
# 一、探索和轉換數據
TensorFlow 是用于使用數據流圖進行數值計算的開源軟件庫。 圖中的節點表示數學運算,而圖的邊緣表示在它們之間傳遞的多維數據數組(張量)。
該庫包含各種函數,使您能夠實現和探索用于圖像和文本處理的最先進的卷積神經網絡(CNN)和循環神經網絡(RNN)架構。 由于復雜的計算以圖的形式排列,因此 TensorFlow 可用作框架,使您能夠輕松開發自己的模型并將其用于機器學習領域。
它還能夠在從 CPU 到移動處理器(包括高度并行的 GPU 計算)的大多數異構環境中運行,并且新的服務架構可以在所有指定選項的非常復雜的混合環境中運行:
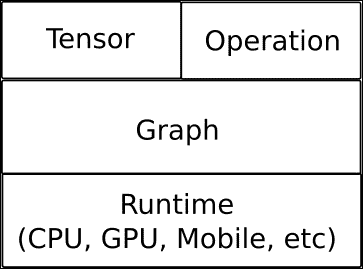
# TensorFlow 的主要數據結構 -- 張量
TensorFlow 的數據管理基于張量。 張量是來自數學領域的概念,并且是作為向量和矩陣的線性代數項的概括而開發的。
專門討論 TensorFlow 時,張量只是在張量對象中建模的帶類型的多維數組,帶有其他操作。
## 張量屬性 -- 階數,形狀和類型
如前所述,TensorFlow 使用張量數據結構表示所有數據。 任何張量都具有靜態類型和動態尺寸,因此您可以實時更改張量的內部組織。
張量的另一個特性是,只有張量類型的對象才能在計算圖中的節點之間傳遞。
現在讓我們看一下張量的屬性是什么(從現在開始,每次使用張量這個詞時,我們都將引用 TensorFlow 的張量對象)。
### 張量階數
張量階數表示張量的維度方面,但與矩陣階數不同。 它表示張量所處的維數,而不是行/列或等效空間中張量擴展的精確度量。
秩為 1 的張量等于向量,秩為 2 的張量是矩陣。 對于二階張量,您可以使用語法`t[i, j]`訪問任何元素。 對于三階張量,您將需要使用`t[i, j, k]`來尋址元素,依此類推。
在下面的示例中,我們將創建一個張量,并訪問其分量之一:
```py
>>> import tensorflow as tf
>>> tens1 = tf.constant([[[1,2],[2,3]],[[3,4],[5,6]]])
>>> print sess.run(tens1)[1,1,0]
5
```
這是三階張量,因為在包含矩陣的每個元素中都有一個向量元素:
| 秩 | 數學實體 | 代碼定義示例 |
| --- | --- | --- |
| 0 | 標量 | `scalar = 1000` |
| 1 | 向量 | `vector = [2, 8, 3]` |
| 2 | 矩陣 | `matrix = [[4, 2, 1], [5, 3, 2], [5, 5, 6]]` |
| 3 | 3 階張量 | `tensor = [[[4], [3], [2]], [[6], [100], [4]], [[5], [1], [4]]]` |
| n | n 階張量 | ... |
### 張量形狀
TensorFlow 文檔使用三種符號約定來描述張量維數:階數,形狀和維數。 下表顯示了它們之間的相互關系:
| 秩 | 形狀 | 維度數量 | 示例 |
| --- | --- | --- | --- |
| 0 | `[]` | 0 | `4` |
| 1 | `[D0]` | 1 | `[2]` |
| 2 | `[D0,D1]` | 2 | `[6, 2]` |
| 3 | `[D0,D1,D2]` | 3 | `[7, 3, 2]` |
| n | `[D0,D1,... Dn-1]` | d | 形狀為`[D0, D1, ..., Dn-1]`的張量。 |
在下面的示例中,我們創建一個樣本階數三張量,并打印其形狀:

### 張量數據類型
除了維數外,張量還具有固定的數據類型。 您可以將以下任意一種數據類型分配給張量:
| 數據類型 | Python 類型 | 描述 |
| --- | --- | --- |
| `DT_FLOAT` | `tf.float32` | 32 位浮點。 |
| `DT_DOUBLE` | `tf.float64` | 64 位浮點。 |
| `DT_INT8` | `tf.int8` | 8 位有符號整數。 |
| `DT_INT16` | `tf.int16` | 16 位有符號整數。 |
| `DT_INT32` | `tf.int32` | 32 位有符號整數。 |
| `DT_INT64` | `tf.int64` | 64 位有符號整數。 |
| `DT_UINT8` | `tf.uint8` | 8 位無符號整數。 |
| `DT_STRING` | `tf.string` | 可變長度字節數組。 張量的每個元素都是一個字節數組。 |
| `DT_BOOL` | `tf.bool` | 布爾值。 |
## 創建新的張量
我們可以創建自己的張量,也可以從著名的 numpy 庫派生它們。 在以下示例中,我們創建一些 numpy 數組,并對其進行一些基本數學運算:
```py
import tensorflow as tf
import numpy as np
x = tf.constant(np.random.rand(32).astype(np.float32))
y= tf.constant ([1,2,3])
```
### 從 numpy 到張量,以及反向
TensorFlow 可與 numpy 互操作,通常`eval()`函數調用將返回一個 numpy 對象,準備與標準數值工具一起使用。
### 提示
我們必須注意,張量對象是操作結果的符號句柄,因此它不保存其包含的結構的結果值。 因此,我們必須運行`eval()`方法來獲取實際值,該值等于`Session.run(tensor_to_eval)`。
在此示例中,我們構建了兩個 numpy 數組,并將它們轉換為張量:
```py
import tensorflow as tf #we import tensorflow
import numpy as np #we import numpy
sess = tf.Session() #start a new Session Object
x_data = np.array([[1.,2.,3.],
[3.,2.,6.]]) # 2x3 matrix
x = tf.convert_to_tensor(x_data, dtype=tf.float32) #Finally, we create the tensor, starting from the fload 3x matrix
```
#### 有用的方法
`tf.convert_to_tensor`:此函數將各種類型的 Python 對象轉換為張量對象。 它接受張量對象,numpy 數組,Python 列表和 Python 標量。
## 完成工作 -- 與 TensorFlow 交互
與大多數 Python 模塊一樣,TensorFlow 允許使用 Python 的交互式控制臺:
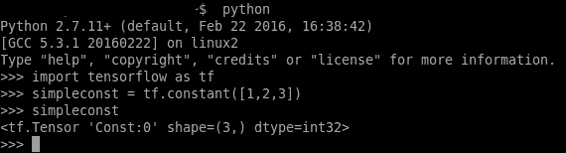
與 Python 的解釋器和 TensorFlow 庫輕松交互
在上圖中,我們調用 Python 解釋器(通過簡單地調用 Python)并創建常量類型的張量。 然后我們再次調用它,Python 解釋器顯示張量的形狀和類型。
我們還可以使用 IPython 解釋器,該解釋器將允許我們采用與筆記本樣式工具(例如 Jupyter)更兼容的格式:
IPython 提示
在談論以交互方式運行 TensorFlow 會話時,最好使用`InteractiveSession`對象。
與普通的`tf.Session`類不同,`tf.InteractiveSession`類將自身安裝為構造時的默認會話。 因此,當您嘗試求值張量或運行操作時,將不需要傳遞`Session`對象來指示它所引用的會話。
# 處理計算工作流程 -- TensorFlow 的數據流程圖
TensorFlow 的數據流圖是模型計算如何工作的符號表示:
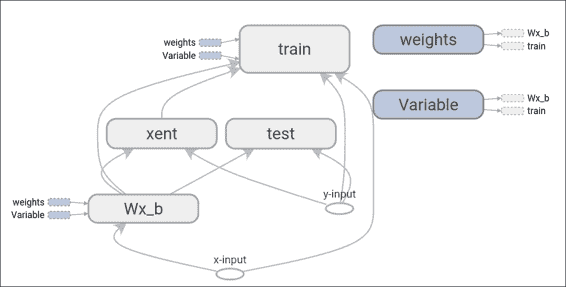
在 TensorBoard 上繪制的簡單數據流圖表示
簡而言之,數據流圖是一個完整的 TensorFlow 計算,表示為一個圖,其中節點是操作,邊是操作之間的數據流。
通常,節點執行數學運算,但也表示連接以輸入數據或變量,或推出結果。
邊緣描述節點之間的輸入/輸出關系。 這些數據邊僅傳輸張量。 節點被分配給計算設備,并且一旦它們進入邊緣上的所有張量都可用,就會異步并行執行。
所有運算都有一個名稱,并表示一個抽象計算(例如,矩陣求逆或乘積)。
## 計算圖構建
通常在庫用戶創建張量和模型將支持的操作時構建計算圖,因此無需直接構建`Graph()`對象。 Python 張量構造器,例如`tf.constant()`,會將必要的元素添加到默認圖。 TensorFlow 操作也會發生同樣的情況。
例如,`c = tf.matmul(a, b)`創建一個`MatMul`類型的操作,該操作將張量`a`和`b`作為輸入并產生`c`作為輸出。
### 有用的操作對象方法
* `tf.Operation.type`:返回操作的類型(例如`MatMul`)
* `tf.Operation.inputs`:返回代表操作輸入的張量對象列表
* `tf.Graph.get_operations()`:返回圖中的操作列表
* `tf.Graph.version`:返回圖的自動數字版本
## 饋送
TensorFlow 還提供了一種饋送機制,可將張量直接修補到圖中的任何操作中。
提要用張量值臨時替換操作的輸出。 您將提要數據作為`run()`調用的參數提供。 提要僅用于傳遞給它的運行調用。 最常見的用例涉及通過使用`tf.placeholder()`創建特定的操作,使其指定為`feed`操作。
## 變量
在大多數計算中,圖執行多次。 大多數張量都無法通過圖的一次執行而幸存。 但是,變量是一種特殊的操作,它可以將句柄返回到持久可變的張量,該張量在圖執行過程中仍然存在。 對于 TensorFlow 的機器學習應用,模型的參數通常存儲在變量中保存的張量中,并在運行模型的訓練圖時進行更新。
### 變量初始化
要初始化變量,只需使用張量作為參數調用`Variable`對象構造器。
在此示例中,我們使用`1000`零數組初始化了一些變量:
```py
b = tf.Variable(tf.zeros([1000]))
```
## 保存數據流程圖
數據流圖是使用 Google 的協議緩沖區編寫的,因此以后可以使用多種語言進行讀取。
### 圖序列化語言 -- 協議緩沖區
協議緩沖區是一種不依賴語言,不依賴平臺的可擴展機制,用于序列化結構化數據。 首先定義數據結構,然后可以使用專門生成的代碼來使用多種語言進行讀寫。
#### 有用的方法
`tf.Graph.as_graph_def(from_version=None, add_shapes=False)`:返回此圖的序列化`GraphDef`表示形式。
參數:
* `from_version`:如果設置了此選項,它將返回帶有從該版本添加的節點的`GraphDef`
* `add_shapes`:如果`true`,則向每個節點添加一個`shape`屬性
### 建立圖的示例
在此示例中,我們將構建一個非常簡單的數據流圖,并觀察生成的 protobuffer 文件的概述:
```py
import tensorflow as tf
g = tf.Graph()
with g.as_default():
import tensorflow as tf
sess = tf.Session()
W_m = tf.Variable(tf.zeros([10, 5]))
x_v = tf.placeholder(tf.float32, [None, 10])
result = tf.matmul(x_v, W_m)
print g.as_graph_def()
```
生成的 protobuffer(摘要)為:
```py
node {
name: "zeros"
op: "Const"
attr {
key: "dtype"
value {
type: DT_FLOAT
}
}
attr {
key: "value"
value {
tensor {
dtype: DT_FLOAT
tensor_shape {
dim {
size: 10
}
dim {
size: 5
}
}
float_val: 0.0
}
}
}
}
...
node {
name: "MatMul"
op: "MatMul"
input: "Placeholder"
input: "Variable/read"
attr {
key: "T"
value {
type: DT_FLOAT
}
}
...
}
versions {
producer: 8
}
```
# 運行我們的程序 -- 會話
客戶端程序通過創建會話與 TensorFlow 系統交互。 會話對象表示將在其中運行計算的環境。 `Session`對象開始為空,并且當程序員創建不同的操作和張量時,它們將被自動添加到`Session`中,在調用`Run()`方法之前,該對象不會進行任何計算。
`Run()`方法采用一組需要計算的輸出名稱,以及一組可選的張量,以代替節點的某些輸出輸入到圖中。
如果調用此方法,并且命名操作依賴于某些操作,則`Session`對象將執行所有這些操作,然后繼續執行命名操作。
這條簡單的線是創建會話所需的唯一一行:
```py
s = tf.Session()
Sample command line output:
tensorflow/core/common_runtime/local_session.cc:45]Localsessioninteropparallelism threads:6
```
# 基本張量方法
在本節中,我們將探索 TensorFlow 支持的一些基本方法。 它們對于初始數據探索和為更好的并行計算準備數據很有用。
## 簡單矩陣運算
TensorFlow 支持許多更常見的矩陣運算,例如轉置,乘法,獲取行列式和逆運算。
這是應用于樣本數據的那些函數的一個小例子:
```py
In [1]: import tensorflow as tf
In [2]: sess = tf.InteractiveSession()
In [3]: x = tf.constant([[2, 5, 3, -5],
...: [0, 3,-2, 5],
...: [4, 3, 5, 3],
...: [6, 1, 4, 0]])
In [4]: y = tf.constant([[4, -7, 4, -3, 4],
...: [6, 4,-7, 4, 7],
...: [2, 3, 2, 1, 4],
...: [1, 5, 5, 5, 2]])
In [5]: floatx = tf.constant([[2., 5., 3., -5.],
...: [0., 3.,-2., 5.],
...: [4., 3., 5., 3.],
...: [6., 1., 4., 0.]])
In [6]: tf.transpose(x).eval() # Transpose matrix
Out[6]:
array([[ 2, 0, 4, 6],
[ 5, 3, 3, 1],
[ 3, -2, 5, 4],
[-5, 5, 3, 0]], dtype=int32)
In [7]: tf.matmul(x, y).eval() # Matrix multiplication
Out[7]:
array([[ 39, -10, -46, -8, 45],
[ 19, 31, 0, 35, 23],
[ 47, 14, 20, 20, 63],
[ 38, -26, 25, -10, 47]], dtype=int32)
In [8]: tf.matrix_determinant(floatx).eval() # Matrix determinant
Out[8]: 818.0
In [9]: tf.matrix_inverse(floatx).eval() # Matrix inverse
Out[9]:
array([[-0.00855745, 0.10513446, -0.18948655, 0.29584351],
[ 0.12958434, 0.12224938, 0.01222495, -0.05134474],
[-0.01955992, -0.18826403, 0.28117359, -0.18092911],
[-0.08557458, 0.05134474, 0.10513448, -0.0415648 ]], dtype=float32)
In [10]: tf.matrix_solve(floatx, [[1],[1],[1],[1]]).eval() # Solve Matrix system
Out[10]:
array([[ 0.20293398],
[ 0.21271393],
[-0.10757945],
[ 0.02933985]], dtype=float32)
```
### 歸約
歸約運算是對張量的一個維度進行運算的操作,而其維數較小。
支持的操作(具有相同參數)包括乘積,最小值,最大值,平均值,所有,任意和`accumulate_n`)。
```py
In [1]: import tensorflow as tf
In [2]: sess = tf.InteractiveSession()
In [3]: x = tf.constant([[1, 2, 3],
...: [3, 2, 1],
...: [-1,-2,-3]])
In [4]:
In [4]: boolean_tensor = tf.constant([[True, False, True],
...: [False, False, True],
...: [True, False, False]])
In [5]: tf.reduce_prod(x, reduction_indices=1).eval() # reduce prod
Out[5]: array([ 6, 6, -6], dtype=int32)
In [6]: tf.reduce_min(x, reduction_indices=1).eval() # reduce min
Out[6]: array([ 1, 1, -3], dtype=int32)
In [7]: tf.reduce_max(x, reduction_indices=1).eval() # reduce max
Out[7]: array([ 3, 3, -1], dtype=int32)
In [8]: tf.reduce_mean(x, reduction_indices=1).eval() # reduce mean
Out[8]: array([ 2, 2, -2], dtype=int32)
In [9]: tf.reduce_all(boolean_tensor, reduction_indices=1).eval() # reduce all
Out[9]: array([False, False, False], dtype=bool)
In [10]: tf.reduce_any(boolean_tensor, reduction_indices=1).eval() # reduce any
Out[10]: array([ True, True, True], dtype=bool)
```
### 張量分段
張量分段是一個過程,其中某個維度被歸約,并且所得元素由索引行確定。 如果該行中的某些元素被重復,則對應的索引將轉到其中的值,并且該操作將在具有重復索引的索引之間應用。
索引數組的大小應與索引數組的維度 0 的大小相同,并且必須增加 1。
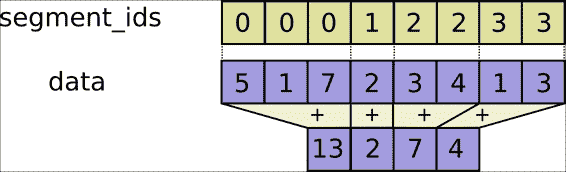
細分說明(重做)
```py
In [1]: import tensorflow as tf
In [2]: sess = tf.InteractiveSession()
In [3]: seg_ids = tf.constant([0,1,1,2,2]); # Group indexes : 0|1,2|3,4
In [4]: tens1 = tf.constant([[2, 5, 3, -5],
...: [0, 3,-2, 5],
...: [4, 3, 5, 3],
...: [6, 1, 4, 0],
...: [6, 1, 4, 0]]) # A sample constant matrix
In [5]: tf.segment_sum(tens1, seg_ids).eval() # Sum segmentation
Out[5]:
array([[ 2, 5, 3, -5],
[ 4, 6, 3, 8],
[12, 2, 8, 0]], dtype=int32)
In [6]: tf.segment_prod(tens1, seg_ids).eval() # Product segmentation
Out[6]:
array([[ 2, 5, 3, -5],
[ 0, 9, -10, 15],
[ 36, 1, 16, 0]], dtype=int32)
In [7]: tf.segment_min(tens1, seg_ids).eval() # minimun value goes to group
Out[7]:
array([[ 2, 5, 3, -5],
[ 0, 3, -2, 3],
[ 6, 1, 4, 0]], dtype=int32)
In [8]: tf.segment_max(tens1, seg_ids).eval() # maximum value goes to group
Out[8]:
array([[ 2, 5, 3, -5],
[ 4, 3, 5, 5],
[ 6, 1, 4, 0]], dtype=int32)
In [9]: tf.segment_mean(tens1, seg_ids).eval() # mean value goes to group
Out[9]:
array([[ 2, 5, 3, -5],
[ 2, 3, 1, 4],
[ 6, 1, 4, 0]], dtype=int32)
```
## 序列
序列工具包括諸如`argmin`和`argmax`(顯示維度的最小值和最大值),`listdiff`(顯示列表之間交集的補碼),`where`(顯示真實值的索引)和`unique`(在列表上顯示唯一值)之類的張量方法。
```py
In [1]: import tensorflow as tf
In [2]: sess = tf.InteractiveSession()
In [3]: x = tf.constant([[2, 5, 3, -5],
...: [0, 3,-2, 5],
...: [4, 3, 5, 3],
...: [6, 1, 4, 0]])
In [4]: listx = tf.constant([1,2,3,4,5,6,7,8])
In [5]: listy = tf.constant([4,5,8,9])
In [6]:
In [6]: boolx = tf.constant([[True,False], [False,True]])
In [7]: tf.argmin(x, 1).eval() # Position of the maximum value of columns
Out[7]: array([3, 2, 1, 3])
In [8]: tf.argmax(x, 1).eval() # Position of the minimum value of rows
Out[8]: array([1, 3, 2, 0])
In [9]: tf.listdiff(listx, listy)[0].eval() # List differences
Out[9]: array([1, 2, 3, 6, 7], dtype=int32)
In [10]: tf.where(boolx).eval() # Show true values
Out[10]:
array([[0, 0],
[1, 1]])
In [11]: tf.unique(listx)[0].eval() # Unique values in list
Out[11]: array([1, 2, 3, 4, 5, 6, 7, 8], dtype=int32)
```
## 張量形狀變換
這些操作與矩陣形狀有關,用于調整不匹配的數據結構并檢索有關數據量度的快速信息。 這在確定運行時的處理策略時很有用。
在以下示例中,我們將從第二張量張量開始,并將打印有關它的一些信息。
然后,我們將探討按維度修改矩陣的操作,包括添加或刪除維度,例如`squeeze`和`expand_dims`:
```py
In [1]: import tensorflow as tf
In [2]: sess = tf.InteractiveSession()
In [3]: x = tf.constant([[2, 5, 3, -5],
...: [0, 3,-2, 5],
...: [4, 3, 5, 3],
...: [6, 1, 4, 0]])
In [4]: tf.shape(x).eval() # Shape of the tensor
Out[4]: array([4, 4], dtype=int32)
In [5]: tf.size(x).eval() # size of the tensor
Out[5]: 16
In [6]: tf.rank(x).eval() # rank of the tensor
Out[6]: 2
In [7]: tf.reshape(x, [8, 2]).eval() # converting to a 10x2 matrix
Out[7]:
array([[ 2, 5],
[ 3, -5],
[ 0, 3],
[-2, 5],
[ 4, 3],
[ 5, 3],
[ 6, 1],
[ 4, 0]], dtype=int32)
In [8]: tf.squeeze(x).eval() # squeezing
Out[8]:
array([[ 2, 5, 3, -5],
[ 0, 3, -2, 5],
[ 4, 3, 5, 3],
[ 6, 1, 4, 0]], dtype=int32)
In [9]: tf.expand_dims(x,1).eval() #Expanding dims
Out[9]:
array([[[ 2, 5, 3, -5]],
[[ 0, 3, -2, 5]],
[[ 4, 3, 5, 3]],
[[ 6, 1, 4, 0]]], dtype=int32)
```
### 張量切片和合并
為了從大型數據集中提取和合并有用的信息,切片和聯接方法使您可以合并所需的列信息,而不必使用非特定信息來占用內存空間。
在以下示例中,我們將提取矩陣切片,對其進行分割,添加填充以及對行進行打包和解包:
```py
In [1]: import tensorflow as tf
In [2]: sess = tf.InteractiveSession()
In [3]: t_matrix = tf.constant([[1,2,3],
...: [4,5,6],
...: [7,8,9]])
In [4]: t_array = tf.constant([1,2,3,4,9,8,6,5])
In [5]: t_array2= tf.constant([2,3,4,5,6,7,8,9])
In [6]: tf.slice(t_matrix, [1, 1], [2,2]).eval() # cutting an slice
Out[6]:
array([[5, 6],
[8, 9]], dtype=int32)
In [7]: tf.split(0, 2, t_array) # splitting the array in two
Out[7]:
[<tf.Tensor 'split:0' shape=(4,) dtype=int32>,
<tf.Tensor 'split:1' shape=(4,) dtype=int32>]
In [8]: tf.tile([1,2],[3]).eval() # tiling this little tensor 3 times
Out[8]: array([1, 2, 1, 2, 1, 2], dtype=int32)
In [9]: tf.pad(t_matrix, [[0,1],[2,1]]).eval() # padding
Out[9]:
array([[0, 0, 1, 2, 3, 0],
[0, 0, 4, 5, 6, 0],
[0, 0, 7, 8, 9, 0],
[0, 0, 0, 0, 0, 0]], dtype=int32)
In [10]: tf.concat(0, [t_array, t_array2]).eval() #concatenating list
Out[10]: array([1, 2, 3, 4, 9, 8, 6, 5, 2, 3, 4, 5, 6, 7, 8, 9], dtype=int32)
In [11]: tf.pack([t_array, t_array2]).eval() # packing
Out[11]:
array([[1, 2, 3, 4, 9, 8, 6, 5],
[2, 3, 4, 5, 6, 7, 8, 9]], dtype=int32)
In [12]: sess.run(tf.unpack(t_matrix)) # Unpacking, we need the run method to view the tensors
Out[12]:
[array([1, 2, 3], dtype=int32),
array([4, 5, 6], dtype=int32),
array([7, 8, 9], dtype=int32)]
In [13]: tf.reverse(t_matrix, [False,True]).eval() # Reverse matrix
Out[13]:
array([[3, 2, 1],
[6, 5, 4],
[9, 8, 7]], dtype=int32)
```
## 數據流結構和結果可視化 -- TensorBoard
可視化摘要信息是任何數據科學家工具箱的重要組成部分。
TensorBoard 是一個軟件工具,它允許數據流圖的圖形表示和用于解釋結果的儀表板,通常來自日志記錄工具:
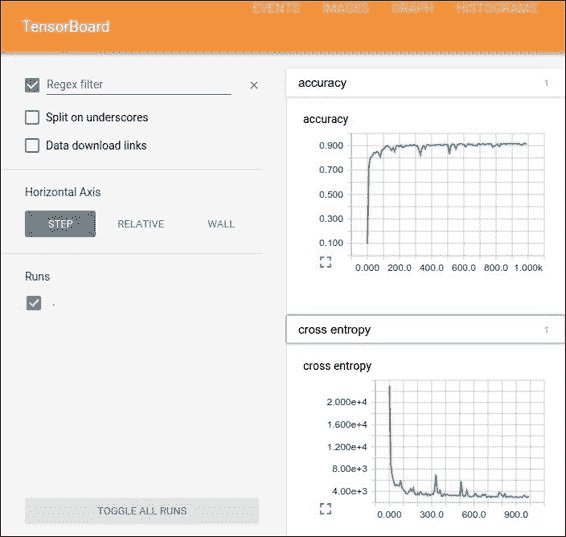
TensorBoard GUI
可以將圖的所有張量和操作設置為將信息寫入日志。 TensorBoard 分析在`Session`運行時正常編寫的信息,并向用戶顯示許多圖形項,每個圖形項一個。
### 命令行用法
要調用 TensorBoard,命令行為:

## TensorBoard 的工作方式
我們構建的每個計算圖都有 TensorFlow 的實時日志記錄機制,以便保存模型擁有的幾乎所有信息。
但是,模型構建者必須考慮應保存的幾百個信息維中的哪一個,以后才能用作分析工具。
為了保存所有必需的信息,TensorFlow API 使用了稱為摘要的數據輸出對象。
這些摘要將結果寫入 TensorFlow 事件文件,該文件收集在`Session`運行期間生成的所有必需數據。
在以下示例中,我們將直接在生成的事件日志目錄上運行 TensorBoard:

### 添加摘要節點
TensorFlow 會話中的所有摘要均由`SummaryWriter`對象編寫。 調用的主要方法是:
```py
tf.train.SummaryWriter.__init__(logdir, graph_def=None)
```
該命令將在參數的路徑中創建一個`SummaryWriter`和一個事件文件。
`SummaryWriter`的構造器將在`logdir`中創建一個新的事件文件。 當您調用以下函數之一時,此事件文件將包含`Event`類型的協議緩沖區:`add_summary()`,`add_session_log()`,`add_event()`或`add_graph()`。
如果將`graph_def`協議緩沖區傳遞給構造器,則會將其添加到事件文件中。 (這等效于稍后調用`add_graph()`)。
當您運行 TensorBoard 時,它將從文件中讀取圖定義并以圖形方式顯示它,以便您可以與其進行交互。
首先,創建您要從中收集摘要數據的 TensorFlow 圖,并確定要使用摘要操作標注的節點。
TensorFlow 中的操作在您運行它們或取決于它們的輸出的操作之前不會做任何事情。 我們剛剛創建的摘要節點是圖的外圍:當前運行的所有操作都不依賴于它們。 因此,要生成摘要,我們需要運行所有這些摘要節點。 手動管理它們很繁瑣,因此請使用`tf.merge_all_summaries`將它們組合為一個可生成所有摘要數據的操作。
然后,您可以運行合并的摘要操作,這將在給定步驟中生成一個包含所有摘要數據的序列化摘要`protobuf`對象。 最后,要將摘要數據寫入磁盤,請將摘要`protobuf`傳遞給`tf.train.SummaryWriter`。
`SummaryWriter`在其構造器中帶有`logdir`,此`logdir`非常重要,它是所有事件將被寫出的目錄。 同樣,`SummaryWriter`可以選擇在其構造器中使用`GraphDef`。 如果收到一個,TensorBoard 還將可視化您的圖。
現在,您已經修改了圖并具有`SummaryWriter`,就可以開始運行網絡了! 如果需要,您可以在每個步驟中運行合并的摘要操作,并記錄大量的訓練數據。 不過,這可能是您需要的更多數據。 相反,請考慮每 n 個步驟運行一次合并的摘要操作。
### 通用摘要操作
這是不同的摘要類型及其構造所使用的參數的列表:
* `tf.scalar_summary(label, value, collection=None, name=None)`
* `tf.image_summary(label, tensor, max_images=3, collection=None, name=None)`
* `tf.histogram_summary(label, value, collection=None, name=None)`
### 特殊摘要函數
這些是特殊函數,用于合并不同操作的值,無論是摘要的集合,還是圖中的所有摘要:
* `tf.merge_summary(input, collection=None, name=None)`
* `tf.merge_all_summaries(key="summary")`
最后,作為提高可讀性的最后一項幫助,可視化對常數和匯總節點使用特殊的圖標。 總而言之,這是節點符號表:
| 符號 | 含義 |
| --- | --- |
|  | 代表名稱范圍的高級節點。 雙擊以展開一個高級節點。 |
|  | 彼此不連接的編號節點序列。 |
|  | 彼此連接的編號節點序列。 |
|  | 單個操作節點。 |
|  | 一個常數。 |
|  | 摘要節點。 |
|  | 顯示操作之間的數據流的邊。 |
|  | 顯示操作之間的控制依賴項的邊。 |
|  | 顯示輸出操作節點可以改變輸入張量的參考邊。 |
### 與 TensorBoard 的 GUI 交互
通過平移和縮放來瀏覽圖形。單擊并拖動以進行平移,然后使用滾動手勢進行縮放。 雙擊節點,或單擊其`+`按鈕,以展開表示操作代碼的名稱范圍。 為了輕松跟蹤縮放時的當前視點,右下角有一個小地圖:
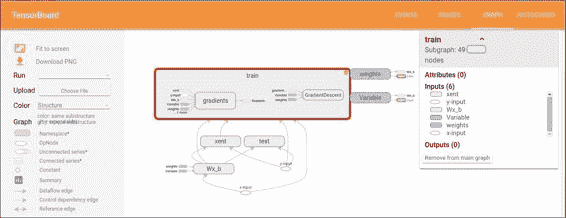
具有一個擴展的操作組和圖例的 Openflow
要關閉打開的節點,請再次雙擊它或單擊其`-`按鈕。 您也可以單擊一次以選擇一個節點。 它將變為較暗的顏色,有關該顏色及其連接的節點的詳細信息將顯示在可視化文件右上角的信息卡中。
選擇還有助于理解高級節點。 選擇任何高度節點,其他連接的相應節點圖標也會被選擇。 例如,這可以輕松查看正在保存的節點和未保存的節點。
單擊信息卡中的節點名稱將其選中。 如有必要,視點將自動平移以使該節點可見。
最后,您可以使用圖例上方的顏色菜單為圖形選擇兩種配色方案。 默認的“結構視圖”顯示結構:當兩個高級節點具有相同的結構時,它們以相同的彩虹色顯示。 唯一結構化的節點為灰色。 第二個視圖顯示了不同操作在哪個設備上運行。 名稱范圍的顏色與設備中用于其內部操作的部分的比例成比例。
## 從磁盤讀取信息
TensorFlow 讀取許多最標準的格式,包括眾所周知的 CSV,圖像文件(JPG 和 PNG 解碼器)以及標準 TensorFlow 格式。
### 列表格式 -- CSV
為了讀取眾所周知的 CSV 格式,TensorFlow 有自己的方法。 與其他庫(例如熊貓)相比,讀取簡單 CSV 文件的過程稍微復雜一些。
讀取 CSV 文件需要完成前面的幾個步驟。 首先,我們必須使用要使用的文件列表創建文件名隊列對象,然后創建`TextLineReader`。 使用此行讀取器,剩下的操作將是解碼 CSV 列,并將其保存在張量上。 如果我們想將同類數據混合在一起,則`pack`方法將起作用。
#### 鳶尾花數據集
鳶尾花數據集或費舍爾鳶尾花數據集是分類問題的眾所周知基準。 這是羅納德·費舍爾(Ronald Fisher)在 1936 年的論文中引入的多元數據集,該分類法是將生物分類問題中的多次測量用作線性判別分析的示例。
數據集包含來自三種鳶尾花(鳶尾鳶尾,初春鳶尾和雜色鳶尾)中每種的 50 個樣本。 在每個樣本中測量了四個特征:萼片和花瓣的長度和寬度,以厘米為單位。 基于這四個特征的組合,Fisher 開發了一個線性判別模型以區分物種。 (您可以在書的代碼包中獲取此數據集的`.csv`文件。)
為了讀取 CSV 文件,您必須下載它并將其放在與 Python 可執行文件運行所在的目錄中。
在下面的代碼示例中,我們將從知名的鳶尾數據庫中讀取和打印前五個記錄:
```py
import tensorflow as tf
sess = tf.Session()
filename_queue = tf.train.string_input_producer(
tf.train.match_filenames_once("./*.csv"),
shuffle=True)
reader = tf.TextLineReader(skip_header_lines=1)
key, value = reader.read(filename_queue)
record_defaults = [[0.], [0.], [0.], [0.], [""]]
col1, col2, col3, col4, col5 = tf.decode_csv(value, record_defaults=record_defaults) # Convert CSV records to tensors. Each column maps to one tensor.
features = tf.pack([col1, col2, col3, col4])
tf.initialize_all_variables().run(session=sess)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord, sess=sess)
for iteration in range(0, 5):
example = sess.run([features])
print(example)
coord.request_stop()
coord.join(threads)
```
這就是輸出的樣子:
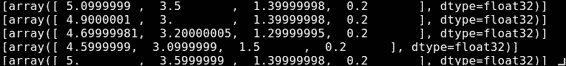
### 讀取圖像數據
TensorFlow 允許從圖像格式導入數據,這對于導入面向圖像的模型的自定義圖像輸入將非常有用。可接受的圖像格式將為 JPG 和 PNG,內部表示形式為`uint8`張量,每個張量為圖片通道的二階張量:

要讀取的樣本圖像
### 加載和處理圖像
在此示例中,我們將加載示例圖像并對其進行一些其他處理,將生成的圖像保存在單獨的文件中:
```py
import tensorflow as tf
sess = tf.Session()
filename_queue = tf.train.string_input_producer(tf.train.match_filenames_once("./blue_jay.jpg"))
reader = tf.WholeFileReader()
key, value = reader.read(filename_queue)
image=tf.image.decode_jpeg(value)
flipImageUpDown=tf.image.encode_jpeg(tf.image.flip_up_down(image))
flipImageLeftRight=tf.image.encode_jpeg(tf.image.flip_left_right(image))
tf.initialize_all_variables().run(session=sess)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord, sess=sess)
example = sess.run(flipImageLeftRight)
print example
file=open ("flippedUpDown.jpg", "wb+")
file.write (flipImageUpDown.eval(session=sess))
file.close()
file=open ("flippedLeftRight.jpg", "wb+")
file.write (flipImageLeftRight.eval(session=sess))
file.close()
```
`print example`行將逐行顯示圖像中 RGB 值的摘要:
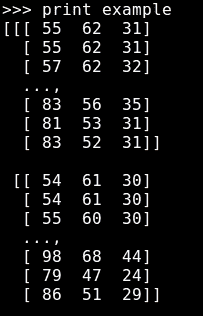
最終圖像如下所示:

比較原始圖像和變更后的圖像(上下翻轉和左右翻轉)
### 從標準 TensorFlow 格式讀取
另一種方法是將您擁有的任意數據轉換為正式格式。 這種方法使混合和匹配數據集和網絡架構變得更加容易。
您可以編寫一個獲取數據的小程序,將其填充到示例協議緩沖區中,將協議緩沖區序列化為字符串,然后使用`tf.python_io.TFRecordWriter`類將字符串寫入`TFRecords`文件。
要讀取`TFRecords`的文件,請將`tf.TFRecordReader`與`tf.parse_single_example`解碼器一起使用。 `parse_single_example` `op`將示例協議緩沖區解碼為張量。
# 總結
在本章中,我們學習了可應用于數據的主要數據結構和簡單操作,并對計算圖的各個部分進行了簡要總結。
這些操作將成為即將出現的技術的基礎。 通過這些類,數據科學家可以在查看當前數據的總體特征之后,確定類的分離或調整特征是否足夠清晰,或者直接使用更復雜的工具,從而決定是否使用更簡單的模型。
在下一章中,我們將開始構建和運行圖,并使用本章中介紹的某些方法來解決問題。
- TensorFlow 1.x 深度學習秘籍
- 零、前言
- 一、TensorFlow 簡介
- 二、回歸
- 三、神經網絡:感知器
- 四、卷積神經網絡
- 五、高級卷積神經網絡
- 六、循環神經網絡
- 七、無監督學習
- 八、自編碼器
- 九、強化學習
- 十、移動計算
- 十一、生成模型和 CapsNet
- 十二、分布式 TensorFlow 和云深度學習
- 十三、AutoML 和學習如何學習(元學習)
- 十四、TensorFlow 處理單元
- 使用 TensorFlow 構建機器學習項目中文版
- 一、探索和轉換數據
- 二、聚類
- 三、線性回歸
- 四、邏輯回歸
- 五、簡單的前饋神經網絡
- 六、卷積神經網絡
- 七、循環神經網絡和 LSTM
- 八、深度神經網絡
- 九、大規模運行模型 -- GPU 和服務
- 十、庫安裝和其他提示
- TensorFlow 深度學習中文第二版
- 一、人工神經網絡
- 二、TensorFlow v1.6 的新功能是什么?
- 三、實現前饋神經網絡
- 四、CNN 實戰
- 五、使用 TensorFlow 實現自編碼器
- 六、RNN 和梯度消失或爆炸問題
- 七、TensorFlow GPU 配置
- 八、TFLearn
- 九、使用協同過濾的電影推薦
- 十、OpenAI Gym
- TensorFlow 深度學習實戰指南中文版
- 一、入門
- 二、深度神經網絡
- 三、卷積神經網絡
- 四、循環神經網絡介紹
- 五、總結
- 精通 TensorFlow 1.x
- 一、TensorFlow 101
- 二、TensorFlow 的高級庫
- 三、Keras 101
- 四、TensorFlow 中的經典機器學習
- 五、TensorFlow 和 Keras 中的神經網絡和 MLP
- 六、TensorFlow 和 Keras 中的 RNN
- 七、TensorFlow 和 Keras 中的用于時間序列數據的 RNN
- 八、TensorFlow 和 Keras 中的用于文本數據的 RNN
- 九、TensorFlow 和 Keras 中的 CNN
- 十、TensorFlow 和 Keras 中的自編碼器
- 十一、TF 服務:生產中的 TensorFlow 模型
- 十二、遷移學習和預訓練模型
- 十三、深度強化學習
- 十四、生成對抗網絡
- 十五、TensorFlow 集群的分布式模型
- 十六、移動和嵌入式平臺上的 TensorFlow 模型
- 十七、R 中的 TensorFlow 和 Keras
- 十八、調試 TensorFlow 模型
- 十九、張量處理單元
- TensorFlow 機器學習秘籍中文第二版
- 一、TensorFlow 入門
- 二、TensorFlow 的方式
- 三、線性回歸
- 四、支持向量機
- 五、最近鄰方法
- 六、神經網絡
- 七、自然語言處理
- 八、卷積神經網絡
- 九、循環神經網絡
- 十、將 TensorFlow 投入生產
- 十一、更多 TensorFlow
- 與 TensorFlow 的初次接觸
- 前言
- 1.?TensorFlow 基礎知識
- 2. TensorFlow 中的線性回歸
- 3. TensorFlow 中的聚類
- 4. TensorFlow 中的單層神經網絡
- 5. TensorFlow 中的多層神經網絡
- 6. 并行
- 后記
- TensorFlow 學習指南
- 一、基礎
- 二、線性模型
- 三、學習
- 四、分布式
- TensorFlow Rager 教程
- 一、如何使用 TensorFlow Eager 構建簡單的神經網絡
- 二、在 Eager 模式中使用指標
- 三、如何保存和恢復訓練模型
- 四、文本序列到 TFRecords
- 五、如何將原始圖片數據轉換為 TFRecords
- 六、如何使用 TensorFlow Eager 從 TFRecords 批量讀取數據
- 七、使用 TensorFlow Eager 構建用于情感識別的卷積神經網絡(CNN)
- 八、用于 TensorFlow Eager 序列分類的動態循壞神經網絡
- 九、用于 TensorFlow Eager 時間序列回歸的遞歸神經網絡
- TensorFlow 高效編程
- 圖嵌入綜述:問題,技術與應用
- 一、引言
- 三、圖嵌入的問題設定
- 四、圖嵌入技術
- 基于邊重構的優化問題
- 應用
- 基于深度學習的推薦系統:綜述和新視角
- 引言
- 基于深度學習的推薦:最先進的技術
- 基于卷積神經網絡的推薦
- 關于卷積神經網絡我們理解了什么
- 第1章概論
- 第2章多層網絡
- 2.1.4生成對抗網絡
- 2.2.1最近ConvNets演變中的關鍵架構
- 2.2.2走向ConvNet不變性
- 2.3時空卷積網絡
- 第3章了解ConvNets構建塊
- 3.2整改
- 3.3規范化
- 3.4匯集
- 第四章現狀
- 4.2打開問題
- 參考
- 機器學習超級復習筆記
- Python 遷移學習實用指南
- 零、前言
- 一、機器學習基礎
- 二、深度學習基礎
- 三、了解深度學習架構
- 四、遷移學習基礎
- 五、釋放遷移學習的力量
- 六、圖像識別與分類
- 七、文本文件分類
- 八、音頻事件識別與分類
- 九、DeepDream
- 十、自動圖像字幕生成器
- 十一、圖像著色
- 面向計算機視覺的深度學習
- 零、前言
- 一、入門
- 二、圖像分類
- 三、圖像檢索
- 四、對象檢測
- 五、語義分割
- 六、相似性學習
- 七、圖像字幕
- 八、生成模型
- 九、視頻分類
- 十、部署
- 深度學習快速參考
- 零、前言
- 一、深度學習的基礎
- 二、使用深度學習解決回歸問題
- 三、使用 TensorBoard 監控網絡訓練
- 四、使用深度學習解決二分類問題
- 五、使用 Keras 解決多分類問題
- 六、超參數優化
- 七、從頭開始訓練 CNN
- 八、將預訓練的 CNN 用于遷移學習
- 九、從頭開始訓練 RNN
- 十、使用詞嵌入從頭開始訓練 LSTM
- 十一、訓練 Seq2Seq 模型
- 十二、深度強化學習
- 十三、生成對抗網絡
- TensorFlow 2.0 快速入門指南
- 零、前言
- 第 1 部分:TensorFlow 2.00 Alpha 簡介
- 一、TensorFlow 2 簡介
- 二、Keras:TensorFlow 2 的高級 API
- 三、TensorFlow 2 和 ANN 技術
- 第 2 部分:TensorFlow 2.00 Alpha 中的監督和無監督學習
- 四、TensorFlow 2 和監督機器學習
- 五、TensorFlow 2 和無監督學習
- 第 3 部分:TensorFlow 2.00 Alpha 的神經網絡應用
- 六、使用 TensorFlow 2 識別圖像
- 七、TensorFlow 2 和神經風格遷移
- 八、TensorFlow 2 和循環神經網絡
- 九、TensorFlow 估計器和 TensorFlow HUB
- 十、從 tf1.12 轉換為 tf2
- TensorFlow 入門
- 零、前言
- 一、TensorFlow 基本概念
- 二、TensorFlow 數學運算
- 三、機器學習入門
- 四、神經網絡簡介
- 五、深度學習
- 六、TensorFlow GPU 編程和服務
- TensorFlow 卷積神經網絡實用指南
- 零、前言
- 一、TensorFlow 的設置和介紹
- 二、深度學習和卷積神經網絡
- 三、TensorFlow 中的圖像分類
- 四、目標檢測與分割
- 五、VGG,Inception,ResNet 和 MobileNets
- 六、自編碼器,變分自編碼器和生成對抗網絡
- 七、遷移學習
- 八、機器學習最佳實踐和故障排除
- 九、大規模訓練
- 十、參考文獻