
## 14.1 線性回歸
我們還可以使用一般線性模型來描述兩個變量之間的關系,并決定這種關系是否具有統計意義;此外,該模型允許我們在給定獨立變量的一些新值的情況下預測因變量的值。最重要的是,一般線性模型將允許我們建立包含多個獨立變量的模型,而相關性只能告訴我們兩個獨立變量之間的關系。
我們為此使用的 GLM 的特定版本稱為 _ 線性回歸 _。術語 _ 回歸 _ 是由 Francis Galton 創造的,他注意到,當他比較父母和他們的孩子的某些特征(如身高)時,極端父母的孩子(即非常高或非常矮的父母)通常比他們的父母更接近平均值。這是非常重要的一點,我們將回到下面。
線性回歸模型的最簡單版本(具有單個獨立變量)可以表示為:

值告訴我們,給定 x 中一個單位的變化,y 會發生多大的變化。截距是一個整體偏移量,它告訴我們當時,y 會有多大的值;從我們早期的建模討論中,您可能會記得,這對于建模過度非常重要。所有數據的大小,即使從未真正達到零。誤差項指的是模型一旦被擬合后所剩下的一切。如果我們想知道如何預測 y(我們稱之為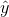),那么我們可以刪除錯誤項:
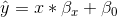
圖[14.2](#fig:LinearRegression)顯示了應用于研究時間示例的此模型的示例。

圖 14.2 研究時間數據的線性回歸解用藍色表示。當 x 變量等于零時,截距值等于 y 變量的預測值;這用虛線黑線表示。β值等于直線的斜率,也就是 x 單位變化的 y 變化量。紅色虛線示意性地顯示了這一點,它顯示了學習時間單單位增加的年級增加程度。
### 14.1.1 回歸平均值
回歸到平均值的概念 _ 是 Galton 對科學的重要貢獻之一,在我們解釋實驗數據分析結果時,它仍然是理解的關鍵點。假設我們想研究閱讀干預對貧困讀者表現的影響。為了驗證我們的假設,我們可能會去一所學校,在一些閱讀測試中招募那些分布在 25%最底層的人,進行干預,然后檢查他們的表現。假設干預實際上沒有效果,每個人的閱讀分數只是來自正態分布的獨立樣本。我們可以模擬:_
```r
# create simulated data for regression to the mean example
nstudents <- 100
readingScores <- data.frame(
#random normal distribution of scores for test 1
test1 = rnorm(n = nstudents, mean = 0, sd = 1) * 10 + 100,
#random normal distribution of scores for test 2
test2 = rnorm(n = nstudents, mean = 0, sd = 1) * 10 + 100
)
# select the students in the bottom 25% on the first test
cutoff <- quantile(readingScores$test1, 0.25)
readingScores <-
readingScores %>%
mutate(badTest1 = test1 < cutoff) %>%
dplyr::filter(badTest1 == TRUE) %>%
summarize(
test1mean = mean(test1),
test2mean = mean(test2)
) %>%
pander()
```
如果我們看看第一次和第二次考試的平均成績之間的差異,似乎干預對這些學生有了很大的幫助,因為他們的分數在考試中提高了超過 10 分!然而,我們知道事實上,學生根本沒有進步,因為在這兩種情況下,分數只是從隨機正態分布中選擇的。事實上,一些受試者在第一次考試中由于隨機的機會得分很低。如果我們只根據第一次考試的分數來選擇這些科目,那么在第二次考試中,即使沒有培訓的效果,他們也會回到整個組的平均水平。這就是為什么我們需要一個未經治療的對照組(htg0)來解釋隨時間變化的讀數;否則我們很可能會被回歸到平均值所欺騙。
### 14.1.2 估算線性回歸參數
我們通常使用 _ 線性代數 _ 從數據中估計線性模型的參數,這是應用于向量和矩陣的代數形式。如果你不熟悉線性代數,不用擔心——你實際上不需要在這里使用它,因為 R 將為我們做所有的工作。然而,線性代數中的一個簡短的偏移可以提供一些關于模型參數如何在實踐中估計的見解。
首先,讓我們介紹向量和矩陣的概念;您已經在 r 的上下文中遇到過它們,但是我們將在這里回顧它們。矩陣是一組排列在一個正方形或矩形中的數字,這樣就有一個或多個 _ 維度 _ 可供矩陣變化。通常在行中放置不同的觀察單位(如人),在列中放置不同的變量。讓我們從上面獲取學習時間數據。我們可以將這些數字排列在一個矩陣中,這個矩陣有八行(每個學生一行)和兩列(一列用于學習時間,一列用于成績)。如果你在想“這聽起來像 R 中的數據幀”,你是完全正確的!實際上,數據幀是矩陣的專用版本,我們可以使用`as.matrix()`函數將數據幀轉換為矩陣。
```r
df_matrix <-
df %>%
dplyr::select(studyTime, grade) %>%
as.matrix()
```
我們可以將線性代數中的一般線性模型寫成如下:
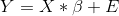
這看起來非常像我們之前使用的方程,除了字母都是大寫的,這意味著它們是向量這一事實。
我們知道等級數據進入 Y 矩陣,但是什么進入了矩陣?請記住,在我們最初討論線性回歸時,除了我們感興趣的獨立變量之外,我們還需要添加一個常量,因此我們的矩陣(我們稱之為 _ 設計矩陣 _)需要包括兩列:一列表示研究時間變量,另一列表示研究時間變量,以及 mn,每個個體具有相同的值(我們通常用所有值填充)。我們可以以圖形方式查看結果設計矩陣(參見圖[14.3](#fig:GLMmatrix))。
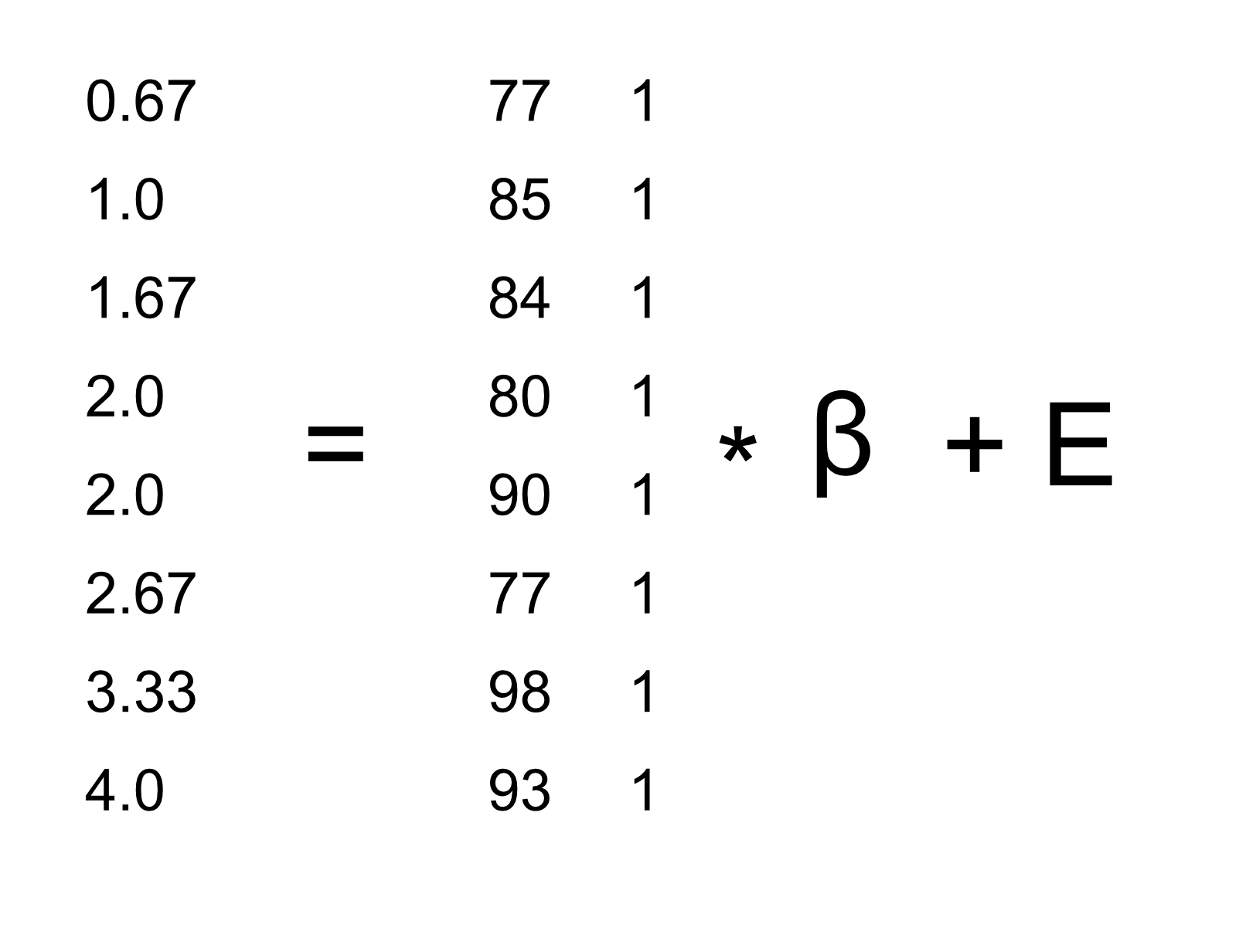
圖 14.3 用矩陣代數描述研究時間數據的線性模型。
矩陣乘法規則告訴我們,矩陣的維數必須相互匹配;在這種情況下,設計矩陣的維數為 8(行)x 2(列),Y 變量的維數為 8 x 1。因此,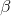矩陣需要尺寸為 2 x 1,因為一個 8 x 2 矩陣乘以一個 2 x 1 矩陣會得到一個 8 x 1 矩陣(作為匹配的中間尺寸退出)。對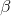矩陣中的兩個值的解釋是,它們分別乘以研究時間和 1,得出每個個體的估計等級。我們還可以將線性模型視為每個個體的一組單獨方程:
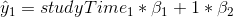

……

記住,我們的目標是根據已知的和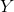值確定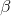的最佳擬合值。這樣做的一個簡單方法是使用簡單代數來求解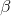——這里我們去掉了錯誤項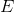,因為它超出了我們的控制范圍:

這里的挑戰是和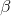現在是矩陣,而不是單個數字——但是線性代數的規則告訴我們如何除以矩陣,這與乘以矩陣的 _ 逆 _ 相同(稱為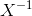)。我們可以在 r 中這樣做:
```r
# compute beta estimates using linear algebra
Y <- as.matrix(df$grade) #create Y variable 8 x 1 matrix
X <- matrix(0, nrow = 8, ncol = 2) #create X variable 8 x 2 matrix
X[, 1] <- as.matrix(df$studyTime) #assign studyTime values to first column in X matrix
X[, 2] <- 1 #assign constant of 1 to second column in X matrix
# compute inverse of X using ginv()
# %*% is the R matrix multiplication operator
beta_hat <- ginv(X) %*% Y #multiple the inverse of X by Y
print(beta_hat)
```
```r
## [,1]
## [1,] 4.3
## [2,] 76.2
```
對于認真使用統計方法感興趣的人,強烈鼓勵他們花一些時間學習線性代數,因為它為幾乎所有用于標準統計的工具提供了基礎。
### 14.1.3 相關性與回歸的關系
相關系數與回歸系數有著密切的關系。記住,皮爾遜的相關系數是以協方差的比值和 x 和 y 的標準差的乘積來計算的:
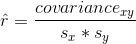
而回歸β的計算公式為:
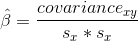
基于這兩個方程,我們可以得出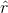和之間的關系:

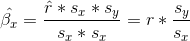
也就是說,回歸斜率等于相關值乘以 y 和 x 的標準差之比。這告訴我們的一件事是,當 x 和 y 的標準差相同時(例如,當數據被轉換為 z 分數時),則相關估計等于 l 回歸斜率估計。
### 14.1.4 回歸模型的標準誤差
如果我們想對回歸參數估計進行推斷,那么我們還需要對它們的可變性進行估計。為了計算這一點,我們首先需要計算模型的 _ 殘差方差 _ 或 _ 誤差方差 _——也就是說,依賴變量中有多少可變性不是由模型解釋的。模型殘差計算如下:
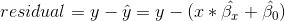
然后我們計算 _ 平方誤差之和(sse)_:
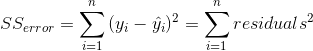
由此我們計算出 _ 的均方誤差 _:
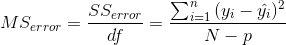
其中,自由度(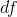)是通過從觀測值()中減去估計參數(本例中為 2 個參數:和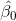)來確定的。一旦我們有了均方誤差,我們就可以將模型的標準誤差計算為:
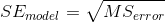
為了得到特定回歸參數估計的標準誤差,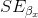,我們需要根據 x 變量平方和的平方根重新調整模型的標準誤差:
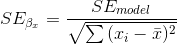
### 14.1.5 回歸參數的統計檢驗
一旦我們得到了參數估計值及其標準誤差,我們就可以計算出一個 _t_ 統計數據,告訴我們觀察到的參數估計值與無效假設下的某些預期值相比的可能性。在這種情況下,我們將根據無效假設(即)進行測試:

在 R 中,我們不需要手工計算這些值,因為它們由`lm()`函數自動返回給我們:
```r
summary(lmResult)
```
```r
##
## Call:
## lm(formula = grade ~ studyTime, data = df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -10.656 -2.719 0.125 4.703 7.469
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 76.16 5.16 14.76 6.1e-06 ***
## studyTime 4.31 2.14 2.01 0.091 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 6.4 on 6 degrees of freedom
## Multiple R-squared: 0.403, Adjusted R-squared: 0.304
## F-statistic: 4.05 on 1 and 6 DF, p-value: 0.0907
```
在這種情況下,我們看到截距明顯不同于零(這不是很有趣),并且研究時間對成績的影響微乎其微。
### 14.1.6 模型擬合優度的量化
有時量化模型在整體上與數據的匹配程度是很有用的,而做到這一點的一種方法是詢問模型對數據中的可變性有多大的解釋。這是使用一個名為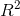的值(也稱為 _ 確定系數 _)來量化的。如果只有一個 x 變量,那么只需將相關系數平方即可輕松計算:
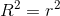
對于我們的研究時間數據,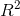=0.4,這意味著我們已經占了數據方差的 40%。
更一般地說,我們可以將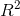看作是模型所占數據中方差分數的度量,可以通過將方差分解為多個分量來計算:

其中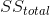是數據的方差(),并且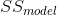和如本章前面所示進行計算。利用這個,我們可以計算確定系數為:
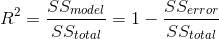
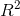的一個小值告訴我們,即使模型擬合具有統計意義,它也只能解釋數據中的少量信息。
- 前言
- 0.1 本書為什么存在?
- 0.2 你不是統計學家-我們為什么要聽你的?
- 0.3 為什么是 R?
- 0.4 數據的黃金時代
- 0.5 開源書籍
- 0.6 確認
- 1 引言
- 1.1 什么是統計思維?
- 1.2 統計數據能為我們做什么?
- 1.3 統計學的基本概念
- 1.4 因果關系與統計
- 1.5 閱讀建議
- 2 處理數據
- 2.1 什么是數據?
- 2.2 測量尺度
- 2.3 什么是良好的測量?
- 2.4 閱讀建議
- 3 概率
- 3.1 什么是概率?
- 3.2 我們如何確定概率?
- 3.3 概率分布
- 3.4 條件概率
- 3.5 根據數據計算條件概率
- 3.6 獨立性
- 3.7 逆轉條件概率:貝葉斯規則
- 3.8 數據學習
- 3.9 優勢比
- 3.10 概率是什么意思?
- 3.11 閱讀建議
- 4 匯總數據
- 4.1 為什么要總結數據?
- 4.2 使用表格匯總數據
- 4.3 分布的理想化表示
- 4.4 閱讀建議
- 5 將模型擬合到數據
- 5.1 什么是模型?
- 5.2 統計建模:示例
- 5.3 什么使模型“良好”?
- 5.4 模型是否太好?
- 5.5 最簡單的模型:平均值
- 5.6 模式
- 5.7 變異性:平均值與數據的擬合程度如何?
- 5.8 使用模擬了解統計數據
- 5.9 Z 分數
- 6 數據可視化
- 6.1 數據可視化如何拯救生命
- 6.2 繪圖解剖
- 6.3 使用 ggplot 在 R 中繪制
- 6.4 良好可視化原則
- 6.5 最大化數據/墨水比
- 6.6 避免圖表垃圾
- 6.7 避免數據失真
- 6.8 謊言因素
- 6.9 記住人的局限性
- 6.10 其他因素的修正
- 6.11 建議閱讀和視頻
- 7 取樣
- 7.1 我們如何取樣?
- 7.2 采樣誤差
- 7.3 平均值的標準誤差
- 7.4 中心極限定理
- 7.5 置信區間
- 7.6 閱讀建議
- 8 重新采樣和模擬
- 8.1 蒙特卡羅模擬
- 8.2 統計的隨機性
- 8.3 生成隨機數
- 8.4 使用蒙特卡羅模擬
- 8.5 使用模擬統計:引導程序
- 8.6 閱讀建議
- 9 假設檢驗
- 9.1 無效假設統計檢驗(NHST)
- 9.2 無效假設統計檢驗:一個例子
- 9.3 無效假設檢驗過程
- 9.4 現代環境下的 NHST:多重測試
- 9.5 閱讀建議
- 10 置信區間、效應大小和統計功率
- 10.1 置信區間
- 10.2 效果大小
- 10.3 統計能力
- 10.4 閱讀建議
- 11 貝葉斯統計
- 11.1 生成模型
- 11.2 貝葉斯定理與逆推理
- 11.3 進行貝葉斯估計
- 11.4 估計后驗分布
- 11.5 選擇優先權
- 11.6 貝葉斯假設檢驗
- 11.7 閱讀建議
- 12 分類關系建模
- 12.1 示例:糖果顏色
- 12.2 皮爾遜卡方檢驗
- 12.3 應急表及雙向試驗
- 12.4 標準化殘差
- 12.5 優勢比
- 12.6 貝葉斯系數
- 12.7 超出 2 x 2 表的分類分析
- 12.8 注意辛普森悖論
- 13 建模持續關系
- 13.1 一個例子:仇恨犯罪和收入不平等
- 13.2 收入不平等是否與仇恨犯罪有關?
- 13.3 協方差和相關性
- 13.4 相關性和因果關系
- 13.5 閱讀建議
- 14 一般線性模型
- 14.1 線性回歸
- 14.2 安裝更復雜的模型
- 14.3 變量之間的相互作用
- 14.4“預測”的真正含義是什么?
- 14.5 閱讀建議
- 15 比較方法
- 15.1 學生 T 考試
- 15.2 t 檢驗作為線性模型
- 15.3 平均差的貝葉斯因子
- 15.4 配對 t 檢驗
- 15.5 比較兩種以上的方法
- 16 統計建模過程:一個實例
- 16.1 統計建模過程
- 17 做重復性研究
- 17.1 我們認為科學應該如何運作
- 17.2 科學(有時)是如何工作的
- 17.3 科學中的再現性危機
- 17.4 有問題的研究實踐
- 17.5 進行重復性研究
- 17.6 進行重復性數據分析
- 17.7 結論:提高科學水平
- 17.8 閱讀建議
- References