
# 八、TFLearn
TFLearn 是一個庫,它使用漂亮且熟悉的 scikit-learn API 包裝了許多新的 TensorFlow API。
TensorFlow 是關于構建和執行圖的全部內容。這是一個非常強大的概念,但從一開始就很麻煩。
在 TFLearn 的引擎蓋下,我們只使用了三個部分:
* 層:一組高級 TensorFlow 函數,允許我們輕松構建復雜的圖,從完全連接的層,卷積和批量規范到損失和優化。
* `graph_actions`:一組工具,用于對 TensorFlow 圖進行訓練,評估和運行推理。
* 估計器:將所有內容打包成一個遵循 scikit-learn 接口的類,并提供了一種輕松構建和訓練自定義 TensorFlow 模型的方法。
## 安裝
要安裝 TFLearn, 最簡單的方法是運行以下命令:
```py
pip install git+https://github.com/tflearn/tflearn.git
```
對于最新的穩定版本,請使用以下命令:
```py
pip install tflearn
```
否則,您也可以通過運行以下命令(從源文件夾)從源安裝它:
```py
python setup.py install
```
## 泰坦尼克號生存預測器
在本教程中,我們將學習使用 TFLearn 和 TensorFlow,使用他們的個人信息(如性別和年齡)模擬泰坦尼克號乘客的生存機會。為了解決這個經典的 ML 任務,我們將構建一個 DNN 分類器。
我們來看看數據集(TFLearn 將自動為您下載)。
對于每位乘客,提供以下信息:
```py
survived Survived (0 = No; 1 = Yes)
pclass Passenger Class (1 = st; 2 = nd; 3 = rd)
name Name
sex Sex
age Age
sibsp Number of Siblings/Spouses Aboard
parch Number of Parents/Children Aboard
ticket Ticket Number
fare Passenger Fare
```
以下是數據集中的一些示例:
| `sibsp` | `parch` | `ticket` | `fare` |
| --- | --- | --- | --- |
| 1 | 1 | Aubart, Mme. Leontine Pauline | female | 24 | 0 | 0 | PC 17477 | 69.3000 |
| 0 | 2 | Bowenur, Mr. Solomon | male | 42 | 0 | 0 | 211535 | 13.0000 |
| 1 | 3 | Baclini, Miss. Marie Catherine | female | 5 | 2 | 1 | 2666 | 19.2583 |
| 0 | 3 | Youseff, Mr. Gerious | male | 45.5 | 0 | 0 | 2628 | 7.2250 |
我們的任務有兩個類:沒有幸存(`class = 0`)和幸存(`class = 1`)。乘客數據有 8 個特征。泰坦尼克號數據集存儲在 CSV 文件中,因此我們可以使用`TFLearn load_csv()`函數將文件中的數據加載到 Python 列表中。我們指定`target_column`參數以指示我們的標簽(幸存與否)位于第一列(ID:0)。這些函數將返回一個元組:(數據,標簽)。
讓我們從導入 NumPy 和 TFLearn 庫開始:
```py
import numpy as np
import tflearn as tfl
```
下載泰坦尼克號數據集:
```py
from tflearn.datasets import titanic
titanic.download_dataset('titanic_dataset.csv')
```
加載 CSV 文件,并指出第一列代表`labels`:
```py
from tflearn.data_utils import load_csv
data, labels = load_csv('titanic_dataset.csv', target_column=0,
categorical_labels=True, n_classes=2)
```
在準備好在我們的 DNN 分類器中使用之前,數據需要一些預處理。我們必須刪除無法幫助我們進行分析的列字段。我們丟棄名稱和票據字段,因為我們估計乘客的姓名和票證與他們的幸存機會無關:
```py
def preprocess(data, columns_to_ignore):
```
預處理階段從降序 ID 和刪除列開始:
```py
for id in sorted(columns_to_ignore, reverse=True):
[r.pop(id) for r in data]
for i in range(len(data)):
```
性別場轉換為浮動(待操縱):
```py
data[i][1] = 1\. if data[i][1] == 'female' else 0.
return np.array(data, dtype=np.float32)
```
如前所述,分析將忽略名稱和故障單字段:
```py
to_ignore=[1, 6]
```
然后我們調用`preprocess`程序:
```py
data = preprocess(data, to_ignore)
```
接下來,我們指定輸入數據的形狀。輸入樣本總共有`6`特征,我們將分批量樣本以節省內存,因此我們的數據輸入形狀為`[None, 6]`。`None`參數表示未知維度,因此我們可以更改批量中處理的樣本總數:
```py
net = tfl.input_data(shape=[None, 6])
```
最后,我們用這個簡單的語句序列構建了一個 3 層神經網絡:
```py
net = tfl.fully_connected(net, 32)
net = tfl.fully_connected(net, 32)
net = tfl.fully_connected(net, 2, activation='softmax')
net = tfl.regression(net)
```
TFLearn 提供了一個模型包裝器`DNN`,它自動執行神經網絡分類器任務:
```py
model = tfl.DNN(net)
```
我們將為批量大小為`16`的`10`周期運行它:
```py
model.fit(data, labels, n_epoch=10, batch_size=16, show_metric=True)
```
當我們運行模型時,我們應該得到以下輸出:
```py
Training samples: 1309
Validation samples: 0
--
Training Step: 82 | total loss: 0.64003
| Adam | epoch: 001 | loss: 0.64003 - acc: 0.6620 -- iter: 1309/1309
--
Training Step: 164 | total loss: 0.61915
| Adam | epoch: 002 | loss: 0.61915 - acc: 0.6614 -- iter: 1309/1309
--
Training Step: 246 | total loss: 0.56067
| Adam | epoch: 003 | loss: 0.56067 - acc: 0.7171 -- iter: 1309/1309
--
Training Step: 328 | total loss: 0.51807
| Adam | epoch: 004 | loss: 0.51807 - acc: 0.7799 -- iter: 1309/1309
--
Training Step: 410 | total loss: 0.47475
| Adam | epoch: 005 | loss: 0.47475 - acc: 0.7962 -- iter: 1309/1309
--
Training Step: 574 | total loss: 0.48988
| Adam | epoch: 007 | loss: 0.48988 - acc: 0.7891 -- iter: 1309/1309
--
Training Step: 656 | total loss: 0.55073
| Adam | epoch: 008 | loss: 0.55073 - acc: 0.7427 -- iter: 1309/1309
--
Training Step: 738 | total loss: 0.50242
| Adam | epoch: 009 | loss: 0.50242 - acc: 0.7854 -- iter: 1309/1309
--
Training Step: 820 | total loss: 0.41557
| Adam | epoch: 010 | loss: 0.41557 - acc: 0.8110 -- iter: 1309/1309
--
```
模型準確率約為 81%,這意味著它可以預測 81% 乘客的正確結果(即乘客是否幸存)。
# PrettyTensor
PrettyTensor 允許開發人員包裝 TensorFlow 操作,以快速鏈接任意數量的層來定義神經網絡。即將推出的是 PrettyTensor 功能的簡單示例:我們將一個標準的 TensorFlow 對象包裝成一個與庫兼容的對象;然后我們通過三個完全連接的層提供它,我們最終輸出 softmax 分布:
```py
pretty = tf.placeholder([None, 784], tf.float32)
softmax = (prettytensor.wrap(examples)
.fully_connected(256, tf.nn.relu)
.fully_connected(128, tf.sigmoid)
.fully_connected(64, tf.tanh)
.softmax(10))
```
PrettyTensor 安裝非常簡單。您只需使用`pip`安裝程序:
```py
sudo pip install prettytensor
```
## 鏈接層
PrettyTensor 具有三種操作模式,共享鏈式方法的能力。
## 正常模式
在正常模式下,每調用一次,就會創建一個新的 PrettyTensor。這樣可以輕松鏈接,您仍然可以多次使用任何特定對象。這樣可以輕松分支網絡。
## 順序模式
在順序模式下, 內部變量 - 頭部 - 跟蹤最近的輸出張量,從而允許將調用鏈分解為多個語句。
這是一個簡單的例子:
```py
seq = pretty_tensor.wrap(input_data).sequential()
seq.flatten()
seq.fully_connected(200, activation_fn=tf.nn.relu)
seq.fully_connected(10, activation_fn=None)
result = seq.softmax(labels, name=softmax_name))
```
## 分支和連接
可以使用一流`branch`和`join`方法構建復雜網絡:
* `branch`創建一個單獨的 PrettyTensor 對象,該對象在調用時指向當前頭部,這允許用戶定義一個單獨的塔,該塔以回歸目標結束,以輸出結束或重新連接網絡。重新連接允許用戶定義復合層,如初始。
* `join`用于連接多個輸入或重新連接復合層。
## 數字分類器
在這個例子中,我們將定義和訓練一個兩層模型和一個 LeNe??t 5 風格的卷積模型:
```py
import tensorflow as tf
import prettytensor as pt
from prettytensor.tutorial import data_utils
tf.app.flags.DEFINE_string('save_path',\
None, \
'Where to save the model checkpoints.')
FLAGS = tf.app.flags.FLAGS
BATCH_SIZE = 50
EPOCH_SIZE = 60000
TEST_SIZE = 10000
```
由于我們將數據作為 NumPy 數組提供,因此我們需要在圖中創建占位符。這些然后必須使用進料`dict`語句饋送:
```py
image_placeholder = tf.placeholder\
(tf.float32, [BATCH_SIZE, 28, 28, 1])
labels_placeholder = tf.placeholder\
(tf.float32, [BATCH_SIZE, 10])
```
接下來,我們創建`multilayer_fully_connected`函數。前兩層是完全連接的(`100`神經元),最后一層是`softmax`結果層。如您所見,鏈接層是一個非常簡單的操作:
```py
def multilayer_fully_connected(images, labels):
images = pt.wrap(images)
with pt.defaults_scope\
(activation_fn=tf.nn.relu,l2loss=0.00001):
return (images.flatten().\
fully_connected(100).\
fully_connected(100).\
softmax_classifier(10, labels))
```
現在我們將構建一個多層卷積網絡:該架構類似于 LeNet5。請更改此設置,以便您可以嘗試其他架構:
```py
def lenet5(images, labels):
images = pt.wrap(images)
with pt.defaults_scope\
(activation_fn=tf.nn.relu, l2loss=0.00001):
return (images.conv2d(5, 20).\
max_pool(2, 2).\
conv2d(5, 50).\
max_pool(2, 2).\
flatten().\
fully_connected(500).\
softmax_classifier(10, labels))
```
根據所選模型,我們可能有一個 2 層分類器(`multilayer_fully_connected`)或卷積分類器(`lenet5`):
```py
def make_choice():
var = int(input('(1) = multy layer model (2) = LeNet5 '))
print(var)
if var == 1:
result = multilayer_fully_connected\
(image_placeholder,labels_placeholder)
run_model(result)
elif var == 2:
result = lenet5\
(image_placeholder,labels_placeholder)
run_model(result)
else:
print ('incorrect input value')
```
最后,我們將為所選模型定義`accuracy`:
```py
def run_model(result):
accuracy = result.softmax.evaluate_classifier\
(labels_placeholder,phase=pt.Phase.test)
```
接下來,我們構建訓練和測試集:
```py
train_images, train_labels = data_utils.mnist(training=True)
test_images, test_labels = data_utils.mnist(training=False)
```
我們將使用梯度下降優化程序并將其應用于圖。`pt.apply_optimizer`函數增加了正則化損失并設置了一個步進計數器:
```py
optimizer = tf.train.GradientDescentOptimizer(0.01)
train_op = pt.apply_optimizer\
(optimizer,losses=[result.loss])
```
我們可以在正在運行的會話中設置`save_path`,以便每隔一段時間自動保存進度。否則,模型將在會話結束時丟失:
```py
runner = pt.train.Runner(save_path=FLAGS.save_path)
with tf.Session():
for epoch in range(0,10)
```
隨機展示訓練數據:
```py
train_images, train_labels = \
data_utils.permute_data\
((train_images, train_labels))
runner.train_model(train_op,result.\
loss,EPOCH_SIZE,\
feed_vars=(image_placeholder,\
labels_placeholder),\
feed_data=pt.train.\
feed_numpy(BATCH_SIZE,\
train_images,\
train_labels),\
print_every=100)
classification_accuracy = runner.evaluate_model\
(accuracy,\
TEST_SIZE,\
feed_vars=(image_placeholder,\
labels_placeholder),\
feed_data=pt.train.\
feed_numpy(BATCH_SIZE,\
test_images,\
test_labels))
print("epoch" , epoch + 1)
print("accuracy", classification_accuracy )
if __name__ == '__main__':
make_choice()
```
運行示例,我們必須選擇要訓練的模型:
```py
(1) = multylayer model (2) = LeNet5
```
通過選擇`multylayer model`,我們應該具有 95.5% 的準確率:
```py
Extracting /tmp/data\train-images-idx3-ubyte.gz
Extracting /tmp/data\train-labels-idx1-ubyte.gz
Extracting /tmp/data\t10k-images-idx3-ubyte.gz
Extracting /tmp/data\t10k-labels-idx1-ubyte.gz
epoch 1
accuracy [0.8969]
epoch 2
accuracy [0.914]
epoch 3
accuracy [0.9188]
epoch 4
accuracy [0.9306]
epoch 5
accuracy [0.9353]
epoch 6
accuracy [0.9384]
epoch 7
accuracy [0.9445]
epoch 8
accuracy [0.9472]
epoch 9
accuracy [0.9531]
epoch 10
accuracy [0.9552]
```
而對于 Lenet5,我們應該具有 98.8% 的準確率:
```py
Extracting /tmp/data\train-images-idx3-ubyte.gz
Extracting /tmp/data\train-labels-idx1-ubyte.gz
Extracting /tmp/data\t10k-images-idx3-ubyte.gz
Extracting /tmp/data\t10k-labels-idx1-ubyte.gz
epoch 1
accuracy [0.9686]
epoch 2
accuracy [0.9755]
epoch 3
accuracy [0.983]
epoch 4
accuracy [0.9841]
epoch 5
accuracy [0.9844]
epoch 6
accuracy [0.9863]
epoch 7
accuracy [0.9862]
epoch 8
accuracy [0.9877]
epoch 9
accuracy [0.9855]
epoch 10
accuracy [0.9886]
```
# Keras
Keras 是一個用 Python 編寫的開源神經網絡庫。它專注于最小化,模塊化和可擴展性,旨在實現 DNN 的快速實驗。
該庫的主要作者和維護者是名為 Fran?oisChollet 的 Google 工程師,該庫是項目 ONEIROS(開放式神經電子智能機器人操作系統)研究工作的一部分。
Keras 是按照以下設計原則開發的:
* 模塊化:模型被理解為獨立,完全可配置的模塊序列或圖,可以通過盡可能少的限制插入到一起。神經層,成本函數,優化器,初始化方案和激活函數都是獨立的模塊,可以組合起來創建新模型。
* 極簡主義:每個模塊必須簡短(幾行代碼)并且簡單。在骯臟的讀取之上,源代碼應該是透明的。
* 可擴展性:新模塊易于添加(如新類和函數),現有模塊提供了基于新模塊的示例。能夠輕松創建新模塊可以實現完全表現力,使 Keras 適合高級研究。
Keras 既可以作為 TensorFlow API 在嵌入式版本中使用,也可以作為庫使用:
* `tf.keras`來自[此鏈接](https://www.tensorflow.org/api_docs/python/tf/keras)
* Keras v2.1.4(更新和安裝指南請參見[此鏈接](https://keras.io))
在以下部分中,我們將了解如何使用第一個和第二個實現。
## Keras 編程模型
Keras 的核心數據結構是一個模型,它是一種組織層的方法。有兩種類型的模型:
* 順序:這只是用于實現簡單模型的線性層疊
* 函數式 API:用于更復雜的架構,例如具有多個輸出和有向無環圖的模型
### 順序模型
在本節中,我們將快速通過向您展示代碼來解釋順序模型的工作原理。讓我們首先使用 TensorFlow API 導入和構建 Keras `Sequential`模型:
```py
import tensorflow as tf
from tensorflow.python.keras.models import Sequential
model = Sequential()
```
一旦我們定義了模型,我們就可以添加一個或多個層。堆疊操作由`add()`語句提供:
```py
from keras.layers import Dense, Activation
```
例如,讓我們添加第一個完全連接的神經網絡層和激活函數:
```py
model.add(Dense(output_dim=64, input_dim=100))
model.add(Activation("relu"))
```
然后我們添加第二個`softmax`層:
```py
model.add(Dense(output_dim=10))
model.add(Activation("softmax"))
```
如果模型看起來很好,我們必須`compile()`模型,指定損失函數和要使用的優化器:
```py
model.compile(loss='categorical_crossentropy',\
optimizer='sgd',\
metrics=['accuracy'])
```
我們現在可以配置我們的優化器。 Keras 嘗試使編程變得相當簡單,允許用戶在需要時完全控制。
編譯完成后,模型必須符合以下數據:
```py
model.fit(X_train, Y_train, nb_epoch=5, batch_size=32)
```
或者,我們可以手動將批次提供給我們的模型:
```py
model.train_on_batch(X_batch, Y_batch)
```
一旦訓練完成,我們就可以使用我們的模型對新數據進行預測:
```py
classes = model.predict_classes(X_test, batch_size=32)
proba = model.predict_proba(X_test, batch_size=32)
```
#### 電影評論的情感分類
在這個例子中,我們將 Keras 序列模型應用于情感分析問題。情感分析是破譯書面或口頭文本中包含的觀點的行為。這種技術的主要目的是識別詞匯表達的情感(或極性),這可能具有中性,正面或負面的含義。我們想要解決的問題是 IMDB 電影評論情感分類問題:每個電影評論是一個可變的單詞序列,每個電影評論的情感(正面或負面)必須分類。
問題非常復雜,因為序列的長度可能不同,并且包含大量的輸入符號詞匯。該解決方案要求模型學習輸入序列中符號之間的長期依賴關系。
IMDB 數據集包含 25,000 個極地電影評論(好的或壞的)用于訓練,并且相同的數量再次用于測試。這些數據由斯坦福大學的研究人員收集,并用于 2011 年的一篇論文中,其中五五開的數據被用于訓練和測試。在本文中,實現了 88.89% 的準確率。
一旦我們定義了問題,我們就可以開發一個順序 LSTM 模型來對電影評論的情感進行分類。我們可以快速開發用于 IMDB 問題的 LSTM 并獲得良好的準確率。讓我們首先導入此模型所需的類和函數,并將隨機數生成器初始化為常量值,以確保我們可以輕松地重現結果。
在此示例中,我們在 TensorFlow API 中使用嵌入式 Keras:
```py
import numpy
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras.datasets import imdb
from tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.layers import LSTM
from tensorflow.python.keras.layers import Embedding
from tensorflow.python.keras.preprocessing import sequence
numpy.random.seed(7)
```
我們加載 IMDB 數據集。我們將數據集限制為前 5,000 個單詞。我們還將數據集分為訓練(50%)和測試(50%)集。
Keras 提供對 IMDB 數據集的內置訪問。`imdb.load_data()`函數允許您以準備好在神經網絡和 DL 模型中使用的格式加載數據集。單詞已被整數替換,這些整數表示數據集中每個單詞的有序頻率。因此,每個評論中的句子包括一系列整數。
這是代碼:
```py
top_words = 5000
(X_train, y_train), (X_test, y_test) = \
imdb.load_data(num_words=top_words)
```
接下來,我們需要截斷并填充輸入序列,以便它們具有相同的建模長度。該模型將學習不攜帶信息的零值,因此序列在內容方面的長度不同,但是向量需要在 Keras 中計算相同的長度。每個評論中的序列長度各不相同,因此我們將每個評論限制為`500`單詞,截斷長評論并用零值填充較短評論:
讓我們來看看:
```py
max_review_length = 500
X_train = sequence.pad_sequences\
(X_train, maxlen=max_review_length)
X_test = sequence.pad_sequences\
(X_test, maxlen=max_review_length)
```
我們現在可以定義,編譯和調整我們的 LSTM 模型。
要解決情感分類問題,我們將使用單詞嵌入技術。它包括在連續向量空間中表示單詞,該向量空間是語義相似的單詞被映射到相鄰點的區域。單詞嵌入基于分布式假設,該假設指出出現在給定上下文中的單詞必須具有相同的語義含義。然后將每個電影評論映射到真實的向量域,其中在意義方面的單詞之間的相似性轉換為向量空間中的接近度。 Keras 提供了一種通過使用嵌入層將單詞的正整數表示轉換為單詞嵌入的便捷方式。
在這里,我們定義嵌入向量和模型的長度:
```py
embedding_vector_length = 32
model = Sequential()
```
第一層是嵌入層。它使用 32 個長度向量來表示每個單詞:
```py
model.add(Embedding(top_words, \
embedding_vector_length,\
input_length=max_review_length))
```
下一層是具有`100`存儲單元的 LSTM 層。最后,因為這是一個分類問題,我們使用具有單個神經元的密集輸出層和`sigmoid`激活函數來預測問題中的類(好的和壞的):
```py
model.add(LSTM(100))
model.add(Dense(1, activation='sigmoid'))
```
因為它是二元分類問題,我們使用`binary_crossentropy`作為損失函數,而這里使用的優化器是`adam`優化算法(我們在之前的 TensorFlow 實現中遇到過它):
```py
model.compile(loss='binary_crossentropy',\
optimizer='adam',\
metrics=['accuracy'])
print(model.summary())
```
我們只適合三個周期,因為模型很快就會適應。批量大小為 64 的評論用于分隔權重更新:
```py
model.fit(X_train, y_train, \
validation_data=(X_test, y_test),\
num_epochs=3, \
batch_size=64)
```
然后,我們估計模型在看不見的評論中的表現:
```py
scores = model.evaluate(X_test, y_test, verbose=0)
print("Accuracy: %.2f%%" % (scores[1]*100))
```
運行此示例將生成以下輸出:
```py
Epoch 1/3
16750/16750 [==============================] - 107s - loss: 0.5570 - acc: 0.7149
Epoch 2/3
16750/16750 [==============================] - 107s - loss: 0.3530 - acc: 0.8577
Epoch 3/3
16750/16750 [==============================] - 107s - loss: 0.2559 - acc: 0.9019
Accuracy: 86.79%
```
您可以看到,這個簡單的 LSTM 幾乎沒有調整,可以在 IMDB 問題上獲得最接近最先進的結果。重要的是,這是一個模板,您可以使用該模板將 LSTM 網絡應用于您自己的序列分類問題。
### 函數式 API
為了構建復雜的網絡,我們將在這里描述的函數式方法非常有用。如第 4 章,卷積神經網絡上的 TensorFlow 所示,最流行的神經網絡(AlexNET,VGG 等)由一個或多個重復多次的神經迷你網絡組成。函數式 API 包括將神經網絡視為我們可以多次調用的函數。這種方法在計算上是有利的,因為為了構建神經網絡,即使是復雜的神經網絡,也只需要幾行代碼。
在以下示例中,我們使用來自[此鏈接](https://keras.io)的 Keras v2.1.4 。
讓我們看看它是如何工作的。首先,您需要導入`Model`模塊:
```py
from keras.models import Model
```
首先要做的是指定模型的輸入。讓我們使用`Input()`函數聲明一個`28×28×1`的張量:
```py
from keras.layers import Input
digit_input = Input(shape=(28, 28,1))
```
這是順序模型和函數式 API 之間的顯著差異之一。因此,使用`Conv2D`和`MaxPooling2D` API,我們構建卷積層:
```py
x = Conv2D(64, (3, 3))(digit_input)
x = Conv2D(64, (3, 3))(x)
x = MaxPooling2D((2, 2))(x)
out = Flatten()(x)
```
請注意,變量`x`指定應用層的變量。最后,我們通過指定輸入和輸出來定義模型:
```py
vision_model = Model(digit_input, out)
```
當然,我們還需要使用`fit`和`compile`方法指定損失,優化器等,就像我們對順序模型一樣。
#### SqueezeNet
在這個例子中,我們引入了一個名為 SqueezeNet 的小型 CNN 架構,它在 ImageNet 上實現了 AlexNet 級精度,參數減少了 50 倍。這個架構的靈感來自 GoogleNet 的初始模塊,發表在論文中:SqueezeNet:AlexNet 級準確率,參數減少 50 倍,模型小于 1MB,[可從此鏈接下載](http://arxiv.org/pdf/1602.07360v2.pdf)。
SqueezeNet 背后的想法是減少使用壓縮方案處理的參數數量。此策略使用較少的過濾器減少參數數量。這是通過將擠壓層送入它們所稱的擴展層來完成的。這兩層組成了所謂的 Fire Module,如下圖所示:
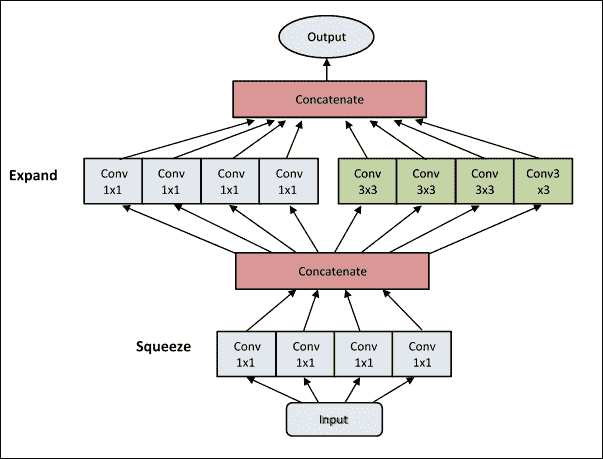
圖 2:SqueezeNet 消防模塊
`fire_module`由`1×1`卷積濾波器組成,然后是 ReLU 操作:
```py
x = Convolution2D(squeeze,(1,1),padding='valid', name='fire2/squeeze1x1')(x)
x = Activation('relu', name='fire2/relu_squeeze1x1')(x)
```
`expand`部分有兩部分:`left`和`right`。
`left`部分使用`1×1`卷積,稱為擴展`1×1`:
```py
left = Conv2D(expand, (1, 1), padding='valid', name=s_id + exp1x1)(x)
left = Activation('relu', name=s_id + relu + exp1x1)(left)
```
`right`部分使用`3×3`卷積,稱為`expand3x3`。這兩個部分后面都是 ReLU 層:
```py
right = Conv2D(expand, (3, 3), padding='same', name=s_id + exp3x3)(x)
right = Activation('relu', name=s_id + relu + exp3x3)(right)
```
消防模塊的最終輸出是左右連接:
```py
x = concatenate([left, right], axis=channel_axis, name=s_id + 'concat')
```
然后,重復使用`fire_module`構建完整的網絡,如下所示:
```py
x = Convolution2D(64,(3,3),strides=(2,2), padding='valid',\
name='conv1')(img_input)
x = Activation('relu', name='relu_conv1')(x)
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), name='pool1')(x)
x = fire_module(x, fire_id=2, squeeze=16, expand=64)
x = fire_module(x, fire_id=3, squeeze=16, expand=64)
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), name='pool3')(x)
x = fire_module(x, fire_id=4, squeeze=32, expand=128)
x = fire_module(x, fire_id=5, squeeze=32, expand=128)
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), name='pool5')(x)
x = fire_module(x, fire_id=6, squeeze=48, expand=192)
x = fire_module(x, fire_id=7, squeeze=48, expand=192)
x = fire_module(x, fire_id=8, squeeze=64, expand=256)
x = fire_module(x, fire_id=9, squeeze=64, expand=256)
x = Dropout(0.5, name='drop9')(x)
x = Convolution2D(classes, (1, 1), padding='valid', name='conv10')(x)
x = Activation('relu', name='relu_conv10')(x)
x = GlobalAveragePooling2D()(x)
x = Activation('softmax', name='loss')(x)
model = Model(inputs, x, name='squeezenet')
```
下圖顯示了 SqueezeNet 架構:

圖 3:SqueezeNet 架構
您可以從下面的鏈接執行 Keras 的 SqueezeNet(在[`squeezenet.py`文件](https://github.com/rcmalli/keras-squeezenet)):
然后我們在以下`squeeze_test.jpg`(`227×227`)圖像上測試模型:

圖 4:SqueezeNet 測試圖像
我們只需使用以下幾行代碼即可:
```py
import os
import numpy as np
import squeezenet as sq
from keras.applications.imagenet_utils import preprocess_input
from keras.applications.imagenet_utils import preprocess_input, decode_predictions
from keras.preprocessing import image
model = sq.SqueezeNet()
img = image.load_img('squeeze_test.jpg', target_size=(227, 227))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
preds = model.predict(x)
print('Predicted:', decode_predictions(preds))
```
如您所見,結果非常有趣:
```py
Predicted: [[('n02504013', 'Indian_elephant', 0.64139527), ('n02504458', 'African_elephant', 0.22846894), ('n01871265', 'tusker', 0.12922771), ('n02397096', 'warthog', 0.00037213496), ('n02408429', 'water_buffalo', 0.00032306617)]]
```
# 總結
在本章中,我們研究了一些基于 TensorFlow 的 DL 研究和開發庫。我們引入了`tf.estimator`,它是 DL/ML 的簡化接口,現在是 TensorFlow 和高級 ML API 的一部分,可以輕松訓練,配置和評估各種 ML 模型。我們使用估計器函數為鳶尾花數據集實現分類器。
我們還看了一下 TFLearn 庫,它包含了很多 TensorFlow API。在這個例子中,我們使用 TFLearn 來估計泰坦尼克號上乘客的生存機會。為了解決這個問題,我們構建了一個 DNN 分類器。
然后,我們介紹了 PrettyTensor,它允許 TensorFlow 操作被包裝以鏈接任意數量的層。我們以 LeNet 的風格實現了卷積模型,以快速解決手寫分類模型。
然后我們快速瀏覽了 Keras,它設計用于極簡主義和模塊化,允許用戶快速定義 DL 模型。使用 Keras,我們學習了如何為 IMDB 電影評論情感分類問題開發一個簡單的單層 LSTM 模型。在最后一個例子中,我們使用 Keras 的函數從預訓練的初始模型開始構建 SqueezeNet 神經網絡。
下一章將介紹強化學習。我們將探討強化學習的基本原理和算法。我們還將看到一些使用 TensorFlow 和 OpenAI Gym 框架的示例,這是一個用于開發和比較強化學習算法的強大工具包。
- TensorFlow 1.x 深度學習秘籍
- 零、前言
- 一、TensorFlow 簡介
- 二、回歸
- 三、神經網絡:感知器
- 四、卷積神經網絡
- 五、高級卷積神經網絡
- 六、循環神經網絡
- 七、無監督學習
- 八、自編碼器
- 九、強化學習
- 十、移動計算
- 十一、生成模型和 CapsNet
- 十二、分布式 TensorFlow 和云深度學習
- 十三、AutoML 和學習如何學習(元學習)
- 十四、TensorFlow 處理單元
- 使用 TensorFlow 構建機器學習項目中文版
- 一、探索和轉換數據
- 二、聚類
- 三、線性回歸
- 四、邏輯回歸
- 五、簡單的前饋神經網絡
- 六、卷積神經網絡
- 七、循環神經網絡和 LSTM
- 八、深度神經網絡
- 九、大規模運行模型 -- GPU 和服務
- 十、庫安裝和其他提示
- TensorFlow 深度學習中文第二版
- 一、人工神經網絡
- 二、TensorFlow v1.6 的新功能是什么?
- 三、實現前饋神經網絡
- 四、CNN 實戰
- 五、使用 TensorFlow 實現自編碼器
- 六、RNN 和梯度消失或爆炸問題
- 七、TensorFlow GPU 配置
- 八、TFLearn
- 九、使用協同過濾的電影推薦
- 十、OpenAI Gym
- TensorFlow 深度學習實戰指南中文版
- 一、入門
- 二、深度神經網絡
- 三、卷積神經網絡
- 四、循環神經網絡介紹
- 五、總結
- 精通 TensorFlow 1.x
- 一、TensorFlow 101
- 二、TensorFlow 的高級庫
- 三、Keras 101
- 四、TensorFlow 中的經典機器學習
- 五、TensorFlow 和 Keras 中的神經網絡和 MLP
- 六、TensorFlow 和 Keras 中的 RNN
- 七、TensorFlow 和 Keras 中的用于時間序列數據的 RNN
- 八、TensorFlow 和 Keras 中的用于文本數據的 RNN
- 九、TensorFlow 和 Keras 中的 CNN
- 十、TensorFlow 和 Keras 中的自編碼器
- 十一、TF 服務:生產中的 TensorFlow 模型
- 十二、遷移學習和預訓練模型
- 十三、深度強化學習
- 十四、生成對抗網絡
- 十五、TensorFlow 集群的分布式模型
- 十六、移動和嵌入式平臺上的 TensorFlow 模型
- 十七、R 中的 TensorFlow 和 Keras
- 十八、調試 TensorFlow 模型
- 十九、張量處理單元
- TensorFlow 機器學習秘籍中文第二版
- 一、TensorFlow 入門
- 二、TensorFlow 的方式
- 三、線性回歸
- 四、支持向量機
- 五、最近鄰方法
- 六、神經網絡
- 七、自然語言處理
- 八、卷積神經網絡
- 九、循環神經網絡
- 十、將 TensorFlow 投入生產
- 十一、更多 TensorFlow
- 與 TensorFlow 的初次接觸
- 前言
- 1.?TensorFlow 基礎知識
- 2. TensorFlow 中的線性回歸
- 3. TensorFlow 中的聚類
- 4. TensorFlow 中的單層神經網絡
- 5. TensorFlow 中的多層神經網絡
- 6. 并行
- 后記
- TensorFlow 學習指南
- 一、基礎
- 二、線性模型
- 三、學習
- 四、分布式
- TensorFlow Rager 教程
- 一、如何使用 TensorFlow Eager 構建簡單的神經網絡
- 二、在 Eager 模式中使用指標
- 三、如何保存和恢復訓練模型
- 四、文本序列到 TFRecords
- 五、如何將原始圖片數據轉換為 TFRecords
- 六、如何使用 TensorFlow Eager 從 TFRecords 批量讀取數據
- 七、使用 TensorFlow Eager 構建用于情感識別的卷積神經網絡(CNN)
- 八、用于 TensorFlow Eager 序列分類的動態循壞神經網絡
- 九、用于 TensorFlow Eager 時間序列回歸的遞歸神經網絡
- TensorFlow 高效編程
- 圖嵌入綜述:問題,技術與應用
- 一、引言
- 三、圖嵌入的問題設定
- 四、圖嵌入技術
- 基于邊重構的優化問題
- 應用
- 基于深度學習的推薦系統:綜述和新視角
- 引言
- 基于深度學習的推薦:最先進的技術
- 基于卷積神經網絡的推薦
- 關于卷積神經網絡我們理解了什么
- 第1章概論
- 第2章多層網絡
- 2.1.4生成對抗網絡
- 2.2.1最近ConvNets演變中的關鍵架構
- 2.2.2走向ConvNet不變性
- 2.3時空卷積網絡
- 第3章了解ConvNets構建塊
- 3.2整改
- 3.3規范化
- 3.4匯集
- 第四章現狀
- 4.2打開問題
- 參考
- 機器學習超級復習筆記
- Python 遷移學習實用指南
- 零、前言
- 一、機器學習基礎
- 二、深度學習基礎
- 三、了解深度學習架構
- 四、遷移學習基礎
- 五、釋放遷移學習的力量
- 六、圖像識別與分類
- 七、文本文件分類
- 八、音頻事件識別與分類
- 九、DeepDream
- 十、自動圖像字幕生成器
- 十一、圖像著色
- 面向計算機視覺的深度學習
- 零、前言
- 一、入門
- 二、圖像分類
- 三、圖像檢索
- 四、對象檢測
- 五、語義分割
- 六、相似性學習
- 七、圖像字幕
- 八、生成模型
- 九、視頻分類
- 十、部署
- 深度學習快速參考
- 零、前言
- 一、深度學習的基礎
- 二、使用深度學習解決回歸問題
- 三、使用 TensorBoard 監控網絡訓練
- 四、使用深度學習解決二分類問題
- 五、使用 Keras 解決多分類問題
- 六、超參數優化
- 七、從頭開始訓練 CNN
- 八、將預訓練的 CNN 用于遷移學習
- 九、從頭開始訓練 RNN
- 十、使用詞嵌入從頭開始訓練 LSTM
- 十一、訓練 Seq2Seq 模型
- 十二、深度強化學習
- 十三、生成對抗網絡
- TensorFlow 2.0 快速入門指南
- 零、前言
- 第 1 部分:TensorFlow 2.00 Alpha 簡介
- 一、TensorFlow 2 簡介
- 二、Keras:TensorFlow 2 的高級 API
- 三、TensorFlow 2 和 ANN 技術
- 第 2 部分:TensorFlow 2.00 Alpha 中的監督和無監督學習
- 四、TensorFlow 2 和監督機器學習
- 五、TensorFlow 2 和無監督學習
- 第 3 部分:TensorFlow 2.00 Alpha 的神經網絡應用
- 六、使用 TensorFlow 2 識別圖像
- 七、TensorFlow 2 和神經風格遷移
- 八、TensorFlow 2 和循環神經網絡
- 九、TensorFlow 估計器和 TensorFlow HUB
- 十、從 tf1.12 轉換為 tf2
- TensorFlow 入門
- 零、前言
- 一、TensorFlow 基本概念
- 二、TensorFlow 數學運算
- 三、機器學習入門
- 四、神經網絡簡介
- 五、深度學習
- 六、TensorFlow GPU 編程和服務
- TensorFlow 卷積神經網絡實用指南
- 零、前言
- 一、TensorFlow 的設置和介紹
- 二、深度學習和卷積神經網絡
- 三、TensorFlow 中的圖像分類
- 四、目標檢測與分割
- 五、VGG,Inception,ResNet 和 MobileNets
- 六、自編碼器,變分自編碼器和生成對抗網絡
- 七、遷移學習
- 八、機器學習最佳實踐和故障排除
- 九、大規模訓練
- 十、參考文獻