
# 一、基礎
## 變量
TensorFlow 是一種表示計算的方式,直到請求時才實際執行。 從這個意義上講,它是一種延遲計算形式,它能夠極大改善代碼的運行:
+ 更快地計算復雜變量
+ 跨多個系統的分布式計算,包括 GPU。
+ 減少了某些計算中的冗余
我們來看看實際情況。 首先,一個非常基本的 python 腳本:
```py
x = 35
y = x + 5
print(y)
```
這個腳本基本上只是“創建一個值為`35`的變量`x`,將新變量`y`的值設置為它加上`5`,當前為`40`,并將其打印出來”。 運行此程序時將打印出值`40`。 如果你不熟悉 python,請創建一個名為`basic_script.py`的新文本文件,并將該代碼復制到該文件中。將其保存在你的計算機上并運行它:
```
python basic_script.py
```
請注意,路徑(即`basic_script.py`)必須指向該文件,因此如果它位于`Code`文件夾中,則使用:
```
python Code/basic_script.py
```
此外,請確保已激活 Anaconda 虛擬環境。 在 Linux 上,這將使你的提示符看起來像:
```
(tensorenv)username@computername:~$
```
如果起作用,讓我們將其轉換為 TensorFlow 等價形式。
```py
import tensorflow as tf
x = tf.constant(35, name='x')
y = tf.Variable(x + 5, name='y')
print(y)
```
運行之后,你會得到一個非常有趣的輸出,類似于`<tensorflow.python.ops.variables.Variable object at 0x7f074bfd9ef0>`。 這顯然不是`40`的值。
原因在于,我們的程序實際上與前一個程序完全不同。 這里的代碼執行以下操作:
+ 導入`tensorflow`模塊并將其命名為`tf`
+ 創建一個名為`x`的常量值,并為其賦值`35`
+ 創建一個名為`y`的變量,并將其定義為等式`x + 5`
+ 打印`y`的等式對象
微妙的區別是,`y`沒有像我們之前的程序那樣,給出`x + 5`的當前值”。 相反,它實際上是一個等式,意思是“當計算這個變量時,取`x`的值(就像那樣)并將它加上`5`”。 `y`值的計算在上述程序中從未實際執行。
我們來解決這個問題:
```py
import tensorflow as tf
x = tf.constant(35, name='x')
y = tf.Variable(x + 5, name='y')
model = tf.global_variables_initializer()
with tf.Session() as session:
session.run(model)
print(session.run(y))
```
我們刪除了`print(y)`語句,而是創建了一個會話,并實際計算了`y`的值。這里有相當多的樣板,但它的工作原理如下:
+ 導入`tensorflow`模塊并將其命名為`tf`
+ 創建一個名為`x`的常量值,并為其賦值`35`
+ 創建一個名為`y`的變量,并將其定義為等式`x + 5`
+ 使用`tf.global_variables_initializer()`初始化變量(我們將在此詳細介紹)
+ 創建用于計算值的會話
+ 運行第四步中創建的模型
+ 僅運行變量`y`并打印出其當前值
上面的第四步是一些魔術發生的地方。在此步驟中,將創建變量之間的依賴關系的圖。在這種情況下,變量`y`取決于變量`x`,并且通過向其添加`5`來轉換它的值。請記住,直到第七步才計算該值,在此之前,僅計算等式和關系。
1)常量也可以是數組。預測此代碼將執行的操作,然后運行它來確認:
```py
import tensorflow as tf
x = tf.constant([35, 40, 45], name='x')
y = tf.Variable(x + 5, name='y')
model = tf.global_variables_initializer()
with tf.Session() as session:
session.run(model)
print(session.run(y))
```
生成包含 10,000 個隨機數的 NumPy 數組(稱為`x`),并創建一個存儲等式的變量。
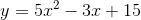
你可以使用以下代碼生成 NumPy 數組:
```py
import numpy as np
data = np.random.randint(1000, size=10000)
```
然后可以使用`data`變量代替上面問題 1 中的列表。 作為一般規則,NumPy 應該用于更大的列表/數字數組,因為它具有比列表更高的內存效率和更快的計算速度。 它還提供了大量的函數(例如計算均值),通常不可用于列表。
3)你還可以在循環更新的變量,稍后我們將這些變量用于機器學習。 看看這段代碼,預測它會做什么(然后運行它來檢查):
```py
import tensorflow as tf
x = tf.Variable(0, name='x')
model = tf.global_variables_initializer()
with tf.Session() as session:
session.run(model)
for i in range(5):
x = x + 1
print(session.run(x))
```
4)使用上面(2)和(3)中的代碼,創建一個程序,計算以下代碼行的“滑動”平均值:`np.random.randint(1000)`。 換句話說,保持循環,并在每個循環中,調用`np.random.randint(1000)`一次,并將當前平均值存儲在在每個循環中不斷更新變量中。
5)使用 TensorBoard 可視化其中一些示例的圖。 要運行 TensorBoard,請使用以下命令:`tensorboard --logdir=path/to/log-directory`。
```py
import tensorflow as tf
x = tf.constant(35, name='x')
print(x)
y = tf.Variable(x + 5, name='y')
with tf.Session() as session:
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter("/tmp/basic", session.graph)
model = tf.global_variables_initializer()
session.run(model)
print(session.run(y))
```
要了解 Tensorboard 的更多信息,請訪問我們的[可視化課程](http://learningtensorflow.com/Visualisation/)。
## 數組
在本教程中,我們將處理圖像,以便可視化數組的更改。 數組是強大的結構,我們在前面的教程中簡要介紹了它。 生成有趣的數組可能很困難,但圖像提供了很好的選擇。
首先,下載此圖像到你的計算機(右鍵單擊,并尋找選項“圖片另存為”)。

此圖片來自[維基共享的用戶 Uoaei1](https://commons.wikimedia.org/wiki/Main_Page#/media/File:Dactylorhiza_majalis_Spechtensee_01.JPG)。
要處理圖像,我們需要`matplotlib`。 我們還需要`pillow`庫,它會覆蓋已棄用的 PIL 庫來處理圖像。 你可以使用 Anaconda 的安裝方法在你的環境中安裝它們:
```
conda install matplotlib pillow
```
要加載圖像,我們使用`matplotlib`的圖像模塊:
```py
import matplotlib.image as mpimg
import os
# 首先加載圖像
dir_path = os.path.dirname(os.path.realpath(__file__))
filename = dir_path + "/MarshOrchid.jpg"
# 加載圖像
image = mpimg.imread(filename)
# 打印它的形狀
print(image.shape)
```
上面的代碼將圖像作為 NumPy 數組讀入,并打印出大小。 請注意,文件名必須是下載的圖像文件的完整路徑(絕對路徑或相對路徑)。
你會看到輸出,即`(5528, 3685, 3)`。 這意味著圖像高 5528 像素,寬 3685 像素,3 種顏色“深”。
你可以使用`pyplot`查看當前圖像,如下所示:
```py
import matplotlib.pyplot as plt
plt.imshow(image)
plt.show()
```
現在我們有了圖像,讓我們使用 TensorFlow 對它進行一些更改。
## 幾何操作
我們將要執行的第一個轉換是轉置,將圖像逆時針旋轉 90 度。 完整的程序如下,其中大部分是你見過的。
```py
import tensorflow as tf
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import os
# 再次加載圖像
dir_path = os.path.dirname(os.path.realpath(__file__))
filename = dir_path + "/MarshOrchid.jpg"
image = mpimg.imread(filename)
# 創建 TF 變量
x = tf.Variable(image, name='x')
model = tf.global_variables_initializer()
with tf.Session() as session:
x = tf.transpose(x, perm=[1, 0, 2])
session.run(model)
result = session.run(x)
plt.imshow(result)
plt.show()
```
轉置操作的結果:

新東西是這一行:
```py
x = tf.transpose(x, perm=[1, 0, 2])
```
該行使用 TensorFlow 的`transpose`方法,使用`perm`參數交換軸 0 和 1(軸 2 保持原樣)。
我們將要做的下一個操作是(左右)翻轉,將像素從一側交換到另一側。 TensorFlow 有一個稱為`reverse_sequence`的方法,但簽名有點奇怪。 這是文檔所說的內容(來自[該頁面](https://tensorflow.google.cn/api_docs/python/tf/reverse_sequence)):
> ```py
> tf.reverse_sequence(
> input,
> seq_lengths,
> seq_axis=None,
> batch_axis=None,
> name=None,
> seq_dim=None,
> batch_dim=None
> )
> ```
>
> 反轉可變長度切片。
>
> 這個操作首先沿著維度`batch_axis`對`input`卻偏,并且對于每個切片`i`,沿著維度`seq_axis`反轉第一個`seq_lengths [i]`元素。
>
> `seq_lengths`的元素必須滿足`seq_lengths [i] <= input.dims [seq_dim]`,而`seq_lengths`必須是長度為`input.dims [batch_dim]`的向量。
>
> 然后,輸入切片`i`給出了沿維度`batch_axis`的輸出切片`i`,其中第一個`seq_lengths [i]`切片沿著維度`seq_axis`被反轉。
對于這個函數,最好將其視為:
+ 根據`batch_dim`迭代數組。 設置`batch_dim = 0`意味著我們遍歷行(從上到下)。
+ 對于迭代中的每個項目
+ 對第二維切片,用`seq_dim`表示。 設置`seq_dim = 1`意味著我們遍歷列(從左到右)。
+ 迭代中第`n`項的切片由`seq_lengths`中的第`n`項表示
讓我們實際看看它:
```py
import numpy as np
import tensorflow as tf
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import os
# First, load the image again
dir_path = os.path.dirname(os.path.realpath(__file__))
filename = dir_path + "/MarshOrchid.jpg"
image = mpimg.imread(filename)
height, width, depth = image.shape
# Create a TensorFlow Variable
x = tf.Variable(image, name='x')
model = tf.global_variables_initializer()
with tf.Session() as session:
x = tf.reverse_sequence(x, [width] * height, 1, batch_dim=0)
session.run(model)
result = session.run(x)
print(result.shape)
plt.imshow(result)
plt.show()
```
新東西是這一行:
```py
x = tf.reverse_sequence(x, np.ones((height,)) * width, 1, batch_dim=0)
```
它從上到下(沿著它的高度)迭代圖像,并從左到右(沿著它的寬度)切片。 從這里開始,它選取大小為`width`的切片,其中`width`是圖像的寬度。
> 譯者注:
>
> 還有兩個函數用于實現切片操作。一個是[`tf.reverse`](https://tensorflow.google.cn/api_docs/python/tf/manip/reverse),另一個是張量的下標和切片運算符(和 NumPy 用法一樣)。
代碼`np.ones((height,)) * width`創建一個填充值`width`的 NumPy 數組。 這不是很有效! 不幸的是,在編寫本文時,似乎此函數不允許你僅指定單個值。
“翻轉”操作的結果:

1)將轉置與翻轉代碼組合來順時針旋轉。
2)目前,翻轉代碼(使用`reverse_sequence`)需要預先計算寬度。 查看`tf.shape`函數的文檔,并使用它在會話中計算`x`變量的寬度。
3)執行“翻轉”,從上到下翻轉圖像。
4)計算“鏡像”,復制圖像的前半部分,(左右)翻轉然后復制到后半部分。
## 占位符
到目前為止,我們已經使用`Variables`來管理我們的數據,但是有一個更基本的結構,即占位符。 占位符只是一個變量,我們將在以后向它分配數據。 它允許我們創建我們的操作,并構建我們的計算圖,而不需要數據。 在 TensorFlow 術語中,我們隨后通過這些占位符,將數據提供給圖。
```py
import tensorflow as tf
x = tf.placeholder("float", None)
y = x * 2
with tf.Session() as session:
result = session.run(y, feed_dict={x: [1, 2, 3]})
print(result)
```
這個例子與我們之前的例子略有不同,讓我們分解它。
首先,我們正常導入`tensorflow`。然后我們創建一個名為`x`的`placeholder`,即我們稍后將存儲值的內存中的位置。
然后,我們創建一個`Tensor`,它是`x`乘以 2 的運算。注意我們還沒有為`x`定義任何初始值。
我們現在定義了一個操作(`y`),現在可以在會話中運行它。我們創建一個會話對象,然后只運行`y`變量。請注意,這意味著,如果我們定義了更大的操作圖,我們只能運行圖的一小部分。這個子圖求值實際上是 TensorFlow 的一個賣點,而且許多其他類似的東西都沒有。
運行`y`需要了解`x`的值。我們在`feed_dict`參數中定義這些來運行。我們在這里聲明`x`的值是`[1,2,3]`。我們運行`y`,給了我們結果`[2,4,6]`。
占位符不需要靜態大小。讓我們更新我們的程序,讓`x`可以接受任何長度。將`x`的定義更改為:
```py
x = tf.placeholder("float", None)
```
現在,當我們在`feed_dict`中定義`x`的值時,我們可以有任意維度的值。 代碼應該仍然有效,并給出相同的答案,但現在它也可以處理`feed_dict`中的任意維度的值。
占位符也可以有多個維度,允許存儲數組。 在下面的示例中,我們創建一個 3 乘 2 的矩陣,并在其中存儲一些數字。 然后,我們使用與以前相同的操作,來逐元素加倍數字。
```py
import tensorflow as tf
x = tf.placeholder("float", [None, 3])
y = x * 2
with tf.Session() as session:
x_data = [[1, 2, 3],
[4, 5, 6],]
result = session.run(y, feed_dict={x: x_data})
print(result)
```
占位符的第一個維度是`None`,這意味著我們可以有任意數量的行。 第二個維度固定為 3,這意味著每行需要有三列數據。
我們可以擴展它來接受任意數量的`None`維度。 在此示例中,我們加載來自上一課的圖像,然后創建一個存儲該圖像切片的占位符。 切片是圖像的 2D 片段,但每個“像素”具有三個分量(紅色,綠色,藍色)。 因此,對于前兩個維度,我們需要`None`,但是對于最后一個維度,需要 3(或`None`也能用)。 然后,我們使用 TensorFlow 的切片方法從圖像中取出一個子片段來操作。
```py
import tensorflow as tf
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import os
# First, load the image again
dir_path = os.path.dirname(os.path.realpath(__file__))
filename = dir_path + "/MarshOrchid.jpg"
raw_image_data = mpimg.imread(filename)
image = tf.placeholder("uint8", [None, None, 3])
slice = tf.slice(image, [1000, 0, 0], [3000, -1, -1])
with tf.Session() as session:
result = session.run(slice, feed_dict={image: raw_image_data})
print(result.shape)
plt.imshow(result)
plt.show()
```
> 譯者注:使用下標和切片運算符也可以實現切片。
結果是圖像的子片段:
1)在官方文檔中查看 TensorFlow 中的[其他數組函數](https://www.tensorflow.com/versions/master/api_docs/python/array_ops.html#slicing-and-joining)。
2)將圖像分成四個“角”,然后再將它拼在一起。
3)將圖像轉換為灰度。 一種方法是只采用一個顏色通道并顯示。 另一種方法是將三個通道的平均值作為灰色。
## 交互式會話
現在我們有了一些例子,讓我們更仔細地看看發生了什么。
正如我們之前已經確定的那樣,TensorFlow 允許我們創建操作和變量圖。這些變量稱為張量,表示數據,無論是單個數字,字符串,矩陣還是其他內容。張量通過操作來組合,整個過程以圖來建模。
首先,確保激活了`tensorenv`虛擬環境,一旦激活,請輸入`conda install jupyter`來安裝`jupter books`。
然后,運行`jupyter notebook`以啟動 Jupyter Notebook(以前稱為 IPython Notebook)的瀏覽器會話。 (如果你的瀏覽器沒有打開,請打開它并在瀏覽器的地址欄中輸入`localhost:8888`。)
單擊`New`(新建),然后單擊`Notebooks`(筆記本)下的`Python 3`(Python 3)。這將啟動一個新的瀏覽器選項卡。通過單擊頂部的`Untitled`(無標題)為該筆記本命名,并為其命名(我使用`Interactive TensorFlow`)。
> 如果你以前從未使用過 Jupyter 筆記本(或 IPython 筆記本),請查看[此站點](http://opentechschool.github.io/python-data-intro/core/notebook.html)來獲得簡介。
接下來,和以前一樣,讓我們創建一個基本的 TensorFlow 程序。 一個主要的變化是使用`InteractiveSession`,它允許我們運行變量,而不需要經常引用會話對象(減少輸入!)。 下面的代碼塊分為不同的單元格。 如果你看到代碼中斷,則需要先運行上一個單元格。 此外,如果你不自信,請確保在運行之前將給定塊中的所有代碼鍵入單元格。
```py
import tensorflow as tf
session = tf.InteractiveSession()
x = tf.constant(list(range(10)))
```
在這段代碼中,我們創建了一個`InteractiveSession`,然后定義一個常量值,就像一個占位符,但具有設置的值(不會改變)。 在下一個單元格中,我們可以求解此常量并打印結果。
```py
print(x.eval())
```
下面我們關閉打開的會話。
```py
session.close()
```
關閉會話非常重要,并且很容易忘記。 出于這個原因,我們在之前的教程中使用`with`關鍵字來處理這個問題。 當`with`塊完成執行時,會話將被關閉(如果發生錯誤也會發生這種情況 - 會話仍然關閉)。
現在讓我們來看更大的例子。 在這個例子中,我們將使用一個非常大的矩陣并對其進行計算,跟蹤何時使用內存。 首先,讓我們看看我們的 Python 會話當前使用了多少內存:
```py
import resource
print("{} Kb".format(resource.getrusage(resource.RUSAGE_SELF).ru_maxrss))
```
在我的系統上,運行上面的代碼之后,使用了 78496 千字節。 現在,創建一個新會話,并定義兩個矩陣:
```py
import numpy as np
session = tf.InteractiveSession()
X = tf.constant(np.eye(10000))
Y = tf.constant(np.random.randn(10000, 300))
```
讓我們再看一下我們的內存使用情況:
```py
print("{} Kb".format(resource.getrusage(resource.RUSAGE_SELF).ru_maxrss))
```
在我的系統上,內存使用率躍升至 885,220 Kb - 那些矩陣很大!
現在,讓我們使用`matmul`將這些矩陣相乘:
```py
Z = tf.matmul(X, Y)
```
如果我們現在檢查我們的內存使用情況,我們發現沒有使用更多的內存 - 沒有實際的`Z`的計算。 只有當我們求解操作時,我們才真正計算。 對于交互式會話,你可以使用`Z.eval()`,而不是運行`session.run(Z)`。 請注意,你不能總是依賴`.eval()`,因為這是使用“默認”會話的快捷方式,不一定是你要使用的會話。
如果你的計算機比較低級(例如,ram 低于 3Gb),那么不要運行此代碼 - 相信我!
```py
Z.eval()
```
你的計算機會考慮很長一段時間,因為現在它才實際執行這些矩陣相乘。 之后檢查內存使用情況會發現此計算已經發生,因為它現在使用了接近 3Gb!
```py
print("{} Kb".format(resource.getrusage(resource.RUSAGE_SELF).ru_maxrss))
```
別忘了關閉你的會話!
```py
session.close()
```
注意:我建議使用新的 Jupyter Notebook,因為上面的示例代碼可能會被意外再次執行,可能導致計算機崩潰!
1)創建一個整數值的大矩陣(至少 10,000,000)(例如,使用 NumPy 的`randint`函數)。 創建矩陣后檢查內存使用情況。 然后,使用 TensorFlow 的`to_float`函數將矩陣轉換為浮點值。 再次檢查內存使用情況,看到內存使用量增加超過兩倍。 “加倍”是由創建矩陣的副本引起的,但是“額外增加”的原因是什么? 執行此實驗后,你可以使用此代碼顯示圖像。
```py
from PIL import Image
from io import BytesIO
# 從字符串讀取數據
im = Image.open(BytesIO(result))
im
```
> 提示:確保在每一步之后仔細測量內存使用情況,因為只是導入 TensorFlow 就會使用相當多的內存。
2)使用 TensorFlow 的圖像函數將上一個教程中的圖像(或其他圖像)轉換為 JPEG 并記錄內存使用情況。
## 可視化
在本課中,我們將介紹如何使用 TensorBoard 創建和可視化圖。 我們在第一課變量中簡要地瀏覽了 TensorBoard
那么什么是 TensorBoard 以及我們為什么要使用它呢?
TensorBoard 是一套 Web 應用程序,用于檢查和理解你的 TensorFlow 運行和圖。 TensorBoard 目前支持五種可視化:標量,圖像,音頻,直方圖和圖。 你將在 TensorFlow 中的計算用于訓練大型深度神經網絡,可能相當復雜且令人困惑,TensorBoard 將使你更容易理解,調試和優化 TensorFlow 程序。
要實際查看 TensorBoard,請單擊[此處](https://www.tensorflow.org/get_started/graph_viz)。
這就是 TensorBoard 圖的樣子:
## 基本的腳本
下面我們有了構建 TensorBoard 圖的基本腳本。 現在,如果你在 python 解釋器中運行它,會返回 63。
```py
import tensorflow as tf
a = tf.add(1, 2,)
b = tf.multiply(a, 3)
c = tf.add(4, 5,)
d = tf.multiply(c, 6,)
e = tf.multiply(4, 5,)
f = tf.div(c, 6,)
g = tf.add(b, d)
h = tf.multiply(g, f)
with tf.Session() as sess:
print(sess.run(h))
```
現在我們在代碼末尾添加一個`SummaryWriter`,這將在給定目錄中創建一個文件夾,其中包含 TensorBoard 用于構建圖的信息。
```py
with tf.Session() as sess:
writer = tf.summary.FileWriter("output", sess.graph)
print(sess.run(h))
writer.close()
```
如果你現在運行 TensorBoard,使用`tensorboard --logdir=path/to/logs/directory`,你會看到在你給定的目錄中,你得到一個名為`output`的文件夾。 如果你在終端中訪問 IP 地址,它將帶你到 TensorBoard,然后如果你點擊圖,你將看到你的圖。
在這一點上,圖遍布各處,并且相當難以閱讀。 因此,請命名一些部分來其更更加可讀。
## 添加名稱
在下面的代碼中,我們只添加了`parameter`幾次。`name=[something]`。 這個`parameter`將接受所選區域并在圖形上為其命名。
```py
a = tf.add(1, 2, name="Add_these_numbers")
b = tf.multiply(a, 3)
c = tf.add(4, 5, name="And_These_ones")
d = tf.multiply(c, 6, name="Multiply_these_numbers")
e = tf.multiply(4, 5, name="B_add")
f = tf.div(c, 6, name="B_mul")
g = tf.add(b, d)
h = tf.multiply(g, f)
```
現在,如果你重新運行 python 文件,然后再次運行`tensorboard --logdir=path/to/logs/directory`,你現在將看到,在你命名的特定部分上,你的圖有了一些名稱。 然而,它仍然非常混亂,如果這是一個巨大的神經網絡,它幾乎是不可讀的。
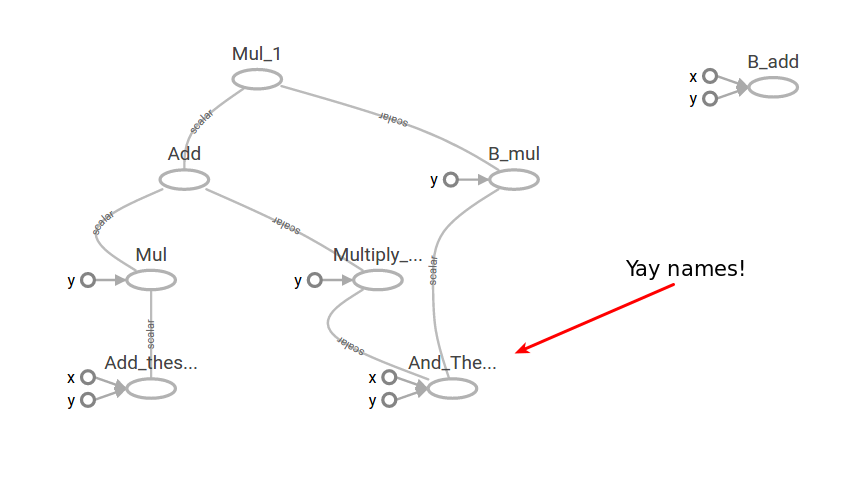
## 創建作用域
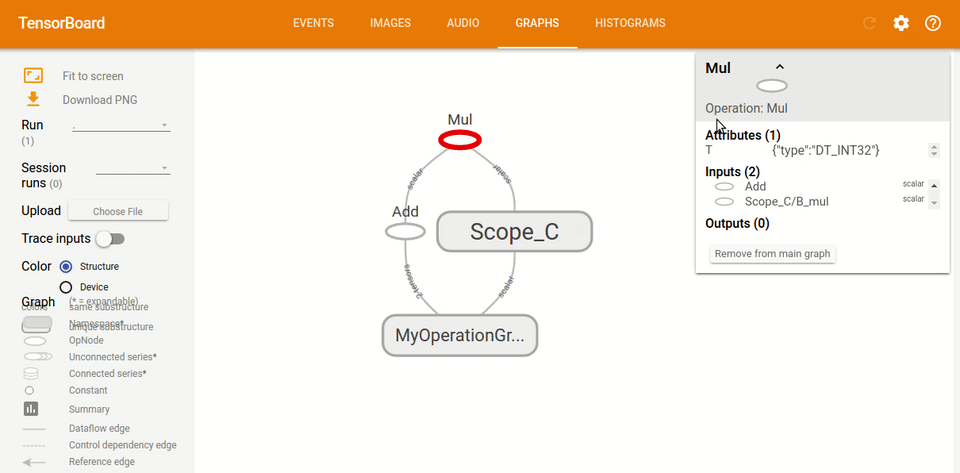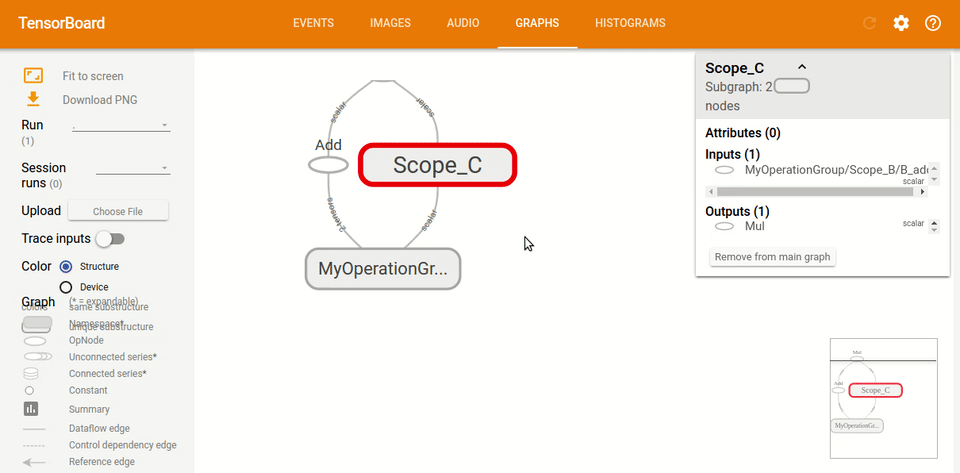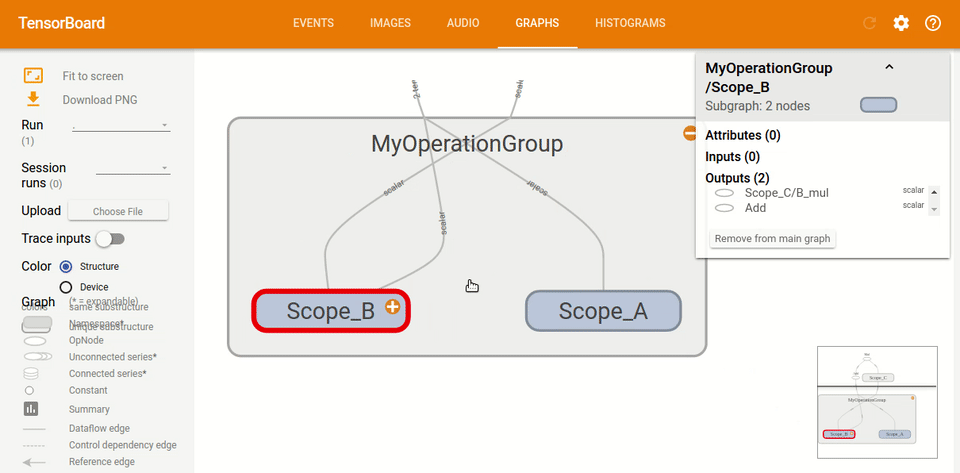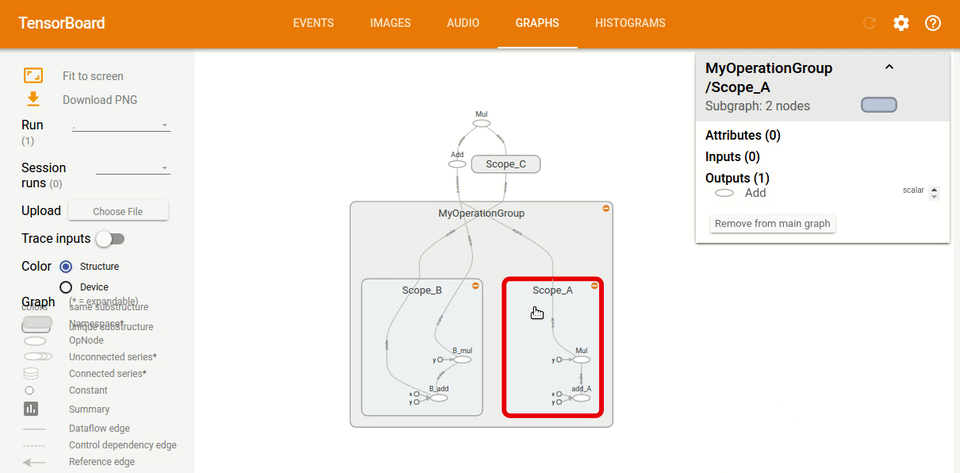
如果我們通過鍵入`tf.name_scope("MyOperationGroup"):`給圖命名:并使用`with tf.name_scope("Scope_A"):`給圖這樣的作用域,當你重新運行你的 TensorBoard 時,你會看到一些非常不同的東西。 圖現在更容易閱讀,你可以看到它都在圖的標題下,這里是`MyOperationGroup`,然后你有你的作用域`A`和`B`,其中有操作。
```py
# 這里我們定義圖的名稱,作用域 A,B 和 C。
with tf.name_scope("MyOperationGroup"):
with tf.name_scope("Scope_A"):
a = tf.add(1, 2, name="Add_these_numbers")
b = tf.multiply(a, 3)
with tf.name_scope("Scope_B"):
c = tf.add(4, 5, name="And_These_ones")
d = tf.multiply(c, 6, name="Multiply_these_numbers")
with tf.name_scope("Scope_C"):
e = tf.multiply(4, 5, name="B_add")
f = tf.div(c, 6, name="B_mul")
g = tf.add(b, d)
h = tf.multiply(g, f)
```
如你所見,圖現在更容易閱讀。
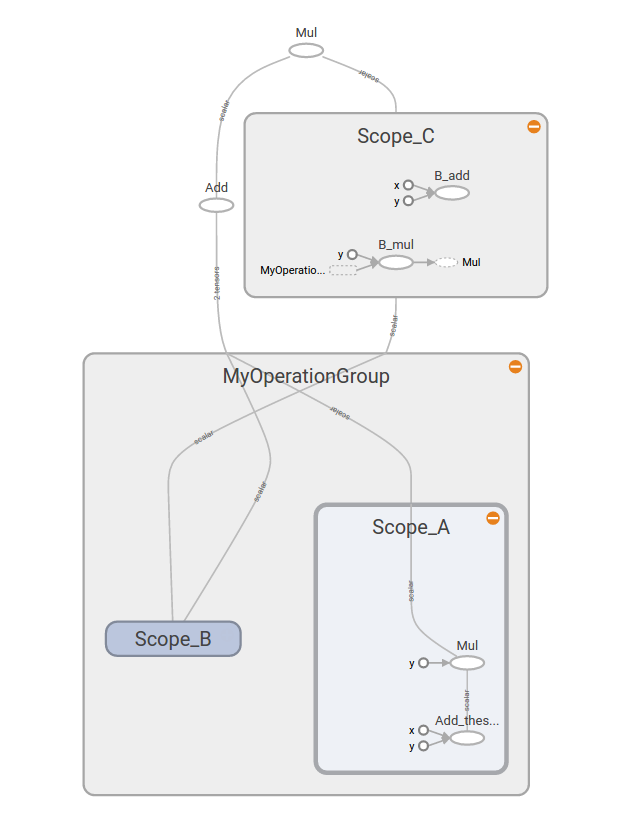
TensorBoard 具有廣泛的功能,其中一些我們將在未來的課程中介紹。 如果你想深入了解,請先觀看 [2017 年 TensorFlow 開發者大會的視頻](https://www.youtube.com/embed/eBbEDRsCmv4?list=PLOU2XLYxmsIKGc_NBoIhTn2Qhraji53cv)。
在本課中,我們研究了:
+ TensorBoard 圖的基本布局
+ 添加摘要編寫器來構建 TensorBoard
+ 將名稱添加到 TensorBoard 圖
+ 將名稱和作用域添加到 TensorBoard
有一個很棒的第三方工具叫做 TensorDebugger(TDB),TBD 就像它所謂的調試器一樣。 但是與 TensorBoard 中內置的標準調試器不同,TBD 直接與 TensorFlow 圖的執行交互,并允許一次執行一個節點。 由于標準 TensorBoard 調試器不能在運行 TensorFlow 圖時同時使用,因此必須先寫日志文件。
+ 從[這里](https://github.com/ericjang/tdb)安裝 TBD 并閱讀材料(試試 Demo!)。
+ 將 TBD 與此梯度下降代碼一起使用,繪制一個圖表,通過結果顯示調試器的工作,并打印預測模型。 (注意:這僅僅與 2.7 兼容)
```py
import tensorflow as tf
import numpy as np
# x 和 y 是我們的訓練數據的占位符
x = tf.placeholder("float")
y = tf.placeholder("float")
# w 是存儲我們的值的變量。 它使用“猜測”來初始化
# w[0] 是我們方程中的“a”,w[1] 是“b”
w = tf.Variable([1.0, 2.0], name="w")
# 我們的模型是 y = a*x + b
y_model = tf.multiply(x, w[0]) + w[1]
# 我們的誤差定義為差異的平方
error = tf.square(y - y_model)
# GradientDescentOptimizer 完成繁重的工作
train_op = tf.train.GradientDescentOptimizer(0.01).minimize(error)
# TensorFlow 常規 - 初始化值,創建會話并運行模型
model = tf.global_variables_initializer()
with tf.Session() as session:
session.run(model)
for i in range(1000):
x_value = np.random.rand()
y_value = x_value * 2 + 6
session.run(train_op, feed_dict={x: x_value, y: y_value})
w_value = session.run(w)
print("Predicted model: {a:.3f}x + {b:.3f}".format(a=w_value[0], b=w_value[1]))
```
這些特殊圖標用于常量和摘要節點。

## 讀取文件
TensorFlow 支持讀取更大的數據集,特別是這樣,數據永遠不能一次全部保存在內存中(如果有這個限制則不會非常有用)。 你可以使用一些函數和選項,從標準 Python 一直到特定的操作。
TensorFlow 還支持編寫自定義數據處理程序,如果你有一個包含大量數據的非常大的項目,這是值得研究的。 編寫自定義數據加載是前期的一點努力,但以后可以節省大量時間。 此主題的更多信息,請查看[此處](https://www.tensorflow.org/versions/r0.11/how_tos/new_data_formats/index.html)的官方文檔。
在本課程中,我們將介紹使用 TensorFlow 讀取 CSV 文件,以及在圖中使用數據的基礎知識。
### 占位符
讀取數據的最基本方法是使用標準 python 代碼讀取它。 讓我們來看一個基本的例子,從這個 [2016 年奧運會獎牌統計數據](https://pastebin.com/bPBrr46B)中讀取數據。
首先,我們創建我們的圖,它接受一行數據,并累計總獎牌。
```py
import tensorflow as tf
import os
dir_path = os.path.dirname(os.path.realpath(__file__))
filename = dir_path + "/olympics2016.csv"
features = tf.placeholder(tf.int32, shape=[3], name='features')
country = tf.placeholder(tf.string, name='country')
total = tf.reduce_sum(features, name='total')
```
接下來,我將介紹一個名為`Print`的新操作,它打印出圖形上某些節點的當前值。 它是一個單位元素,這意味著它將操作作為輸入,只返回與輸出相同的值。
```py
printerop = tf.Print(total, [country, features, total], name='printer')
```
當你求解打印操作時會發生什么? 它基本上將當前值記錄在第二個參數中(在本例中為列表`[country, features, total]`)并返回第一個值(`total`)。 但它被認為是一個變量,因此我們需要在啟動會話時初始化所有變量。
接下來,我們啟動會話,然后打開文件來讀取。 請注意,文件讀取完全是在 python 中完成的 - 我們只是在執行圖形的同時讀取它。
```py
with tf.Session() as sess:
sess.run( tf.global_variables_initializer())
with open(filename) as inf:
# 跳過標題
next(inf)
for line in inf:
# 使用 python 將數據讀入我們的特征
country_name, code, gold, silver, bronze, total = line.strip().split(",")
gold = int(gold)
silver = int(silver)
bronze = int(bronze)
# 運行打印操作
total = sess.run(printerop, feed_dict={features: [gold, silver, bronze], country:country_name})
print(country_name, total)
```
在循環的內部部分,我們讀取文件的一行,用逗號分割,將值轉換為整數,然后將數據作為占位符值提供給`feed_dict`。 如果你不確定這里發生了什么,請查看之前的占位符教程。
當你運行它時,你會在每一行看到兩個輸出。 第一個輸出將是打印操作的結果,看起來有點像這樣:
```
I tensorflow/core/kernels/logging_ops.cc:79] [\"France\"][10 18 14][42]
```
下一個輸出將是`print(country_name, total)`行的結果,該行打印當前國家/地區名稱(python 變量)和運行打印操作的結果。 由于打印操作是一個單位函數,因此調用它的結果只是求值`total`的結果,這會將金,銀和銅的數量相加。
它通常以類似的方式工作得很好。 創建占位符,將一些數據加載到內存中,計算它,然后循環使用新數據。 畢竟,這是占位符的用途。
### 讀取 CSV
TensorFlow 支持將數據直接讀入張量,但格式有點笨重。 我將通過一種方式逐步完成此操作,但我選擇了一種特殊的通用方法,我希望你可以將它用于你自己的項目。
步驟是創建要讀取的文件名的隊列(列表),然后創建稍后將執行讀取的讀取器操作。 從這個閱讀器操作中,創建在圖執行階段執行時用實際值替換的變量。
讓我們來看看該過程的最后幾個步驟:
```py
def create_file_reader_ops(filename_queue):
reader = tf.TextLineReader(skip_header_lines=1)
_, csv_row = reader.read(filename_queue)
record_defaults = [[""], [""], [0], [0], [0], [0]]
country, code, gold, silver, bronze, total = tf.decode_csv(csv_row, record_defaults=record_defaults)
features = tf.pack([gold, silver, bronze])
return features, country
```
這里的讀取器在技術上采用隊列對象,而不是普通的 Python 列表,所以我們需要在將它傳遞給函數之前構建一個:
```py
filename_queue = tf.train.string_input_producer(filenames, num_epochs=1, shuffle=False)
example, country = create_file_reader_ops(filename_queue)
```
由該函數調用產生的那些操作,稍后將表示來自我們的數據集的單個條目。 運行這些需要比平常更多的工作。 原因是隊列本身不像正常操作那樣位于圖上,因此我們需要一個`Coordinator`來管理隊列中的運行。 每次求值示例和標簽時,此協調器將在數據集中遞增,因為它們有效地從文件中提取數據。
```py
with tf.Session() as sess:
tf.global_variables_initializer().run()
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
while True:
try:
example_data, country_name = sess.run([example, country])
print(example_data, country_name)
except tf.errors.OutOfRangeError:
break
```
內部`while`循環保持循環,直到我們遇到`OutOfRangeError`,表明沒有更多數據要還原。
有了這段代碼,我們現在從數據集中一次得到一行,直接加載到我們的圖形中。 還有其他用于創建批量和打亂的功能 - 如果你想了解這些參數的更多信息,請查看`tf.train.string_input_producer`和`tf.train.shuffle_batch`中的一些參數。
在本課中,我們研究了:
+ 在執行 TensorFlow 圖時使用 Python 讀取數據
+ `tf.Print`操作
+ 將數據直接讀入 TensorFlow 圖/變量
+ 隊列對象
+ 更新第二個示例的代碼(直接將文件讀入 TensorFlow),使用與 python-version 相同的方式輸出總和(即打印出來并使用`tf.Print`)
+ 在`create_file_reader_ops`中解包特征操作,即不執行`tf.pack`行。 更改代碼的其余部分來滿足一下情況,特征作為三個單獨的特征返回,而不是單個打包的特征。 需要改變什么?
+ 將數據文件拆分為幾個不同的文件(可以使用文本編輯器完成)并更新隊列來全部讀取它們。
+ 使用`tf.train.shuffle_batch`將多行合成一個變量。 這對于較大的數據集比逐行讀取更有用。
對于問題4,一個好的目標是在一個批量中加載盡可能多的數據,但不要太多以至于它會使計算機的 RAM 過載。 這對于這個數據集無關緊要,但以后請記住。
另外,使用批量時不會返回所有數據 - 如果批量未滿,則不會返回。
## 遷移到 AWS
在很多情況下,運行代碼可能非常耗時,特別是如果你正在運行機器學習或神經網絡。除非你在計算機上花費了大量資金,否則轉向基于云的服務可能是最好的方法。
在本教程中,我們將采用一些 Tensorflow 代碼并將其移至 Amazon Web 服務(AWS)彈性計算云實例(EC2)。
亞馬遜網絡服務(AWS)是一個安全的云服務平臺,提供計算能力,數據庫存儲,內容交付和其他功能,來幫助企業擴展和發展。此外,亞馬遜彈性計算云(Amazon EC2)是一種 Web 服務,可在云中提供可調整大小的計算能力。它旨在使 Web 級云計算對開發人員更輕松。
這樣做的好處是,亞馬遜擁有大量基于云的服務器,其背后有很多功能。這將允許你在網絡上運行代碼的時間,只有你能夠從本地計算機運行代碼的一半。這也意味著如果它是一個需要 5-8 個小時才能完成的大型文件,你可以在 EC2 實例上運行它,并將其保留在后臺而不使用你的整個計算機資源。
> 創建一個 EC2 環境會花費你的錢,但它是一個非常少,8 小時可能大約 4.00 美元。 一旦你停止使用它,將不會收取你的費用。請訪問[此鏈接](https://aws.amazon.com/ec2/pricing/)來查看價格。
### 創建 EC2 實例
首先,訪問 [AWS 控制臺](https://console.aws.amazon.com/console/home?region=us-east-1)。
使用你的亞馬遜帳戶登錄。如果你沒有,則會提示你創建一個,你需要執行此操作才能繼續。
接下來,請訪問 [EC2 服務控制臺](https://console.aws.amazon.com/ec2/v2/home?region=us-east-1)。
單擊`Launch Instance`并在右上角的下拉菜單中選擇你的地區(例如`sydney, N california`)作為你的位置。
接下來轉到社區 AMI 并搜索 Ubuntu x64 AMI 和 TensorFlow(GPU),它已準備好通過 GPU 運行代碼,但它也足以在其上運行基本或大型 Tensorflow 腳本,而且優勢是 Tensorflow 已安裝。
> 此時,將向你收取費用,因此請務必在完成后關閉機器。 你可以轉到 EC2 服務,選擇機器并停止它。 你不需要為未運行的機器付費。
系統將提示你如何連接到實例的一些信息。 如果你之前未使用過 AWS,則可能需要創建一個新密鑰對才能安全地連接到你的實例。 在這種情況下,為你的密鑰對命名,下載 pemfile,并將其存儲在安全的地方 - 如果丟失,你將無法再次連接到你的實例!
單擊“連接”來獲取使用 pem 文件連接到實例的信息。 最可能的情況是你將使用以下命令來使用`ssh`:
```
ssh -i <certificante_name>.pem ubuntu@<server_ip_address>
```
### 將你的代碼移動到 AWS EC2
我們將使用以下示例繼續我們的 EC2 實例,這來自前面的章節:
```py
import tensorflow as tf
import numpy as np
# x 和 y 是我們的訓練數據的占位符
x = tf.placeholder("float")
y = tf.placeholder("float")
# w 是存儲我們的值的變量。 它使用“猜測”來初始化
# w[0] 是我們方程中的“a”,w[1] 是“b”
w = tf.Variable([1.0, 2.0], name="w")
# 我們的模型是 y = a*x + b
y_model = tf.multiply(x, w[0]) + w[1]
# 我們的誤差定義為差異的平方
error = tf.square(y - y_model)
# GradientDescentOptimizer 完成繁重的工作
train_op = tf.train.GradientDescentOptimizer(0.01).minimize(error)
# TensorFlow 常規 - 初始化值,創建會話并運行模型
model = tf.global_variables_initializer()
with tf.Session() as session:
session.run(model)
for i in range(1000):
x_value = np.random.rand()
y_value = x_value * 2 + 6
session.run(train_op, feed_dict={x: x_value, y: y_value})
w_value = session.run(w)
print("Predicted model: {a:.3f}x + {b:.3f}".format(a=w_value[0], b=w_value[1]))
```
有很多方法可以將此文件放到EC2實例上,但最簡單的方法之一就是復制并粘貼內容。
首先,按`Ctrl + A`高亮以上所有代碼,然后使用`Ctrl + C`復制所有代碼
在 Amazon 虛擬機上,移動到主目錄并使用新文件名打開`nano`,我們將在此示例中調用`basic.py `(以下是終端命令):
```
$ cd~/
$ nano <nameofscript>.py
```
`nano`程序將打開,這是一個命令行文本編輯器。
打開此程序后,將剪貼板的內容粘貼到此文件中。 在某些系統上,你可能需要使用`ssh`程序的文件選項,而不是按`Ctrl + V`進行粘貼。 在`nano`中,按`Ctrl + O`將文件保存在磁盤上,我們將其命名為`basic.py`,然后按`Ctrl + X`退出程序。
一旦你退出`nano`,輸入`python basic.py`就可以了!
你現在應該看到終端中彈出代碼的結果,因為你很可能會發現,這可能是一種執行大型數據程序的更好方法。
Facenet 是一款利用 Tensorflow 的人臉識別程序,它提供了預先訓練的模型,供你下載和運行來查看其工作原理。
1)訪問此鏈接并下載預先訓練的人臉識別模型
2)使用上面的教程,將代碼上傳到 EC2 實例并使其運行。
- TensorFlow 1.x 深度學習秘籍
- 零、前言
- 一、TensorFlow 簡介
- 二、回歸
- 三、神經網絡:感知器
- 四、卷積神經網絡
- 五、高級卷積神經網絡
- 六、循環神經網絡
- 七、無監督學習
- 八、自編碼器
- 九、強化學習
- 十、移動計算
- 十一、生成模型和 CapsNet
- 十二、分布式 TensorFlow 和云深度學習
- 十三、AutoML 和學習如何學習(元學習)
- 十四、TensorFlow 處理單元
- 使用 TensorFlow 構建機器學習項目中文版
- 一、探索和轉換數據
- 二、聚類
- 三、線性回歸
- 四、邏輯回歸
- 五、簡單的前饋神經網絡
- 六、卷積神經網絡
- 七、循環神經網絡和 LSTM
- 八、深度神經網絡
- 九、大規模運行模型 -- GPU 和服務
- 十、庫安裝和其他提示
- TensorFlow 深度學習中文第二版
- 一、人工神經網絡
- 二、TensorFlow v1.6 的新功能是什么?
- 三、實現前饋神經網絡
- 四、CNN 實戰
- 五、使用 TensorFlow 實現自編碼器
- 六、RNN 和梯度消失或爆炸問題
- 七、TensorFlow GPU 配置
- 八、TFLearn
- 九、使用協同過濾的電影推薦
- 十、OpenAI Gym
- TensorFlow 深度學習實戰指南中文版
- 一、入門
- 二、深度神經網絡
- 三、卷積神經網絡
- 四、循環神經網絡介紹
- 五、總結
- 精通 TensorFlow 1.x
- 一、TensorFlow 101
- 二、TensorFlow 的高級庫
- 三、Keras 101
- 四、TensorFlow 中的經典機器學習
- 五、TensorFlow 和 Keras 中的神經網絡和 MLP
- 六、TensorFlow 和 Keras 中的 RNN
- 七、TensorFlow 和 Keras 中的用于時間序列數據的 RNN
- 八、TensorFlow 和 Keras 中的用于文本數據的 RNN
- 九、TensorFlow 和 Keras 中的 CNN
- 十、TensorFlow 和 Keras 中的自編碼器
- 十一、TF 服務:生產中的 TensorFlow 模型
- 十二、遷移學習和預訓練模型
- 十三、深度強化學習
- 十四、生成對抗網絡
- 十五、TensorFlow 集群的分布式模型
- 十六、移動和嵌入式平臺上的 TensorFlow 模型
- 十七、R 中的 TensorFlow 和 Keras
- 十八、調試 TensorFlow 模型
- 十九、張量處理單元
- TensorFlow 機器學習秘籍中文第二版
- 一、TensorFlow 入門
- 二、TensorFlow 的方式
- 三、線性回歸
- 四、支持向量機
- 五、最近鄰方法
- 六、神經網絡
- 七、自然語言處理
- 八、卷積神經網絡
- 九、循環神經網絡
- 十、將 TensorFlow 投入生產
- 十一、更多 TensorFlow
- 與 TensorFlow 的初次接觸
- 前言
- 1.?TensorFlow 基礎知識
- 2. TensorFlow 中的線性回歸
- 3. TensorFlow 中的聚類
- 4. TensorFlow 中的單層神經網絡
- 5. TensorFlow 中的多層神經網絡
- 6. 并行
- 后記
- TensorFlow 學習指南
- 一、基礎
- 二、線性模型
- 三、學習
- 四、分布式
- TensorFlow Rager 教程
- 一、如何使用 TensorFlow Eager 構建簡單的神經網絡
- 二、在 Eager 模式中使用指標
- 三、如何保存和恢復訓練模型
- 四、文本序列到 TFRecords
- 五、如何將原始圖片數據轉換為 TFRecords
- 六、如何使用 TensorFlow Eager 從 TFRecords 批量讀取數據
- 七、使用 TensorFlow Eager 構建用于情感識別的卷積神經網絡(CNN)
- 八、用于 TensorFlow Eager 序列分類的動態循壞神經網絡
- 九、用于 TensorFlow Eager 時間序列回歸的遞歸神經網絡
- TensorFlow 高效編程
- 圖嵌入綜述:問題,技術與應用
- 一、引言
- 三、圖嵌入的問題設定
- 四、圖嵌入技術
- 基于邊重構的優化問題
- 應用
- 基于深度學習的推薦系統:綜述和新視角
- 引言
- 基于深度學習的推薦:最先進的技術
- 基于卷積神經網絡的推薦
- 關于卷積神經網絡我們理解了什么
- 第1章概論
- 第2章多層網絡
- 2.1.4生成對抗網絡
- 2.2.1最近ConvNets演變中的關鍵架構
- 2.2.2走向ConvNet不變性
- 2.3時空卷積網絡
- 第3章了解ConvNets構建塊
- 3.2整改
- 3.3規范化
- 3.4匯集
- 第四章現狀
- 4.2打開問題
- 參考
- 機器學習超級復習筆記
- Python 遷移學習實用指南
- 零、前言
- 一、機器學習基礎
- 二、深度學習基礎
- 三、了解深度學習架構
- 四、遷移學習基礎
- 五、釋放遷移學習的力量
- 六、圖像識別與分類
- 七、文本文件分類
- 八、音頻事件識別與分類
- 九、DeepDream
- 十、自動圖像字幕生成器
- 十一、圖像著色
- 面向計算機視覺的深度學習
- 零、前言
- 一、入門
- 二、圖像分類
- 三、圖像檢索
- 四、對象檢測
- 五、語義分割
- 六、相似性學習
- 七、圖像字幕
- 八、生成模型
- 九、視頻分類
- 十、部署
- 深度學習快速參考
- 零、前言
- 一、深度學習的基礎
- 二、使用深度學習解決回歸問題
- 三、使用 TensorBoard 監控網絡訓練
- 四、使用深度學習解決二分類問題
- 五、使用 Keras 解決多分類問題
- 六、超參數優化
- 七、從頭開始訓練 CNN
- 八、將預訓練的 CNN 用于遷移學習
- 九、從頭開始訓練 RNN
- 十、使用詞嵌入從頭開始訓練 LSTM
- 十一、訓練 Seq2Seq 模型
- 十二、深度強化學習
- 十三、生成對抗網絡
- TensorFlow 2.0 快速入門指南
- 零、前言
- 第 1 部分:TensorFlow 2.00 Alpha 簡介
- 一、TensorFlow 2 簡介
- 二、Keras:TensorFlow 2 的高級 API
- 三、TensorFlow 2 和 ANN 技術
- 第 2 部分:TensorFlow 2.00 Alpha 中的監督和無監督學習
- 四、TensorFlow 2 和監督機器學習
- 五、TensorFlow 2 和無監督學習
- 第 3 部分:TensorFlow 2.00 Alpha 的神經網絡應用
- 六、使用 TensorFlow 2 識別圖像
- 七、TensorFlow 2 和神經風格遷移
- 八、TensorFlow 2 和循環神經網絡
- 九、TensorFlow 估計器和 TensorFlow HUB
- 十、從 tf1.12 轉換為 tf2
- TensorFlow 入門
- 零、前言
- 一、TensorFlow 基本概念
- 二、TensorFlow 數學運算
- 三、機器學習入門
- 四、神經網絡簡介
- 五、深度學習
- 六、TensorFlow GPU 編程和服務
- TensorFlow 卷積神經網絡實用指南
- 零、前言
- 一、TensorFlow 的設置和介紹
- 二、深度學習和卷積神經網絡
- 三、TensorFlow 中的圖像分類
- 四、目標檢測與分割
- 五、VGG,Inception,ResNet 和 MobileNets
- 六、自編碼器,變分自編碼器和生成對抗網絡
- 七、遷移學習
- 八、機器學習最佳實踐和故障排除
- 九、大規模訓練
- 十、參考文獻