
# 十一、圖像著色
顏色是大自然的笑容。
——雷·亨特
直到 1840 年代,世界都是以黑白捕獲。 加布里埃爾·利普曼(Gabriel Lippmann)于 1908 年獲得諾貝爾物理學獎,從而開始了色彩捕捉的時代。 1935 年,伊士曼·柯達(Eastman Kodak)推出了一體式三重彩色膠卷,稱為 *Kodachrome*,用于拍攝彩色照片。
彩色圖像不僅與美學和美感有關,而且比黑白圖像捕獲的信息要多得多。 顏色是現實世界對象的重要屬性,它為我們對周圍世界的感知增加了另一個維度。 色彩的重要性是如此之大,以至于有許多項目為整個歷史上的藝術作品和攝影作品著色。 隨著 Adobe Photoshop 和 GIMP 等工具的出現,人們一直在努力地將舊照片轉換為彩色照片。 reddit r / Colorization 子組是一個在線社區,人們在這里分享經驗并致力于將黑白圖像轉換為彩色圖像。
到目前為止,在本書中,我們涵蓋了不同的領域和場景,以展示遷移學習的驚人好處。 在本章中,我們將介紹使用深度學習進行圖像著色的概念,并利用遷移學習來改善結果。 本章將涵蓋以下主題:
* 問題陳述
* 了解圖像著色
* 彩色圖像
* 建立基于深度神經網絡的著色網絡
* 改進之處
* 挑戰
在接下來的部分中,我們將使用術語黑白,單色和灰度來表示沒有任何顏色信息的圖像。 我們將這些術語互換使用。
# 問題陳述
照片可以幫助我們及時保存事件。 它們不僅幫助我們重溫記憶,還提供對過去重要事件的見解。 在彩色攝影成為主流之前,我們的攝影歷史是用黑白拍攝的。 圖像著色的任務是將給定的灰度圖像轉換為合理的顏色版本。
圖像著色的任務可以從不同的角度進行。 手動過程非常耗時,[并且需要出色的技能](https://www.reddit.com/r/Colorization/)。 計算機視覺和深度學習領域的研究人員一直在研究使過程自動化的不同方法。 通過本章,我們將努力理解如何將深層神經網絡用于此類任務。 我們還將嘗試利用遷移學習的力量來改善結果。
我們鼓勵讀者在繼續進行之前,先對問題陳述進行思考。 考慮一下您將如何處理這樣的任務。 在深入探討該解決方案之前,讓我們獲取有關彩色圖像和相關概念的一些信息。 下一節涵蓋了處理當前任務所需的基本概念。
# 彩色圖像
不到 100 年前,單色捕獲是一個限制,而不是一種選擇。 數碼和移動攝影的出現使黑白圖像或灰度圖像成為一種藝術選擇。 當然,這樣的圖像具有戲劇性的效果,但是黑白圖像不僅僅是改變捕獲設備(無論是數碼相機還是電話)上的選項。
我們對顏色和正式顏色模型的了解早于彩色圖像。 托馬斯·楊(Thomas Young)在 1802 年提出了三種類型的感光器或視錐細胞的存在(如下圖所示)。 他的理論詳述了這三個視錐細胞中的每一個僅對特定范圍的可見光敏感。 進一步發展了該理論,將這些視錐細胞分為短,中和長三種,分別優選藍色,綠色和紅色:
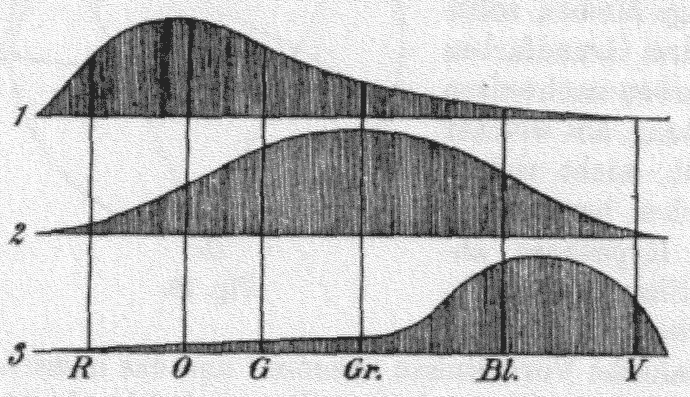
托馬斯·楊(Thomas Young)和赫爾曼·赫爾姆霍爾茨(Hermann Helmholtz):[三錐細胞理論](https://en.wikipedia.org/wiki/Color_space#/media/File:YoungHelm.jpg)
我們對顏色的理解以及對顏色的理解方式的進步導致了顏色理論的形式化。 由于色彩理論本身是一個完整的領域,因此在本章中,我們將對其進行簡要介紹。 關于這些主題的詳細討論超出了本書的范圍。
# 色彩理論
簡單來說,色彩理論是用于指導色彩感知,混合,匹配和復制方法的正式框架。 多年來,已經進行了各種嘗試來基于色輪,原色,第二色等正式定義顏色。 因此,顏色理論是一個廣闊的領域,在此之下,我們可以正式定義與色度,色相,配方等顏色相關的屬性。
# 色彩模型和色彩空間
顏色模型是顏色理論到顏色表示的表述。 顏色模型是一種抽象的數學概念,當與它的組成的精確理解相關聯時,被稱為**顏色空間**。 大多數顏色模型都用表示特定顏色成分的三到四個數字的元組表示。
# RGB
托馬斯·楊(Thomas Young)三錐理論**紅色綠色藍色**(**RGB**)的延續,是最古老,使用最廣泛的顏色模型和顏色空間之一。 RGB 是加色模型。 在此模型中,以不同的濃度添加了光的三個分量(紅色,綠色和藍色),以實現可見光的完整光譜。 附加色空間如下圖所示:
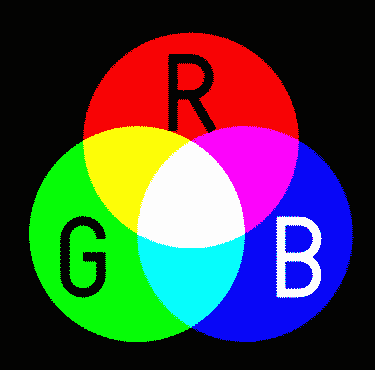
RGB 顏色空間([來源:英語 Wikipedia 的 SharkD。更高版本由 Jacobolus 上傳,已從 wikipedia en 轉移到 Public Commons 域](https://commons.wikimedia.org/w/index.php?curid=2529435))
每種成分的零強度會導致黑色,而全強度會導致對白色的感覺。 盡管簡單,但此顏色模型和顏色空間構成了大多數電子顯示器(包括 CRT,LCD 和 LED)的基礎。
# YUV
`Y`代表**亮度**,而`U`和`V`通道代表**色度**。 該編碼方案在視頻系統中被廣泛使用以映射人類的顏色感知。 紫外線通道主要幫助確定紅色和藍色的相對含量。 由于該方案使用較低的帶寬并且不易出現傳輸錯誤的能力,因此被廣泛使用,如下所示:
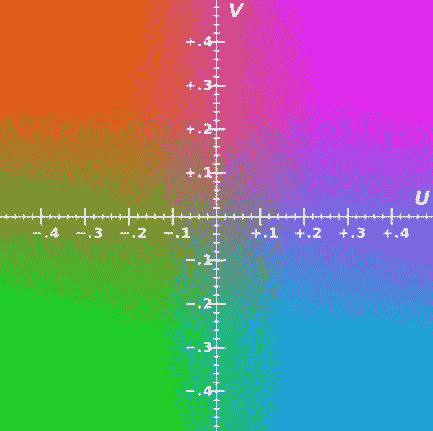
YUV 色彩空間([來源:Tonyle](https://commons.wikimedia.org/w/index.php?curid=6977944),本人著作,CC BY-SA 3.0)
此圖像是 UV 顏色通道在 0.5 Y 處的樣本表示。
# LAB
這種與設備無關的色彩空間參考是由國際照明委員會開發的。 `L`通道表示顏色的亮度(0 為黑色,而 100 為漫射白色)。
`A`表示綠色和品紅色之間的位置,而`B`表示藍色和黃色之間的位置,如下所示:
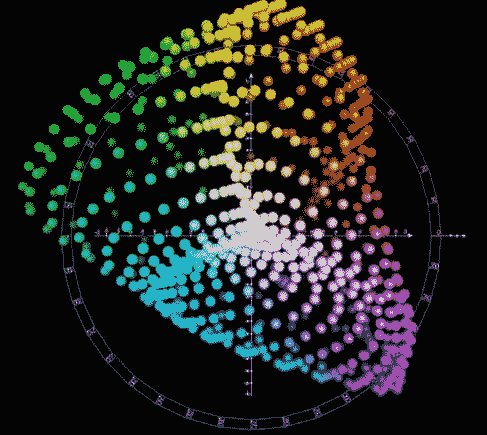
LAB 色彩空間([來源:Holger kkk Everding](https://commons.wikimedia.org/w/index.php?curid=38366968),自己的作品,CC BY-SA 4.0)
除了這三種以外,還存在其他各種顏色模型。 出于當前有關圖像著色的用例的目的,我們將采用一種非常有趣的方法。
# 重新陳述問題
如果我們遵循使用最廣泛的顏色模型 RGB,那么事實證明,訓練模型以將輸入的單色圖像映射到顏色將是一項艱巨的任務。
深度學習領域的研究人員在解決和提出問題方面頗具創造力。 在圖像著色的情況下,研究人員巧妙地研究了利用不同輸入來實現灰度圖像逼真的幻覺的方法。
在最初的嘗試中,參考圖像和顏色涂鴉形式的顏色引導輸入的不同變體被用來產生巨大的效果。 請參閱威爾士和合著者以及萊文和合著者。
最近的工作集中在利用深層 CNN 中的遷移學習使整個過程自動化。 結果令人鼓舞,有時甚至足以愚弄人類。
最近的工作,以及遷移學習的力量,已經巧妙地嘗試利用包含灰度通道作為其組成部分之一的顏色模型。 那會響嗎? 現在讓我們從另一個角度看問題陳述。
除了無所不在的 RGB 顏色空間外,我們還討論了 LAB。 LAB 色彩空間包含灰度值,因為`L`通道(用于亮度),而其余兩個通道(`a`和`b`)賦予顏色屬性。 因此,著色問題可以用以下數學方式建模:

在上述方程式中,我們表示從給定數據將`L`通道映射到同一圖像的`a`和`b`通道的函數。 下圖說明了這一點:
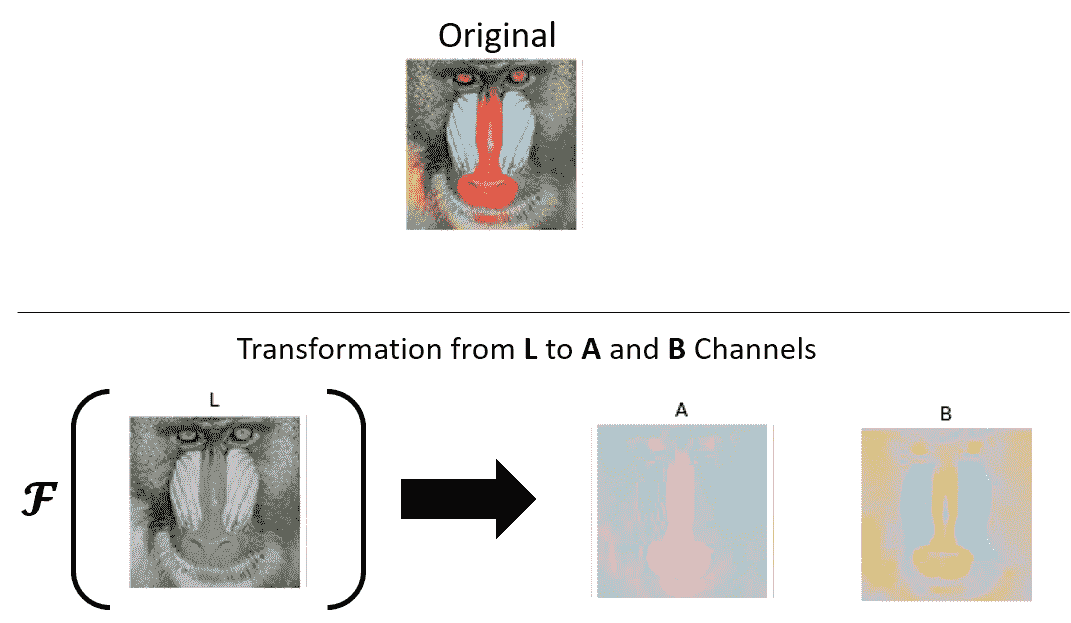
colornet 轉換
簡而言之,我們已經將圖像著色的任務轉換為將一個通道(灰度`L`通道)轉換為兩個顏色通道(`A`和`B`)的任務 ,說明如下:

彩色圖像及其組件 -- RGB,YUV 和 LAB
前面的圖像顯示了彩色圖像的`L`,`A`和`B`通道,基于 [Zhang 及其合著者(2016)和 Federico 及其合著者(2017)](https://arxiv.org/abs/1603.08511)的作品。 我們將在接下來的部分中詳細研究它們。
我們鼓勵讀者閱讀標題為[《Deep Koalarization:使用 CNN 和 Inception-ResNet-v2 進行圖像著色》](https://arxiv.org/abs/1712.03400)的論文。 我們要感謝 Federico Baldassarre,Diego Gonzalez-Morin 和 Lucas Rodes-Guirao 為他們的工作及其實現提供了詳細的信息和見解。 我們還要感謝 Emil Wallner 使用 Keras 出色地實現了本文。
讀者應注意,類似的過程也可以應用于 YUV 色彩空間。 [Jeff Hwang 和他的合著者在題為《利用深度卷積神經網絡進行圖像著色》的論文中討論了利用這種色彩空間的嘗試,效果也很好](http://cs231n.stanford.edu/reports/2016/pdfs/219_Report.pdf)。
# 建立著色深層神經網絡
現在是時候構建著色深層神經網絡或色網。 如前一節所述,如果我們使用替代顏色空間,例如 LAB(或 YUV),則可以將著色任務轉換為數學轉換。 轉換如下:

數學公式和創造力很好,但是學習這些轉換的圖像在哪里呢? 深度學習網絡需要大量數據,但幸運的是,我們有來自各種開源數據集的大量不同圖像的集合。 在本章中,我們將依賴于 ImageNet 本身的一些示例圖像。 由于 ImageNet 是一個龐大的數據集,因此我們為問題陳述隨機選擇了一些彩色圖像。 在后面的部分中,我們將討論為什么選擇此子集及其一些細微差別。
我們依靠 Baldassarre 及其合作者開發的圖像提取工具,用于[《Deep Koalarization:使用 CNN 和 Inception-ResNet-v2 進行圖像著色》](https://arxiv.org/abs/1712.03400)的論文,來整理本章中使用的 ImageNet 樣本的子集。 可以在[這個頁面](https://github.com/baldassarreFe/deep-koalarization/tree/master/dataset)上獲取數據提取的代碼。
本書的 GitHub 存儲庫中提供了本章使用的代碼和示例圖像以及`colornet_vgg16.ipynb`筆記本。
# 預處理
獲取/整理所需數據集后的第一步是預處理。 對于當前的圖像著色任務,我們需要執行以下預處理步驟:
* **重新縮放**:ImageNet 是一個具有各種圖像的多樣化數據集,包括類和大小(尺寸)。 為了實現此目的,我們將所有圖像重新縮放為固定大小。
* **利用 24 位 RGB**:由于人眼只能區分 2 和 1000 萬種顏色,因此我們可以利用 24 位 RGB 來近似 1600 萬種顏色。 減少每個通道的位數將有助于我們以更少的資源更快地訓練模型。 這可以通過簡單地將像素值除以 255 來實現。
* **RGB 到 LAB**:由于在 LAB 色彩空間中更容易解決圖像著色問題,因此我們將利用 skimage 來轉換和提取 RGB 圖像中的 LAB 通道。
# 標準化
LAB 顏色空間的值介于 -128 至 +128 之間。 由于神經網絡對輸入值的大小敏感,因此我們將從-128 到+128 的變換后的像素值歸一化,并將它們置于 -1 到 +1 范圍內。 以下代碼片段中展示了相同的內容:
```py
def prep_data(file_list=[],
dir_path=None,
dim_x=256,
dim_y=256):
#Get images
X = []
for filename in file_list:
X.append(img_to_array(
sp.misc.imresize(
load_img(
dir_path+filename),
(dim_x, dim_y))
)
)
X = np.array(X, dtype=np.float64)
X = 1.0/255*X
return X
```
轉換后,我們將數據分為訓練集和測試集。 對于拆分,我們使用了 sklearn 的`train_test_split utility`。
# 損失函數
模型是通過改善損失函數或目標函數來學習的。 任務是使用反向傳播學習最佳參數,以最小化原始彩色圖像和模型輸出之間的差異。 來自模型的輸出彩色圖像也稱為灰度圖像的幻覺著色。 在此實現中,我們將**均方誤差**(**MSE**)用作損失函數。 以下等式對此進行了總結:
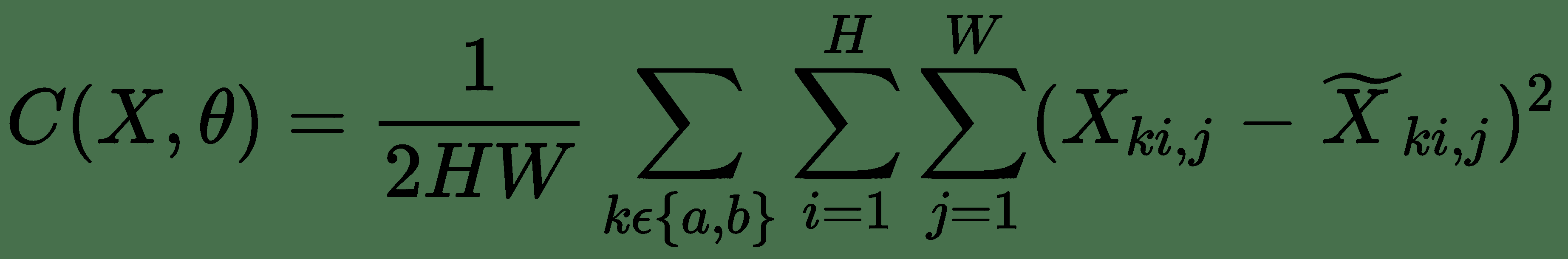
原始顏色和色網輸出之間的損失函數(來源:Baldassarre 和合著者)
對于 Keras,使用此損失函數就像在編譯 Keras 模型時設置參數一樣容易。 我們利用 RMSprop 優化器來訓練我們的模型(本文使用 Adam 代替)。
# 編碼器
**卷積神經網絡**(**CNN**)是令人驚嘆的圖像分類器。 他們通過提取位置不變特征來實現。 在此過程中,它們傾向于使輸入圖像失真。
在圖像著色的情況下,這種失真將是災難性的。 為此,我們使用編碼器將`H x W`尺寸的輸入灰度圖像轉換為`H / 8 x W / 8`。 編碼器通過使用零填充來保持圖像通過不同層的縱橫比。 以下代碼片段顯示了使用 Keras 的編碼器:
```py
#Encoder
enc_input = Input(shape=(DIM, DIM, 1,))
enc_output = Conv2D(64, (3,3),
activation='relu',
padding='same', strides=2)(enc_input)
enc_output = Conv2D(128, (3,3),
activation='relu',
padding='same')(enc_output)
enc_output = Conv2D(128, (3,3),
activation='relu',
padding='same', strides=2)(enc_output)
```
```py
enc_output = Conv2D(256, (3,3),
activation='relu',
padding='same')(enc_output)
enc_output = Conv2D(256, (3,3),
activation='relu',
padding='same', strides=2)(enc_output)
enc_output = Conv2D(512, (3,3),
activation='relu',
padding='same')(enc_output)
enc_output = Conv2D(512, (3,3),
activation='relu',
padding='same')(enc_output)
enc_output = Conv2D(256, (3,3),
activation='relu',
padding='same')(enc_output)
```
在前面的代碼片段中,有趣的方面是對第 1 層,第 3 層和第 5 層使用了 2 的步幅大小。2 的步幅長度將圖像尺寸減半,但仍設法保持了縱橫比。 這有助于增加信息密度而不會扭曲原始圖像。
# 遷移學習 – 特征提取
本章討論的圖像著色網絡是一個非常獨特的網絡。 它的獨特性來自我們使用遷移學習來增強模型的方式。 我們知道可以將預訓練的網絡用作特征提取器,以幫助遷移學習的模式并提高模型的表現。
在這種當前設置下,我們利用預訓練的 VGG16(本文指的是利用預訓練的 Inception 模型)進行遷移學習。 由于 VGG16 需要以特定格式輸入,因此我們通過調整輸入圖像的大小并將其連接 3 次以補償丟失的通道信息,來轉換輸入的灰度圖像(輸入到網絡編碼器部分的相同灰度圖像)。
以下代碼段獲取輸入的灰度圖像并生成所需的嵌入:
```py
#Create embedding
def create_vgg_embedding(grayscaled_rgb):
gs_rgb_resized = []
for i in grayscaled_rgb:
i = resize(i, (224, 224, 3),
mode='constant')
gs_rgb_resized.append(i)
gs_rgb_resized = np.array(gs_rgb_resized)
gs_rgb_resized = preprocess_input(gs_rgb_resized)
with vgg16.graph.as_default():
embedding = vgg16.predict(gs_rgb_resized)
return embedding
```
前面的代碼段生成大小為`1,000 x 1 x 1`的輸出特征向量。
# 融合層
我們在前幾章中構建的大多數網絡都使用了 Keras 的順序 API。 融合層是在這種情況下利用遷移學習的創新方式。 請記住,我們已將輸入灰度圖像用作兩個不同網絡(一個編碼器和一個預訓練的 VGG16)的輸入。 由于兩個網絡的輸出具有不同的形狀,因此我們將 VGG16 的輸出重復 1,000 次,然后將其與編碼器輸出連接或合并。 以下代碼段準備了融合層:
```py
#Fusion
fusion_layer_output = RepeatVector(32*32)(emd_input)
fusion_layer_output = Reshape(([32,32,
1000]))(fusion_layer_output)
fusion_layer_output = concatenate([enc_output,
fusion_layer_output], axis=3)
fusion_layer_output = Conv2D(DIM, (1, 1),
activation='relu',
padding='same')(fusion_layer_output)
```
VGG16 的輸出重復沿編碼器輸出的深度軸連接。 這樣可以確保從 VGG16 中提取的圖像特征嵌入均勻地分布在整個圖像中:
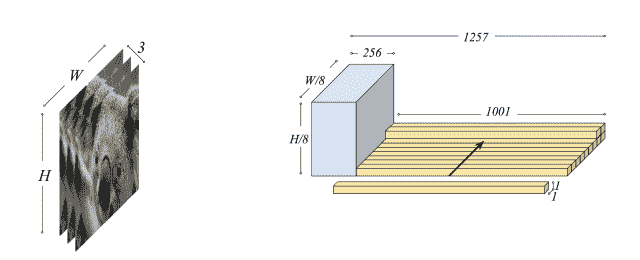
級聯灰度輸入預訓練網絡(左),融合層(右)
來源:Baldassarre 等
上圖顯示了特征提取器或預訓練的 VGG16 的輸入以及融合層的結構。
# 解碼器
網絡的最后階段是解碼器。 在網絡的前兩個部分中,我們利用編碼器和預訓練模型來學習不同的特征并生成嵌入。 融合層的輸出為張量,大小為`H / 8 x W / 8 x 256`,其中`H`和`W`是灰度圖像的原始高度和寬度(在我們的情況是`256 x 256`)。 該輸入經過一個八層解碼器,該解碼器使用五個卷積層和三個上采樣層構建。 上采樣層可幫助我們使用基本的最近鄰方法將圖像大小增加一倍。 以下代碼片段展示了網絡的解碼器部分:
```py
#Decoder
dec_output = Conv2D(128, (3,3),
activation='relu',
padding='same')(fusion_layer_output)
dec_output = UpSampling2D((2, 2))(dec_output)
dec_output = Conv2D(64, (3,3),
activation='relu',
padding='same')(dec_output)
dec_output = UpSampling2D((2, 2))(dec_output)
dec_output = Conv2D(32, (3,3),
activation='relu',
padding='same')(dec_output)
dec_output = Conv2D(16, (3,3),
activation='relu',
padding='same')(dec_output)
dec_output = Conv2D(2, (3, 3),
activation='tanh',
padding='same')(dec_output)
dec_output = UpSampling2D((2, 2))(dec_output)
```
解碼器網絡的輸出是具有兩個通道的原始大小的圖像,即,輸出是形狀為`H x W x 2`的張量。 最終的卷積層使用 tanh 激活函數將預測像素值保持在 -1 到 +1 范圍內。
下圖顯示了具有三個組成部分的網絡:
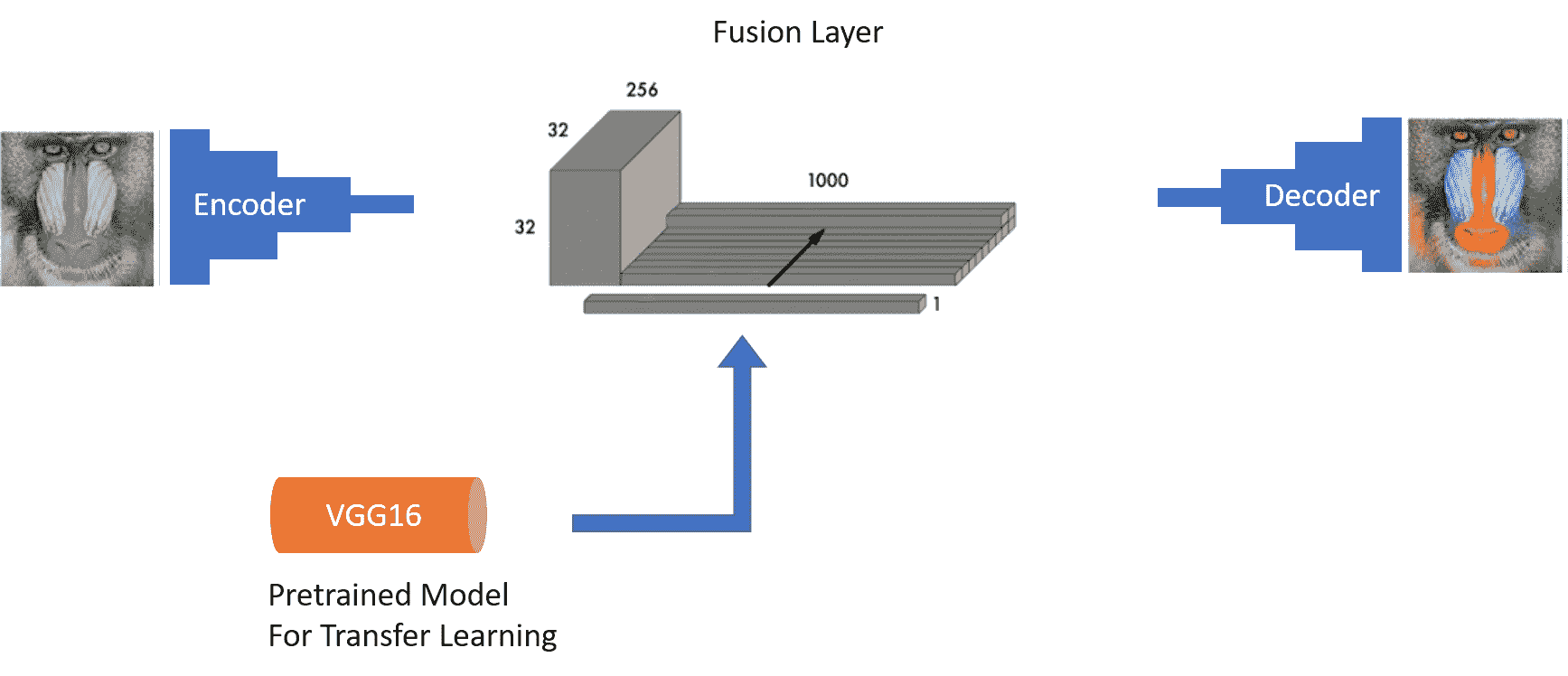
Colornet 由編碼器,作為特征提取器的預訓練模型,融合層和解碼器組成
使用 Keras 構建的深度學習模型通常是使用順序 API 構建的。 在這種情況下,我們的著色網絡(即 colornet)利用函數式 API 來實現融合層。
# 后處理
解決問題的技巧還沒有結束。 如“預處理”小節中所述,我們將 -1 到 +1 之間的像素值標準化,以確保我們的網絡正確訓練。 同樣,兩個顏色通道的 LAB 顏色空間的值在 -128 到 +128 之間。 因此,執行以下兩個后處理步驟:
* 我們將每個像素值乘以 128,以將值帶入所需的顏色通道范圍
* 我們將灰度輸入圖像與輸出兩通道圖像連接起來,以獲得幻覺的彩色圖像
以下代碼段執行后處理步驟,以產生幻覺的彩色圖像:
```py
sample_img = []
for filename in test_files:
sample_img.append(sp.misc.imresize(load_img(IMG_DIR+filename),
(DIM, DIM)))
sample_img = np.array(sample_img,
dtype=float)
sample_img = 1.0/255*sample_img
sample_img = gray2rgb(rgb2gray(sample_img))
sample_img = rgb2lab(sample_img)[:,:,:,0]
sample_img = sample_img.reshape(sample_img.shape+(1,))
#embedding input
sample_img_embed = create_vgg_embedding(sample_img)
```
如前面的代碼片段所示,我們使用 skimage 中的`lab2rgb`工具將生成的輸出轉換為 RGB 顏色空間。 這樣做是為了便于可視化輸出圖像。
# 訓練與結果
訓練如此復雜的網絡可能很棘手。 在本章中,我們從 ImageNet 中選擇了一小部分圖像。 為了幫助我們的網絡學習和推廣,我們使用 Keras 的`ImageDataGenerator`類來擴充數據集并在輸入數據集中產生變化。 以下代碼片段展示了圖像增強和模型訓練:
```py
# Image transformer
datagen = ImageDataGenerator(
shear_range=0.2,
zoom_range=0.2,
rotation_range=20,
horizontal_flip=True)
def colornet_img_generator(X,
batch_size=BATCH_SIZE):
for batch in datagen.flow(X, batch_size=batch_size):
gs_rgb = gray2rgb(rgb2gray(batch))
batch_lab = rgb2lab(batch)
batch_l = batch_lab[:,:,:,0]
batch_l = batch_l.reshape(batch_l.shape+(1,))
batch_ab = batch_lab[:,:,:,1:] / 128
yield ([batch_l,
create_vgg_embedding(gs_rgb)], batch_ab)
history = model.fit_generator(colornet_img_generator(X_train,
BATCH_SIZE),
epochs=EPOCH,
steps_per_epoch=STEPS_PER_EPOCH)
```
在著色網絡的情況下,這種損失可能會產生誤導。 它似乎已穩定在 100 個周期以下,但所產生的結果更多是烏賊色而不是顏色。 因此,我們做了更多的實驗以達到以下結果:

Colornet 輸出:第一列代表灰度輸入,第二列代表模型輸出,第三列代表原始圖像
前面的結果雖然不令人吃驚,但令人鼓舞。 通過對模型進行 600 個周期的訓練,批次大小為 64,可以實現上述結果。
# 挑戰
深度神經網絡是功能強大的模型,具有成千上萬個可學習的參數。 當前訓練著色網絡的方案提出了一系列新的挑戰,其中一些挑戰如下:
* 當前的網絡似乎已經學習了高級特征,例如草地和運動球衣(在一定程度上),而它發現學習較小物體的顏色模式有些困難。
* 訓練集僅限于非常具體的圖像子集,因此反映在測試數據集中。 該模型對訓練集中不存在的對象或包含這些對象的樣本不多的表現不佳。
* 即使訓練損失似乎已穩定在 50 個周期以下,但我們看到,除非進行數百個周期訓練,否則該模型的著色表現相當差。
* 該模型很容易將大多數對象著色為灰色或棕褐色。 在訓練了較少周期的模型中觀察到了這一點。
除了這些挑戰之外,對于如此復雜的架構,計算和內存要求也很高。
# 進一步改進
當前的實現盡管顯示出令人鼓舞的結果,但是可以進一步調整。 通過利用更大,更多樣化的數據集可以實現進一步的改進。
也可以通過使用功能更強大的最新預訓練圖像分類模型(例如 InceptionV3 或 InceptionResNetV2)來進行改進。
我們還可以通過準備由更復雜的架構組成的集成網絡來利用 Keras 的函數式 API。 接下來的步驟之一可能是向網絡提供時間信息,并查看是否還可以學習為視頻著色。
# 總結
圖像著色是深度學習領域的前沿主題之一。 隨著我們對遷移學習和深度學習的理解日趨成熟,應用范圍變得越來越令人興奮且更具創造力。 圖像著色是研究的活躍領域,最近,深度學習專家分享了一些激動人心的工作。
在本章中,我們學習了顏色理論,不同的顏色模型和顏色空間。 這種理解幫助我們將問題陳述重新表述為從單通道灰度圖像到兩通道輸出的映射。 然后,我們根據 Baldassarre 和他的合著者的作品,著手建立一個色網。 該實現涉及一個獨特的三層網絡,該網絡由編碼器,解碼器和融合層組成。 融合層使我們能夠通過將 VGG16 嵌入與編碼器輸出連接來利用遷移學習。 網絡需要一些特定的預處理和后處理步驟來訓練給定的圖像集。 我們的訓練和測試數據集由 ImageNet 樣本的子集組成。 我們對色網進行了數百次訓練。 最后,我們提供了一些幻影圖像,以了解該模型對著色任務的學習程度。 訓練有素的色網學習了某些高級對象,例如草,但在較小或較不頻繁的對象上表現不佳。 我們還討論了這種類型的網絡帶來的一些挑戰。
這結束了本書中由用例驅動的系列文章中的最后一章。 我們介紹了跨不同領域的不同用例。 每個用例都幫助我們利用了遷移學習的概念,本書的前兩部分對此進行了詳細討論。 機器學習和深度學習領域的領先人物之一 Andrew Ng 在他的 NIPS 2016 教程中表示:
*遷移學習將成為機器學習商業成功的下一個推動力。*
在本書中討論和展示了各種應用及其優勢之后,您現在應該了解遷移學習的巨大潛力。
- TensorFlow 1.x 深度學習秘籍
- 零、前言
- 一、TensorFlow 簡介
- 二、回歸
- 三、神經網絡:感知器
- 四、卷積神經網絡
- 五、高級卷積神經網絡
- 六、循環神經網絡
- 七、無監督學習
- 八、自編碼器
- 九、強化學習
- 十、移動計算
- 十一、生成模型和 CapsNet
- 十二、分布式 TensorFlow 和云深度學習
- 十三、AutoML 和學習如何學習(元學習)
- 十四、TensorFlow 處理單元
- 使用 TensorFlow 構建機器學習項目中文版
- 一、探索和轉換數據
- 二、聚類
- 三、線性回歸
- 四、邏輯回歸
- 五、簡單的前饋神經網絡
- 六、卷積神經網絡
- 七、循環神經網絡和 LSTM
- 八、深度神經網絡
- 九、大規模運行模型 -- GPU 和服務
- 十、庫安裝和其他提示
- TensorFlow 深度學習中文第二版
- 一、人工神經網絡
- 二、TensorFlow v1.6 的新功能是什么?
- 三、實現前饋神經網絡
- 四、CNN 實戰
- 五、使用 TensorFlow 實現自編碼器
- 六、RNN 和梯度消失或爆炸問題
- 七、TensorFlow GPU 配置
- 八、TFLearn
- 九、使用協同過濾的電影推薦
- 十、OpenAI Gym
- TensorFlow 深度學習實戰指南中文版
- 一、入門
- 二、深度神經網絡
- 三、卷積神經網絡
- 四、循環神經網絡介紹
- 五、總結
- 精通 TensorFlow 1.x
- 一、TensorFlow 101
- 二、TensorFlow 的高級庫
- 三、Keras 101
- 四、TensorFlow 中的經典機器學習
- 五、TensorFlow 和 Keras 中的神經網絡和 MLP
- 六、TensorFlow 和 Keras 中的 RNN
- 七、TensorFlow 和 Keras 中的用于時間序列數據的 RNN
- 八、TensorFlow 和 Keras 中的用于文本數據的 RNN
- 九、TensorFlow 和 Keras 中的 CNN
- 十、TensorFlow 和 Keras 中的自編碼器
- 十一、TF 服務:生產中的 TensorFlow 模型
- 十二、遷移學習和預訓練模型
- 十三、深度強化學習
- 十四、生成對抗網絡
- 十五、TensorFlow 集群的分布式模型
- 十六、移動和嵌入式平臺上的 TensorFlow 模型
- 十七、R 中的 TensorFlow 和 Keras
- 十八、調試 TensorFlow 模型
- 十九、張量處理單元
- TensorFlow 機器學習秘籍中文第二版
- 一、TensorFlow 入門
- 二、TensorFlow 的方式
- 三、線性回歸
- 四、支持向量機
- 五、最近鄰方法
- 六、神經網絡
- 七、自然語言處理
- 八、卷積神經網絡
- 九、循環神經網絡
- 十、將 TensorFlow 投入生產
- 十一、更多 TensorFlow
- 與 TensorFlow 的初次接觸
- 前言
- 1.?TensorFlow 基礎知識
- 2. TensorFlow 中的線性回歸
- 3. TensorFlow 中的聚類
- 4. TensorFlow 中的單層神經網絡
- 5. TensorFlow 中的多層神經網絡
- 6. 并行
- 后記
- TensorFlow 學習指南
- 一、基礎
- 二、線性模型
- 三、學習
- 四、分布式
- TensorFlow Rager 教程
- 一、如何使用 TensorFlow Eager 構建簡單的神經網絡
- 二、在 Eager 模式中使用指標
- 三、如何保存和恢復訓練模型
- 四、文本序列到 TFRecords
- 五、如何將原始圖片數據轉換為 TFRecords
- 六、如何使用 TensorFlow Eager 從 TFRecords 批量讀取數據
- 七、使用 TensorFlow Eager 構建用于情感識別的卷積神經網絡(CNN)
- 八、用于 TensorFlow Eager 序列分類的動態循壞神經網絡
- 九、用于 TensorFlow Eager 時間序列回歸的遞歸神經網絡
- TensorFlow 高效編程
- 圖嵌入綜述:問題,技術與應用
- 一、引言
- 三、圖嵌入的問題設定
- 四、圖嵌入技術
- 基于邊重構的優化問題
- 應用
- 基于深度學習的推薦系統:綜述和新視角
- 引言
- 基于深度學習的推薦:最先進的技術
- 基于卷積神經網絡的推薦
- 關于卷積神經網絡我們理解了什么
- 第1章概論
- 第2章多層網絡
- 2.1.4生成對抗網絡
- 2.2.1最近ConvNets演變中的關鍵架構
- 2.2.2走向ConvNet不變性
- 2.3時空卷積網絡
- 第3章了解ConvNets構建塊
- 3.2整改
- 3.3規范化
- 3.4匯集
- 第四章現狀
- 4.2打開問題
- 參考
- 機器學習超級復習筆記
- Python 遷移學習實用指南
- 零、前言
- 一、機器學習基礎
- 二、深度學習基礎
- 三、了解深度學習架構
- 四、遷移學習基礎
- 五、釋放遷移學習的力量
- 六、圖像識別與分類
- 七、文本文件分類
- 八、音頻事件識別與分類
- 九、DeepDream
- 十、自動圖像字幕生成器
- 十一、圖像著色
- 面向計算機視覺的深度學習
- 零、前言
- 一、入門
- 二、圖像分類
- 三、圖像檢索
- 四、對象檢測
- 五、語義分割
- 六、相似性學習
- 七、圖像字幕
- 八、生成模型
- 九、視頻分類
- 十、部署
- 深度學習快速參考
- 零、前言
- 一、深度學習的基礎
- 二、使用深度學習解決回歸問題
- 三、使用 TensorBoard 監控網絡訓練
- 四、使用深度學習解決二分類問題
- 五、使用 Keras 解決多分類問題
- 六、超參數優化
- 七、從頭開始訓練 CNN
- 八、將預訓練的 CNN 用于遷移學習
- 九、從頭開始訓練 RNN
- 十、使用詞嵌入從頭開始訓練 LSTM
- 十一、訓練 Seq2Seq 模型
- 十二、深度強化學習
- 十三、生成對抗網絡
- TensorFlow 2.0 快速入門指南
- 零、前言
- 第 1 部分:TensorFlow 2.00 Alpha 簡介
- 一、TensorFlow 2 簡介
- 二、Keras:TensorFlow 2 的高級 API
- 三、TensorFlow 2 和 ANN 技術
- 第 2 部分:TensorFlow 2.00 Alpha 中的監督和無監督學習
- 四、TensorFlow 2 和監督機器學習
- 五、TensorFlow 2 和無監督學習
- 第 3 部分:TensorFlow 2.00 Alpha 的神經網絡應用
- 六、使用 TensorFlow 2 識別圖像
- 七、TensorFlow 2 和神經風格遷移
- 八、TensorFlow 2 和循環神經網絡
- 九、TensorFlow 估計器和 TensorFlow HUB
- 十、從 tf1.12 轉換為 tf2
- TensorFlow 入門
- 零、前言
- 一、TensorFlow 基本概念
- 二、TensorFlow 數學運算
- 三、機器學習入門
- 四、神經網絡簡介
- 五、深度學習
- 六、TensorFlow GPU 編程和服務
- TensorFlow 卷積神經網絡實用指南
- 零、前言
- 一、TensorFlow 的設置和介紹
- 二、深度學習和卷積神經網絡
- 三、TensorFlow 中的圖像分類
- 四、目標檢測與分割
- 五、VGG,Inception,ResNet 和 MobileNets
- 六、自編碼器,變分自編碼器和生成對抗網絡
- 七、遷移學習
- 八、機器學習最佳實踐和故障排除
- 九、大規模訓練
- 十、參考文獻