
# 一、TensorFlow 簡介
曾經嘗試僅使用 NumPy 用 Python 編寫用于神經網絡的代碼的任何人都知道它很繁瑣。 為一個簡單的單層前饋網絡編寫代碼需要 40 條線,這增加了編寫代碼和執行時間方面的難度。
TensorFlow 使得一切變得更容易,更快捷,從而減少了實現想法與部署之間的時間。 在這本書中,您將學習如何發揮 TensorFlow 的功能來實現深度神經網絡。
在本章中,我們將介紹以下主題:
* 安裝 TensorFlow
* TensorFlow 中的 HelloWorld
* 了解 TensorFlow 程序結構
* 使用常量,變量和占位符
* 使用 TensorFlow 執行矩陣操作
* 使用數據流程圖
* 從 0.x 遷移到 1.x
* 使用 XLA 增強計算性能
* 調用 CPU/GPU 設備
* 將 TensorFlow 用于深度學習
* 基于 DNN 的問題所需的不同 Python 包
# 介紹
TensorFlow 是 Google Brain 團隊針對**深層神經網絡**(**DNN**)開發的功能強大的開源軟件庫。 它于 2015 年 11 月首次在 Apache 2.x 許可下提供; 截止到今天,其 [GitHub 存儲庫](https://github.com/tensorflow/tensorflow)提交了超過 17,000 次提交,在短短兩年內大約有 845 個貢獻者。 這本身就是 TensorFlow 受歡迎程度和性能的衡量標準。 下圖顯示了流行的深度學習框架的比較,可以明顯看出 TensorFlow 是其中的佼佼者:
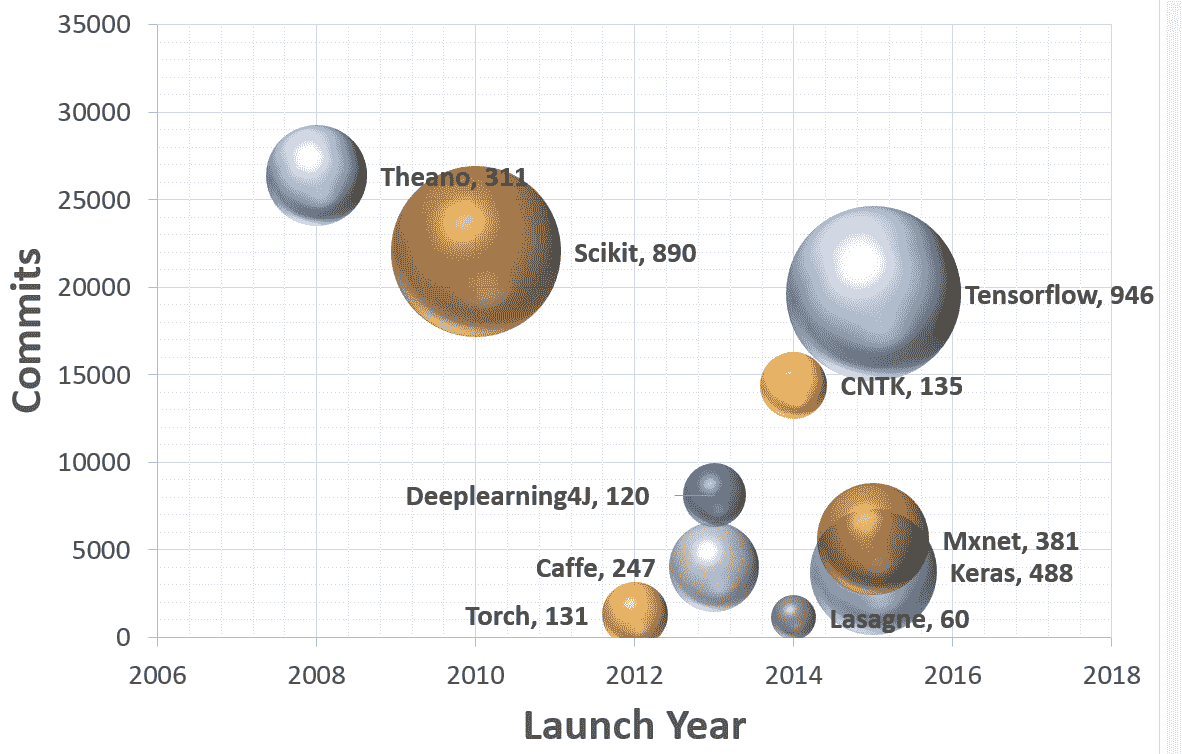
該圖是基于截至 2017 年 7 月 12 日的每個 Github 存儲庫中的數據。 每個氣泡都有一個圖例:(框架,貢獻者)。
首先讓我們了解 TensorFlow 到底是什么,以及為什么它在 DNN 研究人員和工程師中如此受歡迎。 TensorFlow 是開源深度學習庫,它允許使用單個 TensorFlow API 在一個或多個 CPU,服務器,臺式機或移動設備上的 GPU 上部署深度神經網絡計算。 您可能會問,還有很多其他深度學習庫,例如 Torch,Theano,Caffe 和 MxNet。 是什么讓 TensorFlow 與眾不同? TensorFlow 等大多數其他深度學習庫具有自動微分功能,許多都是開源的,大多數都支持 CPU/GPU 選項,具有經過預訓練的模型,并支持常用的 NN 架構,例如**循環神經網絡**(**RNN**),**卷積神經網絡**(**CNN**)和**深度置信網絡**(**DBN**)。 那么,TensorFlow 還有什么呢? 讓我們為您列出它們:
* 它適用于所有很酷的語言。 TensorFlow 適用于 Python,C++ ,Java,R 和 Go。
* TensorFlow 可在多個平臺上運行,甚至可以移動和分布式。
* 所有云提供商(AWS,Google 和 Azure)都支持它。
* Keras 是高級神經網絡 API,已與 TensorFlow 集成。
* 它具有更好的計算圖可視化效果,因為它是本機的,而 Torch/Theano 中的等效視圖看上去并不那么酷。
* TensorFlow 允許模型部署并易于在生產中使用。
* TensorFlow 具有很好的社區支持。
* TensorFlow 不僅僅是一個軟件庫; 它是一套包含 TensorFlow,TensorBoard 和 TensorServing 的軟件。
[Google 研究博客](https://research.googleblog.com/2016/11/celebrating-tensorflows-first-year.html)列出了世界各地使用 TensorFlow 進行的一些引人入勝的項目:
* Google 翻譯正在使用 TensorFlow 和**張量處理單元**(**TPU**)
* 可以使用基于強化學習的模型生成旋律的 Magenta 項目采用 TensorFlow
* 澳大利亞海洋生物學家正在使用 TensorFlow 來發現和了解瀕臨滅絕的海牛
* 一位日本農民使用 TensorFlow 開發了一個應用,該應用使用大小和形狀等物理參數對黃瓜進行分類
列表很長,使用 TensorFlow 的可能性更大。 本書旨在向您提供對應用于深度學習模型的 TensorFlow 的理解,以便您可以輕松地將它們適應于數據集并開發有用的應用。 每章都包含一組秘籍,涉及技術問題,依賴項,實際代碼及其理解。 我們已經將這些秘籍彼此構建在一起,以便在每一章的最后,您都擁有一個功能齊全的深度學習模型。
# 安裝 TensorFlow
在本秘籍中,您將學習如何在不同的 OS(Linux,Mac 和 Windows)上全新安裝 TensorFlow 1.3。 我們將找到安裝 TensorFlow 的必要要求。 TensorFlow 可以在 Ubuntu 和 macOS 上使用本機 PIP,Anaconda,Virtualenv 和 Docker 安裝。 對于 Windows 操作系統,可以使用本機 PIP 或 Anaconda。
由于 Anaconda 可以在所有三個 OS 上工作,并且提供了一種簡便的方法,不僅可以在同一系統上進行安裝,還可以在同一系統上維護不同的項目環境,因此在本書中,我們將集中精力使用 Anaconda 安裝 TensorFlow。 可從[這里](https://conda.io/docs/user-guide/index.html)閱讀有關 Anaconda 及其管理環境的更多詳細信息。
本書中的代碼已在以下平臺上經過測試:
* Windows 10,Anaconda 3,Python 3.5,TensorFlow GPU,CUDA 工具包 8.0,cuDNN v5.1,NVDIA?GTX 1070
* Windows 10 / Ubuntu 14.04 / Ubuntu 16.04 / macOS Sierra,Anaconda3,Python 3.5,TensorFlow(CPU)
# 準備
TensorFlow 安裝的前提條件是系統已安裝 Python 2.5 或更高版本。 本書中的秘籍是為 Python 3.5(Anaconda 3 發行版)設計的。 要準備安裝 TensorFlow,請首先確保已安裝 Anaconda。 您可以從[這里](https://www.continuum.io/downloads)下載并安裝適用于 Windows/macOS 或 Linux 的 Anaconda。
安裝后,您可以在終端窗口中使用以下命令來驗證安裝:
```py
conda --version
```
安裝 Anaconda 后,我們將繼續下一步,確定是安裝 TensorFlow CPU 還是 GPU。 盡管幾乎所有計算機都支持 TensorFlow CPU,但只有當計算機具有具有 CUDA 計算能力 3.0 或更高版本的 NVDIA?GPU 卡(臺式機最低為 NVDIA?GTX 650)時,才能安裝 TensorFlow GPU。
**CPU versus GPU: Central Processing Unit** (**CPU**) consists of a few cores (4-8) optimized for sequential serial processing. A **Graphical Processing Unit** (**GPU**) on the other hand has a massively parallel architecture consisting of thousands of smaller, more efficient cores (roughly in 1,000s) designed to handle multiple tasks simultaneously.
對于 TensorFlow GPU,必須安裝 CUDA 工具包 7.0 或更高版本,安裝正確的 NVDIA?驅動程序,并安裝 cuDNN v3 或更高版本。 在 Windows 上,此外,需要某些 DLL 文件。 您可以下載所需的 DLL 文件,也可以安裝 Visual Studio C++ 。 要記住的另一件事是 cuDNN 文件安裝在另一個目錄中。 需要確保目錄位于系統路徑中。 也可以選擇將相關文件復制到相應文件夾中的 CUDA 庫中。
# 操作步驟
我們按以下步驟進行:
1. 在命令行中使用以下命令創建 conda 環境(如果使用 Windows,最好在命令行中以管理員身份進行操作):
```py
conda create -n tensorflow python=3.5
```
2. 激活 conda 環境:
```py
# Windows
activate tensorflow
#Mac OS/ Ubuntu:
source activate tensorflow
```
3. 該命令應更改提示符:
```py
# Windows
(tensorflow)C:>
# Mac OS/Ubuntu
(tensorflow)$
```
4. 接下來,根據要在 conda 環境中安裝的 TensorFlow 版本,輸入以下命令:
```py
## Windows
# CPU Version only(tensorflow)C:>pip install --ignore-installed --upgrade https://storage.googleapis.com/tensorflow/windows/cpu/tensorflow-1.3.0cr2-cp35-cp35m-win_amd64.whl
# GPU Version
(tensorflow)C:>pip install --ignore-installed --upgrade https://storage.googleapis.com/tensorflow/windows/gpu/tensorflow_gpu-1.3.0cr2-cp35-cp35m-win_amd64.whl
```
```py
## Mac OS
# CPU only Version
(tensorflow)$ pip install --ignore-installed --upgrade https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-1.3.0cr2-py3-none-any.whl# GPU version(tensorflow)$ pip install --ignore-installed --upgrade https://storage.googleapis.com/tensorflow/mac/gpu/tensorflow_gpu-1.3.0cr2-py3-none-any.whl
```
```py
## Ubuntu# CPU only Version(tensorflow)$ pip install --ignore-installed --upgrade https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.3.0cr2-cp35-cp35m-linux_x86_64.whl# GPU Version
(tensorflow)$ pip install --ignore-installed --upgrade https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow_gpu-1.3.0cr2-cp35-cp35m-linux_x86_64.whl
```
5. 在命令行上,輸入`python`。
6. 編寫以下代碼:
```py
import tensorflow as tf
message = tf.constant('Welcome to the exciting world of Deep Neural Networks!')
with tf.Session() as sess:
print(sess.run(message).decode())
```
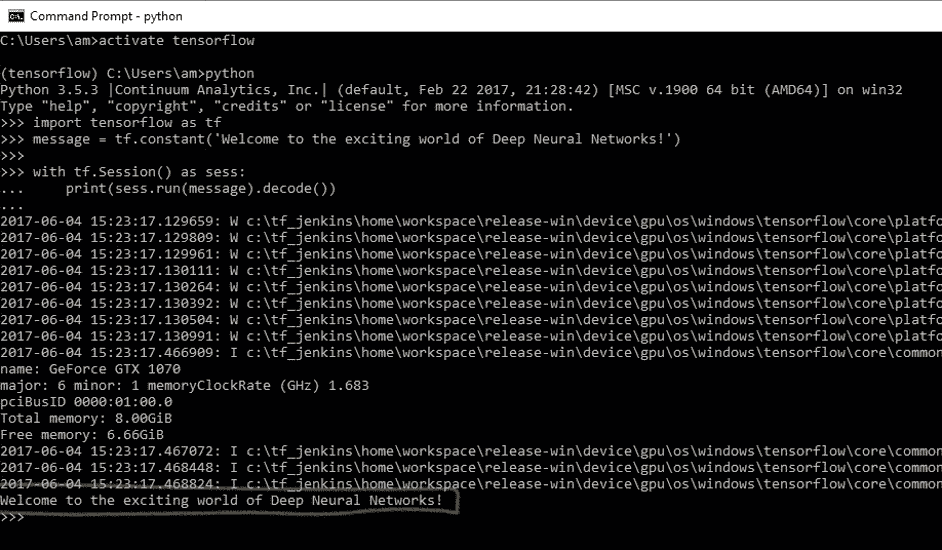
7. 您將收到以下輸出:
8. 在 Windows 上使用命令`deactivate`在 MAC/Ubuntu 上使用`source deactivate`在命令行上禁用 conda 環境。
# 工作原理
Google 使用 Wheels 標準分發 TensorFlow。 它是具有`.whl`擴展名的 ZIP 格式存檔。 Anaconda 3 中的默認 Python 解釋器 Python 3.6 沒有安裝輪子。 在撰寫本書時,僅對 Linux/Ubuntu 支持 Python 3.6。 因此,在創建 TensorFlow 環境時,我們指定了 Python 3.5。 這將在名為`tensorflow`的 conda 環境中安裝 PIP,python 和 wheel 以及其他一些包。
創建 conda 環境后,可使用`source activate/activate`命令激活該環境。 在激活的環境中,將`pip install`命令與適當的 TensorFlow-API URL 配合使用以安裝所需的 TensorFlow。 盡管存在使用 Conda forge 安裝 TensorFlow CPU 的 Anaconda 命令,但 TensorFlow 文檔建議使用`pip install`。 在 conda 環境中安裝 TensorFlow 之后,我們可以將其停用。 現在您可以執行第一個 TensorFlow 程序了。
程序運行時,您可能會看到一些警告(W)消息,一些信息(I)消息以及最后的代碼輸出:
```py
Welcome to the exciting world of Deep Neural Networks!
```
恭喜您成功安裝并執行了第一個 TensorFlow 代碼! 在下一個秘籍中,我們將更深入地研究代碼。
# 更多
此外,您還可以安裝 Jupyter 筆記本:
1. 如下安裝`ipython`:
```py
conda install -c anaconda ipython
```
2. 安裝`nb_conda_kernels`:
```py
conda install -channel=conda-forge nb_conda_kernels
```
3. 啟動`Jupyter notebook`:
```py
jupyter notebook
```
This will result in the opening of a new browser window.
如果您的系統上已經安裝了 TensorFlow,則可以使用`pip install --upgrade tensorflow`對其進行升級。
# TensorFlow 中的 HelloWorld
您學習用任何計算機語言編寫的第一個程序是 HelloWorld。 我們在本書中保持約定,并從 HelloWorld 程序開始。 我們在上一節中用于驗證 TensorFlow 安裝的代碼如下:
```py
import tensorflow as tf
message = tf.constant('Welcome to the exciting world of Deep Neural Networks!')
with tf.Session() as sess:
print(sess.run(message).decode())
```
讓我們深入研究這個簡單的代碼。
# 操作步驟
1. 導入`tensorflow`會導入 TensorFlow 庫,并允許您使用其出色的功能。
```py
import tensorflow as tf
```
2. 由于我們要打印的消息是一個常量字符串,因此我們使用`tf.constant`:
```py
message = tf.constant('Welcome to the exciting world of Deep Neural Networks!')
```
3. 要執行圖元素,我們需要使用`with`定義`Session`并使用`run`運行會話:
```py
with tf.Session() as sess:
print(sess.run(message).decode())
```
4. 根據您的計算機系統和操作系統,輸出包含一系列警告消息(W),聲稱如果針對您的特定計算機進行編譯,代碼可以更快地運行:
```py
The TensorFlow library wasn't compiled to use SSE instructions, but these are available on your machine and could speed up CPU computations.
The TensorFlow library wasn't compiled to use SSE2 instructions, but these are available on your machine and could speed up CPU computations.
The TensorFlow library wasn't compiled to use SSE3 instructions, but these are available on your machine and could speed up CPU computations.
The TensorFlow library wasn't compiled to use SSE4.1 instructions, but these are available on your machine and could speed up CPU computations.
The TensorFlow library wasn't compiled to use SSE4.2 instructions, but these are available on your machine and could speed up CPU computations.
The TensorFlow library wasn't compiled to use AVX instructions, but these are available on your machine and could speed up CPU computations.
The TensorFlow library wasn't compiled to use AVX2 instructions, but these are available on your machine and could speed up CPU computations.
The TensorFlow library wasn't compiled to use FMA instructions, but these are available on your machine and could speed up CPU computations.
```
5. 如果您正在使用 TensorFlow GPU,則還會獲得信息性消息列表(I),其中提供了所用設備的詳細信息:
```py
Found device 0 with properties:
name: GeForce GTX 1070
major: 6 minor: 1 memoryClockRate (GHz) 1.683
pciBusID 0000:01:00.0
Total memory: 8.00GiB
Free memory: 6.66GiB
DMA: 0
0: Y
Creating TensorFlow device (/gpu:0) -> (device: 0, name: GeForce GTX 1070, pci bus id: 0000:01:00.0)
```
6. 最后是我們要求在會話中打印的消息:
```py
Welcome to the exciting world of Deep Neural Networks
```
# 工作原理
前面的代碼分為三個主要部分。 **導入塊**包含我們的代碼將使用的所有庫; 在當前代碼中,我們僅使用 TensorFlow。 `import tensorflow as tf`語句使 Python 可以訪問所有 TensorFlow 的類,方法和符號。 第二塊包含圖定義部分; 在這里,我們建立了所需的計算圖。 在當前情況下,我們的圖僅由一個節點組成,張量常數消息由字節字符串`"Welcome to the exciting world of Deep Neural Networks"`組成。 我們代碼的第三部分是**作為會話運行計算圖**; 我們使用`with`關鍵字創建了一個會話。 最后,在會話中,我們運行上面創建的圖。
現在讓我們了解輸出。 收到的警告消息告訴您,TensorFlow 代碼可能會以更高的速度運行,這可以通過從源代碼安裝 TensorFlow 來實現(我們將在本章稍后的內容中進行此操作)。 收到的信息消息會通知您有關用于計算的設備。 對它們而言,這兩種消息都相當無害,但是如果您不希望看到它們,則添加以下兩行代碼即可解決問題:
```py
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
```
該代碼將忽略直到級別 2 的所有消息。級別 1 用于提供信息,級別 2 用于警告,級別 3 用于錯誤消息。
程序將打印運行圖的結果,該圖是使用`sess.run()`語句運行的。 運行圖的結果將饋送到`print`函數,可使用`decode`方法對其進行進一步修改。 `sess.run`求值消息中定義的張量。 `print`函數在`stdout`上打印求值結果:
```py
b'Welcome to the exciting world of Deep Neural Networks'
```
這表示結果是`byte string`。 要刪除字符串引號和`b`(用于**字節**),我們使用方法`decode()`。
# 了解 TensorFlow 程序結構
TensorFlow 與其他編程語言非常不同。 我們首先需要為要創建的任何神經網絡構建一個藍圖。 這是通過將程序分為兩個獨立的部分來完成的,即計算圖的定義及其執行。 首先,這對于常規程序員而言似乎很麻煩,但是執行圖與圖定義的這種分離賦予了 TensorFlow 強大的力量,即可以在多個平臺上工作和并行執行的能力。
**計算圖**:計算圖是節點和邊的網絡。 在本節中,定義了所有要使用的數據,即張量對象(常量,變量和占位符)和所有要執行的計算,即操作對象(簡稱為`ops`)。 每個節點可以有零個或多個輸入,但只有一個輸出。 網絡中的節點表示對象(張量和運算),邊緣表示在運算之間流動的張量。 計算圖定義了神經網絡的藍圖,但其中的張量尚無與其關聯的值。
為了構建計算圖,我們定義了我們需要執行的所有常量,變量和操作。 常量,變量和占位符將在下一個秘籍中處理。 數學運算將在矩陣處理的秘籍中詳細介紹。 在這里,我們使用一個簡單的示例來描述結構,該示例定義并執行圖以添加兩個向量。
**圖的執行**:使用會話對象執行圖。 *會話對象封裝了求值張量和操作對象的環境*。 這是實際計算和信息從一層傳輸到另一層的地方。 不同張量對象的值僅初始化,訪問并保存在會話對象中。 到目前為止,張量對象僅僅是抽象的定義,在這里它們就變成了現實。
# 操作步驟
我們按以下步驟進行:
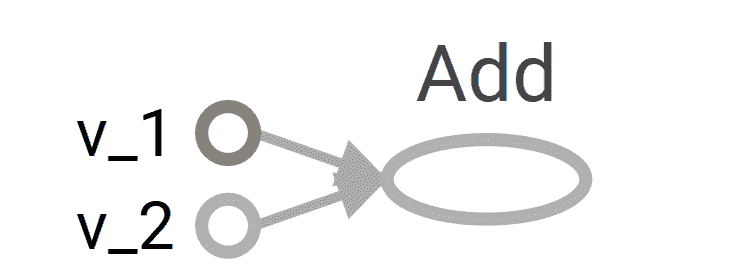
1. 我們考慮一個簡單的例子,將兩個向量相加,我們有兩個輸入向量`v_1`和`v_2`,它們將被作為`Add`操作的輸入。 我們要構建的圖如下:
2. 定義計算圖的相應代碼如下:
```py
v_1 = tf.constant([1,2,3,4])
v_2 = tf.constant([2,1,5,3])
v_add = tf.add(v_1,v_2) # You can also write v_1 + v_2 instead
```
3. 接下來,我們在會話中執行圖:
```py
with tf.Session() as sess:
prin(sess.run(v_add))
```
上面的兩個命令等效于以下代碼。 使用`with`塊的優點是不需要顯式關閉會話。
```py
sess = tf.Session()
print(ses.run(tv_add))
sess.close()
```
4. 這導致打印兩個向量的和:
```py
[3 3 8 7]
```
請記住,每個會話都需要使用`close()`方法顯式關閉,而`with`塊在結束時會隱式關閉會話。
# 工作原理
計算圖的構建非常簡單; 您將繼續添加變量和運算,并按照您逐層構建神經網絡的順序將它們傳遞(使張量流動)。 TensorFlow 還允許您使用`with tf.device()`將特定設備(CPU/GPU)與計算圖的不同對象一起使用。 在我們的示例中,計算圖由三個節點組成,`v_1`和`v_2`代表兩個向量,`Add`是對其執行的操作。
現在,要使該圖更生動,我們首先需要使用`tf.Session()`定義一個會話對象; 我們給會話對象起了名字`sess`。 接下來,我們使用 Session 類中定義的`run`方法運行它,如下所示:
```py
run (fetches, feed_dict=None, options=None, run_metadata)
```
這將求值`fetches`中的張量; 我們的示例在提取中具有張量`v_add`。 `run`方法將執行導致`v_add`的圖中的每個張量和每個操作。 如果您在提取中包含`v_1`而不是`v_add`,則結果將是向量`v_1`的值:
```py
[1,2,3,4]
```
訪存可以是單個張量/運算對象,也可以是多個張量/操作對象,例如,如果訪存為`[v_1, v_2, v_add]`,則輸出將為以下內容:
```py
[array([1, 2, 3, 4]), array([2, 1, 5, 3]), array([3, 3, 8, 7])]
```
在同一程序代碼中,我們可以有許多會話對象。
# 更多
您一定想知道為什么我們必須編寫這么多行代碼才能進行簡單的向量加法或打印一條小消息。 好吧,您可以很方便地以單線方式完成此工作:
```py
print(tf.Session().run(tf.add(tf.constant([1,2,3,4]),tf.constant([2,1,5,3]))))
```
編寫這種類型的代碼不僅會影響計算圖,而且在`for`循環中重復執行相同的操作(OP)時可能會占用大量內存。 養成顯式定義所有張量和操作對象的習慣,不僅使代碼更具可讀性,而且還有助于您以更簡潔的方式可視化計算圖。
使用 TensorBoard 可視化圖形是 TensorFlow 最有用的功能之一,尤其是在構建復雜的神經網絡時。 可以在圖對象的幫助下查看我們構建的計算圖。
如果您正在使用 Jupyter 筆記本或 Python Shell,則使用`tf.InteractiveSession`代替`tf.Session`更為方便。 `InteractiveSession`使其成為默認會話,因此您可以使用`eval()`直接調用運行張量對象,而無需顯式調用該會話,如以下示例代碼中所述:
```py
sess = tf.InteractiveSession()
v_1 = tf.constant([1,2,3,4])
v_2 = tf.constant([2,1,5,3])
v_add = tf.add(v_1,v_2)
print(v_add.eval())
sess.close()
```
# 使用常量,變量和占位符
用最簡單的術語講,TensorFlow 提供了一個庫來定義和執行帶有張量的不同數學運算。 張量基本上是 n 維矩陣。 所有類型的數據,即標量,向量和矩陣都是張量的特殊類型:
| **數據類型** | **張量** | **形狀** |
| --- | --- | --- |
| 標量 | 0 維張量 | `[]` |
| 向量 | 一維張量 | `[D0]` |
| 矩陣 | 二維張量 | `[D0, D1]` |
| 張量 | ND 張量 | `[D0, D1, D[n-1]]` |
TensorFlow 支持三種類型的張量:
* 常量
* 變量
* 占位符
**常量**:常數是無法更改其值的張量。
**變量**:當值需要在會話中更新時,我們使用變量張量。 例如,在神經網絡的情況下,需要在訓練期間更新權重,這是通過將權重聲明為變量來實現的。 在使用之前,需要對變量進行顯式初始化。 另一個要注意的重要事項是常量存儲在計算圖定義中。 每次加載圖時都會加載它們。 換句話說,它們是昂貴的內存。 另一方面,變量是分開存儲的。 它們可以存在于參數服務器上。
**占位符**:這些占位符用于將值輸入 TensorFlow 圖。 它們與`feed_dict`一起用于輸入數據。 它們通常用于在訓練神經網絡時提供新的訓練示例。 在會話中運行圖時,我們為占位符分配一個值。 它們使我們無需數據即可創建操作并構建計算圖。 需要注意的重要一點是,占位符不包含任何數據,因此也無需初始化它們。
# 操作步驟
讓我們從常量開始:
1. 我們可以聲明一個常量標量:
```py
t_1 = tf.constant(4)
```
2. 形狀為`[1,3]`的常數向量可以聲明如下:
```py
t_2 = tf.constant([4, 3, 2])
```
3. 為了創建一個所有元素都為零的張量,我們使用`tf.zeros()`。 該語句創建一個形狀為`[M,N]`和`dtype`的零矩陣(`int32`,`float32`等):
```py
tf.zeros([M,N],tf.dtype)
```
讓我們舉個例子:
```py
zero_t = tf.zeros([2,3],tf.int32)
# Results in an 2×3 array of zeros: [[0 0 0], [0 0 0]]
```
4. 我們還可以創建與現有 Numpy 數組形狀相同的張量常數或張量常數,如下所示:
```py
tf.zeros_like(t_2)
# Create a zero matrix of same shape as t_2
tf.ones_like(t_2)
# Creates a ones matrix of same shape as t_2
```
5. 我們可以將所有元素設置為一個來創建張量; 在這里,我們創建一個形狀為`[M,N]`的 1 矩陣:
```py
tf.ones([M,N],tf.dtype)
```
讓我們舉個例子:
```py
ones_t = tf.ones([2,3],tf.int32)
# Results in an 2×3 array of ones:[[1 1 1], [1 1 1]]
```
讓我們繼續序列:
1. 我們可以在總的`num`值內生成從開始到結束的一系列均勻間隔的向量:
```py
tf.linspace(start, stop, num)
```
2. 相應的值相差`(stop-start)/(num-1)`。
3. 讓我們舉個例子:
```py
range_t = tf.linspace(2.0,5.0,5)
# We get: [ 2\. 2.75 3.5 4.25 5\. ]
```
4. 從頭開始生成一系列數字(默認值為 0),以增量遞增(默認值為 1),直到但不包括限制:
```py
tf.range(start,limit,delta)
```
這是一個例子:
```py
range_t = tf.range(10)
# Result: [0 1 2 3 4 5 6 7 8 9]
```
TensorFlow 允許創建具有不同分布的**隨機張量**:
1. 要根據形狀為`[M,N]`的正態分布創建隨機值,其中均值(默認值為 0.0),標準差(默認值為 1.0),種子,我們可以使用以下方法:
```py
t_random = tf.random_normal([2,3], mean=2.0, stddev=4, seed=12)
# Result: [[ 0.25347459 5.37990952 1.95276058], [-1.53760314 1.2588985 2.84780669]]
```
2. 要從形狀為`[M,N]`的截斷正態分布(帶有平均值(默認值為 0.0)和標準差(默認值為 1.0))創建隨機值,我們可以使用以下方法:
```py
t_random = tf.truncated_normal([1,5], stddev=2, seed=12)
# Result: [[-0.8732627 1.68995488 -0.02361972 -1.76880157 -3.87749004]]
```
3. 要根據給定的形狀`[M,N]`的伽瑪分布在`[minval (default=0), maxval]`范圍內創建帶有種子的隨機值,請執行以下操作:
```py
t_random = tf.random_uniform([2,3], maxval=4, seed=12)
# Result: [[ 2.54461002 3.69636583 2.70510912], [ 2.00850058 3.84459829 3.54268885]]
```
4. 要將給定張量隨機裁剪為指定大小,請執行以下操作:
```py
tf.random_crop(t_random, [2,5],seed=12)
```
在這里,`t_random`是已經定義的張量。 這將導致從張量`t_random`中隨機裁剪出`[2,5]`張量。
很多時候,我們需要以隨機順序展示訓練樣本; 我們可以使用`tf.random_shuffle()`沿其第一維隨機調整張量。 如果`t_random`是我們想要改組的張量,那么我們使用以下代碼:
```py
tf.random_shuffle(t_random)
```
5. 隨機生成的張量受初始種子值的影響。 為了在多個運行或會話中獲得相同的隨機數,應將種子設置為恒定值。 當使用大量隨機張量時,我們可以使用`tf.set_random_seed()`為所有隨機生成的張量設置種子。 以下命令將所有會話的隨機張量的種子設置為`54`:
```py
tf.set_random_seed(54)
```
Seed can have only integer value.
現在轉到變量:
1. 它們是使用變量類創建的。 變量的定義還包括應從中初始化變量的常數/隨機值。 在下面的代碼中,我們創建兩個不同的張量變量`t_a`和`t_b`。 都將初始化為形狀為`[50, 50]`,`minval=0`和`maxval=10`的隨機均勻分布:
```py
rand_t = tf.random_uniform([50,50], 0, 10, seed=0)
t_a = tf.Variable(rand_t)
t_b = tf.Variable(rand_t)
```
變量通常用于表示神經網絡中的權重和偏置。
2. 在下面的代碼中,我們定義了兩個變量權重和偏差。 權重變量使用正態分布隨機初始化,均值為零,標準差為 2,權重的大小為`100×100`。 偏差由 100 個元素組成,每個元素都初始化為零。 在這里,我們還使用了可選的參數名稱來為計算圖中定義的變量命名。
```py
weights = tf.Variable(tf.random_normal([100,100],stddev=2))
bias = tf.Variable(tf.zeros[100], name = 'biases')
```
3. 在所有前面的示例中,變量的初始化源都是某個常量。 我們還可以指定一個要從另一個變量初始化的變量。 以下語句將從先前定義的權重中初始化`weight2`:
```py
weight2=tf.Variable(weights.initialized_value(), name='w2')
```
4. 變量的定義指定如何初始化變量,但是我們必須顯式初始化所有聲明的變量。 在計算圖的定義中,我們通過聲明一個初始化操作對象來實現:
```py
intial_op = tf.global_variables_initializer().
```
5. 在運行圖中,還可以使用`tf.Variable.initializer`分別初始化每個變量:
```py
bias = tf.Variable(tf.zeros([100,100]))
with tf.Session() as sess:
sess.run(bias.initializer)
```
6. **保存變量**:我們可以使用`Saver`類保存變量。 為此,我們定義一個`saver`操作對象:
```py
saver = tf.train.Saver()
```
7. 在常量和變量之后,我們來到最重要的元素占位符,它們用于將數據饋入圖。 我們可以使用以下內容定義占位符:
```py
tf.placeholder(dtype, shape=None, name=None)
```
8. `dtype`指定占位符的數據類型,并且在聲明占位符時必須指定。 在這里,我們為`x`定義一個占位符,并使用`feed_dict`為隨機`4×5`矩陣計算`y = 2 * x`:
```py
x = tf.placeholder("float")
y = 2 * x
data = tf.random_uniform([4,5],10)
with tf.Session() as sess:
x_data = sess.run(data)
print(sess.run(y, feed_dict = {x:x_data}))
```
# 工作原理
所有常量,變量和占位符都將在代碼的計算圖部分中定義。 如果在定義部分中使用`print`語句,我們將僅獲得有關張量類型的信息,而不是張量的值。
為了找出該值,我們需要創建會話圖,并顯式使用`run`命令,并將所需的張量值設為`fetches`:
```py
print(sess.run(t_1))
# Will print the value of t_1 defined in step 1
```
# 更多
很多時候,我們將需要恒定的大尺寸張量對象。 在這種情況下,為了優化內存,最好將它們聲明為具有可訓練標志設置為`False`的變量:
```py
t_large = tf.Variable(large_array, trainable = False)
```
TensorFlow 的設計可完美地與 Numpy 配合使用,因此所有 TensorFlow 數據類型均基于 Numpy 的數據類型。 使用`tf.convert_to_tensor()`,我們可以將給定值轉換為張量類型,并將其與 TensorFlow 函數和運算符一起使用。 該函數接受 Numpy 數組,Python 列表和 Python 標量,并允許與張量對象互操作。
下表列出了一些常見的 TensorFlow 支持的數據類型(摘自 [TensorFlow.org](http://TensorFlow.org) ):
| **數據類型** | **TensorFlow 類型** |
| --- | --- |
| `DT_FLOAT` | `tf.float32` |
| `DT_DOUBLE` | `tf.float64` |
| `DT_INT8` | `tf.int8` |
| `DT_UINT8` | `tf.uint8` |
| `DT_STRING` | `tf.string` |
| `DT_BOOL` | `tf.bool` |
| `DT_COMPLEX64` | `tf.complex64` |
| `DT_QINT32` | `tf.qint32` |
請注意,與 Python/Numpy 序列不同,TensorFlow 序列不可??迭代。 嘗試以下代碼:
```py
for i in tf.range(10)
```
您會得到一個錯誤:
```py
#TypeError("'Tensor' object is not iterable.")
```
# 使用 TensorFlow 執行矩陣操作
矩陣運算(例如執行乘法,加法和減法)是任何神經網絡中信號傳播中的重要運算。 通常在計算中,我們需要隨機,零,一或恒等矩陣。
本秘籍將向您展示如何獲取不同類型的矩陣以及如何對它們執行不同的矩陣操作。
# 操作步驟
我們按以下步驟進行:
1. 我們開始一個交互式會話,以便可以輕松求值結果:
```py
import tensorflow as tf
#Start an Interactive Session
sess = tf.InteractiveSession()
#Define a 5x5 Identity matrix
I_matrix = tf.eye(5)
print(I_matrix.eval())
# This will print a 5x5 Identity matrix
#Define a Variable initialized to a 10x10 identity matrix
X = tf.Variable(tf.eye(10))
X.initializer.run() # Initialize the Variable
print(X.eval())
# Evaluate the Variable and print the result
#Create a random 5x10 matrix
A = tf.Variable(tf.random_normal([5,10]))
A.initializer.run()
#Multiply two matrices
product = tf.matmul(A, X)
print(product.eval())
#create a random matrix of 1s and 0s, size 5x10
b = tf.Variable(tf.random_uniform([5,10], 0, 2, dtype= tf.int32))
b.initializer.run()
print(b.eval())
b_new = tf.cast(b, dtype=tf.float32)
#Cast to float32 data type
# Add the two matrices
t_sum = tf.add(product, b_new)
t_sub = product - b_new
print("A*X _b\n", t_sum.eval())
print("A*X - b\n", t_sub.eval())
```
2. 可以按以下方式執行其他一些有用的矩陣操作,例如按元素進行乘法,與標量相乘,按元素進行除法,按元素進行除法的余數:
```py
import tensorflow as tf
# Create two random matrices
a = tf.Variable(tf.random_normal([4,5], stddev=2))
b = tf.Variable(tf.random_normal([4,5], stddev=2))
#Element Wise Multiplication
A = a * b
#Multiplication with a scalar 2
B = tf.scalar_mul(2, A)
# Elementwise division, its result is
C = tf.div(a,b)
#Element Wise remainder of division
D = tf.mod(a,b)
init_op = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init_op)
writer = tf.summary.FileWriter('graphs', sess.graph)
a,b,A_R, B_R, C_R, D_R = sess.run([a , b, A, B, C, D])
print("a\n",a,"\nb\n",b, "a*b\n", A_R, "\n2*a*b\n", B_R, "\na/b\n", C_R, "\na%b\n", D_R)
writer.close()
```
`tf.div` returns a tensor of the same type as the first argument.
# 工作原理
矩陣的所有算術運算(例如加,乘,除,乘(元素乘),模和叉)都要求兩個張量矩陣的數據類型相同。 如果不是這樣,它們將產生錯誤。 我們可以使用`tf.cast()`將張量從一種數據類型轉換為另一種數據類型。
# 更多
如果我們要在整數張量之間進行除法,最好使用`tf.truediv(a,b)`,因為它首先將整數張量強制轉換為浮點,然后執行逐元素除法。
# 使用數據流程圖
TensorFlow 使用 TensorBoard 提供計算圖的圖形圖像。 這使得理解,調試和優化復雜的神經網絡程序變得很方便。 TensorBoard 還可以提供有關網絡執行情況的定量指標。 它讀取 TensorFlow 事件文件,其中包含您在運行 TensorFlow 會話時生成的摘要數據。
# 操作步驟
1. 使用 TensorBoard 的第一步是確定您想要的 OP 摘要。 對于 DNN,習慣上要知道損耗項(目標函數)如何隨時間變化。 在自適應學習率的情況下,學習率本身隨時間變化。 我們可以在`tf.summary.scalar` OP 的幫助下獲得所需項的摘要。 假設變量損失定義了誤差項,并且我們想知道它是如何隨時間變化的,那么我們可以這樣做,如下所示:
```py
loss = tf...
tf.summary.scalar('loss', loss)
```
2. 您還可以使用`tf.summary.histogram`可視化特定層的梯度,權重甚至輸出的分布:
```py
output_tensor = tf.matmul(input_tensor, weights) + biases
tf.summary.histogram('output', output_tensor)
```
3. 摘要將在會話期間生成。 您可以在計算圖中定義`tf.merge_all_summaries` OP,而不用單獨執行每個摘要操作,以便一次運行即可獲得所有摘要。
4. 然后需要使用`tf.summary.Filewriter`將生成的摘要寫入事件文件:
```py
writer = tf.summary.Filewriter('summary_dir', sess.graph)
```
5. 這會將所有摘要和圖寫入`'summary_dir'`目錄。
6. 現在,要可視化摘要,您需要從命令行調用 TensorBoard:
```py
tensorboard --logdir=summary_dir
```
7. 接下來,打開瀏覽器并輸入地址`http://localhost:6006/`(或運行 TensorBoard 命令后收到的鏈接)。
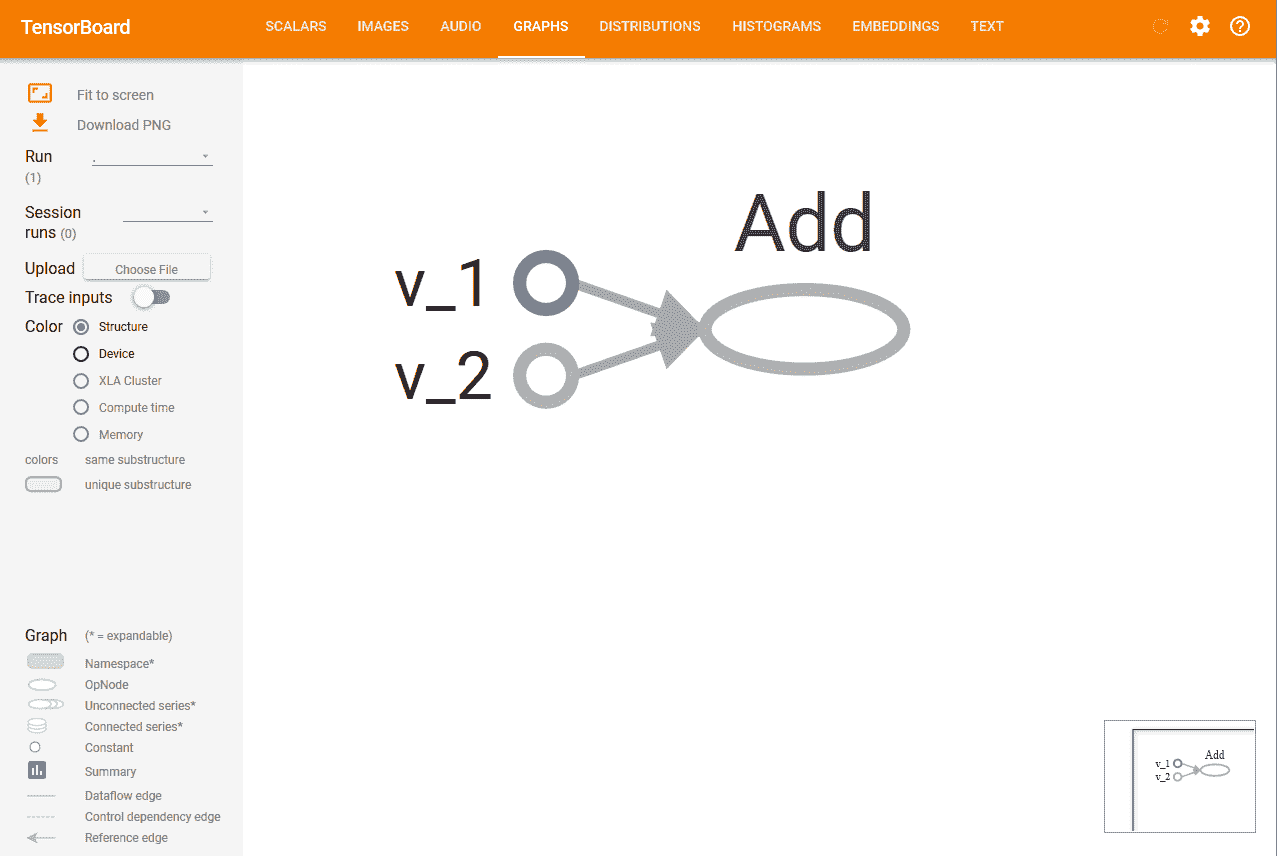
8. 您將看到類似以下的內容,頂部帶有許多選項卡。 圖表標簽會顯示圖表:
# 從 0.x 遷移到 1.x
TensorFlow 1.x 不提供向后兼容性。 這意味著適用于 TensorFlow 0.x 的代碼可能不適用于 TensorFlow 1.0。 因此,如果您有適用于 TensorFlow 0.x 的代碼,則需要對其進行升級(舊的 GitHub 存儲庫或您自己的代碼)。 本秘籍將指出 TensorFlow 0.x 和 TensorFlow 1.0 之間的主要區別,并向您展示如何使用腳本`tf_upgrade.py`自動升級 TensorFlow 1.0 的代碼。
# 操作步驟
這是我們進行秘籍的方法:
1. 首先,從[這里](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/tools/compatibility)下載`tf_upgrade.py`。
2. 如果要將一個文件從 TensorFlow 0.x 轉換為 TensorFlow 1.0,請在命令行中使用以下命令:
```py
python tf_upgrade.py --infile old_file.py --outfile upgraded_file.py
```
3. 例如,如果您有一個名為`test.py`的 TensorFlow 程序文件,則將使用以下命令,如下所示:
```py
python tf_upgrade.py --infile test.py --outfile test_1.0.py
```
4. 這將導致創建一個名為`test_1.0.py`的新文件。
5. 如果要遷移目錄的所有文件,請在命令行中使用以下命令:
```py
python tf_upgrade.py --intree InputDIr --outtree OutputDir
# For example, if you have a directory located at /home/user/my_dir you can migrate all the python files in the directory located at /home/user/my-dir_1p0 using the above command as:
python tf_upgrade.py --intree /home/user/my_dir --outtree /home/user/my_dir_1p0
```
6. 在大多數情況下,該目錄還包含數據集文件。 您可以使用以下方法確保將非 Python 文件也復制到新目錄(上例中為`my-dir_1p0`):
```py
python tf_upgrade.py --intree /home/user/my_dir --outtree /home/user/my_dir_1p0 -copyotherfiles True
```
7. 在所有這些情況下,都會生成一個`report.txt`文件。 該文件包含轉換的詳細信息以及過程中的任何錯誤。
8. 讀取`report.txt`文件,然后手動升級腳本無法更新的部分代碼。
# 更多
`tf_upgrade.py`具有某些限制:
* 它不能更改`tf.reverse()`的參數:您將必須手動修復它
* 對于參數列表重新排序的方法,例如`tf.split()`和`tf.reverse_split()`,它將嘗試引入關鍵字參數,但實際上無法對其重新排序
* 您將必須手動將`tf.get.variable_scope().reuse_variables()`之類的結構替換為以下內容:
```py
with tf.variable_scope(tf.get_variable_scope(), resuse=True):
```
# 使用 XLA 增強計算性能
**加速線性代數**(**XLA**)是線性代數的特定領域編譯器。 根據[這個頁面](https://www.tensorflow.org/performance/xla/)的說法,它仍處于實驗階段,可用于優化 TensorFlow 計算。 它可以提高服務器和移動平臺上的執行速度,內存使用率和可移植性。 它提供雙向 **JIT**(**即時**)編譯或 **AoT**(**預先**)編譯。 使用 XLA,您可以生成平臺相關的二進制文件(適用于 x64,ARM 等大量平臺),可以針對內存和速度進行優化。
# 準備
目前,XLA 不包含在 TensorFlow 的二進制發行版中。 需要從源代碼構建它。 要從源代碼構建 TensorFlow,需要具備 LLVM 和 Bazel 以及 TensorFlow 的知識。 [TensorFlow.org](http://TensorFlow.org) 僅在 MacOS 和 Ubuntu 中支持從源代碼構建。 [從源代碼構建 TensorFlow 所需的步驟如下](https://www.tensorflow.org/install/install_sources):
1. 確定要安裝的 TensorFlow-僅具有 CPU 支持的 TensorFlow 或具有 GPU 支持的 TensorFlow。
2. 克隆 TensorFlow 存儲庫:
```py
git clone https://github.com/tensorflow/tensorflow
cd tensorflow
git checkout Branch #where Branch is the desired branch
```
3. 安裝以下依賴項:
4. 配置安裝。 在此步驟中,您需要選擇不同的選項,例如 XLA,Cuda 支持,動詞等等:
```py
./configure
```
5. 接下來,使用`bazel-build`:
6. 對于僅 CPU 版本,請使用:
```py
bazel build --config=opt //tensorflow/tools/pip_package:build_pip_package
```
7. 如果您有兼容的 GPU 設備,并且需要 GPU 支持,請使用:
```py
bazel build --config=opt --config=cuda //tensorflow/tools/pip_package:build_pip_package
```
8. 成功運行后,您將獲得一個腳本`build_pip_package`。
9. 如下運行此腳本以構建`whl`文件:
```py
bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg
```
10. 安裝`pip`包:
```py
sudo pip install /tmp/tensorflow_pkg/tensorflow-1.1.0-py2-none-any.whl
```
現在您可以開始了。
# 操作步驟
TensorFlow 生成 TensorFlow 圖。 借助 XLA,可以在任何新型設備上運行 TensorFlow 圖。
1. **JIT 編譯**:這將在會話級別打開 JIT 編譯:
```py
# Config to turn on JIT compilation
config = tf.ConfigProto()
config.graph_options.optimizer_options.global_jit_level = tf.OptimizerOptions.ON_1
sess = tf.Session(config=config)
```
2. 這是為了手動打開 JIT 編譯:
```py
jit_scope = tf.contrib.compiler.jit.experimental_jit_scope
x = tf.placeholder(np.float32)
with jit_scope():
y = tf.add(x, x) # The "add" will be compiled with XLA.
```
3. 我們還可以通過將運算符放在特定的 XLA 設備`XLA_CPU`或`XLA_GPU`上,通過 XLA 運行計算:
```py
with tf.device \ ("/job:localhost/replica:0/task:0/device:XLA_GPU:0"):
output = tf.add(input1, input2)
```
**AoT 編譯**:在這里,我們將 tfcompile 作為獨立版本將 TensorFlow 圖轉換為適用于不同設備(移動設備)的可執行代碼。
TensorFlow.org 講述了 tfcompile:
tfcompile 接受一個由 TensorFlow 概念的提要和獲取標識的子圖,并生成實現該子圖的函數。 提要是函數的輸入參數,而提取是函數的輸出參數。 提要必須完全指定所有輸入; 結果修剪后的子圖不能包含占位符或變量節點。 通常將所有占位符和變量指定為提要,以確保結果子圖不再包含這些節點。 生成的函數打包為 cc_library,帶有導出函數簽名的頭文件和包含實現的目標文件。 用戶編寫代碼以適當地調用生成的函數。
有關執行此操作的高級步驟,可以參考[這里](https://www.tensorflow.org/performance/xla/tfcompile)。
# 調用 CPU/GPU 設備
TensorFlow 支持 CPU 和 GPU。 它還支持分布式計算。 我們可以在一臺或多臺計算機系統中的多個設備上使用 TensorFlow。 TensorFlow 將支持的設備命名為 CPU 設備的`"/device:CPU:0"`(或`"/cpu:0"`),將第`i`個 GPU 的設備命名為`"/device:GPU:I"`(或`"/gpu:I"`)。
如前所述,GPU 比 CPU 快得多,因為它們具有許多小型內核。 但是,就計算速度而言,將 GPU 用于所有類型的計算并不總是一個優勢。 與 GPU 相關的開銷有時可能比 GPU 提供的并行計算的優勢在計算上更為昂貴。 為了解決這個問題,TensorFlow 規定將計算放在特定的設備上。 默認情況下,如果同時存在 CPU 和 GPU,則 TensorFlow 會優先考慮 GPU。
# 操作步驟
TensorFlow 將設備表示為字符串。 在這里,我們將向您展示如何在 TensorFlow 中手動分配用于矩陣乘法的設備。 為了驗證 TensorFlow 確實在使用指定的設備(CPU 或 GPU),我們使用`log_device_placement`標志設置為`True`,即`config=tf.ConfigProto(log_device_placement=True)`創建會話:
1. 如果您不確定設備并希望 TensorFlow 選擇現有和受支持的設備,則可以將`allow_soft_placement`標志設置為`True`:
```py
config=tf.ConfigProto(allow_soft_placement=True, log_device_placement=True)
```
2. 手動選擇 CPU 進行操作:
```py
with tf.device('/cpu:0'):
rand_t = tf.random_uniform([50,50], 0, 10, dtype=tf.float32, seed=0)
a = tf.Variable(rand_t)
b = tf.Variable(rand_t)
c = tf.matmul(a,b)
init = tf.global_variables_initializer()
sess = tf.Session(config)
sess.run(init)
print(sess.run(c))
```
3. 我們得到以下輸出:
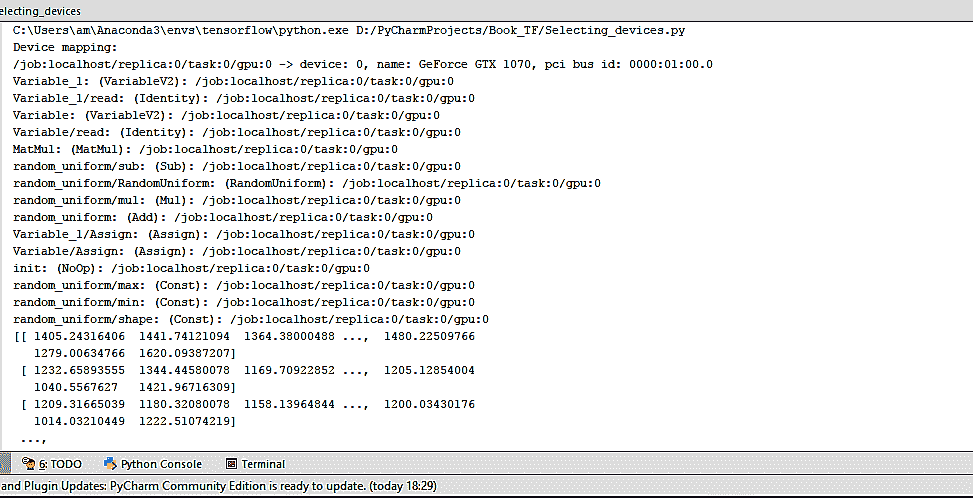
我們可以看到,在這種情況下,所有設備都是`'/cpu:0'`。
4. 手動選擇單個 GPU 進行操作:
```py
with tf.device('/gpu:0'):
rand_t = tf.random_uniform([50,50], 0, 10, dtype=tf.float32, seed=0)
a = tf.Variable(rand_t)
b = tf.Variable(rand_t)
c = tf.matmul(a,b)
init = tf.global_variables_initializer()
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
sess.run(init)
print(sess.run(c))
```
5. 現在,輸出更改為以下內容:

6. 每次操作后的`'/cpu:0'`現在由`'/gpu:0'`代替。
7. 手動選擇多個 GPU:
```py
c=[]
for d in ['/gpu:1','/gpu:2']:
with tf.device(d):
rand_t = tf.random_uniform([50, 50], 0, 10, dtype=tf.float32, seed=0)
a = tf.Variable(rand_t)
b = tf.Variable(rand_t)
c.append(tf.matmul(a,b))
init = tf.global_variables_initializer()
sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True,log_device_placement=True))
sess.run(init)
print(sess.run(c))
sess.close()
```
8. 在這種情況下,如果系統具有三個 GPU 設備,則第一組乘法將由`'/gpu:1'`進行,第二組乘法將由`'/gpu:2'`進行。
# 工作原理
`tf.device()`參數選擇設備(CPU 或 GPU)。 `with`塊確保選擇設備的操作。 `with`塊中定義的所有變量,常量和操作都將使用`tf.device()`中選擇的設備。 會話配置使用`tf.ConfigProto`控制。 通過設置`allow_soft_placement`和`log_device_placement`標志,我們告訴 TensorFlow 在指定設備不可用的情況下自動選擇可用設備,并在執行會話時提供日志消息作為輸出,描述設備的分配。
# 將 TensorFlow 用于深度學習
今天的 DNN 是 AI 社區的流行語。 使用 DNN 的候選人最近贏得了許多數據科學/凝視競賽。 自 1962 年 Rosenblat 提出感知機以來,就一直使用 DNN 的概念,而 1986 年 Rumelhart,Hinton 和 Williams 發明了梯度下降算法后,DNN 就變得可行了。 直到最近,DNN 才成為 AI/ML 愛好者和全世界工程師的最愛。
造成這種情況的主要原因是現代計算功能的可用性,例如 GPU 和 TensorFlow 之類的工具,這些功能使只需幾行代碼即可更輕松地訪問 GPU 并構建復雜的神經網絡。
作為機器學習愛好者,您必須已經熟悉神經網絡和深度學習的概念,但是為了完整起見,我們將在此處介紹基礎知識并探索 TensorFlow 的哪些功能使其成為深度學習的熱門選擇。
神經網絡是一種受生物學啟發的模型,用于計算和學習。 像生物神經元一樣,它們從其他單元(神經元或環境)中獲取加權輸入。 該加權輸入經過一個處理元素,并產生可以是二進制(觸發或不觸發)或連續(概率,預測)的輸出。 **人工神經網絡**(**ANN**)是這些神經元的網絡,可以隨機分布或以分層結構排列。 這些神經元通過一組權重和與之相關的偏置來學習。
下圖很好地說明了生物學中的神經網絡與人工神經網絡的相似性:
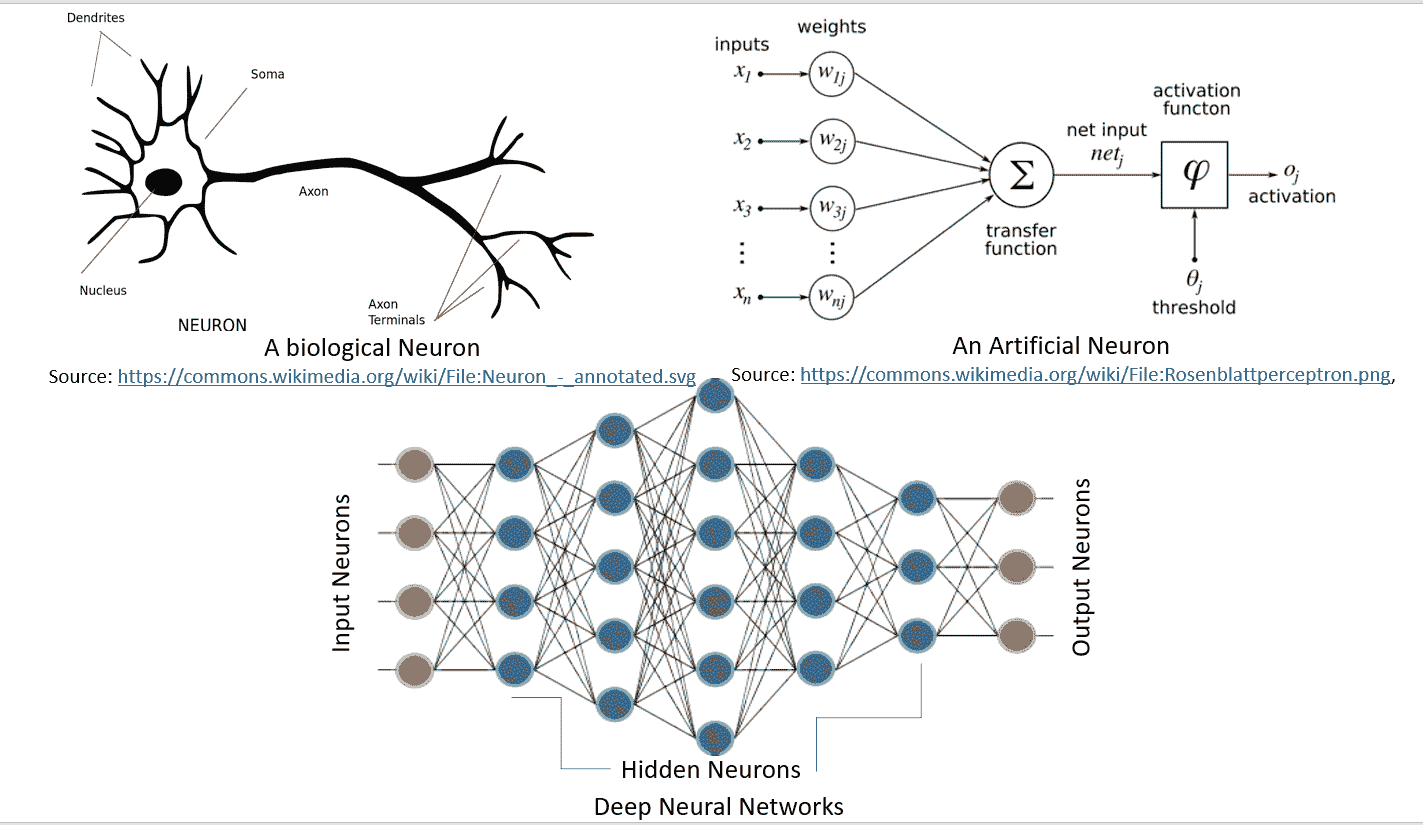
[由 Hinton 等人定義的深度學習](https://www.cs.toronto.edu/~hinton/absps/NatureDeepReview.pdf),由包含多個處理層(隱藏層)的計算模型組成。 層數的增加導致學習時間的增加。 由于數據集很大,因此學習時間進一步增加,正如當今的 CNN 或**生成對抗網絡**(**GAN**)的標準一樣。 因此,要實際實現 DNN,我們需要很高的計算能力。 NVDIA?的 GPU 的出現使其變得可行,然后 Google 的 TensorFlow 使得無需復雜的數學細節即可實現復雜的 DNN 結構成為可能,并且大型數據集的可用性為 DNN 提供了必要的條件。 TensorFlow 是最受歡迎的深度學習庫,其原因如下:
* TensorFlow 是一個強大的庫,用于執行大規模的數值計算,例如矩陣乘法或自動微分。 這兩個計算對于實現和訓練 DNN 是必需的。
* TensorFlow 在后端使用 C/C++,這使其計算速度更快。
* TensorFlow 具有高級的機器學習 API(`tf.contrib.learn`),使配置,訓練和評估大量機器學習模型變得更加容易。
* 在 TensorFlow 之上,可以使用高級深度學習庫 Keras。 Keras 非常易于使用,可以輕松快速地制作原型。 它支持各種 DNN,例如 RNN,CNN,甚至是兩者的組合。
# 操作步驟
任何深度學習網絡都包含四個重要組成部分:數據集,定義模型(網絡結構),訓練/學習和預測/評估。 我們可以在 TensorFlow 中完成所有這些操作; 讓我們看看如何:
* **數據集**:DNN 依賴于大量數據。 可以收集或生成數據,或者也可以使用可用的標準數據集。 TensorFlow 支持三種主要方法來讀取數據。 有不同的數據集。 我們將用來訓練本書中構建的模型的一些數據集如下:
* **MNIST**:這是最大的手寫數字數據庫(0-9)。 它由 60,000 個示例的訓練集和 10,000 個示例的測試集組成。 數據集保存在 [Yann LeCun 的主頁](http://yann.lecun.com/exdb/mnist/)中。 數據集包含在`tensorflow.examples.tutorials.mnist`中的 TensorFlow 庫中。
* **CIFAR10**:此數據集包含 10 類 60,000 張`32 x 32`彩色圖像,每類 6,000 張圖像。 訓練集包含 50,000 張圖像和測試數據集 10,000 張圖像。 數據集的十類是:飛機,汽車,鳥,貓,鹿,狗,青蛙,馬,船和卡車。 數據由[多倫多大學計算機科學系](https://www.cs.toronto.edu/~kriz/cifar.html)維護。
* **WORDNET**:這是英語的詞匯數據庫。 它包含名詞,動詞,副詞和形容詞,它們被分組為認知同義詞(同義詞集),也就是說,代表相同概念的單詞(例如,關閉和關閉或汽車和汽車)被分組為無序集合。 它包含 155,287 個單詞,按 117,659 個同義詞集進行組織,總計 206,941 個單詞感對。 數據由[普林斯頓大學](https://wordnet.princeton.edu/)維護。
* **ImageNET**:這是根據 WORDNET 層次結構組織的圖像數據集(目前僅名詞)。 每個有意義的概念(同義詞集)由多個單詞或單詞短語描述。 每個同義詞集平均由 1,000 張圖像表示。 目前,它具有 21,841 個同義詞集和總共 14,197,122 張圖像。 自 2010 年以來,每年組織一次 **ImageNet 大規模視覺識別挑戰賽**(**ILSVRC**),以將圖像分類為 1,000 個對象類別之一。 這項工作由[普林斯頓大學,斯坦福大學,A9 和 Google](http://www.image-net.org/) 贊助。
* **YouTube-8M**:這是一個大規模的標記視頻數據集,包含數百萬個 YouTube 視頻。 它有大約 700 萬個 YouTube 視頻 URL,分為 4716 個類別,分為 24 個頂級類別。 它還提供了預處理支持和幀級功能。 該數據集由 [Google Research](https://research.google.com/youtube8m/)維護。
**讀取數據**:在 TensorFlow 中可以通過三種方式讀取數據:通過`feed_dict`饋送,從文件讀取以及使用預加載的數據。 我們將在整本書中使用本秘籍中描述的組件來閱讀和提供數據。 在接下來的步驟中,您將學習每個步驟。
1. **饋送**:在這種情況下,使用`run()`或`eval()`函數調用中的`feed_dict`參數在運行每個步驟時提供數據。 這是在占位符的幫助下完成的,該方法使我們可以傳遞 Numpy 數據數組。 考慮使用 TensorFlow 的以下代碼部分:
```py
...
y = tf.placeholder(tf.float32)
x = tf.placeholder(tf.float32).
...
with tf.Session as sess:
X_Array = some Numpy Array
Y_Array = other Numpy Array
loss= ...
sess.run(loss,feed_dict = {x: X_Array, y: Y_Array}).
...
```
這里,`x`和`y`是占位符; 使用它們,我們在`feed_dict`的幫助下傳遞包含`X`值的數組和包含`Y`值的數組。
2. **從文件中讀取**:當數據集非常大時,可以使用此方法來確保并非所有數據都一次占用內存(想象 60 GB YouTube-8m 數據集)。 從文件讀取的過程可以按照以下步驟完成:
```py
filename_queue = tf.train.string_input_producer(files)
# where files is the list of filenames created above
```
此函數還提供了隨機播放和設置最大周期數的選項。 文件名的整個列表將添加到每個周期的隊列中。 如果選擇了改組選項(`shuffle=True`),則文件名將在每個周期被改組。
```py
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
```
```py
record_defaults = [[1], [1], [1]]
col1, col2, col3 = tf.decode_csv(value, record_defaults=record_defaults)
```
3. **預加載數據**:當數據集較小且可以完全加載到內存中時使用。 為此,我們可以將數據存儲為常量或變量。 在使用變量時,我們需要將可訓練標記設置為`False`,以便在訓練期間數據不會更改。 作為 TensorFlow 常量:
```py
# Preloaded data as constant
training_data = ...
training_labels = ...
with tf.Session as sess:
x_data = tf.Constant(training_data)
y_data = tf.Constant(training_labels)
...
```
```py
# Preloaded data as Variables
training_data = ...
training_labels = ...
with tf.Session as sess:
data_x = tf.placeholder(dtype=training_data.dtype, shape=training_data.shape)
data_y = tf.placeholder(dtype=training_label.dtype, shape=training_label.shape)
x_data = tf.Variable(data_x, trainable=False, collections[])
y_data = tf.Variable(data_y, trainable=False, collections[])
...
```
按照慣例,數據分為三部分-訓練數據,驗證數據和測試數據。
4. **定義模型**:建立一個描述網絡結構的計算圖。 它涉及指定超參數,變量和占位符序列,其中信息從一組神經元流向另一組神經元,并傳遞損失/誤差函數。 您將在本章的后續部分中了解有關計算圖的更多信息。
5. **訓練/學習**:DNN 中的學習通常基于梯度下降算法,(將在第 2 章,“回歸”中詳細介紹) 目的是找到訓練變量(權重/偏差),以使誤差或損失(由用戶在步驟 2 中定義)最小。 這是通過初始化變量并使用`run()`實現的:
```py
with tf.Session as sess:
....
sess.run(...)
...
```
6. **評估模型**:訓練完網絡后,我們將使用`predict()`對驗證數據和測試數據進行評估。 通過評估,我們可以估計出模型對數據集的擬合程度。 因此,我們可以避免過擬合或擬合不足的常見錯誤。 對模型滿意后,便可以將其部署到生產中。
# 還有更多
在 TensorFlow 1.3 中,添加了一個稱為 TensorFlow 估計器的新功能。 TensorFlow 估計器使創建神經網絡模型的任務變得更加容易,它是一個高級 API,封裝了訓練,評估,預測和服務的過程。 它提供了使用預建估計器的選項,也可以編寫自己的自定義估計器。 有了預建的估計器,就不再需要擔心構建計算或創建會話,它就可以處理所有這些。
目前,TensorFlow 估計器有六個預建的估計器。 使用 TensorFlow 預建的估計器的另一個優勢是,它本身也可以創建可在 TensorBoard 上可視化的摘要。 有關估計器的更多詳細信息,請訪問[這里](https://www.tensorflow.org/programmers_guide/estimators)。
# 基于 DNN 的問題所需的不同 Python 包
TensorFlow 負責大多數神經網絡的實現。 但是,這還不夠。 對于預處理任務,序列化甚至是繪圖,我們需要更多的 Python 包。
# 操作步驟
以下列出了一些常用的 Python 包:
1. **Numpy**:這是使用 Python 進行科學計算的基本包。 它支持 n 維數組和矩陣。 它還具有大量的高級數學函數。 它是 TensorFlow 所需的必需包,因此,如果尚未安裝`pip install tensorflow`,則將其安裝。
2. **Matplolib**:這是 Python 2D 繪圖庫。 只需幾行代碼,您就可以使用它來創建圖表,直方圖,條形圖,誤差圖,散點圖和功率譜。 可以使用`pip:`安裝
```py
pip install matplotlib
# or using Anaconda
conda install -c conda-forge matplotlib
```
3. **OS**:這是基本 Python 安裝中包含的內容。 它提供了一種使用與操作系統相關的函數(如讀取,寫入和更改文件和目錄)的簡便方法。
4. **Pandas**:這提供了各種數據結構和數據分析工具。 使用 Pandas,您可以在內存數據結構和不同格式之間讀取和寫入數據。 我們可以讀取`.csv`和文本文件。 可以使用`pip install`或`conda install`進行安裝。
5. **Seaborn**:這是基于 Matplotlib 構建的專門統計數據可視化工具。
6. **H5fs**:H5fs??是適用于 Linux 的文件系統(也是具有 FUSE 實現的其他操作系統,例如 MacOSX),可以在 **HDFS** (**分層數據格式文件系統**)上運行 。
7. **PythonMagick**:它是`ImageMagick`庫的 Python 綁定。 它是顯示,轉換和編輯光柵圖像和向量圖像文件的庫。 它支持 200 多種圖像文件格式。 可以使用`ImageMagick.`提供的源代碼版本進行安裝。某些`.whl`格式也可用于方便的[`pip install`](http://www.lfd.uci.edu/%7Egohlke/pythonlibs/#pythonmagick)。
8. **TFlearn**:TFlearn 是建立在 TensorFlow 之上的模塊化透明的深度學習庫。 它為 TensorFlow 提供了更高級別的 API,以促進并加速實驗。 它目前支持大多數最新的深度學習模型,例如卷積,LSTM,BatchNorm,BiRNN,PReLU,殘差網絡和生成網絡。 它僅適用于 TensorFlow 1.0 或更高版本。 要安裝,請使用`pip install tflearn`。
9. **Keras**:Keras 也是神經網絡的高級 API,它使用 TensorFlow 作為其后端。 它也可以在 Theano 和 CNTK 之上運行。 這是非常用戶友好的,添加層只是一項工作。 可以使用`pip install keras`安裝。
# 另見
您可以在下面找到一些 Web 鏈接以獲取有關 TensorFlow 安裝的更多信息
* <https://www.tensorflow.org/install/>
* <https://www.tensorflow.org/install/install_sources>
* <http://llvm.org/>
* <https://bazel.build/>
- TensorFlow 1.x 深度學習秘籍
- 零、前言
- 一、TensorFlow 簡介
- 二、回歸
- 三、神經網絡:感知器
- 四、卷積神經網絡
- 五、高級卷積神經網絡
- 六、循環神經網絡
- 七、無監督學習
- 八、自編碼器
- 九、強化學習
- 十、移動計算
- 十一、生成模型和 CapsNet
- 十二、分布式 TensorFlow 和云深度學習
- 十三、AutoML 和學習如何學習(元學習)
- 十四、TensorFlow 處理單元
- 使用 TensorFlow 構建機器學習項目中文版
- 一、探索和轉換數據
- 二、聚類
- 三、線性回歸
- 四、邏輯回歸
- 五、簡單的前饋神經網絡
- 六、卷積神經網絡
- 七、循環神經網絡和 LSTM
- 八、深度神經網絡
- 九、大規模運行模型 -- GPU 和服務
- 十、庫安裝和其他提示
- TensorFlow 深度學習中文第二版
- 一、人工神經網絡
- 二、TensorFlow v1.6 的新功能是什么?
- 三、實現前饋神經網絡
- 四、CNN 實戰
- 五、使用 TensorFlow 實現自編碼器
- 六、RNN 和梯度消失或爆炸問題
- 七、TensorFlow GPU 配置
- 八、TFLearn
- 九、使用協同過濾的電影推薦
- 十、OpenAI Gym
- TensorFlow 深度學習實戰指南中文版
- 一、入門
- 二、深度神經網絡
- 三、卷積神經網絡
- 四、循環神經網絡介紹
- 五、總結
- 精通 TensorFlow 1.x
- 一、TensorFlow 101
- 二、TensorFlow 的高級庫
- 三、Keras 101
- 四、TensorFlow 中的經典機器學習
- 五、TensorFlow 和 Keras 中的神經網絡和 MLP
- 六、TensorFlow 和 Keras 中的 RNN
- 七、TensorFlow 和 Keras 中的用于時間序列數據的 RNN
- 八、TensorFlow 和 Keras 中的用于文本數據的 RNN
- 九、TensorFlow 和 Keras 中的 CNN
- 十、TensorFlow 和 Keras 中的自編碼器
- 十一、TF 服務:生產中的 TensorFlow 模型
- 十二、遷移學習和預訓練模型
- 十三、深度強化學習
- 十四、生成對抗網絡
- 十五、TensorFlow 集群的分布式模型
- 十六、移動和嵌入式平臺上的 TensorFlow 模型
- 十七、R 中的 TensorFlow 和 Keras
- 十八、調試 TensorFlow 模型
- 十九、張量處理單元
- TensorFlow 機器學習秘籍中文第二版
- 一、TensorFlow 入門
- 二、TensorFlow 的方式
- 三、線性回歸
- 四、支持向量機
- 五、最近鄰方法
- 六、神經網絡
- 七、自然語言處理
- 八、卷積神經網絡
- 九、循環神經網絡
- 十、將 TensorFlow 投入生產
- 十一、更多 TensorFlow
- 與 TensorFlow 的初次接觸
- 前言
- 1.?TensorFlow 基礎知識
- 2. TensorFlow 中的線性回歸
- 3. TensorFlow 中的聚類
- 4. TensorFlow 中的單層神經網絡
- 5. TensorFlow 中的多層神經網絡
- 6. 并行
- 后記
- TensorFlow 學習指南
- 一、基礎
- 二、線性模型
- 三、學習
- 四、分布式
- TensorFlow Rager 教程
- 一、如何使用 TensorFlow Eager 構建簡單的神經網絡
- 二、在 Eager 模式中使用指標
- 三、如何保存和恢復訓練模型
- 四、文本序列到 TFRecords
- 五、如何將原始圖片數據轉換為 TFRecords
- 六、如何使用 TensorFlow Eager 從 TFRecords 批量讀取數據
- 七、使用 TensorFlow Eager 構建用于情感識別的卷積神經網絡(CNN)
- 八、用于 TensorFlow Eager 序列分類的動態循壞神經網絡
- 九、用于 TensorFlow Eager 時間序列回歸的遞歸神經網絡
- TensorFlow 高效編程
- 圖嵌入綜述:問題,技術與應用
- 一、引言
- 三、圖嵌入的問題設定
- 四、圖嵌入技術
- 基于邊重構的優化問題
- 應用
- 基于深度學習的推薦系統:綜述和新視角
- 引言
- 基于深度學習的推薦:最先進的技術
- 基于卷積神經網絡的推薦
- 關于卷積神經網絡我們理解了什么
- 第1章概論
- 第2章多層網絡
- 2.1.4生成對抗網絡
- 2.2.1最近ConvNets演變中的關鍵架構
- 2.2.2走向ConvNet不變性
- 2.3時空卷積網絡
- 第3章了解ConvNets構建塊
- 3.2整改
- 3.3規范化
- 3.4匯集
- 第四章現狀
- 4.2打開問題
- 參考
- 機器學習超級復習筆記
- Python 遷移學習實用指南
- 零、前言
- 一、機器學習基礎
- 二、深度學習基礎
- 三、了解深度學習架構
- 四、遷移學習基礎
- 五、釋放遷移學習的力量
- 六、圖像識別與分類
- 七、文本文件分類
- 八、音頻事件識別與分類
- 九、DeepDream
- 十、自動圖像字幕生成器
- 十一、圖像著色
- 面向計算機視覺的深度學習
- 零、前言
- 一、入門
- 二、圖像分類
- 三、圖像檢索
- 四、對象檢測
- 五、語義分割
- 六、相似性學習
- 七、圖像字幕
- 八、生成模型
- 九、視頻分類
- 十、部署
- 深度學習快速參考
- 零、前言
- 一、深度學習的基礎
- 二、使用深度學習解決回歸問題
- 三、使用 TensorBoard 監控網絡訓練
- 四、使用深度學習解決二分類問題
- 五、使用 Keras 解決多分類問題
- 六、超參數優化
- 七、從頭開始訓練 CNN
- 八、將預訓練的 CNN 用于遷移學習
- 九、從頭開始訓練 RNN
- 十、使用詞嵌入從頭開始訓練 LSTM
- 十一、訓練 Seq2Seq 模型
- 十二、深度強化學習
- 十三、生成對抗網絡
- TensorFlow 2.0 快速入門指南
- 零、前言
- 第 1 部分:TensorFlow 2.00 Alpha 簡介
- 一、TensorFlow 2 簡介
- 二、Keras:TensorFlow 2 的高級 API
- 三、TensorFlow 2 和 ANN 技術
- 第 2 部分:TensorFlow 2.00 Alpha 中的監督和無監督學習
- 四、TensorFlow 2 和監督機器學習
- 五、TensorFlow 2 和無監督學習
- 第 3 部分:TensorFlow 2.00 Alpha 的神經網絡應用
- 六、使用 TensorFlow 2 識別圖像
- 七、TensorFlow 2 和神經風格遷移
- 八、TensorFlow 2 和循環神經網絡
- 九、TensorFlow 估計器和 TensorFlow HUB
- 十、從 tf1.12 轉換為 tf2
- TensorFlow 入門
- 零、前言
- 一、TensorFlow 基本概念
- 二、TensorFlow 數學運算
- 三、機器學習入門
- 四、神經網絡簡介
- 五、深度學習
- 六、TensorFlow GPU 編程和服務
- TensorFlow 卷積神經網絡實用指南
- 零、前言
- 一、TensorFlow 的設置和介紹
- 二、深度學習和卷積神經網絡
- 三、TensorFlow 中的圖像分類
- 四、目標檢測與分割
- 五、VGG,Inception,ResNet 和 MobileNets
- 六、自編碼器,變分自編碼器和生成對抗網絡
- 七、遷移學習
- 八、機器學習最佳實踐和故障排除
- 九、大規模訓練
- 十、參考文獻