
## 5.9 Z 分數
```r
crimeData <-
read.table(
"data/CrimeOneYearofData_clean.csv",
header = TRUE,
sep = ","
)
# let's drop DC since it is so small
crimeData <-
crimeData %>%
dplyr::filter(State != "District of Columbia")
caCrimeData <-
crimeData %>%
dplyr::filter(State == "California")
```
以分布的中心趨勢和變異性為特征后,通常有助于根據個體分數相對于總體分布的位置來表示。假設我們有興趣描述不同州犯罪的相對水平,以確定加利福尼亞是否是一個特別危險的地方。我們可以使用來自[FBI 統一犯罪報告網站](https://www.ucrdatatool.gov/Search/Crime/State/RunCrimeOneYearofData.cfm)的 2014 年數據來問這個問題。圖[5.8](#fig:crimeHist)的左面板顯示了每個州暴力犯罪數量的柱狀圖,突出了加州的價值。從這些數據來看,加利福尼亞州似乎非常危險,當年共有 153709 起犯罪。
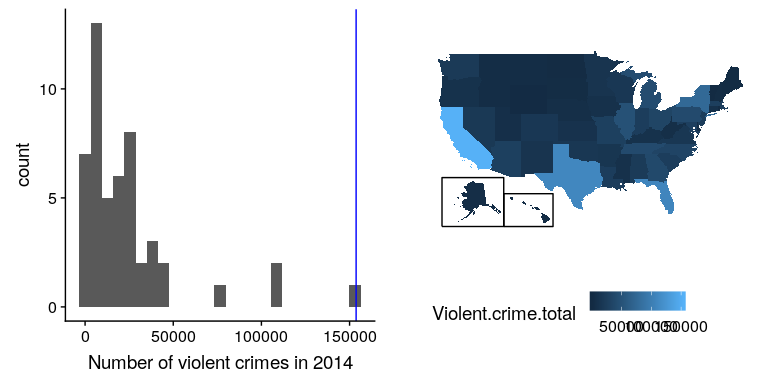
圖 5.8 左:暴力犯罪數量的柱狀圖。CA 的值以藍色繪制。右圖:一張相同數據的地圖,用彩色繪制每個州的犯罪數量。
使用 r,還可以很容易地生成一個顯示變量跨狀態分布的地圖,如圖[5.8](#fig:crimeHist)右面板所示。
然而,你可能已經意識到加州在美國任何一個州的人口都是最多的,所以它也會有更多的犯罪是合理的。如果我們將這兩種情況相提并論(參見圖[5.9](#fig:popVsCrime)的左面板),我們就會發現人口與犯罪數量之間存在直接關系。
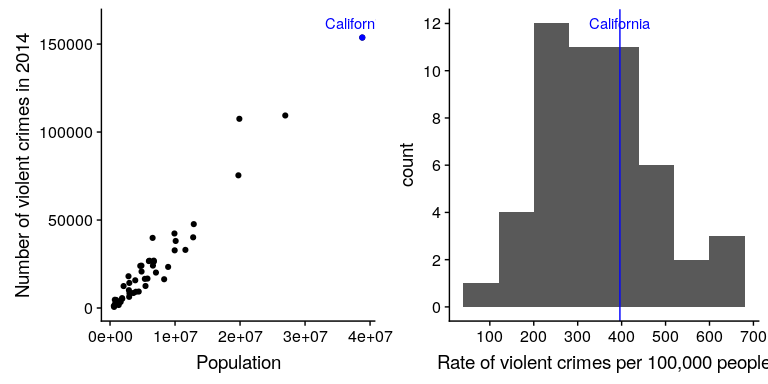
圖 5.9 左:按州劃分的犯罪數量與人口的關系圖。對:人均犯罪率的柱狀圖,以每 10 萬人的犯罪率表示。
我們不應使用犯罪的原始數量,而應使用人均暴力犯罪率,即犯罪數量除以國家人口所得的比率。FBI 的數據集已經包含了這個值(以每 100000 人的比率表示)。
```r
# print crime rate statistics, normalizing for population
sprintf("rate of 2014 violent crimes in CA: %.2f", caCrimeData$Violent.Crime.rate)
```
```r
## [1] "rate of 2014 violent crimes in CA: 396.10"
```
```r
sprintf("mean rate: %.2f", mean(crimeData$Violent.Crime.rate))
```
```r
## [1] "mean rate: 346.81"
```
```r
sprintf("std of rate: %.2f", sd(crimeData$Violent.Crime.rate))
```
```r
## [1] "std of rate: 128.82"
```
從右圖[5.9](#fig:popVsCrime)中我們可以看出,加利福尼亞畢竟沒有那么危險——它每 10 萬人的犯罪率為 396.1,略高于 346.81 的平均值,但在許多其他州的范圍內。但是,如果我們想更清楚地了解它與發行版的其他部分有多遠呢?
_z-score_ 允許我們以一種方式表示數據,從而更深入地了解每個數據點與整體分布的關系。如果我們知道總體平均值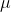和標準差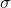的值,則計算數據點 z 得分的公式為:
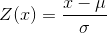
直觀地說,你可以把 z 值看作是告訴你離任何數據點的平均值有多遠,以標準偏差為單位。我們可以根據犯罪率數據來計算,如圖[5.10](#fig:crimeZplot)所示。
```r
## [1] "mean of Z-scored data: 1.4658413372004e-16"
```
```r
## [1] "std deviation of Z-scored data: 1"
```
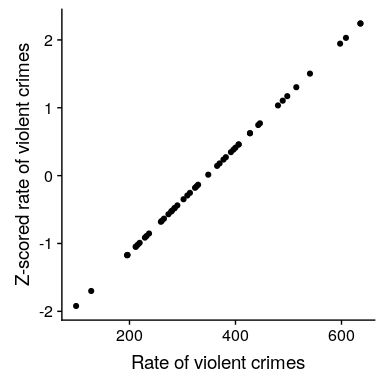
圖 5.10 原始犯罪率數據與 Z 評分數據的散點圖。
散點圖表明,z-得分的過程并沒有改變數據點的相對分布(可以看到原始數據和 z-得分數據在相互作圖時落在一條直線上),只是將它們移動到一個平均值為零和一個標準差。一個。然而,如果你仔細觀察,你會發現平均值并不完全為零——只是非常小。這里所發生的是,計算機以一定的 _ 數字精度 _ 表示數字,這意味著有些數字不完全為零,但小到 R 認為它們為零。
```r
# examples of numerical precision
print(paste("smallest number such that 1+x != 1", .Machine$double.eps))
```
```r
## [1] "smallest number such that 1+x != 1 2.22044604925031e-16"
```
```r
# We can confirm this by showing that adding anything less than that number to
# 1 is treated as 1 by R
print((1 + .Machine$double.eps) == 1)
```
```r
## [1] FALSE
```
```r
print((1 + .Machine$double.eps / 2) == 1)
```
```r
## [1] TRUE
```
```r
# we can also look at the largest number
print(paste("largest number", .Machine$double.xmax))
```
```r
## [1] "largest number 1.79769313486232e+308"
```
```r
# similarly here, we can see that adding 1 to the largest possible number
# is no different from the largest possible number, in R's eyes at least.
print((1 + .Machine$double.xmax) == .Machine$double.xmax)
```
```r
## [1] TRUE
```
圖[5.11](#fig:crimeZmap)顯示了使用地理視圖的 Z 評分犯罪數據。
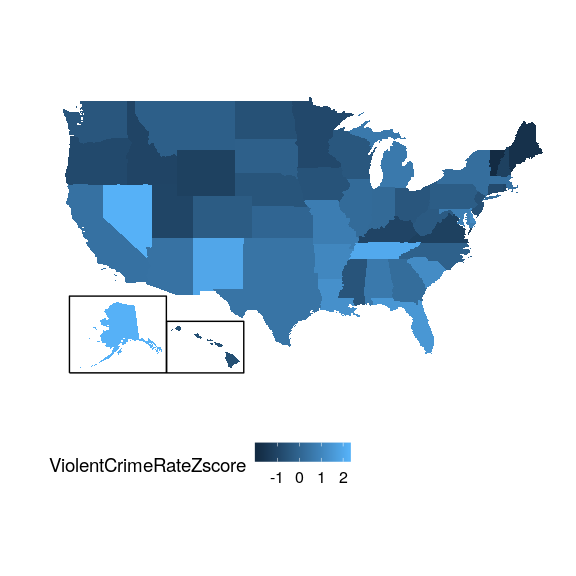
圖 5.11 呈現在美國地圖上的犯罪數據,以 z 分數表示。
這為我們提供了一個稍微更具解釋性的數據視圖。例如,我們可以看到內華達州、田納西州和新墨西哥州的犯罪率都比平均值高出大約兩個標準差。
### 5.9.1 解釋 z-分數
“z-得分”中的“z”源于標準正態分布(即平均值為零且標準偏差為 1 的正態分布)通常被稱為“z”分布。我們可以使用標準正態分布來幫助我們了解相對于分布的其余部分,特定的 z 分數告訴我們數據點的位置。
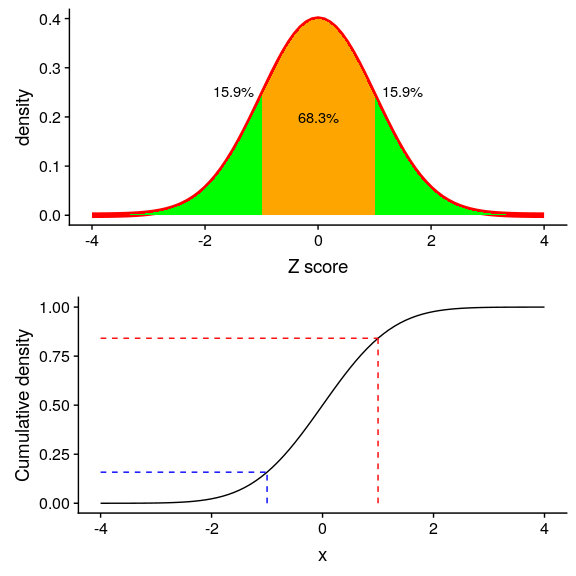
圖 5.12 標準正態分布的密度(頂部)和累積分布(底部),在平均值以上/以下的一個標準偏差處進行截止。
圖[5.12](#fig:zDensityCDF)中的上面板顯示,我們預計約 16%的值會落在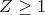中,同樣的比例也會落在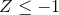中。
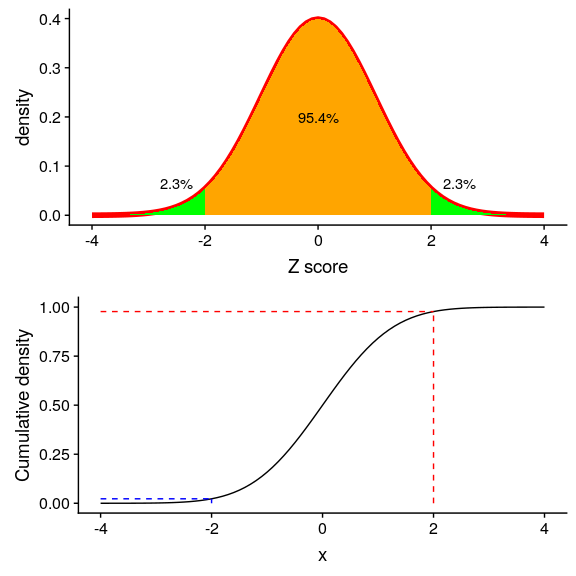
圖 5.13 標準正態分布的密度(頂部)和累積分布(底部),平均值以上/以下兩個標準偏差處的截止值
圖[5.13](#fig:zDensity2SD)顯示了兩個標準偏差的相同曲線圖。在這里,我們看到只有約 2.3%的值落在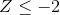中,同樣的也落在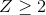中。因此,如果我們知道特定數據點的 z 值,我們可以估計找到一個值的可能性或可能性有多大,至少與該值一樣極端,這樣我們就可以將值放入更好的上下文中。
### 5.9.2 標準化評分
假設我們希望生成平均值為 100、標準差為 10 的標準化犯罪評分,而不是 Z 評分。這類似于用智力測驗的分數來產生智力商數(IQ)的標準化。我們可以簡單地將 z 分數乘以 10,然后再加 100。
```r
## [1] "mean of standardized score data: 100"
```
```r
## [1] "std deviation of standardized score data: 10"
```
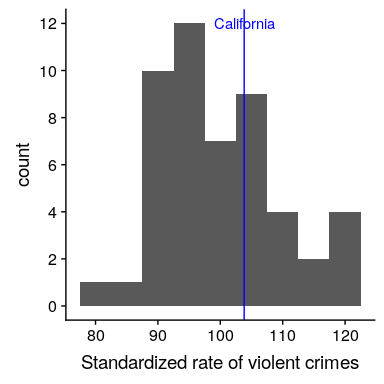
圖 5.14 犯罪數據以標準化分數呈現,平均值為 100,標準差為 10。
#### 5.9.2.1 使用 z 分比較分布
z 值的一個有用的應用是比較不同變量的分布。假設我們想比較暴力犯罪和財產犯罪在各州的分布情況。在圖[5.15](#fig:crimeTypePlot)的左面板中,我們將這些圖形繪制在一起,用藍色繪制 CA。正如你所看到的,財產犯罪的原始率遠遠高于暴力犯罪的原始率,所以我們不能直接比較數字。但是,我們可以將這些數據的 z 值相互繪制出來(圖[5.15](#fig:crimeTypePlot)的右面板)——這里我們再次看到數據的分布沒有改變。把每一個變量的數據放入 z 值后,就可以進行比較了,讓我們看到加州實際上處于暴力犯罪和財產犯罪分布的中間。
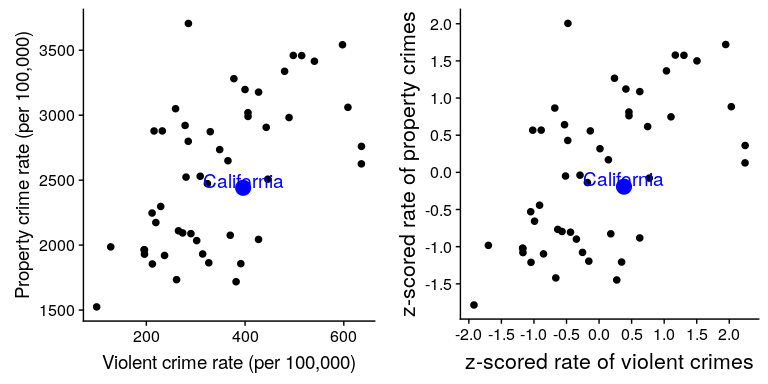
圖 5.15 暴力與財產犯罪率(左)和 Z 得分率(右)的曲線圖。
讓我們再給情節加一個因素:人口。在圖[5.16](#fig:crimeTypePopPlot)的左面板中,我們使用繪圖符號的大小來顯示這一點,這通常是向繪圖添加信息的一種有用方法。
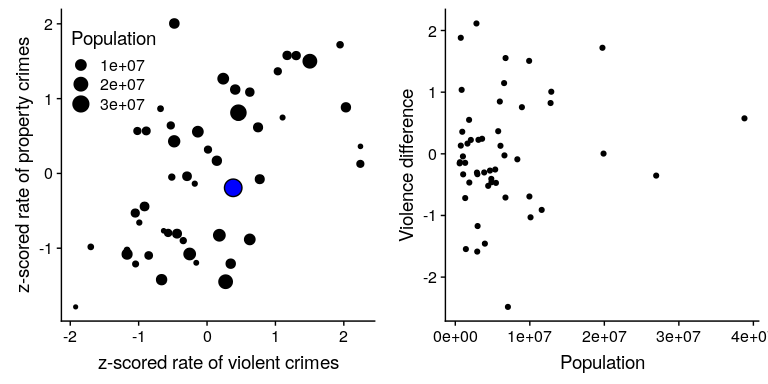
圖 5.16 左圖:暴力犯罪率與財產犯罪率的對比圖,人口規模以繪圖符號的大小表示;加利福尼亞州以藍色表示。對:針對人口的暴力和財產犯罪的得分差異。
因為 z 分數是直接可比的,所以我們也可以計算“暴力差異”分數,該分數表示各州暴力與非暴力(財產)犯罪的相對比率。然后我們可以將這些得分與人口進行對比(參見圖[5.16](#fig:crimeTypePopPlot)的右面板)。這說明我們如何使用 z-分數將不同的變量放在一個共同的尺度上。
值得注意的是,最小的國家在兩個方向上的差異似乎最大。雖然這可能會吸引我們去觀察每一個狀態,并試圖確定為什么它有一個高或低的差異分數,但這可能反映了這樣一個事實,即從較小的樣本中獲得的估計值必然會有更多的變量,正如我們將在幾章中更詳細地討論的那樣。
- 前言
- 0.1 本書為什么存在?
- 0.2 你不是統計學家-我們為什么要聽你的?
- 0.3 為什么是 R?
- 0.4 數據的黃金時代
- 0.5 開源書籍
- 0.6 確認
- 1 引言
- 1.1 什么是統計思維?
- 1.2 統計數據能為我們做什么?
- 1.3 統計學的基本概念
- 1.4 因果關系與統計
- 1.5 閱讀建議
- 2 處理數據
- 2.1 什么是數據?
- 2.2 測量尺度
- 2.3 什么是良好的測量?
- 2.4 閱讀建議
- 3 概率
- 3.1 什么是概率?
- 3.2 我們如何確定概率?
- 3.3 概率分布
- 3.4 條件概率
- 3.5 根據數據計算條件概率
- 3.6 獨立性
- 3.7 逆轉條件概率:貝葉斯規則
- 3.8 數據學習
- 3.9 優勢比
- 3.10 概率是什么意思?
- 3.11 閱讀建議
- 4 匯總數據
- 4.1 為什么要總結數據?
- 4.2 使用表格匯總數據
- 4.3 分布的理想化表示
- 4.4 閱讀建議
- 5 將模型擬合到數據
- 5.1 什么是模型?
- 5.2 統計建模:示例
- 5.3 什么使模型“良好”?
- 5.4 模型是否太好?
- 5.5 最簡單的模型:平均值
- 5.6 模式
- 5.7 變異性:平均值與數據的擬合程度如何?
- 5.8 使用模擬了解統計數據
- 5.9 Z 分數
- 6 數據可視化
- 6.1 數據可視化如何拯救生命
- 6.2 繪圖解剖
- 6.3 使用 ggplot 在 R 中繪制
- 6.4 良好可視化原則
- 6.5 最大化數據/墨水比
- 6.6 避免圖表垃圾
- 6.7 避免數據失真
- 6.8 謊言因素
- 6.9 記住人的局限性
- 6.10 其他因素的修正
- 6.11 建議閱讀和視頻
- 7 取樣
- 7.1 我們如何取樣?
- 7.2 采樣誤差
- 7.3 平均值的標準誤差
- 7.4 中心極限定理
- 7.5 置信區間
- 7.6 閱讀建議
- 8 重新采樣和模擬
- 8.1 蒙特卡羅模擬
- 8.2 統計的隨機性
- 8.3 生成隨機數
- 8.4 使用蒙特卡羅模擬
- 8.5 使用模擬統計:引導程序
- 8.6 閱讀建議
- 9 假設檢驗
- 9.1 無效假設統計檢驗(NHST)
- 9.2 無效假設統計檢驗:一個例子
- 9.3 無效假設檢驗過程
- 9.4 現代環境下的 NHST:多重測試
- 9.5 閱讀建議
- 10 置信區間、效應大小和統計功率
- 10.1 置信區間
- 10.2 效果大小
- 10.3 統計能力
- 10.4 閱讀建議
- 11 貝葉斯統計
- 11.1 生成模型
- 11.2 貝葉斯定理與逆推理
- 11.3 進行貝葉斯估計
- 11.4 估計后驗分布
- 11.5 選擇優先權
- 11.6 貝葉斯假設檢驗
- 11.7 閱讀建議
- 12 分類關系建模
- 12.1 示例:糖果顏色
- 12.2 皮爾遜卡方檢驗
- 12.3 應急表及雙向試驗
- 12.4 標準化殘差
- 12.5 優勢比
- 12.6 貝葉斯系數
- 12.7 超出 2 x 2 表的分類分析
- 12.8 注意辛普森悖論
- 13 建模持續關系
- 13.1 一個例子:仇恨犯罪和收入不平等
- 13.2 收入不平等是否與仇恨犯罪有關?
- 13.3 協方差和相關性
- 13.4 相關性和因果關系
- 13.5 閱讀建議
- 14 一般線性模型
- 14.1 線性回歸
- 14.2 安裝更復雜的模型
- 14.3 變量之間的相互作用
- 14.4“預測”的真正含義是什么?
- 14.5 閱讀建議
- 15 比較方法
- 15.1 學生 T 考試
- 15.2 t 檢驗作為線性模型
- 15.3 平均差的貝葉斯因子
- 15.4 配對 t 檢驗
- 15.5 比較兩種以上的方法
- 16 統計建模過程:一個實例
- 16.1 統計建模過程
- 17 做重復性研究
- 17.1 我們認為科學應該如何運作
- 17.2 科學(有時)是如何工作的
- 17.3 科學中的再現性危機
- 17.4 有問題的研究實踐
- 17.5 進行重復性研究
- 17.6 進行重復性數據分析
- 17.7 結論:提高科學水平
- 17.8 閱讀建議
- References