
## 5.5 最簡單的模型:平均值
我們已經遇到了平均值(或平均值),事實上,大多數人知道平均值,即使他們從未上過統計課。它通常用來描述我們稱之為數據集“中心趨勢”的東西——也就是說,數據以什么值為中心?大多數人不認為計算平均值是將模型與數據相匹配。然而,這正是我們計算平均值時要做的。
我們已經看到了計算數據樣本平均值的公式:
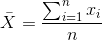
注意,我說過這個公式是專門針對數據的 _ 樣本 _ 的,它是從更大的人群中選擇的一組數據點。我們希望通過一個樣本來描述一個更大的群體——我們感興趣的全套個體。例如,如果我們是一個政治民意測驗者,我們感興趣的人群可能都是注冊選民,而我們的樣本可能只包括從這個人群中抽取的幾千人。在本課程的后面,我們將更詳細地討論抽樣,但現在重要的一點是統計學家通常喜歡使用不同的符號來區分描述樣本值的統計數據和描述總體值的參數;在這種情況下,公式 a 表示總體平均值(表示為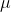)為:
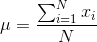
其中 n 是整個人口的大小。
我們已經看到,平均值是保證給我們的平均誤差為零的匯總統計。平均值還有另一個特點:它是最小化平方誤差總和(SSE)的匯總統計。在統計學中,我們稱之為“最佳”估計量。我們可以從數學上證明這一點,但我們將在圖[5.7](#fig:MinSSE)中以圖形方式證明這一點。

圖 5.7 平均值作為統計值的證明,可使平方誤差之和最小化。使用 nhanes 子高度數據,我們計算平均值(用藍色條表示)。然后,我們測試其他值的范圍,對于每個值,我們從該值計算每個數據點的平方誤差之和,該值由黑色曲線表示。我們看到平均值降到平方誤差圖的最小值。
SSE 的最小化是一個很好的特性,這就是為什么平均值是最常用的統計數據匯總。然而,均值也有一個陰暗面。假設一個酒吧有五個人,我們檢查每個人的收入:
```r
# create income data frame
incomeDf <-
tibble(
income = c(48000, 64000, 58000, 72000, 66000),
person = c("Joe", "Karen", "Mark", "Andrea", "Pat")
)
# glimpse(incomeDf)
panderOptions('digits',2)
pander(incomeDf)
```
<colgroup><col style="width: 12%"> <col style="width: 12%"></colgroup>
| 收入 | 人 |
| --- | --- |
| 48000 個 | 喬 |
| 64000 個 | 凱倫 |
| 5.8 萬 | 作記號 |
| 72000 個 | 安德莉亞 |
| 66000 個 | 拍打 |
```r
sprintf("Mean income: %0.2f", mean(incomeDf$income))
```
```r
## [1] "Mean income: 61600.00"
```
這個平均值似乎是這五個人收入的一個很好的總結。現在讓我們看看如果碧昂斯·諾爾斯走進酒吧會發生什么:
```r
# add Beyonce to income data frame
incomeDf <-
incomeDf %>%
rbind(c(54000000, "Beyonce")) %>%
mutate(income = as.double(income))
pander(incomeDf)
```
<colgroup><col style="width: 13%"> <col style="width: 13%"></colgroup>
| income | person |
| --- | --- |
| 48000 | Joe |
| 64000 | Karen |
| 58000 | Mark |
| 72000 | Andrea |
| 66000 | Pat |
| 5.4E+07 型 | 碧昂斯 |
```r
sprintf("Mean income: %0.2f", mean(incomeDf$income))
```
```r
## [1] "Mean income: 9051333.33"
```
平均值現在接近 1000 萬美元,這并不能真正代表酒吧里的任何人——特別是,它受到了碧昂絲價值的巨大驅動。一般來說,平均值對極值非常敏感,這就是為什么在使用平均值匯總數據時,確保沒有極值總是很重要的原因。
### 5.5.1 中間值
如果我們想以對異常值不太敏感的方式總結數據,我們可以使用另一種稱為 _ 中位數 _ 的統計。如果我們按大小來排序所有的值,那么中值就是中間值。如果有一個偶數的值,那么中間會有兩個值,在這種情況下,我們取這兩個數字的平均值(即中間點)。
讓我們來看一個例子。假設我們要總結以下值:
```r
# create example data frame
dataDf <-
tibble(
values = c(8, 6, 3, 14, 12, 7, 6, 4, 9)
)
pander(dataDf)
```
<colgroup><col style="width: 11%"></colgroup>
| 價值觀 |
| --- |
| 8 個 |
| 6 |
| 三 |
| 14 |
| 12 個 |
| 7 |
| 6 |
| 4 |
| 9 |
如果我們對這些值進行排序:
```r
# sort values and print
dataDf <-
dataDf %>%
arrange(values)
pander(dataDf)
```
<colgroup><col style="width: 11%"></colgroup>
| values |
| --- |
| 3 |
| 4 |
| 6 |
| 6 |
| 7 |
| 8 |
| 9 |
| 12 |
| 14 |
中間值是中間值,在本例中是 9 個值中的第 5 個。
平均值最小化平方誤差之和,而中位數最小化一個微小的不同數量:絕對誤差之和。這就解釋了為什么它對異常值不那么敏感——與采用絕對值相比,平方化會加劇較大誤差的影響。我們可以在收入示例中看到這一點:
```r
# print income table
pander(incomeDf)
```
<colgroup><col style="width: 13%"> <col style="width: 13%"></colgroup>
| income | person |
| --- | --- |
| 48000 | Joe |
| 64000 | Karen |
| 58000 | Mark |
| 72000 | Andrea |
| 66000 | Pat |
| 5.4e+07 | Beyonce |
```r
sprintf('Mean income: %.2f',mean(incomeDf$income))
```
```r
## [1] "Mean income: 9051333.33"
```
```r
sprintf('Median income: %.2f',median(incomeDf$income))
```
```r
## [1] "Median income: 65000.00"
```
中位數更能代表整個群體,對一個大的離群值不太敏感。
既然如此,我們為什么要用平均數呢?正如我們將在后面的章節中看到的,平均值是“最佳”估計值,因為與其他估計值相比,它在樣本之間的差異較小。這取決于我們是否值得考慮對潛在異常值的敏感性——統計數據都是關于權衡的。
- 前言
- 0.1 本書為什么存在?
- 0.2 你不是統計學家-我們為什么要聽你的?
- 0.3 為什么是 R?
- 0.4 數據的黃金時代
- 0.5 開源書籍
- 0.6 確認
- 1 引言
- 1.1 什么是統計思維?
- 1.2 統計數據能為我們做什么?
- 1.3 統計學的基本概念
- 1.4 因果關系與統計
- 1.5 閱讀建議
- 2 處理數據
- 2.1 什么是數據?
- 2.2 測量尺度
- 2.3 什么是良好的測量?
- 2.4 閱讀建議
- 3 概率
- 3.1 什么是概率?
- 3.2 我們如何確定概率?
- 3.3 概率分布
- 3.4 條件概率
- 3.5 根據數據計算條件概率
- 3.6 獨立性
- 3.7 逆轉條件概率:貝葉斯規則
- 3.8 數據學習
- 3.9 優勢比
- 3.10 概率是什么意思?
- 3.11 閱讀建議
- 4 匯總數據
- 4.1 為什么要總結數據?
- 4.2 使用表格匯總數據
- 4.3 分布的理想化表示
- 4.4 閱讀建議
- 5 將模型擬合到數據
- 5.1 什么是模型?
- 5.2 統計建模:示例
- 5.3 什么使模型“良好”?
- 5.4 模型是否太好?
- 5.5 最簡單的模型:平均值
- 5.6 模式
- 5.7 變異性:平均值與數據的擬合程度如何?
- 5.8 使用模擬了解統計數據
- 5.9 Z 分數
- 6 數據可視化
- 6.1 數據可視化如何拯救生命
- 6.2 繪圖解剖
- 6.3 使用 ggplot 在 R 中繪制
- 6.4 良好可視化原則
- 6.5 最大化數據/墨水比
- 6.6 避免圖表垃圾
- 6.7 避免數據失真
- 6.8 謊言因素
- 6.9 記住人的局限性
- 6.10 其他因素的修正
- 6.11 建議閱讀和視頻
- 7 取樣
- 7.1 我們如何取樣?
- 7.2 采樣誤差
- 7.3 平均值的標準誤差
- 7.4 中心極限定理
- 7.5 置信區間
- 7.6 閱讀建議
- 8 重新采樣和模擬
- 8.1 蒙特卡羅模擬
- 8.2 統計的隨機性
- 8.3 生成隨機數
- 8.4 使用蒙特卡羅模擬
- 8.5 使用模擬統計:引導程序
- 8.6 閱讀建議
- 9 假設檢驗
- 9.1 無效假設統計檢驗(NHST)
- 9.2 無效假設統計檢驗:一個例子
- 9.3 無效假設檢驗過程
- 9.4 現代環境下的 NHST:多重測試
- 9.5 閱讀建議
- 10 置信區間、效應大小和統計功率
- 10.1 置信區間
- 10.2 效果大小
- 10.3 統計能力
- 10.4 閱讀建議
- 11 貝葉斯統計
- 11.1 生成模型
- 11.2 貝葉斯定理與逆推理
- 11.3 進行貝葉斯估計
- 11.4 估計后驗分布
- 11.5 選擇優先權
- 11.6 貝葉斯假設檢驗
- 11.7 閱讀建議
- 12 分類關系建模
- 12.1 示例:糖果顏色
- 12.2 皮爾遜卡方檢驗
- 12.3 應急表及雙向試驗
- 12.4 標準化殘差
- 12.5 優勢比
- 12.6 貝葉斯系數
- 12.7 超出 2 x 2 表的分類分析
- 12.8 注意辛普森悖論
- 13 建模持續關系
- 13.1 一個例子:仇恨犯罪和收入不平等
- 13.2 收入不平等是否與仇恨犯罪有關?
- 13.3 協方差和相關性
- 13.4 相關性和因果關系
- 13.5 閱讀建議
- 14 一般線性模型
- 14.1 線性回歸
- 14.2 安裝更復雜的模型
- 14.3 變量之間的相互作用
- 14.4“預測”的真正含義是什么?
- 14.5 閱讀建議
- 15 比較方法
- 15.1 學生 T 考試
- 15.2 t 檢驗作為線性模型
- 15.3 平均差的貝葉斯因子
- 15.4 配對 t 檢驗
- 15.5 比較兩種以上的方法
- 16 統計建模過程:一個實例
- 16.1 統計建模過程
- 17 做重復性研究
- 17.1 我們認為科學應該如何運作
- 17.2 科學(有時)是如何工作的
- 17.3 科學中的再現性危機
- 17.4 有問題的研究實踐
- 17.5 進行重復性研究
- 17.6 進行重復性數據分析
- 17.7 結論:提高科學水平
- 17.8 閱讀建議
- References