
## 12.3 應急表及雙向試驗
我們經常使用卡方檢驗的另一種方法是詢問兩個分類變量是否相互關聯。作為一個更現實的例子,讓我們來考慮一個問題,當一個黑人司機被警察攔下時,他們是否比一個白人司機更有可能被搜查,斯坦福公開警務項目([https://open policing.stanford.edu/](https://openpolicing.stanford.edu/))研究了這個問題,并提供了我們可以用來分析問題的數據。我們將使用來自康涅狄格州的數據,因為它們相當小。首先清理這些數據,以刪除所有不必要的數據(參見 code/process_ct_data.py)。
```r
# load police stop data
stopData <-
read_csv("data/CT_data_cleaned.csv") %>%
rename(searched = search_conducted)
```
表示分類分析數據的標準方法是通過 _ 列聯表 _,列聯表顯示了屬于每個變量值的每個可能組合的觀測值的數量或比例。
讓我們計算一下警察搜索數據的應急表:
```r
# compute and print two-way contingency table
summaryDf2way <-
stopData %>%
count(searched, driver_race) %>%
arrange(driver_race, searched)
summaryContingencyTable <-
summaryDf2way %>%
spread(driver_race, n)
pander(summaryContingencyTable)
```
<colgroup><col style="width: 15%"> <col style="width: 11%"> <col style="width: 11%"></colgroup>
| 已搜索 | 黑色 | 白色 |
| --- | --- | --- |
| 錯誤的 | 36244 個 | 239241 個 |
| 真的 | 1219 年 | 3108 個 |
使用比例而不是原始數字查看應急表也很有用,因為它們更容易在視覺上進行比較。
```r
# Compute and print contingency table using proportions
# rather than raw frequencies
summaryContingencyTableProportion <-
summaryContingencyTable %>%
mutate(
Black = Black / nrow(stopData), #count of Black individuals searched / total searched
White = White / nrow(stopData)
)
pander(summaryContingencyTableProportion, round = 4)
```
<colgroup><col style="width: 15%"> <col style="width: 12%"> <col style="width: 12%"></colgroup>
| searched | Black | White |
| --- | --- | --- |
| FALSE | 0.1295 年 | 0.855 個 |
| TRUE | 0.0044 美元 | 0.0111 個 |
Pearson 卡方檢驗允許我們檢驗觀察到的頻率是否與預期頻率不同,因此我們需要確定如果搜索和種族不相關,我們期望在每個細胞中出現的頻率,我們可以定義為 _ 獨立。_ 請記住,如果 x 和 y 是獨立的,那么:
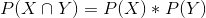
也就是說,零獨立假設下的聯合概率僅僅是每個變量的 _ 邊際 _ 概率的乘積。邊際概率只是每一個事件發生的概率,與其他事件無關。我們可以計算這些邊際概率,然后將它們相乘,得到獨立狀態下的預期比例。
| | 黑色 | 白色 | |
| --- | --- | --- | --- |
| 未搜索 | P(ns)*P(b) | P(ns)*P(w) | P(納秒) |
| 已搜索 | P(S)*P(B) | P(S)*P(W) | P(S) |
| | P(B) | P(寬) | |
我們可以使用稱為“外積”的線性代數技巧(通過`outer()`函數)來輕松計算。
```r
# first, compute the marginal probabilities
# probability of being each race
summaryDfRace <-
stopData %>%
count(driver_race) %>% #count the number of drivers of each race
mutate(
prop = n / sum(n) #compute the proportion of each race out of all drivers
)
# probability of being searched
summaryDfStop <-
stopData %>%
count(searched) %>% #count the number of searched vs. not searched
mutate(
prop = n / sum(n) # compute proportion of each outcome out all traffic stops
)
```
```r
# second, multiply outer product by n (all stops) to compute expected frequencies
expected <- outer(summaryDfRace$prop, summaryDfStop$prop) * nrow(stopData)
# create a data frame of expected frequencies for each race
expectedDf <-
data.frame(expected, driverRace = c("Black", "White")) %>%
rename(
NotSearched = X1,
Searched = X2
)
# tidy the data frame
expectedDfTidy <-
gather(expectedDf, searched, n, -driverRace) %>%
arrange(driverRace, searched)
```
```r
# third, add expected frequencies to the original summary table
# and fourth, compute the standardized squared difference between
# the observed and expected frequences
summaryDf2way <-
summaryDf2way %>%
mutate(expected = expectedDfTidy$n)
summaryDf2way <-
summaryDf2way %>%
mutate(stdSqDiff = (n - expected)**2 / expected)
pander(summaryDf2way)
```
<colgroup><col style="width: 15%"> <col style="width: 19%"> <col style="width: 12%"> <col style="width: 15%"> <col style="width: 15%"></colgroup>
| searched | 車手比賽 | N 號 | 預期 | 標準平方差 |
| --- | --- | --- | --- | --- |
| FALSE | 黑色 | 36244 | 36883.67 個 | 2009 年 11 月 |
| TRUE | Black | 1219 | 579.33 條 | 第 706.31 條 |
| FALSE | 白色 | 239241 | 238601.3 條 | 1.71 條 |
| TRUE | White | 3108 | 3747.67 美元 | 109.18 條 |
```r
# finally, compute chi-squared statistic by
# summing the standardized squared differences
chisq <- sum(summaryDf2way$stdSqDiff)
sprintf("Chi-squared value = %0.2f", chisq)
```
```r
## [1] "Chi-squared value = 828.30"
```
在計算了卡方統計之后,我們現在需要將其與卡方分布進行比較,以確定它與我們在無效假設下的期望相比有多極端。這種分布的自由度是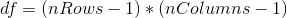——因此,對于類似于這里的 2x2 表,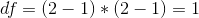。這里的直覺是計算預期頻率需要我們使用三個值:觀察總數和兩個變量的邊際概率。因此,一旦計算出這些值,就只有一個數字可以自由變化,因此有一個自由度。鑒于此,我們可以計算卡方統計的 p 值:
```r
pval <- pchisq(chisq, df = 1, lower.tail = FALSE)
sprintf("p-value = %e", pval)
```
```r
## [1] "p-value = 3.795669e-182"
```
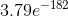的 p 值非常小,表明如果種族和警察搜查之間真的沒有關系,觀察到的數據就不太可能,因此我們應該拒絕獨立性的無效假設。
我們還可以使用 r 中的`chisq.test()`函數輕松執行此測試:
```r
# first need to rearrange the data into a 2x2 table
summaryDf2wayTable <-
summaryDf2way %>%
dplyr::select(-expected, -stdSqDiff) %>%
spread(searched, n) %>%
dplyr::select(-driver_race)
chisqTestResult <- chisq.test(summaryDf2wayTable, 1, correct = FALSE)
chisqTestResult
```
```r
##
## Pearson's Chi-squared test
##
## data: summaryDf2wayTable
## X-squared = 800, df = 1, p-value <2e-16
```
- 前言
- 0.1 本書為什么存在?
- 0.2 你不是統計學家-我們為什么要聽你的?
- 0.3 為什么是 R?
- 0.4 數據的黃金時代
- 0.5 開源書籍
- 0.6 確認
- 1 引言
- 1.1 什么是統計思維?
- 1.2 統計數據能為我們做什么?
- 1.3 統計學的基本概念
- 1.4 因果關系與統計
- 1.5 閱讀建議
- 2 處理數據
- 2.1 什么是數據?
- 2.2 測量尺度
- 2.3 什么是良好的測量?
- 2.4 閱讀建議
- 3 概率
- 3.1 什么是概率?
- 3.2 我們如何確定概率?
- 3.3 概率分布
- 3.4 條件概率
- 3.5 根據數據計算條件概率
- 3.6 獨立性
- 3.7 逆轉條件概率:貝葉斯規則
- 3.8 數據學習
- 3.9 優勢比
- 3.10 概率是什么意思?
- 3.11 閱讀建議
- 4 匯總數據
- 4.1 為什么要總結數據?
- 4.2 使用表格匯總數據
- 4.3 分布的理想化表示
- 4.4 閱讀建議
- 5 將模型擬合到數據
- 5.1 什么是模型?
- 5.2 統計建模:示例
- 5.3 什么使模型“良好”?
- 5.4 模型是否太好?
- 5.5 最簡單的模型:平均值
- 5.6 模式
- 5.7 變異性:平均值與數據的擬合程度如何?
- 5.8 使用模擬了解統計數據
- 5.9 Z 分數
- 6 數據可視化
- 6.1 數據可視化如何拯救生命
- 6.2 繪圖解剖
- 6.3 使用 ggplot 在 R 中繪制
- 6.4 良好可視化原則
- 6.5 最大化數據/墨水比
- 6.6 避免圖表垃圾
- 6.7 避免數據失真
- 6.8 謊言因素
- 6.9 記住人的局限性
- 6.10 其他因素的修正
- 6.11 建議閱讀和視頻
- 7 取樣
- 7.1 我們如何取樣?
- 7.2 采樣誤差
- 7.3 平均值的標準誤差
- 7.4 中心極限定理
- 7.5 置信區間
- 7.6 閱讀建議
- 8 重新采樣和模擬
- 8.1 蒙特卡羅模擬
- 8.2 統計的隨機性
- 8.3 生成隨機數
- 8.4 使用蒙特卡羅模擬
- 8.5 使用模擬統計:引導程序
- 8.6 閱讀建議
- 9 假設檢驗
- 9.1 無效假設統計檢驗(NHST)
- 9.2 無效假設統計檢驗:一個例子
- 9.3 無效假設檢驗過程
- 9.4 現代環境下的 NHST:多重測試
- 9.5 閱讀建議
- 10 置信區間、效應大小和統計功率
- 10.1 置信區間
- 10.2 效果大小
- 10.3 統計能力
- 10.4 閱讀建議
- 11 貝葉斯統計
- 11.1 生成模型
- 11.2 貝葉斯定理與逆推理
- 11.3 進行貝葉斯估計
- 11.4 估計后驗分布
- 11.5 選擇優先權
- 11.6 貝葉斯假設檢驗
- 11.7 閱讀建議
- 12 分類關系建模
- 12.1 示例:糖果顏色
- 12.2 皮爾遜卡方檢驗
- 12.3 應急表及雙向試驗
- 12.4 標準化殘差
- 12.5 優勢比
- 12.6 貝葉斯系數
- 12.7 超出 2 x 2 表的分類分析
- 12.8 注意辛普森悖論
- 13 建模持續關系
- 13.1 一個例子:仇恨犯罪和收入不平等
- 13.2 收入不平等是否與仇恨犯罪有關?
- 13.3 協方差和相關性
- 13.4 相關性和因果關系
- 13.5 閱讀建議
- 14 一般線性模型
- 14.1 線性回歸
- 14.2 安裝更復雜的模型
- 14.3 變量之間的相互作用
- 14.4“預測”的真正含義是什么?
- 14.5 閱讀建議
- 15 比較方法
- 15.1 學生 T 考試
- 15.2 t 檢驗作為線性模型
- 15.3 平均差的貝葉斯因子
- 15.4 配對 t 檢驗
- 15.5 比較兩種以上的方法
- 16 統計建模過程:一個實例
- 16.1 統計建模過程
- 17 做重復性研究
- 17.1 我們認為科學應該如何運作
- 17.2 科學(有時)是如何工作的
- 17.3 科學中的再現性危機
- 17.4 有問題的研究實踐
- 17.5 進行重復性研究
- 17.6 進行重復性數據分析
- 17.7 結論:提高科學水平
- 17.8 閱讀建議
- References