
# 一、TensorFlow 101
TensorFlow 是解決機器學習和深度學習問題的流行庫之一。在開發供 Google 內部使用后,它作為開源發布供公眾使用和開發。讓我們理解 TensorFlow 的三個模型:**數據模型**,**編程模型**和**執行模型**。
TensorFlow 數據模型由張量組成,編程模型由數據流圖或計算圖組成。 TensorFlow 執行模型包括基于依賴條件從序列中觸發節點,從依賴于輸入的初始節點開始。
在本章中,我們將回顧構成這三個模型的 TensorFlow 元素,也稱為核心 TensorFlow。
我們將在本章中介紹以下主題:
* TensorFlow 核心
* 張量
* 常量
* 占位符
* 操作
* 從 Python 對象創建張量
* 變量
* 從庫函數生成的張量
* 數據流圖或計算圖
* 執行順序和延遲加載
* 跨計算設備執行圖 - CPU 和 GPU
* 多個圖
* TensorBoard 概述
本書的編寫注重實際,因此您可以從本書的 GitHub 倉庫中克隆代碼或從 Packt Publishing 下載它。 您可以使用代碼包中包含的 Jupyter 筆記本`ch-01_TensorFlow_101`來遵循本章中的代碼示例。
# 什么是 TensorFlow?
根據 [TensorFlow 網站](http://www.tensorflow.org):
TensorFlow 是一個使用數據流圖進行數值計算的開源庫。
最初由谷歌開發用于其內部消費,它于 2015 年 11 月 9 日開源發布。從那時起,TensorFlow 已被廣泛用于開發各種領域的機器學習和深度神經網絡模型,并繼續在谷歌內部用于研究和產品開發。 TensorFlow 1.0 于 2017 年 2 月 15 日發布。讓人懷疑這是否是 Google 向機器學習工程師贈送的情人節禮物!
TensorFlow 可以用數據模型,編程模型和執行模型來描述:
* **數據模型**由張量組成,它們在 TensorFlow 程序中創建,操作和保存的基本數據單元。
* **編程模型**由數據流圖或計算圖組成。在 TensorFlow 中創建程序意味著構建一個或多個 TensorFlow 計算圖。
* **執行**模型包括以依賴序列觸發計算圖的節點。執行從運行直接連接到輸入的節點開始,僅依賴于存在的輸入。
要在項目中使用 TensorFlow,您需要學習如何使用 TensorFlow API 進行編程。 TensorFlow 有多個 API,可用于與庫交互。 TF API 或庫分為兩個級別:
* **低級庫**:低級庫,也稱為 TensorFlow 核心,提供非常細粒度的低級功能,從而提供對如何在模型中使用和實現庫的完全控制。我們將在本章介紹 TensorFlow 核心。
* **高級庫**:這些庫提供高級功能,并且在模型中相對容易學習和實現。一些庫包括 TFEstimators,TFLearn,TFSlim,Sonnet 和 Keras。我們將在下一章介紹其中一些庫。
# TensorFlow 核心
TensorFlow 核心是較低級別的庫,其上構建了更高級別的 TensorFlow 模塊。在深入學習高級 TensorFlow 之前,學習低級庫的概念非常重要。在本節中,我們將快速回顧所有這些核心概念。
# 代碼預熱 - Hello TensorFlow
作為學習任何新編程語言,庫或平臺的習慣傳統,讓我們在深入探討之前,編寫簡單的 Hello TensorFlow 代碼作為熱身練習。
我們假設您已經安裝了 TensorFlow。 如果還沒有,請參閱 [TensorFlow 安裝指南](https://www.tensorflow.org/install/),了解安裝 TensorFlow 的詳細說明。
打開 Jupyter 筆記本中的文件`ch-01_TensorFlow_101.ipynb`,在學習文本時關注并運行代碼。
1. 使用以下代碼導入 TensorFlow 庫:
```py
import tensorflow as tf
```
1. 獲取 TensorFlow 會話。 TensorFlow 提供兩種會話:`Session()`和`InteractiveSession()`。我們將使用以下代碼創建交互式會話:
```py
tfs = tf.InteractiveSession()
```
`Session()`和`InteractiveSession()`之間的唯一區別是用`InteractiveSession()`創建的會話成為默認會話。因此,我們不需要指定會話上下文以便稍后執行與會話相關的命令。例如,假設我們有一個會話對象`tfs`和一個常量對象`hello`。如果`tfs`是一個`InteractiveSession()`對象,那么我們可以使用代碼`hello.eval()`來求值`hello`。如果`tfs`是`Session()`對象,那么我們必須使用`tfs.hello.eval()`或`with`塊。最常見的做法是使用`with`塊,這將在本章后面介紹。
1. 定義 TensorFlow 常量,`hello`:
```py
hello = tf.constant("Hello TensorFlow !!")
```
1. 在 TensorFlow 會話中執行常量并打印輸出:
```py
print(tfs.run(hello))
```
1. 您將獲得以下輸出:
```py
'Hello TensorFlow !!'
```
現在您已經使用 TensorFlow 編寫并執行了前兩行代碼,讓我們來看看 TensorFlow 的基本組成部分。
# 張量
**張量**是 TensorFlow 中計算的基本元素和基本數據結構。可能是您需要學習使用 TensorFlow 的唯一數據結構。張量是由維度,形狀和類型標識的 n 維數據集合。
**階數**是張量的維數,**形狀**是表示每個維度的大小的列表。張量可以具有任意數量的尺寸。您可能已經熟悉零維集合(標量),一維集合(向量),二維集合(矩陣)的數量,以及多維集合。
標量值是等級 0 的張量,因此具有[1]的形狀。向量或一維數組是秩 1 的張量,并且具有列或行的形狀。矩陣或二維數組是秩 2 的張量,并且具有行和列的形狀。三維數組將是秩 3 的張量,并且以相同的方式,n 維數組將是秩`n`的張量。
請參閱以下資源以了解有關張量及其數學基礎的更多信息:
* [維基百科上的張量頁面](https://en.wikipedia.org/wiki/Tensor)
* [來自美國國家航空航天局的張量導言](https://www.grc.nasa.gov/www/k-12/Numbers/Math/documents/Tensors_TM2002211716.pdf)
張量可以在其所有維度中存儲一種類型的數據,并且其元素的數據類型被稱為張量的數據類型。
您還可以在[這里](https://www.tensorflow.org/api_docs/python/tf/DType)查看最新版本的 TensorFlow 庫中定義的數據類型。
在編寫本書時,TensorFlow 定義了以下數據類型:
| **TensorFlow Python API 數據類型** | **描述** |
| --- | --- |
| `tf.float16` | 16 位半精度浮點 |
| `tf.float32` | 32 位單精度浮點 |
| `tf.float64` | 64 位雙精度浮點 |
| `tf.bfloat16` | 16 位截斷浮點 |
| `tf.complex64` | 64 位單精度復數 |
| `tf.complex128` | 128 位雙精度復數 |
| `tf.int8` | 8 位有符號整數 |
| `tf.uint8` | 8 位無符號整數 |
| `tf.uint16` | 16 位無符號整數 |
| `tf.int16` | 16 位有符號整數 |
| `tf.int32` | 32 位有符號整數 |
| `tf.int64` | 64 位有符號整數 |
| `tf.bool` | 布爾 |
| `tf.string` | 字符串 |
| `tf.qint8` | 量化的 8 位有符號整數 |
| `tf.quint8` | 量化的 8 位無符號整數 |
| `tf.qint16` | 量化的 16 位有符號整數 |
| `tf.quint16` | 量化的 16 位無符號整數 |
| `tf.qint32` | 量化的 32 位有符號整數 |
| `tf.resource` | 可變資源 |
我們建議您避免使用 Python 本地數據類型。 使用 TensorFlow 數據類型來定義張量,而不是 Python 本地數據類型。
可以通過以下方式創建張量:
* 通過定義常量,操作和變量,并將值傳遞給它們的構造器。
* 通過定義占位符并將值傳遞給`session.run()`。
* 通過`tf.convert_to_tensor()`函數轉換 Python 對象,如標量值,列表和 NumPy 數組。
讓我們來看看創建張量的不同方法。
# 常量
使用具有以下簽名的`tf.constant()`函數創建常量值張量:
```py
tf.constant(
value,
dtype=None,
shape=None,
name='Const',
verify_shape=False
)
```
讓我們看看本書中 Jupyter 筆記本中提供的示例代碼:
```py
c1=tf.constant(5,name='x')
c2=tf.constant(6.0,name='y')
c3=tf.constant(7.0,tf.float32,name='z')
```
讓我們詳細研究一下代碼:
* 第一行定義一個常數張量`c1`,給它值 5,并將其命名為`x`。
* 第二行定義一個常數張量`c2`,存儲值為 6.0,并將其命名為`y`。
* 當我們打印這些張量時,我們看到`c1`和`c2`的數據類型由 TensorFlow 自動推導出來。
* 要專門定義數據類型,我們可以使用`dtype`參數或將數據類型作為第二個參數。在前面的代碼示例中,我們將`tf.float32`的數據類型定義為`tf.float32`。
讓我們打印常量`c1`,`c2`和`c3`:
```py
print('c1 (x): ',c1)
print('c2 (y): ',c2)
print('c3 (z): ',c3)
```
當我們打印這些常量時,我??們得到以下輸出:
```py
c1 (x): Tensor("x:0", shape=(), dtype=int32)
c2 (y): Tensor("y:0", shape=(), dtype=float32)
c3 (z): Tensor("z:0", shape=(), dtype=float32)
```
為了打印這些常量的值,我們必須使用`tfs.run()`命令在 TensorFlow 會話中執行它們:
```py
print('run([c1,c2,c3]) : ',tfs.run([c1,c2,c3]))
```
我們看到以下輸出:
```py
run([c1,c2,c3]) : [5, 6.0, 7.0]
```
# 操作
TensorFlow 為我們提供了許多可以應用于張量的操作。通過傳遞值并將輸出分配給另一個張量來定義操作。例如,在提供的 Jupyter 筆記本文件中,我們定義了兩個操作,`op1`和`op2`:
```py
op1 = tf.add(c2,c3)
op2 = tf.multiply(c2,c3)
```
當我們打印`op1`和`op2`時,我們發現它們被定義為張量:
```py
print('op1 : ', op1)
print('op2 : ', op2)
```
輸出如下:
```py
op1 : Tensor("Add:0", shape=(), dtype=float32)
op2 : Tensor("Mul:0", shape=(), dtype=float32)
```
要打印這些操作的值,我們必須在 TensorFlow 會話中運行它們:
```py
print('run(op1) : ', tfs.run(op1))
print('run(op2) : ', tfs.run(op2))
```
輸出如下:
```py
run(op1) : 13.0
run(op2) : 42.0
```
下表列出了一些內置操作:
| **操作類型** | **操作** |
| --- | --- |
| 算術運算 | `tf.add`,`tf.subtract`,`tf.multiply`,`tf.scalar_mul`,`tf.div`,`tf.divide`,`tf.truediv`,`tf.floordiv`,`tf.realdiv`,`tf.truncatediv`,`tf.floor_div`,`tf.truncatemod`,`tf.floormod`,`tf.mod`,`tf.cross` |
| 基本的數學運算 | `tf.add_n`,`tf.abs`,`tf.negative`,`tf.sign`,`tf.reciprocal`,`tf.square`,`tf.round`,`tf.sqrt`,`tf.rsqrt`,`tf.pow`,`tf.exp`,`tf.expm1`,`tf.log`,`tf.log1p`,`tf.ceil`,`tf.floor`,`tf.maximum`,`tf.minimum`,`tf.cos`,`tf.sin`,`tf.lbeta`,`tf.tan`,`tf.acos`,`tf.asin`,`tf.atan`,`tf.lgamma`,`tf.digamma`,`tf.erf`,`tf.erfc`,`tf.igamma`,`tf.squared_difference`,`tf.igammac`,`tf.zeta`,`tf.polygamma`,`tf.betainc`,`tf.rint` |
| 矩陣數學運算 | `tf.diag`,`tf.diag_part`,`tf.trace`,`tf.transpose`,`tf.eye`,`tf.matrix_diag`,`tf.matrix_diag_part`,`tf.matrix_band_part`,`tf.matrix_set_diag`,`tf.matrix_transpose`,`tf.matmul`,`tf.norm`,`tf.matrix_determinant` ],`tf.matrix_inverse`,`tf.cholesky`,`tf.cholesky_solve`,`tf.matrix_solve`,`tf.matrix_triangular_solve`,`tf.matrix_solve_ls`,`tf.qr, tf.self_adjoint_eig`,`tf.self_adjoint_eigvals`,`tf.svd` |
| 張量數學運算 | `tf.tensordot` |
| 復數運算 | `tf.complex`,`tf.conj`,`tf.imag`,`tf.real` |
| 字符串操作 | `tf.string_to_hash_bucket_fast`,`tf.string_to_hash_bucket_strong`,`tf.as_string`,`tf.encode_base64`,`tf.decode_base64`,`tf.reduce_join`,`tf.string_join`,`tf.string_split`,`tf.substr`,`tf.string_to_hash_bucket` |
# 占位符
雖然常量允許我們在定義張量時提供值,但占位符允許我們創建可在運行時提供其值的張量。 TensorFlow 為`tf.placeholder()`函數提供以下簽名以創建占位符:
```py
tf.placeholder(
dtype,
shape=None,
name=None
)
```
例如,讓我們創建兩個占位符并打印它們:
```py
p1 = tf.placeholder(tf.float32)
p2 = tf.placeholder(tf.float32)
print('p1 : ', p1)
print('p2 : ', p2)
```
我們看到以下輸出:
```py
p1 : Tensor("Placeholder:0", dtype=float32)
p2 : Tensor("Placeholder_1:0", dtype=float32)
```
現在讓我們使用這些占位符定義一個操作:
```py
op4 = p1 * p2
```
TensorFlow 允許使用速記符號進行各種操作。在前面的例子中,`p1 * p2`是`tf.multiply(p1,p2)`的簡寫:
```py
print('run(op4,{p1:2.0, p2:3.0}) : ',tfs.run(op4,{p1:2.0, p2:3.0}))
```
上面的命令在 TensorFlow 會話中運行`op4`,為`p1`和`p2`的值提供 Python 字典(`run()`操作的第二個參數)。
輸出如下:
```py
run(op4,{p1:2.0, p2:3.0}) : 6.0
```
我們還可以使用`run()`操作中的`feed_dict`參數指定字典:
```py
print('run(op4,feed_dict = {p1:3.0, p2:4.0}) : ',
tfs.run(op4, feed_dict={p1: 3.0, p2: 4.0}))
```
輸出如下:
```py
run(op4,feed_dict = {p1:3.0, p2:4.0}) : 12.0
```
讓我們看一下最后一個例子,向量被送到同一個操作:
```py
print('run(op4,feed_dict = {p1:[2.0,3.0,4.0], p2:[3.0,4.0,5.0]}) : ',
tfs.run(op4,feed_dict = {p1:[2.0,3.0,4.0], p2:[3.0,4.0,5.0]}))
```
輸出如下:
```py
run(op4,feed_dict={p1:[2.0,3.0,4.0],p2:[3.0,4.0,5.0]}):[ 6\. 12\. 20.]
```
兩個輸入向量的元素以元素方式相乘。
# 從 Python 對象創建張量
我們可以使用帶有以下簽名的`tf.convert_to_tensor()`操作從 Python 對象(如列表和 NumPy 數組)創建張量:
```py
tf.convert_to_tensor(
value,
dtype=None,
name=None,
preferred_dtype=None
)
```
讓我們創建一些張量并打印出來進行練習:
1. 創建并打印 0D 張量:
```py
tf_t=tf.convert_to_tensor(5.0,dtype=tf.float64)
print('tf_t : ',tf_t)
print('run(tf_t) : ',tfs.run(tf_t))
```
輸出如下:
```py
tf_t : Tensor("Const_1:0", shape=(), dtype=float64)
run(tf_t) : 5.0
```
1. 創建并打印 1D 張量:
```py
a1dim = np.array([1,2,3,4,5.99])
print("a1dim Shape : ",a1dim.shape)
tf_t=tf.convert_to_tensor(a1dim,dtype=tf.float64)
print('tf_t : ',tf_t)
print('tf_t[0] : ',tf_t[0])
print('tf_t[0] : ',tf_t[2])
print('run(tf_t) : \n',tfs.run(tf_t))
```
輸出如下:
```py
a1dim Shape : (5,)
tf_t : Tensor("Const_2:0", shape=(5,), dtype=float64)
tf_t[0] : Tensor("strided_slice:0", shape=(), dtype=float64)
tf_t[0] : Tensor("strided_slice_1:0", shape=(), dtype=float64)
run(tf_t) :
[ 1\. 2\. 3\. 4\. 5.99]
```
1. 創建并打印 2D 張量:
```py
a2dim = np.array([(1,2,3,4,5.99),
(2,3,4,5,6.99),
(3,4,5,6,7.99)
])
print("a2dim Shape : ",a2dim.shape)
tf_t=tf.convert_to_tensor(a2dim,dtype=tf.float64)
print('tf_t : ',tf_t)
print('tf_t[0][0] : ',tf_t[0][0])
print('tf_t[1][2] : ',tf_t[1][2])
print('run(tf_t) : \n',tfs.run(tf_t))
```
輸出如下:
```py
a2dim Shape : (3, 5)
tf_t : Tensor("Const_3:0", shape=(3, 5), dtype=float64)
tf_t[0][0] : Tensor("strided_slice_3:0", shape=(), dtype=float64)
tf_t[1][2] : Tensor("strided_slice_5:0", shape=(), dtype=float64)
run(tf_t) :
[[ 1\. 2\. 3\. 4\. 5.99]
[ 2\. 3\. 4\. 5\. 6.99]
[ 3\. 4\. 5\. 6\. 7.99]]
```
1. 創建并打印 3D 張量:
```py
a3dim = np.array([[[1,2],[3,4]],
[[5,6],[7,8]]
])
print("a3dim Shape : ",a3dim.shape)
tf_t=tf.convert_to_tensor(a3dim,dtype=tf.float64)
print('tf_t : ',tf_t)
print('tf_t[0][0][0] : ',tf_t[0][0][0])
print('tf_t[1][1][1] : ',tf_t[1][1][1])
print('run(tf_t) : \n',tfs.run(tf_t))
```
輸出如下:
```py
a3dim Shape : (2, 2, 2)
tf_t : Tensor("Const_4:0", shape=(2, 2, 2), dtype=float64)
tf_t[0][0][0] : Tensor("strided_slice_8:0", shape=(), dtype=float64)
tf_t[1][1][1] : Tensor("strided_slice_11:0", shape=(), dtype=float64)
run(tf_t) :
[[[ 1\. 2.][ 3\. 4.]]
[[ 5\. 6.][ 7\. 8.]]]
```
TensorFlow 可以將 NumPy `ndarray`無縫轉換為 TensorFlow 張量,反之亦然。
# 變量
到目前為止,我們已經看到了如何創建各種張量對象:常量,操作和占位符。在使用 TensorFlow 構建和訓練模型時,通常需要將參數值保存在可在運行時更新的內存位置。該內存位置由 TensorFlow 中的變量標識。
在 TensorFlow 中,變量是張量對象,它們包含可在程序執行期間修改的值。
雖然`tf.Variable`看起來與`tf.placeholder`類似,但兩者之間存在細微差別:
| **`tf.placeholder`** | **`tf.Variable`** |
| --- | --- |
| `tf.placeholder`定義了不隨時間變化的輸入數據 | `tf.Variable`定義隨時間修改的變量值 |
| `tf.placeholder`在定義時不需要初始值 | `tf.Variable`在定義時需要初始值 |
在 TensorFlow 中,可以使用`tf.Variable()`創建變量。讓我們看一個帶有線性模型的占位符和變量的示例:
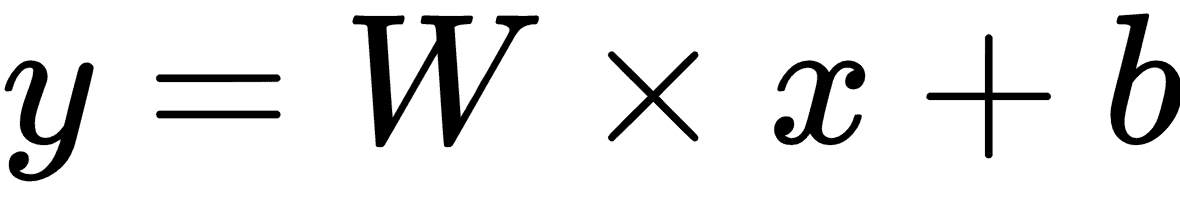
1. 我們將模型參數`w`和`b`分別定義為具有`[.3]`和`[-0.3]`初始值的變量:
```py
w = tf.Variable([.3], tf.float32)
b = tf.Variable([-.3], tf.float32)
```
1. 輸入`x`定義為占位符,輸出`y`定義為操作:
```py
x = tf.placeholder(tf.float32)
y = w * x + b
```
1. 讓我們打印`w`,`v`,`x`和`y`,看看我們得到了什么:
```py
print("w:",w)
print("x:",x)
print("b:",b)
print("y:",y)
```
我們得到以下輸出:
```py
w: <tf.Variable 'Variable:0' shape=(1,) dtype=float32_ref>
x: Tensor("Placeholder_2:0", dtype=float32)
b: <tf.Variable 'Variable_1:0' shape=(1,) dtype=float32_ref>
y: Tensor("add:0", dtype=float32)
```
輸出顯示`x`是占位符張量,`y`是操作張量,而`w`和`b`是形狀`(1,)`和數據類型`float32`的變量。
在 TensorFlow 會話中使用變量之前,必須先初始化它們。您可以通過運行其初始化程序操作來初始化單個變量。
例如,讓我們初始化變量`w`:
```py
tfs.run(w.initializer)
```
但是,在實踐中,我們使用 TensorFlow 提供的便利函數來初始化所有變量:
```py
tfs.run(tf.global_variables_initializer())
```
您還可以使用`tf.variables_initializer()`函數來初始化一組變量。
也可以通過以下方式調用全局初始化程序便利函數,而不是在會話對象的`run()`函數內調用:
```py
tf.global_variables_initializer().run()
```
在初始化變量之后,讓我們運行我們的模型來給出`x = [1,2,3,4]`的值的輸出:
```py
print('run(y,{x:[1,2,3,4]}) : ',tfs.run(y,{x:[1,2,3,4]}))
```
我們得到以下輸出:
```py
run(y,{x:[1,2,3,4]}) : [ 0\. 0.30000001 0.60000002 0.90000004]
```
# 從庫函數生成的張量
張量也可以從各種 TensorFlow 函數生成。這些生成的張量可以分配給常量或變量,也可以在初始化時提供給它們的構造器。
例如,以下代碼生成 100 個零的向量并將其打印出來:
```py
a=tf.zeros((100,))
print(tfs.run(a))
```
TensorFlow 提供了不同類型的函數來在定義時填充張量:
* 使用相同的值填充所有元素
* 用序列填充元素
* 使用隨機概率分布填充元素,例如正態分布或均勻分布
# 使用相同的值填充張量元素
下表列出了一些張量生成庫函數,用于使用相同的值填充張量的所有元素:
```py
zeros(
shape,
dtype=tf.float32,
name=None
)
```
創建所提供形狀的張量,所有元素都設置為零
---
```py
zeros_like(
tensor,
dtype=None,
name=None,
optimize=True
)
```
創建與參數形狀相同的張量,所有元素都設置為零
---
```py
ones(
shape,
dtype=tf.float32,
name=None
)
```
創建所提供形狀的張量,所有元素都設置為 1
---
```py
ones_like(
tensor,
dtype=None,
name=None,
optimize=True
)
```
創建與參數形狀相同的張量,所有元素都設置為 1
---
```py
fill(
dims,
value,
name=None
)
```
創建一個形狀的張量作為`dims`參數,,所有元素都設置為`value`;例如,`a = tf.fill([100],0)`
# 用序列填充張量元素
下表列出了一些張量生成函數,用于使用序列填充張量元素:
```py
lin_space(
start,
stop,
num,
name=None
)
```
從`[start, stop]`范圍內的`num`序列生成 1D 張量。張量與`start`參數具有相同的數據類型。例如,`a = tf.lin_space(1,100,10)`生成值為`[1,12,23,34,45,56,67,78,89,100]`的張量。
---
```py
range(
limit,
delta=1,
dtype=None,
name='range'
)
range(
start,
limit,
delta=1,
dtype=None,
name='range'
)
```
從`[start, limit]`范圍內的數字序列生成 1D 張量,增量為`delta`。如果未指定`dtype`參數,則張量具有與`start`參數相同的數據類型。 此函數有兩個版本。在第二個版本中,如果省略`start`參數,則`start`變為數字 0。例如,`a = tf.range(1,91,10)`生成具有值`[1,11,21,31,41,51,61,71,81]`的張量。請注意,`limit`參數的值(即 91)不包含在最終生成的序列中。
# 使用隨機分布填充張量元素
TensorFlow 為我們提供了生成填充隨機值分布的張量的函數。
生成的分布受圖級別或操作級別種子的影響。使用`tf.set_random_seed`設置圖級種子,而在所有隨機分布函數中給出操作級種子作為參數`seed`。如果未指定種子,則使用隨機種子。
有關 TensorFlow 中隨機種子的更多詳細信息,請訪問[此鏈接](https://www.tensorflow.org/api_docs/python/tf/set_random_seed)。
下表列出了一些張量生成函數,用于使用隨機值分布填充張量元素:
```py
random_normal(
shape,
mean=0.0,
stddev=1.0,
dtype=tf.float32,
seed=None,
name=None
)
```
生成指定形狀的張量,填充正態分布的值:`normal(mean,?stddev)`。
---
```py
truncated_normal(
shape,
mean=0.0,
stddev=1.0,
dtype=tf.float32,
seed=None,
name=None
)
```
生成指定形狀的張量,填充來自截斷的正態分布的值:`normal(mean,?stddev)`。截斷意味著返回的值始終與平均值的距離小于兩個標準偏差。
---
```py
random_uniform(
shape,
minval=0,
maxval=None,
dtype=tf.float32,
seed=None,
name=None
)
```
生成指定形狀的張量,填充均勻分布的值:`uniform([minval,?maxval))`。
---
```py
random_gamma(
shape,
alpha,
beta=None,
dtype=tf.float32,
seed=None,
name=None
)
```
生成指定形狀的張量,填充來自伽馬分布的值:`gamma(alpha,beta)`。有關`random_gamma`函數的更多詳細信息,請訪問[此鏈接](https://www.tensorflow.org/api_docs/python/tf/random_gamma)。
# 使用`tf.get_variable()`獲取變量
如果使用之前定義的名稱定義變量,則 TensorFlow 會拋出異常。因此,使用`tf.get_variable()`函數代替`tf.Variable()`很方便。函數`tf.get_variable()`返回具有相同名稱的現有變量(如果存在),并創建具有指定形狀的變量和初始化器(如果它不存在)。例如:
```py
w = tf.get_variable(name='w',shape=[1],dtype=tf.float32,initializer=[.3])
b = tf.get_variable(name='b',shape=[1],dtype=tf.float32,initializer=[-.3])
```
初始化程序可以是上面示例中顯示的張量或值列表,也可以是內置初始化程序之一:
* `tf.constant_initializer`
* `tf.random_normal_initializer`
* `tf.truncated_normal_initializer`
* `tf.random_uniform_initializer`
* `tf.uniform_unit_scaling_initializer`
* `tf.zeros_initializer`
* `tf.ones_initializer`
* `tf.orthogonal_initializer`
在分布式 TensorFlow 中,我們可以跨機器運行代碼,`tf.get_variable()`為我們提供了全局變量。要獲取局部變量,TensorFlow 具有類似簽名的函數:`tf.get_local_variable()`。
**共享或重用變量**:獲取已定義的變量可促進重用。但是,如果未使用`tf.variable_scope.reuse_variable()`或`tf.variable.scope(reuse=True)`設置重用標志,則會拋出異常。
現在您已經學會了如何定義張量,常量,運算,占位符和變量,讓我們了解 TensorFlow 中的下一級抽象,它將這些基本元素組合在一起形成一個基本的計算單元,即數據流圖或計算圖。
# 數據流圖或計算圖
**數據流圖**或**計算圖**是 TensorFlow 中的基本計算單元。從現在開始,我們將它們稱為**計算圖**。計算圖由節點和邊組成。每個節點代表一個操作(`tf.Operation`),每個邊代表一個在節點之間傳遞的張量(`tf.Tensor`)。
TensorFlow 中的程序基本上是計算圖。您可以使用表示變量,常量,占位符和操作的節點創建圖,并將其提供給 TensorFlow。 TensorFlow 找到它可以觸發或執行的第一個節點。觸發這些節點會導致其他節點觸發,依此類推。
因此,TensorFlow 程序由計算圖上的兩種操作組成:
* 構建計算圖
* 運行計算圖
TensorFlow 附帶一個默認圖。除非明確指定了另一個圖,否則會將新節點隱式添加到默認圖中。我們可以使用以下命令顯式訪問默認圖:
```py
graph = tf.get_default_graph()
```
例如,如果我們想要定義三個輸入并添加它們以產生輸出`y = x1 + x2 + x3`,我們可以使用以下計算圖來表示它:
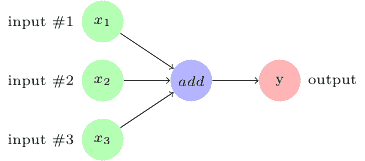
在 TensorFlow 中,前一圖像中的添加操作將對應于代碼`y = tf.add( x1 + x2 + x3 )`。
在我們創建變量,常量和占位符時,它們會添加到圖中。然后我們創建一個會話對象,以執行操作對象,求值張量對象。
讓我們構建并執行一個計算圖來計算`y = w × x + b`,正如我們在前面的例子中已經看到的那樣:
```py
# Assume Linear Model y = w * x + b
# Define model parameters
w = tf.Variable([.3], tf.float32)
b = tf.Variable([-.3], tf.float32)
# Define model input and output
x = tf.placeholder(tf.float32)
y = w * x + b
output = 0
with tf.Session() as tfs:
# initialize and print the variable y
tf.global_variables_initializer().run()
output = tfs.run(y,{x:[1,2,3,4]})
print('output : ',output)
```
在`with`塊中創建和使用會話可確保在塊完成時會話自動關閉。否則,必須使用`tfs.close()`命令顯式關閉會話,其中`tfs`是會話名稱。
# 執行順序和延遲加載
節點按依賴順序執行。如果節點`a`依賴于節點`b`,則`a`將在執行`b`之前執行請求`b`。除非未請求執行節點本身或取決于它的其他節點,否則不執行節點。這也稱為延遲加載;即,在需要之前不創建和初始化節點對象。
有時,您可能希望控制在圖中執行節點的順序。這可以通過`tf.Graph.control_dependencies()`函數實現。 例如,如果圖具有節點`a, b, c`和`d`并且您想在`a`和`b`之前執行`c`和`d`,請使用以下語句:
```py
with graph_variable.control_dependencies([c,d]):
# other statements here
```
這確保了在執行了節點`c`和`d`之后,才執行前面`with`塊中的任何節點。
# 跨計算設備執行圖 - CPU 和 GPU
圖可以分為多個部分,每個部分可以放置在不同的設備上執行,例如 CPU 或 GPU。您可以使用以下命令列出可用于執行圖的所有設備:
```py
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
```
我們得到以下輸出(您的輸出會有所不同,具體取決于系統中的計算設備):
```py
[name: "/device:CPU:0"
device_type: "CPU"
memory_limit: 268435456
locality {
}
incarnation: 12900903776306102093
, name: "/device:GPU:0"
device_type: "GPU"
memory_limit: 611319808
locality {
bus_id: 1
}
incarnation: 2202031001192109390
physical_device_desc: "device: 0, name: Quadro P5000, pci bus id: 0000:01:00.0, compute capability: 6.1"
]
```
TensorFlow 中的設備用字符串`/device:<device_type>:<device_idx>`標識。在上述輸出中,`CPU`和`GPU`表示器件類型,`0`表示器件索引。
關于上述輸出需要注意的一點是它只顯示一個 CPU,而我們的計算機有 8 個 CPU。原因是 TensorFlow 隱式地在 CPU 單元中分配代碼,因此默認情況下`CPU:0`表示 TensorFlow 可用的所有 CPU。當 TensorFlow 開始執行圖時,它在一個單獨的線程中運行每個圖中的獨立路徑,每個線程在一個單獨的 CPU 上運行。我們可以通過改變`inter_op_parallelism_threads`的數量來限制用于此目的的線程數。類似地,如果在獨立路徑中,操作能夠在多個線程上運行,TensorFlow 將在多個線程上啟動該特定操作。可以通過設置`intra_op_parallelism_threads`的數量來更改此池中的線程數。
# 將圖節點放置在特定的計算設備上
讓我們通過定義配置對象來啟用變量放置的記錄,將`log_device_placement`屬性設置為`true`,然后將此`config`對象傳遞給會話,如下所示:
```py
tf.reset_default_graph()
# Define model parameters
w = tf.Variable([.3], tf.float32)
b = tf.Variable([-.3], tf.float32)
# Define model input and output
x = tf.placeholder(tf.float32)
y = w * x + b
config = tf.ConfigProto()
config.log_device_placement=True
with tf.Session(config=config) as tfs:
# initialize and print the variable y
tfs.run(global_variables_initializer())
print('output',tfs.run(y,{x:[1,2,3,4]}))
```
我們在 Jupyter 筆記本控制臺中獲得以下輸出:
```py
b: (VariableV2): /job:localhost/replica:0/task:0/device:GPU:0
b/read: (Identity): /job:localhost/replica:0/task:0/device:GPU:0
b/Assign: (Assign): /job:localhost/replica:0/task:0/device:GPU:0
w: (VariableV2): /job:localhost/replica:0/task:0/device:GPU:0
w/read: (Identity): /job:localhost/replica:0/task:0/device:GPU:0
mul: (Mul): /job:localhost/replica:0/task:0/device:GPU:0
add: (Add): /job:localhost/replica:0/task:0/device:GPU:0
w/Assign: (Assign): /job:localhost/replica:0/task:0/device:GPU:0
init: (NoOp): /job:localhost/replica:0/task:0/device:GPU:0
x: (Placeholder): /job:localhost/replica:0/task:0/device:GPU:0
b/initial_value: (Const): /job:localhost/replica:0/task:0/device:GPU:0
Const_1: (Const): /job:localhost/replica:0/task:0/device:GPU:0
w/initial_value: (Const): /job:localhost/replica:0/task:0/device:GPU:0
Const: (Const): /job:localhost/replica:0/task:0/device:GPU:0
```
因此,默認情況下,TensorFlow 會在設備上創建變量和操作節點,從而獲得最高表現。 可以使用`tf.device()`函數將變量和操作放在特定設備上。讓我們把圖放在 CPU 上:
```py
tf.reset_default_graph()
with tf.device('/device:CPU:0'):
# Define model parameters
w = tf.get_variable(name='w',initializer=[.3], dtype=tf.float32)
b = tf.get_variable(name='b',initializer=[-.3], dtype=tf.float32)
# Define model input and output
x = tf.placeholder(name='x',dtype=tf.float32)
y = w * x + b
config = tf.ConfigProto()
config.log_device_placement=True
with tf.Session(config=config) as tfs:
# initialize and print the variable y
tfs.run(tf.global_variables_initializer())
print('output',tfs.run(y,{x:[1,2,3,4]}))
```
在 Jupyter 控制臺中,我們看到現在變量已經放在 CPU 上,并且執行也發生在 CPU 上:
```py
b: (VariableV2): /job:localhost/replica:0/task:0/device:CPU:0
b/read: (Identity): /job:localhost/replica:0/task:0/device:CPU:0
b/Assign: (Assign): /job:localhost/replica:0/task:0/device:CPU:0
w: (VariableV2): /job:localhost/replica:0/task:0/device:CPU:0
w/read: (Identity): /job:localhost/replica:0/task:0/device:CPU:0
mul: (Mul): /job:localhost/replica:0/task:0/device:CPU:0
add: (Add): /job:localhost/replica:0/task:0/device:CPU:0
w/Assign: (Assign): /job:localhost/replica:0/task:0/device:CPU:0
init: (NoOp): /job:localhost/replica:0/task:0/device:CPU:0
x: (Placeholder): /job:localhost/replica:0/task:0/device:CPU:0
b/initial_value: (Const): /job:localhost/replica:0/task:0/device:CPU:0
Const_1: (Const): /job:localhost/replica:0/task:0/device:CPU:0
w/initial_value: (Const): /job:localhost/replica:0/task:0/device:CPU:0
Const: (Const): /job:localhost/replica:0/task:0/device:CPU:0
```
# 簡單放置
TensorFlow 遵循這些簡單的規則,也稱為簡單放置,用于將變量放在設備上:
```py
If the graph was previously run,
then the node is left on the device where it was placed earlier
Else If the tf.device() block is used,
then the node is placed on the specified device
Else If the GPU is present
then the node is placed on the first available GPU
Else If the GPU is not present
then the node is placed on the CPU
```
# 動態展示放置
`tf.device()`也可以傳遞函數名而不是設備字符串。在這種情況下,該函數必須返回設備字符串。此函數允許使用復雜的算法將變量放在不同的設備上。例如,TensorFlow 在`tf.train.replica_device_setter()`中提供循環設備設置器,我們將在下一節中討論。
# 軟放置
當您在 GPU 上放置 TensorFlow 操作時,TF 必須具有該操作的 GPU 實現,稱為內核。如果內核不存在,則放置會導致運行時錯誤。此外,如果您請求的 GPU 設備不存在,您將收到運行時錯誤。處理此類錯誤的最佳方法是,如果請求 GPU 設備導致錯誤,則允許將操作置于 CPU 上。這可以通過設置以下`config`值來實現:
```py
config.allow_soft_placement = True
```
# GPU 內存處理
當您開始運行 TensorFlow 會話時,默認情況下它會抓取所有 GPU 內存,即使您將操作和變量僅放置在多 GPU 系統中的一個 GPU 上也是如此。如果您嘗試同時運行另一個會話,則會出現內存不足錯誤。這可以通過多種方式解決:
* 對于多 GPU 系統,請設置環境變量`CUDA_VISIBLE_DEVICES=<list of device idx>`
```py
os.environ['CUDA_VISIBLE_DEVICES']='0'
```
在此設置之后執行的代碼將能夠獲取僅可見 GPU 的所有內存。
* 當您不希望會話占用 GPU 的所有內存時,您可以使用配置選項`per_process_gpu_memory_fraction`來分配一定百分比的內存:
```py
config.gpu_options.per_process_gpu_memory_fraction = 0.5
```
這將分配所有 GPU 設備的 50% 的內存。
* 您還可以結合上述兩種策略,即只制作一個百分比,同時只讓部分 GPU 對流程可見。
* 您還可以將 TensorFlow 進程限制為僅在進程開始時獲取所需的最小內存。隨著進程的進一步執行,您可以設置配置選項以允許此內存的增長。
```py
config.gpu_options.allow_growth = True
```
此選項僅允許分配的內存增長,但內存永遠不會釋放。
您將學習在后面的章節中跨多個計算設備和多個節點分配計算的技術。
# 多個圖
您可以創建與默認圖分開的圖,并在會話中執行它們。但是,不建議創建和執行多個圖,因為它具有以下缺點:
* 在同一程序中創建和使用多個圖將需要多個 TensorFlow 會話,并且每個會話將消耗大量資源
* 您無法直接在圖之間傳遞數據
因此,推薦的方法是在單個圖中包含多個子圖。如果您希望使用自己的圖而不是默認圖,可以使用`tf.graph()`命令執行此操作。下面是我們創建自己的圖`g`并將其作為默認圖執行的示例:
```py
g = tf.Graph()
output = 0
# Assume Linear Model y = w * x + b
with g.as_default():
# Define model parameters
w = tf.Variable([.3], tf.float32)
b = tf.Variable([-.3], tf.float32)
# Define model input and output
x = tf.placeholder(tf.float32)
y = w * x + b
with tf.Session(graph=g) as tfs:
# initialize and print the variable y
tf.global_variables_initializer().run()
output = tfs.run(y,{x:[1,2,3,4]})
print('output : ',output)
```
# TensorBoard
即使對于中等大小的問題,計算圖的復雜性也很高。代表復雜機器學習模型的大型計算圖可能變得非常混亂且難以理解。可視化有助于輕松理解和解釋計算圖,從而加速 TensorFlow 程序的調試和優化。 TensorFlow 附帶了一個內置工具,可以讓我們可視化計算圖,即 TensorBoard。
TensorBoard 可視化計算圖結構,提供統計分析并繪制在計算圖執行期間作為摘要捕獲的值。讓我們看看它在實踐中是如何運作的。
# TensorBoard 最小示例
1. 通過定義線性模型的變量和占位符來實現:
```py
# Assume Linear Model y = w * x + b
# Define model parameters
w = tf.Variable([.3], name='w',dtype=tf.float32)
b = tf.Variable([-.3], name='b', dtype=tf.float32)
# Define model input and output
x = tf.placeholder(name='x',dtype=tf.float32)
y = w * x + b
```
1. 初始化會話,并在此會話的上下文中,執行以下步驟:
* 初始化全局變量
* 創建`tf.summary.FileWriter`將使用默認圖中的事件在`tflogs`文件夾中創建輸出
* 獲取節點`y`的值,有效地執行我們的線性模型
```py
with tf.Session() as tfs:
tfs.run(tf.global_variables_initializer())
writer=tf.summary.FileWriter('tflogs',tfs.graph)
print('run(y,{x:3}) : ', tfs.run(y,feed_dict={x:3}))
```
1. 我們看到以下輸出:
```py
run(y,{x:3}) : [ 0.60000002]
```
當程序執行時,日志將收集在`tflogs`文件夾中,TensorBoard 將使用該文件夾進行可視化。打開命令行界面,導航到運行`ch-01_TensorFlow_101`筆記本的文件夾,然后執行以下命令:
```py
tensorboard --logdir='tflogs'
```
您會看到類似于此的輸出:
```py
Starting TensorBoard b'47' at http://0.0.0.0:6006
```
打開瀏覽器并導航到`http://0.0.0.0:6006`。看到 TensorBoard 儀表板后,不要擔心顯示任何錯誤或警告,只需單擊頂部的 GRAPHS 選項卡即可。您將看到以下屏幕:
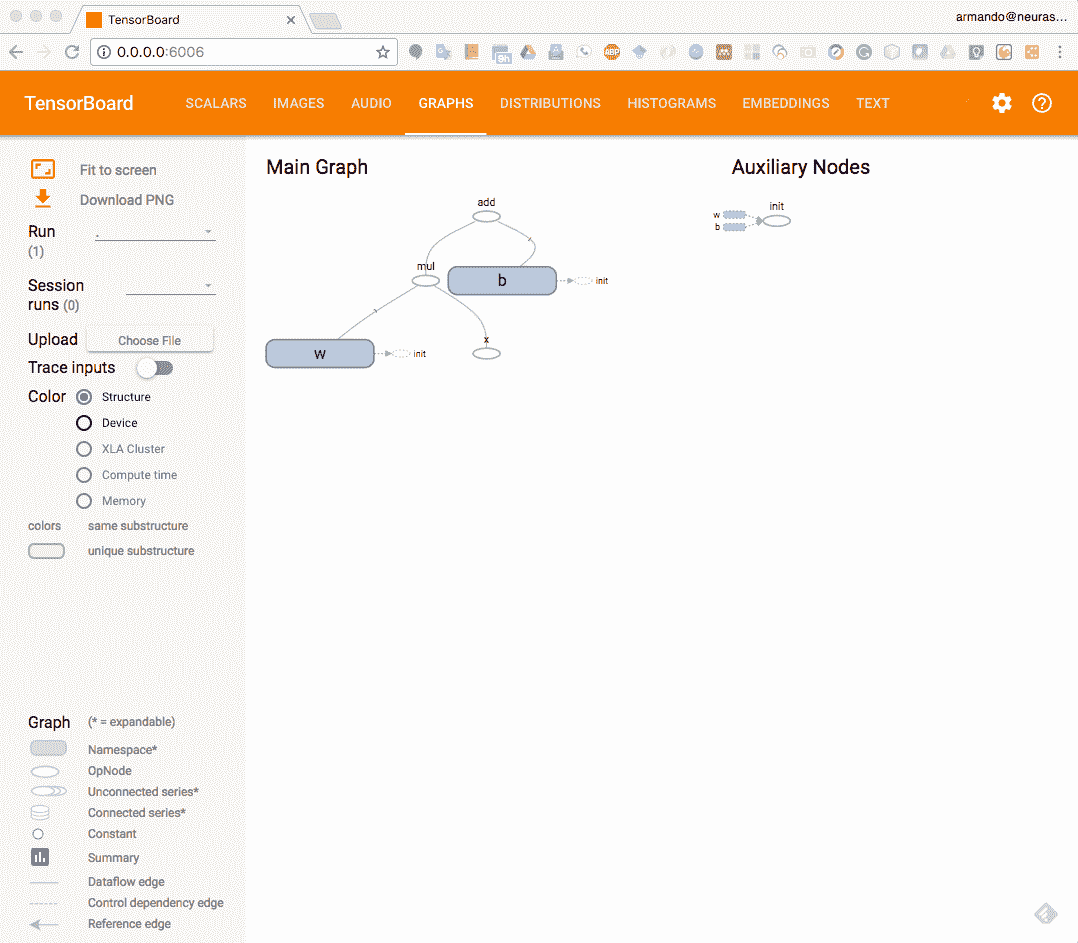TensorBoard console
您可以看到 TensorBoard 將我們的第一個簡單模型可視化為計算圖:
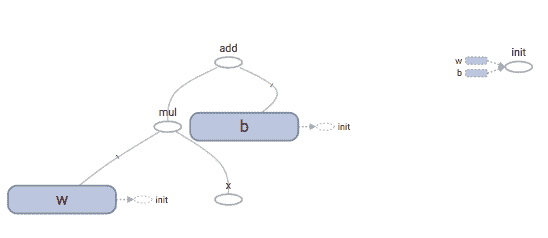Computation graph in TensorBoard
現在讓我們試著了解 TensorBoard 的詳細工作原理。
# TensorBoard 詳情
TensorBoard 通過讀取 TensorFlow 生成的日志文件來工作。因此,我們需要修改此處定義的編程模型,以包含其他操作節點,這些操作節點將在我們想要使用 TensorBoard 可視化的日志中生成信息。編程模型或使用 TensorBoard 的程序流程通常可以說如下:
1. 像往常一樣創建計算圖。
2. 創建摘要節點。將`tf.summary`包中的摘要操作附加到輸出您要收集和分析的值的節點。
3. 運行摘要節點以及運行模型節點。通常,您將使用便捷函數`tf.summary.merge_all()`將所有匯總節點合并到一個匯總節點中。然后執行此合并節點將基本上執行所有摘要節點。合并的摘要節點生成包含所有摘要的并集的序列化`Summary` ProtocolBuffers 對象。
1. 通過將`Summary` ProtocolBuffers 對象傳遞給`tf.summary.FileWriter`對象將事件日志寫入磁盤。
2. 啟動 TensorBoard 并分析可視化數據。
在本節中,我們沒有創建匯總節點,而是以非常簡單的方式使用 TensorBoard。我們將在本書后面介紹 TensorBoard 的高級用法。
# 總結
在本章中,我們快速回顧了 TensorFlow 庫。我們了解了可用于構建 TensorFlow 計算圖的 TensorFlow 數據模型元素,例如常量,變量和占位符。我們學習了如何從 Python 對象創建 Tensors。張量對象也可以作為特定值,序列或來自 TensorFlow 中可用的各種庫函數的隨機值分布生成。
TensorFlow 編程模型包括構建和執行計算圖。計算圖具有節點和邊。節點表示操作,邊表示將數據從一個節點傳輸到另一個節點的張量。我們介紹了如何創建和執行圖,執行順序以及如何在不同的計算設備(如 GPU 和 CPU)上執行圖。我們還學習了可視化 TensorFlow 計算圖 TensorBoard 的工具。
在下一章中,我們將探索構建在 TensorFlow 之上的一些高級庫,并允許我們快速構建模型。
- TensorFlow 1.x 深度學習秘籍
- 零、前言
- 一、TensorFlow 簡介
- 二、回歸
- 三、神經網絡:感知器
- 四、卷積神經網絡
- 五、高級卷積神經網絡
- 六、循環神經網絡
- 七、無監督學習
- 八、自編碼器
- 九、強化學習
- 十、移動計算
- 十一、生成模型和 CapsNet
- 十二、分布式 TensorFlow 和云深度學習
- 十三、AutoML 和學習如何學習(元學習)
- 十四、TensorFlow 處理單元
- 使用 TensorFlow 構建機器學習項目中文版
- 一、探索和轉換數據
- 二、聚類
- 三、線性回歸
- 四、邏輯回歸
- 五、簡單的前饋神經網絡
- 六、卷積神經網絡
- 七、循環神經網絡和 LSTM
- 八、深度神經網絡
- 九、大規模運行模型 -- GPU 和服務
- 十、庫安裝和其他提示
- TensorFlow 深度學習中文第二版
- 一、人工神經網絡
- 二、TensorFlow v1.6 的新功能是什么?
- 三、實現前饋神經網絡
- 四、CNN 實戰
- 五、使用 TensorFlow 實現自編碼器
- 六、RNN 和梯度消失或爆炸問題
- 七、TensorFlow GPU 配置
- 八、TFLearn
- 九、使用協同過濾的電影推薦
- 十、OpenAI Gym
- TensorFlow 深度學習實戰指南中文版
- 一、入門
- 二、深度神經網絡
- 三、卷積神經網絡
- 四、循環神經網絡介紹
- 五、總結
- 精通 TensorFlow 1.x
- 一、TensorFlow 101
- 二、TensorFlow 的高級庫
- 三、Keras 101
- 四、TensorFlow 中的經典機器學習
- 五、TensorFlow 和 Keras 中的神經網絡和 MLP
- 六、TensorFlow 和 Keras 中的 RNN
- 七、TensorFlow 和 Keras 中的用于時間序列數據的 RNN
- 八、TensorFlow 和 Keras 中的用于文本數據的 RNN
- 九、TensorFlow 和 Keras 中的 CNN
- 十、TensorFlow 和 Keras 中的自編碼器
- 十一、TF 服務:生產中的 TensorFlow 模型
- 十二、遷移學習和預訓練模型
- 十三、深度強化學習
- 十四、生成對抗網絡
- 十五、TensorFlow 集群的分布式模型
- 十六、移動和嵌入式平臺上的 TensorFlow 模型
- 十七、R 中的 TensorFlow 和 Keras
- 十八、調試 TensorFlow 模型
- 十九、張量處理單元
- TensorFlow 機器學習秘籍中文第二版
- 一、TensorFlow 入門
- 二、TensorFlow 的方式
- 三、線性回歸
- 四、支持向量機
- 五、最近鄰方法
- 六、神經網絡
- 七、自然語言處理
- 八、卷積神經網絡
- 九、循環神經網絡
- 十、將 TensorFlow 投入生產
- 十一、更多 TensorFlow
- 與 TensorFlow 的初次接觸
- 前言
- 1.?TensorFlow 基礎知識
- 2. TensorFlow 中的線性回歸
- 3. TensorFlow 中的聚類
- 4. TensorFlow 中的單層神經網絡
- 5. TensorFlow 中的多層神經網絡
- 6. 并行
- 后記
- TensorFlow 學習指南
- 一、基礎
- 二、線性模型
- 三、學習
- 四、分布式
- TensorFlow Rager 教程
- 一、如何使用 TensorFlow Eager 構建簡單的神經網絡
- 二、在 Eager 模式中使用指標
- 三、如何保存和恢復訓練模型
- 四、文本序列到 TFRecords
- 五、如何將原始圖片數據轉換為 TFRecords
- 六、如何使用 TensorFlow Eager 從 TFRecords 批量讀取數據
- 七、使用 TensorFlow Eager 構建用于情感識別的卷積神經網絡(CNN)
- 八、用于 TensorFlow Eager 序列分類的動態循壞神經網絡
- 九、用于 TensorFlow Eager 時間序列回歸的遞歸神經網絡
- TensorFlow 高效編程
- 圖嵌入綜述:問題,技術與應用
- 一、引言
- 三、圖嵌入的問題設定
- 四、圖嵌入技術
- 基于邊重構的優化問題
- 應用
- 基于深度學習的推薦系統:綜述和新視角
- 引言
- 基于深度學習的推薦:最先進的技術
- 基于卷積神經網絡的推薦
- 關于卷積神經網絡我們理解了什么
- 第1章概論
- 第2章多層網絡
- 2.1.4生成對抗網絡
- 2.2.1最近ConvNets演變中的關鍵架構
- 2.2.2走向ConvNet不變性
- 2.3時空卷積網絡
- 第3章了解ConvNets構建塊
- 3.2整改
- 3.3規范化
- 3.4匯集
- 第四章現狀
- 4.2打開問題
- 參考
- 機器學習超級復習筆記
- Python 遷移學習實用指南
- 零、前言
- 一、機器學習基礎
- 二、深度學習基礎
- 三、了解深度學習架構
- 四、遷移學習基礎
- 五、釋放遷移學習的力量
- 六、圖像識別與分類
- 七、文本文件分類
- 八、音頻事件識別與分類
- 九、DeepDream
- 十、自動圖像字幕生成器
- 十一、圖像著色
- 面向計算機視覺的深度學習
- 零、前言
- 一、入門
- 二、圖像分類
- 三、圖像檢索
- 四、對象檢測
- 五、語義分割
- 六、相似性學習
- 七、圖像字幕
- 八、生成模型
- 九、視頻分類
- 十、部署
- 深度學習快速參考
- 零、前言
- 一、深度學習的基礎
- 二、使用深度學習解決回歸問題
- 三、使用 TensorBoard 監控網絡訓練
- 四、使用深度學習解決二分類問題
- 五、使用 Keras 解決多分類問題
- 六、超參數優化
- 七、從頭開始訓練 CNN
- 八、將預訓練的 CNN 用于遷移學習
- 九、從頭開始訓練 RNN
- 十、使用詞嵌入從頭開始訓練 LSTM
- 十一、訓練 Seq2Seq 模型
- 十二、深度強化學習
- 十三、生成對抗網絡
- TensorFlow 2.0 快速入門指南
- 零、前言
- 第 1 部分:TensorFlow 2.00 Alpha 簡介
- 一、TensorFlow 2 簡介
- 二、Keras:TensorFlow 2 的高級 API
- 三、TensorFlow 2 和 ANN 技術
- 第 2 部分:TensorFlow 2.00 Alpha 中的監督和無監督學習
- 四、TensorFlow 2 和監督機器學習
- 五、TensorFlow 2 和無監督學習
- 第 3 部分:TensorFlow 2.00 Alpha 的神經網絡應用
- 六、使用 TensorFlow 2 識別圖像
- 七、TensorFlow 2 和神經風格遷移
- 八、TensorFlow 2 和循環神經網絡
- 九、TensorFlow 估計器和 TensorFlow HUB
- 十、從 tf1.12 轉換為 tf2
- TensorFlow 入門
- 零、前言
- 一、TensorFlow 基本概念
- 二、TensorFlow 數學運算
- 三、機器學習入門
- 四、神經網絡簡介
- 五、深度學習
- 六、TensorFlow GPU 編程和服務
- TensorFlow 卷積神經網絡實用指南
- 零、前言
- 一、TensorFlow 的設置和介紹
- 二、深度學習和卷積神經網絡
- 三、TensorFlow 中的圖像分類
- 四、目標檢測與分割
- 五、VGG,Inception,ResNet 和 MobileNets
- 六、自編碼器,變分自編碼器和生成對抗網絡
- 七、遷移學習
- 八、機器學習最佳實踐和故障排除
- 九、大規模訓練
- 十、參考文獻