
# 九、協同過濾和電影推薦
在這一部分,我們將看到如何利用協同過濾來開發推薦引擎。然而,在此之前讓我們討論偏好的效用矩陣。
## 效用矩陣
在基于協同過濾的推薦系統中,存在實體的維度:用戶和項目(項目指的是諸如電影,游戲和歌曲的產品)。作為用戶,您可能對某些項目有首選項。因此,必須從有關項目,用戶或評級的數據中提取這些首選項。該數據通常表示為效用矩陣,例如用戶 - 項目對。這種類型的值可以表示關于用戶對特定項目的偏好程度的已知信息。
矩陣中的條目可以來自有序集。例如,整數 1-5 可用于表示用戶在評價項目時給出的星數。我們已經提到用戶可能不會經常評價項目,因此大多數條目都是未知的。因此,將 0 分配給未知項將失敗,這也意味著矩陣可能是稀疏的。未知評級意味著我們沒有關于用戶對項目的偏好的明確信息。
表 1 顯示示例效用矩陣。矩陣表示用戶以 1-5 分為單位給予電影的評級,其中 5 為最高評級。空白條目表示特定用戶未為該特定電影提供任何評級的事實。 HP1,HP2 和 HP3 是 Harry Potter I,II 和 III 的首字母縮略詞,TW 代表 Twilight,SW1,SW2 和 SW3 代表星球大戰的第 1,2 和 3 集。字母 A,B,C 和 D 代表用戶:

表 1:效用矩陣(用戶與電影矩陣)
用戶電影對有許多空白條目。這意味著用戶尚未對這些電影進行評級。在現實生活中,矩陣可能更稀疏,典型的用戶評級只是所有可用電影的一小部分。使用此矩陣,目標是預測效用矩陣中的空白。現在,讓我們看一個例子。假設我們很想知道用戶 A 是否想要 SW2。很難解決這個問題,因為表 1 中的矩陣內沒有太多數據可供使用。
因此,在實踐中,我們可能會開發一個電影推薦引擎來考慮電影的其他屬性,例如制片人,導演,主要演員,甚至是他們名字的相似性。這樣,我們可以計算電影 SW1 和 SW2 的相似度。這種相似性會讓我們得出結論,因為 A 不喜歡 SW1,所以他們也不太可能喜歡 SW2。
但是,這可能不適用于更大的數據集。因此,有了更多的數據,我們可能會發現,對 SW1 和 SW2 進行評級的人都傾向于給予他們相似的評級。最后,我們可以得出結論,A 也會給 SW2 一個低評級,類似于 A 的 SW1 評級。
在下一節中,我們將看到如何使用協同過濾方法開發電影推薦引擎。我們將看到如何利用這種類型的矩陣。
### 注意
如何使用代碼庫:此代碼庫中有八個 Python 腳本(即使用`TensorFlow_09_Codes/CollaborativeFiltering`進行深度學習)。首先,執行執行數據集探索性分析的`eda.py`。然后,調用`train.py`腳本執行訓練。最后,`Test.py`可用于模型推理和評估。
以下是每個腳本的簡要功能:
* `eda.py`:這用于 MovieLens1M 數據集的探索性分析。
* `train.py`:它執行訓練和驗證。然后它打印驗證誤差。最后,它創建了用戶項密集表。
* `Test.py`:恢復訓練中生成的用戶與項目表。然后評估所有模型。
* `run.py`:用于模型推理并進行預測。
* `kmean.py`:它集中了類似的電影。
* `main.py`:它計算前 K 個電影,創建用戶評級,找到前 K 個相似項目,計算用戶相似度,計算項目相關性并計算用戶 Pearson 相關性。
* `readers.py`:它讀取評級和電影數據并執行一些預處理。最后,它為批量訓練準備數據集。
* `model.py`:它創建模型并計算訓練/驗證損失。
工作流程可以描述如下:
1. 首先,我們將使用可用的評級來訓練模型。
2. 然后我們使用訓練的模型來預測用戶與電影矩陣中的缺失評級。
3. 然后,利用所有預測的評級,將構建新用戶與電影矩陣并以`.pkl`文件的形式保存。
4. 然后,我們使用此矩陣來預測特定用戶的評級。
5. 最后,我們將訓練 K 均值模型來聚類相關電影。
## 數據集的描述
在我們開始實現電影 RE 之前,讓我們看一下將要使用的數據集。 MovieLens1M 數據集從 [MovieLens 網站](http://files.grouplens.org/datasets/movielens/ml-1m.zip)下載。
我真誠地感謝 F. Maxwell Harper 和 Joseph A. Konstan 使數據集可供使用。數據集發布在 MovieLens 數據集:歷史和上下文中。 ACM 交互式智能系統交易(TiiS)5,4,第 19 條(2015 年 12 月),共 19 頁。
數據集中有三個文件,它們與電影,評級和用戶有關。這些文件包含 1,000,209 個匿名評級,約有 3,900 部電影,由 2000 年加入 MovieLens 的 6,040 名 MovieLens 用戶制作。
### 評級數據
所有評級都包含在`ratings.dat`文件中,格式如下 - `UserID :: MovieID :: Rating :: Timestamp`:
* `UserID`的范圍在 1 到 6,040 之間
* `MovieID`的范圍在 1 到 3,952 之間
* `Rating`為五星級
* `Timestamp`以秒表示
請注意,每位用戶至少評了 20 部電影。
### 電影數據
電影信息是`movies.dat`文件中的 ,格式如下 - `MovieID :: Title :: Genres`:
* 標題與 IMDb 提供的標題相同(發布年份)
* 流派是分開的,每部電影分為動作,冒險,動畫,兒童,喜劇,犯罪,戲劇,戰爭,紀錄片,幻想,電影黑色,恐怖,音樂,神秘,浪漫,科幻菲律賓,驚悚片和西部片
### 用戶數據
用戶信息位于`users.dat`文件中,格式如下:`UserID :: Gender :: Age :: Occupation :: Zip-code`。
所有人口統計信息均由用戶自愿提供,不會檢查其準確率。此數據集中僅包含已提供某些人口統計信息的用戶。男性 M 和女性 F 表示性別。
年齡選自以下范圍:
* 1:18 歲以下
* 18:18-24
* 25:25-34
* 35:35-44
* 45:45-49
* 50:50-55
* 56:56+
職業選自以下選項:
0:其他,或未指定
1:學術/教育者
2:藝術家
3:文員/管理員
4:大學/研究生
5:客戶服務
6:醫生/保健
7:執行/管理
8:農民
9:主婦
10:K-12 學生
11:律師
12:程序員
13:退休了
14:銷售/營銷
15:科學家
16:自雇人士
17:技師/工程師
18:匠人/工匠
19:失業
20:作家
## 對 MovieLens 數據集的探索性分析
在這里,在我們開始開發 RE 之前,我們將看到數據集的探索性描述。我假設讀者已經從[此鏈接](http://files.grouplens.org/datasets/movielens/ml-1m.zip)下載了 MovieLens1m 數據集并將其解壓縮到此代碼庫中的輸入目錄。現在,為此,在終端上執行`$ python3 eda.py`命令:
1. 首先,讓我們導入所需的庫和包:
```py
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
```
2. 現在讓我們加載用戶,評級和電影數據集并創建一個 pandas `DataFrame`:
```py
ratings_list = [i.strip().split("::") for i in open('Input/ratings.dat', 'r').readlines()]
users_list = [i.strip().split("::") for i in open('Input/users.dat', 'r').readlines()]
movies_list = [i.strip().split("::") for i in open('Input/movies.dat', 'r',encoding='latin-1').readlines()]
ratings_df = pd.DataFrame(ratings_list, columns = ['UserID', 'MovieID', 'Rating', 'Timestamp'], dtype = int)
movies_df = pd.DataFrame(movies_list, columns = ['MovieID', 'Title', 'Genres'])
user_df=pd.DataFrame(users_list, columns=['UserID','Gender','Age','Occupation','ZipCode'])
```
3. 接下來的任務是使用內置的`to_numeric()` pandas 函數將分類列(如`MovieID`,`UserID`和`Age`)轉換為數值:
```py
movies_df['MovieID'] = movies_df['MovieID'].apply(pd.to_numeric)
user_df['UserID'] = user_df['UserID'].apply(pd.to_numeric)
user_df['Age'] = user_df['Age'].apply(pd.to_numeric)
```
4. 讓我們看一下用戶表中的一些例子:
```py
print("User table description:")
print(user_df.head())
print(user_df.describe())
>>>
User table description:
UserID Gender Age Occupation ZipCode
1 F 1 10 48067
2 M 56 16 70072
3 M 25 15 55117
4 M 45 7 02460
5 M 25 20 55455
UserID Age
count 6040.000000 6040.000000
mean 3020.500000 30.639238
std 1743.742145 12.895962
min 1.000000 1.000000
25% 1510.750000 25.000000
50% 3020.500000 25.000000
75% 4530.250000 35.000000
max 6040.000000 56.000000
```
5. 讓我們看一下來自評級數據集的一些信息:
```py
print("Rating table description:")
print(ratings_df.head())
print(ratings_df.describe())
>>>
Rating table description:
UserID MovieID Rating Timestamp
1 1193 5 978300760
1 661 3 978302109
1 914 3 978301968
1 3408 4 978300275
1 2355 5 978824291
UserID MovieID Rating Timestamp
count 1.000209e+06 1.000209e+06 1.000209e+06 1.000209e+06
mean 3.024512e+03 1.865540e+03 3.581564e+00 9.722437e+08
std 1.728413e+03 1.096041e+03 1.117102e+00 1.215256e+07
min 1.000000e+00 1.000000e+00 1.000000e+00 9.567039e+08
25% 1.506000e+03 1.030000e+03 3.000000e+00 9.653026e+08
50% 3.070000e+03 1.835000e+03 4.000000e+00 9.730180e+08
75% 4.476000e+03 2.770000e+03 4.000000e+00 9.752209e+08
max 6.040000e+03 3.952000e+03 5.000000e+00 1.046455e+09
```
6. 讓我們看看電影數據集中的一些信息:
```py
>>>
print("Movies table description:")
print(movies_df.head())
print(movies_df.describe())
>>>
Movies table description:
MovieID Title Genres
0 1 Toy Story (1995) Animation|Children's|Comedy
1 2 Jumanji (1995) Adventure|Children's|Fantasy
2 3 Grumpier Old Men (1995) Comedy|Romance
3 4 Waiting to Exhale (1995) Comedy|Drama
4 5 Father of the Bride Part II (1995) Comedy
MovieID
count 3883.000000
mean 1986.049446
std 1146.778349
min 1.000000
25% 982.500000
50% 2010.000000
75% 2980.500000
max 3952.000000
```
7. 現在讓我們看看評級最高的五部電影:
```py
print("Top ten most rated movies:")
print(ratings_df['MovieID'].value_counts().head())
>>>
Top 10 most rated movies with title and rating count:
American Beauty (1999) 3428
Star Wars: Episode IV - A New Hope (1977) 2991
Star Wars: Episode V - The Empire Strikes Back (1980) 2990
Star Wars: Episode VI - Return of the Jedi (1983) 2883
Jurassic Park (1993) 2672
Saving Private Ryan (1998) 2653
Terminator 2: Judgment Day (1991) 2649
Matrix, The (1999) 2590
Back to the Future (1985) 2583
Silence of the Lambs, The (1991) 2578
```
8. 現在,讓我們看一下電影評級分布。 為此,讓我們使用直方圖,該圖演示了一個重要的模式,票數呈正態分布:
```py
plt.hist(ratings_df.groupby(['MovieID'])['Rating'].mean().sort_values(axis=0, ascending=False))
plt.title("Movie rating Distribution")
plt.ylabel('Count of movies')
plt.xlabel('Rating');
plt.show()
>>>
```
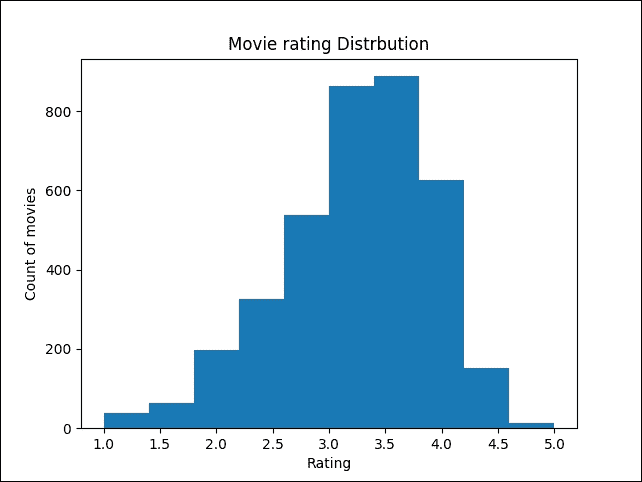
圖 3:電影評級分布
9. 讓我們看看評級如何分布在不同年齡段:
```py
user_df.Age.plot.hist()
plt.title("Distribution of users (by ages)")
plt.ylabel('Count of users')
plt.xlabel('Age');
plt.show()
>>>
```
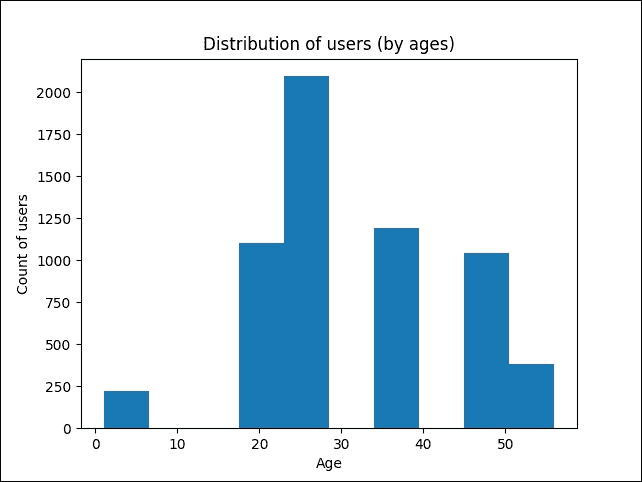
圖 4:按年齡分布的用戶
10. 現在讓我們看看收視率最高的電影,評級至少為 150:
```py
movie_stats = df.groupby('Title').agg({'Rating': [np.size, np.mean]})
print("Highest rated movie with minimum 150 ratings")
print(movie_stats.Rating[movie_stats.Rating['size'] > 150].sort_values(['mean'],ascending=[0]).head())
>>>
Top 5 and a highest rated movie with a minimum of 150 ratings-----------------------------------------------------------
Title size mean
Seven Samurai (The Magnificent Seven) 628 4.560510
Shawshank Redemption, The (1994) 2227 4.554558
Godfather, The (1972) 2223 4.524966
Close Shave, A (1995) 657 4.520548
Usual Suspects, The (1995) 1783 4.517106
```
11. 讓我們看看在電影評級中的性別偏置,即電影評級如何按評論者的性別進行比較:
```py
>>>
pivoted = df.pivot_table(index=['MovieID', 'Title'], columns=['Gender'], values='Rating', fill_value=0)
print("Gender biasing towards movie rating")
print(pivoted.head())
```
12. 我們現在可以看看電影收視率的性別偏置及它們之間的差異,即男性和女性對電影的評價方式不同:
```py
pivoted['diff'] = pivoted.M - pivoted.F
print(pivoted.head())
>>>
Gender F M diff
MovieID Title
1 Toy Story (1995) 4.87817 4.130552 -0.057265
2 Jumanji (1995) 3.278409 3.175238 -0.103171
3 Grumpier Old Men (1995) 3.073529 2.994152 -0.079377
4 Waiting to Exhale (1995) 2.976471 2.482353 -0.494118
5 Father of the Bride Part II (1995) 3.212963 2.888298 -0.324665
```
13. 從前面的輸出中可以清楚地看出,在大多數情況下,男性的收視率高于女性。現在我們已經看到了有關數據集的一些信息和統計數據,現在是構建我們的 TensorFlow 推薦模型的時候了。
## 實現電影 RE
在這個例子中,我們將看到如何推薦前 K 部電影(其中 K 是電影數量),預測用戶評級并推薦前 K 個類似項目(其中 K 是項目數)。然后我們將看到如何計算用戶相似度。
然后我們將使用 Pearson 的相關算法看到項目項相關性和用戶 - 用戶相關性。最后,我們將看到如何使用 K 均值算法對類似的電影進行聚類。
換句話說,我們將使用協同過濾方法制作電影推薦引擎,并使用 K 均值來聚類類似的電影。
距離計算:還有其他計算距離的方法。例如:
1. 通過僅考慮最顯著的尺寸,可以使用切比雪夫距離來測量距離。
2. 漢明距離算法可以識別兩個字符串之間的差異。
3. 馬哈拉諾比斯距離可用于歸一化協方差矩陣。
4. 曼哈頓距離用于通過僅考慮軸對齊方向來測量距離。
5. Haversine 距離用于測量球體上兩個點之間的大圓距離。
考慮到這些距離測量算法,很明顯歐幾里德距離算法最適合解決 K 均值算法中距離計算的目的。
總之,以下是用于開發此模型的工作流程:
1. 首先,使用可用的評級來訓練模型。
2. 使用該訓練模型來預測用戶與電影矩陣中的缺失評級。
3. 利用所有預測的評級,用戶與電影矩陣成為受訓用戶與電影矩陣,我們以`.pkl`文件的形式保存。
4. 然后,我們使用用戶與電影矩陣,或訓練用戶與電影矩陣的訓練參數,進行進一步處理。
在訓練模型之前,第一項工作是利用所有可用的數據集來準備訓練集。
### 使用可用的評級訓練模型
對于這一部分,請使用`train.py`腳本,該腳本依賴于其他腳本。我們將看到依賴項:
1. 首先,讓我們導入必要的包和模塊:
```py
from collections import deque
from six import next
import readers
import os
import tensorflow as tf
import numpy as np
import model as md
import pandas as pd
import time
import matplotlib.pyplot as plt
```
2. 然后我們設置隨機種子的復現性:
```py
np.random.seed(12345)
```
3. 下一個任務是定義訓練參數。讓我們定義所需的數據參數,例如評級數據集的位置,批量大小,SVD 的維度,最大周期和檢查點目錄:
```py
data_file ="Input/ratings.dat"# Input user-movie-rating information file
batch_size = 100 #Batch Size (default: 100)
dims =15 #Dimensions of SVD (default: 15)
max_epochs = 50 # Maximum epoch (default: 25)
checkpoint_dir ="save/" #Checkpoint directory from training run
val = True #True if Folders with files and False if single file
is_gpu = True # Want to train model with GPU
```
4. 我們還需要一些其他參數,例如允許軟放置和日志設備放置:
```py
allow_soft_placement = True #Allow device soft device placement
log_device_placement=False #Log placement of ops on devices
```
5. 我們不想用舊的元數據或檢查點和模型文件污染我們的新訓練 ,所以如果有的話,讓我們刪除它們:
```py
print("Start removing previous Files ...")
if os.path.isfile("model/user_item_table.pkl"):
os.remove("model/user_item_table.pkl")
if os.path.isfile("model/user_item_table_train.pkl"):
os.remove("model/user_item_table_train.pkl")
if os.path.isfile("model/item_item_corr.pkl"):
os.remove("model/item_item_corr.pkl")
if os.path.isfile("model/item_item_corr_train.pkl"):
os.remove("model/item_item_corr_train.pkl")
if os.path.isfile("model/user_user_corr.pkl"):
os.remove("model/user_user_corr.pkl")
if os.path.isfile("model/user_user_corr_train.pkl"):
os.remove("model/user_user_corr_train.pkl")
if os.path.isfile("model/clusters.csv"):
os.remove("model/clusters.csv")
if os.path.isfile("model/val_error.pkl"):
os.remove("model/val_error.pkl")
print("Done ...")
>>>
Start removing previous Files...
Done...
```
6. 然后讓我們定義檢查點目錄。 TensorFlow 假設此目錄已存在,因此我們需要創建它:
```py
checkpoint_prefix = os.path.join(checkpoint_dir, "model")
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
```
7. 在進入數據之前,讓我們設置每批的樣本數量,數據的維度以及網絡看到所有訓練數據的次數 :
```py
batch_size =batch_size
dims =dims
max_epochs =max_epochs
```
8. 現在讓我們指定用于所有 TensorFlow 計算,CPU 或 GPU 的設備:
```py
if is_gpu:
place_device = "/gpu:0"
else:
place_device="/cpu:0"
```
9. 現在我們通過`get_data()`函數讀取帶有分隔符`::`的評級文件。示例列包含用戶 ID,項 ID,評級和時間戳,例如`3 :: 1196 :: 4 :: 978297539`。然后,上面的代碼執行純粹基于整數位置的索引,以便按位置進行選擇。之后,它將數據分為訓練和測試,75% 用于訓練,25% 用于測試。最后,它使用索引來分離數據并返回用于訓練的數據幀:
```py
def get_data():
print("Inside get data ...")
df = readers.read_file(data_file, sep="::")
rows = len(df)
df = df.iloc[np.random.permutation(rows)].reset_index(drop=True)
split_index = int(rows * 0.75)
df_train = df[0:split_index]
df_test = df[split_index:].reset_index(drop=True)
print("Done !!!")
print(df.shape)
return df_train, df_test,df['user'].max(),df['item'].max()
```
10. 然后,我們在數組中剪切值的限制:給定一個間隔,將間隔外的值剪切到間隔的邊緣。例如,如果指定`[0,1]`間隔,則小于 0 的值變為 0,大于 1 的值變為 1:
```py
def clip(x):
return np.clip(x, 1.0, 5.0)
```
然后,我們調用`read_data()`方法從評級文件中讀取數據以構建 TensorFlow 模型:
```py
df_train, df_test,u_num,i_num = get_data()
>>>
Inside get data...
Done!!!
```
1. 然后,我們定義數據集中評級電影的用戶數量,以及數據集中的電影數量:
```py
u_num = 6040 # Number of users in the dataset
i_num = 3952 # Number of movies in the dataset
```
2. 現在讓我們生成每批樣本數量:
```py
samples_per_batch = len(df_train) // batch_size
print("Number of train samples %d, test samples %d, samples per batch %d" % (len(df_train), len(df_test), samples_per_batch))
>>>
Number of train samples 750156, test samples 250053, samples per batch 7501
```
3. 現在,使用`ShuffleIterator`,我們生成隨機批次。在訓練中,這有助于防止偏差結果以及過擬合:
```py
iter_train = readers.ShuffleIterator([df_train["user"], df_train["item"],df_train["rate"]], batch_size=batch_size)
```
4. 有關此類的更多信息,請參閱`readers.py`腳本。為方便起見,以下是此類的來源:
```py
class ShuffleIterator(object):
def __init__(self, inputs, batch_size=10):
self.inputs = inputs
self.batch_size = batch_size
self.num_cols = len(self.inputs)
self.len = len(self.inputs[0])
self.inputs = np.transpose(np.vstack([np.array(self.inputs[i]) for i in range(self.num_cols)]))
def __len__(self):
return self.len
def __iter__(self):
return self
def __next__(self):
return self.next()
def next(self):
ids = np.random.randint(0, self.len, (self.batch_size,))
out = self.inputs[ids, :]
return [out[:, i] for i in range(self.num_cols)]
```
5. 然后我們依次生成一個周期的批次進行測試(參見`train.py`):
```py
iter_test = readers.OneEpochIterator([df_test["user"], df_test["item"], df_test["rate"]], batch_size=-1)
```
6. 有關此類的更多信息,請參閱`readers.py`腳本。為了方便,這里是這個類的源碼:
```py
class OneEpochIterator(ShuffleIterator):
def __init__(self, inputs, batch_size=10):
super(OneEpochIterator, self).__init__(inputs, batch_size=batch_size)
if batch_size > 0:
self.idx_group = np.array_split(np.arange(self.len), np.ceil(self.len / batch_size))
else:
self.idx_group = [np.arange(self.len)]
self.group_id = 0
def next(self):
if self.group_id >= len(self.idx_group):
self.group_id = 0
raise StopIteration
out = self.inputs[self.idx_group[self.group_id], :]
self.group_id += 1
return [out[:, i] for i in range(self.num_cols)]
```
7. 現在是創建 TensorFlow 占位符的時間:
```py
user_batch = tf.placeholder(tf.int32, shape=[None], name="id_user")
item_batch = tf.placeholder(tf.int32, shape=[None], name="id_item")
rate_batch = tf.placeholder(tf.float32, shape=[None])
```
8. 現在我們的訓練集和占位符已準備好容納訓練值的批次,現在該實例化模型了。 為此,我們使用`model()`方法并使用 l2 正則化來避免過擬合(請參見`model.py`腳本):
```py
infer, regularizer = md.model(user_batch, item_batch, user_num=u_num, item_num=i_num, dim=dims, device=place_device)
```
`model()`方法如下:
```py
def model(user_batch, item_batch, user_num, item_num, dim=5, device="/cpu:0"):
with tf.device("/cpu:0"):
# Using a global bias term
bias_global = tf.get_variable("bias_global", shape=[])
# User and item bias variables: get_variable: Prefixes the name with the current variable
# scope and performs reuse checks.
w_bias_user = tf.get_variable("embd_bias_user", shape=[user_num])
w_bias_item = tf.get_variable("embd_bias_item", shape=[item_num])
# embedding_lookup: Looks up 'ids' in a list of embedding tensors
# Bias embeddings for user and items, given a batch
bias_user = tf.nn.embedding_lookup(w_bias_user, user_batch, name="bias_user")
bias_item = tf.nn.embedding_lookup(w_bias_item, item_batch, name="bias_item")
# User and item weight variables
w_user = tf.get_variable("embd_user", shape=[user_num, dim],
initializer=tf.truncated_normal_initializer(stddev=0.02))
w_item = tf.get_variable("embd_item", shape=[item_num, dim],
initializer=tf.truncated_normal_initializer(stddev=0.02))
# Weight embeddings for user and items, given a batch
embd_user = tf.nn.embedding_lookup(w_user, user_batch, name="embedding_user")
embd_item = tf.nn.embedding_lookup(w_item, item_batch, name="embedding_item")
# reduce_sum: Computes the sum of elements across dimensions of a tensor
infer = tf.reduce_sum(tf.multiply(embd_user, embd_item), 1)
infer = tf.add(infer, bias_global)
infer = tf.add(infer, bias_user)
infer = tf.add(infer, bias_item, name="svd_inference")
# l2_loss: Computes half the L2 norm of a tensor without the sqrt
regularizer = tf.add(tf.nn.l2_loss(embd_user), tf.nn.l2_loss(embd_item), name="svd_regularizer")
return infer, regularizer
```
9. 現在讓我們定義訓練操作(參見`models.py`腳本中的更多內容):
```py
_, train_op = md.loss(infer, regularizer, rate_batch, learning_rate=0.001, reg=0.05, device=place_device)
```
`loss()`方法如下:
```py
def loss(infer, regularizer, rate_batch, learning_rate=0.1, reg=0.1, device="/cpu:0"):
with tf.device(device):
cost_l2 = tf.nn.l2_loss(tf.subtract(infer, rate_batch))
penalty = tf.constant(reg, dtype=tf.float32, shape=[], name="l2")
cost = tf.add(cost_l2, tf.multiply(regularizer, penalty))
train_op = tf.train.FtrlOptimizer(learning_rate).minimize(cost)
return cost, train_op
```
1. 一旦我們實例化了模型和訓練操作,我們就可以保存模型以備將來使用:
```py
saver = tf.train.Saver()
init_op = tf.global_variables_initializer()
session_conf = tf.ConfigProto(
allow_soft_placement=allow_soft_placement, log_device_placement=log_device_placement)
```
2. 現在我們開始訓練模型:
```py
with tf.Session(config = session_conf) as sess:
sess.run(init_op)
print("%s\t%s\t%s\t%s" % ("Epoch", "Train err", "Validation err", "Elapsed Time"))
errors = deque(maxlen=samples_per_batch)
train_error=[]
val_error=[]
start = time.time()
for i in range(max_epochs * samples_per_batch):
users, items, rates = next(iter_train)
_, pred_batch = sess.run([train_op, infer], feed_dict={user_batch: users, item_batch: items, rate_batch: rates})
pred_batch = clip(pred_batch)
errors.append(np.power(pred_batch - rates, 2))
if i % samples_per_batch == 0:
train_err = np.sqrt(np.mean(errors))
test_err2 = np.array([])
for users, items, rates in iter_test:
pred_batch = sess.run(infer, feed_dict={user_batch: users, item_batch: items})
pred_batch = clip(pred_batch)
test_err2 = np.append(test_err2, np.power(pred_batch - rates, 2))
end = time.time()
print("%02d\t%.3f\t\t%.3f\t\t%.3f secs" % (i // samples_per_batch, train_err, np.sqrt(np.mean(test_err2)), end - start))
train_error.append(train_err)
val_error.append(np.sqrt(np.mean(test_err2)))
start = end
saver.save(sess, checkpoint_prefix)
pd.DataFrame({'training error':train_error,'validation error':val_error}).to_pickle("val_error.pkl")
print("Training Done !!!")
sess.close()
```
3. 前面的代碼執行訓練并將誤差保存在 PKL 文件中。最后,它打印了訓練和驗證誤差以及所花費的時間:
```py
>>>
Epoch Train err Validation err Elapsed Time
00 2.816 2.812 0.118 secs
01 2.813 2.812 4.898 secs
… … … …
48 2.770 2.767 1.618 secs
49 2.765 2.760 1.678 secs
```
完成訓練!!!
結果是刪節,只顯示了幾個步驟。現在讓我們以圖形方式看到這些誤差:
```py
error = pd.read_pickle("val_error.pkl")
error.plot(title="Training vs validation error (per epoch)")
plt.ylabel('Error/loss')
plt.xlabel('Epoch');
plt.show()
>>>
```
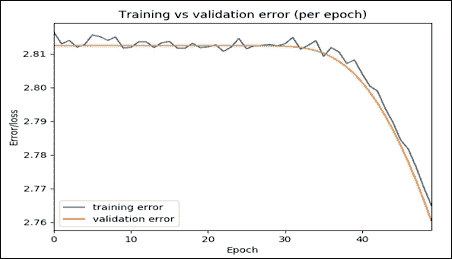
圖 5:每個周期的訓練與驗證誤差
該圖表明,隨著時間的推移,訓練和驗證誤差都會減少,這意味著我們正朝著正確的方向行走。盡管如此,您仍然可以嘗試增加步驟,看看這兩個值是否可以進一步降低,這意味著更高的準確率。
### 使用已保存的模型執行推斷
以下代碼使用保存的模型執行模型推理,并打印整體驗證誤差:
```py
if val:
print("Validation ...")
init_op = tf.global_variables_initializer()
session_conf = tf.ConfigProto(
allow_soft_placement=allow_soft_placement,
log_device_placement=log_device_placement)
with tf.Session(config = session_conf) as sess:
new_saver = tf.train.import_meta_graph("{}.meta".format(checkpoint_prefix))
new_saver.restore(sess, tf.train.latest_checkpoint(checkpoint_dir))
test_err2 = np.array([])
for users, items, rates in iter_test:
pred_batch = sess.run(infer, feed_dict={user_batch: users, item_batch: items})
pred_batch = clip(pred_batch)
test_err2 = np.append(test_err2, np.power(pred_batch - rates, 2))
print("Validation Error: ",np.sqrt(np.mean(test_err2)))
print("Done !!!")
sess.close()
>>>
Validation Error: 2.14626890224
Done!!!
```
### 生成用戶項表
以下方法創建用戶項數據幀。它用于創建訓練有素的`DataFrame`。使用 SVD 訓練模型在此處填寫用戶項表中的所有缺失值。它采用評級數據幀并存儲所有電影的所有用戶評級。最后,它會生成一個填充的評級數據幀,其中行是用戶,列是項:
```py
def create_df(ratings_df=readers.read_file(data_file, sep="::")):
if os.path.isfile("model/user_item_table.pkl"):
df=pd.read_pickle("user_item_table.pkl")
else:
df = ratings_df.pivot(index = 'user', columns ='item', values = 'rate').fillna(0)
df.to_pickle("user_item_table.pkl")
df=df.T
users=[]
items=[]
start = time.time()
print("Start creating user-item dense table")
total_movies=list(ratings_df.item.unique())
for index in df.columns.tolist():
#rated_movies=ratings_df[ratings_df['user']==index].drop(['st', 'user'], axis=1)
rated_movie=[]
rated_movie=list(ratings_df[ratings_df['user']==index].drop(['st', 'user'], axis=1)['item'].values)
unseen_movies=[]
unseen_movies=list(set(total_movies) - set(rated_movie))
for movie in unseen_movies:
users.append(index)
items.append(movie)
end = time.time()
print(("Found in %.2f seconds" % (end-start)))
del df
rated_list = []
init_op = tf.global_variables_initializer()
session_conf = tf.ConfigProto(
allow_soft_placement=allow_soft_placement,
log_device_placement=log_device_placement)
with tf.Session(config = session_conf) as sess:
#sess.run(init_op)
print("prediction started ...")
new_saver = tf.train.import_meta_graph("{}.meta".format(checkpoint_prefix))
new_saver.restore(sess, tf.train.latest_checkpoint(checkpoint_dir))
test_err2 = np.array([])
rated_list = sess.run(infer, feed_dict={user_batch: users, item_batch: items})
rated_list = clip(rated_list)
print("Done !!!")
sess.close()
df_dict={'user':users,'item':items,'rate':rated_list}
df = ratings_df.drop(['st'],axis=1).append(pd.DataFrame(df_dict)).pivot(index = 'user', columns ='item', values = 'rate').fillna(0)
df.to_pickle("user_item_table_train.pkl")
return df
```
現在讓我們調用前面的方法來生成用戶項表作為 pandas 數據幀:
```py
create_df(ratings_df = readers.read_file(data_file, sep="::"))
```
此行將為訓練集創建用戶與項目表,并將數據幀保存為指定目錄中的`user_item_table_train.pkl`文件。
### 聚類類似的電影
對于這一部分,請參閱`kmean.py`腳本。此腳本將評級數據文件作為輸入,并返回電影及其各自的簇。
從技術上講,本節的目的是找到類似的電影;例如,用戶 1 喜歡電影 1,并且因為電影 1 和電影 2 相似,所以用戶想要電影 2.讓我們開始導入所需的包和模塊:
```py
import tensorflow as tf
import numpy as np
import pandas as pd
import time
import readers
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.decomposition import PCA
```
現在讓我們定義要使用的數據參數:評級數據文件的路徑,簇的數量,K 和最大迭代次數。此外,我們還定義了是否要使用經過訓練的用戶與項目矩陣:
```py
data_file = "Input/ratings.dat" #Data source for the positive data
K = 5 # Number of clusters
MAX_ITERS =1000 # Maximum number of iterations
TRAINED = False # Use TRAINED user vs item matrix
```
然后定義`k_mean_clustering ()`方法。它返回電影及其各自的群集。它采用評級數據集`ratings_df`,這是一個評級數據幀。然后它存儲各個電影的所有用戶評級,`K`是簇的數量,`MAX_ITERS`是推薦的最大數量,`TRAINED`是一種布爾類型,表示是否使用受過訓練的用戶與電影表或未經訓練的人。
### 提示
如何找到最佳 K 值
在這里,我們樸素地設定 K 的值。但是,為了微調聚類表現,我們可以使用一種稱為 Elbow 方法的啟發式方法。我們從`K = 2`開始,然后,我們通過增加 K 來運行 K 均值算法并使用 WCSS 觀察成本函數(CF)的值。在某些時候,CF 會大幅下降。然而,隨著 K 值的增加,這種改善變得微不足道。總之,我們可以在 WCSS 的最后一次大跌之后選擇 K 作為最佳值。
最后,`k_mean_clustering()`函數返回一個電影/項目列表和一個簇列表:
```py
def k_mean_clustering(ratings_df,K,MAX_ITERS,TRAINED=False):
if TRAINED:
df=pd.read_pickle("user_item_table_train.pkl")
else:
df=pd.read_pickle("user_item_table.pkl")
df = df.T
start = time.time()
N=df.shape[0]
points = tf.Variable(df.as_matrix())
cluster_assignments = tf.Variable(tf.zeros([N], dtype=tf.int64))
centroids = tf.Variable(tf.slice(points.initialized_value(), [0,0], [K,df.shape[1]]))
rep_centroids = tf.reshape(tf.tile(centroids, [N, 1]), [N, K, df.shape[1]])
rep_points = tf.reshape(tf.tile(points, [1, K]), [N, K, df.shape[1]])
sum_squares = tf.reduce_sum(tf.square(rep_points - rep_centroids),reduction_indices=2)
best_centroids = tf.argmin(sum_squares, 1) did_assignments_change = tf.reduce_any(tf.not_equal(best_centroids, cluster_assignments))
means = bucket_mean(points, best_centroids, K)
with tf.control_dependencies([did_assignments_change]):
do_updates = tf.group(
centroids.assign(means),
cluster_assignments.assign(best_centroids))
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
changed = True
iters = 0
while changed and iters < MAX_ITERS:
iters += 1
[changed, _] = sess.run([did_assignments_change, do_updates])
[centers, assignments] = sess.run([centroids, cluster_assignments])
end = time.time()
print (("Found in %.2f seconds" % (end-start)), iters, "iterations")
cluster_df=pd.DataFrame({'movies':df.index.values,'clusters':assignments})
cluster_df.to_csv("clusters.csv",index=True)
return assignments,df.index.values
```
在前面的代碼中,我們有一個愚蠢的初始化,在某種意義上我們使用前 K 個點作為起始質心。在現實世界中,它可以進一步改進。
在前面的代碼塊中,我們復制每個質心的 N 個副本和每個數據點的 K 個副本。然后我們減去并計算平方距離的總和。然后我們使用`argmin`選擇最低距離點。但是,在計算分配是否已更改之前,我們不會編寫已分配的群集變量,因此具有依賴性。
如果仔細查看前面的代碼,有一個名為`bucket_mean()`的函數。它獲取數據點,最佳質心和暫定簇的數量 K,并計算在簇計算中使用的平均值:
```py
def bucket_mean(data, bucket_ids, num_buckets):
total = tf.unsorted_segment_sum(data, bucket_ids, num_buckets)
count = tf.unsorted_segment_sum(tf.ones_like(data), bucket_ids, num_buckets)
return total / count
```
一旦我們訓練了我們的 K 均值模型,下一個任務就是可視化代表類似電影的那些簇。為此,我們有一個名為`showClusters()`的函數,它接受用戶項表,CSV 文件(`clusters.csv`)中寫入的聚簇數據,主成分數(默認為 2)和 SVD 求解器(可能的值是隨機的和完整的)。
問題是,在 2D 空間中,很難繪制代表電影簇的所有數據點。出于這個原因,我們應用主成分分析(PCA)來降低維數而不會犧牲質量:
```py
user_item=pd.read_pickle(user_item_table)
cluster=pd.read_csv(clustered_data, index_col=False)
user_item=user_item.T
pcs = PCA(number_of_PCA_components, svd_solver)
cluster['x']=pcs.fit_transform(user_item)[:,0]
cluster['y']=pcs.fit_transform(user_item)[:,1]
fig = plt.figure()
ax = plt.subplot(111)
ax.scatter(cluster[cluster['clusters']==0]['x'].values,cluster[cluster['clusters']==0]['y'].values,color="r", label='cluster 0')
ax.scatter(cluster[cluster['clusters']==1]['x'].values,cluster[cluster['clusters']==1]['y'].values,color="g", label='cluster 1')
ax.scatter(cluster[cluster['clusters']==2]['x'].values,cluster[cluster['clusters']==2]['y'].values,color="b", label='cluster 2')
ax.scatter(cluster[cluster['clusters']==3]['x'].values,cluster[cluster['clusters']==3]['y'].values,color="k", label='cluster 3')
ax.scatter(cluster[cluster['clusters']==4]['x'].values,cluster[cluster['clusters']==4]['y'].values,color="c", label='cluster 4')
ax.legend()
plt.title("Clusters of similar movies using K-means")
plt.ylabel('PC2')
plt.xlabel('PC1');
plt.show()
```
做得好。我們將評估我們的模型并在評估步驟中繪制簇。
### 預測用戶的電影評級
為此,我編寫了一個名為`prediction()`的函數。它采用有關用戶和項目(在本例中為電影)的示例輸入,并按名稱從圖創建 TensorFlow 占位符。然后它求值這些張量。在以下代碼中,需要注意的是 TensorFlow 假定檢查點目錄已存在,因此請確保它已存在。有關此步驟的詳細信息,請參閱`run.py`文件。請注意,此腳本不顯示任何結果,但在`main.py`腳本中進一步調用此腳本中名為`prediction`的函數進行預測:
```py
def prediction(users=predicted_user, items=predicted_item, allow_soft_placement=allow_soft_placement,\
log_device_placement=log_device_placement, checkpoint_dir=checkpoint_dir):
rating_prediction=[]
checkpoint_prefix = os.path.join(checkpoint_dir, "model")
graph = tf.Graph()
with graph.as_default():
session_conf = tf.ConfigProto(allow_soft_placement=allow_soft_placement,log_device_placement=log_device_placement)
with tf.Session(config = session_conf) as sess:
new_saver = tf.train.import_meta_graph("{}.meta".format(checkpoint_prefix))
new_saver.restore(sess, tf.train.latest_checkpoint(checkpoint_dir))
user_batch = graph.get_operation_by_name("id_user").outputs[0]
item_batch = graph.get_operation_by_name("id_item").outputs[0]
predictions = graph.get_operation_by_name("svd_inference").outputs[0]
pred = sess.run(predictions, feed_dict={user_batch: users, item_batch: items})
pred = clip(pred)
sess.close()
return pred
```
我們將看到如何使用此方法來預測電影的前 K 部電影和用戶評級。在前面的代碼段中,`clip()`是一個用戶定義的函數,用于限制數組中的值。這是實現:
```py
def clip(x):
return np.clip(x, 1.0, 5.0) # rating 1 to 5
```
現在讓我們看看,我們如何使用`prediction()`方法來制作用戶的一組電影評級預測:
```py
def user_rating(users,movies):
if type(users) is not list: users=np.array([users])
if type(movies) is not list:
movies=np.array([movies])
return prediction(users,movies)
```
上述函數返回各個用戶的用戶評級。它采用一個或多個數字的列表,一個或多個用戶 ID 的列表,以及一個或多個數字的列表以及一個或多個電影 ID 的列表。最后,它返回預測電影列表。
### 尋找前 K 部電影
以下方法提取用戶未見過的前 K 個電影,其中 K 是任意整數,例如 10.函數的名稱是`top_k_movies()`。它返回特定用戶的前 K 部電影。它需要一個用戶 ID 列表和評級數據幀。然后它存儲這些電影的所有用戶評級。輸出是包含用戶 ID 作為鍵的字典,以及該用戶的前 K 電影列表作為值:
```py
def top_k_movies(users,ratings_df,k):
dicts={}
if type(users) is not list:
users = [users]
for user in users:
rated_movies = ratings_df[ratings_df['user']==user].drop(['st', 'user'], axis=1)
rated_movie = list(rated_movies['item'].values)
total_movies = list(ratings_df.item.unique())
unseen_movies = list(set(total_movies) - set(rated_movie))
rated_list = []
rated_list = prediction(np.full(len(unseen_movies),user),np.array(unseen_movies))
useen_movies_df = pd.DataFrame({'item': unseen_movies,'rate':rated_list})
top_k = list(useen_movies_df.sort_values(['rate','item'], ascending=[0, 0])['item'].head(k).values)
dicts.update({user:top_k})
result = pd.DataFrame(dicts)
result.to_csv("user_top_k.csv")
return dicts
```
在前面的代碼段中,`prediction()`是我們之前描述的用戶定義函數。我們將看到一個如何預測前 K 部電影的例子(更多或見后面的部分見`Test.py`)。
### 預測前 K 類似的電影
我編寫了一個名為`top_k_similar_items()`的函數,它計算并返回與特定電影類似的 K 個電影。它需要一個數字列表,數字,電影 ID 列表和評級數據幀。它存儲這些電影的所有用戶評級。它還將 K 作為自然數。
`TRAINED`的值可以是`TRUE`或`FALSE`,它指定是使用受過訓練的用戶還是使用電影表或未經訓練的用戶。最后,它返回一個 K 電影列表,類似于作為輸入傳遞的電影:
```py
def top_k_similar_items(movies,ratings_df,k,TRAINED=False):
if TRAINED:
df=pd.read_pickle("user_item_table_train.pkl")
else:
df=pd.read_pickle("user_item_table.pkl")
corr_matrix=item_item_correlation(df,TRAINED)
if type(movies) is not list:
return corr_matrix[movies].sort_values(ascending=False).drop(movies).index.values[0:k]
else:
dict={}
for movie in movies: dict.update({movie:corr_matrix[movie].sort_values(ascending=False).drop(movie).index.values[0:k]})
pd.DataFrame(dict).to_csv("movie_top_k.csv")
return dict
```
在前面的代碼中,`item_item_correlation()`函數是一個用戶定義的函數,它計算在預測前 K 個類似電影時使用的電影 - 電影相關性。方法如下:
```py
def item_item_correlation(df,TRAINED):
if TRAINED:
if os.path.isfile("model/item_item_corr_train.pkl"):
df_corr=pd.read_pickle("item_item_corr_train.pkl")
else:
df_corr=df.corr()
df_corr.to_pickle("item_item_corr_train.pkl")
else:
if os.path.isfile("model/item_item_corr.pkl"):
df_corr=pd.read_pickle("item_item_corr.pkl")
else:
df_corr=df.corr()
df_corr.to_pickle("item_item_corr.pkl")
return df_corr
```
### 計算用戶 - 用戶相似度
為了計算用戶 - 用戶相似度,我編寫了`user_similarity()`函數,它返回兩個用戶之間的相似度。它需要三個參數:用戶 1,用戶 2;評級數據幀;并且`TRAINED`的值可以是`TRUE`或`FALSE`,并且指的是是否應該使用受過訓練的用戶與電影表或未經訓練的用戶。最后,它計算用戶之間的 Pearson 系數(介于 -1 和 1 之間的值):
```py
def user_similarity(user_1,user_2,ratings_df,TRAINED=False):
corr_matrix=user_user_pearson_corr(ratings_df,TRAINED)
return corr_matrix[user_1][user_2]
```
在前面的函數中,`user_user_pearson_corr()`是一個計算用戶 - 用戶 Pearson 相關性的函數:
```py
def user_user_pearson_corr(ratings_df,TRAINED):
if TRAINED:
if os.path.isfile("model/user_user_corr_train.pkl"):
df_corr=pd.read_pickle("user_user_corr_train.pkl")
else:
df =pd.read_pickle("user_item_table_train.pkl")
df=df.T
df_corr=df.corr()
df_corr.to_pickle("user_user_corr_train.pkl")
else:
if os.path.isfile("model/user_user_corr.pkl"):
df_corr=pd.read_pickle("user_user_corr.pkl")
else:
df = pd.read_pickle("user_item_table.pkl")
df=df.T
df_corr=df.corr()
df_corr.to_pickle("user_user_corr.pkl")
return df_corr
```
## 評估推薦系統
在這個小節中,我們將通過繪制它們以評估電影如何在不同的簇中傳播來評估簇。
然后,我們將看到前 K 部電影,并查看我們之前討論過的用戶 - 用戶相似度和其他指標。現在讓我們開始導入所需的庫:
```py
import tensorflow as tf
import pandas as pd
import readers
import main
import kmean as km
import numpy as np
```
接下來,讓我們定義用于評估的數據參數:
```py
DATA_FILE = "Input/ratings.dat" # Data source for the positive data.
K = 5 #Number of clusters
MAX_ITERS = 1000 #Maximum number of iterations
TRAINED = False # Use TRAINED user vs item matrix
USER_ITEM_TABLE = "user_item_table.pkl"
COMPUTED_CLUSTER_CSV = "clusters.csv"
NO_OF_PCA_COMPONENTS = 2 #number of pca components
SVD_SOLVER = "randomized" #svd solver -e.g. randomized, full etc.
```
讓我們看看加載將在`k_mean_clustering()`方法的調用調用中使用的評級數據集:
```py
ratings_df = readers.read_file("Input/ratings.dat", sep="::")
clusters,movies = km.k_mean_clustering(ratings_df, K, MAX_ITERS, TRAINED = False)
cluster_df=pd.DataFrame({'movies':movies,'clusters':clusters})
```
做得好!現在讓我們看一些簡單的輸入簇(電影和各自的簇):
```py
print(cluster_df.head(10))
>>>
clusters movies
0 0 0
1 4 1
2 4 2
3 3 3
4 4 4
5 2 5
6 4 6
7 3 7
8 3 8
9 2 9
print(cluster_df[cluster_df['movies']==1721])
>>>
clusters movies
1575 2 1721
print(cluster_df[cluster_df['movies']==647])
>>>
clusters movies
627 2 647
```
讓我們看看電影是如何分散在群集中的:
```py
km.showClusters(USER_ITEM_TABLE, COMPUTED_CLUSTER_CSV, NO_OF_PCA_COMPONENTS, SVD_SOLVER)
>>>
```
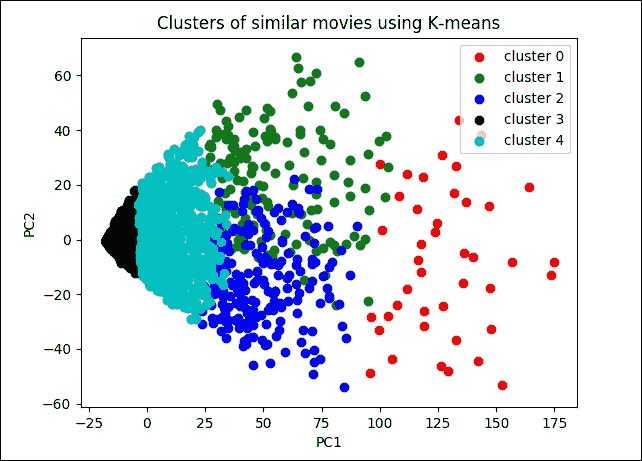
圖 6:類似電影的簇
如果我們查看該圖,很明顯數據點更準確地聚集在簇 3 和 4 上。但是,簇 0,1 和 2 更分散并且不能很好地聚類。
在這里,我們沒有計算任何準確率指標,因為訓練數據沒有標簽。現在讓我們為給定的相應電影名稱計算前 K 個類似的電影并打印出來:
```py
ratings_df = readers.read_file("Input/ratings.dat", sep="::")
topK = main.top_k_similar_items(9,ratings_df = ratings_df,k = 10,TRAINED = False)
print(topK)
>>>
[1721, 1369, 164, 3081, 732, 348, 647, 2005, 379, 3255]
```
上述結果為電影`9 ::Sudden Death (1995)::Action`計算了 Top-K 類似的電影。現在,如果您觀察`movies.dat`文件,您將看到以下電影與此類似:
```py
1721::Titanic (1997)::Drama|Romance
1369::I Can't Sleep (J'ai pas sommeil) (1994)::Drama|Thriller
164::Devil in a Blue Dress (1995)::Crime|Film-Noir|Mystery|Thriller
3081::Sleepy Hollow (1999)::Horror|Romance
732::Original Gangstas (1996)::Crime
348::Bullets Over Broadway (1994)::Comedy
647::Courage Under Fire (1996)::Drama|War
2005::Goonies, The (1985)::Adventure|Children's|Fantasy
379::Timecop (1994)::Action|Sci-Fi
3255::League of Their Own, A (1992)::Comedy|Drama
```
現在讓我們計算用戶 - 用戶 Pearson 相關性。當運行此用戶相似度函數時,在第一次運行時需要時間來提供輸出但在此之后,其響應是實時的:
```py
print(main.user_similarity(1,345,ratings_df))
>>>
0.15045477803357316
Now let's compute the aspect rating given by a user for a movie:
print(main.user_rating(0,1192))
>>>
4.25545645
print(main.user_rating(0,660))
>>>
3.20203304
```
讓我們看一下用戶的 K 電影推薦:
```py
print(main.top_k_movies([768],ratings_df,10))
>>>
{768: [2857, 2570, 607, 109, 1209, 2027, 592, 588, 2761, 479]}
print(main.top_k_movies(1198,ratings_df,10))
>>>
{1198: [2857, 1195, 259, 607, 109, 2027, 592, 857, 295, 479]}
```
到目前為止,我們已經看到如何使用電影和評級數據集開發簡單的 RE。但是,大多數推薦問題都假設我們有一個由(用戶,項目,評級)元組集合形成的消費/評級數據集。這是協同過濾算法的大多數變體的起點,并且已經證明它們可以產生良好的結果;但是,在許多應用中,我們有大量的項目元數據(標簽,類別和流派)可用于做出更好的預測。
這是將 FM 用于特征豐富的數據集的好處之一,因為有一種自然的方式可以在模型中包含額外的特征,并且可以使用維度參數 d 對高階交互進行建模(參見下面的圖 7)更多細節)。
最近的一些類型的研究表明,特征豐富的數據集可以提供更好的預測:i)Xiangnan He 和 Tat-Seng Chua,用于稀疏預測分析的神經分解機。在 SIGIR '17 的論文集中,2017 年 8 月 7 日至 11 日,日本東京新宿。ii)Jun Xiao,Hao Ye,Xiantian He,Hanwang Zhang,Fei Wu 和 Tat-Seng Chua(2017)Attentional Factorization Machines:Learning the Learning 通過注意網絡的特征交互的權重 IJCAI,墨爾本,澳大利亞,2017 年 8 月 19 - 25 日。
這些論文解釋了如何將現有數據轉換為特征豐富的數據集,以及如何在數據集上實現 FM。因此,研究人員正在嘗試使用 FM 來開發更準確和更強大的 RE。在下一節中,我們將看到一些使用 FM 和一些變體的示例。
# 分解機和推薦系統
在本節中,我們將看到兩個使用 FM 開發更強大的推薦系統的示例 。我們將首先簡要介紹 FM 及其在冷啟動推薦問題中的應用。
然后我們將看到使用 FM 開發真實推薦系統的簡短示例。之后,我們將看到一個使用稱為神經分解機(NFM)的 FM 算法的改進版本的示例。
## 分解機
基于 FM 的技術處于個性化的前沿。它們已經被證明是非常強大的,具有足夠的表達能力來推廣現有模型,例如矩陣/張量分解和多項式核回歸。換句話說,這種類型的算法是監督學習方法,其通過結合矩陣分解算法中不存在的二階特征交互來增強線性模型的表現。
現有的推薦算法需要(用戶,項目和評級)元組中的消費(產品)或評級(電影)數據集。這些類型的數據集主要用于協同過濾(CF)算法的變體。 CF 算法已得到廣泛采用,并已證明可以產生良好的結果。但是,在許多情況下,我們有大量的項目元數據(標簽,類別和流派),可以用來做出更好的預測。不幸的是,CF 算法不使用這些類型的元數據。
FM 可以使用這些特征豐富的(元)數據集。 FM 可以使用這些額外的特征來模擬指定維度參數 d 的高階交互。最重要的是,FM 還針對處理大規模稀疏數據集進行了優化。因此,二階 FM 模型就足夠了,因為沒有足夠的信息來估計更復雜的交互:

圖 7:表示具有特征向量 x 和目標 y 的個性化問題的示例訓練數據集。這里的行指的是導演,演員和流派信息的電影和專欄
假設預測問題的數據集由設計矩陣`X ∈ R^nxp`描述,如圖 7 所示。在圖 1 中,`X`的第`i`行`X ∈ R^p`描述了一種情況,其中`p`是實數估值變量。另一方面,`y[i]`是第`i`個情況的預測目標。或者,我們可以將此集合描述為元組`(x, y)`的集合`S`,其中(同樣)`x ∈ R^p`是特征向量,`y`是其對應的目標或標簽。
換句話說,在圖 7 中,每行表示特征向量`x[i]`與其相應的目標`y[i]`。為了便于解釋,這些特征分為活躍用戶(藍色),活動項目(紅色),同一用戶評級的其他電影(橙色),月份時間(綠色)和最后一部電影評級指標(棕色)。然后,FM 算法使用以下分解的交互參數來模擬`x`中`p`輸入變量之間的所有嵌套交互(直到`d`階):
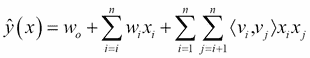
在等式中,`v`表示與每個變量(用戶和項目)相關聯的 K 維潛在向量,并且括號運算符表示內積。具有數據矩陣和特征向量的這種表示在許多機器學習方法中是常見的,例如,在線性回歸或支持向量機(SVM)中。
但是,如果您熟悉矩陣分解(MF)模型,則前面的等式應該看起來很熟悉:它包含全局偏差以及用戶/項目特定的偏差,并包括用戶項目交互。現在,如果我們假設每個`x(j)`向量在位置`u`和`i`處僅為非零,我們得到經典的 MF 模型:
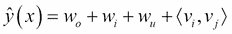
然而,用于推薦系統的 MF 模型經常遭受冷啟動問題。我們將在下一節討論這個問題。
### 冷啟動問題和協同過濾方法
冷啟動這個問題聽起來很有趣,但顧名思義,它源于汽車。假設你住在阿拉斯加狀態。由于寒冷,您的汽車發動機可能無法順利啟動,但一旦達到最佳工作溫度,它將啟動,運行并正常運行。
在推薦引擎的領域中,術語冷啟動僅僅意味著對于引擎來說還不是最佳的環境以提供最佳結果。在電子商務中,冷啟動有兩個不同的類別:產品冷啟動和用戶冷啟動。
冷啟動是基于計算機的信息系統中的潛在問題,涉及一定程度的自動數據建模。具體而言,它涉及的問題是系統無法對尚未收集到足夠信息的用戶或項目進行任何推斷。
冷啟動問題在推薦系統中最為普遍。在協同過濾方法中,推薦系統將識別與活動用戶共享偏好的用戶,并提出志同道合的用戶喜歡的項目(并且活躍用戶尚未看到)。由于冷啟動問題,這種方法將無法考慮社區中沒有人評定的項目。
通過在基于內容的匹配和協同過濾之間采用混合方法,通常可以減少冷啟動問題。尚未收到用戶評級的新項目將根據社區分配給其他類似項目的評級自動分配評級。項目相似性將根據項目的基于內容的特征來確定。
使用基于 CF 的方法的推薦引擎根據用戶操作推薦每個項目。項目具有的用戶操作越多,就越容易分辨哪個用戶對其感興趣以及其他項目與之類似。隨著時間的推移,系統將能夠提供越來越準確的建議。在某個階段,當新項目或用戶添加到用戶項目矩陣時,會出現此問題:
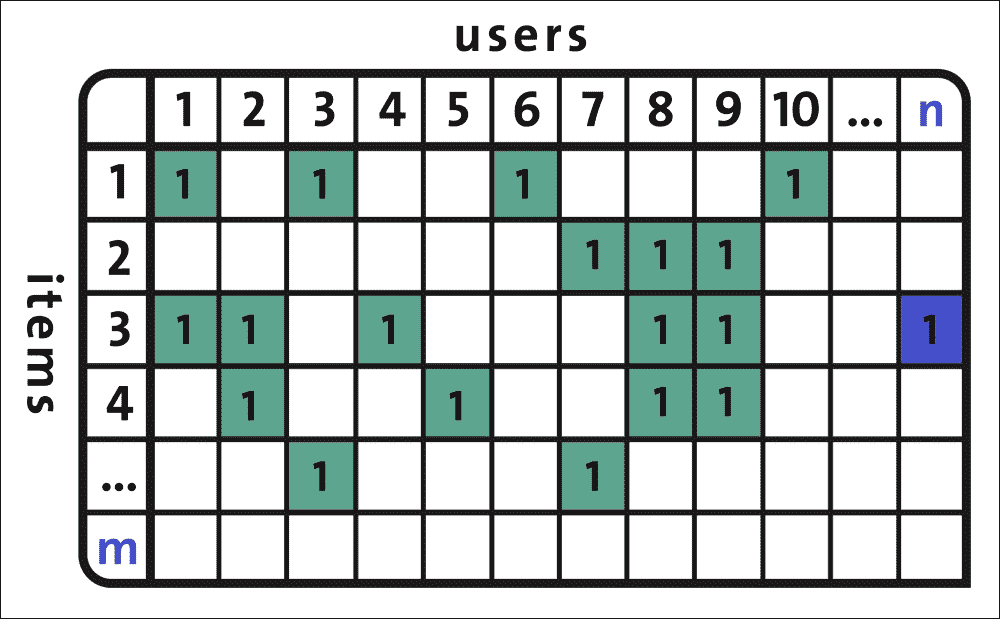
圖 8:用戶與項目矩陣有時會導致冷啟動問題
在這種情況下,RE 還沒有足夠的知識來了解這個新用戶或這個新項目。類似于 FM 的基于內容的過濾方法是可以結合以減輕冷啟動問題的方法。
前兩個方程之間的主要區別在于,FM 在潛在向量方面引入了高階相互作用,潛在向量也受分類或標簽數據的影響。這意味著模型超越了共現,以便在每個特征的潛在表示之間找到更強的關系。
## 問題的定義和制定
給定用戶在電子商務網站上的典型會話期間執行的點擊事件的序列 ,目標是預測用戶是否購買或不購買,如果他們正在購買,他們會買什么物品。因此,這項任務可分為兩個子目標:
* 用戶是否會在此會話中購買物品?
* 如果是,那么將要購買的物品是什么?
為了預測在會話中購買的項目的數量,強大的分類器可以幫助預測用戶是否將購買該項目的 。在最初實現 FM 后,訓練數據的結構應如下:

圖 9:用戶與項目/類別/歷史表可用于訓練推薦模型
為了準備這樣的訓練集,我們可以使用 pandas 中的`get_dummies()`方法將所有列轉換為分類數據,因為 FM 模型使用表示為整數的分類數據。
我們使用兩個函數`TFFMClassifier`和`TFFMRegressor`來進行預測(參見`items.py`)并分別計算 MSE(參見來自`tffm`庫的`quantity.py`腳本(在 MIT 許可下))。`tffm`是基于 TensorFlow 的 FM 和 pandas 實現,用于預處理和結構化數據。這個基于 TensorFlow 的實現提供了一個任意順序(`>= 2`)分解機,它支持:
* 密集和稀疏的輸入
* 不同的(基于梯度的)優化方法
* 通過不同的損失函數進行分類/回歸(logistic 和 mse 實現)
* 通過 TensorBoard 記錄
另一個好處是推理時間相對于特征數量是線性的。
我們要感謝作者并引用他們的工作如下:Mikhail Trofimov,Alexander Novikov,TFFM:TensorFlow 實現任意順序分解機,[GitHub 倉庫](https://github.com/geffy/tffm),2016。
要使用此庫,只需在終端上發出以下命令:
```py
$ sudo pip3 install tffm # For Python3.x
$ sudo pip install tffm # For Python 2.7.x
```
在開始實現之前,讓我們看一下我們將在本例中使用的數據集。
## 數據集描述
例如,我將使用 RecSys 2015 挑戰數據集來說明如何擬合 FM 模型以獲得個性化推薦。該數據包含電子商務網站的點擊和購買事件,以及其他項目類別數據。數據集的大小約為 275MB,可以從[此鏈接](https://s3-eu-west-1.amazonaws.com/yc-rdata/yoochoose-data.7z)下載。
有三個文件和一個自述文件;但是,我們將使用`youchoose-buys.dat`(購買活動)和`youchoose-clicks.dat`(點擊活動):
* `youchoose-clicks.dat`:文件中的每條記錄/行都包含以下字段:
* 會話 ID:一個會話中的一次或多次點擊
* 時間戳:發生點擊的時間
* 項目 ID:項目的唯一標識符
* 類別:項目的類別
* `youchoose-buys.dat`:文件中的每條記錄/行都包含以下字段:
* 會話 ID:會話 ID:會話中的一個或多個購買事件
* 時間戳:購買發生的時間
* 物料 ID:物品的唯一標識符
* 價格:商品的價格
* 數量:購買了多少件商品
`youchoose-buys.dat`中的會話 ID 也存在于`youchoose-clicks.dat`文件中。這意味著具有相同會話 ID 的記錄一起形成會話期間某個用戶的點擊事件序列。
會話可能很短(幾分鐘)或很長(幾個小時),可能只需點擊一下或點擊幾百次。這一切都取決于用戶的活動。
### 實現工作流程
讓我們開發一個預測并生成`solution.data`文件的推薦模型。這是一個簡短的工作流程:
1. 下載并加載 RecSys 2015 挑戰數據集,并復制到本章代碼庫的`data`文件夾中
2. 購買數據包含會話 ID,時間戳,項目 ID,類別和數量。此外,`youchoose-clicks.dat`包含會話 ID,時間戳,項目 ID 和類別。我們不會在這里使用時間戳。我們刪除時間戳,對所有列進行單熱編碼, 合并買入和點擊數據集以使數據集特征豐富。在預處理之后,數據看起來類似于圖 11 中所示的數據。
3. 為簡化起見,我們僅考慮前 10,000 個會話,并將數據集拆分為訓練(75%)和測試(25%)集。
4. 然后,我們將測試分為正常(保留歷史數據)和冷啟動(通過刪除歷史數據),以區分具有歷史記錄或沒有歷史記錄的用戶/項目的模型。
5. 然后我們使用`tffm`訓練我們的 FM 模型,這是 TensorFlow 中 FM 的實現,并使用訓練數據訓練模型。
6. 最后,我們在正常和冷啟動數據集上評估模型。
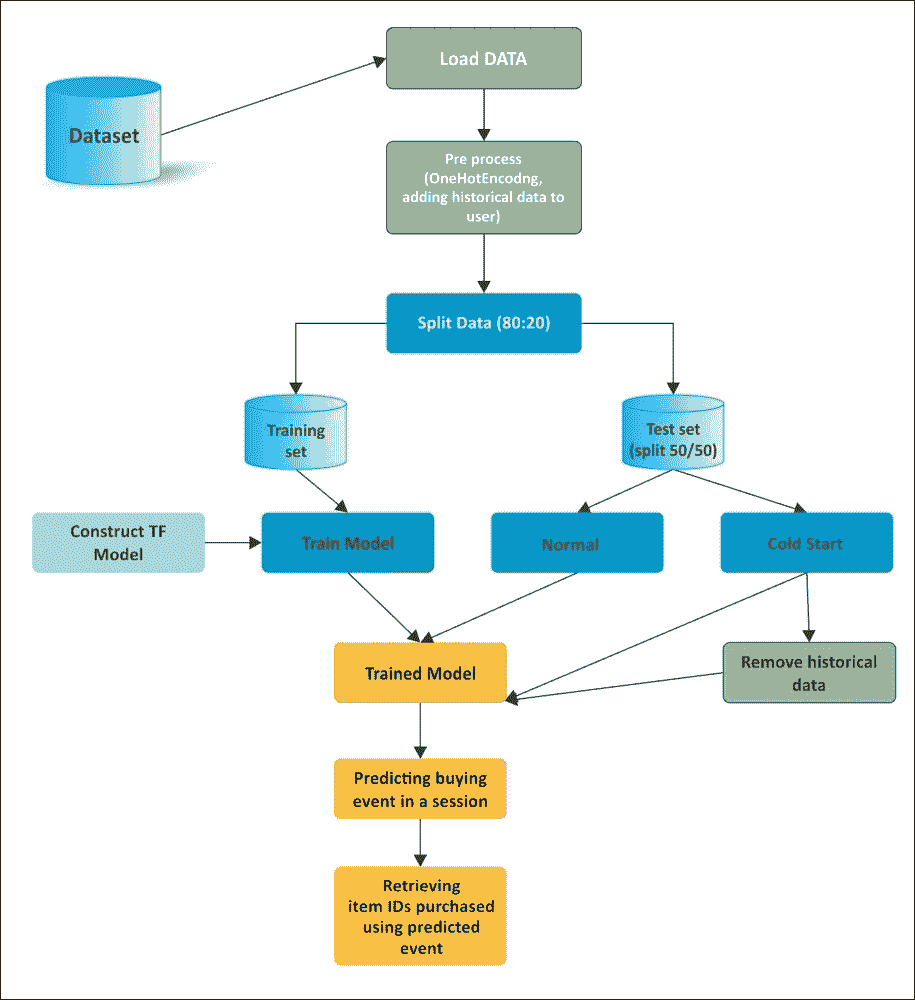
圖 10:使用 FM 預測會話中已購買項目列表的工作流程
## 預處理
如果我們想充分利用類別和擴展的歷史數據,我們需要加載數據并將其轉換為正確的格式。因此,在準備訓練集之前,必須進行一些預處理。讓我們從加載包和模塊開始:
```py
import tensorflow as tf
import pandas as pd
from collections import Counter
from tffm import TFFMClassifier
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
import numpy as np
from sklearn.metrics import accuracy_score
import os
```
我是 ,假設您已經從前面提到的鏈接下載了數據集。現在讓我們加載數據集:
```py
buys = open('data/yoochoose-buys.dat', 'r')
clicks = open('data/yoochoose-clicks.dat', 'r')
```
現在為點擊創建 pandas 數據幀并購買數據集:
```py
initial_buys_df = pd.read_csv(buys, names=['Session ID', 'Timestamp', 'Item ID', 'Category', 'Quantity'], dtype={'Session ID': 'float32', 'Timestamp': 'str', 'Item ID': 'float32','Category': 'str'})
initial_buys_df.set_index('Session ID', inplace=True)
initial_clicks_df = pd.read_csv(clicks, names=['Session ID', 'Timestamp', 'Item ID', 'Category'],dtype={'Category': 'str'})
initial_clicks_df.set_index('Session ID', inplace=True)
```
我們不需要在這個例子中使用時間戳,所以讓我們從數據幀中刪除它們:
```py
initial_buys_df = initial_buys_df.drop('Timestamp', 1)
print(initial_buys_df.head()) # first five records
print(initial_buys_df.shape) # shape of the dataframe
>>>
```

```py
initial_clicks_df = initial_clicks_df.drop('Timestamp', 1)
print(initial_clicks_df.head())
print(initial_clicks_df.shape)
>>>
```

由于在此示例中我們不使用時間戳,因此從數據幀(`df`)中刪除`Timestamp`列:
```py
initial_buys_df = initial_buys_df.drop('Timestamp', 1)
print(initial_buys_df.head(n=5))
print(initial_buys_df.shape)
>>>
```

```py
initial_clicks_df = initial_clicks_df.drop('Timestamp', 1)
print(initial_clicks_df.head(n=5))
print(initial_clicks_df.shape)
>>>
```
讓我們選取前 10,000 名購買用戶:
```py
x = Counter(initial_buys_df.index).most_common(10000)
top_k = dict(x).keys()
initial_buys_df = initial_buys_df[initial_buys_df.index.isin(top_k)]
print(initial_buys_df.head())
print(initial_buys_df.shape)
>>>
```

```py
initial_clicks_df = initial_clicks_df[initial_clicks_df.index.isin(top_k)]
print(initial_clicks_df.head())
print(initial_clicks_df.shape)
>>>
```
現在讓我們創建索引的副本,因為我們還將對其應用單熱編碼:
```py
initial_buys_df['_Session ID'] = initial_buys_df.index
print(initial_buys_df.head())
print(initial_buys_df.shape)
>>>
```
正如我們之前提到的 ,我們可以將歷史參與數據引入我們的 FM 模型。我們將使用一些`group_by`魔法生成整個用戶參與的歷史記錄。首先,我們對所有列進行單熱編碼以獲得點擊和購買:
```py
transformed_buys = pd.get_dummies(initial_buys_df)
print(transformed_buys.shape)
>>>
(106956, 356)
transformed_clicks = pd.get_dummies(initial_clicks_df)print(transformed_clicks.shape)
>>>
(209024, 56)
```
現在是時候匯總項目和類別的歷史數據了:
```py
filtered_buys = transformed_buys.filter(regex="Item.*|Category.*")
print(filtered_buys.shape)
>>>
(106956, 354)
filtered_clicks = transformed_clicks.filter(regex="Item.*|Category.*")
print(filtered_clicks.shape)
>>>
(209024, 56)
historical_buy_data = filtered_buys.groupby(filtered_buys.index).sum()
print(historical_buy_data.shape)
>>>
(10000, 354)
historical_buy_data = historical_buy_data.rename(columns=lambda column_name: 'buy history:' + column_name)
print(historical_buy_data.shape)
>>>
(10000, 354)
historical_click_data = filtered_clicks.groupby(filtered_clicks.index).sum()
print(historical_click_data.shape)
>>>
(10000, 56)
historical_click_data = historical_click_data.rename(columns=lambda column_name: 'click history:' + column_name)
```
然后我們合并每個`user_id`的歷史數據:
```py
merged1 = pd.merge(transformed_buys, historical_buy_data, left_index=True, right_index=True)
print(merged1.shape)
merged2 = pd.merge(merged1, historical_click_data, left_index=True, right_index=True)
print(merged2.shape)
>>>
(106956, 710)
(106956, 766)
```
然后我們將數量作為目標并將其轉換為二元:
```py
y = np.array(merged2['Quantity'].as_matrix())
```
現在讓我們將`y`轉換為二元:如果購買發生,為`1`;否則為`0`:
```py
for i in range(y.shape[0]):
if y[i]!=0:
y[i]=1
else:
y[i]=0
print(y.shape)
print(y[0:100])
print(y, y.shape[0])
print(y[0])
print(y[0:100])
print(y, y.shape)
>>>
```

### 訓練 FM 模型
由于我們準備了數據集,下一個任務是創建 MF 模型。首先,讓我們將數據分成訓練和測試集:
```py
X_tr, X_te, y_tr, y_te = train_test_split(merged2, y, test_size=0.25)
```
然后我們將測試數據分成一半,一個用于正常測試,一個用于冷啟動測試:
```py
X_te, X_te_cs, y_te, y_te_cs = train_test_split(X_te, y_te, test_size=0.5)
```
現在讓我們在數據幀中包含會話 ID 和項目 ID:
```py
test_x = pd.DataFrame(X_te, columns = ['Item ID'])
print(test_x.head())
>>>
```
```py
test_x_cs = pd.DataFrame(X_te_cs, columns = ['Item ID'])
print(test_x_cs.head())
>>>
```

然后我們從數據集中刪除不需要的特征:
```py
X_tr.drop(['Item ID', '_Session ID', 'click history:Item ID', 'buy history:Item ID', 'Quantity'], 1, inplace=True)
X_te.drop(['Item ID', '_Session ID', 'click history:Item ID', 'buy history:Item ID', 'Quantity'], 1, inplace=True)
X_te_cs.drop(['Item ID', '_Session ID', 'click history:Item ID', 'buy history:Item ID', 'Quantity'], 1, inplace=True)
```
然后我們需要將`DataFrame`轉換為數組:
```py
ax_tr = np.array(X_tr)
ax_te = np.array(X_te)
ax_te_cs = np.array(X_te_cs)
```
既然 pandas `DataFrame`已經轉換為 NumPy 數組,我們需要做一些`null`處理。我們簡單地用零替換 NaN:
```py
ax_tr = np.nan_to_num(ax_tr)
ax_te = np.nan_to_num(ax_te)
ax_te_cs = np.nan_to_num(ax_te_cs)
```
然后我們用優化的超參數實例化 TF 模型進行分類:
```py
model = TFFMClassifier(
order=2,
rank=7,
optimizer=tf.train.AdamOptimizer(learning_rate=0.001),
n_epochs=100,
batch_size=1024,
init_std=0.001,
reg=0.01,
input_type='dense',
log_dir = ' logs/',
verbose=1,
seed=12345
)
```
在我們開始訓練模型之前,我們必須為冷啟動準備數據:
```py
cold_start = pd.DataFrame(ax_te_cs, columns=X_tr.columns)
```
和前面提到的一樣,如果我們只能訪問類別而沒有歷史點擊/購買數據,我們也有興趣了解會發生什么。讓我們刪除`cold_start`測試集的歷史點擊和購買數據:
```py
for column in cold_start.columns:
if ('buy' in column or 'click' in column) and ('Category' not in column):
cold_start[column] = 0
```
現在讓我們訓練模型:
```py
model.fit(ax_tr, y_tr, show_progress=True)
```
其中一項最重要的任務是預測會議中的購買事件:
```py
predictions = model.predict(ax_te)
print('accuracy: {}'.format(accuracy_score(y_te, predictions)))
print("predictions:",predictions[:10])
print("actual value:",y_te[:10])
>>>
accuracy: 1.0
predictions: [0 0 1 0 0 1 0 1 1 0]
actual value: [0 0 1 0 0 1 0 1 1 0]
cold_start_predictions = model.predict(ax_te_cs)
print('Cold-start accuracy: {}'.format(accuracy_score(y_te_cs, cold_start_predictions)))
print("cold start predictions:",cold_start_predictions[:10])
print("actual value:",y_te_cs[:10])
>>>
Cold-start accuracy: 1.0
cold start predictions: [1 1 1 1 1 0 1 0 0 1]
actual value: [1 1 1 1 1 0 1 0 0 1]
```
然后讓我們將預測值添加到測試數據中:
```py
test_x["Predicted"] = predictions
test_x_cs["Predicted"] = cold_start_predictions
```
現在是時候找到測試數據中每個`session_id`的所有買入事件并檢索相應的項目 ID:
```py
sess = list(set(test_x.index))
fout = open("solution.dat", "w")
print("writing the results into .dat file....")
for i in sess:
if test_x.loc[i]["Predicted"].any()!= 0:
fout.write(str(i)+";"+','.join(s for s in str(test_x.loc[i]["Item ID"].tolist()).strip('[]').split(','))+'\n')
fout.close()
>>>
writing the results into .dat file....
```
然后我們對冷啟動測試數據做同樣的事情:
```py
sess_cs = list(set(test_x_cs.index))
fout = open("solution_cs.dat", "w")
print("writing the cold start results into .dat file....")
for i in sess_cs:
if test_x_cs.loc[i]["Predicted"].any()!= 0:
fout.write(str(i)+";"+','.join(s for s in str(test_x_cs.loc[i]["Item ID"].tolist()).strip('[]').split(','))+'\n')
fout.close()
>>>
writing the cold start results into .dat file....
print("completed..!!")
>>>
completed!!
```
最后,我們銷毀模型以釋放內存:
```py
model.destroy()
```
另外,我們可以看到文件的示例內容:
```py
11009963;214853767
10846132;214854343, 214851590
8486841;214848315
10256314;214854125
8912828;214853085
11304897;214567215
9928686;214854300, 214819577
10125303;214567215, 214853852
10223609;214854358
```
考慮到我們使用相對較小的數據集來擬合我們的模型, 實驗結果很好。正如預期的那樣,如果我們可以通過項目購買和點擊訪問所有信息集,則更容易生成預測,但我們仍然只使用匯總類別數據獲得冷啟動建議的預測。
既然我們已經看到客戶將在每個會話中購買,那么計算兩個測試集的均方誤差將會很棒。`TFFMRegressor`方法可以幫助我們解決這個問題。為此,請使用`quantity.py`腳本。
首先,問題是如果我們只能訪問類別而沒有歷史點擊/購買數據會發生什么。讓我們刪除`cold_start`測試集的歷史點擊和購買數據:
```py
for column in cold_start.columns:
if ('buy' in column or 'click' in column) and ('Category' not in column):
cold_start[column] = 0
```
讓我們創建 MF 模型。您可以使用超參數:
```py
reg_model = TFFMRegressor(
order=2,
rank=7,
optimizer=tf.train.AdamOptimizer(learning_rate=0.1),
n_epochs=100,
batch_size=-1,
init_std=0.001,
input_type='dense',
log_dir = ' logs/',
verbose=1
)
```
在前面的代碼塊中,隨意放入您自己的日志記錄路徑。現在是時候使用正常和冷啟動訓練集訓練回歸模型:
```py
reg_model.fit(X_tr, y_tr, show_progress=True)
```
然后我們計算兩個測試集的均方誤差:
```py
predictions = reg_model.predict(X_te)
print('MSE: {}'.format(mean_squared_error(y_te, predictions)))
print("predictions:",predictions[:10])
print("actual value:",y_te[:10])
cold_start_predictions = reg_model.predict(X_te_cs)
print('Cold-start MSE: {}'.format(mean_squared_error(y_te_cs, cold_start_predictions)))
print("cold start predictions:",cold_start_predictions[:10])
print("actual value:",y_te_cs[:10])
print("Regression completed..!!")
>>>MSE: 0.4897467853668941
predictions: [ 1.35086 0.03489107 1.0565269 -0.17359206 -0.01603088 0.03424695
2.29936886 1.65422797 0.01069662 0.02166392]
actual value: [1 0 1 0 0 0 1 1 0 0]
Cold-start MSE: 0.5663486183636738
cold start predictions: [-0.0112379 1.21811676 1.29267406 0.02357371 -0.39662406 1.06616664
-0.10646269 0.00861482 1.22619736 0.09728943]
actual value: [0 1 1 0 1 1 0 0 1 0]
Regression completed..!!
```
最后,我們銷毀模型以釋放內存:
```py
reg_model.destroy()
```
因此,從訓練數據集中刪除類別列會使 MSE 更小,但這樣做意味著我們無法解決冷啟動建議問題。考慮到我們使用相對較小的數據集的條件,實驗結果很好。
正如預期的那樣,如果我們可以通過項目購買和點擊訪問完整的信息設置,則更容易生成預測,但我們仍然只使用匯總的類別數據獲得冷啟動建議的預測。
# 改進的分解機
Web 應用的許多預測任務需要對分類變量(例如用戶 ID)和人口統計信息(例如性別和職業)進行建模。為了應用標準 ML 技術,需要通過單熱編碼(或任何其他技術)將這些分類預測變換器轉換為一組二元特征。這使得得到的特征向量高度稀疏。要從這種稀疏數據中有效地學習,考慮特征之間的相互作用是很重要的。
在上一節中,我們看到 FM 可以有效地應用于模型二階特征交互。但是,FM 模型以線性方式進行交互,如果您想捕獲真實世界數據的非線性和固有復雜結構,則這種方式是不夠的。
Xiangnan He 和 Jun Xiao 等。為了克服這一局限,我們提出了一些研究計劃,如神經因子分解機(NFM)和注意因子分解機(AFM)。
有關更多信息,請參閱以下文章:
* Xiangnan He 和 Tat-Seng Chua,用于稀疏預測分析的神經分解機。在 SIGIR '17,新宿,東京,日本,2017 年 8 月 7 日至 11 日的會議錄。
* Jun Xiao,Hao Ye,Xiantian He,Hanwang Zhang,Fei Wu 和 Tat-Seng Chua(2017),注意分解機:通過注意網絡學習特征交互的權重 IJCAI,墨爾本,澳大利亞,2017 年 8 月 19 - 25 日。
通過在建模二階特征相互作用中無縫地組合 FM 的線性度和在建模高階特征相互作用中神經網絡的非線性,NFM 可用于在稀疏設置下進行預測。
另一方面,即使所有特征交互具有相同的權重,AFM 也可用于對數據建模,因為并非所有特征交互都同樣有用且具有預測性。
在下一節中,我們將看到使用 NFM 進行電影推薦的示例。
## 神經分解機
使用原始 FM 算法,其表現可能受到建模方式阻礙,它使用相同權重建模所有特征交互,因為并非所有特征交互都同樣有用且具有預測性。例如,與無用特征的交互甚至可能引入噪聲并對表現產生不利影響。
最近,Xiangnan H.等。提出了一種稱為神經分解機(NFM)的 FM 算法的改進版本。 NFM 在建模二階特征相互作用中無縫地結合了 FM 的線性度,在建模高階特征相互作用時無縫地結合了神經網絡的非線性。從概念上講,NFM 比 FM 更具表現力,因為 FM 可以被看作是沒有隱藏層的 NFM 的特例。
### 數據集描述
我們使用 MovieLens 數據進行個性化標簽推薦。它包含電影上 668,953 個用戶的標簽應用。使用單熱編碼將每個標簽應用(用戶 ID,電影 ID 和標簽)轉換為特征向量。這留下了 90,445 個二元特征,稱為`ml-tag`數據集。
我使用 Perl 腳本將其從`.dat`轉換為`.libfm`格式。轉換程序在[此鏈接](http://www.libfm.org/libfm-1.42.manual.pdf)(第 2.2.1 節)中描述。轉換后的數據集包含用于訓練,驗證和測試的文件,如下所示:
* `ml-tag.train.libfm`
* `ml-tag.validation.libfm`
* `ml-tag.test.libfm`
有關此文件格式的更多信息,請參閱[此鏈接](http://www.libfm.org/)。
### NFM 和電影推薦
我們使用 TensorFlow 并復用來自這個 [GitHub](https://github.com/hexiangnan/neural_factorization_machine) 的擴展 NFM 實現。這是 FM 的深度版本,與常規 FM 相比更具表現力。倉庫有三個文件,即`NeuralFM.py`,`FM.py`和`LoadData.py`:
* `FM.py`用于訓練數據集。這是 FM 的原始實現。
* `NeuralFM.py`用于訓練數據集。這是 NFM 的原始實現,但有一些改進和擴展。
* `LoadData.py`用于以 libfm 格式預處理和加載數據集。
#### 模型訓練
首先,我們使用以下命令訓練 FM 模型。該命令還包括執行訓練所需的參數:
```py
$ python3 FM.py --dataset ml-tag --epoch 20 --pretrain -1 --batch_size 4096 --lr 0.01 --keep 0.7
>>>
FM: dataset=ml-tag, factors=16, #epoch=20, batch=4096, lr=0.0100, lambda=0.0e+00, keep=0.70, optimizer=AdagradOptimizer, batch_norm=1
#params: 1537566
Init: train=1.0000, validation=1.0000 [5.7 s]
Epoch 1 [13.9 s] train=0.5413, validation=0.6005 [7.8 s]
Epoch 2 [14.2 s] train=0.4927, validation=0.5779 [8.3 s]
…
Epoch 19 [15.4 s] train=0.3272, validation=0.5429 [8.1 s]
Epoch 20 [16.6 s] train=0.3242, validation=0.5425 [7.8 s]
```
訓練結束后,訓練好的模型將保存在主目錄的`pretrain`文件夾中:
將模型保存為預訓練文件。
此外,我已嘗試使用以下代碼進行驗證和訓練損失的訓練和驗證誤差:
```py
# Plot loss over time
plt.plot(epoch_list, train_err_list, 'r--', label='FM training loss per epoch', linewidth=4)
plt.title('FM training loss per epoch')
plt.xlabel('Epoch')
plt.ylabel('Training loss')
plt.legend(loc='upper right')
plt.show()
# Plot accuracy over time
plt.plot(epoch_list, valid_err_list, 'r--', label='FM validation loss per epoch', linewidth=4)
plt.title('FM validation loss per epoch')
plt.xlabel('Epoch')
plt.ylabel('Validation loss')
plt.legend(loc='upper left')
plt.show()
```
前面的代碼生成繪圖,顯示 FM 模型中每次迭代的訓練與驗證損失:
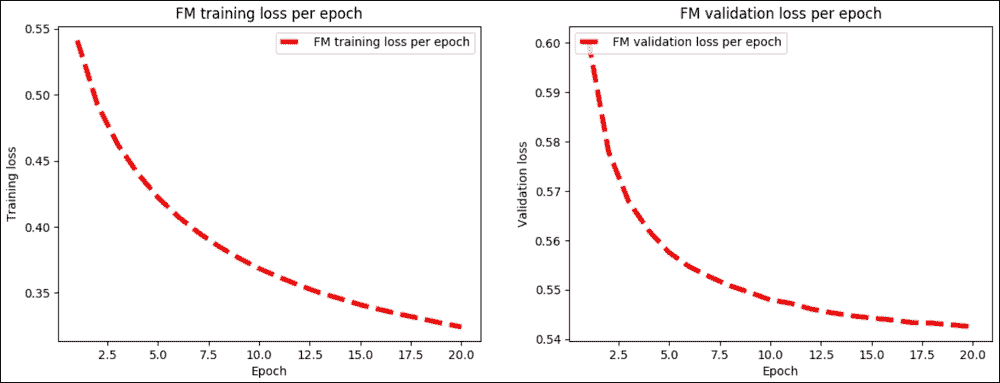
圖 11:FM 模型中每次迭代的訓練與驗證損失
如果查看前面的輸出日志,最佳訓練(即驗證和訓練)將在第 20 次和最后一次迭代時進行。但是,您可以進行更多迭代以改進訓練,這意味著評估步驟中的 RMSE 值較低:
```py
Best Iter(validation)= 20 train = 0.3242, valid = 0.5425 [490.9 s]
```
現在讓我們使用以下命令訓練 NFM 模型(但也使用參數):
```py
$ python3 NeuralFM.py --dataset ml-tag --hidden_factor 64 --layers [64] --keep_prob [0.8,0.5] --loss_type square_loss --activation relu --pretrain 0 --optimizer AdagradOptimizer --lr 0.01 --batch_norm 1 --verbose 1 --early_stop 1 --epoch 20
>>>
Neural FM: dataset=ml-tag, hidden_factor=64, dropout_keep=[0.8,0.5], layers=[64], loss_type=square_loss, pretrain=0, #epoch=20, batch=128, lr=0.0100, lambda=0.0000, optimizer=AdagradOptimizer, batch_norm=1, activation=relu, early_stop=1
#params: 5883150
Init: train=0.9911, validation=0.9916, test=0.9920 [25.8 s]
Epoch 1 [60.0 s] train=0.6297, validation=0.6739, test=0.6721 [28.7 s]
Epoch 2 [60.4 s] train=0.5646, validation=0.6390, test=0.6373 [28.5 s]
…
Epoch 19 [53.4 s] train=0.3504, validation=0.5607, test=0.5587 [25.7 s]
Epoch 20 [55.1 s] train=0.3432, validation=0.5577, test=0.5556 [27.5 s]
```
此外,我嘗試使用以下代碼使驗證和訓練損失的訓練和驗證誤差可見:
```py
# Plot test accuracy over time
plt.plot(epoch_list, test_err_list, 'r--', label='NFM test loss per epoch', linewidth=4)
plt.title('NFM test loss per epoch')
plt.xlabel('Epoch')
plt.ylabel('Test loss')
plt.legend(loc='upper left')
plt.show()
```
前面的代碼在 NFM 模型中產生每次迭代的訓練與驗證損失:
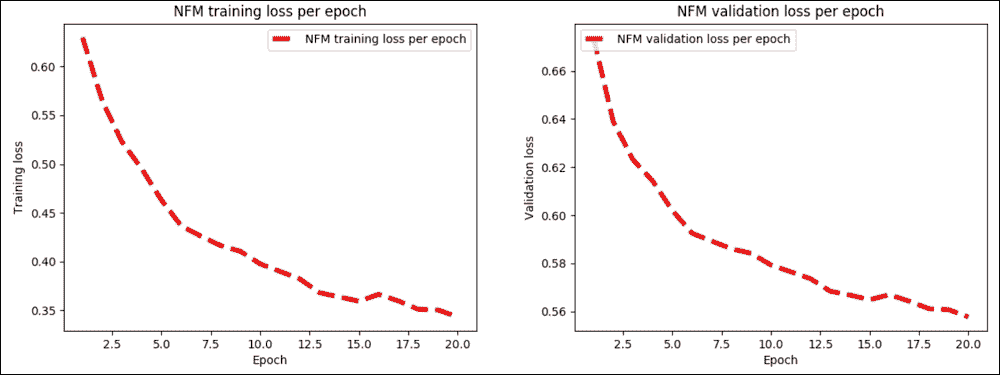
圖 12:NFM 模型中每次迭代的訓練與驗證損失
對于 NFM 模型,最佳訓練(用于驗證和訓練)發生在第 20 次和最后一次迭代。但是,您可以進行更多迭代以改進訓練,這意味著評估步驟中的 RMSE 值較低:
```py
Best Iter (validation) = 20 train = 0.3432, valid = 0.5577, test = 0.5556 [1702.5 s]
```
#### 模型評估
現在,要評估原始 FM 模型,請執行以下命令:
```py
$ python3 FM.py --dataset ml-tag --epoch 20 --batch_size 4096 --lr 0.01 --keep 0.7 --process evaluate
Test RMSE: 0.5427
```
### 注意
對于 TensorFlow 上的 Attentional Factorization Machines 實現,感興趣的讀者可以參考[此鏈接](https://github.com/hexiangnan/attentional_factorization_machine)中的 GitHub 倉庫。但請注意,某些代碼可能無效。我將它們更新為兼容 TensorFlow v1.6。因此,我強烈建議您使用本書提供的代碼。
要評估 NFM 模型,只需將以下行添加到`NeuralFM.py`腳本中的`main()`方法,如下所示:
```py
# Model evaluation
print("RMSE: ")
print(model.evaluate(data.Test_data)) #evaluate on test set
>>>
RMSE: 0.5578330373003925
```
因此,RMSE 幾乎與 FM 模型相同。現在讓我們看看每次迭代的測試誤差:
```py
# Plot test accuracy over time
plt.plot(epoch_list, test_err_list, 'r--', label='NFM test loss per epoch', linewidth=4)
plt.title('NFM test loss per epoch')
plt.xlabel('Epoch')
plt.ylabel('Test loss')
plt.legend(loc='upper left')
plt.show()
```
前面的代碼繪制了 NFM 模型中每次迭代的測試損失:
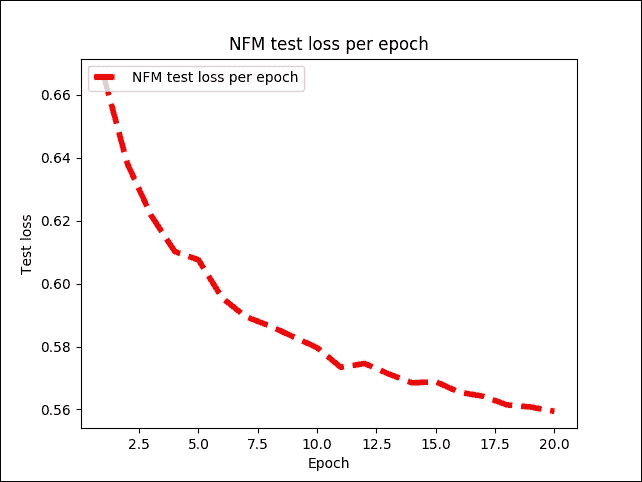
圖 13:NFM 模型中每次迭代的測試損失
# 總結
在本章中,我們討論了如何使用 TensorFlow 開發可擴展的推薦系統。我們已經看到推薦系統的一些理論背景,并在開發推薦系統時使用協同過濾方法。在本章后面,我們看到了如何使用 SVD 和 K 均值來開發電影推薦系統。
最后,我們了解了如何使用 FM 和一種稱為 NFM 的變體來開發更準確的推薦系統,以便處理大規模稀疏矩陣。我們已經看到處理冷啟動問題的最佳方法是使用 FM 協同過濾方法。
下一章是關于設計由批評和獎勵驅動的 ML 系統。我們將看到如何應用 RL 算法為現實數據集制作預測模型。
- TensorFlow 1.x 深度學習秘籍
- 零、前言
- 一、TensorFlow 簡介
- 二、回歸
- 三、神經網絡:感知器
- 四、卷積神經網絡
- 五、高級卷積神經網絡
- 六、循環神經網絡
- 七、無監督學習
- 八、自編碼器
- 九、強化學習
- 十、移動計算
- 十一、生成模型和 CapsNet
- 十二、分布式 TensorFlow 和云深度學習
- 十三、AutoML 和學習如何學習(元學習)
- 十四、TensorFlow 處理單元
- 使用 TensorFlow 構建機器學習項目中文版
- 一、探索和轉換數據
- 二、聚類
- 三、線性回歸
- 四、邏輯回歸
- 五、簡單的前饋神經網絡
- 六、卷積神經網絡
- 七、循環神經網絡和 LSTM
- 八、深度神經網絡
- 九、大規模運行模型 -- GPU 和服務
- 十、庫安裝和其他提示
- TensorFlow 深度學習中文第二版
- 一、人工神經網絡
- 二、TensorFlow v1.6 的新功能是什么?
- 三、實現前饋神經網絡
- 四、CNN 實戰
- 五、使用 TensorFlow 實現自編碼器
- 六、RNN 和梯度消失或爆炸問題
- 七、TensorFlow GPU 配置
- 八、TFLearn
- 九、使用協同過濾的電影推薦
- 十、OpenAI Gym
- TensorFlow 深度學習實戰指南中文版
- 一、入門
- 二、深度神經網絡
- 三、卷積神經網絡
- 四、循環神經網絡介紹
- 五、總結
- 精通 TensorFlow 1.x
- 一、TensorFlow 101
- 二、TensorFlow 的高級庫
- 三、Keras 101
- 四、TensorFlow 中的經典機器學習
- 五、TensorFlow 和 Keras 中的神經網絡和 MLP
- 六、TensorFlow 和 Keras 中的 RNN
- 七、TensorFlow 和 Keras 中的用于時間序列數據的 RNN
- 八、TensorFlow 和 Keras 中的用于文本數據的 RNN
- 九、TensorFlow 和 Keras 中的 CNN
- 十、TensorFlow 和 Keras 中的自編碼器
- 十一、TF 服務:生產中的 TensorFlow 模型
- 十二、遷移學習和預訓練模型
- 十三、深度強化學習
- 十四、生成對抗網絡
- 十五、TensorFlow 集群的分布式模型
- 十六、移動和嵌入式平臺上的 TensorFlow 模型
- 十七、R 中的 TensorFlow 和 Keras
- 十八、調試 TensorFlow 模型
- 十九、張量處理單元
- TensorFlow 機器學習秘籍中文第二版
- 一、TensorFlow 入門
- 二、TensorFlow 的方式
- 三、線性回歸
- 四、支持向量機
- 五、最近鄰方法
- 六、神經網絡
- 七、自然語言處理
- 八、卷積神經網絡
- 九、循環神經網絡
- 十、將 TensorFlow 投入生產
- 十一、更多 TensorFlow
- 與 TensorFlow 的初次接觸
- 前言
- 1.?TensorFlow 基礎知識
- 2. TensorFlow 中的線性回歸
- 3. TensorFlow 中的聚類
- 4. TensorFlow 中的單層神經網絡
- 5. TensorFlow 中的多層神經網絡
- 6. 并行
- 后記
- TensorFlow 學習指南
- 一、基礎
- 二、線性模型
- 三、學習
- 四、分布式
- TensorFlow Rager 教程
- 一、如何使用 TensorFlow Eager 構建簡單的神經網絡
- 二、在 Eager 模式中使用指標
- 三、如何保存和恢復訓練模型
- 四、文本序列到 TFRecords
- 五、如何將原始圖片數據轉換為 TFRecords
- 六、如何使用 TensorFlow Eager 從 TFRecords 批量讀取數據
- 七、使用 TensorFlow Eager 構建用于情感識別的卷積神經網絡(CNN)
- 八、用于 TensorFlow Eager 序列分類的動態循壞神經網絡
- 九、用于 TensorFlow Eager 時間序列回歸的遞歸神經網絡
- TensorFlow 高效編程
- 圖嵌入綜述:問題,技術與應用
- 一、引言
- 三、圖嵌入的問題設定
- 四、圖嵌入技術
- 基于邊重構的優化問題
- 應用
- 基于深度學習的推薦系統:綜述和新視角
- 引言
- 基于深度學習的推薦:最先進的技術
- 基于卷積神經網絡的推薦
- 關于卷積神經網絡我們理解了什么
- 第1章概論
- 第2章多層網絡
- 2.1.4生成對抗網絡
- 2.2.1最近ConvNets演變中的關鍵架構
- 2.2.2走向ConvNet不變性
- 2.3時空卷積網絡
- 第3章了解ConvNets構建塊
- 3.2整改
- 3.3規范化
- 3.4匯集
- 第四章現狀
- 4.2打開問題
- 參考
- 機器學習超級復習筆記
- Python 遷移學習實用指南
- 零、前言
- 一、機器學習基礎
- 二、深度學習基礎
- 三、了解深度學習架構
- 四、遷移學習基礎
- 五、釋放遷移學習的力量
- 六、圖像識別與分類
- 七、文本文件分類
- 八、音頻事件識別與分類
- 九、DeepDream
- 十、自動圖像字幕生成器
- 十一、圖像著色
- 面向計算機視覺的深度學習
- 零、前言
- 一、入門
- 二、圖像分類
- 三、圖像檢索
- 四、對象檢測
- 五、語義分割
- 六、相似性學習
- 七、圖像字幕
- 八、生成模型
- 九、視頻分類
- 十、部署
- 深度學習快速參考
- 零、前言
- 一、深度學習的基礎
- 二、使用深度學習解決回歸問題
- 三、使用 TensorBoard 監控網絡訓練
- 四、使用深度學習解決二分類問題
- 五、使用 Keras 解決多分類問題
- 六、超參數優化
- 七、從頭開始訓練 CNN
- 八、將預訓練的 CNN 用于遷移學習
- 九、從頭開始訓練 RNN
- 十、使用詞嵌入從頭開始訓練 LSTM
- 十一、訓練 Seq2Seq 模型
- 十二、深度強化學習
- 十三、生成對抗網絡
- TensorFlow 2.0 快速入門指南
- 零、前言
- 第 1 部分:TensorFlow 2.00 Alpha 簡介
- 一、TensorFlow 2 簡介
- 二、Keras:TensorFlow 2 的高級 API
- 三、TensorFlow 2 和 ANN 技術
- 第 2 部分:TensorFlow 2.00 Alpha 中的監督和無監督學習
- 四、TensorFlow 2 和監督機器學習
- 五、TensorFlow 2 和無監督學習
- 第 3 部分:TensorFlow 2.00 Alpha 的神經網絡應用
- 六、使用 TensorFlow 2 識別圖像
- 七、TensorFlow 2 和神經風格遷移
- 八、TensorFlow 2 和循環神經網絡
- 九、TensorFlow 估計器和 TensorFlow HUB
- 十、從 tf1.12 轉換為 tf2
- TensorFlow 入門
- 零、前言
- 一、TensorFlow 基本概念
- 二、TensorFlow 數學運算
- 三、機器學習入門
- 四、神經網絡簡介
- 五、深度學習
- 六、TensorFlow GPU 編程和服務
- TensorFlow 卷積神經網絡實用指南
- 零、前言
- 一、TensorFlow 的設置和介紹
- 二、深度學習和卷積神經網絡
- 三、TensorFlow 中的圖像分類
- 四、目標檢測與分割
- 五、VGG,Inception,ResNet 和 MobileNets
- 六、自編碼器,變分自編碼器和生成對抗網絡
- 七、遷移學習
- 八、機器學習最佳實踐和故障排除
- 九、大規模訓練
- 十、參考文獻