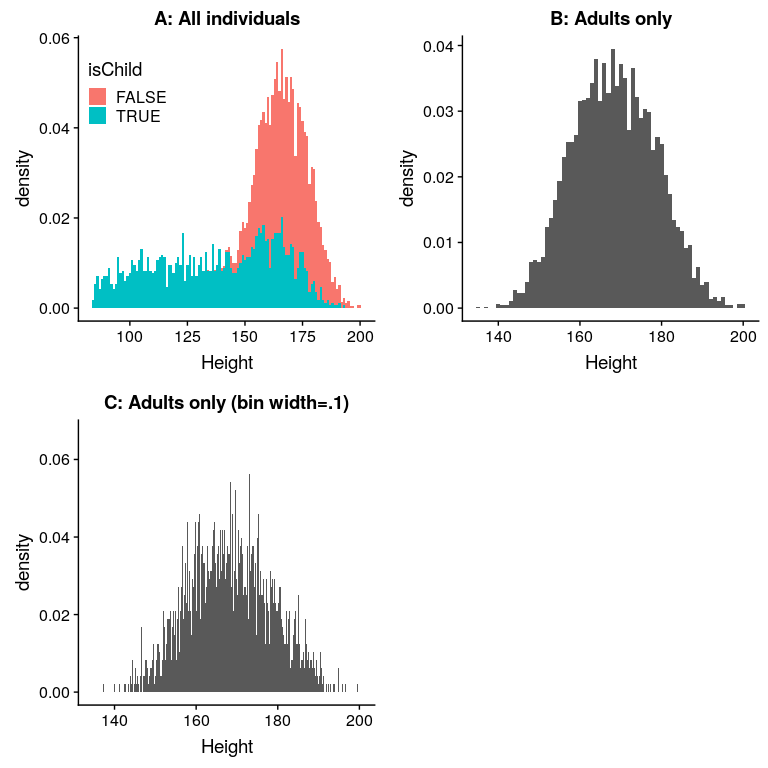
圖 4.5 nhanes 高度柱狀圖。A:分別為兒童(藍色)和成人(紅色)繪制的值。B:僅限成人使用。C:與 B 相同,但倉寬=0.1
### 4.2.4 柱狀圖箱
在我們前面使用睡眠變量的例子中,數據是以整數報告的,我們只計算報告每個可能值的人數。但是,如果您查看 nhanes 中高度變量的一些值,您將看到它是以厘米為單位測量的,一直到小數點后一位:
```r
# take a slice of a few values from the full data frame
NHANES_adult %>%
dplyr::select(Height) %>%
slice(45:50) %>%
pander()
```
<colgroup><col style="width: 11%"></colgroup>
| 高度 |
| --- |
| 169.6 條 |
| 169.8 條 |
| 167.5 條 |
| 155.2 條 |
| 173.8 條 |
| 174.5 條 |
圖[4.5](#fig:heightHistSep)的面板 C 顯示了統計每個可能值的密度的直方圖。這個柱狀圖看起來真的參差不齊,這是因為特定的小數位值的可變性。例如,值 173.2 出現 32 次,而值 173.3 只出現 15 次。我們可能不認為這兩個權重的流行率真的有如此大的差異;更可能的原因是我們的樣本中的隨機變異性。
一般來說,當我們創建一個連續的或可能有很多值的數據柱狀圖時,我們將 _bin_ 這些值,這樣我們就不會計算和繪制每個特定值的頻率,而是計算和繪制特定范圍內的值的頻率。e.這就是為什么上面[4.5](#fig:heightHistSep)的面板 B 中的圖看起來不那么鋸齒狀的原因;如果您查看`geom_histogram`命令,您將看到我們設置了“b in width=1”,它告訴命令通過將 b in 中的值與寬度為 1 的值組合來計算柱狀圖;因此,值 1.3、1.5 和 1.6 would 所有數據都計算在同一個存儲單元的頻率上,從等于 1 的值到小于 2 的值。
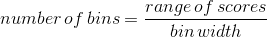
請注意,一旦選擇了箱大小,則箱的數量將由數據確定:
如何選擇最佳的倉寬沒有硬性和快速性的規則。偶爾它會很明顯(就像只有幾個可能的值一樣),但在許多情況下,它需要反復嘗試。有一些方法試圖找到一個最佳的倉位大小,例如在 r 的`nclass.FD()`函數中實現的 freedman diaconis 方法;我們將在下面的一些示例中使用該函數。
- 前言
- 0.1 本書為什么存在?
- 0.2 你不是統計學家-我們為什么要聽你的?
- 0.3 為什么是 R?
- 0.4 數據的黃金時代
- 0.5 開源書籍
- 0.6 確認
- 1 引言
- 1.1 什么是統計思維?
- 1.2 統計數據能為我們做什么?
- 1.3 統計學的基本概念
- 1.4 因果關系與統計
- 1.5 閱讀建議
- 2 處理數據
- 2.1 什么是數據?
- 2.2 測量尺度
- 2.3 什么是良好的測量?
- 2.4 閱讀建議
- 3 概率
- 3.1 什么是概率?
- 3.2 我們如何確定概率?
- 3.3 概率分布
- 3.4 條件概率
- 3.5 根據數據計算條件概率
- 3.6 獨立性
- 3.7 逆轉條件概率:貝葉斯規則
- 3.8 數據學習
- 3.9 優勢比
- 3.10 概率是什么意思?
- 3.11 閱讀建議
- 4 匯總數據
- 4.1 為什么要總結數據?
- 4.2 使用表格匯總數據
- 4.3 分布的理想化表示
- 4.4 閱讀建議
- 5 將模型擬合到數據
- 5.1 什么是模型?
- 5.2 統計建模:示例
- 5.3 什么使模型“良好”?
- 5.4 模型是否太好?
- 5.5 最簡單的模型:平均值
- 5.6 模式
- 5.7 變異性:平均值與數據的擬合程度如何?
- 5.8 使用模擬了解統計數據
- 5.9 Z 分數
- 6 數據可視化
- 6.1 數據可視化如何拯救生命
- 6.2 繪圖解剖
- 6.3 使用 ggplot 在 R 中繪制
- 6.4 良好可視化原則
- 6.5 最大化數據/墨水比
- 6.6 避免圖表垃圾
- 6.7 避免數據失真
- 6.8 謊言因素
- 6.9 記住人的局限性
- 6.10 其他因素的修正
- 6.11 建議閱讀和視頻
- 7 取樣
- 7.1 我們如何取樣?
- 7.2 采樣誤差
- 7.3 平均值的標準誤差
- 7.4 中心極限定理
- 7.5 置信區間
- 7.6 閱讀建議
- 8 重新采樣和模擬
- 8.1 蒙特卡羅模擬
- 8.2 統計的隨機性
- 8.3 生成隨機數
- 8.4 使用蒙特卡羅模擬
- 8.5 使用模擬統計:引導程序
- 8.6 閱讀建議
- 9 假設檢驗
- 9.1 無效假設統計檢驗(NHST)
- 9.2 無效假設統計檢驗:一個例子
- 9.3 無效假設檢驗過程
- 9.4 現代環境下的 NHST:多重測試
- 9.5 閱讀建議
- 10 置信區間、效應大小和統計功率
- 10.1 置信區間
- 10.2 效果大小
- 10.3 統計能力
- 10.4 閱讀建議
- 11 貝葉斯統計
- 11.1 生成模型
- 11.2 貝葉斯定理與逆推理
- 11.3 進行貝葉斯估計
- 11.4 估計后驗分布
- 11.5 選擇優先權
- 11.6 貝葉斯假設檢驗
- 11.7 閱讀建議
- 12 分類關系建模
- 12.1 示例:糖果顏色
- 12.2 皮爾遜卡方檢驗
- 12.3 應急表及雙向試驗
- 12.4 標準化殘差
- 12.5 優勢比
- 12.6 貝葉斯系數
- 12.7 超出 2 x 2 表的分類分析
- 12.8 注意辛普森悖論
- 13 建模持續關系
- 13.1 一個例子:仇恨犯罪和收入不平等
- 13.2 收入不平等是否與仇恨犯罪有關?
- 13.3 協方差和相關性
- 13.4 相關性和因果關系
- 13.5 閱讀建議
- 14 一般線性模型
- 14.1 線性回歸
- 14.2 安裝更復雜的模型
- 14.3 變量之間的相互作用
- 14.4“預測”的真正含義是什么?
- 14.5 閱讀建議
- 15 比較方法
- 15.1 學生 T 考試
- 15.2 t 檢驗作為線性模型
- 15.3 平均差的貝葉斯因子
- 15.4 配對 t 檢驗
- 15.5 比較兩種以上的方法
- 16 統計建模過程:一個實例
- 16.1 統計建模過程
- 17 做重復性研究
- 17.1 我們認為科學應該如何運作
- 17.2 科學(有時)是如何工作的
- 17.3 科學中的再現性危機
- 17.4 有問題的研究實踐
- 17.5 進行重復性研究
- 17.6 進行重復性數據分析
- 17.7 結論:提高科學水平
- 17.8 閱讀建議
- References