
# 五、釋放遷移學習的力量
在上一章中,我們介紹了圍繞遷移學習的主要概念。 關鍵思想是,與從頭開始構建自己的深度學習模型和架構相比,在各種任務中利用先進的,經過預訓練的深度學習模型可產生更好的結果。 在本章中,我們將獲得一個更動手的觀點,即使用遷移學習實際構建深度學習模型并將其應用于實際問題。 有無遷移學習,我們將構建各種深度學習模型。 我們將分析它們的架構,并比較和對比它們的表現。 本章將涵蓋以下主要方面:
* 遷移學習的必要性
* 從頭開始構建**卷積神經網絡**(**CNN**)模型:
* 建立基本的 CNN 模型
* 通過正則化改進我們的 CNN 模型
* 通過圖像增強改善我們的 CNN 模型
* 在預訓練的 CNN 模型中利用遷移學習:
* 使用預訓練模型作為特征提取器
* 通過圖像增強改進我們的預訓練模型
* 通過微調改進我們的預訓練模型
* 模型表現評估
我們要感謝 Francois Chollet 不僅創建了令人驚嘆的深度學習框架 Keras,還感謝他在他的書《Python 深度學習》中談到了有效學習遷移的現實世界問題。 在本章中,我們以此為靈感來刻畫了遷移學習的真正力量。 本章的代碼將在 GitHub 存儲庫中的[文件夾中提供](https://github.com/dipanjanS/hands-on-transfer-learning-with-python),根據需要遵循本章。
# 遷移學習的必要性
我們已經在第 4 章“遷移學習基礎”中簡要討論了遷移學習的優勢。 概括地說,與從頭開始構建深度學習模型相比,我們獲得了一些好處,例如,改善了基準表現,加快了整體模型的開發和訓練時間,并且還獲得了整體改進和優越的模型表現。 這里要記住的重要一點是,遷移學習作為一個領域早已在深度學習之前就存在了,并且還可以應用于不需要深度學習的領域或問題。
現在讓我們考慮一個現實世界的問題,在本章中,我們還將繼續使用它來說明我們不同的深度學習模型,并在同一模型上利用遷移學習。 您必須一次又一次聽到深度學習的關鍵要求之一是,我們需要大量數據和樣本來構建可靠的深度學習模型。 其背后的想法是模型可以從大量樣本中自動學習特征。 但是,如果我們沒有足夠的訓練樣本并且要解決的問題仍然是一個相對復雜的問題,我們該怎么辦? 例如,計算機視覺問題,例如圖像分類,可能難以使用傳統的統計技術或**機器學習**(**ML**)技術解決。 我們會放棄深度學習嗎?
考慮到**圖像分類**問題,由于我們要處理的圖像本質上是高維張量,因此擁有更多數據可使深度學習模型學習更好的圖像基本特征表示。 但是,即使我們每個類別的圖像樣本的范圍從幾百到數千,基本的 CNN 模型在正確的架構和規范化條件下仍能正常運行。 這里要記住的關鍵點是,CNN 會學習與縮放,平移和旋轉不變的模式和特征,因此我們在這里不需要自定義特征工程技術。 但是,我們可能仍然會遇到模型過擬合之類的問題,我們將在本章稍后部分嘗試解決這些問題。
關于遷移學習,已經在著名的 [ImageNet 數據集](http://image-net.org/about-overview)上訓練了一些出色的預訓練深度學習模型。 我們已經在第 3 章“了解深度學習架構”中詳細介紹了其中一些模型,本章將利用著名的`VGG-16`模型。 想法是使用通常是圖像分類專家的預訓練模型來解決我們的問題,即數據樣本較少。
# 制定我們的現實問題
正如我們前面提到的,我們將在圖像分類問題上進行工作,每個類別的訓練樣本數量較少。 我們的問題的數據集可在 Kaggle 上獲得,它是其中最受歡迎的基于計算機視覺的數據集之一。 我們將使用的數據集來自[**貓狗**挑戰](https://www.kaggle.com/c/dogs-vs-cats/data),而我們的主要目標是建立一個可以成功識別圖像并將其分類為貓或狗的模型。 就機器學習而言,這是一個基于圖像的二分類問題。
首先,從數據集頁面下載`train.zip`文件并將其存儲在本地系統中。 下載后,將其解壓縮到文件夾中。 該文件夾將包含 25,000 張貓和狗的圖像; 即每個類別 12500 張圖像。
# 建立我們的數據集
雖然我們可以使用所有 25,000 張圖像并在它們上建立一些不錯的模型,但是,如果您還記得的話,我們的問題目標包括增加的約束,即每類圖像的數量很少。 為此,我們構建自己的數據集。 如果您想自己運行示例,可以參考`Datasets Builder.ipynb` Jupyter 筆記本。
首先,我們加載以下依賴項,包括一個名為`utils`的工具模塊,該模塊在本章代碼文件中的`utils.py`文件中可用。 當我們將圖像復制到新文件夾時,這主要用于獲得視覺進度條:
```py
import glob
import numpy as np
import os
import shutil
from utils import log_progress
np.random.seed(42)
```
現在,如下所示將所有圖像加載到原始訓練數據文件夾中:
```py
files = glob.glob('train/*')
cat_files = [fn for fn in files if 'cat' in fn]
dog_files = [fn for fn in files if 'dog' in fn]
len(cat_files), len(dog_files)
Out [3]: (12500, 12500)
```
我們可以使用前面的輸出來驗證每個類別有 12,500 張圖像。 現在,我們構建較小的數據集,以使我們有 3,000 張圖像用于訓練,1,000 張圖像用于驗證和 1,000 張圖像用于我們的測試數據集(兩個動物類別的表示均相同):
```py
cat_train = np.random.choice(cat_files, size=1500, replace=False)
dog_train = np.random.choice(dog_files, size=1500, replace=False)
cat_files = list(set(cat_files) - set(cat_train))
dog_files = list(set(dog_files) - set(dog_train))
cat_val = np.random.choice(cat_files, size=500, replace=False)
dog_val = np.random.choice(dog_files, size=500, replace=False)
cat_files = list(set(cat_files) - set(cat_val))
dog_files = list(set(dog_files) - set(dog_val))
cat_test = np.random.choice(cat_files, size=500, replace=False)
dog_test = np.random.choice(dog_files, size=500, replace=False)
print('Cat datasets:', cat_train.shape, cat_val.shape, cat_test.shape)
print('Dog datasets:', dog_train.shape, dog_val.shape, dog_test.shape)
Cat datasets: (1500,) (500,) (500,)
Dog datasets: (1500,) (500,) (500,)
```
現在我們已經創建了數據集,讓我們將它們寫到單獨文件夾中的磁盤中,以便我們將來可以在任何時候返回它們,而不必擔心它們是否存在于主內存中:
```py
train_dir = 'training_data'
val_dir = 'validation_data'
test_dir = 'test_data'
train_files = np.concatenate([cat_train, dog_train])
validate_files = np.concatenate([cat_val, dog_val])
test_files = np.concatenate([cat_test, dog_test])
os.mkdir(train_dir) if not os.path.isdir(train_dir) else None
os.mkdir(val_dir) if not os.path.isdir(val_dir) else None
os.mkdir(test_dir) if not os.path.isdir(test_dir) else None
for fn in log_progress(train_files, name='Training Images'):
shutil.copy(fn, train_dir)
for fn in log_progress(validate_files, name='Validation Images'):
shutil.copy(fn, val_dir)
for fn in log_progress(test_files, name='Test Images'):
shutil.copy(fn, test_dir)
```
一旦所有圖像都復制到各自的目錄中,以下屏幕快照中描述的進度條將變為綠色:
# 制定我們的方法
由于這是圖像分類問題,因此我們將利用 CNN 模型或 convNets 嘗試解決此問題。 在本章開始時,我們簡要討論了我們的方法。 我們將從頭開始構建簡單的 CNN 模型,然后嘗試使用正則化和圖像增強等技術進行改進。 然后,我們將嘗試利用預訓練的模型來釋放轉學的真正力量!
# 從頭開始構建 CNN 模型
讓我們開始構建圖像分類分類器。 我們的方法是在訓練數據集上建立模型,并在驗證數據集上進行驗證。 最后,我們將在測試數據集上測試所有模型的表現。 在進入建模之前,讓我們加載并準備數據集。 首先,我們加載一些基本的依賴項:
```py
import glob
import numpy as np
import matplotlib.pyplot as plt
from keras.preprocessing.image import ImageDataGenerator, load_img, img_to_array, array_to_img
%matplotlib inline
```
現在,使用以下代碼片段加載數據集:
```py
IMG_DIM = (150, 150)
train_files = glob.glob('training_data/*')
train_imgs = [img_to_array(load_img(img, target_size=IMG_DIM)) for img
in train_files]
train_imgs = np.array(train_imgs)
train_labels = [fn.split('/')[1].split('.')[0].strip() for fn in
train_files]
validation_files = glob.glob('validation_data/*')
validation_imgs = [img_to_array(load_img(img, target_size=IMG_DIM)) for
img in validation_files]
validation_imgs = np.array(validation_imgs)
validation_labels = [fn.split('/')[1].split('.')[0].strip() for fn in
validation_files]
print('Train dataset shape:', train_imgs.shape,
'tValidation dataset shape:', validation_imgs.shape)
Train dataset shape: (3000, 150, 150, 3)
Validation dataset shape: (1000, 150, 150, 3)
```
我們可以清楚地看到我們有`3000`訓練圖像和`1000`驗證圖像。 每個圖像的尺寸為`150 x 150`,并具有用于紅色,綠色和藍色(RGB)的三個通道,因此為每個圖像提供(`150`,`150`,`3`)尺寸。 現在,我們將像素值在`(0, 255)`之間的每個圖像縮放到`(0, 1)`之間的值,因為深度學習模型在較小的輸入值下確實可以很好地工作:
```py
train_imgs_scaled = train_imgs.astype('float32')
validation_imgs_scaled = validation_imgs.astype('float32')
train_imgs_scaled /= 255
validation_imgs_scaled /= 255
# visualize a sample image
print(train_imgs[0].shape)
array_to_img(train_imgs[0])
(150, 150, 3)
```
前面的代碼生成以下輸出:

前面的輸出顯示了我們訓練數據集中的示例圖像之一。 現在,讓我們設置一些基本的配置參數,并將文本類標簽編碼為數值(否則,Keras 將拋出錯誤):
```py
batch_size = 30
num_classes = 2
epochs = 30
input_shape = (150, 150, 3)
# encode text category labels
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(train_labels)
train_labels_enc = le.transform(train_labels)
validation_labels_enc = le.transform(validation_labels)
print(train_labels[1495:1505], train_labels_enc[1495:1505])
['cat', 'cat', 'cat', 'cat', 'cat', 'dog', 'dog', 'dog', 'dog', 'dog']
[0 0 0 0 0 1 1 1 1 1]
```
我們可以看到,我們的編碼方案將`0`分配給`cat`標簽,將`1`分配給`dog`標簽。 現在,我們準備構建我們的第一個基于 CNN 的深度學習模型。
# 基本的 CNN 模型
我們將從建立具有三個卷積層的基本 CNN 模型開始,再加上用于從圖像中自動提取特征的最大池化,以及對輸出卷積特征圖進行下采樣。 要刷新有關卷積和池化層如何工作的記憶,請查看第 3 章“了解深度學習架構”中的 CNN 部分。
提取這些特征圖后,我們將使用一個密集層以及一個具有 S 型函數的輸出層進行分類。 由于我們正在執行二分類,因此`binary_crossentropy`損失函數就足夠了。 我們將使用流行的 RMSprop 優化器,該優化器可幫助我們使用反向傳播來優化網絡中單元的權重,從而使網絡中的損失降到最低,從而得到一個不錯的分類器。 請參閱第 2 章,“深度學習要點”中的“隨機梯度下降”和“SGD 改進”部分,以獲取有關優化器如何工作的深入見解。 簡而言之,優化器(如 RMSprop)指定有關損耗梯度如何用于更新傳遞到我們網絡的每批數據中的參數的規則。
讓我們利用 Keras 并立即構建我們的 CNN 模型架構:
```py
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from keras.models import Sequential
from keras import optimizers
model = Sequential()
# convolution and pooling layers
model.add(Conv2D(16, kernel_size=(3, 3), activation='relu',
input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(),
metrics=['accuracy'])
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 148, 148, 16) 448
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 74, 74, 16) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 72, 72, 64) 9280
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 36, 36, 64) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 34, 34, 128) 73856
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 17, 17, 128) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 36992) 0
_________________________________________________________________
dense_1 (Dense) (None, 512) 18940416
_________________________________________________________________
dense_2 (Dense) (None, 1) 513
=================================================================
Total params: 19,024,513
Trainable params: 19,024,513
Non-trainable params: 0
```
前面的輸出向我們展示了我們的基本 CNN 模型摘要。 就像我們之前提到的,我們使用三個卷積層進行特征提取。 平整層用于平整我們從第三卷積層獲得的`17 x 17`特征圖中的 128 個。 這被饋送到我們的密集層,以最終確定圖像是狗(1)還是貓(0)。 所有這些都是模型訓練過程的一部分,因此,讓我們使用以下利用`fit(...)`函數的代碼片段訓練模型。 以下幾項對于訓練我們的模型非常重要:
* `batch_size`表示每次迭代傳遞給模型的圖像總數
* 每次迭代后,將更新層中單元的權重
* 迭代總數始終等于訓練樣本總數除以`batch_size`
* 一個周期是整個數據集一次通過網絡,即所有迭代均基于數據批量而完成
我們使用`30`的`batch_size`,我們的訓練數據總共有 3,000 個樣本,這表示每個周期總共有 100 次迭代。 我們對模型進行了總共 30 個周期的訓練,并因此在我們的 1,000 張圖像的驗證集上進行了驗證:
```py
history = model.fit(x=train_imgs_scaled, y=train_labels_enc,
validation_data=(validation_imgs_scaled,
validation_labels_enc),
batch_size=batch_size,
epochs=epochs,
verbose=1)
Train on 3000 samples, validate on 1000 samples
Epoch 1/30
3000/3000 - 10s - loss: 0.7583 - acc: 0.5627 - val_loss: 0.7182 - val_acc: 0.5520
Epoch 2/30
3000/3000 - 8s - loss: 0.6343 - acc: 0.6533 - val_loss: 0.5891 - val_acc: 0.7190
...
...
Epoch 29/30
3000/3000 - 8s - loss: 0.0314 - acc: 0.9950 - val_loss: 2.7014 - val_acc: 0.7140
Epoch 30/30
3000/3000 - 8s - loss: 0.0147 - acc: 0.9967 - val_loss: 2.4963 - val_acc: 0.7220
```
根據訓練和驗證的準確率值,我們的模型似乎有點過擬合。 我們可以使用以下代碼段繪制模型的準確率和誤差,以獲得更好的視角:
```py
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
t = f.suptitle('Basic CNN Performance', fontsize=12)
f.subplots_adjust(top=0.85, wspace=0.3)
epoch_list = list(range(1,31))
ax1.plot(epoch_list, history.history['acc'], label='Train Accuracy')
ax1.plot(epoch_list, history.history['val_acc'], label='Validation Accuracy')
ax1.set_xticks(np.arange(0, 31, 5))
ax1.set_ylabel('Accuracy Value')
ax1.set_xlabel('Epoch')
ax1.set_title('Accuracy')
l1 = ax1.legend(loc="best")
```
```py
ax2.plot(epoch_list, history.history['loss'], label='Train Loss')
ax2.plot(epoch_list, history.history['val_loss'], label='Validation Loss')
ax2.set_xticks(np.arange(0, 31, 5))
ax2.set_ylabel('Loss Value')
ax2.set_xlabel('Epoch')
ax2.set_title('Loss')
l2 = ax2.legend(loc="best")
```
以下圖表利用了歷史對象,其中包含每個周期的精度和損耗值:
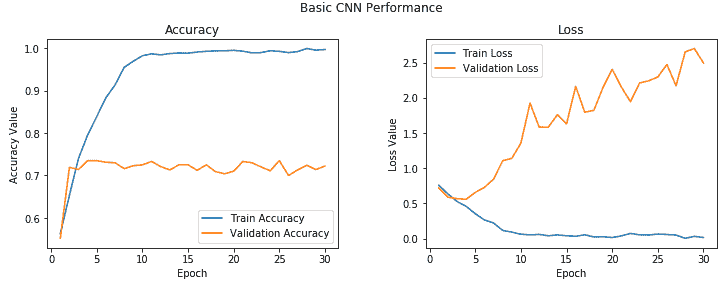
您可以清楚地看到,在 2-3 個周期之后,模型開始對訓練數據進行過擬合。 我們在驗證集中獲得的平均準確率約為 **72%**,這不是一個不好的開始! 我們可以改進此模型嗎?
# 具有正則化的 CNN 模型
讓我們通過增加一個卷積層,另一個密集的隱藏層來改進我們的基本 CNN 模型。 除此之外,我們將在每個隱藏的密集層之后添加 0.3 的差值以啟用正則化。 我們在第 2 章“深度學習基礎知識”中簡要介紹了丟棄法問題,因此隨時可以快速瀏覽一下它,以備不時之需。 基本上,丟棄法是在深度神經網絡中進行正則化的有效方法。 它可以分別應用于輸入層和隱藏層。
通過將輸出的輸出設置為零,丟棄法隨機掩蓋了一部分設備的輸出(在我們的示例中,它是密集層中 30% 的設備的輸出):
```py
model = Sequential()
# convolutional and pooling layers
model.add(Conv2D(16, kernel_size=(3, 3), activation='relu',
input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(),
metrics=['accuracy'])
```
現在,讓我們在訓練數據上訓練新模型,并在驗證數據集上驗證其表現:
```py
history = model.fit(x=train_imgs_scaled, y=train_labels_enc,
validation_data=(validation_imgs_scaled,
validation_labels_enc),
batch_size=batch_size,
epochs=epochs,
verbose=1)
Train on 3000 samples, validate on 1000 samples
Epoch 1/30
3000/3000 - 7s - loss: 0.6945 - acc: 0.5487 - val_loss: 0.7341 - val_acc: 0.5210
Epoch 2/30
3000/3000 - 7s - loss: 0.6601 - acc: 0.6047 - val_loss: 0.6308 - val_acc: 0.6480
...
...
Epoch 29/30
3000/3000 - 7s - loss: 0.0927 - acc: 0.9797 - val_loss: 1.1696 - val_acc: 0.7380
Epoch 30/30
3000/3000 - 7s - loss: 0.0975 - acc: 0.9803 - val_loss: 1.6790 - val_acc: 0.7840
```
我們還要看看模型訓練期間所有周期的準確率和損失值:
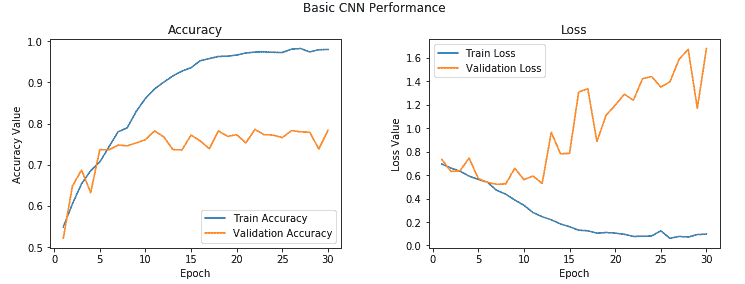
從前面的輸出中您可以清楚地看到,盡管模型花費了更長的時間,但仍然最終使模型過擬合,并且我們還獲得了約 **78%** 的更好的驗證精度,這雖然不錯,但并不令人驚訝。
模型過擬合的原因是因為我們的訓練數據少得多,并且模型在每個周期隨著時間的推移不斷看到相同的實例。 解決此問題的一種方法是利用圖像增強策略,以與現有圖像略有不同的圖像來增強我們現有的訓練數據。 我們將在下一節中詳細介紹。 讓我們暫時保存該模型,以便以后可以使用它來評估其在測試數據上的表現:
```py
model.save('cats_dogs_basic_cnn.h5')
```
# 具有圖像增強的 CNN 模型
讓我們通過使用適當的圖像增強策略添加更多數據來改進我們的常規 CNN 模型。 由于我們先前的模型每次都在相同的小數據點樣本上進行訓練,因此無法很好地推廣,并在經過幾個周期后最終過擬合。
圖像增強背后的想法是,我們遵循一個既定過程,從訓練數據集中獲取現有圖像,并對它們應用一些圖像變換操作,例如旋轉,剪切,平移,縮放等,以生成現有圖像的新的,經過修改的版本。 由于這些隨機轉換,我們每次都不會獲得相同的圖像,我們將利用 Python 生成器在訓練過程中將這些新圖像提供給我們的模型。
Keras 框架具有一個稱為`ImageDataGenerator`的出色工具,可以幫助我們完成所有前面的操作。 讓我們為訓練和驗證數據集初始化兩個數據生成器:
```py
train_datagen = ImageDataGenerator(rescale=1./255, zoom_range=0.3,
rotation_range=50,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
val_datagen = ImageDataGenerator(rescale=1./255)
```
`ImageDataGenerator`中有很多可用的選項,我們只是利用了其中一些。 隨時查看[這個頁面](https://keras.io/preprocessing/image/)上的文檔,以獲取更詳細的信息。 在我們的訓練數據生成器中,我們獲取原始圖像,然后對它們執行幾次轉換以生成新圖像。 其中包括:
* 使用`zoom_range`參數將圖像隨機放大`0.3`倍。
* 使用`rotation_range`參數將圖像隨機旋轉`50`度。
* 使用`width_shift_range`和`height_shift_range`參數,以圖像寬度或高度的`0.2`因子水平或垂直地隨機轉換圖像。
* 使用`shear_range`參數隨機應用基于剪切的變換。
* 使用`horizontal_flip`參數在水平方向隨機翻轉一半圖像。
* 在應用任何前述操作(尤其是旋轉或平移)之后,利用`fill_mode`參數為圖像填充新像素。 在這種情況下,我們只用周圍最近的像素值填充新像素。
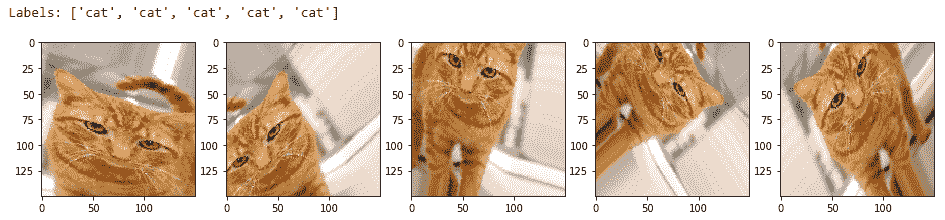
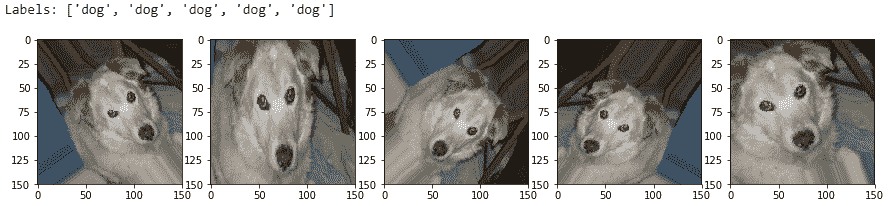
讓我們看看其中一些生成的圖像可能看起來如何,以便您可以更好地理解它們。 我們將從訓練數據集中獲取兩個樣本圖像進行說明。 第一張圖片是貓的圖片:
```py
img_id = 2595
cat_generator = train_datagen.flow(train_imgs[img_id:img_id+1],
train_labels[img_id:img_id+1],
batch_size=1)
cat = [next(cat_generator) for i in range(0,5)]
fig, ax = plt.subplots(1,5, figsize=(16, 6))
print('Labels:', [item[1][0] for item in cat])
l = [ax[i].imshow(cat[i][0][0]) for i in range(0,5)]
```
您可以在以下輸出中清楚地看到,我們每次都會生成新版本的訓練圖像(具有平移,旋轉和縮放),并且我們為其分配了一個`cat`標簽,以便該模型可以從這些圖像中提取相關特征,還請記住,這些是貓:
讓我們看一下現在是狗的圖像:
```py
img_id = 1991
dog_generator = train_datagen.flow(train_imgs[img_id:img_id+1],
train_labels[img_id:img_id+1],
batch_size=1)
dog = [next(dog_generator) for i in range(0,5)]
fig, ax = plt.subplots(1,5, figsize=(15, 6))
print('Labels:', [item[1][0] for item in dog])
l = [ax[i].imshow(dog[i][0][0]) for i in range(0,5)]
```
這向我們展示了圖像增強如何幫助創建新圖像,以及在其上訓練模型應如何幫助對抗過擬合:
請記住,對于我們的驗證生成器,我們只需要將驗證圖像(原始圖像)發送到模型以進行評估; 因此,我們僅縮放圖像像素(介于 0-1 之間),并且不應用任何變換。 我們僅將圖像增強轉換應用于我們的訓練圖像:
```py
train_generator = train_datagen.flow(train_imgs, train_labels_enc,
batch_size=30)
val_generator = val_datagen.flow(validation_imgs,
validation_labels_enc,
batch_size=20)
input_shape = (150, 150, 3)
```
現在,使用我們創建的圖像增強數據生成器來訓練帶有正則化的 CNN 模型。 我們將使用之前的相同模型架構:
```py
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from keras.models import Sequential
from keras import optimizers
model = Sequential()
# convolution and pooling layers
model.add(Conv2D(16, kernel_size=(3, 3), activation='relu',
input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['accuracy'])
```
我們在這里為優化器將默認學習率降低了 10 倍,以防止模型陷入局部最小值或過擬合,因為我們將發送大量具有隨機變換的圖像。 為了訓練模型,我們現在需要稍微修改我們的方法,因為我們正在使用數據生成器。 我們將利用 Keras 的`fit_generator(...)`函數來訓練該模型。 `train_generator`每次生成 30 張圖像,因此我們將使用`steps_per_epoch`參數并將其設置為 100,以針對每個周期從訓練數據中隨機生成的 3,000 張圖像上訓練模型。 我們的`val_generator`每次生成 20 張圖像,因此我們將`validation_steps`參數設置為 50,以在所有 1,000 張驗證圖像上驗證我們的模型準確率(請記住,我們沒有增加驗證數據集):
```py
history = model.fit_generator(train_generator,
steps_per_epoch=100, epochs=100,
validation_data=val_generator,
validation_steps=50, verbose=1)
Epoch 1/100
100/100 - 12s - loss: 0.6924 - acc: 0.5113 - val_loss: 0.6943 - val_acc: 0.5000
Epoch 2/100
100/100 - 11s - loss: 0.6855 - acc: 0.5490 - val_loss: 0.6711 - val_acc: 0.5780
...
...
Epoch 99/100
100/100 - 11s - loss: 0.3735 - acc: 0.8367 - val_loss: 0.4425 - val_acc: 0.8340
Epoch 100/100
100/100 - 11s - loss: 0.3733 - acc: 0.8257 - val_loss: 0.4046 - val_acc: 0.8200
```
我們的驗證準確率躍升至 **82%** 左右,幾乎比我們先前的模型好 **4-5%**。 此外,我們的訓練準確率與驗證準確率非常相似,這表明我們的模型不再適合。 下圖描述了模型的準確率和每個周期的損失:
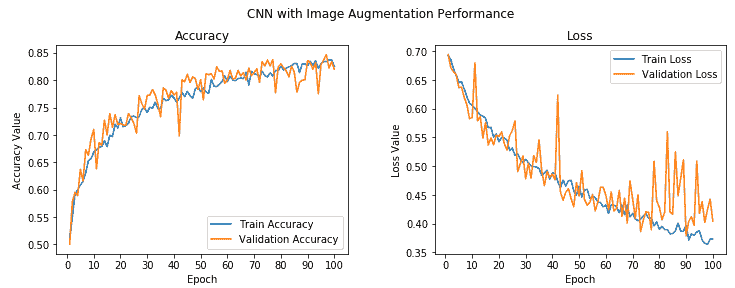
總體上,雖然驗證準確率和損失存在一些峰值,但我們發現它與訓練準確率非常接近,損失表明我們獲得的模型與以前的模型相比,泛化效果更好。 現在保存此模型,以便稍后可以在測試數據集中對其進行評估:
```py
model.save('cats_dogs_cnn_img_aug.h5')
```
現在,我們將嘗試并利用遷移學習的功能,看看是否可以構建更好的模型。
# 利用預訓練的 CNN 模型的遷移學習
到目前為止,我們已經通過指定自己的架構從頭開始構建了 CNN 深度學習模型。 在本節中,我們將利用預訓練的模型,該模型基本上是計算機視覺領域的專家,并且在圖像分類和歸類中享有盛譽。 我們建議您閱讀第 4 章“遷移學習基礎知識”,以簡要地了解預訓練模型及其在該領域中的應用。
在構建新模型或重用它們時,可以通過以下兩種流行的方式來使用預訓練的模型:
* 使用預訓練模型作為特征提取器
* 微調預訓練模型
我們將在本節中詳細介紹這兩個方面。 我們將在本章中使用的預訓練模型是流行的 VGG-16 模型,該模型由牛津大學的視覺幾何小組創建,該模型專門為大型視覺識別構建非常深的卷積網絡。 您可以在[這個頁面](http://www.robots.ox.ac.uk/~vgg/research/very_deep/)中找到有關它的更多信息。 **ImageNet 大規模視覺識別挑戰賽**(**ILSVRC**)評估了用于大規模物體檢測和圖像分類的算法,其模型通常在這場比賽中獲得第一名。
像 VGG-16 這樣的預訓練模型是已經在具有大量不同圖像類別的巨大數據集(ImageNet)上進行訓練的模型。 考慮到這一事實,正如我們之前針對 CNN 模型所學習的特征所討論的那樣,該模型應該已經學習了穩健的特征層次結構,即空間,旋轉和平移不變性。 因此,該模型已經學會了對屬于 1,000 個不同類別的一百萬個圖像的特征的良好表示,可以充當適合于計算機視覺問題的新圖像的良好特征提取器。 這些新圖像可能永遠不會存在于 ImageNet 數據集中或可能屬于完全不同的類別,但考慮到我們在第 4 章“遷移學習基礎”中討論的遷移學習原理,該模型仍應能夠從這些圖像中提取相關特征。
這為我們提供了一個優勢,即可以使用預先訓練的模型作為新圖像的有效特征提取器,以解決各種復雜的計算機視覺任務,例如用較少的圖像解決我們的貓對狗分類器,甚至構建狗的品種分類器,面部表情分類器 , 以及更多! 在釋放遷移學習的力量解決我們的問題之前,讓我們簡要討論一下 VGG-16 模型架構。
# 了解 VGG-16 模型
VGG-16 模型是建立在 ImageNet 數據庫上的 16 層(卷積和完全連接)網絡,該網絡旨在進行圖像識別和分類。 該模型是由 Karen Simonyan 和 Andrew Zisserman 建立的,并在他們的論文[《用于大規模圖像識別的超深度卷積網絡》](https://arxiv.org/pdf/1409.1556.pdf)(arXiv 2014)。
我建議所有感興趣的讀者繼續閱讀本文中的優秀文獻。 在第 3 章“了解深度學習架構”中簡要提到了 VGG-16 模型,但我們將對其進行更詳細的討論,并在我們的示例中也使用它。 下圖描述了 VGG-16 模型的架構:

您可以清楚地看到,我們總共有 13 個卷積層,其中使用了`3 x 3`卷積濾波器,以及用于下采樣的最大池化層,每層中總共有兩個完全連接的隱藏層,共 4,096 個單元,然后是 1,000 個單元的密集層, 其中每個單元代表 ImageNet 數據庫中的圖像類別之一。
我們不需要最后三層,因為我們將使用我們自己的完全連接的密集層來預測圖像是狗還是貓。 我們更關注前五個塊,因此我們可以利用 VGG 模型作為有效的特征提取器。 對于其中一個模型,我們將凍結所有五個卷積塊以確保它們的權重在每個周期后都不會更新,從而將其用作簡單的特征提取器。 對于最后一個模型,我們將對 VGG 模型進行微調,在該模型中,我們將解凍最后兩個塊(**塊 4** 和**塊 5**),以便在我們訓練自己的模型時,它們的權重在每個周期(每批數據)得到更新。
在下面的框圖中,我們代表了先前的架構以及將要使用的兩個變體(基本特征提取器和微調),因此您可以獲得更好的視覺視角:
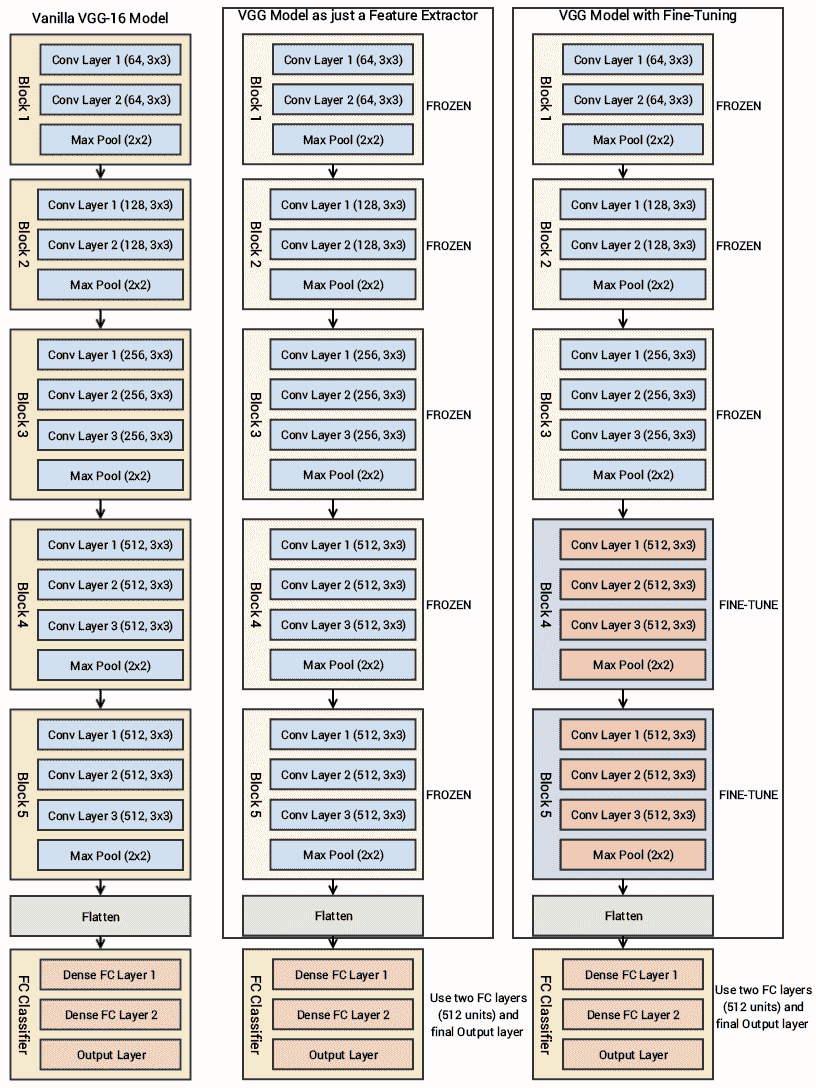
因此,我們最關心的是利用 VGG-16 模型的卷積塊,然后展平最終輸出(來自特征圖),以便我們可以將其輸入到我們自己的密集層中進行分類。 本章本節中使用的所有代碼都可以通過`Transfer Learning.ipynb` Jupyter 筆記本在 CNN 中找到。
# 作為特征提取器的預訓練的 CNN 模型
讓我們利用 Keras,加載 VGG-16 模型并凍結卷積塊,以便將其用作圖像特征提取器:
```py
from keras.applications import vgg16
from keras.models import Model
import keras
vgg = vgg16.VGG16(include_top=False, weights='imagenet',
input_shape=input_shape)
output = vgg.layers[-1].output
output = keras.layers.Flatten()(output)
vgg_model = Model(vgg.input, output)
vgg_model.trainable = False
for layer in vgg_model.layers:
layer.trainable = False
vgg_model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 150, 150, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 150, 150, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 150, 150, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 75, 75, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 75, 75, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 37, 37, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 8192) 0
=================================================================
Total params: 14,714,688
Trainable params: 0
Non-trainable params: 14,714,688
__________________________________________________________________
```
該模型摘要向我們顯示了每個塊以及每個塊中存在的層,這些層與我們之前描述的架構圖匹配。 您會看到我們刪除了與 VGG-16 模型有關的分類器的最后一部分,因為我們將構建自己的分類器并利用 VGG 作為特征提取器。
要驗證 VGG-16 模型的各層是否凍結,我們可以使用以下代碼:
```py
import pandas as pd
pd.set_option('max_colwidth', -1)
layers = [(layer, layer.name, layer.trainable) for layer in
vgg_model.layers]
pd.DataFrame(layers, columns=['Layer Type', 'Layer Name', 'Layer
Trainable'])
```
前面的代碼生成以下輸出:

```py
print("Trainable layers:", vgg_model.trainable_weights)
Trainable layers: []
```
從前面的輸出中很明顯,VGG-16 模型的所有層都是凍結的,這很好,因為我們不希望在模型訓練期間改變它們的權重。 VGG-16 模型中的最后一個激活特征圖(`block5_pool`的輸出)為我們提供了瓶頸特征,這些特征可以被展平并饋送到完全連接的深度神經網絡分類器中。 以下代碼片段顯示了來自我們的訓練數據的樣本圖像的瓶頸特征:
```py
bottleneck_feature_example = vgg.predict(train_imgs_scaled[0:1]) print(bottleneck_feature_example.shape)
plt.imshow(bottleneck_feature_example[0][:,:,0])
(1, 4, 4, 512)
```
前面的代碼生成以下輸出:
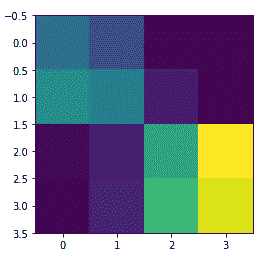
我們將`vgg_model`對象中的瓶頸特征展平,以使其可以被饋送到我們完全連接的分類器中。 節省模型訓練時間的一種方法是使用該模型,并從我們的訓練和驗證數據集中提取所有特征,然后將它們作為輸入提供給分類器。 現在,讓我們從訓練和驗證集中提取瓶頸特征:
```py
def get_bottleneck_features(model, input_imgs):
features = model.predict(input_imgs, verbose=0)
return features
train_features_vgg = get_bottleneck_features(vgg_model,
train_imgs_scaled)
validation_features_vgg = get_bottleneck_features(vgg_model,
validation_imgs_scaled)
print('Train Bottleneck Features:', train_features_vgg.shape,
'\tValidation Bottleneck Features:',
validation_features_vgg.shape)
Train Bottleneck Features: (3000, 8192) Validation Bottleneck Features:
(1000, 8192)
```
前面的輸出告訴我們,我們已經成功提取了 3,000 個訓練圖像和 1,000 個驗證圖像的尺寸為`1 x 8,192`的扁平瓶頸特征。 現在讓我們構建深度神經網絡分類器的架構,它將這些特征作為輸入:
```py
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout, InputLayer
from keras.models import Sequential
from keras import optimizers
input_shape = vgg_model.output_shape[1]
model = Sequential()
model.add(InputLayer(input_shape=(input_shape,)))
model.add(Dense(512, activation='relu', input_dim=input_shape)) model.add(Dropout(0.3)) model.add(Dense(512, activation='relu')) model.add(Dropout(0.3)) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['accuracy'])
model.summary()
_______________________________________________________________
Layer (type) Output Shape Param # =================================================================
input_2 (InputLayer) (None, 8192) 0 _________________________________________________________________
dense_1 (Dense) (None, 512) 4194816 _________________________________________________________________
dropout_1 (Dropout) (None, 512) 0 _________________________________________________________________
dense_2 (Dense) (None, 512) 262656 _________________________________________________________________
dropout_2 (Dropout) (None, 512) 0 _________________________________________________________________
dense_3 (Dense) (None, 1) 513 =================================================================
```
就像我們之前提到的,大小為`8192`的瓶頸特征向量用作我們分類模型的輸入。 關于密集層,我們使用與以前的模型相同的架構。 讓我們現在訓練這個模型:
```py
history = model.fit(x=train_features_vgg, y=train_labels_enc,
validation_data=(validation_features_vgg,
validation_labels_enc),
batch_size=batch_size, epochs=epochs, verbose=1)
Train on 3000 samples, validate on 1000 samples
Epoch 1/30
3000/3000 - 1s 373us/step - loss: 0.4325 - acc: 0.7897 - val_loss: 0.2958 - val_acc: 0.8730
Epoch 2/30
3000/3000 - 1s 286us/step - loss: 0.2857 - acc: 0.8783 - val_loss: 0.3294 - val_acc: 0.8530
...
...
Epoch 29/30
3000/3000 - 1s 287us/step - loss: 0.0121 - acc: 0.9943 - val_loss: 0.7760 - val_acc: 0.8930
Epoch 30/30
3000/3000 - 1s 287us/step - loss: 0.0102 - acc: 0.9987 - val_loss: 0.8344 - val_acc: 0.8720
```
我們得到的模型的驗證精度接近 **88%**,幾乎比具有圖像增強的基本 CNN 模型提高了 **5-6%**,這非常好。 不過,該模型似乎確實過擬合,我們可以使用下圖中所示的精度和損耗圖進行檢查:
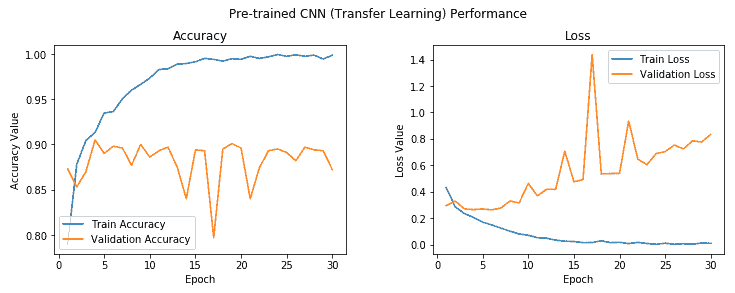
在第五個周期之后,模型訓練與驗證準確率之間存在相當大的差距,這清楚表明模型在此之后對訓練數據過擬合。 但是總的來說,這似乎是迄今為止最好的模型,通過利用 VGG-16 模型作為特征提取器,我們甚至不需要使用圖像增強策略就可以接近 **90%** 驗證精度。 但是我們還沒有充分利用遷移學習的全部潛力。 讓我們嘗試在此模型上使用我們的圖像增強策略。 在此之前,我們使用以下代碼將此模型保存到磁盤:
```py
model.save('cats_dogs_tlearn_basic_cnn.h5')
```
# 作為圖像增強的特征提取器預訓練的 CNN 模型
我們將為之前使用的訓練和驗證數據集使用相同的數據生成器。 為了便于理解,構建它們的代碼如下所示:
```py
train_datagen = ImageDataGenerator(rescale=1./255, zoom_range=0.3,
rotation_range=50,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
val_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow(train_imgs, train_labels_enc,
batch_size=30)
val_generator = val_datagen.flow(validation_imgs,
validation_labels_enc,
batch_size=20)
```
現在讓我們構建深度學習模型架構。 因為我們將在數據生成器上進行訓練,所以我們不會像上次那樣提取瓶頸特征。 因此,我們將`vgg_model`對象作為輸入傳遞給我們自己的模型:
```py
model = Sequential()
model.add(vgg_model)
model.add(Dense(512, activation='relu', input_dim=input_shape)) model.add(Dropout(0.3)) model.add(Dense(512, activation='relu')) model.add(Dropout(0.3)) model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=2e-5),
metrics=['accuracy'])
```
您可以清楚地看到一切都一樣。 由于我們將訓練 100 個周期,因此我們將學習率稍微降低了,并且不想對我們的模型層進行突然的權重調整。 請記住,VGG-16 模型的層仍在此處凍結,我們仍將其僅用作基本特征提取器:
```py
history = model.fit_generator(train_generator, steps_per_epoch=100,
epochs=100,
validation_data=val_generator,
validation_steps=50,
verbose=1)
Epoch 1/100
100/100 - 45s 449ms/step - loss: 0.6511 - acc: 0.6153 - val_loss: 0.5147 - val_acc: 0.7840
Epoch 2/100
100/100 - 41s 414ms/step - loss: 0.5651 - acc: 0.7110 - val_loss: 0.4249 - val_acc: 0.8180
...
...
Epoch 99/100
100/100 - 42s 417ms/step - loss: 0.2656 - acc: 0.8907 - val_loss: 0.2757 - val_acc: 0.9050
Epoch 100/100
100/100 - 42s 418ms/step - loss: 0.2876 - acc: 0.8833 - val_loss: 0.2665 - val_acc: 0.9000
```
我們可以看到我們的模型的整體驗證精度為 **90%**,這比我們先前的模型略有改進,并且訓練和驗證精度彼此非常接近,表明該模型是欠擬合。 可以通過查看以下有關模型準確率和損失的圖來加強這一點:
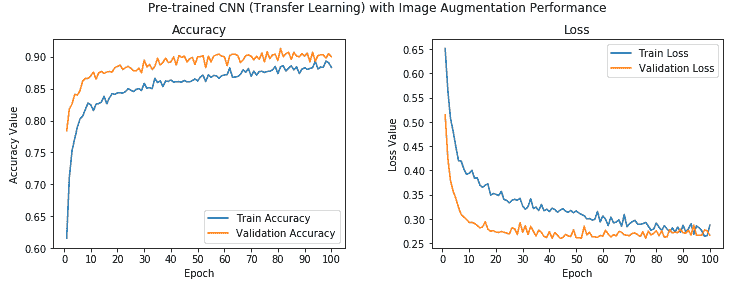
我們可以清楚地看到,訓練值和驗證準確率的值非常接近,并且模型也不會過擬合。 此外,我們達到 **90%** 的準確率,這很干凈! 讓我們現在將此模型保存在磁盤上,以便將來對測試數據進行評估:
```py
model.save('cats_dogs_tlearn_img_aug_cnn.h5')
```
現在,我們將微調 VGG-16 模型以構建我們的最后一個分類器,我們將在此取消凍結第 4 塊和第 5 塊,如本節開頭所述。
# 具有微調和圖像增強的預訓練 CNN 模型
現在,我們將利用存儲在`vgg_model`變量中的 VGG-16 模型對象,解凍卷積塊 4 和 5,同時保持前三個塊處于凍結狀態。 以下代碼可幫助我們實現這一目標:
```py
vgg_model.trainable = True
set_trainable = False
for layer in vgg_model.layers:
if layer.name in ['block5_conv1', 'block4_conv1']:
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False
print("Trainable layers:", vgg_model.trainable_weights)
Trainable layers:
[<tf.Variable 'block4_conv1/kernel:0' shape=(3, 3, 256, 512) dtype=float32_ref>, <tf.Variable 'block4_conv1/bias:0' shape=(512,) dtype=float32_ref>,
<tf.Variable 'block4_conv2/kernel:0' shape=(3, 3, 512, 512) dtype=float32_ref>, <tf.Variable 'block4_conv2/bias:0' shape=(512,) dtype=float32_ref>,
<tf.Variable 'block4_conv3/kernel:0' shape=(3, 3, 512, 512) dtype=float32_ref>, <tf.Variable 'block4_conv3/bias:0' shape=(512,) dtype=float32_ref>,
<tf.Variable 'block5_conv1/kernel:0' shape=(3, 3, 512, 512) dtype=float32_ref>, <tf.Variable 'block5_conv1/bias:0' shape=(512,) dtype=float32_ref>,
<tf.Variable 'block5_conv2/kernel:0' shape=(3, 3, 512, 512) dtype=float32_ref>, <tf.Variable 'block5_conv2/bias:0' shape=(512,) dtype=float32_ref>,
<tf.Variable 'block5_conv3/kernel:0' shape=(3, 3, 512, 512) dtype=float32_ref>, <tf.Variable 'block5_conv3/bias:0' shape=(512,) dtype=float32_ref>]
```
您可以從前面的輸出中清楚地看到,與塊 4 和 5 有關的卷積和池化層現在是可訓練的,并且還可以使用以下代碼來驗證凍結和解凍哪些層:
```py
layers = [(layer, layer.name, layer.trainable) for layer in vgg_model.layers] pd.DataFrame(layers, columns=['Layer Type', 'Layer
Name', 'Layer Trainable'])
```
前面的代碼生成以下輸出:

我們可以清楚地看到最后兩個塊現在是可訓練的,這意味著當我們傳遞每批數據時,這些層的權重也將在每個周期中通過反向傳播進行更新。 我們將使用與之前的模型相同的數據生成器和模型架構,并對模型進行訓練。 因為我們不想卡在任何局部最小值上,所以我們會稍微降低學習率,并且我們也不想突然將可訓練的 VGG-16 模型層的權重突然增加可能會對模型產生不利影響的大因素:
```py
# data generators
train_datagen = ImageDataGenerator(rescale=1./255, zoom_range=0.3,
rotation_range=50,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
val_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow(train_imgs, train_labels_enc,
batch_size=30)
val_generator = val_datagen.flow(validation_imgs,
validation_labels_enc,
batch_size=20)
# build model architecture
model = Sequential()
model.add(vgg_model)
model.add(Dense(512, activation='relu', input_dim=input_shape)) model.add(Dropout(0.3)) model.add(Dense(512, activation='relu')) model.add(Dropout(0.3)) model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-5),
metrics=['accuracy'])
# model training
history = model.fit_generator(train_generator, steps_per_epoch=100,
epochs=100,
validation_data=val_generator,
validation_steps=50,
verbose=1)
Epoch 1/100
100/100 - 64s 642ms/step - loss: 0.6070 - acc: 0.6547 - val_loss: 0.4029 - val_acc: 0.8250
Epoch 2/100
100/100 - 63s 630ms/step - loss: 0.3976 - acc: 0.8103 - val_loss: 0.2273 - val_acc: 0.9030
...
...
Epoch 99/100
100/100 - 63s 629ms/step - loss: 0.0243 - acc: 0.9913 - val_loss: 0.2861 - val_acc: 0.9620
Epoch 100/100
100/100 - 63s 629ms/step - loss: 0.0226 - acc: 0.9930 - val_loss: 0.3002 - val_acc: 0.9610
```
從前面的輸出中我們可以看到,我們的模型的驗證精度約為 **96%**,這比我們先前的模型提高了 **6%**。 總體而言,與我們的第一個基本 CNN 模型相比,該模型的驗證準確率提高了 **24%**。 這確實顯示了遷移學習可以多么有用。
讓我們觀察模型的準確率和損失圖:
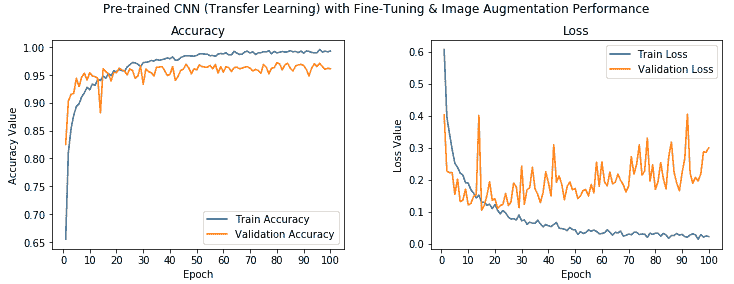
我們可以看到,這里的準確率值確實非常好,盡管模型看起來可能對訓練數據有些過擬合,但我們仍然獲得了很高的驗證準確率。 現在,使用以下代碼將此模型保存到磁盤:
```py
model.save('cats_dogs_tlearn_finetune_img_aug_cnn.h5')
```
現在,通過在測試數據集上實際評估模型的表現,將所有模型進行測試。
# 評估我們的深度學習模型
現在,我們將評估到目前為止構建的五個不同模型,方法是首先在樣本測試圖像上對其進行測試,然后可視化 CNN 模型實際上是如何嘗試從圖像中分析和提取特征,最后通過在測試數據集上測試每個模型的表現來進行評估 。 如果要執行代碼并遵循本章的內容,`Model Performance Evaluations.ipynb` Jupyter 筆記本中提供了此部分的代碼。 我們還構建了一個名為`model_evaluation_utils`的實用工具模塊,我們將使用該模塊來評估深度學習模型的表現。 讓我們在開始之前加載以下依賴項:
```py
import glob
import numpy as np
import matplotlib.pyplot as plt
from keras.preprocessing.image import load_img, img_to_array, array_to_img
from keras.models import load_model
import model_evaluation_utils as meu
%matplotlib inline
```
加載這些依賴關系后,讓我們加載到目前為止已保存的模型:
```py
basic_cnn = load_model('cats_dogs_basic_cnn.h5')
img_aug_cnn = load_model('cats_dogs_cnn_img_aug.h5')
tl_cnn = load_model('cats_dogs_tlearn_basic_cnn.h5')
tl_img_aug_cnn = load_model('cats_dogs_tlearn_img_aug_cnn.h5') tl_img_aug_finetune_cnn =
load_model('cats_dogs_tlearn_finetune_img_aug_cnn.h5')
```
這有助于我們檢索使用各種技術和架構在本章中創建的所有五個模型。
# 樣本測試圖像的模型預測
現在,我們將加載不屬于任何數據集的樣本圖像,并嘗試查看不同模型的預測。 我將在此處使用我的寵物貓的圖像,因此這將很有趣! 讓我們加載示例圖像和一些基本配置:
```py
# basic configurations
IMG_DIM = (150, 150)
input_shape = (150, 150, 3)
num2class_label_transformer = lambda l: ['cat' if x == 0 else 'dog' for
x in l]
class2num_label_transformer = lambda l: [0 if x == 'cat' else 1 for x
in l]
# load sample image
sample_img_path = 'my_cat.jpg'
sample_img = load_img(sample_img_path, target_size=IMG_DIM)
sample_img_tensor = img_to_array(sample_img)
sample_img_tensor = np.expand_dims(sample_img_tensor, axis=0)
sample_img_tensor /= 255\.
print(sample_img_tensor.shape)
plt.imshow(sample_img_tensor[0]) (1, 150, 150, 3)
```
前面的代碼生成以下輸出:
現在,我們已經加載了示例圖像,讓我們看看我們的模型將其作為該圖像類別的預測(我的貓):
```py
cnn_prediction = num2class_label_transformer(basic_cnn.predict_classes(
sample_img_tensor,
verbose=0))
cnn_img_aug_prediction = num2class_label_transformer(img_aug_cnn.predict_classes(
sample_img_tensor,
verbose=0))
tlearn_cnn_prediction = num2class_label_transformer(tl_cnn.predict_classes(
get_bottleneck_features(vgg_model,
sample_img_tensor),
verbose=0))
tlearn_cnn_img_aug_prediction =
num2class_label_transformer(
tl_img_aug_cnn.predict_classes(sample_img_tensor,
verbose=0))
tlearn_cnn_finetune_img_aug_prediction =
num2class_label_transformer(
tl_img_aug_finetune_cnn.predict_classes(sample_img_tensor,
verbose=0))
print('Predictions for our sample image:\n',
'\nBasic CNN:', cnn_prediction,
'\nCNN with Img Augmentation:', cnn_img_aug_prediction,
'\nPre-trained CNN (Transfer Learning):', tlearn_cnn_prediction,
'\nPre-trained CNN with Img Augmentation (Transfer Learning):',
tlearn_cnn_img_aug_prediction,
'\nPre-trained CNN with Fine-tuning & Img Augmentation (Transfer
Learning):', tlearn_cnn_finetune_img_aug_prediction)
Predictions for our sample image: Basic CNN: ['cat']
CNN with Img Augmentation: ['dog']
Pre-trained CNN (Transfer Learning): ['dog']
Pre-trained CNN with Img Augmentation (Transfer Learning): ['cat']
Pre-trained CNN with Fine-tuning & Img Augmentation (Transfer Learning): ['cat']
```
您可以從前面的輸出中看到,我們的三個模型像貓一樣正確地預測了圖像,其中兩個錯誤。 有趣的是,基本的 CNN 模型也正確無誤,并且預訓練的模型具有預期的微調和圖像增強。
# 可視化 CNN 模型的感知
深度學習模型通常被稱為**黑盒模型**,因為與諸如決策樹之類的簡單 ML 模型相比,很難真正解釋該模型在內部的工作方式。 我們知道,基于 CNN 的深度學習模型使用卷積層,該卷積層使用過濾器提取代表特征空間層次的激活特征圖。 從概念上講,頂級卷積層學習小的局部模式,而網絡中較低的層則學習更復雜和更大的模式,這些模式是從頂級卷積層獲得的。 讓我們嘗試通過一個示例來形象化。
我們將采用最佳模型(通過微調和圖像增強進行遷移學習),并嘗試從前八層中提取輸出激活特征圖。 本質上,這將最終為我們提供 VGG-16 模型前三個模塊的卷積和池化層,因為我們在模型中使用了相同的特征提取。
要查看這些層,可以使用以下代碼:
```py
tl_img_aug_finetune_cnn.layers[0].layers[1:9]
[<keras.layers.convolutional.Conv2D at 0x7f514841b0b8>, <keras.layers.convolutional.Conv2D at 0x7f514841b0f0>, <keras.layers.pooling.MaxPooling2D at 0x7f5117d4bb00>, <keras.layers.convolutional.Conv2D at 0x7f5117d4bbe0>, <keras.layers.convolutional.Conv2D at 0x7f5117d4bd30>, <keras.layers.pooling.MaxPooling2D at 0x7f5117d4beb8>, <keras.layers.convolutional.Conv2D at 0x7f5117d4bf98>, <keras.layers.convolutional.Conv2D at 0x7f5117d00128>]
```
現在,基于它試圖從我的貓的樣本測試圖像中提取的內容,從我們的模型中提取特征圖。 為了簡單說明,我們從塊 1 中提取第一個卷積層之后的輸出,并在以下代碼段中從中查看一些激活特征圖:
```py
from keras import models
# Extracts the outputs of the top 8 layers:
layer_outputs = [layer.output for layer in
tl_img_aug_finetune_cnn.layers[0].layers[1:9]]
# Creates a model that will return these outputs, given the model input: activation_model = models.Model(
inputs=tl_img_aug_finetune_cnn.layers[0].layers[1].input,
outputs=layer_outputs)
# This will return a list of 8 Numpy arrays
# one array per layer activation
activations = activation_model.predict(sample_img_tensor)
print('Sample layer shape:', activations[0].shape)
print('Sample convolution (activation map) shape:',
activations[0][0, :, :, 1].shape)
fig, ax = plt.subplots(1,5, figsize=(16, 6))
ax[0].imshow(activations[0][0, :, :, 10], cmap='bone') ax[1].imshow(activations[0][0, :, :, 25], cmap='bone') ax[2].imshow(activations[0][0, :, :, 40], cmap='bone') ax[3].imshow(activations[0][0, :, :, 55], cmap='bone') ax[4].imshow(activations[0][0, :, :, 63], cmap='bone')
Sample layer shape: (1, 150, 150, 64)
Sample convolution (activation map) shape: (150, 150)
```
前面的代碼生成以下輸出:
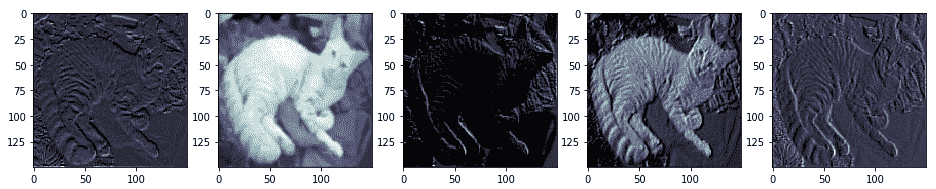
從前面的輸出中,我們可以清楚地看到,第一卷積層的輸出為我們提供了總共 64 個激活特征圖,每個特征圖的大小為`150 x 150`。 我們在前面的代碼段中可視化了其中五個特征圖。 您可以看到模型如何嘗試提取與圖像有關的相關特征,例如色相,強度,邊緣,角等。 以下輸出描繪了來自塊 1 和 2 的 VGG-16 模型的更多激活圖:

為了獲得上述激活函數圖,我們利用了`Model Performance Evaluations.ipynb` Jupyter 筆記本中可用的代碼段,這要感謝 Francois Chollet 和他的書《Python 深度學習》,它可以幫助可視化我們的 CNN 模型中所有選定的層。我們已經可視化了模型的前八層,這是我們在筆記本中較早選擇的,但是在這里顯示了前兩個塊的激活圖。 隨意檢出筆記本并為自己的模型重復使用相同的代碼。 從前面的屏幕截圖中,您可能會看到頂層特征圖通常保留了很多原始圖像,但是當您深入模型時,特征圖變得更加抽象,復雜且難以解釋。
# 在測試數據上評估模型表現
現在是時候進行最終測試了,在該測試中,我們通過對測試數據集進行預測來從字面上測試模型的表現。 在進行預測之前,讓我們先加載并準備測試數據集:
```py
IMG_DIM = (150, 150)
test_files = glob.glob('test_data/*')
test_imgs = [img_to_array(load_img(img, target_size=IMG_DIM))
for img in test_files]
test_imgs = np.array(test_imgs)
test_labels = [fn.split('/')[1].split('.')[0].strip() for fn in test_files] test_labels_enc = class2num_label_transformer(test_labels)
test_imgs_scaled = test_imgs.astype('float32')
test_imgs_scaled /= 255
print('Test dataset shape:', test_imgs.shape)
Test dataset shape: (1000, 150, 150, 3)
```
現在我們已經準備好按比例縮放的數據集,讓我們通過對所有測試圖像進??行預測來評估每個模型,然后通過檢查預測的準確率來評估模型的表現:
```py
# Model 1 - Basic CNN
predictions = basic_cnn.predict_classes(test_imgs_scaled, verbose=0)
predictions = num2class_label_transformer(predictions) meu.display_model_performance_metrics(true_labels=test_labels,
predicted_labels=predictions,
classes=list(set(test_labels)))
```
前面的代碼生成以下輸出:

```py
# Model 2 - Basic CNN with Image Augmentation
predictions = img_aug_cnn.predict_classes(test_imgs_scaled, verbose=0) predictions = num2class_label_transformer(predictions) meu.display_model_performance_metrics(true_labels=test_labels,
predicted_labels=predictions,
classes=list(set(test_labels)))
```
前面的代碼生成以下輸出:

```py
# Model 3 - Transfer Learning (basic feature extraction)
test_bottleneck_features = get_bottleneck_features(vgg_model, test_imgs_scaled) predictions = tl_cnn.predict_classes(test_bottleneck_features, verbose=0) predictions = num2class_label_transformer(predictions)
meu.display_model_performance_metrics(true_labels=test_labels,
predicted_labels=predictions,
classes=list(set(test_labels)))
```
前面的代碼生成以下輸出:

```py
# Model 4 - Transfer Learning with Image Augmentation
predictions = tl_img_aug_cnn.predict_classes(test_imgs_scaled, verbose=0) predictions = num2class_label_transformer(predictions) meu.display_model_performance_metrics(true_labels=test_labels,
predicted_labels=predictions,
classes=list(set(test_labels)))
```
前面的代碼生成以下輸出:

```py
# Model 5 - Transfer Learning with Fine-tuning & Image Augmentation
predictions = tl_img_aug_finetune_cnn.predict_classes(test_imgs_scaled,
verbose=0)
predictions = num2class_label_transformer(predictions) meu.display_model_performance_metrics(true_labels=test_labels,
predicted_labels=predictions,
classes=list(set(test_labels)))
```

我們可以看到我們肯定有一些有趣的結果。 每個后續模型的表現均優于先前模型,這是預期的,因為我們對每個新模型都嘗試了更高級的技術。 我們最差的模型是基本的 CNN 模型,其模型準確率和 F1 分數約為 **78%**,而我們最好的模型是經過微調的模型,其中包含遷移學習和圖像增強,從而為我們提供了一個模型準確率和 **96%** 的 F1 得分,考慮到我們從 3,000 個圖像訓練數據集中訓練了模型,這真是太了不起了。 現在,讓我們繪制最差模型和最佳模型的 ROC 曲線:
```py
# worst model - basic CNN
meu.plot_model_roc_curve(basic_cnn, test_imgs_scaled,
true_labels=test_labels_enc, class_names=[0,
1])
# best model - transfer learning with fine-tuning & image augmentation meu.plot_model_roc_curve(tl_img_aug_finetune_cnn, test_imgs_scaled,
true_labels=test_labels_enc, class_names=[0,
1])
```
我們得到的圖如下:
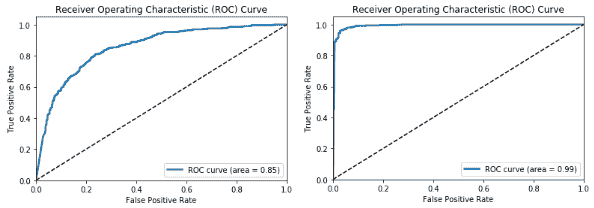
這應該給您一個很好的主意,即預訓練模型和遷移學習可以帶來多大的差異,尤其是當我們面臨諸如數據較少等約束時,在解決復雜問題上。 我們鼓勵您使用自己的數據嘗試類似的策略。
# 總結
本章的目的是讓您更深入地了解構建深度學習模型以解決實際問題,并了解遷移學習的有效性。 我們涵蓋了遷移學習需求的各個方面,尤其是在解決數據受限的問題時。 我們從頭開始構建了多個 CNN 模型,還看到了適當的圖像增強策略的好處。 我們還研究了如何利用預訓練的模型進行遷移學習,并介紹了使用它們的各種方法,包括用作特征提取器和微調。 我們看到了 VGG-16 模型的詳細架構,以及如何利用該模型作為有效的圖像特征提取器。 與遷移學習有關的策略(包括特征提取和微調以及圖像增強)被用來構建有效的深度學習圖像分類器。
最后但并非最不重要的一點是,我們在測試數據集上評估了所有模型,并獲得了一些卷積神經網絡在構建特征圖時如何在內部可視化圖像的觀點。 在隨后的章節中,我們將研究需要遷移學習的更復雜的實際案例研究。 敬請關注!
- TensorFlow 1.x 深度學習秘籍
- 零、前言
- 一、TensorFlow 簡介
- 二、回歸
- 三、神經網絡:感知器
- 四、卷積神經網絡
- 五、高級卷積神經網絡
- 六、循環神經網絡
- 七、無監督學習
- 八、自編碼器
- 九、強化學習
- 十、移動計算
- 十一、生成模型和 CapsNet
- 十二、分布式 TensorFlow 和云深度學習
- 十三、AutoML 和學習如何學習(元學習)
- 十四、TensorFlow 處理單元
- 使用 TensorFlow 構建機器學習項目中文版
- 一、探索和轉換數據
- 二、聚類
- 三、線性回歸
- 四、邏輯回歸
- 五、簡單的前饋神經網絡
- 六、卷積神經網絡
- 七、循環神經網絡和 LSTM
- 八、深度神經網絡
- 九、大規模運行模型 -- GPU 和服務
- 十、庫安裝和其他提示
- TensorFlow 深度學習中文第二版
- 一、人工神經網絡
- 二、TensorFlow v1.6 的新功能是什么?
- 三、實現前饋神經網絡
- 四、CNN 實戰
- 五、使用 TensorFlow 實現自編碼器
- 六、RNN 和梯度消失或爆炸問題
- 七、TensorFlow GPU 配置
- 八、TFLearn
- 九、使用協同過濾的電影推薦
- 十、OpenAI Gym
- TensorFlow 深度學習實戰指南中文版
- 一、入門
- 二、深度神經網絡
- 三、卷積神經網絡
- 四、循環神經網絡介紹
- 五、總結
- 精通 TensorFlow 1.x
- 一、TensorFlow 101
- 二、TensorFlow 的高級庫
- 三、Keras 101
- 四、TensorFlow 中的經典機器學習
- 五、TensorFlow 和 Keras 中的神經網絡和 MLP
- 六、TensorFlow 和 Keras 中的 RNN
- 七、TensorFlow 和 Keras 中的用于時間序列數據的 RNN
- 八、TensorFlow 和 Keras 中的用于文本數據的 RNN
- 九、TensorFlow 和 Keras 中的 CNN
- 十、TensorFlow 和 Keras 中的自編碼器
- 十一、TF 服務:生產中的 TensorFlow 模型
- 十二、遷移學習和預訓練模型
- 十三、深度強化學習
- 十四、生成對抗網絡
- 十五、TensorFlow 集群的分布式模型
- 十六、移動和嵌入式平臺上的 TensorFlow 模型
- 十七、R 中的 TensorFlow 和 Keras
- 十八、調試 TensorFlow 模型
- 十九、張量處理單元
- TensorFlow 機器學習秘籍中文第二版
- 一、TensorFlow 入門
- 二、TensorFlow 的方式
- 三、線性回歸
- 四、支持向量機
- 五、最近鄰方法
- 六、神經網絡
- 七、自然語言處理
- 八、卷積神經網絡
- 九、循環神經網絡
- 十、將 TensorFlow 投入生產
- 十一、更多 TensorFlow
- 與 TensorFlow 的初次接觸
- 前言
- 1.?TensorFlow 基礎知識
- 2. TensorFlow 中的線性回歸
- 3. TensorFlow 中的聚類
- 4. TensorFlow 中的單層神經網絡
- 5. TensorFlow 中的多層神經網絡
- 6. 并行
- 后記
- TensorFlow 學習指南
- 一、基礎
- 二、線性模型
- 三、學習
- 四、分布式
- TensorFlow Rager 教程
- 一、如何使用 TensorFlow Eager 構建簡單的神經網絡
- 二、在 Eager 模式中使用指標
- 三、如何保存和恢復訓練模型
- 四、文本序列到 TFRecords
- 五、如何將原始圖片數據轉換為 TFRecords
- 六、如何使用 TensorFlow Eager 從 TFRecords 批量讀取數據
- 七、使用 TensorFlow Eager 構建用于情感識別的卷積神經網絡(CNN)
- 八、用于 TensorFlow Eager 序列分類的動態循壞神經網絡
- 九、用于 TensorFlow Eager 時間序列回歸的遞歸神經網絡
- TensorFlow 高效編程
- 圖嵌入綜述:問題,技術與應用
- 一、引言
- 三、圖嵌入的問題設定
- 四、圖嵌入技術
- 基于邊重構的優化問題
- 應用
- 基于深度學習的推薦系統:綜述和新視角
- 引言
- 基于深度學習的推薦:最先進的技術
- 基于卷積神經網絡的推薦
- 關于卷積神經網絡我們理解了什么
- 第1章概論
- 第2章多層網絡
- 2.1.4生成對抗網絡
- 2.2.1最近ConvNets演變中的關鍵架構
- 2.2.2走向ConvNet不變性
- 2.3時空卷積網絡
- 第3章了解ConvNets構建塊
- 3.2整改
- 3.3規范化
- 3.4匯集
- 第四章現狀
- 4.2打開問題
- 參考
- 機器學習超級復習筆記
- Python 遷移學習實用指南
- 零、前言
- 一、機器學習基礎
- 二、深度學習基礎
- 三、了解深度學習架構
- 四、遷移學習基礎
- 五、釋放遷移學習的力量
- 六、圖像識別與分類
- 七、文本文件分類
- 八、音頻事件識別與分類
- 九、DeepDream
- 十、自動圖像字幕生成器
- 十一、圖像著色
- 面向計算機視覺的深度學習
- 零、前言
- 一、入門
- 二、圖像分類
- 三、圖像檢索
- 四、對象檢測
- 五、語義分割
- 六、相似性學習
- 七、圖像字幕
- 八、生成模型
- 九、視頻分類
- 十、部署
- 深度學習快速參考
- 零、前言
- 一、深度學習的基礎
- 二、使用深度學習解決回歸問題
- 三、使用 TensorBoard 監控網絡訓練
- 四、使用深度學習解決二分類問題
- 五、使用 Keras 解決多分類問題
- 六、超參數優化
- 七、從頭開始訓練 CNN
- 八、將預訓練的 CNN 用于遷移學習
- 九、從頭開始訓練 RNN
- 十、使用詞嵌入從頭開始訓練 LSTM
- 十一、訓練 Seq2Seq 模型
- 十二、深度強化學習
- 十三、生成對抗網絡
- TensorFlow 2.0 快速入門指南
- 零、前言
- 第 1 部分:TensorFlow 2.00 Alpha 簡介
- 一、TensorFlow 2 簡介
- 二、Keras:TensorFlow 2 的高級 API
- 三、TensorFlow 2 和 ANN 技術
- 第 2 部分:TensorFlow 2.00 Alpha 中的監督和無監督學習
- 四、TensorFlow 2 和監督機器學習
- 五、TensorFlow 2 和無監督學習
- 第 3 部分:TensorFlow 2.00 Alpha 的神經網絡應用
- 六、使用 TensorFlow 2 識別圖像
- 七、TensorFlow 2 和神經風格遷移
- 八、TensorFlow 2 和循環神經網絡
- 九、TensorFlow 估計器和 TensorFlow HUB
- 十、從 tf1.12 轉換為 tf2
- TensorFlow 入門
- 零、前言
- 一、TensorFlow 基本概念
- 二、TensorFlow 數學運算
- 三、機器學習入門
- 四、神經網絡簡介
- 五、深度學習
- 六、TensorFlow GPU 編程和服務
- TensorFlow 卷積神經網絡實用指南
- 零、前言
- 一、TensorFlow 的設置和介紹
- 二、深度學習和卷積神經網絡
- 三、TensorFlow 中的圖像分類
- 四、目標檢測與分割
- 五、VGG,Inception,ResNet 和 MobileNets
- 六、自編碼器,變分自編碼器和生成對抗網絡
- 七、遷移學習
- 八、機器學習最佳實踐和故障排除
- 九、大規模訓練
- 十、參考文獻