
# 十五、TensorFlow 集群的分布式模型
之前我們學習了如何使用 Kubernetes,Docker 和 TensorFlow 服務在生產中大規模運行 TensorFlow 模型。 TensorFlow 服務并不是大規模運行 TensorFlow 模型的唯一方法。 TensorFlow 提供了另一種機制,不僅可以運行,還可以在多個節點或同一節點上的不同節點和不同設備上訓練模型。 在第 1 章,TensorFlow 101 中,我們還學習了如何在不同設備上放置變量和操作。在本章中,我們將學習如何分發 TensorFlow 模型以在多個節點上的多個設備上運行。
在本章中,我們將介紹以下主題:
* 分布式執行策略
* TensorFlow 集群
* 數據并行模型
* 對分布式模型的異步和同步更新
# 分布式執行策略
為了在多個設備或節點上分發單個模型的訓練,有以下策略:
* **模型并行**:將模型劃分為多個子圖,并將單獨的圖放在不同的節點或設備上。子圖執行計算并根據需要交換變量。
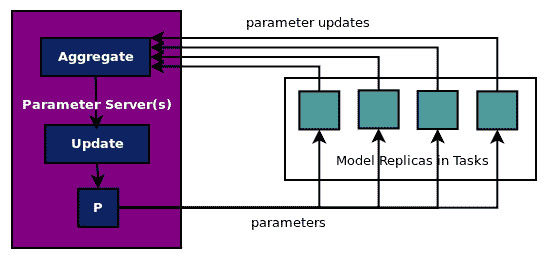
* **數據并行**:將數據分組并在多個節點或設備上運行相同的模型,并在主節點上組合參數。因此,工作節點在批量數據上訓練模型并將參數更新發送到主節點,也稱為參數服務器。
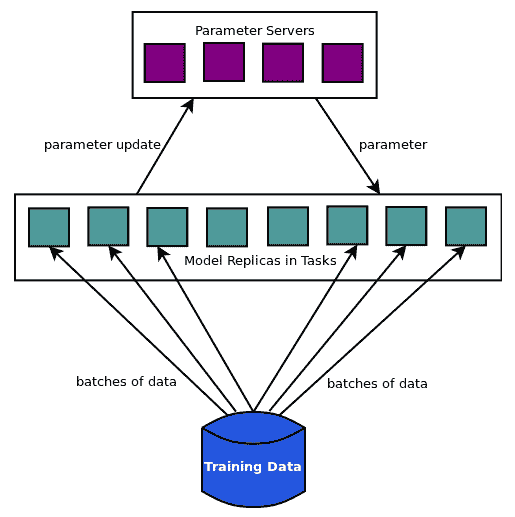
上圖顯示了數據并行方法,其中模型副本分批讀取數據分區并將參數更新發送到參數服務器,參數服務器將更新的參數發送回模型副本以進行下一次批量計算的更新。
在 TensorFlow 中,有兩種方法可以在數據并行策略下在多??個節點/設備上實現模型的復制:
* **圖中復制**:在這種方法中,有一個客戶端任務擁有模型參數,并將模型計算分配給多個工作任務。
* **圖之間復制**:在這種方法中,每個客戶端任務都連接到自己的工作者以分配模型計算,但所有工作器都更新相同的共享模型。在此模型中,TensorFlow 會自動將一個工作器指定為主要工作器,以便模型參數僅由主要工作器初始化一次。
在這兩種方法中,參數服務器上的參數可以通過兩種不同的方式更新:
* **同步更新**:在同步更新中,參數服務器等待在更新梯度之前從所有工作器接收更新。參數服務器聚合更新,例如通過計算所有聚合的平均值并將其應用于參數。更新后,參數將同時發送給所有工作器。這種方法的缺點是一個慢工作者可能會減慢每個人的更新速度。
* **異步更新**:在異步更新中,工作器在準備好時將更新發送到參數服務器,然后參數服務器在接收更新時應用更新并將其發回。這種方法的缺點是,當工作器計算參數并發回更新時,參數可能已被其他工作器多次更新。這個問題可以通過幾種方法來減輕,例如降低批量大小或降低學習率。令人驚訝的是,異步方法甚至可以工作,但實際上,它們確實有效!
# TensorFlow 集群
TensorFlow(TF)集群是一種實現我們剛剛討論過的分布式策略的機制。在邏輯層面,TF 集群運行一個或多個作業,并且每個作業由一個或多個任務組成。因此,工作只是任務的邏輯分組。在進程級別,每個任務都作為 TF 服務器運行。在機器級別,每個物理機器或節點可以通過運行多個服務器(每個任務一個服務器)來運行多個任務。客戶端在不同的服務器上創建圖,并通過調用遠程會話在一臺服務器上開始執行圖。
作為示例,下圖描繪了連接到名為`m1`的兩個作業的兩個客戶端:
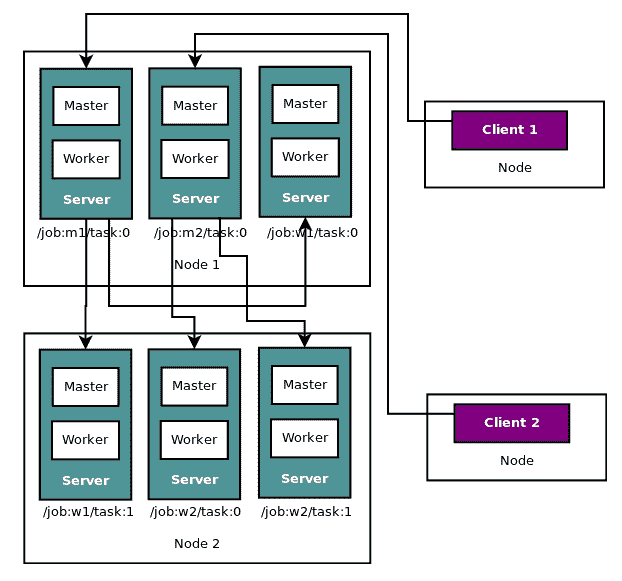
這兩個節點分別運行三個任務,作業`w1`分布在兩個節點上,而其他作業包含在節點中。
TF 服務器實現為兩個進程:主控制器和工作器。 主控制器與其他任務協調計算,工作器是實際運行計算的工作器。 在更高級別,您不必擔心 TF 服務器的內部。 出于我們的解釋和示例的目的,我們將僅涉及 TF 任務。
要以數據并行方式創建和訓練模型,請使用以下步驟:
1. 定義集群規范
2. 創建服務器以承載任務
3. 定義要分配給參數服務器任務的變量節點
4. 定義要在所有工作任務上復制的操作節點
1. 創建遠程會話
2. 在遠程會話中訓練模型
3. 使用該模型進行預測
# 定義集群規范
要創建集群,首先要定義集群規范。集群規范通常包含兩個作業:`ps`用于創建參數服務器任務,`worker`用于創建工作任務。`worker`和`ps`作業包含運行各自任務的物理節點列表。舉個例子:
```py
clusterSpec = tf.train.ClusterSpec({
'ps': [
'master0.neurasights.com:2222', # /job:ps/task:0
'master1.neurasights.com:2222' # /job:ps/task:1
]
'worker': [
'worker0.neurasights.com:2222', # /job:worker/task:0
'worker1.neurasights.com:2222', # /job:worker/task:1
'worker0.neurasights.com:2223', # /job:worker/task:2
'worker1.neurasights.com:2223' # /job:worker/task:3
]
})
```
該規范創建了兩個作業,作業`ps`中的兩個任務分布在兩個物理節點上,作業`worker`中的四個任務分布在兩個物理節點上。
在我們的示例代碼中,我們在不同端口上的 localhost 上創建所有任務:
```py
ps = [
'localhost:9001', # /job:ps/task:0
]
workers = [
'localhost:9002', # /job:worker/task:0
'localhost:9003', # /job:worker/task:1
'localhost:9004', # /job:worker/task:2
]
clusterSpec = tf.train.ClusterSpec({'ps': ps, 'worker': workers})
```
正如您在代碼中的注釋中所看到的,任務通過`/job:<job name>/task:<task index>`標識。
# 創建服務器實例
由于集群每個任務包含一個服務器實例,因此在每個物理節點上,通過向服務器傳遞集群規范,它們自己的作業名稱和任務索引來啟動服務器。服務器使用集群規范來確定計算中涉及的其他節點。
```py
server = tf.train.Server(clusterSpec, job_name="ps", task_index=0)
server = tf.train.Server(clusterSpec, job_name="worker", task_index=0)
server = tf.train.Server(clusterSpec, job_name="worker", task_index=1)
server = tf.train.Server(clusterSpec, job_name="worker", task_index=2)
```
在我們的示例代碼中,我們有一個 Python 文件可以在所有物理機器上運行,包含以下內容:
```py
server = tf.train.Server(clusterSpec,
job_name=FLAGS.job_name,
task_index=FLAGS.task_index,
config=config
)
```
在此代碼中,`job_name`和`task_index`取自命令行傳遞的參數。包`tf.flags`是一個花哨的解析器,可以訪問命令行參數。 Python 文件在每個物理節點上執行如下(如果您僅使用本地主機,則在同一節點上的單獨終端中執行):
```py
# the model should be run in each physical node
# using the appropriate arguments
$ python3 model.py --job_name='ps' --task_index=0
$ python3 model.py --job_name='worker' --task_index=0
$ python3 model.py --job_name='worker' --task_index=1
$ python3 model.py --job_name='worker' --task_index=2
```
為了在任何集群上運行代碼具有更大的靈活性,您還可以通過命令行傳遞運行參數服務器和工作程序的計算機列表:`-ps='localhost:9001' --worker='localhost:9002,localhost:9003,``localhost:9004'`。您需要解析它們并在集群規范字典中正確設置它們。
為確保我們的參數服務器僅使用 CPU 而我們的工作器任務使用 GPU,我們使用配置對象:
```py
config = tf.ConfigProto()
config.allow_soft_placement = True
if FLAGS.job_name=='ps':
#print(config.device_count['GPU'])
config.device_count['GPU']=0
server = tf.train.Server(clusterSpec,
job_name=FLAGS.job_name,
task_index=FLAGS.task_index,
config=config
)
server.join()
sys.exit('0')
elif FLAGS.job_name=='worker':
config.gpu_options.per_process_gpu_memory_fraction = 0.2
server = tf.train.Server(clusterSpec,
job_name=FLAGS.job_name,
task_index=FLAGS.task_index,
config=config
```
當工作器執行模型訓練并退出時,參數服務器等待`server.join()`。
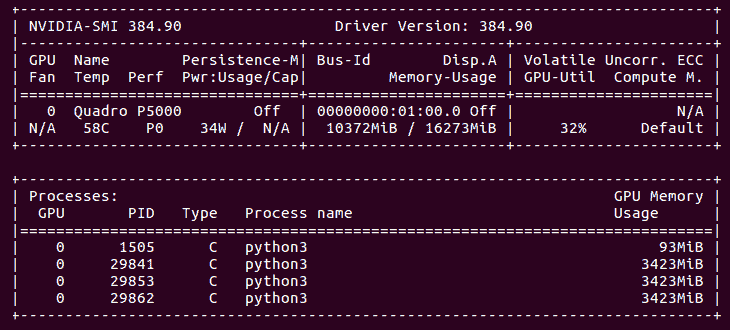
這就是我們的 GPU 在所有四臺服務器運行時的樣子:
# 定義服務器和設備之間的參數和操作
您可以使用我們在第 1 章中使用的`tf.device()`函數,將參數放在`ps`任務和`worker`任務上圖的計算節點上。
請注意,您還可以通過將設備字符串添加到任務字符串來將圖節點放置在特定設備上,如下所示:`/job:<job name>/task:<task index>/device:<device type>:<device index>`.
對于我們的演示示例,我們使用 TensorFlow 函數`tf.train.replica_device_setter()`來放置變量和操作。
1. 首先,我們將工作器設備定義為當前工作器:
```py
worker_device='/job:worker/task:{}'.format(FLAGS.task_index)
```
1. 接下來,使用`replica_device_setter`定義設備函數,傳遞集群規范和當前工作設備。`replica_device_setter`函數從集群規范中計算出參數服務器,如果有多個參數服務器,則默認情況下以循環方式在它們之間分配參數。參數放置策略可以更改為`tf.contrib`包中的用戶定義函數或預構建策略。
```py
device_func = tf.train.replica_device_setter(
worker_device=worker_device,cluster=clusterSpec)
```
1. 最后,我們在`tf.device(device_func)`塊內創建圖并訓練它。對于同步更新和異步更新,圖的創建和訓練是不同的,因此我們將在兩個單獨的小節中介紹這些內容。
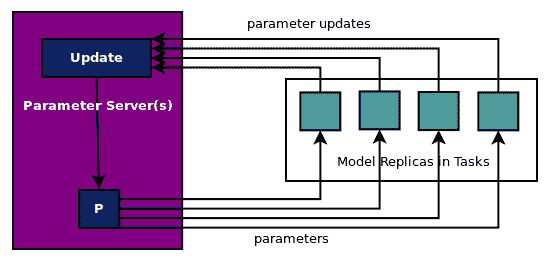
# 定義并訓練圖以進行異步更新
如前所述,并在此處的圖中顯示,在異步更新中,所有工作任務在準備就緒時發送參數更新,參數服務器更新參數并發回參數。參數更新沒有同步或等待或聚合:
The full code for this example is in?`ch-15_mnist_dist_async.py`. You are encouraged to modify and explore the code with your own datasets.
對于異步更新,將使用以下步驟創建和訓練圖:
1. 圖的定義在`with`塊內完成:
```py
with tf.device(device_func):
```
1. 使用內置的 TensorFlow 函數創建全局步驟變量:
```py
global_step = tf.train.get_or_create_global_step()
```
1. 此變量也可以定義為:
```py
tf.Variable(0,name='global_step',trainable=False)
```
1. 像往常一樣定義數據集,參數和超參數:
```py
x_test = mnist.test.images
y_test = mnist.test.labels
n_outputs = 10 # 0-9 digits
n_inputs = 784 # total pixels
learning_rate = 0.01
n_epochs = 50
batch_size = 100
n_batches = int(mnist.train.num_examples/batch_size)
n_epochs_print=10
```
1. 像往常一樣定義占位符,權重,偏差,對率,交叉熵,損失操作,訓練操作,準確率:
```py
# input images
x_p = tf.placeholder(dtype=tf.float32,
name='x_p',
shape=[None, n_inputs])
# target output
y_p = tf.placeholder(dtype=tf.float32,
name='y_p',
shape=[None, n_outputs])
w = tf.Variable(tf.random_normal([n_inputs, n_outputs],
name='w'
)
)
b = tf.Variable(tf.random_normal([n_outputs],
name='b'
)
)
logits = tf.matmul(x_p,w) + b
entropy_op = tf.nn.softmax_cross_entropy_with_logits(labels=y_p,
logits=logits
)
loss_op = tf.reduce_mean(entropy_op)
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
train_op = optimizer.minimize(loss_op,global_step=global_step)
correct_pred = tf.equal(tf.argmax(logits, 1), tf.argmax(y_p, 1))
accuracy_op = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
```
當我們學習如何構建同步更新時,這些定義將會改變。
1. TensorFlow 提供了一個主管類,可以幫助創建訓練會話,在分布式訓練設置中非常有用。創建一個`supervisor`對象,如下所示:
```py
init_op = tf.global_variables_initializer
sv = tf.train.Supervisor(is_chief=is_chief,
init_op = init_op(),
global_step=global_step)
```
1. 使用`supervisor`對象創建會話并像往常一樣在此會話塊下運行訓練:
```py
with sv.prepare_or_wait_for_session(server.target) as mts:
lstep = 0
for epoch in range(n_epochs):
for batch in range(n_batches):
x_batch, y_batch = mnist.train.next_batch(batch_size)
feed_dict={x_p:x_batch,y_p:y_batch}
_,loss,gstep=mts.run([train_op,loss_op,global_step],
feed_dict=feed_dict)
lstep +=1
if (epoch+1)%n_epochs_print==0:
print('worker={},epoch={},global_step={}, \
local_step={},loss={}'.
format(FLAGS.task_index,epoch,gstep,lstep,loss))
feed_dict={x_p:x_test,y_p:y_test}
accuracy = mts.run(accuracy_op, feed_dict=feed_dict)
print('worker={}, final accuracy = {}'
.format(FLAGS.task_index,accuracy))
```
在啟動參數服務器時,我們得到以下輸出:
```py
$ python3 ch-15_mnist_dist_async.py --job_name='ps' --task_index=0
I tensorflow/core/common_runtime/gpu/gpu_device.cc:1030] Found device 0 with properties:
name: Quadro P5000 major: 6 minor: 1 memoryClockRate(GHz): 1.506
pciBusID: 0000:01:00.0
totalMemory: 15.89GiB freeMemory: 15.79GiB
I tensorflow/core/common_runtime/gpu/gpu_device.cc:1120] Creating TensorFlow device (/device:GPU:0) -> (device: 0, name: Quadro P5000, pci bus id: 0000:01:00.0, compute capability: 6.1)
E1213 16:50:14.023235178 27224 ev_epoll1_linux.c:1051] grpc epoll fd: 23
I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize GrpcChannelCache for job ps -> {0 -> localhost:9001}
I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize GrpcChannelCache for job worker -> {0 -> localhost:9002, 1 -> localhost:9003, 2 -> localhost:9004}
I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:324] Started server with target: grpc://localhost:9001
```
在啟動工作任務時,我們得到以下三個輸出:
工作器 1 的輸出:
```py
$ python3 ch-15_mnist_dist_async.py --job_name='worker' --task_index=0
I tensorflow/core/common_runtime/gpu/gpu_device.cc:1030] Found device 0 with properties:
name: Quadro P5000 major: 6 minor: 1 memoryClockRate(GHz): 1.506
pciBusID: 0000:01:00.0
totalMemory: 15.89GiB freeMemory: 9.16GiB
I tensorflow/core/common_runtime/gpu/gpu_device.cc:1120] Creating TensorFlow device (/device:GPU:0) -> (device: 0, name: Quadro P5000, pci bus id: 0000:01:00.0, compute capability: 6.1)
E1213 16:50:37.516609689 27507 ev_epoll1_linux.c:1051] grpc epoll fd: 23
I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize GrpcChannelCache for job ps -> {0 -> localhost:9001}
I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize GrpcChannelCache for job worker -> {0 -> localhost:9002, 1 -> localhost:9003, 2 -> localhost:9004}
I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:324] Started server with target: grpc://localhost:9002
I tensorflow/core/distributed_runtime/master_session.cc:1004] Start master session 1421824c3df413b5 with config: gpu_options { per_process_gpu_memory_fraction: 0.2 } allow_soft_placement: true
worker=0,epoch=9,global_step=10896, local_step=5500, loss = 1.2575616836547852
worker=0,epoch=19,global_step=22453, local_step=11000, loss = 0.7158586382865906
worker=0,epoch=29,global_step=39019, local_step=16500, loss = 0.43712112307548523
worker=0,epoch=39,global_step=55513, local_step=22000, loss = 0.3935799300670624
worker=0,epoch=49,global_step=72002, local_step=27500, loss = 0.3877961337566376
worker=0, final accuracy = 0.8865000009536743
```
工作器 2 的輸出:
```py
$ python3 ch-15_mnist_dist_async.py --job_name='worker' --task_index=1
I tensorflow/core/common_runtime/gpu/gpu_device.cc:1030] Found device 0 with properties:
name: Quadro P5000 major: 6 minor: 1 memoryClockRate(GHz): 1.506
pciBusID: 0000:01:00.0
totalMemory: 15.89GiB freeMemory: 12.43GiB
I tensorflow/core/common_runtime/gpu/gpu_device.cc:1120] Creating TensorFlow device (/device:GPU:0) -> (device: 0, name: Quadro P5000, pci bus id: 0000:01:00.0, compute capability: 6.1)
E1213 16:50:36.684334877 27461 ev_epoll1_linux.c:1051] grpc epoll fd: 23
I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize GrpcChannelCache for job ps -> {0 -> localhost:9001}
I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize GrpcChannelCache for job worker -> {0 -> localhost:9002, 1 -> localhost:9003, 2 -> localhost:9004}
I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:324] Started server with target: grpc://localhost:9003
I tensorflow/core/distributed_runtime/master_session.cc:1004] Start master session 2bd8a136213a1fce with config: gpu_options { per_process_gpu_memory_fraction: 0.2 } allow_soft_placement: true
worker=1,epoch=9,global_step=11085, local_step=5500, loss = 0.6955764889717102
worker=1,epoch=19,global_step=22728, local_step=11000, loss = 0.5891970992088318
worker=1,epoch=29,global_step=39074, local_step=16500, loss = 0.4183048903942108
worker=1,epoch=39,global_step=55599, local_step=22000, loss = 0.32243454456329346
worker=1,epoch=49,global_step=72105, local_step=27500, loss = 0.5384714007377625
worker=1, final accuracy = 0.8866000175476074
```
工作器 3 的輸出:
```py
$ python3 ch-15_mnist_dist_async.py --job_name='worker' --task_index=2
I tensorflow/core/common_runtime/gpu/gpu_device.cc:1030] Found device 0 with properties:
name: Quadro P5000 major: 6 minor: 1 memoryClockRate(GHz): 1.506
pciBusID: 0000:01:00.0
totalMemory: 15.89GiB freeMemory: 15.70GiB
I tensorflow/core/common_runtime/gpu/gpu_device.cc:1120] Creating TensorFlow device (/device:GPU:0) -> (device: 0, name: Quadro P5000, pci bus id: 0000:01:00.0, compute capability: 6.1)
E1213 16:50:35.568349791 27449 ev_epoll1_linux.c:1051] grpc epoll fd: 23
I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize GrpcChannelCache for job ps -> {0 -> localhost:9001}
I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:215] Initialize GrpcChannelCache for job worker -> {0 -> localhost:9002, 1 -> localhost:9003, 2 -> localhost:9004}
I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:324] Started server with target: grpc://The full code for this example is in ch-15_mnist_dist_sync.py. You are encouraged to modify and explore the code with your own datasets.localhost:9004
I tensorflow/core/distributed_runtime/master_session.cc:1004] Start master session cb0749c9f5fc163e with config: gpu_options { per_process_gpu_memory_fraction: 0.2 } allow_soft_placement: true
I tensorflow/core/distributed_runtime/master_session.cc:1004] Start master session 55bf9a2b9718a571 with config: gpu_options { per_process_gpu_memory_fraction: 0.2 } allow_soft_placement: true
worker=2,epoch=9,global_step=37367, local_step=5500, loss = 0.8077645301818848
worker=2,epoch=19,global_step=53859, local_step=11000, loss = 0.26333487033843994
worker=2,epoch=29,global_step=70299, local_step=16500, loss = 0.6506651043891907
worker=2,epoch=39,global_step=76999, local_step=22000, loss = 0.20321622490882874
worker=2,epoch=49,global_step=82499, local_step=27500, loss = 0.4170967936515808
worker=2, final accuracy = 0.8894000053405762
```
我們打印了全局步驟和本地步驟。全局步驟表示所有工作器任務的步數,而本地步驟是該工作器任務中的計數,這就是為什么本地任務計數高達 27,500 并且每個工作器的每個周期都相同,但是因為工作器正在做按照自己的步驟采取全局性措施,全局步驟的數量在周期或工作器之間沒有對稱性或模式。此外,我們發現每個工作器的最終準確率是不同的,因為每個工作器在不同的時間執行最終的準確率,當時有不同的參數。
# 定義并訓練圖以進行同步更新
如前所述,并在此處的圖中描述,在同步更新中,任務將其更新發送到參數服務器,`ps`任務等待接收所有更新,聚合它們,然后更新參數。工作任務在繼續下一次計算參數更新迭代之前等待更新:
此示例的完整代碼位于`ch-15_mnist_dist_sync.py`中。建議您使用自己的數據集修改和瀏覽代碼。
對于同步更新,需要對代碼進行以下修改:
1. 優化器需要包裝在`SyncReplicaOptimizer`中。因此,在定義優化器后,添加以下代碼:
```py
# SYNC: next line added for making it sync update
optimizer = tf.train.SyncReplicasOptimizer(optimizer,
replicas_to_aggregate=len(workers),
total_num_replicas=len(workers),
)
```
1. 之后應該像以前一樣添加訓練操作:
```py
train_op = optimizer.minimize(loss_op,global_step=global_step)
```
1. 接下來,添加特定于同步更新方法的初始化函數定義:
```py
if is_chief:
local_init_op = optimizer.chief_init_op()
else:
local_init_op = optimizer.local_step_init_op()
chief_queue_runner = optimizer.get_chief_queue_runner()
init_token_op = optimizer.get_init_tokens_op()
```
1. 使用兩個額外的初始化函數也可以不同地創建`supervisor`對象:
```py
# SYNC: sv is initialized differently for sync update
sv = tf.train.Supervisor(is_chief=is_chief,
init_op = tf.global_variables_initializer(),
local_init_op = local_init_op,
ready_for_local_init_op = optimizer.ready_for_local_init_op,
global_step=global_step)
```
1. 最后,在訓練的會話塊中,我們初始化同步變量并啟動隊列運行器(如果它是主要的工作者任務):
```py
# SYNC: if block added to make it sync update
if is_chief:
mts.run(init_token_op)
sv.start_queue_runners(mts, [chief_queue_runner])
```
其余代碼與異步更新保持一致。
用于支持分布式訓練的 TensorFlow 庫和函數正在不斷發展。 因此,請注意添加的新函數或函數簽名的更改。 在撰寫本書的時候,我們使用了 TensorFlow 1.4。
# 總結
在本章中,我們學習了如何使用 TensorFlow 集群在多臺機器和設??備上分發模型的訓練。我們還學習了 TensorFlow 代碼分布式執行的模型并行和數據并行策略。
參數更新可以與參數服務器的同步或異步更新共享。我們學習了如何為同步和異步參數更新實現代碼。借助本章中學到的技能,您將能夠構建和訓練具有非常大的數據集的非常大的模型。
在下一章中,我們將學習如何在運行 iOS 和 Android 平臺的移動和嵌入式設備上部署 TensorFlow 模型。
- TensorFlow 1.x 深度學習秘籍
- 零、前言
- 一、TensorFlow 簡介
- 二、回歸
- 三、神經網絡:感知器
- 四、卷積神經網絡
- 五、高級卷積神經網絡
- 六、循環神經網絡
- 七、無監督學習
- 八、自編碼器
- 九、強化學習
- 十、移動計算
- 十一、生成模型和 CapsNet
- 十二、分布式 TensorFlow 和云深度學習
- 十三、AutoML 和學習如何學習(元學習)
- 十四、TensorFlow 處理單元
- 使用 TensorFlow 構建機器學習項目中文版
- 一、探索和轉換數據
- 二、聚類
- 三、線性回歸
- 四、邏輯回歸
- 五、簡單的前饋神經網絡
- 六、卷積神經網絡
- 七、循環神經網絡和 LSTM
- 八、深度神經網絡
- 九、大規模運行模型 -- GPU 和服務
- 十、庫安裝和其他提示
- TensorFlow 深度學習中文第二版
- 一、人工神經網絡
- 二、TensorFlow v1.6 的新功能是什么?
- 三、實現前饋神經網絡
- 四、CNN 實戰
- 五、使用 TensorFlow 實現自編碼器
- 六、RNN 和梯度消失或爆炸問題
- 七、TensorFlow GPU 配置
- 八、TFLearn
- 九、使用協同過濾的電影推薦
- 十、OpenAI Gym
- TensorFlow 深度學習實戰指南中文版
- 一、入門
- 二、深度神經網絡
- 三、卷積神經網絡
- 四、循環神經網絡介紹
- 五、總結
- 精通 TensorFlow 1.x
- 一、TensorFlow 101
- 二、TensorFlow 的高級庫
- 三、Keras 101
- 四、TensorFlow 中的經典機器學習
- 五、TensorFlow 和 Keras 中的神經網絡和 MLP
- 六、TensorFlow 和 Keras 中的 RNN
- 七、TensorFlow 和 Keras 中的用于時間序列數據的 RNN
- 八、TensorFlow 和 Keras 中的用于文本數據的 RNN
- 九、TensorFlow 和 Keras 中的 CNN
- 十、TensorFlow 和 Keras 中的自編碼器
- 十一、TF 服務:生產中的 TensorFlow 模型
- 十二、遷移學習和預訓練模型
- 十三、深度強化學習
- 十四、生成對抗網絡
- 十五、TensorFlow 集群的分布式模型
- 十六、移動和嵌入式平臺上的 TensorFlow 模型
- 十七、R 中的 TensorFlow 和 Keras
- 十八、調試 TensorFlow 模型
- 十九、張量處理單元
- TensorFlow 機器學習秘籍中文第二版
- 一、TensorFlow 入門
- 二、TensorFlow 的方式
- 三、線性回歸
- 四、支持向量機
- 五、最近鄰方法
- 六、神經網絡
- 七、自然語言處理
- 八、卷積神經網絡
- 九、循環神經網絡
- 十、將 TensorFlow 投入生產
- 十一、更多 TensorFlow
- 與 TensorFlow 的初次接觸
- 前言
- 1.?TensorFlow 基礎知識
- 2. TensorFlow 中的線性回歸
- 3. TensorFlow 中的聚類
- 4. TensorFlow 中的單層神經網絡
- 5. TensorFlow 中的多層神經網絡
- 6. 并行
- 后記
- TensorFlow 學習指南
- 一、基礎
- 二、線性模型
- 三、學習
- 四、分布式
- TensorFlow Rager 教程
- 一、如何使用 TensorFlow Eager 構建簡單的神經網絡
- 二、在 Eager 模式中使用指標
- 三、如何保存和恢復訓練模型
- 四、文本序列到 TFRecords
- 五、如何將原始圖片數據轉換為 TFRecords
- 六、如何使用 TensorFlow Eager 從 TFRecords 批量讀取數據
- 七、使用 TensorFlow Eager 構建用于情感識別的卷積神經網絡(CNN)
- 八、用于 TensorFlow Eager 序列分類的動態循壞神經網絡
- 九、用于 TensorFlow Eager 時間序列回歸的遞歸神經網絡
- TensorFlow 高效編程
- 圖嵌入綜述:問題,技術與應用
- 一、引言
- 三、圖嵌入的問題設定
- 四、圖嵌入技術
- 基于邊重構的優化問題
- 應用
- 基于深度學習的推薦系統:綜述和新視角
- 引言
- 基于深度學習的推薦:最先進的技術
- 基于卷積神經網絡的推薦
- 關于卷積神經網絡我們理解了什么
- 第1章概論
- 第2章多層網絡
- 2.1.4生成對抗網絡
- 2.2.1最近ConvNets演變中的關鍵架構
- 2.2.2走向ConvNet不變性
- 2.3時空卷積網絡
- 第3章了解ConvNets構建塊
- 3.2整改
- 3.3規范化
- 3.4匯集
- 第四章現狀
- 4.2打開問題
- 參考
- 機器學習超級復習筆記
- Python 遷移學習實用指南
- 零、前言
- 一、機器學習基礎
- 二、深度學習基礎
- 三、了解深度學習架構
- 四、遷移學習基礎
- 五、釋放遷移學習的力量
- 六、圖像識別與分類
- 七、文本文件分類
- 八、音頻事件識別與分類
- 九、DeepDream
- 十、自動圖像字幕生成器
- 十一、圖像著色
- 面向計算機視覺的深度學習
- 零、前言
- 一、入門
- 二、圖像分類
- 三、圖像檢索
- 四、對象檢測
- 五、語義分割
- 六、相似性學習
- 七、圖像字幕
- 八、生成模型
- 九、視頻分類
- 十、部署
- 深度學習快速參考
- 零、前言
- 一、深度學習的基礎
- 二、使用深度學習解決回歸問題
- 三、使用 TensorBoard 監控網絡訓練
- 四、使用深度學習解決二分類問題
- 五、使用 Keras 解決多分類問題
- 六、超參數優化
- 七、從頭開始訓練 CNN
- 八、將預訓練的 CNN 用于遷移學習
- 九、從頭開始訓練 RNN
- 十、使用詞嵌入從頭開始訓練 LSTM
- 十一、訓練 Seq2Seq 模型
- 十二、深度強化學習
- 十三、生成對抗網絡
- TensorFlow 2.0 快速入門指南
- 零、前言
- 第 1 部分:TensorFlow 2.00 Alpha 簡介
- 一、TensorFlow 2 簡介
- 二、Keras:TensorFlow 2 的高級 API
- 三、TensorFlow 2 和 ANN 技術
- 第 2 部分:TensorFlow 2.00 Alpha 中的監督和無監督學習
- 四、TensorFlow 2 和監督機器學習
- 五、TensorFlow 2 和無監督學習
- 第 3 部分:TensorFlow 2.00 Alpha 的神經網絡應用
- 六、使用 TensorFlow 2 識別圖像
- 七、TensorFlow 2 和神經風格遷移
- 八、TensorFlow 2 和循環神經網絡
- 九、TensorFlow 估計器和 TensorFlow HUB
- 十、從 tf1.12 轉換為 tf2
- TensorFlow 入門
- 零、前言
- 一、TensorFlow 基本概念
- 二、TensorFlow 數學運算
- 三、機器學習入門
- 四、神經網絡簡介
- 五、深度學習
- 六、TensorFlow GPU 編程和服務
- TensorFlow 卷積神經網絡實用指南
- 零、前言
- 一、TensorFlow 的設置和介紹
- 二、深度學習和卷積神經網絡
- 三、TensorFlow 中的圖像分類
- 四、目標檢測與分割
- 五、VGG,Inception,ResNet 和 MobileNets
- 六、自編碼器,變分自編碼器和生成對抗網絡
- 七、遷移學習
- 八、機器學習最佳實踐和故障排除
- 九、大規模訓練
- 十、參考文獻