
# 七、文本文件分類
在本章中,我們討論了遷移學習在文本文檔分類中的應用。 文本分類是一種非常流行的自然語言處理任務。 關鍵目標是根據文檔的文本內容將文檔分配到一個或多個類別或類別。 這在行業中得到了廣泛的應用,包括將電子郵件分類為垃圾郵件/非垃圾郵件,審閱和評級分類,情感分析,電子郵件或事件路由,在此我們將電子郵件\事件分類,以便可以將其自動分配給相應的人員。 以下是本章將涉及的主要主題:
* 文本分類概述,行業應用和挑戰
* 基準文本分類數據集和傳統模型的表現
* 密集向量的單詞表示 — 深度學習模型
* CNN 文檔模型-單詞到句子的嵌入,然后進行文檔嵌入
* 源和目標域分布不同的遷移學習的應用; 也就是說,源域由重疊較少的類組成,目標域具有許多混合類
* 源和目標域本身不同的遷移學習的應用(例如,源是新聞,目標是電影評論,依此類推)
* 訓練有素的模型在完成其他文本分析任務(例如文檔摘要)中的應用-解釋為什么將評論歸類為負面/正面
我們將通過動手示例來關注概念和實際實現。 您可以在 [GitHub 存儲庫](https://github.com/dipanjanS/hands-on-transfer-learning-with-python)中的`Chapter 7`文件夾中快速閱讀本章的代碼。 可以根據需要參考本章。
# 文本分類
給定一組文本文檔和一組預定義類別,文本分類的目的是將每個文檔分配給一個類別。 根據問題,輸出可以是軟分配或硬分配。 軟分配意味著將類別分配定義為所有類別上的概率分布。
文本分類在工業中有廣泛的應用。 以下是一些示例:
* **垃圾郵件過濾**:給定電子郵件,將其分類為垃圾郵件或合法電子郵件。
* **情感分類**:給定評論文本(電影評論,產品評論),請確定用戶的極性-無論是正面評論,負面評論還是神經評論。
* **問題單分配**:通常,在任何行業中,每當用戶遇到有關任何 IT 應用或軟件/硬件產品的問題時,第一步就是創建問題單。 這些票證是描述用戶所面臨問題的文本文檔。 下一個合乎邏輯的步驟是,某人必須閱讀說明并將其分配給具有適當專業知識的團隊才能解決問題。 現在,給定一些歷史故障單和解決方案團隊類別,可以構建文本分類器以自動對問題故障單進行分類。
* **問題單的自動解決方案**:在某些情況下,問題的解決方案也是預先定義的; 也就是說,專家團隊知道解決該問題應遵循的步驟。 因此,在這種情況下,如果可以高精度地構建文本分類器來對票證進行分類,則一旦預測了票證類別,便可以運行自動腳本來直接解決問題。 這是未來 **IT 運營人工智能**(**AIOps**)的目標之一。
* **有針對性的營銷**:營銷人員可以監視社交媒體中的用戶,并將其分類為促進者或破壞者,并基于此,對在線產品發表評論。
* **體裁分類**:自動文本體裁分類對于分類和檢索非常重要。 即使一組文檔屬于同一類別,因為它們共享一個共同的主題,但它們通常具有不同的用途,屬于不同的流派類別。 如果可以檢測到搜索數據庫中每個文檔的類型,則可以根據用戶的喜好更好地向用戶呈現信息檢索結果。
* **索賠中的欺詐檢測**:分析保險索賠文本文檔并檢測索賠是否為欺詐。
# 傳統文本分類
構建文本分類算法/模型涉及一組預處理步驟以及將文本數據正確表示為數值向量。 以下是一般的預處理步驟:
1. **句子拆分**:將文檔拆分為一組句子。
2. **分詞**:將句子拆分為組成詞。
3. **詞干或詞根去除**:單詞標記被簡化為它們的基本形式。 例如,諸如演奏,演奏和演奏之類的單詞具有一個基數:*演奏*。 詞干的基本單詞輸出不必是詞典中的單詞。 而來自殘詞化的根詞,也稱為**引理**,將始終存在于字典中。
4. **文本清除**:大小寫轉換,更正拼寫并刪除停用詞和其他不必要的單詞。
給定文本文檔的語料庫,我們可以應用前面的步驟,然后獲得構成語料庫的單詞的純凈詞匯。 下一步是文本表示。 **詞袋**(**BoW**)模型是從文本文檔中提取特征并創建文本向量表示的最簡單但功能最強大的技術之一。 如果我們在提取的詞匯表中有`N`個單詞,則任何文檔都可以表示為`D = {w[1], w[2], ...`,其中`w[i]`代表文檔中單詞出現的頻率。 這種文本作為稀疏向量的表示稱為 BoW 模型。 在這里,我們不考慮文本數據的順序性質。 一種部分捕獲順序信息的方法是在構建詞匯表時考慮單詞短語或 n-gram 和單個單詞特征。 但是,挑戰之一是我們的代表人數。 也就是說,我們的詞匯量爆炸了。
文檔向量也可以表示為二元向量,其中每個`w[i] ∈ {0, 1}`表示文檔中單詞的存在或不存在。 最受歡迎的表示形式是單詞頻率的歸一化表示形式,稱為**詞頻-逆文檔頻率**(**TF-IDF**)表示形式。 通過將我們語料庫中的文檔總數除以每個單詞的文檔頻率,然后對結果應用對數縮放,可以計算出 IDF 表示的文檔逆頻率。 TF-IDF 值是*詞頻*與*逆文檔頻率*的乘積。 它與單詞在文檔中出現的次數成正比地增加,并根據語料庫中單詞的頻率按比例縮小,這有助于調整某些單詞通常更頻繁出現的事實。
現在,我們都準備建立一個分類模型。 我們需要一套帶有標簽的文件或訓練數據。 以下是一些流行的文本分類算法:
* 多項式樸素貝葉斯
* 支持向量機
* K 最近鄰
具有線性核的**支持向量機**(**SVM**)與用于文本分類的基準數據集相比,通常顯示出更高的準確率。
# BoW 模型的缺點
使用基于單詞計數的 BoW 模型,我們將丟失其他信息,例如每個文本文檔中附近單詞周圍的語義,結構,序列和上下文。 在 BoW 中,具有相似含義的單詞將得到不同的對待。 其他文本模型是**潛在語義索引**(**LSI**),其中文檔以低維度(k 遠小于詞匯量)-隱藏的主題空間表示。 在 LSI 中,文檔中的組成詞也可以表示為`k`維密集向量。 據觀察,在 LSI 模型中,具有相似語義的單詞具有緊密的表示形式。 而且,單詞的這種密集表示是將深度學習模型應用于文本的第一步,被稱為**單詞嵌入**。 基于神經網絡的語言模型試圖通過查看語料庫中的單詞序列來預測其相鄰單詞的單詞,并在此過程中學習分布式表示,從而使我們能夠密集地嵌入單詞。
# 基準數據集
以下是大多數文本分類研究中使用的基準數據集的列表:
* **IMDB 電影評論數據集**:這是用于二元情感分類的數據集。 它包含一組用于訓練的 25,000 條電影評論和用于測試的 25,000 條電影。 也有其他未標記的數據可供使用。 該數據集可從[這個鏈接](http://ai.stanford.edu/~amaas/data/sentiment/)下載。
* **路透數據集**:此數據集包含 90 個類別,9,584 個訓練文檔和 3,744 個測試文檔。 它是包`nltk.corpus`的一部分。 該數據集中文檔的類分布非常不正確,其中兩個最常見的類包含大約所有文檔的 70%。 即使僅考慮 10 個最頻繁的類,該數據集中的兩個最頻繁的類也擁有大約 80% 的文檔。 因此,大多數分類結果都是在這些最常見的類別的子集上進行評估的,它們在訓練集中的最常見的 8、10 和 52 類別分別命名為 R8,R10 和 R52。
* **20 個新聞組數據集**:此數據被組織成 20 個不同的新聞組,每個新聞組對應一個不同的主題。 一些新聞組彼此之間有著非常密切的關聯(例如:`comp.sys.ibm.pc.hardware` / `comp.sys.mac.hardware`),而其他新聞組則是高度不相關的(例如:`misc.forsale` / `soc.religion.christian`)。 這是 20 個新聞組的列表,根據主題分為六個主要類別。 該數據集在`sklearn.datasets`中可用:
| | | |
| --- | --- | --- |
| `comp.graphics`,`comp.os.ms-windows.misc`,`comp.sys.ibm.pc.hardware`,`comp.sys.mac.hardware`,`comp.windows.x` | `rec.autos`,`rec.motorcycles`,`rec.sport.baseball`,`rec.sport.hockey` | `sci.crypt`,`sci.electronics`,`sci.med`,`sci.space` |
| `misc.forsale` | `talk.politics.misc`,`talk.politics.guns`,`talk.politics.mideast` | `talk.religion.misc`,`alt.atheism`,`soc.religion.christian` |
稍后我們將討論如何加載此數據集以進行進一步分析。
# 單詞表示
讓我們看一下這些用于處理文本數據并從中提取有意義的特征或單詞嵌入的高級策略,這些策略可用于其他**機器學習**(**ML**)系統中,以執行更高級的任務,例如分類,摘要和翻譯。 我們可以將學習到的單詞表示形式轉移到另一個模型中。 如果我們擁有大量的訓練數據,則可以與最終任務一起共同學習單詞嵌入。
# Word2vec 模型
該模型由 Google 于 2013 年創建,是一種基于深度學習的預測模型,該模型可計算并生成高質量,分布式和連續密集的單詞向量表示,從而捕獲上下文和語義相似性。 從本質上講,這些是無監督模型,可以吸收大量文本語料庫,創建可能單詞的詞匯表,并為代表該詞匯表的向量空間中的每個單詞生成密集的單詞嵌入。 通常,您可以指定單詞嵌入向量的大小,向量的總數本質上是詞匯表的大小。 這使得該密集向量空間的維數大大低于使用傳統 BoW 模型構建的高維稀疏向量空間。
Word2vec 可以利用兩種不同的模型架構來創建這些詞嵌入表示。 這些是:
* **連續詞袋**(**CBOW**)模型
* **SkipGram**模型
CBOW 模型架構嘗試根據源上下文單詞(環繞單詞)來預測當前的目標單詞(中心單詞)。 考慮一個簡單的句子`the quick brown fox jumps over the lazy dog`,這可以是一對`context_window`和`target_word`,如果我們考慮一個大小為 2 的上下文窗口,我們有一些例子,像`([quick, fox], brown)`,`([the, brown], quick)`,`([the, dog], lazy)`,依此類推。 因此,該模型嘗試根據上下文窗口詞來預測目標詞。 Word2vec 系列模型是不受監管的; 這意味著您可以給它一個語料庫,而無需附加標簽或信息,并且它可以從語料庫構建密集的單詞嵌入。 但是,一旦有了這個語料庫,您仍然需要利用監督分類方法。 但是我們將在沒有任何輔助信息的情況下從語料庫內部進行操作。 我們可以將此 CBOW 架構建模為深度學習分類模型,以便將上下文詞作為輸入`X`,并嘗試預測目標詞`Y`。 實際上,構建這種架構比跳過語法模型更簡單,在該模型中,我們嘗試從源目標詞預測一大堆上下文詞。
跳過語法模型架構通常嘗試實現與 CBOW 模型相反的功能。 它嘗試在給定目標詞(中心詞)的情況下預測源上下文詞(環繞詞)。 考慮一下前面的簡單句子`the quick brown fox jumps over the lazy dog`。 如果我們使用 CBOW 模型,則會得到(`context_window`和`target_word`)對,其中,如果考慮大小為 2 的上下文窗口,則有示例,類似`([quick, fox], brown)`,`([the, brown], quick)`,`([the, dog], lazy)`等。 現在,考慮到跳過語法模型的目的是根據目標單詞預測上下文,該模型通常會反轉上下文和目標,并嘗試根據其目標單詞預測每個上下文單詞。
因此,任務變為給定目標單詞`brown`來預測上下文`[quick, fox]`,或給定目標單詞`quick`來預測上下文`[the, brown]`,依此類推。 因此,模型試圖基于`target_word`來預測`context_window`單詞。
以下是前兩個模型的架構圖:
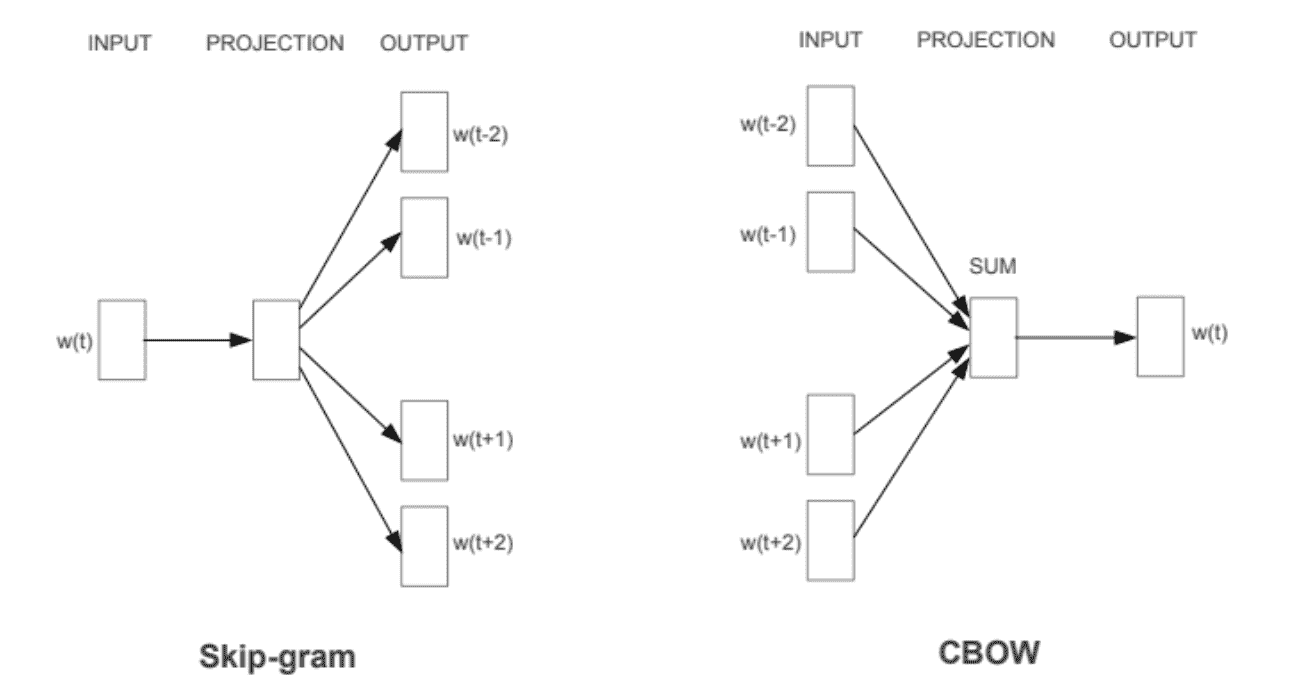
[我們可以在以下博客文章中找到這些模型在 Keras 中的實現](https://towardsdatascience.com/understanding-feature-engineering-part-4-deep-learning-methods-for-text-data-96c44370bbfa)。
# 使用 Gensim 的 Word2vec
Radim Rehurek 創建的 gensim 框架由 [Word2vec 模型](https://radimrehurek.com/gensim/models/word2vec.html)的可靠,高效且可擴展的實現組成。 它使我們可以選擇跳躍語法模型或 CBOW 模型之一。 讓我們嘗試學習和可視化 IMDB 語料庫的詞嵌入。 如前所述,它有 50,000 個帶標簽的文檔和 50,000 個無標簽的文檔。 對于學習單詞表示,我們不需要任何標簽,因此可以使用所有可用的 100,000 個文檔。
首先加載完整的語料庫。 下載的文檔分為`train`,`test`和`unsup`文件夾:
```py
def load_imdb_data(directory = 'train', datafile = None):
'''
Parse IMDB review data sets from Dataset from
http://ai.stanford.edu/~amaas/data/sentiment/
and save to csv.
'''
labels = {'pos': 1, 'neg': 0}
df = pd.DataFrame()
for sentiment in ('pos', 'neg'):
path =r'{}/{}/{}'.format(config.IMDB_DATA, directory,
sentiment)
for review_file in os.listdir(path):
with open(os.path.join(path, review_file), 'r',
encoding= 'utf-8') as input_file:
review = input_file.read()
df = df.append([[utils.strip_html_tags(review),
labels[sentiment]]],
ignore_index=True)
df.columns = ['review', 'sentiment']
indices = df.index.tolist()
np.random.shuffle(indices)
indices = np.array(indices)
df = df.reindex(index=indices)
if datafile is not None:
df.to_csv(os.path.join(config.IMDB_DATA_CSV, datafile),
index=False)
return df
```
我們可以將所有三個數據源結合起來,得到 100,000 個文檔的列表,如下所示:
```py
corpus = unsupervised['review'].tolist() + train_df['review'].tolist()
+ test_df['review'].tolist()
```
我們可以對該語料進行預處理,并將每個文檔轉換為單詞標記序列。 為此,我們使用`nltk`。 然后,我們可以開始進行如下訓練。 我們使用了大量的迭代,因此需要 6-8 個小時的時間來訓練 CPU:
```py
# tokenize sentences in corpus
wpt = nltk.WordPunctTokenizer()
tokenized_corpus = [wpt.tokenize(document.lower()) for document in corpus]
w2v_model = word2vec.Word2Vec(tokenized_corpus, size=50,
window=10, min_count=5,
sample=1e-3, iter=1000)
```
現在讓我們看看該模型學到了什么。 讓我們從這個語料庫中選擇一些見解的詞。 [可以在以下位置找到電影評論中通常使用的大量意見詞](http://member.tokoha-u.ac.jp/~dixonfdm/Writing%20Topics%20htm/Movie%20Review%20Folder/movie_descrip_vocab.htm)。 我們首先將找到與這些給定單詞具有相似嵌入的前五個單詞。 以下是此代碼:
```py
similar_words = {search_term: [item[0] for item in w2v_model.wv.most_similar([search_term], topn=5)]
for search_term in ['good','superior','violent',
'romantic','nasty','unfortunate',
'predictable', 'hilarious',
'fascinating', 'boring','confused',
'sensitive',
'imaginative','senseless',
'bland','disappointing']}
pd.DataFrame(similar_words).transpose()
```
前面的代碼的輸出如下:
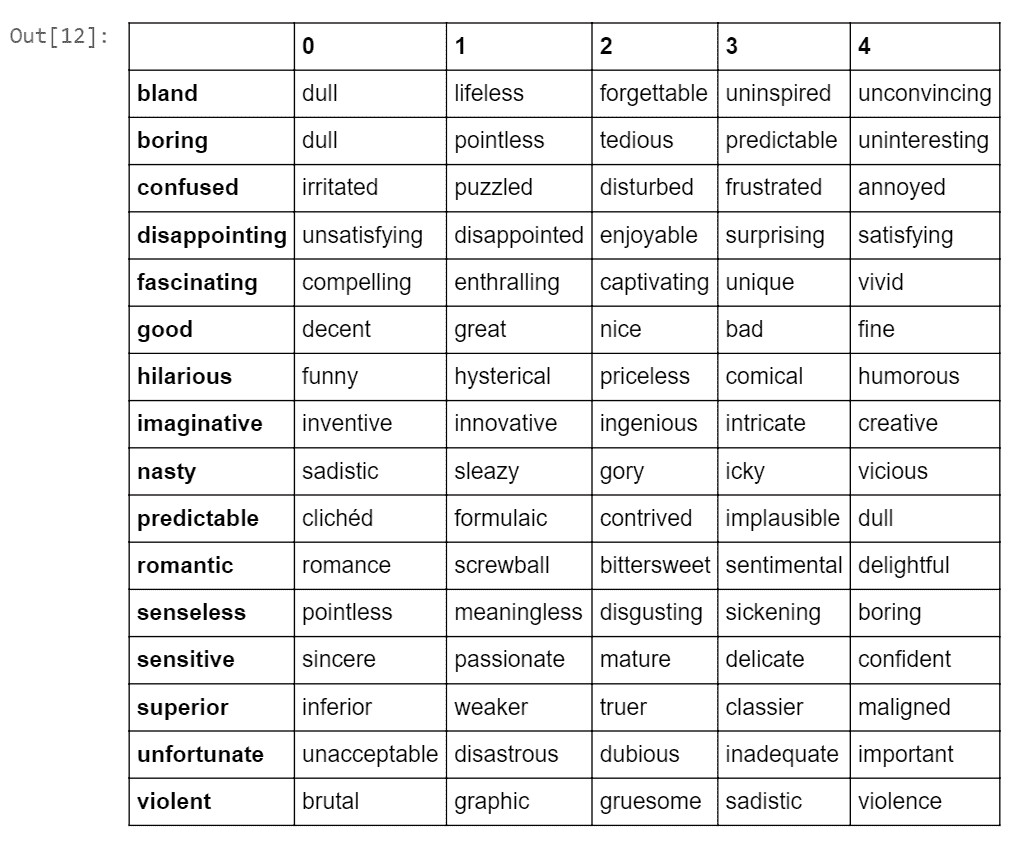
我們可以看到,學習到的嵌入表示具有相似嵌入向量的相似上下文中使用的單詞。 這些詞不必一直都是同義詞,它們也可以相反。 但是,它們在類似的上下文中使用。
# GloVe 模型
GloVe 模型代表全局向量,它是一種無監督的學習模型,可用于獲取類似于 Word2Vec 的密集詞向量。 但是,該技術不同,并且對聚合的全局單詞-單詞共現矩陣執行訓練,從而為我們提供了具有有意義子結構的向量空間。 該方法發表在 Pennington 及其合作者的論文[《GloVe:用于詞表示的全局向量》](https://www.aclweb.org/anthology/D14-1162)。 我們已經討論了基于計數的矩陣分解方法,例如**潛在語義分析**(**LSA**)和預測方法,例如 Word2vec。 本文聲稱,目前這兩個家庭都遭受重大弊端。 像 LSA 之類的方法可以有效地利用統計信息,但是它們在詞類比任務上的表現相對較差-我們是如何找到語義相似的詞的。 像 skip-gram 這樣的方法在類比任務上可能會做得更好,但它們在全局級別上卻很少利用語料庫的統計信息。
GloVe 模型的基本方法是首先創建一個龐大的單詞-上下文共現矩陣,該矩陣由(單詞,上下文)對組成,這樣該矩陣中的每個元素都代表一個單詞在上下文中出現的頻率(可以是一個單詞序列)。 這個詞-語境矩陣`WC`與在各種任務的文本分析中普遍使用的單詞-文檔矩陣非常相似。 矩陣分解用于將矩陣`WC`表示為兩個矩陣的乘積。 **字特征**(**WF**)矩陣和**特征上下文**(**FC**)矩陣。 `WC = WF x FC`。 用一些隨機權重初始化`WF`和`FC`,然后將它們相乘得到`WC'`(近似于`WC`)并測量與`WC`有多近。 我們使用**隨機梯度下降**(**SGD**)進行多次操作,以最大程度地減少誤差。 最后,`WF`矩陣為我們提供了每個單詞的單詞嵌入,其中`F`可以預設為特定數量的維。 要記住的非常重要的一點是,Word2vec 和 GloVe 模型在工作方式上非常相似。 他們兩個的目的都是建立一個向量空間,每個詞的位置根據其上下文和語義而受到其相鄰詞的影響。 Word2vec 從單詞共現對的本地單個示例開始,而 GloVe 從整個語料庫中所有單詞的全局匯總共現統計開始。
在以下各節中,我們將同時使用 Word2vec 和 GloVe 來解決各種分類問題。 我們已經開發了一些工具代碼,可從文件讀取和加載 GloVe 和 Word2vec 向量,并返回嵌入矩陣。 預期的文件格式是標準 GloVe 文件格式。 以下是幾個單詞的五維嵌入格式示例:單詞后跟向量,所有空格分開:
* 甩動`7.068106 -5.410074 1.430083 -4.482612 -1.079401`
* 心`-1.584336 4.421625 -12.552878 4.940779 -5.281123`
* 側面`0.461367 4.773087 -0.176744 8.251079 -11.168787`
* 恐怖`7.324110 -9.026680 -0.616853 -4.993752 -4.057131`
以下是讀取 GloVe 向量的主要函數,給定一個詞匯表作為 Python 字典,字典鍵作為詞匯表中的單詞。 僅需要為我們的訓練詞匯中出現的單詞加載所需的嵌入。 同樣,用所有嵌入的均值向量和一些白噪聲來初始化 GloVe 嵌入中不存在的詞匯。 `0`和`1`行專用于空格和**語音外**(**OOV**)單詞。 這些單詞不在詞匯表中,而是在語料庫中,例如非常少見的單詞或一些過濾掉的雜音。 空間的嵌入是零向量。 OOV 的嵌入是所有其余嵌入的均值向量:
```py
def _init_embedding_matrix(self, word_index_dict,
oov_words_file='OOV-Words.txt'):
# reserve 0, 1 index for empty and OOV
self.embedding_matrix = np.zeros((len(word_index_dict)+2 ,
self.EMBEDDING_DIM))
not_found_words=0
missing_word_index = []
with open(oov_words_file, 'w') as f:
for word, i in word_index_dict.items():
embedding_vector = self.embeddings_index.get(word)
if embedding_vector is not None:
# words not found in embedding index will be all-
zeros.
self.embedding_matrix[i] = embedding_vector
else:
not_found_words+=1
f.write(word + ','+str(i)+'\n')
missing_word_index.append(i)
#oov by average vector:
self.embedding_matrix[1] = np.mean(self.embedding_matrix,
axis=0)
```
```py
for indx in missing_word_index:
self.embedding_matrix[indx] =
np.random.rand(self.EMBEDDING_DIM)+
self.embedding_matrix[1]
print("words not found in embeddings:
{}".format(not_found_words))
```
另一個工具函數是`update_embeddings`。 這是轉學的必要條件。 我們可能希望將一個模型學習的嵌入更新為另一模型學習的嵌入:
```py
def update_embeddings(self, word_index_dict, other_embedding, other_word_index):
num_updated = 0
for word, i in other_word_index.items():
if word_index_dict.get(word) is not None:
embedding_vector = other_embedding[i]
this_vocab_word_indx = word_index_dict.get(word)
self.embedding_matrix[this_vocab_word_indx] =
embedding_vector
num_updated+=1
print('{} words are updated out of {}'.format(num_updated,
len(word_index_dict)))
```
# CNN 文件模型
先前我們看到了詞嵌入如何能夠捕獲它們表示的概念之間的許多語義關系。 現在,我們將介紹一個 ConvNet 文檔模型,該模型可構建文檔的分層分布式表示形式。 這發表在 [Misha Denil 等人的論文](https://arxiv.org/pdf/1406.3830.pdf)中。 該模型分為兩個級別,一個句子級別和一個文檔級別,這兩個級別都使用 ConvNets 實現。 在句子級別,使用 ConvNet 將每個句子中單詞的嵌入轉換為整個句子的嵌入。 在文檔級別,另一個 ConvNet 用于將句子嵌入轉換為文檔嵌入。
在任何 ConvNet 架構中,卷積層之后都是子采樣/池化層。 在這里,我們使用 k-max 池。 k-max 合并操作與正常 max 合并略有不同,后者從神經元的滑動窗口獲取最大值。 在 k-max 合并操作中,最大的`k`神經元取自下一層中的所有神經元。 例如,對`[3, 1, 5, 2]`應用 2-max 合并將產生`[3, 5]`。 在這里,內核大小為 3 且步幅為 1 的常規最大池將得到相同的結果。 讓我們來考慮另一種情況。 如果我們對`[1, 2, 3, 4, 5]`應用最大池,則將得到`[3, 5]`,但是 2-max 池將給出`[4, 5]`。 K-max 池可以應用于可變大小的輸入,并且我們仍然可以獲得相同數量的輸出單元。
下圖描述了**卷積神經網絡**(**CNN**)架構。 我們已針對各種用例對該結構進行了一些微調,將在此處進行討論:
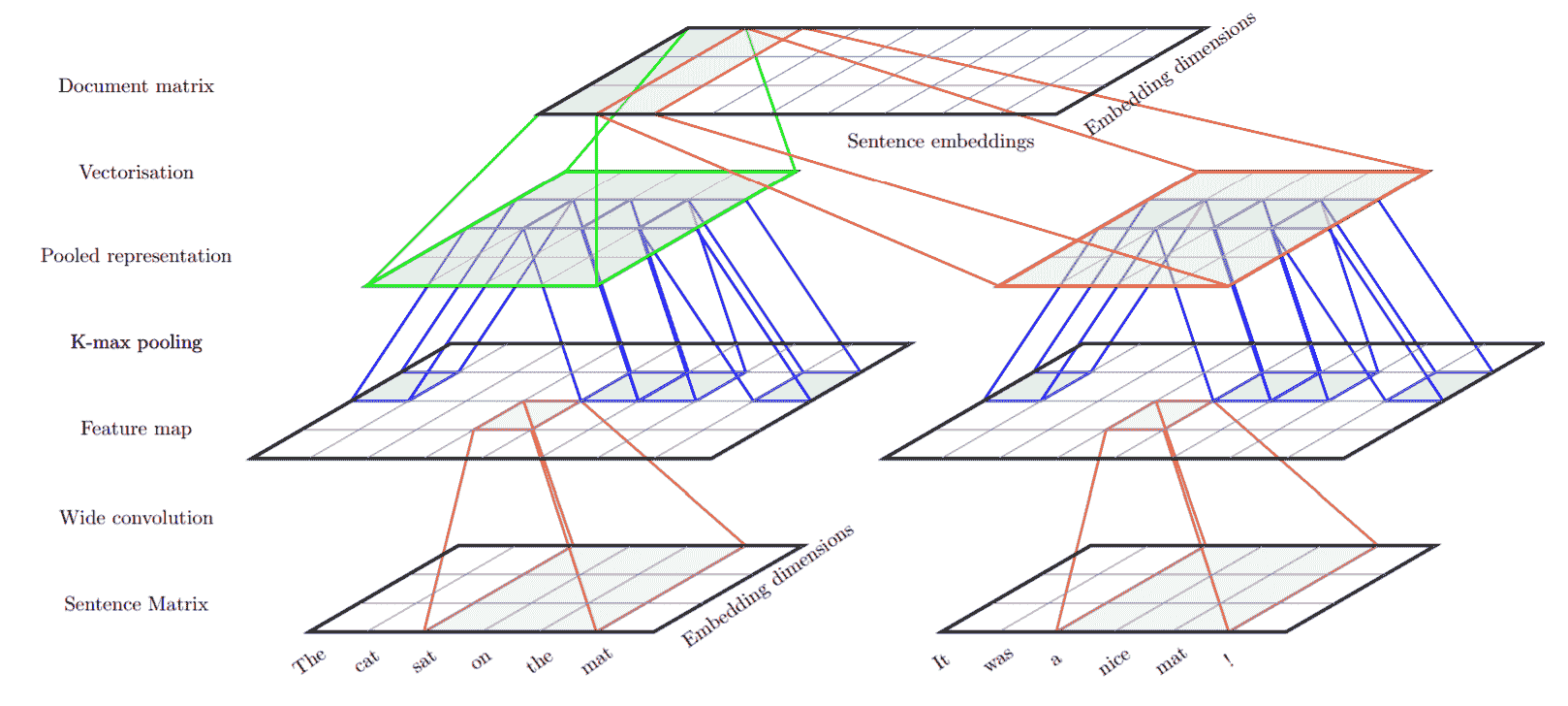
此網絡的輸入層未在此處顯示。 輸入層按順序是文檔中的句子序列,其中每個句子由單詞索引序列表示。 以下代碼段描述了在給定訓練語料庫的情況下如何定義單詞索引。 索引 0 和 1 保留用于空字和 OOV 字。 首先,將語料庫中的文檔標記為單詞。 非英語單詞被過濾掉。 同樣,計算整個語料庫中每個單詞的頻率。 對于大型語料庫,我們可以從詞匯表中過濾掉不常用的詞。 然后,為詞匯表中的每個單詞分配一個整數索引:
```py
from nltk.tokenize import sent_tokenize, wordpunct_tokenize
import re
corpus = ['The cat sat on the mat . It was a nice mat !',
'The rat sat on the mat . The mat was damaged found at 2 places.']
vocab ={}
word_index = {}
for doc in corpus:
for sentence in sent_tokenize(doc):
tokens = wordpunct_tokenize(sentence)
tokens = [token.lower().strip() for token in tokens]
tokens = [token for token in tokens
if re.match('^[a-z,.;!?]+$',token) is not None ]
for token in tokens:
vocab[token] = vocab.get(token, 0)+1
# i= 0 for empty, 1 for OOV
i = 2
for word, count in vocab.items():
word_index[word] = i
i +=1
print(word_index.items())
#Here is the output:
dict_items([('the', 2), ('cat', 3), ('sat', 4), ('on', 5), ('mat', 6), ('.', 7), ('it', 8), ('was', #9), ('a', 10), ('nice', 11), ('!', 12), ('rat', 13), ('damaged', 14), ('found', 15), ('at', 16), ('places', 17)])
```
現在,可以將語料庫轉換為單詞索引數組。 在語料庫中,不同的句子和文檔的長度不同。 盡管卷積可以處理任意寬度的輸入,但是為了簡化實現,我們可以為網絡定義一個固定大小的輸入。 我們可以將短句子置零,并截斷較長的句子以適應固定的句子長度,并在文檔級別執行相同的操作。 在下面的代碼片段中,我們顯示了如何使用`keras.preprocessing`模塊對句子和文檔進行零填充并準備數據:
```py
from keras.preprocessing.sequence import pad_sequences
SENTENCE_LEN = 10; NUM_SENTENCES=3;
for doc in corpus:
doc2wordseq = []
sent_num =0
for sentence in sent_tokenize(doc):
words = wordpunct_tokenize(sentence)
words = [token.lower().strip() for token in words]
word_id_seq = [word_index[word] if word_index.get(word) is not
None \
else 1 for word in words]
padded_word_id_seq = pad_sequences([word_id_seq],
maxlen=SENTENCE_LEN,
padding='post',
truncating='post')
if sent_num < NUM_SENTENCES:
doc2wordseq = doc2wordseq + list(padded_word_id_seq[0])
doc2wordseq = pad_sequences([doc2wordseq],
maxlen=SENTENCE_LEN*NUM_SENTENCES,
padding='post',
truncating='post')
print(doc2wordseq)
# sample output
[ 2 3 4 5 2 6 7 0 0 0 8 9 10 11 6 12 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 2 13 4 5 2 6 7 0 0 0 2 6 9 14 15 16 1 17 7 0 0 0 0 0 0 0 0 0 0 0]
```
因此,您可以看到每個文檔輸入都是一個尺寸為`doc_length = SENTENCE_LEN * NUM_SENTENCES`的一維張量。 這些張量通過網絡的第一層,即嵌入層,以將單詞索引轉換為密集的單詞表示形式,然后得到形狀為`doc_length×embedding_dimension`的二維張量。 所有先前的預處理代碼都捆綁在`Preprocess`類中,并具有`fit`和`transform`方法,例如`scikit`模塊。 `fit`方法將訓練語料庫作為輸入,構建詞匯表,并為詞匯表中的每個單詞分配單詞索引。 然后,可以使用`transform`方法將測試或保留集轉換為填充的單詞索引序列,如先前所示。 `transform`方法將使用由`fit`計算的單詞索引。
可以使用 GloVe 或 Word2vec 初始化嵌入矩陣。 在這里,我們使用了 50 維 GloVe 嵌入來初始化嵌入矩陣。 在 GloVe 和 OOV 單詞中找不到的單詞初始化如下:
* OOV 單詞-訓練數據詞匯(索引 1)中排除的單詞由所有 GloVe 向量的均值初始化
* 在 GloVe 中找不到的單詞由所有 Glove 向量和相同維數的隨機向量的均值初始化
以下代碼段在之前討論的 GloVe `class`的`_init_embedding_matrix`方法中具有相同的功能:
```py
#oov by average vector:
self.embedding_matrix[1] = np.mean(self.embedding_matrix, axis=0)
for indx in missing_word_index:
self.embedding_matrix[indx] = np.random.rand(self.EMBEDDING_DIM)+
self.embedding_matrix[1]
```
初始化嵌入矩陣之后,我們現在可以構建第一層,即嵌入層,如下所示:
```py
from keras.layers import Embedding
embedding_layer = Embedding(vocab_size,
embedding_dim,
weights=[embedding_weights],
input_length=max_seq_length,
trainable=True,
name='embedding')
```
接下來,我們必須構建單詞卷積層。 我們希望在所有句子上應用相同的一維卷積濾波器,也就是說,在所有句子之間共享相同的卷積濾波器權重。 首先,我們使用`Lambda`層將輸入分成句子。 然后,如果我們使用 *C* 卷積濾波器,則每個句子的二維張量形狀(`SENTENCE_LEN×EMBEDDING _DIM`)將轉換為`(SENTENCE_LEN-filter + 1) × C`張量。 以下代碼執行相同的操作:
```py
#Let's take sentence_len=30, embedding_dim=50, num_sentences = 10
#following convolution filters to be used for all sentences.
word_conv_model = Conv1D(filters= 6,
kernel_size= 5,
padding="valid",
activation="relu",
trainable = True,
name = "word_conv",
strides=1)
for sent in range(num_sentences):
##get one sentence from the input document
sentence = Lambda(lambda x : x[:, sent*sentence_len:
(sent+1)*sentence_len, :])(z)
##sentence shape : (None, 30, 50)
conv = word_conv_model(sentence)
## convolution shape : (None, 26, 6)
```
k-max 合并層在`keras`中不可用。 我們可以將 k-max 池實現為自定義層。 要實現自定義層,我們需要實現三種方法:
* `call(x)`:這是實現層的邏輯的地方
* `compute_output_shape(input_shape)`:如果自定義層修改了其輸入的形狀
* `build(input_shape)`:定義層權重(我們不需要此,因為我們的層沒有權重)
這是 k-max 合并層的完整代碼:
```py
import tensorflow as tf
from keras.layers import Layer, InputSpec
class KMaxPooling(Layer):
def __init__(self, k=1, **kwargs):
super().__init__(**kwargs)
self.input_spec = InputSpec(ndim=3)
self.k = k
def compute_output_shape(self, input_shape):
return (input_shape[0], (input_shape[2] * self.k))
def call(self, inputs):
# swap last two dimensions since top_k will be
# applied along the last dimension
shifted_input = tf.transpose(inputs, [0, 2, 1])
# extract top_k, returns two tensors [values, indices]
top_k = tf.nn.top_k(shifted_input, k=self.k, sorted=True,
name=None)[0]
# return flattened output
return top_k
```
將前面的 k-max 池化層應用于單詞卷積,我們得到句子嵌入層:
```py
for sent in range(num_sentences):
##get one sentence from the input document
sentence = Lambda(lambda x : x[:,sent*sentence_len:
(sent+1)*sentence_len, :])(z)
##sentence shape : (None, 30, 50)
conv = word_conv_model(sentence)
## convolution shape : (None, 26, 6)
conv = KMaxPooling(k=3)(conv)
#transpose pooled values per sentence
conv = Reshape([word_filters*sent_k_maxpool,1])(conv)
## shape post k-max pooling and reshape (None, 18=6*3, 1)
```
因此,我們將形狀為`30×50`的每個句子轉換為`18×1`,然后將這些張量連接起來以獲得句子嵌入。 我們使用 Keras 中的`Concatenate`層來實現相同的功能:
```py
z = Concatenate()(conv_blocks) if len(conv_blocks) > 1 else conv_blocks[0]
z = Permute([2,1], name='sentence_embeddings')(z)
## output shape of sentence embedding is : (None, 10, 18)
```
如前所述,對前一句子嵌入應用一維卷積,然后進行 k-max 合并,以獲得*文檔*嵌入。 這樣就完成了文本的文檔模型。 根據手頭的學習任務,可以定義下一層。 對于分類任務,可以將文檔嵌入連接到密集層,然后連接到具有`K`單元的最終 softmax 層,以解決 k 類分類問題。 在最后一層之前,我們可以有多個致密層。 以下代碼段實現了相同的功能:
```py
sent_conv = Conv1D(filters=16,
kernel_size=3,
padding="valid",
activation="relu",
trainable = True,
name = 'sentence_conv',
strides=1)(z)
z = KMaxPooling(k=5)(sent_conv)
z = Flatten(name='document_embedding')(z)
for i in range(num_hidden_layers):
layer_name = 'hidden_{}'.format(i)
z = Dense(hidden_dims, activation=hidden_activation,
name=layer_name)(z)
model_output = Dense(K, activation='sigmoid',name='final')(z)
```
整個代碼包含在`cnn_document_model`模塊中。
# 建立評論情感分類器
現在,通過訓練前面的 CNN 文檔模型來構建情感分類器。 我們將使用[“亞馬遜情感分析評論”](https://www.kaggle.com/bittlingmayer/amazonreviews)數據集來訓練該模型。 該數據集由數百萬個 Amazon 客戶評論(輸入文本)和星級(輸出標簽)組成。 數據格式如下:標簽,后跟空格,審閱標題,后跟`:`和空格,位于審閱文本之前。 該數據集比流行的 IMDB 電影評論數據集大得多。 此外,此數據集包含各種產品和電影的相當多的評論集:
```py
__label__<X> <summary/title>: <Review Text>
Example:
__label__2 Good Movie: Awesome.... simply awesome. I couldn't put this down and laughed, smiled, and even got tears! A brand new favorite author.
```
在此,`__label__1`對應于 1 星和 2 星評論,`__label__2`對應于 4 星和 5 星評論。 但是,此數據集中未包含三星級評論,即具有中性情感的評論。 在此數據集中,我們總共有 360 萬個訓練示例和 40 萬個測試示例。 我們將從訓練示例中隨機抽取一個大小為 200,000 的樣本,以便我們可以猜測一個很好的超參數來進行訓練:
```py
train_df = Loader.load_amazon_reviews('train')
print(train_df.shape)
test_df = Loader.load_amazon_reviews('test')
print(test_df.shape)
dataset = train_df.sample(n=200000, random_state=42)
dataset.sentiment.value_counts()
```
接下來,我們使用`Preprocess`類將語料庫轉換為填充的單詞索引序列,如下所示:
```py
preprocessor = Preprocess()
corpus_to_seq = preprocessor.fit(corpus=corpus)
holdout_corpus = test_df['review'].values
holdout_target = test_df['sentiment'].values
holdout_corpus_to_seq = preprocessor.transform(holdout_corpus)
```
讓我們使用`GloVe`類用 GloVe 初始化嵌入,并構建文檔模型。 我們還需要定義文檔模型參數,例如卷積過濾器的數量,激活函數,隱藏單元等。 為了避免網絡的過擬合,我們可以在輸入層,卷積層甚至最終層或密集層之間插入丟棄層。 同樣,正如我們在密集層所觀察到的,放置高斯噪聲層可作為更好的正則化器。 可以使用以下定義的所有這些參數初始化`DocumentModel`類。 為了對模型參數進行良好的初始化,我們從少量的周期和少量的采樣訓練示例開始。 最初,我們開始使用六個詞卷積過濾器(如針對 IMDB 數據的論文所述),然后發現該模型不適合-訓練的精度未超過 80%,然后我們繼續緩慢地增加詞過濾器的數量 。 同樣,我們發現了大量的句子卷積過濾器。 我們嘗試了卷積層的 ReLU 和 tanh 激活。 如[論文](https://arxiv.org/pdf/1406.3830.pdf)所述,他們將 tanh 激活用于其模型:
```py
glove=GloVe(50)
initial_embeddings = glove.get_embedding(preprocessor.word_index)
amazon_review_model =
DocumentModel(vocab_size=preprocessor.get_vocab_size(),
word_index = preprocessor.word_index,
num_sentences = Preprocess.NUM_SENTENCES,
embedding_weights = initial_embeddings,
conv_activation = 'tanh',
hidden_dims=64,
input_dropout=0.40,
hidden_gaussian_noise_sd=0.5)
```
以下是此模型的參數的完整列表,我們已將其用于訓練了 360 萬個完整的訓練示例:
```py
{
"embedding_dim":50,
"train_embedding":true,
"sentence_len":30,
"num_sentences":10,
"word_kernel_size":5,
"word_filters":30,
"sent_kernel_size":5,
"sent_filters":16,
"sent_k_maxpool":3,
"input_dropout":0.4,
"doc_k_maxpool":4,
"sent_dropout":0,
"hidden_dims":64,
"conv_activation":"relu",
"hidden_activation":"relu",
"hidden_dropout":0,
"num_hidden_layers":1,
"hidden_gaussian_noise_sd":0.5,
"final_layer_kernel_regularizer":0.0,
"learn_word_conv":true,
"learn_sent_conv":true
}
```
最后,在開始全面訓練之前,我們需要確定一個好的批次大小。 對于大批量(如 256),訓練非常慢,因此我們使用了`64`的批量。 我們使用`rmsprop`優化器來訓練我們的模型,并從`keras`使用的默認學習率開始。 以下是訓練參數的完整列表,它們存儲在`TrainingParameters`類中:
```py
{"seed":55,
"batch_size":64,
"num_epochs":35,
"validation_split":0.05,
"optimizer":"rmsprop",
"learning_rate":0.001}
```
以下是開始訓練的代碼:
```py
train_params = TrainingParameters('model_with_tanh_activation')
amazon_review_model.get_classification_model().compile(
loss="binary_crossentropy",
optimizer=
train_params.optimizer,
metrics=["accuracy"])
checkpointer = ModelCheckpoint(filepath=train_params.model_file_path,
verbose=1,
save_best_only=True,
save_weights_only=True)
x_train = np.array(corpus_to_seq)
y_train = np.array(target)
x_test = np.array(holdout_corpus_to_seq)
y_test = np.array(holdout_target)
amazon_review_model.get_classification_model().fit(x_train, y_train,
batch_size=train_params.batch_size,
epochs=train_params.num_epochs,
verbose=2,
validation_split=train_params.validation_split,
callbacks=[checkpointer])
```
我們已經在 CPU 上訓練了該模型,下面是五個周期后的結果。 對于 190k 樣本,只有一個周期非常慢,大約需要 10 分鐘才能運行。 但是,您可以在下面看到,在五個周期之后的訓練和驗證準確率達到 **92%**,這是相當不錯的:
```py
Train on 190000 samples, validate on 10000 samples
Epoch 1/35
- 577s - loss: 0.3891 - acc: 0.8171 - val_loss: 0.2533 - val_acc: 0.8369
Epoch 2/35
- 614s - loss: 0.2618 - acc: 0.8928 - val_loss: 0.2198 - val_acc: 0.9137
Epoch 3/35
- 581s - loss: 0.2332 - acc: 0.9067 - val_loss: 0.2105 - val_acc: 0.9191
Epoch 4/35
- 640s - loss: 0.2197 - acc: 0.9128 - val_loss: 0.1998 - val_acc: 0.9206
Epoch 5/35
...
...
```
我們對 40 萬條評論進行了評估,對模型進行了評估,結果的**準確率也達到 92%**。 這清楚地表明該模型非常適合此審閱數據,并且隨著數據的增加,還有更多的改進空間。 到目前為止,在整個訓練過程中,遷移學習的主要用途是用于初始化單詞嵌入的 GloVe 嵌入向量。 在這里,由于我們擁有大量數據,因此我們可以從頭開始學習權重。 但是,讓我們看看在整個訓練過程中,哪些詞嵌入更新最多。
# 變化最大的嵌入是什么?
我們可以采用初始 GloVe 嵌入和最終學習的嵌入,并通過對每個單詞的差異進行歸一化來比較它們。 然后,我們可以對標準值進行排序,以查看哪些詞變化最大。 這是執行此操作的代碼:
```py
learned_embeddings = amazon_review_model.get_classification_model()
.get_layer('embedding').get_weights()[0]
embd_change = {}
for word, i in preprocessor.word_index.items():
embd_change[word] = np.linalg.norm(initial_embeddings[i]-
learned_embeddings[i])
embd_change = sorted(embd_change.items(), key=lambda x: x[1],
reverse=True)
embd_change[0:20]
```
您可以檢查是否最新的嵌入是針對意見詞的。
# 遷移學習 – 應用到 IMDB 數據集
我們應該使用遷移學習的一種情況是,手頭任務的標簽數據少得多,而相似但不同的領域的訓練數據很多。 [IMDB 數據集](http://ai.stanford.edu/~amaas/data/sentiment/)是二元情??感分類數據集。 它擁有 25,000 條用于訓練的電影評論和 25,000 條用于測試的電影評論。 關于此數據集,有很多已發表的論文,并且可能通過來自 Google 的 Mikolov 的[段落向量](https://arxiv.org/pdf/1405.4053.pdf)在此數據集上獲得最佳結果。 他們在此數據集上實現了 **92.58%** 的準確率。 SVM 達到了 89%。 這個數據集的大小不錯,我們可以從頭開始訓練 CNN 模型。 這為我們提供了與 SVM 相當的結果。 下一節將對此進行討論。
現在,讓我們嘗試使用少量的 IMDB 數據樣本(例如 **5%**)構建模型。 在許多實際情況下,我們面臨訓練數據不足的問題。 我們無法使用此小型數據集訓練 CNN。 因此,我們將使用遷移學習為該數據集構建模型。
我們首先按照與其他數據集相同的步驟預處理和準備數據:
```py
train_df = Loader.load_imdb_data(directory = 'train')
train_df = train_df.sample(frac=0.05, random_state = train_params.seed)
#take only 5%
print(train_df.shape)
test_df = Loader.load_imdb_data(directory = 'test')
print(test_df.shape)
corpus = train_df['review'].tolist()
target = train_df['sentiment'].tolist()
corpus, target = remove_empty_docs(corpus, target)
print(len(corpus))
preprocessor = Preprocess(corpus=corpus)
corpus_to_seq = preprocessor.fit()
test_corpus = test_df['review'].tolist()
test_target = test_df['sentiment'].tolist()
test_corpus, test_target = remove_empty_docs(test_corpus, test_target)
print(len(test_corpus))
test_corpus_to_seq = preprocessor.transform(test_corpus)
x_train = np.array(corpus_to_seq)
x_test = np.array(test_corpus_to_seq)
y_train = np.array(target)
y_test = np.array(test_target)
print(x_train.shape, y_train.shape)
glove=GloVe(50)
initial_embeddings = glove.get_embedding(preprocessor.word_index)
#IMDB MODEL
```
現在,讓我們先加載訓練后的模型。 我們有兩種加載方法:模型的超參數和`DocumentModel`類中學習的模型權重:
```py
def load_model(file_name):
with open(file_name, "r", encoding= "utf-8") as hp_file:
model_params = json.load(hp_file)
doc_model = DocumentModel( **model_params)
print(model_params)
return doc_model
def load_model_weights(self, model_weights_filename):
self._model.load_weights(model_weights_filename, by_name=True)
```
然后,我們使用前述方法加載預訓練的模型,然后按如下方法將學習到的權重轉移到新模型中。 預訓練模型的嵌入矩陣比語料庫更大,單詞更多。 因此,我們不能直接使用預訓練模型中的嵌入矩陣。 我們將使用`GloVe`類中的`update_embedding`方法,使用經過訓練的模型中的嵌入來更新 IMDB 模型的 GloVe 初始化的嵌入:
```py
amazon_review_model = DocumentModel.load_model("model_file.json")
amazon_review_model.load_model_weights("model_weights.hdf5")
learned_embeddings = amazon_review_model.get_classification_model()\
.get_layer('embedding').get_weights()[0]
#update the GloVe embeddings.
glove.update_embeddings(preprocessor.word_index,
np.array(learned_embeddings),
amazon_review_model.word_index)
```
現在,我們都準備建立遷移學習模型。 讓我們首先構建 IMDB 模型,然后從其他預訓練模型初始化權重。 我們不會使用少量數據來訓練該網絡的較低層。 因此,我們將為其設置`trainable=False`。 我們將僅訓練具有較大丟棄法率的最后一層:
```py
initial_embeddings = glove.get_embedding(preprocessor.word_index)#get
updated embeddings
imdb_model = DocumentModel(vocab_size=preprocessor.get_vocab_size(),
word_index = preprocessor.word_index,
num_sentences=Preprocess.NUM_SENTENCES,
embedding_weights=initial_embeddings,
conv_activation = 'tanh',
train_embedding = False,
learn_word_conv = False,
learn_sent_conv = False,
hidden_dims=64,
input_dropout=0.0,
hidden_layer_kernel_regularizer=0.001,
final_layer_kernel_regularizer=0.01)
#transfer word & sentence conv filters
for l_name in ['word_conv','sentence_conv','hidden_0', 'final']:
imdb_model.get_classification_model()\
.get_layer(l_name).set_weights(weights=amazon_review_model
.get_classification_model()
.get_layer(l_name).get_weights())
```
在經過幾個周期的訓練之后,僅對隱藏層和最終的 S 型層進行了微調,我們在 25k 測試集上獲得了 **86%** 測試精度。 如果我們嘗試在這個小的數據集上訓練 SVM 模型并預測整個 25k 測試集,則只能獲得 82% 的準確率。 因此,即使我們的數據較少,遷移學習顯然也有助于建立更好的模型。
# 使用 Word2vec 嵌入來訓練完整 IMDB 數據集
現在,讓我們嘗試通過遷移學習到的 Word2vec 嵌入,在完整的 IMDB 數據集上訓練文檔 CNN 模型。
請注意,我們沒有使用從 Amazon Review 模型中學到的權重。 我們將從頭開始訓練模型。 實際上,這就是本文所做的。
此代碼與前面的 IMDB 訓練代碼非常相似。 您只需要從 Amazon 模型中排除權重加載部分。 該代碼位于存儲庫中名為`imdb_model.py`的模塊中。 另外,這是模型參數:
```py
{
"embedding_dim":50,
"train_embedding":true,
"embedding_regularizer_l2":0.0,
"sentence_len":30,
"num_sentences":20,
"word_kernel_size":5,
"word_filters":30,
"sent_kernel_size":5,
"sent_filters":16,
"sent_k_maxpool":3,
"input_dropout":0.4,
"doc_k_maxpool":5,
"sent_dropout":0.2,
"hidden_dims":64,
"conv_activation":"relu",
"hidden_activation":"relu",
"hidden_dropout":0,
"num_hidden_layers":1,
"hidden_gaussian_noise_sd":0.3,
"final_layer_kernel_regularizer":0.04,
"hidden_layer_kernel_regularizer":0.0,
"learn_word_conv":true,
"learn_sent_conv":true,
"num_units_final_layer":1
}
```
訓練時,我們使用了另一種技巧來避免過擬合。 我們在前 10 個時間段后凍結嵌入層(即`train_embedding=False`),僅訓練其余層。 經過 50 個周期后,我們在 IMDB 數據集上實現了 **89%** 的準確率,這是本文提出的結果。 我們觀察到,如果我們在訓練之前不初始化嵌入權重,則模型將開始過擬合,并且無法實現 **80%** 以上的準確率驗證。
# 使用 CNN 模型創建文檔摘要
評論有很多句子。 這些句子中的一些是中性的,而某些則是多余的,無法確定整個文檔的極性。 總結評論或在評論中突出顯示用戶實際表達意見的句子非常有用。 實際上,它也為我們所做的預測提供了解釋,從而使模型可以解釋。
如本文所述,文本摘要的第一步是通過為每個句子分配重要性分數來為文檔創建顯著性圖。 為了生成給定文檔的顯著性圖,我們可以應用以下技術:
1. 我們首先通過網絡執行前向傳遞,以生成文檔的類別預測。
2. 然后,我們通過反轉網絡預測來構造偽標簽。
3. 將偽標簽作為真實標簽輸入到訓練損失函數中。 偽標簽的這種選擇使我們能夠造成最大的損失。 反過來,這將使反向傳播修改對決定類標簽貢獻最大的句子嵌入的權重。 因此,在實際上是肯定標簽的情況下,如果我們將 0 作為偽標簽傳遞,則強陽性語句嵌入應該會看到最大的變化,即高梯度范數。
4. 計算損失函數相對于句子嵌入層的導數。
5. 按梯度范數按降序對句子進行排序,以使最重要的句子排在頂部。
讓我們在 Keras 中實現它。 我們必須像以前一樣進行預處理,并獲得`x_train`和`y_train` NumPy 數組。 我們將首先加載訓練有素的 IMDB 模型和學習的權重。 然后,我們還需要使用用于從該模型中獲取導數和損失函數的優化器來編譯模型:
```py
imdb_model = DocumentModel.load_model(config.MODEL_DIR+
'/imdb/model_02.json')
imdb_model.load_model_weights(config.MODEL_DIR+ '/imdb/model_02.hdf5')
model = imdb_model.get_classification_model()
model.compile(loss="binary_crossentropy", optimizer='rmsprop',
metrics=["accuracy"])
```
現在,讓我們進行前面提到的*步驟 1*,即前向傳遞,然后生成偽標簽:
```py
preds = model.predict(x_train)
#invert predicted label
pseudo_label = np.subtract(1,preds)
```
為了計算梯度,我們將使用 Keras 函數`model.optimizer.get_gradients()`:
```py
#Get the learned sentence embeddings
sentence_ebd = imdb_model.get_sentence_model().predict(x_train)
input_tensors = [model.inputs[0], # input data
# how much to weight each sample by
model.sample_weights[0],
model.targets[0], # labels
]
#variable tensor at the sentence embedding layer
weights = imdb_model.get_sentence_model().outputs
#calculate gradient of the total model loss w.r.t
#the variables at sentence embd layer
gradients = model.optimizer.get_gradients(model.total_loss, weights)
get_gradients = K.function(inputs=input_tensors, outputs=gradients)
```
現在,我們可以計算出一個文檔(例如,文檔編號`10`)的梯度,如下所示:
```py
document_number = 10
K.set_learning_phase(0)
inputs = [[x_train[document_number]], # X
[1], # sample weights
[[pseudo_label[document_number][0]]], # y
]
grad = get_gradients(inputs)
```
現在,我們可以按梯度范數對句子進行排序。 我們將使用與預處理中使用的相同的`nltk sent_tokenize`函數來獲取文本句子:
```py
sent_score = []
for i in range(Preprocess.NUM_SENTENCES):
sent_score.append((i, -np.linalg.norm(grad[0][0][i])))
sent_score.sort(key=lambda tup: tup[1])
summary_sentences = [ i for i, s in sent_score[:4]]
doc = corpus[document_number]
label = y_train[document_number]
prediction = preds[document_number]
print(doc, label , prediction)
sentences = sent_tokenize(doc)
for i in summary_sentences:
print(i, sentences[i])
```
以下是**否定的**評論:
```py
Wow, what a great cast! Julia Roberts, John Cusack, Christopher Walken, Catherine Zeta-Jones, Hank Azaria...what's that? A script, you say? Now you're just being greedy! Surely such a charismatic bunch of thespians will weave such fetching tapestries of cinematic wonder that a script will be unnecessary? You'd think so, but no. America's Sweethearts is one missed opportunity after another. It's like everyone involved woke up before each day's writing/shooting/editing and though "You know what? I've been working pretty hard lately, and this is guaranteed to be a hit with all these big names, right? I'm just gonna cruise along and let somebody else carry the can." So much potential, yet so painful to sit through. There isn't a single aspect of this thing that doesn't suck. Even Julia's fat suit is lame.
```
從前兩個句子看來,這是非常積極的。 我們對該文件的預測得分是 0.15,這是正確的。 讓我們看看我們得到了什么總結:
```py
4 Surely such a charismatic bunch of thespians will weave such
fetching tapestries of cinematic wonder that a script will be
unnecessary?
2 A script, you say?
6 America's Sweethearts is one missed opportunity after another.
```
讓我們再舉一個積極的例子,這里我們的模型預測為 0.98:
```py
This is what I was expecting when star trek DS9 premiered. Not to slight DS9\. That was a wonderful show in it's own right, however it never really gave the fans more of what they wanted. Enterprise is that show. While having a similarity to the original trek it differs enough to be original in it's own ways. It makes the ideas of exploration exciting to us again. And that was one of the primary ingredients that made the original so loved. Another ingredient to success was the relationships that evolved between the crew members. Viewers really cared deeply for the crew. Enterprise has much promise in this area as well. The chemistry between Bakula and Blalock seems very promising. While sexual tension in a show can often become a crutch, I feel the tensions on enterprise can lead to much more and say alot more than is typical. I think when we deal with such grand scale characters of different races or species even, we get some very interesting ideas and television. Also, we should note the performances, Blalock is very convincing as Vulcan T'pol and Bacula really has a whimsy and strength of character that delivers a great performance. The rest of the cast delivered good performances also. My only gripes are as follows. The theme. It's good it's different, but a little to light hearted for my liking. We need something a little more grand. Doesn't have to be orchestral. Maybe something with a little more electronic sound would suffice. And my one other complaint. They sell too many adds. They could fix this by selling less ads, or making all shows two parters. Otherwise we'll end up seeing the shows final act getting wrapped up way too quickly as was one of my complaints of Voyager.
```
這是摘要:
```py
2 That was a wonderful show in it's own right, however it never really
gave the fans more of what they wanted.
5 It makes the ideas of exploration exciting to us again.
6 And that was one of the primary ingredients that made the original
so loved.
8 Viewers really cared deeply for the crew.
```
您會看到它很好地掌握了摘要句子。 您真的不需要通過整個審查來理解它。 因此,此文本 CNN 模型可與 IMDB 數據集的最新模型相媲美,而且一旦學習,它就可以執行其他高級文本分析任務,例如文本摘要。
# 使用 CNN 模型進行多類分類
現在,我們將相同的模型應用于多類分類。 我們將為此使用 20 個新聞組數據集。 為了訓練 CNN 模型,此數據集很小。 我們仍然會嘗試解決一個更簡單的問題。 如前所述,該數據集中的 20 個類有很多混合,使用 SVM,我們可以獲得最高 70% 的準確率。 在這里,我們將采用該數據集的六大類,并嘗試構建 CNN 分類器。 因此,首先我們將 20 個類別映射到 6 個大類別。 以下是首先從 scikit Learn 加載數據集的代碼:
```py
def load_20newsgroup_data(categories = None, subset='all'):
data = fetch_20newsgroups(subset=subset,
shuffle=True,
remove=('headers', 'footers', 'quotes'),
categories = categories)
return data
dataset = Loader.load_20newsgroup_data(subset='train')
corpus, labels = dataset.data, dataset.target
test_dataset = Loader.load_20newsgroup_data(subset='test')
test_corpus, test_labels = test_dataset.data, test_dataset.target
```
接下來,我們將 20 個類映射到六個類別,如下所示:
```py
six_groups = {
'comp.graphics':0,'comp.os.ms-
windows.misc':0,'comp.sys.ibm.pc.hardware':0,
'comp.sys.mac.hardware':0, 'comp.windows.x':0,
'rec.autos':1, 'rec.motorcycles':1, 'rec.sport.baseball':1,
'rec.sport.hockey':1,
'sci.crypt':2, 'sci.electronics':2,'sci.med':2, 'sci.space':2,
'misc.forsale':3,
'talk.politics.misc':4, 'talk.politics.guns':4,
'talk.politics.mideast':4,
'talk.religion.misc':5, 'alt.atheism':5, 'soc.religion.christian':5
}
map_20_2_6 = [six_groups[dataset.target_names[i]] for i in range(20)]
labels = [six_groups[dataset.target_names[i]] for i in labels]
test_labels = [six_groups[dataset.target_names[i]] for i in
test_labels]
```
我們將執行相同的預處理步驟,然后進行模型初始化。 同樣,在這里,我們使用了 GloVe 嵌入來初始化單詞嵌入向量。 詳細代碼在`20newsgrp_model`模塊的存儲庫中。 這是模型的超參數:
```py
{
"embedding_dim":50,
"train_embedding":false,
"embedding_regularizer_l2":0.0,
"sentence_len":30,
"num_sentences":10,
"word_kernel_size":5,
"word_filters":30,
"sent_kernel_size":5,
"sent_filters":20,
"sent_k_maxpool":3,
"input_dropout":0.2,
"doc_k_maxpool":4,
"sent_dropout":0.3,
"hidden_dims":64,
"conv_activation":"relu",
"hidden_activation":"relu",
"hidden_dropout":0,
"num_hidden_layers":2,
"hidden_gaussian_noise_sd":0.3,
"final_layer_kernel_regularizer":0.01,
"hidden_layer_kernel_regularizer":0.0,
"learn_word_conv":true,
"learn_sent_conv":true,
"num_units_final_layer":6
}
```
這是測試集上模型的詳細結果:
```py
precision recall f1-score support
0 0.80 0.91 0.85 1912
1 0.86 0.85 0.86 1534
2 0.75 0.79 0.77 1523
3 0.88 0.34 0.49 382
4 0.78 0.76 0.77 1027
5 0.84 0.79 0.82 940
avg / total 0.81 0.80 0.80 7318
[[1733 41 114 1 14 9]
[ 49 1302 110 11 47 15]
[ 159 63 1196 5 75 25]
[ 198 21 23 130 9 1]
[ 10 53 94 0 782 88]
[ 22 30 61 0 81 746]]
0.8047280677780815
```
讓我們在此數據集上嘗試 SVM,看看我們獲得的最佳精度是多少:
```py
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import SVC
tv = TfidfVectorizer(use_idf=True, min_df=0.00005, max_df=1.0,
ngram_range=(1, 1), stop_words = 'english',
sublinear_tf=True)
tv_train_features = tv.fit_transform(corpus)
tv_test_features = tv.transform(test_corpus)
clf = SVC(C=1,kernel='linear', random_state=1, gamma=0.01)
svm=clf.fit(tv_train_features, labels)
preds_test = svm.predict(tv_test_features)
from sklearn.metrics import
classification_report,accuracy_score,confusion_matrix
print(classification_report(test_labels, preds_test))
print(confusion_matrix(test_labels, preds_test))
print(accuracy_score(test_labels, preds_test))
```
以下是 SVM 模型的結果。 我們已經對參數`C`進行了調整,以便獲得最佳的交叉驗證精度:
```py
precision recall f1-score support
0 0.86 0.89 0.87 1912
1 0.83 0.89 0.86 1534
2 0.75 0.78 0.76 1523
3 0.87 0.73 0.80 382
4 0.82 0.75 0.79 1027
5 0.85 0.76 0.80 940
avg / total 0.82 0.82 0.82 7318
0.82344902978956
```
因此,我們看到,在多類分類結果的情況下,本文的 CNN 模型也可以給出可比較的結果。 再次,和以前一樣,現在也可以使用經過訓練的模型來執行文本摘要。
# 可視化文檔嵌入
在我們的文檔 CNN 模型中,我們具有文檔嵌入層。 讓我們嘗試可視化模型在這一層中學到的特征。 我們將首先獲取測試集,并按如下方式計算文檔嵌入:
```py
doc_embeddings = newsgrp_model.get_document_model().predict(x_test)
print(doc_embeddings.shape)
(7318, 80)
```
我們為所有測試文檔獲得了 80 維嵌入向量。 為了可視化這些向量,我們將使用流行的 t-SNE 二維還原技術將向量投影到二維空間中,并繪制散點圖,如下所示:
```py
from utils import scatter_plot
doc_proj = TSNE(n_components=2, random_state=42,
).fit_transform(doc_embeddings)
f, ax, sc, txts = scatter_plot(doc_proj, np.array(test_labels))
```
前面代碼的輸出如下:

散點圖上的標簽(0-5)代表六個類別。 如您所見,該模型學習了不錯的嵌入,并且能夠在 80 維空間中很好地分離出六個類。 我們可以將這些嵌入用于其他文本分析任務,例如*信息檢索*或*文本搜索*。 給定一個查詢文檔,我們可以計算其密集嵌入,然后將其與整個語料庫中的相似嵌入進行比較。 這可以幫助我們提高基于關鍵字的查詢結果并提高檢索表現。
# 總結
我們已經從自然語言處理,文本分類,文本摘要以及深度學習 CNN 模型在文本域中的應用中學習了一些概念。 我們已經看到,在大多數用例中,尤其是如果我們的訓練數據較少時,默認的第一步就是以詞嵌入為基礎的遷移學習。 我們已經看到了如何將遷移學習應用于在巨大的 Amazon 產品評論數據集上學習的文本 CNN 模型,以對小型電影評論數據集(相關但不相同的領域)進行預測。
此外,我們在這里還學習了如何將學習到的 CNN 模型用于其他文本處理任務,例如將文檔匯總和表示為密集向量,這些信息可以在信息檢索系統中使用,以提高檢索表現。
- TensorFlow 1.x 深度學習秘籍
- 零、前言
- 一、TensorFlow 簡介
- 二、回歸
- 三、神經網絡:感知器
- 四、卷積神經網絡
- 五、高級卷積神經網絡
- 六、循環神經網絡
- 七、無監督學習
- 八、自編碼器
- 九、強化學習
- 十、移動計算
- 十一、生成模型和 CapsNet
- 十二、分布式 TensorFlow 和云深度學習
- 十三、AutoML 和學習如何學習(元學習)
- 十四、TensorFlow 處理單元
- 使用 TensorFlow 構建機器學習項目中文版
- 一、探索和轉換數據
- 二、聚類
- 三、線性回歸
- 四、邏輯回歸
- 五、簡單的前饋神經網絡
- 六、卷積神經網絡
- 七、循環神經網絡和 LSTM
- 八、深度神經網絡
- 九、大規模運行模型 -- GPU 和服務
- 十、庫安裝和其他提示
- TensorFlow 深度學習中文第二版
- 一、人工神經網絡
- 二、TensorFlow v1.6 的新功能是什么?
- 三、實現前饋神經網絡
- 四、CNN 實戰
- 五、使用 TensorFlow 實現自編碼器
- 六、RNN 和梯度消失或爆炸問題
- 七、TensorFlow GPU 配置
- 八、TFLearn
- 九、使用協同過濾的電影推薦
- 十、OpenAI Gym
- TensorFlow 深度學習實戰指南中文版
- 一、入門
- 二、深度神經網絡
- 三、卷積神經網絡
- 四、循環神經網絡介紹
- 五、總結
- 精通 TensorFlow 1.x
- 一、TensorFlow 101
- 二、TensorFlow 的高級庫
- 三、Keras 101
- 四、TensorFlow 中的經典機器學習
- 五、TensorFlow 和 Keras 中的神經網絡和 MLP
- 六、TensorFlow 和 Keras 中的 RNN
- 七、TensorFlow 和 Keras 中的用于時間序列數據的 RNN
- 八、TensorFlow 和 Keras 中的用于文本數據的 RNN
- 九、TensorFlow 和 Keras 中的 CNN
- 十、TensorFlow 和 Keras 中的自編碼器
- 十一、TF 服務:生產中的 TensorFlow 模型
- 十二、遷移學習和預訓練模型
- 十三、深度強化學習
- 十四、生成對抗網絡
- 十五、TensorFlow 集群的分布式模型
- 十六、移動和嵌入式平臺上的 TensorFlow 模型
- 十七、R 中的 TensorFlow 和 Keras
- 十八、調試 TensorFlow 模型
- 十九、張量處理單元
- TensorFlow 機器學習秘籍中文第二版
- 一、TensorFlow 入門
- 二、TensorFlow 的方式
- 三、線性回歸
- 四、支持向量機
- 五、最近鄰方法
- 六、神經網絡
- 七、自然語言處理
- 八、卷積神經網絡
- 九、循環神經網絡
- 十、將 TensorFlow 投入生產
- 十一、更多 TensorFlow
- 與 TensorFlow 的初次接觸
- 前言
- 1.?TensorFlow 基礎知識
- 2. TensorFlow 中的線性回歸
- 3. TensorFlow 中的聚類
- 4. TensorFlow 中的單層神經網絡
- 5. TensorFlow 中的多層神經網絡
- 6. 并行
- 后記
- TensorFlow 學習指南
- 一、基礎
- 二、線性模型
- 三、學習
- 四、分布式
- TensorFlow Rager 教程
- 一、如何使用 TensorFlow Eager 構建簡單的神經網絡
- 二、在 Eager 模式中使用指標
- 三、如何保存和恢復訓練模型
- 四、文本序列到 TFRecords
- 五、如何將原始圖片數據轉換為 TFRecords
- 六、如何使用 TensorFlow Eager 從 TFRecords 批量讀取數據
- 七、使用 TensorFlow Eager 構建用于情感識別的卷積神經網絡(CNN)
- 八、用于 TensorFlow Eager 序列分類的動態循壞神經網絡
- 九、用于 TensorFlow Eager 時間序列回歸的遞歸神經網絡
- TensorFlow 高效編程
- 圖嵌入綜述:問題,技術與應用
- 一、引言
- 三、圖嵌入的問題設定
- 四、圖嵌入技術
- 基于邊重構的優化問題
- 應用
- 基于深度學習的推薦系統:綜述和新視角
- 引言
- 基于深度學習的推薦:最先進的技術
- 基于卷積神經網絡的推薦
- 關于卷積神經網絡我們理解了什么
- 第1章概論
- 第2章多層網絡
- 2.1.4生成對抗網絡
- 2.2.1最近ConvNets演變中的關鍵架構
- 2.2.2走向ConvNet不變性
- 2.3時空卷積網絡
- 第3章了解ConvNets構建塊
- 3.2整改
- 3.3規范化
- 3.4匯集
- 第四章現狀
- 4.2打開問題
- 參考
- 機器學習超級復習筆記
- Python 遷移學習實用指南
- 零、前言
- 一、機器學習基礎
- 二、深度學習基礎
- 三、了解深度學習架構
- 四、遷移學習基礎
- 五、釋放遷移學習的力量
- 六、圖像識別與分類
- 七、文本文件分類
- 八、音頻事件識別與分類
- 九、DeepDream
- 十、自動圖像字幕生成器
- 十一、圖像著色
- 面向計算機視覺的深度學習
- 零、前言
- 一、入門
- 二、圖像分類
- 三、圖像檢索
- 四、對象檢測
- 五、語義分割
- 六、相似性學習
- 七、圖像字幕
- 八、生成模型
- 九、視頻分類
- 十、部署
- 深度學習快速參考
- 零、前言
- 一、深度學習的基礎
- 二、使用深度學習解決回歸問題
- 三、使用 TensorBoard 監控網絡訓練
- 四、使用深度學習解決二分類問題
- 五、使用 Keras 解決多分類問題
- 六、超參數優化
- 七、從頭開始訓練 CNN
- 八、將預訓練的 CNN 用于遷移學習
- 九、從頭開始訓練 RNN
- 十、使用詞嵌入從頭開始訓練 LSTM
- 十一、訓練 Seq2Seq 模型
- 十二、深度強化學習
- 十三、生成對抗網絡
- TensorFlow 2.0 快速入門指南
- 零、前言
- 第 1 部分:TensorFlow 2.00 Alpha 簡介
- 一、TensorFlow 2 簡介
- 二、Keras:TensorFlow 2 的高級 API
- 三、TensorFlow 2 和 ANN 技術
- 第 2 部分:TensorFlow 2.00 Alpha 中的監督和無監督學習
- 四、TensorFlow 2 和監督機器學習
- 五、TensorFlow 2 和無監督學習
- 第 3 部分:TensorFlow 2.00 Alpha 的神經網絡應用
- 六、使用 TensorFlow 2 識別圖像
- 七、TensorFlow 2 和神經風格遷移
- 八、TensorFlow 2 和循環神經網絡
- 九、TensorFlow 估計器和 TensorFlow HUB
- 十、從 tf1.12 轉換為 tf2
- TensorFlow 入門
- 零、前言
- 一、TensorFlow 基本概念
- 二、TensorFlow 數學運算
- 三、機器學習入門
- 四、神經網絡簡介
- 五、深度學習
- 六、TensorFlow GPU 編程和服務
- TensorFlow 卷積神經網絡實用指南
- 零、前言
- 一、TensorFlow 的設置和介紹
- 二、深度學習和卷積神經網絡
- 三、TensorFlow 中的圖像分類
- 四、目標檢測與分割
- 五、VGG,Inception,ResNet 和 MobileNets
- 六、自編碼器,變分自編碼器和生成對抗網絡
- 七、遷移學習
- 八、機器學習最佳實踐和故障排除
- 九、大規模訓練
- 十、參考文獻