
# 七、TensorFlow GPU 配置
要將 TensorFlow 與 NVIDIA GPU 配合使用,第一步是安裝 CUDA 工具包。
### 注意
要了解更多信息,請訪問[此鏈接](https://developer.nvidia.com/cuda-downloads)。
安裝 CUDA 工具包后,必須從[此鏈接](https://developer.nvidia.com/cudnn)下載適用于 Linux 的 cuDNN v5.1 庫。
cuDNN 是一個有助于加速深度學習框架的庫,例如 TensorFlow 和 Theano。以下是 NVIDIA 網站的簡要說明:
> NVIDIACUDA?深度神經網絡庫(cuDNN)是用于深度神經網絡的 GPU 加速原語庫.cuDNN 為標準例程提供高度調整的實現,例如前向和后向卷積,池化,正則化和激活層。cuDNN 是 NVIDIA 深度學習 SDK 的一部分。
在安裝之前,您需要在 NVIDIA 的加速計算開發人員計劃中注冊。注冊后,登錄并將 cuDNN 5.1 下載到本地計算機。
下載完成后,解壓縮文件并將其復制到 CUDA 工具包目錄中(我們假設目錄為`/usr/local/cuda/`):
```py
$ sudo tar -xvf cudnn-8.0-linux-x64-v5.1-rc.tgz -C /usr/local
```
## 更新 TensorFlow
我們假設您將使用 TensorFlow 來構建您的深度神經網絡模型。只需通過 PIP 用`upgrade`標志更新 TensorFlow。
我們假設您當前正在使用 TensorFlow 0.11:
```py
pip install — upgrade https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow-0.10.0rc0-cp27-none-linux_x86_64.whl
```
現在,您應該擁有使用 GPU 運行模型所需的一切。
## GPU 表示
在 TensorFlow 中, 支持的設備表示為字符串:
* `"/cpu:0"`:您機器的 CPU
* `"/gpu:0"`:機器的 GPU,如果你有的話
* `"/gpu:1"`:你機器的第二個 GPU,依此類推
當將操作分配給 GPU 設備時, 執行流程給予優先級。
## GPU 使用
要在 TensorFlow 程序中使用 GPU,只需鍵入以下內容:
```py
with tf.device("/gpu:0"):
```
然后你需要進行設置操作。這行代碼將創建一個新的上下文管理器,告訴 TensorFlow 在 GPU 上執行這些操作。
讓我們考慮以下示例,其中我們要執行以下兩個大矩陣的和:`A^n + B^n`。
定義基本導入:
```py
import numpy as np
import tensorflow as tf
import datetime
```
我們可以配置 TensorFlow 程序,以找出您的操作和張量分配給哪些設備。為此,我們將創建一個會話,并將以下`log_device_placement`參數設置為`True`:
```py
log_device_placement = True
```
然后我們設置`n`參數,這是要執行的乘法次數:
```py
n=10
```
然后我們構建兩個隨機大矩陣。我們使用 NumPy `rand`函數來執行此操作:
```py
A = np.random.rand(10000, 10000).astype('float32')
B = np.random.rand(10000, 10000).astype('float32')
```
`A`和`B`各自的大小為`10000x10000`。
以下數組將用于存儲結果:
```py
c1 = []
c2 = []
```
接下來,我們定義將由 GPU 執行的內核矩陣乘法函數:
```py
def matpow(M, n):
if n == 1:
return M
else:
return tf.matmul(M, matpow(M, n-1))
```
正如我們之前解釋的 ,我們必須配置 GPU 和 GPU 以執行以下操作:
GPU 將計算`A^n`和`B^n`操作并將結果存儲在`c1`中:
```py
with tf.device('/gpu:0'):
a = tf.placeholder(tf.float32, [10000, 10000])
b = tf.placeholder(tf.float32, [10000, 10000])
c1.append(matpow(a, n))
c1.append(matpow(b, n))
```
`c1`(`A^n + B^n`)中所有元素的添加由 CPU 執行,因此我們定義以下內容:
```py
with tf.device('/cpu:0'):
sum = tf.add_n(c1)
```
`datetime`類允許我們得到計算時間:
```py
t1_1 = datetime.datetime.now()
with tf.Session(config=tf.ConfigProto\
(log_device_placement=log_device_placement)) as sess:
sess.run(sum, {a:A, b:B})
t2_1 = datetime.datetime.now()
```
然后顯示計算時間:
```py
print("GPU computation time: " + str(t2_1-t1_1))
```
在我的筆記本電腦上,使用 GeForce 840M 顯卡,結果如下:
```py
GPU computation time: 0:00:13.816644
```
## GPU 內存管理
在一些情況下,希望該過程僅分配可用內存的子集,或者僅增加該過程所需的內存使用量。 TensorFlow 在會話中提供兩個配置選項來控制它。
第一個是`allow_growth`選項,它嘗試根據運行時分配僅分配盡可能多的 GPU 內存:它開始分配非常少的內存,并且隨著會話運行并需要更多 GPU 內存,我們擴展 GPU 內存量 TensorFlow 流程需要。
請注意, 我們不釋放內存,因為這可能導致更糟糕的內存碎片。要打開此選項,請在`ConfigProto`中設置選項,如下所示:
```py
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
session = tf.Session(config=config, ...)
```
第二種方法是`per_process_gpu_memory_fraction`選項,它確定應分配每個可見 GPU 的總內存量的分數。例如,您可以告訴 TensorFlow 僅分配每個 GPU 總內存的 40%,如下所示:
```py
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.4
session = tf.Session(config=config, ...)
```
如果要真正限制 TensorFlow 進程可用的 GPU 內存量,這非常有用。
## 在多 GPU 系統上分配單個 GPU
如果系統中有多個 GPU,則默認情況下將選擇 ID 最低的 GPU。如果您想在不同的 GPU 上運行會話,則需要明確指定首選項。
例如,我們可以嘗試更改上一代碼中的 GPU 分配:
```py
with tf.device('/gpu:1'):
a = tf.placeholder(tf.float32, [10000, 10000])
b = tf.placeholder(tf.float32, [10000, 10000])
c1.append(matpow(a, n))
c1.append(matpow(b, n))
```
這樣,我們告訴`gpu1`執行內核函數。如果我們指定的設備不??存在(如我的情況),您將獲得`InvalidArgumentError`:
```py
InvalidArgumentError (see above for traceback): Cannot assign a device to node 'Placeholder_1': Could not satisfy explicit device specification '/device:GPU:1' because no devices matching that specification are registered in this process; available devices: /job:localhost/replica:0/task:0/cpu:0
[[Node: Placeholder_1 = Placeholder[dtype=DT_FLOAT, shape=[100,100], _device="/device:GPU:1"]()]]
```
如果您希望 TensorFlow 自動選擇現有且受支持的設備來運行操作(如果指定的設備不??存在),則可以在創建會話時在配置選項中將`allow_soft_placement`設置為`True`。
我們再次為以下節點設置`'/gpu:1'`:
```py
with tf.device('/gpu:1'):
a = tf.placeholder(tf.float32, [10000, 10000])
b = tf.placeholder(tf.float32, [10000, 10000])
c1.append(matpow(a, n))
c1.append(matpow(b, n))
```
然后我們構建一個`Session`,并將以下`allow_soft_placement`參數設置為`True`:
```py
with tf.Session(config=tf.ConfigProto\
(allow_soft_placement=True,\
log_device_placement=log_device_placement))\
as sess:
```
這樣,當我們運行會話時,不會顯示`InvalidArgumentError`。在這種情況下,我們會得到一個正確的結果,但有一點延遲:
```py
GPU computation time: 0:00:15.006644
```
## 具有軟放置的 GPU 的源代碼
這是完整源代碼,僅為了清楚起見:
```py
import numpy as np
import tensorflow as tf
import datetime
log_device_placement = True
n = 10
A = np.random.rand(10000, 10000).astype('float32')
B = np.random.rand(10000, 10000).astype('float32')
c1 = []
c2 = []
def matpow(M, n):
if n == 1:
return M
else:
return tf.matmul(M, matpow(M, n-1))
with tf.device('/gpu:0'):
a = tf.placeholder(tf.float32, [10000, 10000])
b = tf.placeholder(tf.float32, [10000, 10000])
c1.append(matpow(a, n))
c1.append(matpow(b, n))
with tf.device('/cpu:0'):
sum = tf.add_n(c1)
t1_1 = datetime.datetime.now()
with tf.Session(config=tf.ConfigProto\
(allow_soft_placement=True,\
log_device_placement=log_device_placement))\
as sess:
sess.run(sum, {a:A, b:B})
t2_1 = datetime.datetime.now()
```
## 使用多個 GPU
如果您想在多個 GPU 上運行 TensorFlow,您可以通過為 GPU 分配特定的代碼塊來構建模型。例如,如果我們有兩個 GPU,我們可以按如下方式拆分前面的代碼,將第一個矩陣計算分配給第一個 GPU:
```py
with tf.device('/gpu:0'):
a = tf.placeholder(tf.float32, [10000, 10000])
c1.append(matpow(a, n))
```
第二個矩陣計算分配給第二個 GPU:
```py
with tf.device('/gpu:1'):
b = tf.placeholder(tf.float32, [10000, 10000])
c1.append(matpow(b, n))
```
CPU 將管理結果。另請注意,我們使用共享`c1`數組來收集它們:
```py
with tf.device('/cpu:0'):
sum = tf.add_n(c1)
```
在下面的代碼片段中,我們提供了兩個 GPU 管理的具體示例:
```py
import numpy as np
import tensorflow as tf
import datetime
log_device_placement = True
n = 10
A = np.random.rand(10000, 10000).astype('float32')
B = np.random.rand(10000, 10000).astype('float32')
c1 = []
def matpow(M, n):
if n == 1:
return M
else:
return tf.matmul(M, matpow(M, n-1))
#FIRST GPU
with tf.device('/gpu:0'):
a = tf.placeholder(tf.float32, [10000, 10000])
c1.append(matpow(a, n))
#SECOND GPU
with tf.device('/gpu:1'):
b = tf.placeholder(tf.float32, [10000, 10000])
c1.append(matpow(b, n))
with tf.device('/cpu:0'):
sum = tf.add_n(c1)
t1_1 = datetime.datetime.now()
with tf.Session(config=tf.ConfigProto\
(allow_soft_placement=True,\
log_device_placement=log_device_placement))\
as sess:
sess.run(sum, {a:A, b:B})
t2_1 = datetime.datetime.now()
```
# 分布式計算
DL 模型必須接受大量數據的訓練,以提高其表現。但是,訓練具有數百萬參數的深度網絡可能需要數天甚至數周。在大規模分布式深度網絡中,Dean 等人。提出了兩種范例,即模型并行性和數據并行性,它們允許我們在多個物理機器上訓練和服務網絡模型。在下一節中,我們引入了這些范例,重點關注分布式 TensorFlow 功能。
## 模型并行
模型并行性為每個處理器提供相同的數據,但對其應用不同的模型。如果網絡模型太大而無法放入一臺機器的內存中,則可以將模型的不同部分分配給不同的機器。可能的模型并行方法是在機器(節點 1)上具有第一層,在第二機器(節點 2)上具有第二層,等等。有時這不是最佳方法,因為最后一層必須等待在前進步驟期間完成第一層的計算,并且第一層必須在反向傳播步驟期間等待最深層。只有模型可并行化(例如 GoogleNet)才能在不同的機器上實現,而不會遇到這樣的瓶頸:
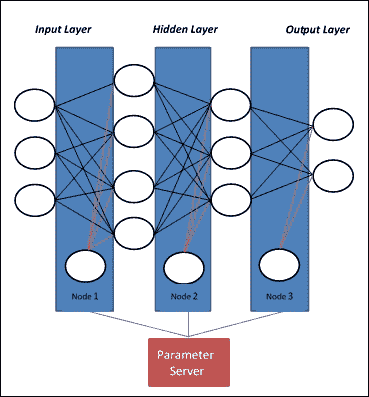
圖 3:在模型并行性中,每個節點計算網絡的不同部分
大約 20 年前, 訓練神經網絡的人可能是術語模型并行性的創始人,因為他們有不同的神經網絡模型來訓練和測試,并且網絡中的多個層可以用相同的數據。
## 數據并行
數據并行性表示將單個指令應用于多個數據項。它是 SIMD(單指令,多數據)計算機架構的理想工作負載,是電子數字計算機上最古老,最簡單的并行處理形式。
在這種方法中,網絡模型適合于一臺機器,稱為參數服務器,而大多數計算工作由多臺機器完成,稱為工作器:
* 參數服務器:這是一個 CPU,您可以在其中存儲工作器所需的變量。就我而言,這是我定義網絡所需的權重變量的地方。
* 工作器:這是我們完成大部分計算密集型工作的地方。
每個工作器負責讀取,計算和更新模型參數,并將它們發送到參數服務器:
* 在正向傳播中,工作者從參數服務器獲取變量,在我們的工作者上對它們執行某些操作。
* 在向后傳遞中,工作器將當前狀態發送回參數服務器,參數服務器執行更新操作,并為我們提供新的權重以進行嘗試:
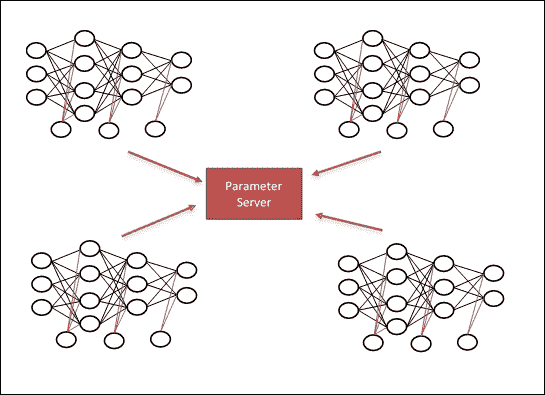
圖 4:在數據并行模型中,每個節點計算所有參數
數據并行可能有兩個主要的選項:
* 同步訓練:所有工作器同時讀取參數,計算訓練操作,并等待所有其他人完成。然后將梯度平均,并將單個更新發送到參數服務器。因此,在任何時間點,工作器都將意識到圖參數的相同值。
* 異步訓練:工作器將異步讀取參數服務器,計算訓練操作,并發送異步更新。在任何時間點,兩個不同的工作器可能會意識到圖參數的不同值。
# 分布式 TensorFlow 配置
在本節中,我們將探索 TensorFlow 中的計算可以分布的機制。運行分布式 TensorFlow 的第一步是使用`tf.train.ClusterSpec`指定集群的架構:
```py
import tensorflow as tf
cluster = tf.train.ClusterSpec({"ps": ["localhost:2222"],\
"worker": ["localhost:2223",\
"localhost:2224"]})
```
節點通常分為兩個作業:主機變量的參數服務器(`ps`)和執行大量計算的工作器。在上面的代碼中,我們有一個參數服務器和兩個工作器,以及每個節點的 IP 地址和端口。
然后我們必須為之前定義的每個參數服務器和工作器構建一個`tf.train.Server`:
```py
ps = tf.train.Server(cluster, job_name="ps", task_index=0)
worker0 = tf.train.Server(cluster,\
job_name="worker", task_index=0)
worker1 = tf.train.Server(cluster,\
job_name="worker", task_index=1)
```
`tf.train.Server`對象包含一組本地設備,一組與`tf.train.ClusterSpec`中其他任務的連接,以及一個可以使用它們執行分布式計算的`tf.Session`。創建它是為了允許設備之間的連接。
接下來,我們使用以下命令將模型變量分配給工作器:
```py
tf.device :
with tf.device("/job:ps/task:0"):
a = tf.constant(3.0, dtype=tf.float32)
b = tf.constant(4.0)
```
將這些指令復制到名為`main.py`的文件中。
在兩個單獨的文件`worker0.py`和`worker1.py`中,我們必須定義工作器。在`worker0.py`中,將兩個變量`a`和`b`相乘并打印出結果:
```py
import tensorflow as tf
from main import *
with tf.Session(worker0.target) as sess:
init = tf.global_variables_initializer()
add_node = tf.multiply(a,b)
sess.run(init)
print(sess.run(add_node))
```
在`worker1.py`中,首先更改`a`的值,然后將兩個變量`a`和`b`相乘:
```py
import tensorflow as tf
from main import *
with tf.Session(worker1.target) as sess:
init = tf.global_variables_initializer()
a = tf.constant(10.0, dtype=tf.float32)
add_node = tf.multiply(a,b)
sess.run(init)
a = add_node
print(sess.run(add_node))
```
要執行此示例,首先從命令提示符運行`main.py`文件。
你應該得到這樣的結果:
```py
>python main.py
Found device 0 with properties:
name: GeForce 840M
major: 5 minor: 0 memoryClockRate (GHz) 1.124
pciBusID 0000:08:00.0
Total memory: 2.00GiB
Free memory: 1.66GiB
Started server with target: grpc://localhost:2222
```
然后我們可以運行工作器:
```py
> python worker0.py
Found device 0 with properties:
name: GeForce 840M
major: 5 minor: 0 memoryClockRate (GHz) 1.124
pciBusID 0000:08:00.0
Total memory: 2.00GiB
Free memory: 1.66GiB
Start master session 83740f48d039c97d with config:
12.0
> python worker1.py
Found device 0 with properties:
name: GeForce 840M
major: 5 minor: 0 memoryClockRate (GHz) 1.124
pciBusID 0000:08:00.0
Total memory: 2.00GiB
Free memory: 1.66GiB
Start master session 3465f63a4d9feb85 with config:
40.0
```
# 總結
在本章中,我們快速了解了與優化 DNN 計算相關的兩個基本主題。
第一個主題解釋了如何使用 GPU 和 TensorFlow 來實現 DNN。它們以非常統一的方式構造,使得在網絡的每一層,數千個相同的人工神經元執行相同的計算。因此,DNN 的架構非常適合 GPU 可以有效執行的計算類型。
第二個主題介紹了分布式計算。這最初用于執行非常復雜的計算,這些計算無法由單個機器完成。同樣,在面對如此大的挑戰時,通過在不同節點之間拆分此任務來快速分析大量數據似乎是最佳策略。
同時,可以使用分布式計算來利用 DL 問題。 DL 計算可以分為多個活動(任務);他們每個人都將獲得一小部分數據,并返回一個結果,該結果必須與其他活動提供的結果重新組合。或者,在大多數復雜情況下,可以為每臺機器分配不同的計算算法。
最后,在最后一個例子中,我們展示了如何分配 TensorFlow 中的計算。
- TensorFlow 1.x 深度學習秘籍
- 零、前言
- 一、TensorFlow 簡介
- 二、回歸
- 三、神經網絡:感知器
- 四、卷積神經網絡
- 五、高級卷積神經網絡
- 六、循環神經網絡
- 七、無監督學習
- 八、自編碼器
- 九、強化學習
- 十、移動計算
- 十一、生成模型和 CapsNet
- 十二、分布式 TensorFlow 和云深度學習
- 十三、AutoML 和學習如何學習(元學習)
- 十四、TensorFlow 處理單元
- 使用 TensorFlow 構建機器學習項目中文版
- 一、探索和轉換數據
- 二、聚類
- 三、線性回歸
- 四、邏輯回歸
- 五、簡單的前饋神經網絡
- 六、卷積神經網絡
- 七、循環神經網絡和 LSTM
- 八、深度神經網絡
- 九、大規模運行模型 -- GPU 和服務
- 十、庫安裝和其他提示
- TensorFlow 深度學習中文第二版
- 一、人工神經網絡
- 二、TensorFlow v1.6 的新功能是什么?
- 三、實現前饋神經網絡
- 四、CNN 實戰
- 五、使用 TensorFlow 實現自編碼器
- 六、RNN 和梯度消失或爆炸問題
- 七、TensorFlow GPU 配置
- 八、TFLearn
- 九、使用協同過濾的電影推薦
- 十、OpenAI Gym
- TensorFlow 深度學習實戰指南中文版
- 一、入門
- 二、深度神經網絡
- 三、卷積神經網絡
- 四、循環神經網絡介紹
- 五、總結
- 精通 TensorFlow 1.x
- 一、TensorFlow 101
- 二、TensorFlow 的高級庫
- 三、Keras 101
- 四、TensorFlow 中的經典機器學習
- 五、TensorFlow 和 Keras 中的神經網絡和 MLP
- 六、TensorFlow 和 Keras 中的 RNN
- 七、TensorFlow 和 Keras 中的用于時間序列數據的 RNN
- 八、TensorFlow 和 Keras 中的用于文本數據的 RNN
- 九、TensorFlow 和 Keras 中的 CNN
- 十、TensorFlow 和 Keras 中的自編碼器
- 十一、TF 服務:生產中的 TensorFlow 模型
- 十二、遷移學習和預訓練模型
- 十三、深度強化學習
- 十四、生成對抗網絡
- 十五、TensorFlow 集群的分布式模型
- 十六、移動和嵌入式平臺上的 TensorFlow 模型
- 十七、R 中的 TensorFlow 和 Keras
- 十八、調試 TensorFlow 模型
- 十九、張量處理單元
- TensorFlow 機器學習秘籍中文第二版
- 一、TensorFlow 入門
- 二、TensorFlow 的方式
- 三、線性回歸
- 四、支持向量機
- 五、最近鄰方法
- 六、神經網絡
- 七、自然語言處理
- 八、卷積神經網絡
- 九、循環神經網絡
- 十、將 TensorFlow 投入生產
- 十一、更多 TensorFlow
- 與 TensorFlow 的初次接觸
- 前言
- 1.?TensorFlow 基礎知識
- 2. TensorFlow 中的線性回歸
- 3. TensorFlow 中的聚類
- 4. TensorFlow 中的單層神經網絡
- 5. TensorFlow 中的多層神經網絡
- 6. 并行
- 后記
- TensorFlow 學習指南
- 一、基礎
- 二、線性模型
- 三、學習
- 四、分布式
- TensorFlow Rager 教程
- 一、如何使用 TensorFlow Eager 構建簡單的神經網絡
- 二、在 Eager 模式中使用指標
- 三、如何保存和恢復訓練模型
- 四、文本序列到 TFRecords
- 五、如何將原始圖片數據轉換為 TFRecords
- 六、如何使用 TensorFlow Eager 從 TFRecords 批量讀取數據
- 七、使用 TensorFlow Eager 構建用于情感識別的卷積神經網絡(CNN)
- 八、用于 TensorFlow Eager 序列分類的動態循壞神經網絡
- 九、用于 TensorFlow Eager 時間序列回歸的遞歸神經網絡
- TensorFlow 高效編程
- 圖嵌入綜述:問題,技術與應用
- 一、引言
- 三、圖嵌入的問題設定
- 四、圖嵌入技術
- 基于邊重構的優化問題
- 應用
- 基于深度學習的推薦系統:綜述和新視角
- 引言
- 基于深度學習的推薦:最先進的技術
- 基于卷積神經網絡的推薦
- 關于卷積神經網絡我們理解了什么
- 第1章概論
- 第2章多層網絡
- 2.1.4生成對抗網絡
- 2.2.1最近ConvNets演變中的關鍵架構
- 2.2.2走向ConvNet不變性
- 2.3時空卷積網絡
- 第3章了解ConvNets構建塊
- 3.2整改
- 3.3規范化
- 3.4匯集
- 第四章現狀
- 4.2打開問題
- 參考
- 機器學習超級復習筆記
- Python 遷移學習實用指南
- 零、前言
- 一、機器學習基礎
- 二、深度學習基礎
- 三、了解深度學習架構
- 四、遷移學習基礎
- 五、釋放遷移學習的力量
- 六、圖像識別與分類
- 七、文本文件分類
- 八、音頻事件識別與分類
- 九、DeepDream
- 十、自動圖像字幕生成器
- 十一、圖像著色
- 面向計算機視覺的深度學習
- 零、前言
- 一、入門
- 二、圖像分類
- 三、圖像檢索
- 四、對象檢測
- 五、語義分割
- 六、相似性學習
- 七、圖像字幕
- 八、生成模型
- 九、視頻分類
- 十、部署
- 深度學習快速參考
- 零、前言
- 一、深度學習的基礎
- 二、使用深度學習解決回歸問題
- 三、使用 TensorBoard 監控網絡訓練
- 四、使用深度學習解決二分類問題
- 五、使用 Keras 解決多分類問題
- 六、超參數優化
- 七、從頭開始訓練 CNN
- 八、將預訓練的 CNN 用于遷移學習
- 九、從頭開始訓練 RNN
- 十、使用詞嵌入從頭開始訓練 LSTM
- 十一、訓練 Seq2Seq 模型
- 十二、深度強化學習
- 十三、生成對抗網絡
- TensorFlow 2.0 快速入門指南
- 零、前言
- 第 1 部分:TensorFlow 2.00 Alpha 簡介
- 一、TensorFlow 2 簡介
- 二、Keras:TensorFlow 2 的高級 API
- 三、TensorFlow 2 和 ANN 技術
- 第 2 部分:TensorFlow 2.00 Alpha 中的監督和無監督學習
- 四、TensorFlow 2 和監督機器學習
- 五、TensorFlow 2 和無監督學習
- 第 3 部分:TensorFlow 2.00 Alpha 的神經網絡應用
- 六、使用 TensorFlow 2 識別圖像
- 七、TensorFlow 2 和神經風格遷移
- 八、TensorFlow 2 和循環神經網絡
- 九、TensorFlow 估計器和 TensorFlow HUB
- 十、從 tf1.12 轉換為 tf2
- TensorFlow 入門
- 零、前言
- 一、TensorFlow 基本概念
- 二、TensorFlow 數學運算
- 三、機器學習入門
- 四、神經網絡簡介
- 五、深度學習
- 六、TensorFlow GPU 編程和服務
- TensorFlow 卷積神經網絡實用指南
- 零、前言
- 一、TensorFlow 的設置和介紹
- 二、深度學習和卷積神經網絡
- 三、TensorFlow 中的圖像分類
- 四、目標檢測與分割
- 五、VGG,Inception,ResNet 和 MobileNets
- 六、自編碼器,變分自編碼器和生成對抗網絡
- 七、遷移學習
- 八、機器學習最佳實踐和故障排除
- 九、大規模訓練
- 十、參考文獻