
# 九、DeepDream
本章重點介紹了生成型深度學習的領域,這已成為真正的**人工智能**(**AI**)最前沿的核心思想之一。 我們將關注**卷積神經網絡**(**CNN**)如何利用遷移學習來思考或可視化圖像中的圖案。 它們可以生成描述這些卷積網絡思維甚至夢境方式之前從未見過的圖像模式! DeepDream 于 2015 年由 Google 首次發布,由于深層網絡開始從圖像生成有趣的圖案,因此引起了轟動。 本章將涵蓋以下主要主題:
* 動機 — 心理幻覺
* 計算機視覺中的算法異同
* 通過可視化 CNN 的內部層來了解 CNN 所學的知識
* DeepDream 算法以及如何創建自己的夢境
就像前面的章節一樣,我們將結合使用概念知識和直觀的實際操作示例。 您可以在 [GitHub 存儲庫](https://github.com/dipanjanS/hands-on-transfer-learning-with-python)中的`Chapter 9`文件夾中快速閱讀本章的代碼。 可以根據需要參考本章。
# 介紹
在詳細介紹神經 DeepDream 之前,讓我們看一下人類所經歷的類似行為。 您是否曾經嘗試過尋找云中的形狀,電視機中的抖動和嘈雜信號,甚至看過一張被烤面包烤成的面孔?
Pareidolia 是一種心理現象,使我們看到隨機刺激中的模式。 人類傾向于感知實際上不存在的面孔或風格的趨勢。 這通常導致將人的特征分配給對象。 請注意,看到不存在的模式(假陽性)相對于看不到存在的模式(假陰性)對進化結果的重要性。 例如,看到沒有獅子的獅子很少會致命。 但是,沒有看到有一只的掠食性獅子,那當然是致命的。
pareidolia 的神經學基礎主要位于大腦深處的大腦顳葉區域,稱為**梭狀回**,在此區域,人類和其他動物的神經元專用于識別面部和其他物體。
# 計算機視覺中的算法異同
計算機視覺的主要任務之一是特別是對象檢測和面部檢測。 有許多具有面部檢測功能的電子設備在后臺運行此類算法并檢測面部。 那么,當我們在這些軟件的前面放置誘發 Pareidolia 的物體時會發生什么呢? 有時,這些軟件解釋面孔的方式與我們完全相同。 有時它可能與我們一致,有時它會引起我們全新的面貌。
在使用人工神經網絡構建的對象識別系統的情況下,更高級別的特征/層對應于更易識別的特征,例如面部或物體。 增強這些特征可以帶出計算機的視覺效果。 這些反映了網絡以前看到的訓練圖像集。 讓我們以 Inception 網絡為例,讓它預測一些誘發 Pareidolia 的圖像中看到的物體。 讓我們在下面的照片中拍攝這些三色堇花。 對我而言,這些花有時看起來像蝴蝶,有時又像憤怒的人,留著濃密的胡須的臉:

讓我們看看 Inception 模型在其中的表現。 我們將使用在 ImageNet 數據上訓練的預訓練的 Inception 網絡模型。 要加載模型,請使用以下代碼:
```py
from keras.applications import inception_v3
from keras import backend as K
from keras.applications.imagenet_utils import decode_predictions
from keras.preprocessing import image
K.set_learning_phase(0)
model = inception_v3.InceptionV3(weights='imagenet',include_top=True)
```
要讀取圖像文件并將其轉換為一個圖像的數據批,這是 Inception 網絡模型的`predict`函數的預期輸入,我們使用以下函數:
```py
def preprocess_image(image_path):
img = image.load_img(image_path)
img = image.img_to_array(img)
#convert single image to a batch with 1 image
img = np.expand_dims(img, axis=0)
img = inception_v3.preprocess_input(img)
return img
```
現在,讓我們使用前面的方法預處理輸入圖像并預測模型看到的對象。 我們將使用`modeld.predict`方法來獲取 ImageNet 中所有 1,000 個類的預測類概率。 要將此概率數組轉換為按概率得分的降序排列的實類標簽,我們使用`keras`中的`decode_predictions`方法。 可在此處找到所有 1,000 個 ImageNet 類或[同義詞集的列表](http://image-net.org/challenges/LSVRC/2014/browse-synsets)。 請注意,三色堇花不在訓練模型的已知類集中:
```py
img = preprocess_image(base_image_path)
preds = model.predict(img)
for n, label, prob in decode_predictions(preds)[0]:
print (label, prob)
```
的預測。 最高預測的類別都不具有很大的概率,這是可以預期的,因為模型之前沒有看到過這種特殊的花朵:
```py
bee 0.022255851
earthstar 0.018780833
sulphur_butterfly 0.015787734
daisy 0.013633176
cabbage_butterfly 0.012270376
```
在上一張照片中,模型找到**蜜蜂**。 好吧,這不是一個不好的猜測。 如您所見,在黃色的花朵中,中間的黑色/棕色陰影的下半部分確實像蜜蜂。 此外,它還會看到一些黃色和白色的蝴蝶,如**硫**和**卷心菜**蝴蝶,就像我們人類一眼就能看到的。 下圖顯示了這些已識別對象/類的實際圖像。 顯然,此輸入激活了該網絡中的某些特征檢測器隱藏層。 也許檢測昆蟲/鳥類翅膀的過濾器與一些與顏色相關的過濾器一起被激活,以得出上述結論:

ImageNet 架構及其中的特征圖數量很多。 讓我們假設一下,我們知道可以檢測這些機翼的特征映射層。 現在,給定輸入圖像,我們可以從這一層提取特征。 我們可以更改輸入圖像,以使來自該層的激活增加嗎? 這意味著我們必須修改輸入圖像,以便在輸入圖像中看到更多類似機翼的物體,即使它們不在那里。 最終的圖像將像夢一樣,到處都是蝴蝶。 這正是 DeepDream 中完成的工作。
現在,讓我們看一下 Inception 網絡中的??一些特征圖。 要了解卷積模型學到的知識,我們可以嘗試可視化卷積過濾器。
# 可視化特征圖
可視化 CNN 模型涉及在給定一定輸入的情況下,查看網絡中各種卷積和池化層輸出的中間層特征圖。 這樣就可以了解網絡如何處理輸入以及如何分層提取各種圖像特征。 所有特征圖都具有三個維度:寬度,高度和深度(通道)。 我們將嘗試將它們可視化為 InceptionV3 模型。
讓我們為拉布拉多犬拍攝以下照片,并嘗試形象化各種特征圖。 由于 InceptionV3 模型具有很深的深度,因此我們將僅可視化一些層:

首先,讓我們創建一個模型以獲取輸入圖像并輸出所有內部激活層。 InceptionV3 中的激活層稱為`activation_i`。 因此,我們可以從加載的 Inception 模型中過濾掉激活層,如以下代碼所示:
```py
activation_layers = [ layer.output for layer in model.layers if
layer.name.startswith("activation_")]
layer_names = [ layer.name for layer in model.layers if
layer.name.startswith("activation_")]
```
現在,讓我們創建一個模型,該模型獲取輸入圖像并將所有上述激活層特征作為列表輸出,如以下代碼所示:
```py
from keras.models import Model
activation_model = Model(inputs=model.input, outputs=activation_layers)
```
現在,要獲得輸出激活,我們可以使用`predict`函數。 我們必須使用與先前定義的相同的預處理函數對圖像進行預處理,然后再將其提供給 Inception 網絡:
```py
img = preprocess_image(base_image_path)
activations = activation_model.predict(img)
```
我們可以繪制這些先前的激活。 一個激活層中的所有過濾器/特征圖都可以繪制在網格中。 因此,根據層中濾鏡的數量,我們將圖像網格定義為 NumPy 數組,如以下代碼所示(以下代碼的某些部分來自[這里](https://blog.keras.io/how-convolutional-neural-networks-see-the-world.html)):
```py
import matplotlib.pyplot as plt
images_per_row = 8
idx = 1 #activation layer index
layer_activation=activations[idx]
# This is the number of features in the feature map
n_features = layer_activation.shape[-1]
# The feature map has shape (1, size1, size2, n_features)
r = layer_activation.shape[1]
c = layer_activation.shape[2]
# We will tile the activation channels in this matrix
n_cols = n_features // images_per_row
display_grid = np.zeros((r * n_cols, images_per_row * c))
print(display_grid.shape)
```
現在,我們將遍歷激活層中的所有特征映射,并將縮放后的輸出放到網格中,如以下代碼所示:
```py
# We'll tile each filter into this big horizontal grid
for col in range(n_cols):
for row in range(images_per_row):
channel_image = layer_activation[0,:, :, col *
images_per_row + row]
# Post-process the feature to make it visually palatable
channel_image -= channel_image.mean()
channel_image /= channel_image.std()
channel_image *= 64
channel_image += 128
channel_image = np.clip(channel_image, 0,
255).astype('uint8')
display_grid[col * r : (col + 1) * r,
row * c : (row + 1) * c] = channel_image
# Display the grid
scale = 1\. / r
plt.figure(figsize=(scale * display_grid.shape[1],
scale * display_grid.shape[0]))
plt.title(layer_names[idx]+" #filters="+str(n_features))
plt.grid(False)
plt.imshow(display_grid, aspect='auto', cmap='viridis')
```
以下是各層的輸出:
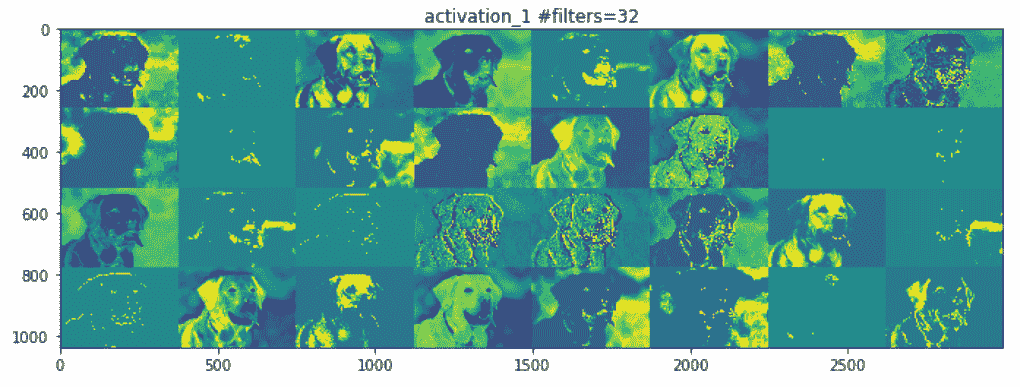
前面的前兩個激活層充當各種邊緣檢測器的集合。 這些激活保留了初始圖片中幾乎所有的信息。
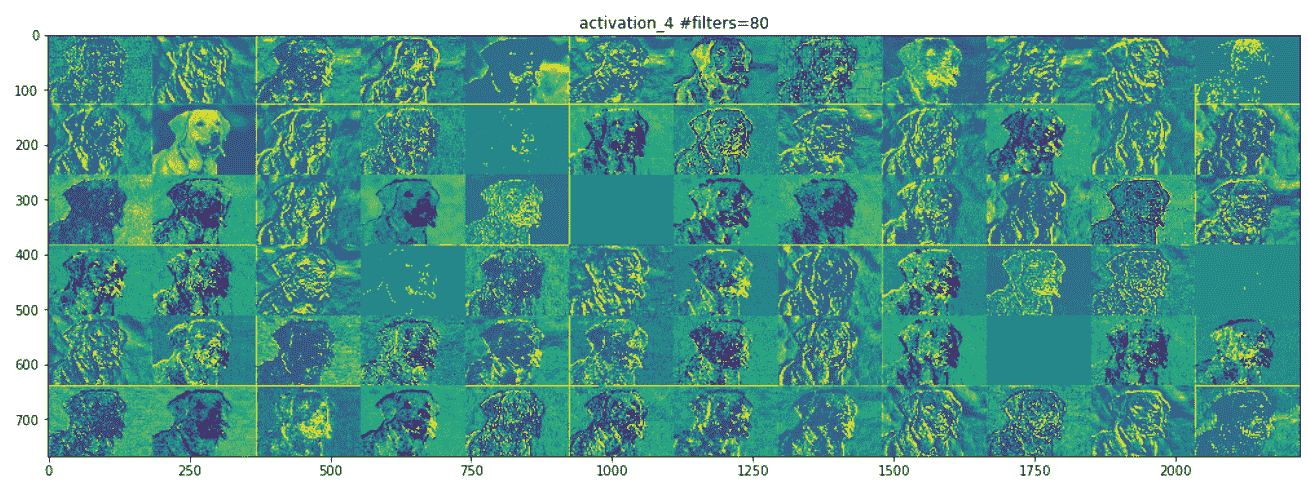
讓我們看下面的屏幕快照,它顯示了網絡中間的一層。 在這里,它開始識別更高級別的特征,例如鼻子,眼睛,舌頭,嘴巴等:
隨著我們的上移,地物圖在視覺上的解釋也越來越少。 較高層的激活會攜帶有關所看到的特定輸入的最少信息,以及有關圖像目標類別(在此情況下為狗)的更多信息。
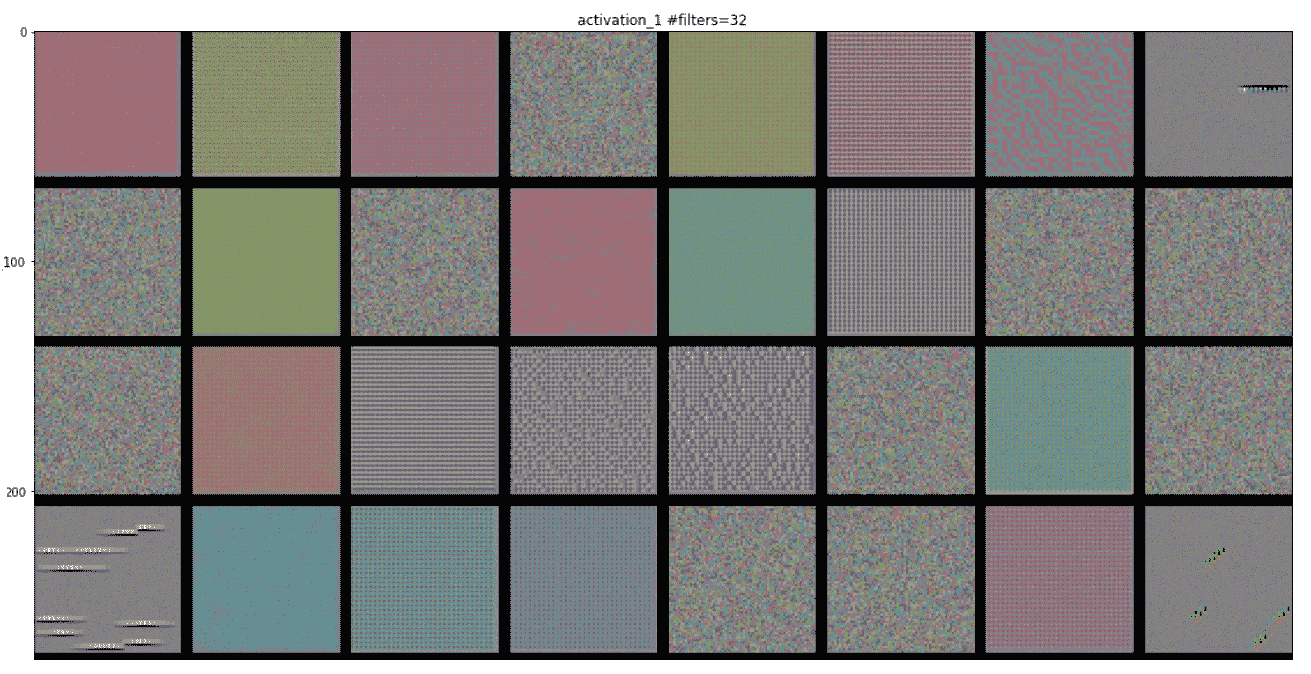
可視化 InceptionV3 學習的過濾器的另一種方法是顯示每個過濾器輸出最大激活值的可視模式。 這可以通過輸入空間中的梯度上升來完成。 基本上,通過使用圖像空間中的梯度上升進行優化,找到使感興趣的活動(層中神經元的激活)最大化的輸入圖像。 最終的輸入圖像將是所選過濾器最大程度地響應的輸入圖像。
每個激活層都有許多特征圖。 以下代碼演示了如何從最后一個激活層提取單個特征圖。 這個激活值實際上是我們要最大化的損失:
```py
layer_name = 'activation_94'
filter_index = 0
layer_output = model.get_layer(layer_name).output
loss = K.mean(layer_output[:, :, :, filter_index])
```
要相對于此`loss`函數計算輸入圖像的梯度,我們可以如下使用`keras`后端梯度函數:
```py
grads = K.gradients(loss, model.input)[0]
# We add 1e-5 before dividing so as to avoid accidentally dividing by
# 0.
grads /= (K.sqrt(K.mean(K.square(grads))) + 1e-5)
```
因此,給定一個激活層和一個可能是隨機噪聲的起始輸入圖像,我們可以使用上面的梯度計算應用梯度上升來獲得特征圖所表示的圖案。 跟隨`generate_pattern`函數執行相同的操作。 歸一化輸出模式,以便我們在圖像矩陣中具有可行的 RGB 值,這是通過使用`deprocess_image`方法完成的。 以下代碼是不言自明的,并具有內聯注釋來解釋每一行:
```py
def generate_pattern(layer_name, filter_index, size=150):
# Build a loss function that maximizes the activation
# of the nth filter of the layer considered.
layer_output = model.get_layer(layer_name).output
loss = K.mean(layer_output[:, :, :, filter_index])
# Compute the gradient of the input picture wrt this loss
grads = K.gradients(loss, model.input)[0]
# Normalization trick: we normalize the gradient
grads /= (K.sqrt(K.mean(K.square(grads))) + 1e-5)
# This function returns the loss and grads given the input picture
iterate = K.function([model.input], [loss, grads])
# We start from a gray image with some noise
input_img_data = np.random.random((1, size, size, 3)) * 20 + 128.
# Run gradient ascent for 40 steps
step = 1.
for i in range(40):
loss_value, grads_value = iterate([input_img_data])
input_img_data += grads_value * step
img = input_img_data[0]
return deprocess_image(img)
def deprocess_image(x):
# normalize tensor: center on 0., ensure std is 0.1
x -= x.mean()
x /= (x.std() + 1e-5)
x *= 0.1
# clip to [0, 1]
x += 0.5
x = np.clip(x, 0, 1)
```
```py
# convert to RGB array
x *= 255
x = np.clip(x, 0, 255).astype('uint8')
return x
```
以下屏幕截圖是某些過濾器層的可視化。 第一層具有各種類型的點圖案:
# DeepDream
**DeepDream** 是一種藝術性的圖像修改技術,它利用了以同名電影命名的深層 CNN 代碼 *Inception* 所學習的表示形式。 我們可以拍攝任何輸入圖像并對其進行處理,以生成令人毛骨悚然的圖片,其中充滿了算法上的擬南芥偽像,鳥羽毛,狗似的面孔,狗眼-這是 DeepDream 修道院在 ImageNet 上接受過訓練的事實,狗在這里繁殖,鳥類種類過多。
DeepDream 算法與使用梯度上升的 ConvNet 過濾器可視化技術幾乎相同,不同之處在于:
* 在 DeepDream 中,最大程度地激活了整個層,而在可視化中,只最大化了一個特定的過濾器,因此將大量特征圖的可視化混合在一起
* 我們不是從隨機噪聲輸入開始,而是從現有圖像開始; 因此,最終的可視化效果將修改先前存在的視覺模式,從而以某種藝術性的方式扭曲圖像的元素
* 輸入圖像以不同的比例(稱為**八度**)進行處理,從而提高了可視化效果的質量
現在,讓我們修改上一部分中的可視化代碼。 首先,我們必須更改`loss`函數和梯度計算。 以下是執行相同操作的代碼:
```py
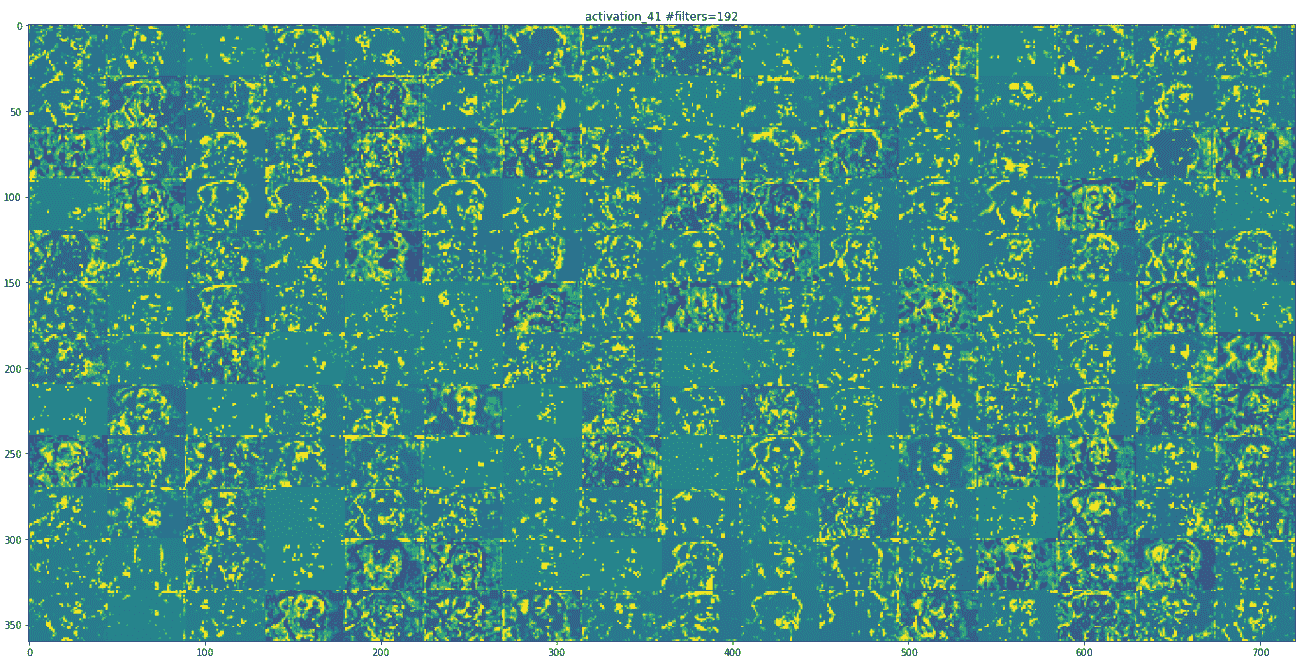
layer_name = 'activation_41'
activation = model.get_layer(layer_name).output
# We avoid border artifacts by only involving non-border pixels in the #loss.
scaling = K.prod(K.cast(K.shape(activation), 'float32'))
loss = K.sum(K.square(activation[:, 2: -2, 2: -2, :])) / scaling
# This tensor holds our generated image
dream = model.input
# Compute the gradients of the dream with regard to the loss.
grads = K.gradients(loss, dream)[0]
# Normalize gradients.
grads /= K.maximum(K.mean(K.abs(grads)), 1e-7)
iterate_grad_ac_step = K.function([dream], [loss, grads])
```
第二個變化是輸入圖像,因此我們必須提供要在其上運行 DeepDream 算法的輸入圖像。 第三個變化是,我們沒有在單個圖像上應用梯度強調,而是創建了各種比例的輸入圖像并應用了梯度強調,如以下代碼所示:
```py
num_octave = 4 # Number of scales at which to run gradient ascent
octave_scale = 1.4 # Size ratio between scales
iterations = 20 # Number of ascent steps per scale
# If our loss gets larger than 10,
# we will interrupt the gradient ascent process, to avoid ugly
# artifacts
max_loss = 20.
base_image_path = 'Path to Image You Want to Use'
# Load the image into a Numpy array
img = preprocess_image(base_image_path)
print(img.shape)
# We prepare a list of shape tuples
# defining the different scales at which we will run gradient ascent
original_shape = img.shape[1:3]
successive_shapes = [original_shape]
for i in range(1, num_octave):
shape = tuple([int(dim / (octave_scale ** i)) for dim in
original_shape])
successive_shapes.append(shape)
# Reverse list of shapes, so that they are in increasing order
successive_shapes = successive_shapes[::-1]
# Resize the Numpy array of the image to our smallest scale
original_img = np.copy(img)
shrunk_original_img = resize_img(img, successive_shapes[0])
print(successive_shapes)
#Example Octaves for image of shape (1318, 1977)
[(480, 720), (672, 1008), (941, 1412), (1318, 1977)]
```
以下代碼顯示了 DeepDream 算法的一些工具函數。 函數`deprocess_image`基本上是 InceptionV3 模型的預處理輸入的逆運算符:
```py
import scipy
def deprocess_image(x):
# Util function to convert a tensor into a valid image.
if K.image_data_format() == 'channels_first':
x = x.reshape((3, x.shape[2], x.shape[3]))
x = x.transpose((1, 2, 0))
else:
x = x.reshape((x.shape[1], x.shape[2], 3))
x /= 2.
x += 0.5
x *= 255.
x = np.clip(x, 0, 255).astype('uint8')
return x
def resize_img(img, size):
img = np.copy(img)
factors = (1,
float(size[0]) / img.shape[1],
float(size[1]) / img.shape[2],
1)
return scipy.ndimage.zoom(img, factors, order=1)
def save_img(img, fname):
pil_img = deprocess_image(np.copy(img))
scipy.misc. (fname, pil_img)
```
在每個連續的音階上,從最小到最大的八度音程,我們都執行梯度上升以使該音階上的先前定義的損耗最大化。 每次梯度爬升后,生成的圖像將放大 40%。 在每個升級步驟中,一些圖像細節都會丟失; 但是我們可以通過添加丟失的信息來恢復它,因為我們知道該比例的原始圖像:
```py
MAX_ITRN = 20
MAX_LOSS = 20
learning_rate = 0.01
for shape in successive_shapes:
print('Processing image shape', shape)
img = resize_img(img, shape)
img = gradient_ascent(img,
iterations=MAX_ITRN,
step=learning_rate,
max_loss=MAX_LOSS)
upscaled_shrunk_original_img = resize_img(shrunk_original_img,
shape)
same_size_original = resize_img(original_img, shape)
lost_detail = same_size_original - upscaled_shrunk_original_img
print('adding lost details', lost_detail.shape)
img += lost_detail
shrunk_original_img = resize_img(original_img, shape)
save_img(img, fname='dream_at_scale_' + str(shape) + '.png')
save_img(img, fname='final_dream.png')
```
# 示例
以下是 DeepDream 輸出的一些示例:
* 在激活層 41 上運行梯度重音。這是我們之前看到的同一層,帶有狗圖像輸入。 在下面的照片中,您可以看到一些動物從云層和藍天中冒出來:

* 在激活層 45 上運行梯度重音。在下圖中,您可以看到山上出現了一些類似狗的動物面孔:

* 在激活層 50 上運行梯度。在下面的照片中,您可以看到在藍天白云下某些特殊的類似葉的圖案夢:

生成這些夢境的原始圖像在代碼存儲庫中共享。
# 總結
在本章中,我們學習了計算機視覺中的算法稀疏。 我們已經解釋了如何通過各種可視化技術來解釋 CNN 模型,例如基于前向通過的激活可視化,基于梯度上升的過濾器可視化。 最后,我們介紹了 DeepDream 算法,該算法再次是對基于梯度上升的可視化技術的略微修改。 DeepDream 算法是將遷移學習應用于計算機視覺或圖像處理任務的示例。
在下一章中,我們將看到更多類似的應用,它們將重點放在風格轉換上。
# 風格遷移
繪畫需要特殊技能,只有少數人已經掌握。 繪畫呈現出內容和風格的復雜相互作用。 另一方面,照片是視角和光線的結合。 當兩者結合時,結果是驚人的和令人驚訝的。 該過程稱為**藝術風格遷移**。 以下是一個示例,其中輸入圖像是德國圖賓根的 Neckarfront,風格圖像是梵高著名的畫作《星空》。 有趣,不是嗎? 看一下以下圖像:

左圖:描繪德國蒂賓根 Neckarfront 的原始照片。 梵高的《星空》)。 來源:《一種藝術風格的神經算法》(Gatys 等人,arXiv:1508.06576v2)
如果您仔細查看前面的圖像,則右側的繪畫風格圖像似乎已經從左側的照片中拾取了內容。 繪畫的風格,顏色和筆觸風格產生了最終結果。 令人著迷的結果是 Gatys 等人在論文[《一種用于藝術風格的神經算法》](https://arxiv.org/abs/1508.06576)中提出的一種遷移學習算法的結果。 我們將從實現的角度討論本文的復雜性,并了解如何自己執行此技術。
在本章中,我們將專注于利用深度學習和傳遞學習來構建神經風格傳遞系統。 本章重點關注的領域包括:
* 了解神經風格轉換
* 圖像預處理方法
* 架構損失函數
* 構造自定義優化器
* 風格遷移實戰
我們將涵蓋有關神經風格遷移,損失函數和優化的理論概念。 除此之外,我們將使用動手方法來實現我們自己的神經風格轉換模型。 本章的代碼可在 [GitHub 存儲庫](https://github.com/dipanjanS/hands-on-transfer-learning-with-python)的第 10 章文件夾中快速參考。 請根據需要參考本章。
# 了解神經風格轉換
**神經風格遷移**是將參考圖像的**風格**應用于特定目標圖像的過程,以使目標圖像的原始**內容**保持不變。 在這里,風格定義為參考圖像中存在的顏色,圖案和紋理,而內容定義為圖像的整體結構和更高層次的組件。
在此,主要目的是保留原始目標圖像的內容,同時在目標圖像上疊加或采用參考圖像的風格。 為了從數學上定義這個概念,請考慮三個圖像:原始內容(表示為`c`),參考風格(表示為`s`)和生成的圖像(表示為`g`)。 我們需要一種方法來衡量在內容方面, `c`和`g`不同的圖像的程度。 同樣,就輸出的風格特征而言,與風格圖像相比,輸出圖像應具有較小的差異。 形式上,神經風格轉換的目標函數可以表述為:
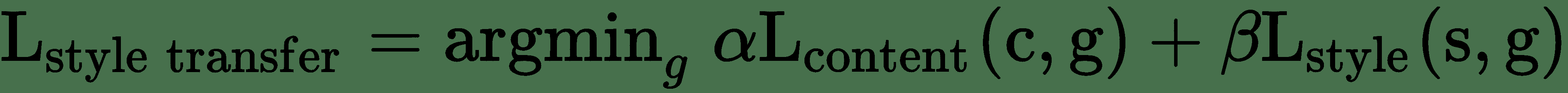
此處,`α`和`β`是用于控制內容和風格成分對整體損失的影響的權重。 此描述可以進一步簡化,并表示如下:
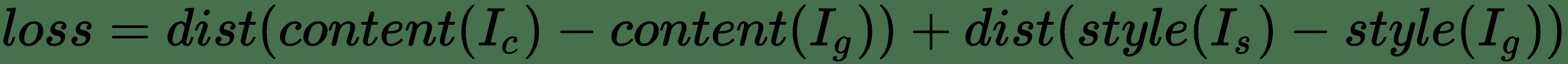
在這里,我們可以根據前面的公式定義以下組件:
* `dist`是規范函數; 例如,L2 規范距離
* `style(...)`是用于為參考風格和生成的圖像計算風格表示的函數
* `content(...)`是一個函數,可為原始內容和生成的圖像計算內容的表示形式
* `I[c]`,`I[s]`和`I[g]`,并分別生成圖像
因此,最小化此損失會導致風格(`I[g]`)接近風格(`I[s]`),以及內容(`I[g]`)接近內容(`I[c]`)。 這有助于我們達成有效的風格轉換所需的規定。 我們將嘗試最小化的損失函數包括三個部分: 即將討論的**內容損失**,**風格損失**和**總變化損失**。 關鍵思想或目標是保留原始目標圖像的*內容*,同時在目標圖像上疊加或采用參考圖像的*風格*。 此外,在神經風格轉換的背景下,您應該記住以下幾點:
* **風格**可以定義為參考圖像中存在的調色板,特定圖案和紋理
* **內容**可以定義為原始目標圖像的整體結構和更高級別的組件
到目前為止,我們知道深度學習對于計算機視覺的真正威力在于利用諸如深層**卷積神經網絡**(**CNN**)模型之類的模型,這些模型可用于在構建這些損失函數時提取正確的圖像表示。 在本章中,我們將使用遷移學習的原理來構建用于神經風格遷移的系統,以提取最佳特征。 在前面的章節中,我們已經討論了與計算機視覺相關的任務的預訓練模型。 在本章中,我們將再次使用流行的 VGG-16 模型作為特征提取器。 執行神經風格轉換的主要步驟如下所示:
* 利用 VGG-16 幫助計算風格,內容和生成圖像的層激活
* 使用這些激活來定義前面提到的特定損失函數
* 最后,使用梯度下降來最大程度地減少總損耗
如果您想更深入地研究神經風格轉換背后的核心原理和理論概念,建議您閱讀以下文章:
* `A Neural Algorithm of Artistic Style, by Leon A. Gatys, Alexander S. Ecker, and?Matthias Bethge (https://arxiv.org/abs/1508.06576)`
* `Perceptual Losses for Real-Time Style Transfer and Super-Resolution, by Justin?Johnson, Alexandre Alahi, and Li Fei-Fei (https://arxiv.org/abs/1603.08155)`
# 圖像預處理方法
在這種情況下,實現此類網絡的第一步也是最重要的一步是對數據或圖像進行預處理。 以下代碼段顯示了一些用于對圖像進行大小和通道調整的快速工具:
```py
import numpy as np
from keras.applications import vgg16
from keras.preprocessing.image import load_img, img_to_array
def preprocess_image(image_path, height=None, width=None):
height = 400 if not height else height
width = width if width else int(width * height / height)
img = load_img(image_path, target_size=(height, width))
img = img_to_array(img)
img = np.expand_dims(img, axis=0)
img = vgg16.preprocess_input(img)
return img
def deprocess_image(x):
# Remove zero-center by mean pixel
x[:, :, 0] += 103.939
x[:, :, 1] += 116.779
x[:, :, 2] += 123.68
# 'BGR'->'RGB'
x = x[:, :, ::-1]
x = np.clip(x, 0, 255).astype('uint8')
return x
```
當我們要編寫自定義損失函數和操作例程時,我們將需要定義某些占位符。 請記住,`keras`是一個利用張量操作后端(例如`tensorflow`,`theano`和`CNTK`)執行繁重工作的高級庫。 因此,這些占位符提供了高級抽象來與基礎張量對象一起使用。 以下代碼段為風格,內容和生成的圖像以及神經網絡的輸入張量準備了占位符:
```py
from keras import backend as K
# This is the path to the image you want to transform.
TARGET_IMG = 'lotr.jpg'
# This is the path to the style image.
REFERENCE_STYLE_IMG = 'pattern1.jpg'
width, height = load_img(TARGET_IMG).size
img_height = 480
img_width = int(width * img_height / height)
target_image = K.constant(preprocess_image(TARGET_IMG,
height=img_height,
width=img_width))
style_image = K.constant(preprocess_image(REFERENCE_STYLE_IMG,
height=img_height,
width=img_width))
# Placeholder for our generated image
generated_image = K.placeholder((1, img_height, img_width, 3))
# Combine the 3 images into a single batch
input_tensor = K.concatenate([target_image,
style_image,
generated_image], axis=0)
```
我們將像前幾章一樣加載預訓練的 VGG-16 模型。 也就是說,沒有頂部的全連接層。 唯一的區別是我們將為模型輸入提供輸入張量的大小尺寸。 以下代碼段有助于我們構建預訓練模型:
```py
model = vgg16.VGG16(input_tensor=input_tensor,
weights='imagenet',
include_top=False)
```
# 構建損失函數
如背景小節所述,神經風格遷移的問題圍繞內容和風格的損失函數。 在本小節中,我們將討論和定義所需的損失函數。
# 內容損失
在任何基于 CNN 的模型中,來自頂層的激活都包含更多的全局和抽象信息(例如,諸如人臉之類的高級結構),而底層將包含局部信息(例如,諸如眼睛,鼻子, 邊緣和角落)。 我們希望利用 CNN 的頂層來捕獲圖像內容的正確表示。 因此,對于內容損失,考慮到我們將使用預訓練的 VGG-16 模型,我們可以將損失函數定義為通過計算得出的頂層激活(給出特征表示)之間的 L2 范數(縮放和平方的歐幾里得距離)。 目標圖像,以及在生成的圖像上計算的同一層的激活。 假設我們通常從 CNN 的頂層獲得與圖像內容相關的特征表示,則預期生成的圖像看起來與基本目標圖像相似。 以下代碼段顯示了計算內容損失的函數:
```py
def content_loss(base, combination):
return K.sum(K.square(combination - base))
```
# 風格損失
關于神經風格遷移的原始論文,[《一種由神經科學風格的神經算法》](https://arxiv.org/abs/1508.06576),由 Gatys 等人撰寫。利用 CNN 中的多個卷積層(而不是一個)來從參考風格圖像中提取有意義的風格和表示,捕獲與外觀或風格有關的信息。 不論圖像內容如何,??在所有空間尺度上都可以工作。風格表示可計算 CNN 不同層中不同特征之間的相關性。
忠于原始論文,我們將利用 **Gram 矩陣**并在由卷積層生成的特征表示上進行計算。 Gram 矩陣計算在任何給定的卷積層中生成的特征圖之間的內積。 內積項與相應特征集的協方差成正比,因此可以捕獲趨于一起激活的層的特征之間的相關性。 這些特征相關性有助于捕獲特定空間比例的圖案的相關匯總統計信息,這些統計信息與風格,紋理和外觀相對應,而不與圖像中存在的組件和對象相對應。
因此,風格損失定義為參考風格的 Gram 矩陣與生成的圖像之間的差異的按比例縮放的 Frobenius 范數(矩陣上的歐幾里得范數)。 最小化此損失有助于確保參考風格圖像中不同空間比例下找到的紋理在生成的圖像中相似。 因此,以下代碼段基于 Gram 矩陣計算定義了風格損失函數:
```py
def style_loss(style, combination, height, width):
def build_gram_matrix(x):
features = K.batch_flatten(K.permute_dimensions(x, (2, 0, 1)))
gram_matrix = K.dot(features, K.transpose(features))
return gram_matrix
S = build_gram_matrix(style)
C = build_gram_matrix(combination)
channels = 3
size = height * width
return K.sum(K.square(S - C))/(4\. * (channels ** 2) * (size ** 2))
```
# 總變化損失
據觀察,僅減少風格和內容損失的優化會導致高度像素化和嘈雜的輸出。 為了解決這個問題,引入了總變化損失。 **總變化損失**與*正則化*損失相似。 引入此方法是為了確保生成的圖像中的空間連續性和平滑性,以避免產生嘈雜的像素化結果。 在函數中的定義如下:
```py
def total_variation_loss(x):
a = K.square(
x[:, :img_height - 1, :img_width - 1, :] - x[:, 1:, :img_width
- 1, :])
b = K.square(
x[:, :img_height - 1, :img_width - 1, :] - x[:, :img_height -
1, 1:, :])
return K.sum(K.pow(a + b, 1.25))
```
# 總損失函數
在定義了用于神經風格傳遞的整體損失函數的組成部分之后,下一步就是將這些構造塊縫合在一起。 由于內容和風格信息是由 CNN 在網絡中的不同深度捕獲的,因此我們需要針對每種損失類型在適當的層上應用和計算損失。 我們將對卷積層進行 1 到 5 層的風格損失,并為每一層設置適當的權重。
這是構建整體損失函數的代碼片段:
```py
# weights for the weighted average loss function
content_weight = 0.05
total_variation_weight = 1e-4
content_layer = 'block4_conv2'
style_layers = ['block1_conv2', 'block2_conv2',
'block3_conv3','block4_conv3', 'block5_conv3']
style_weights = [0.1, 0.15, 0.2, 0.25, 0.3]
# initialize total loss
loss = K.variable(0.)
# add content loss
layer_features = layers[content_layer]
target_image_features = layer_features[0, :, :, :]
combination_features = layer_features[2, :, :, :]
loss += content_weight * content_loss(target_image_features,
combination_features)
# add style loss
for layer_name, sw in zip(style_layers, style_weights):
layer_features = layers[layer_name]
style_reference_features = layer_features[1, :, :, :]
combination_features = layer_features[2, :, :, :]
sl = style_loss(style_reference_features, combination_features,
height=img_height, width=img_width)
loss += (sl*sw)
# add total variation loss
loss += total_variation_weight * total_variation_loss(generated_image)
```
# 構造自定義優化器
目的是在優化算法的幫助下迭代地使總損失最小化。 Gatys 等人的論文中,使用 L-BFGS 算法進行了優化,該算法是基于準牛頓法的一種優化算法,通常用于解決非線性優化問題和參數估計。 該方法通常比標準梯度下降收斂更快。
SciPy 在`scipy.optimize.fmin_l_bfgs_b()`中提供了一個實現。 但是,局限性包括該函數僅適用于平面一維向量,這與我們正在處理的三維圖像矩陣不同,并且損失函數和梯度的值需要作為兩個單獨的函數傳遞。 我們基于模式構建一個`Evaluator`類,然后由`keras`創建者 Fran?oisChollet 創建,以一次計算損失和梯度值,而不是獨立和單獨的計算。 這將在首次調用時返回損耗值,并將緩存下一次調用的梯度。 因此,這將比獨立計算兩者更為有效。 以下代碼段定義了`Evaluator`類:
```py
class Evaluator(object):
def __init__(self, height=None, width=None):
self.loss_value = None
self.grads_values = None
self.height = height
self.width = width
def loss(self, x):
assert self.loss_value is None
x = x.reshape((1, self.height, self.width, 3))
outs = fetch_loss_and_grads([x])
loss_value = outs[0]
grad_values = outs[1].flatten().astype('float64')
self.loss_value = loss_value
self.grad_values = grad_values
return self.loss_value
def grads(self, x):
assert self.loss_value is not None
grad_values = np.copy(self.grad_values)
self.loss_value = None
self.grad_values = None
return grad_values
evaluator = Evaluator(height=img_height, width=img_width)
```
# 風格遷移實戰
難題的最后一步是使用所有構建塊并在操作中執行風格轉換! 可以從數據目錄中獲取藝術/風格和內容圖像,以供參考。 以下代碼片段概述了如何評估損耗和梯度。 我們還按規律的間隔/迭代(`5`,`10`等)寫回輸出,以了解神經風格遷移的過程如何在經過一定的迭代次數后考慮的圖像轉換圖像,如以下代碼段所示:
```py
from scipy.optimize import fmin_l_bfgs_b
from scipy.misc import imsave
from imageio import imwrite
import time
result_prefix = 'st_res_'+TARGET_IMG.split('.')[0]
iterations = 20
# Run scipy-based optimization (L-BFGS) over the pixels of the
# generated image
# so as to minimize the neural style loss.
# This is our initial state: the target image.
# Note that `scipy.optimize.fmin_l_bfgs_b` can only process flat
# vectors.
x = preprocess_image(TARGET_IMG, height=img_height, width=img_width)
x = x.flatten()
for i in range(iterations):
print('Start of iteration', (i+1))
start_time = time.time()
x, min_val, info = fmin_l_bfgs_b(evaluator.loss, x,
fprime=evaluator.grads, maxfun=20)
print('Current loss value:', min_val)
if (i+1) % 5 == 0 or i == 0:
# Save current generated image only every 5 iterations
img = x.copy().reshape((img_height, img_width, 3))
img = deprocess_image(img)
fname = result_prefix + '_iter%d.png' %(i+1)
imwrite(fname, img)
print('Image saved as', fname)
end_time = time.time()
print('Iteration %d completed in %ds' % (i+1, end_time - start_time))
```
到現在為止,必須非常明顯的是,神經風格轉換是一項計算量巨大的任務。 對于所考慮的圖像集,在具有 8GB RAM 的 Intel i5 CPU 上,每次迭代花費了 500-1,000 秒(盡管在 i7 或 Xeon 處理器上要快得多!)。 以下代碼段顯示了我們在 AWS 的 p2.x 實例上使用 GPU 所獲得的加速,每次迭代僅需 25 秒! 以下代碼片段還顯示了一些迭代的輸出。 我們打印每次迭代的損失和時間,并在每五次迭代后保存生成的圖像:
```py
Start of iteration 1
Current loss value: 10028529000.0
Image saved as st_res_lotr_iter1.png
Iteration 1 completed in 28s
Start of iteration 2
Current loss value: 5671338500.0
Iteration 2 completed in 24s
Start of iteration 3
Current loss value: 4681865700.0
Iteration 3 completed in 25s
Start of iteration 4
Current loss value: 4249350400.0
.
.
.
Start of iteration 20
Current loss value: 3458219000.0
Image saved as st_res_lotr_iter20.png
Iteration 20 completed in 25s
```
現在,您將學習神經風格遷移模型如何考慮內容圖像的風格遷移。 請記住,我們在某些迭代之后為每對風格和內容圖像執行了檢查點輸出。 我們利用`matplotlib`和`skimage`加載并了解我們系統執行的風格轉換魔術!
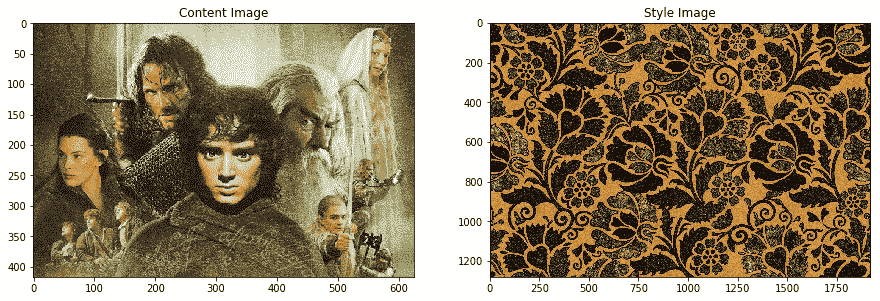
我們將非常受歡迎的《指環王》電影中的以下圖像用作我們的內容圖像,并將基于花卉圖案的精美藝術品用作我們的風格圖像:
在以下代碼段中,我們將在各種迭代之后加載生成的風格化圖像:
```py
from skimage import io
from glob import glob
from matplotlib import pyplot as plt
%matplotlib inline
content_image = io.imread('lotr.jpg')
style_image = io.imread('pattern1.jpg')
iter1 = io.imread('st_res_lotr_iter1.png')
iter5 = io.imread('st_res_lotr_iter5.png')
iter10 = io.imread('st_res_lotr_iter10.png')
iter15 = io.imread('st_res_lotr_iter15.png')
iter20 = io.imread('st_res_lotr_iter20.png')
fig = plt.figure(figsize = (15, 15))
ax1 = fig.add_subplot(6,3, 1)
ax1.imshow(content_image)
t1 = ax1.set_title('Original')
gen_images = [iter1,iter5, iter10, iter15, iter20]
for i, img in enumerate(gen_images):
ax1 = fig.add_subplot(6,3,i+1)
ax1.imshow(content_image)
t1 = ax1.set_title('Iteration {}'.format(i+5))
plt.tight_layout()
fig.subplots_adjust(top=0.95)
t = fig.suptitle('LOTR Scene after Style Transfer')
```
以下是顯示原始圖像和每五次迭代后生成的風格圖像的輸出:
以下是高分辨率的最終風格圖像。 您可以清楚地看到花卉圖案的紋理和風格是如何在原始《指環王》電影圖像中慢慢傳播的,并賦予了其良好的復古外觀:
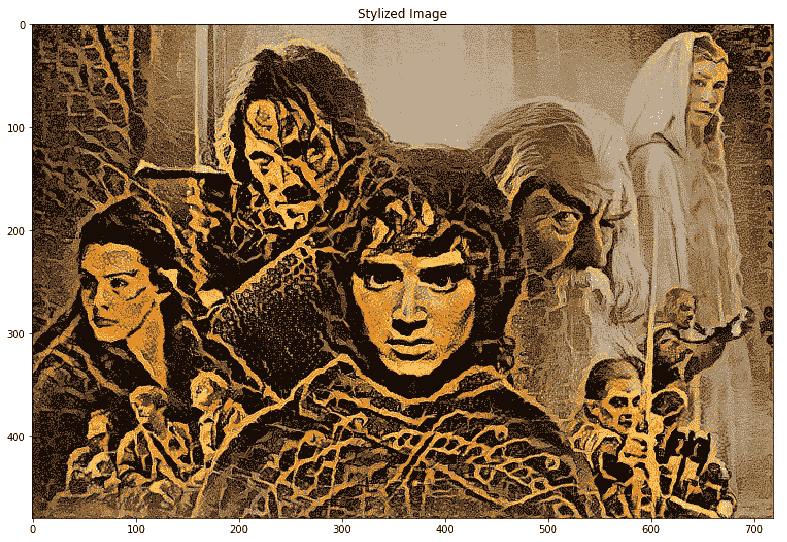
讓我們再舉一個風格遷移示例。 下圖包含我們的內容圖像,即來自黑豹的著名虛構的城市瓦卡達。 風格圖片是梵高非常受歡迎的畫作《星空》! 我們將在風格傳遞系統中將它們用作輸入圖像:
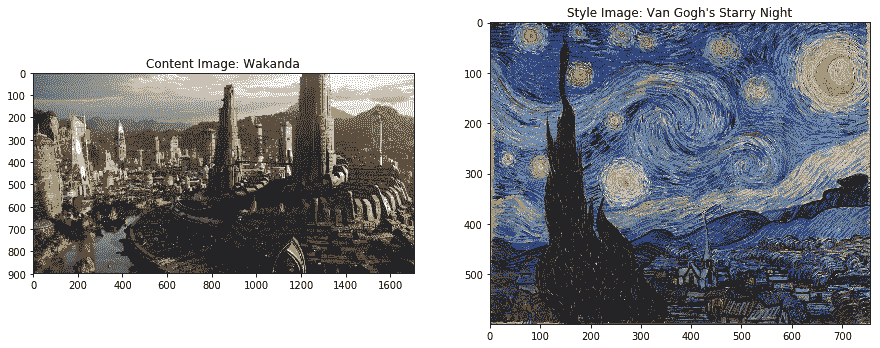
以下是高分辨率的最終風格圖像,顯示在下面的圖像中。 您可以清楚地看到風格繪畫中的紋理,邊緣,顏色和圖案如何傳播到城市內容圖像中:

天空和架構物采用了與您在繪畫中可以觀察到的非常相似的形式,但是內容圖像的整體結構得以保留。 令人著迷,不是嗎? 現在用您自己感興趣的圖像嘗試一下!
# 總結
本章介紹了深度學習領域中一種非常新穎的技術,它利用了深度學習的力量來創造藝術! 確實,數據科學既是一門藝術,也是正確使用數據的科學,而創新則是推動這一發展的事物。 我們介紹了神經風格遷移的核心概念,如何使用有效的損失函數來表示和表達問題,以及如何利用遷移學習的力量和像 VGG-16 這樣的預訓練模型來提取正確的特征表示。
計算機視覺領域不斷發展,深度學習與遷移學習相結合為創新和構建新穎的應用打開了大門。 本章中的示例應幫助您了解該領域的廣泛新穎性,并使您能夠走出去并嘗試新技術,模型和方法來構建諸如神經風格轉換的系統! 隨之而來的是有關圖像標題和著色的更有趣,更復雜的案例研究。 敬請關注!
- TensorFlow 1.x 深度學習秘籍
- 零、前言
- 一、TensorFlow 簡介
- 二、回歸
- 三、神經網絡:感知器
- 四、卷積神經網絡
- 五、高級卷積神經網絡
- 六、循環神經網絡
- 七、無監督學習
- 八、自編碼器
- 九、強化學習
- 十、移動計算
- 十一、生成模型和 CapsNet
- 十二、分布式 TensorFlow 和云深度學習
- 十三、AutoML 和學習如何學習(元學習)
- 十四、TensorFlow 處理單元
- 使用 TensorFlow 構建機器學習項目中文版
- 一、探索和轉換數據
- 二、聚類
- 三、線性回歸
- 四、邏輯回歸
- 五、簡單的前饋神經網絡
- 六、卷積神經網絡
- 七、循環神經網絡和 LSTM
- 八、深度神經網絡
- 九、大規模運行模型 -- GPU 和服務
- 十、庫安裝和其他提示
- TensorFlow 深度學習中文第二版
- 一、人工神經網絡
- 二、TensorFlow v1.6 的新功能是什么?
- 三、實現前饋神經網絡
- 四、CNN 實戰
- 五、使用 TensorFlow 實現自編碼器
- 六、RNN 和梯度消失或爆炸問題
- 七、TensorFlow GPU 配置
- 八、TFLearn
- 九、使用協同過濾的電影推薦
- 十、OpenAI Gym
- TensorFlow 深度學習實戰指南中文版
- 一、入門
- 二、深度神經網絡
- 三、卷積神經網絡
- 四、循環神經網絡介紹
- 五、總結
- 精通 TensorFlow 1.x
- 一、TensorFlow 101
- 二、TensorFlow 的高級庫
- 三、Keras 101
- 四、TensorFlow 中的經典機器學習
- 五、TensorFlow 和 Keras 中的神經網絡和 MLP
- 六、TensorFlow 和 Keras 中的 RNN
- 七、TensorFlow 和 Keras 中的用于時間序列數據的 RNN
- 八、TensorFlow 和 Keras 中的用于文本數據的 RNN
- 九、TensorFlow 和 Keras 中的 CNN
- 十、TensorFlow 和 Keras 中的自編碼器
- 十一、TF 服務:生產中的 TensorFlow 模型
- 十二、遷移學習和預訓練模型
- 十三、深度強化學習
- 十四、生成對抗網絡
- 十五、TensorFlow 集群的分布式模型
- 十六、移動和嵌入式平臺上的 TensorFlow 模型
- 十七、R 中的 TensorFlow 和 Keras
- 十八、調試 TensorFlow 模型
- 十九、張量處理單元
- TensorFlow 機器學習秘籍中文第二版
- 一、TensorFlow 入門
- 二、TensorFlow 的方式
- 三、線性回歸
- 四、支持向量機
- 五、最近鄰方法
- 六、神經網絡
- 七、自然語言處理
- 八、卷積神經網絡
- 九、循環神經網絡
- 十、將 TensorFlow 投入生產
- 十一、更多 TensorFlow
- 與 TensorFlow 的初次接觸
- 前言
- 1.?TensorFlow 基礎知識
- 2. TensorFlow 中的線性回歸
- 3. TensorFlow 中的聚類
- 4. TensorFlow 中的單層神經網絡
- 5. TensorFlow 中的多層神經網絡
- 6. 并行
- 后記
- TensorFlow 學習指南
- 一、基礎
- 二、線性模型
- 三、學習
- 四、分布式
- TensorFlow Rager 教程
- 一、如何使用 TensorFlow Eager 構建簡單的神經網絡
- 二、在 Eager 模式中使用指標
- 三、如何保存和恢復訓練模型
- 四、文本序列到 TFRecords
- 五、如何將原始圖片數據轉換為 TFRecords
- 六、如何使用 TensorFlow Eager 從 TFRecords 批量讀取數據
- 七、使用 TensorFlow Eager 構建用于情感識別的卷積神經網絡(CNN)
- 八、用于 TensorFlow Eager 序列分類的動態循壞神經網絡
- 九、用于 TensorFlow Eager 時間序列回歸的遞歸神經網絡
- TensorFlow 高效編程
- 圖嵌入綜述:問題,技術與應用
- 一、引言
- 三、圖嵌入的問題設定
- 四、圖嵌入技術
- 基于邊重構的優化問題
- 應用
- 基于深度學習的推薦系統:綜述和新視角
- 引言
- 基于深度學習的推薦:最先進的技術
- 基于卷積神經網絡的推薦
- 關于卷積神經網絡我們理解了什么
- 第1章概論
- 第2章多層網絡
- 2.1.4生成對抗網絡
- 2.2.1最近ConvNets演變中的關鍵架構
- 2.2.2走向ConvNet不變性
- 2.3時空卷積網絡
- 第3章了解ConvNets構建塊
- 3.2整改
- 3.3規范化
- 3.4匯集
- 第四章現狀
- 4.2打開問題
- 參考
- 機器學習超級復習筆記
- Python 遷移學習實用指南
- 零、前言
- 一、機器學習基礎
- 二、深度學習基礎
- 三、了解深度學習架構
- 四、遷移學習基礎
- 五、釋放遷移學習的力量
- 六、圖像識別與分類
- 七、文本文件分類
- 八、音頻事件識別與分類
- 九、DeepDream
- 十、自動圖像字幕生成器
- 十一、圖像著色
- 面向計算機視覺的深度學習
- 零、前言
- 一、入門
- 二、圖像分類
- 三、圖像檢索
- 四、對象檢測
- 五、語義分割
- 六、相似性學習
- 七、圖像字幕
- 八、生成模型
- 九、視頻分類
- 十、部署
- 深度學習快速參考
- 零、前言
- 一、深度學習的基礎
- 二、使用深度學習解決回歸問題
- 三、使用 TensorBoard 監控網絡訓練
- 四、使用深度學習解決二分類問題
- 五、使用 Keras 解決多分類問題
- 六、超參數優化
- 七、從頭開始訓練 CNN
- 八、將預訓練的 CNN 用于遷移學習
- 九、從頭開始訓練 RNN
- 十、使用詞嵌入從頭開始訓練 LSTM
- 十一、訓練 Seq2Seq 模型
- 十二、深度強化學習
- 十三、生成對抗網絡
- TensorFlow 2.0 快速入門指南
- 零、前言
- 第 1 部分:TensorFlow 2.00 Alpha 簡介
- 一、TensorFlow 2 簡介
- 二、Keras:TensorFlow 2 的高級 API
- 三、TensorFlow 2 和 ANN 技術
- 第 2 部分:TensorFlow 2.00 Alpha 中的監督和無監督學習
- 四、TensorFlow 2 和監督機器學習
- 五、TensorFlow 2 和無監督學習
- 第 3 部分:TensorFlow 2.00 Alpha 的神經網絡應用
- 六、使用 TensorFlow 2 識別圖像
- 七、TensorFlow 2 和神經風格遷移
- 八、TensorFlow 2 和循環神經網絡
- 九、TensorFlow 估計器和 TensorFlow HUB
- 十、從 tf1.12 轉換為 tf2
- TensorFlow 入門
- 零、前言
- 一、TensorFlow 基本概念
- 二、TensorFlow 數學運算
- 三、機器學習入門
- 四、神經網絡簡介
- 五、深度學習
- 六、TensorFlow GPU 編程和服務
- TensorFlow 卷積神經網絡實用指南
- 零、前言
- 一、TensorFlow 的設置和介紹
- 二、深度學習和卷積神經網絡
- 三、TensorFlow 中的圖像分類
- 四、目標檢測與分割
- 五、VGG,Inception,ResNet 和 MobileNets
- 六、自編碼器,變分自編碼器和生成對抗網絡
- 七、遷移學習
- 八、機器學習最佳實踐和故障排除
- 九、大規模訓練
- 十、參考文獻