
# 九、大規模訓練
到目前為止,在本書中,我們使用或查看的數據集的大小從數萬個(MNIST)樣本到略超過一百萬個(ImageNet)。 盡管所有這些數據集在剛推出時都被認為是巨大的,并且需要使用最先進的機器,但是 GPU 和云計算等技術的迅捷發展現已使它們易于訓練。 由功率較低的機器的人。
但是,深度神經網絡的強大功能來自其隨輸入的數據量進行擴展的能力。 簡而言之,這意味著您可以用來訓練模型的數據越好,越干凈,結果越好。 研究人員已經意識到了這一點,我們可以看到,新的公共數據集中的訓練樣本數量一直在增加。
結果,很有可能,如果您開始研究行業中的問題,甚至只是最近的 Kaggle 競賽,您很有可能將使用可能包含數百萬個元素的數據集。 如何處理如此龐大的數據集,以及如何有效地訓練模型,就成為一個現實問題。 差異可能意味著要等待三天而不是 1 個月的時間來完成模型的訓練,因此這不是您想出錯的事情。
在本章中,您將學習一些解決以下問題的方法:
* 數據集太大而無法放入內存
* 如何在多臺機器上擴展訓練
* 數據過于復雜而無法在普通目錄文件夾和子文件夾中進行組織
# 在 TFRecords 中存儲數據
讓我們從訓練網絡進行圖像分類的示例開始。 在這種情況下,我們的數據將是帶有相關標簽的圖像集合。 我們存儲數據的一種方法是在類似目錄的文件夾結構中。 對于每個標簽,我們將有一個文件夾,其中包含該標簽的圖像:
```py
-Data
- Person
-im1.png
- Cat
-im2.png
- Dog
-im3.png
```
盡管這似乎是存儲數據的一種簡單方法,但一旦數據集大小變得太大,它就會具有一些主要缺點。 當我們開始加載它時,一個很大的缺點就來了。
打開文件是一項耗時的操作,必須多次打開數百萬個文件,這會增加大量的訓練時間開銷。 最重要的是,由于我們已將所有數據拆分開,因此不會將其存儲在一個漂亮的內存塊中。 硬盤驅動器將不得不做更多的工作來嘗試查找和訪問所有硬盤。
解決辦法是什么? 我們將它們全部放入一個文件中。 這樣做的好處是,您的所有數據將在計算機內存中更好地對齊以便讀取,這將加快處理速度。 將所有內容都保存在一個文件中也意味著我們不必花費時間來加載數百萬個文件,這將非常緩慢且效率低下。
我們可以根據需要使用幾種不同的格式來存儲數據,例如 HDF5 或 LMDB。 但是,當我們使用 TensorFlow 時,我們將繼續使用其自己的內置格式 TFRecords。 TFRecords 是 TensorFlow 自己的標準文件格式,用于存儲數據。 它是一種二進制文件格式,提供對其內容的順序訪問。 它足夠靈活,可以存儲復雜的數據集和標簽以及我們可能想要的任何元數據。
# 創建 TFRecord
在開始之前,讓我們分解一下 TFRecord 的工作方式。 打開 TFRecord 文件進行寫入后,創建一個稱為`Example`的內容。 這只是一個協議緩沖區,我們將使用它填充要保存在其中的所有數據。 在示例中,我們將數據存儲在`Feature`中。 功能是描述示例中數據的一種方式。 功能可以是以下三種類型之一:字節列表,浮點列表或`int64`列表。 將所有數據放入功能部件并將它們寫入示例緩沖區后,我們會將整個協議緩沖區序列化為字符串,然后將其寫入 TFRecord 文件。
讓我們看看這在實踐中如何工作。 我們將繼續使用前面的圖像分類示例,并創建一個 TFRecord 來存儲相關數據。
首先,我們創建文件,這還將返回給我們一種寫入文件的方式:
```py
writer = tf.python_io.TFRecordWriter('/data/dataset.tfrecord')
```
接下來,我們假設圖像已經加載并且已經作為`numpy`數組存儲在內存中; 我們將在以后看到如何存儲編碼圖像:
```py
# labels is a list of integer labels.
# image_data is an NxHxWxC numpy array of images
for index in range(len(labels)):
image_raw = image_data[index, ...].tobytes()
# Create our feature.
my_features= {
'image_raw': tf.train.Feature(bytes_list=tf.train.BytesList(value=[image_raw])), 'label':
tf.train.Feature(int64_list=tf.train.Int64List(value=[labels[index]]))}
# The Example protocol buffer.
example = tf.train.Example(features=tf.train.Features(feature=my_features)
writer.write(example.SerializeToString())
writer.close() # Close our tfrecord file after finishing writing to it.
```
我們遍歷標簽列表,將每個圖像數組一次轉換為原始字節。
要在示例中存儲數據,我們需要向其添加功能。 我們將功能存儲在字典中,其中每個鍵都是我們選擇的某些字符串名稱,例如`label`,值是`tf.train.Feature`,這就是我們的數據。
必須使用`tf.train.BytesList`,`tf.train.Int64List`或`tf.train.FloatList`將進入`tf.train.Feature`的數據轉換為期望的正確類型。
接下來,我們創建一個`tf.train.Example`協議緩沖區并將功能傳遞給它。 最后,我們將`Example`序列化為字符串并將其寫入 TFRecord 文件。 一旦遍歷了整個圖像數組,就必須記住關閉文件進行寫入。
# 存儲編碼圖像
優化內存使用率的一種方法是使用某種壓縮方式(即 PNG)對圖像進行編碼,在這種情況下 TFRecord 會更小,但是您仍需要在使用之前解壓縮數據,這可能需要一些時間。 在實踐中要做的是使用另一個 CPU 內核來減輕計算量。
# 分片
盡管我們說最好將所有數據保存在一個文件中,但實際上并非 100% 正確。 由于 TFRecords 是按順序讀取的,因此,如果僅使用一個文件,我們將無法重新整理數據集。 經過一段時間的訓練之后,每次到達 TFRecord 的末尾時,您都將返回到數據集的開頭,但是不幸的是,每次瀏覽文件時,數據的順序都相同。
為了允許我們隨機播放數據,我們可以做的一件事是通過創建多個 TFRecord 文件并將數據散布到這些多個文件中來*分片*我們的數據。 這樣,我們可以在每個周期處重新整理加載 TFRecord 文件的順序,因此我們在訓練時將為我們有效地整理數據。 每 100 萬張圖像需要 1000 個碎片,這是可以遵循的良好基準。
在下一節中,我們將看到如何使用 TFRecords 建立有效的數據饋送流水線。
# 建立高效的流水線
當我們處理較小的數據集時,僅將整個數據集加載到計算機內存中就足夠了。 如果您的數據集足夠小,這很簡單并且可以正常工作; 但是,在很多時候,情況并非如此。 現在我們將研究如何克服這個問題。
為了避免一次加載所有數據,我們將需要創建一個數據流水線以將我們的訓練數據饋入模型。 除其他事項外,該流水線將負責從存儲中加載一批元素,對數據進行預處理,最后將數據提供給我們的模型。 幸運的是,這一切都可以使用 TensorFlow 數據 API 輕松完成。
對于這些示例,我們將假定已將數據保存到多個(在本例中為兩個)TFRecord 文件中,如先前所述。 如果您有兩個以上,則沒有區別; 您只需在設置內容時包括所有名稱即可。
我們首先從所有 TFRecord 文件名的列表創建 TFRecord 數據集:
```py
# Create a TFRecord dataset that reads all of the Examples from
two files.
train_filenames= ["/data/train1.tfrecord", "/data/train2.tfrecord"]
train_dataset = tf.data.TFRecordDataset(filenames)
```
接下來,我們必須解碼 TFRecords。 為此,我們編寫了一個函數,該函數將接受 TFRecord,對其進行解碼,然后返回輸入圖像及其對應的標簽:
```py
# Function for decoding our TFRecord. We assume our images are fixed size 224x224x3
def decode_tfrec(proto_in):
my_features = {'image_raw': tf.FixedLenFeature([], tf.string),
'Label': tf.FixedLenFeature([], tf.int64)}
parsed_features = tf.parse_single_example(proto_in, features=my_features)image = tf.decode_raw(parsed_features['image_raw'], tf.uint8)
image = tf.cast(image, tf.float32) # Tensorflow data needs to be float32.
image = tf.reshape(image, [224,224,3]) # Need to reshape your images.
label = tf.cast(parsed_features['label'], tf.int32) # Labels need to be int32
label = tf.one_hot(label, depth=...) # Convert our labels to one hot.
return image, label
```
然后,我們將此函數傳遞給`dataset.map()`方法,該方法將為我們執行:
```py
train_dataset = train_dataset.map(decode_tfrec, num_parallel_calls=4)
```
# 映射轉換的并行調用
默認情況下,您在數據集上調用的任何映射轉換都僅作用于數據集的單個元素,并且將按順序處理元素。 要加快速度并使用所有 CPU 功能,最簡單的方法是將`num_parallel_calls`參數設置為可用的 CPU 內核數。 這樣,我們就不會浪費任何可用的 CPU 能力。 但是,警告您不要將其設置為高于可用內核的數量,因為由于調度效率低下,這實際上可能會降低性能。
您想要對數據進行的任何轉換(例如數據擴充)也可以編寫為函數,然后像以前一樣傳遞給`map`方法,以將其應用于數據集。 例如,請注意以下代碼:
```py
train_dataset = train_dataset.map(decode_tfrec, num_parallel_calls=4) # Decode tfrecord.
train_dataset = train_dataset.map(data_augmentation,
num_parallel_calls=4) # Augment data.
```
# 批量
您希望在流水線末尾做的最后一件事是生成一批準備發送到 GPU 進行訓練的數據。 這可以通過批量方法簡單地完成,并傳入所需的批量大小:
```py
train_dataset = train_dataset.batch(128) # Take a batch of 128 from the dataset.
```
當試圖使我們的流水線盡可能高效時,批次的大小是一個重要的參數。 盡可能大可能并不總是最好的。 例如,如果您的圖像上有很多預處理步驟,那么當 CPU 對大量圖像進行預處理時,GPU 可能會處于空閑狀態。
# 預取
我們能夠建立有效數據流水線的另一種方法是始終準備好一批數據準備發送到 GPU。 理想情況下,在訓練模型時,我們希望 GPU 的使用率始終保持在 100%。 這樣,我們可以最大程度地利用昂貴的硬件,該硬件可以在訓練時有效地計算前進和后退的傳球次數。
為此,我們需要 CPU 加載并準備一批圖像,以準備在向前和向后傳遞模型的過程中傳遞給 GPU。 幸運的是,在收集批量之后,我們可以使用簡單的預取轉換輕松完成此操作,如下所示:
```py
train_dataset= train_dataset.batch(128).prefetch(1)
```
使用預取將確保我們的數據流水線在進行訓練時為我們準備一整批數據,準備將其加載到 GPU 中以進行下一次迭代。 這樣做可以確保我們的流水線在等待一批批次收集之前不會減慢速度,并且如果獲取批次所需的時間少于模型的前后傳遞時間,那么我們的流水線將盡可能高效。
要清楚的是,此處使用`prefetch(1)`表示我們`prefetch`整批數據。 這就是為什么我們將批量作為流水線的最后一步,并在此處使用預取功能,因為這樣做最有效。
# 追蹤圖
TensorFlow 提供了一種很好的方式來分析并查看整個圖通過其時間軸跟蹤工具執行所需的時間。 這是查看圖的哪些部分正在減慢訓練速度并發現數據流水線中任何低效率的好工具。
我們將從為您提供如何跟蹤圖的示例開始。 這非常簡單:您只需在常規代碼中添加幾行,就會生成一個 JSON 文件,我們可以將該文件加載到 Google Chrome 瀏覽器中,以查看圖執行的所有時間:
```py
from tensorflow.python.client import timeline
.... # Your model and training code here
with tf.Session() as sess:
# We set some options to give to the session so graph execution is profiled.
options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
# Run your graph and supply the options we set.
sess.run(model_output, options=options, run_metadata=run_metadata)
# We create the Timeline object here then write it to json file.
created_timeline = timeline.Timeline(run_metadata.step_stats)
chome_readable_trace = created_timeline.generate_chrome_trace_format()
with open('my_timeline.json', 'w') as file:
file.write(chome_readable_trace)
```
在此代碼中,我們導入 TensorFlow 時間軸模塊,然后設置兩個選項以啟用圖跟蹤并將其提供給`Session.run()`。 運行圖之后,我們創建`Timeline`對象,該對象將包含對圖執行進行性能分析的結果。 然后,我們將其轉換為 Chrome 跟蹤格式,最后將其寫入 JSON 文件。
要查看結果,您需要打開一個新的 Chrome 窗口。 然后,在地址欄中輸入`chrome://tracing`并按`Enter`。 左上角將有一個加載按鈕。 使用它來加載剛剛保存的 JSON 文件。
現在將顯示跟蹤圖的結果。 查看此內容將告訴您圖的每個部分執行所需的時間。 您應該特別注意存在大塊空白的地方。 這些空白表示設備(例如您的 GPU)正坐在那里等待數據,以便它們可以執行計算。 您應該嘗試通過優化數據饋送方式來消除這些問題。
但是請注意,您的流水線可能已完全優化,但是您沒有 CPU 周期來足夠快地處理流水線。 檢查您的 CPU 使用情況,看看是否是這種情況。
# TensorFlow 中的分布式計算
在本節中,您將學習如何在 TensorFlow 中分配計算; 強調如何做到這一點的重要性如下:
* 并行運行更多實驗(即,找到超參數,例如網格搜索)
* 在多個 GPU(在多個服務器上)上分配模型訓練,以減少訓練時間
一個著名的用例是,Facebook 發布了一篇論文,該論文能夠在 1 小時(而不是幾周)內訓練 ImageNet。 基本上,它在 256 個 GPU 上的 ImageNet 上訓練了 ResNet-50,該 GPU 分??布在 32 臺服務器上,批量大小為 8,192 張圖像。
# 模型/數據并行
實現并行性和在多臺服務器中擴展任務的方法主要有兩種:
* **模型并行性**:當模型不適合 GPU 時,您需要在不同服務器上計算層。
* **數據并行性**:當我們在不同的服務器上分布相同的模型但處理不同的批次時,每個服務器將具有不同的梯度,并且我們需要在服務器之間進行某種同步。
在本節中,我們將重點介紹易于實現的數據并行性:
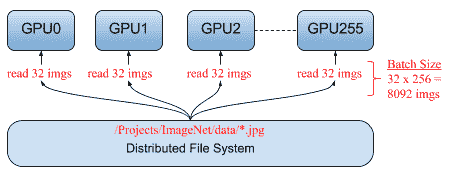
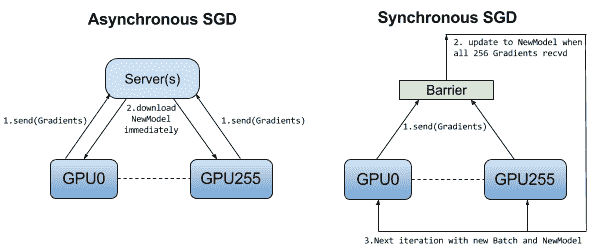
# 同步/異步 SGD
如前所述,在數據并行性中,每個模型都會從訓練集中獲取一些數據并計算自己的梯度,但是考慮到每個工作器都將擁有相同的模型,我們需要在更新模型之前以某種方式進行同步。
在同步 SGD 中,所有工作器都會計算一個梯度并等待計算所有梯度,然后將模型更新并再次分發給所有工作器:
# 當數據不適合在一臺計算機上時
可能出現的一個問題是,我們根本無法將數據存儲在一臺計算機上和/或我們仍然需要在該數據集上進行搜索。 為了解決此類問題,我們可能需要分布式 **NoSQL** 數據庫,例如 Cassandra。 Cassandra 支持在可用性和性能至關重要的多個系統上進行數據分發:
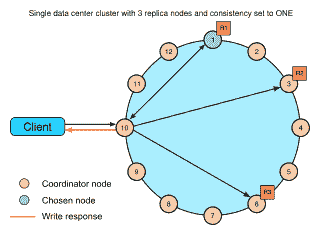
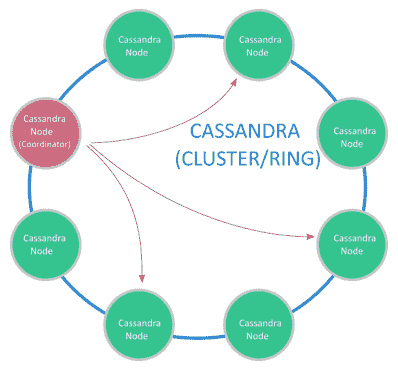
卡桑德拉(Cassandra)盡最大努力避免出現單點故障。 例如,所有節點都將像一種主節點一樣工作(沒有實際的主節點),因此,在某種類型的高可用性備份中,所有節點都有責任處理請求并自動在節點之間分配數據。
# NoSQL 系統的優勢
與關系數據庫(例如舊版本的 MySQL 和 PostgreSQL)相比,NoSQL 數據庫在數據量太大以及不需要關系數據庫的功能(例如觸發器或存儲過程)時會發光。 。
在繼續之前,讓我們列出 NoSQL 系統的優點:
* 水平縮放; 要獲得更高的性能,只需添加更多機器
* 我們不需要事先知道表之間的關系
* 允許在整個工作期間更改表結構
* 更快(沒有復雜的關系數據庫機制)
* 數據通常保存在分布式文件系統上,因此,例如,將圖像存儲在 NoSQL 數據庫中就可以了
# 安裝 Cassandra(Ubuntu 16.04)
安裝 Oracle Java 1.8:
* ``sudo apt-get update?``
* `sudo add-apt-repository ppa:webupd8team/java?`
* `sudo apt-get update?`
* `sudo apt-get -y install oracle-java8-installer?`
安裝 Cassandra:
* `echo "deb http://www.apache.org/dist/Cassandra/debian 310x main" | sudo tee -a /etc/apt/sources.list.d/cassandra.sources.list?`
* `curl https://www.apache.org/dist/Cassandra/KEYS | sudo apt-key add -?`
* `sudo apt-get update?`
* `sudo apt-get install cassandra`
* `sudo service cassandra status`
* `sudo nodetool status?`
# CQLSH 工具
CQLSH 是允許您向 Cassandra 節點發出 SQL 命令的工具:
對于圖形用戶界面,有一個很好的工具叫做 DBWeaver,它也可以完成此工作:
DBWeaver 示例
# 創建數據庫,表和索引
1. 首先,我們需要創建數據庫(鍵空間)并選擇節點如何復制數據:
```py
CREATE KEYSPACE mydb WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : 1 };?
```
2. 現在,我們創建一個表:
```py
CREATE TABLE tb_drive ( id uuid PRIMARY KEY, wheel_angle float, acc float, image blob );?
```
3. 如下添加一些數據:
```py
INSERT INTO tb_drive (id,wheel_angle,acc) VALUES (now(),0.2,0.5);?
INSERT INTO tb_drive (id,wheel_angle,acc) VALUES (now(),0.1,0.5);?
INSERT INTO tb_drive (id,wheel_angle,acc) VALUES (now(),0.0,0.5);?
```
4. (在任何時間點)創建要查詢的所有列的索引(這就是為什么要快)
```py
CREATE INDEX idxAngle ON tb_drive (wheel_angle);?
CREATE INDEX idxAcc ON tb_drive (acc);?
```
# 將 Python 用于查詢
首先,在開始玩之前,我們需要安裝 Python 驅動程序`pip install cassandra-driver?`; 以下代碼片段僅列出了 Cassandra 集群中表的內容:
```py
from cassandra.cluster import Cluster?
import cassandra.util?
import uuid?
import numpy as np?
?
# Considering that the cluster is on localhost?
cluster = Cluster()?
# Other option if you know the IPs?
# cluster = Cluster(['192.168.0.1', '192.168.0.2'])?
# Get a session to the database?
session = cluster.connect('mydb')?
?
# Doing a query?
rows = session.execute('SELECT * FROM tb_drive limit 5')?
print('Columns:',rows.column_names)?
for row in rows:?
print(row.id, row.acc, row.wheel_angle)
```
# 在 Python 中填充表格
在以下示例中,我們將填充表格,包括一個存儲圖像的字段:
```py
insert_string = """?INSERT INTO tb_drive (id, wheel_angle, acc, image)? VALUES (%s, %s, %s, %s)?"""?
?for data in dataset:?
# Split from dataset the image path, steering angle, and acceleration?
img_path, steering_angle, acc = data?
? # Load image (png compressed)?
with open(img_path, 'rb') as f:?
content_file = f.read()?
?
# Insert into database?
session.execute(insert_string,(uuid.uuid1(), steering_angle, acc, content_file))?
```
# 做備份
對于備份(快照):結果存儲在`var/lib/cassandra/data/)?`中:
```py
nodetool -h localhost snapshot mydb?
```
要還原數據(可能需要截斷/刪除表),請執行以下操作:
然后我們復制在目錄`/var/lib/Cassandra/data/keyspace/table_name-UUID`之前創建的快照(數據庫備份文件),然后:
```py
nodetool refresh?
```
# 在云中擴展計算
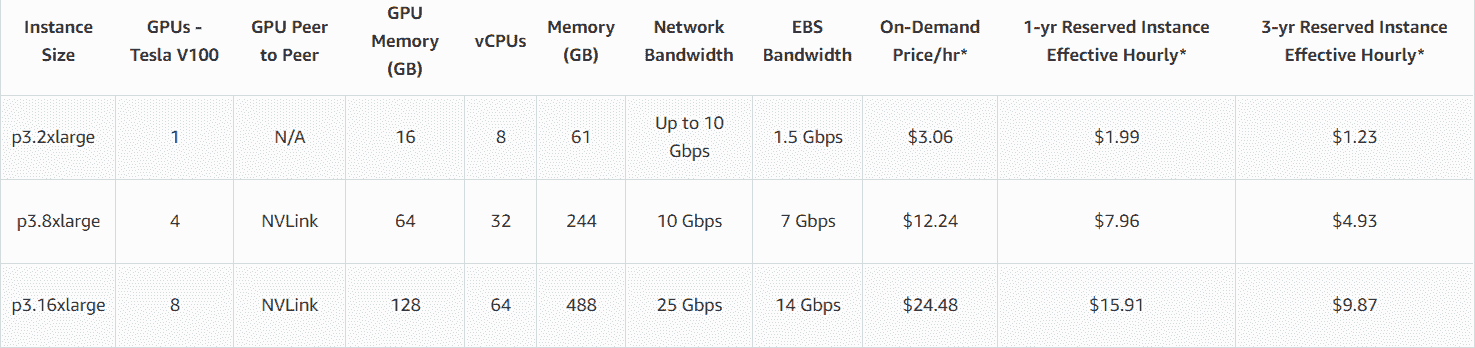
在您作為機器學習工程師的設計周期和生命周期中,您可能會遇到這樣的情況,即您辦公室中可用的計算能力根本不夠,并且您不能等待 IT 團隊為您購買新服務器。 因此,例如,如果您能負擔得起每小時 24.48 美元的價格,則可能擁有一個 p3.16xlarge,帶有 8 個 GPU Nvidia V100、64 核和 488 GB RAM。
在本部分中,您將學習有關可幫助您解決計算能力不足問題的 Amazon AWS 服務的信息。
您將了解以下 Amazon Cloud Services:
* **彈性計算云**(**EC2**)
* S3
* SageMaker
# EC2
這是我們創建服務器的服務,您基本上可以在其中創建任何服務器來完成工作:
在這里,您可以配置諸如訪問服務器的方式(通常使用私鑰):
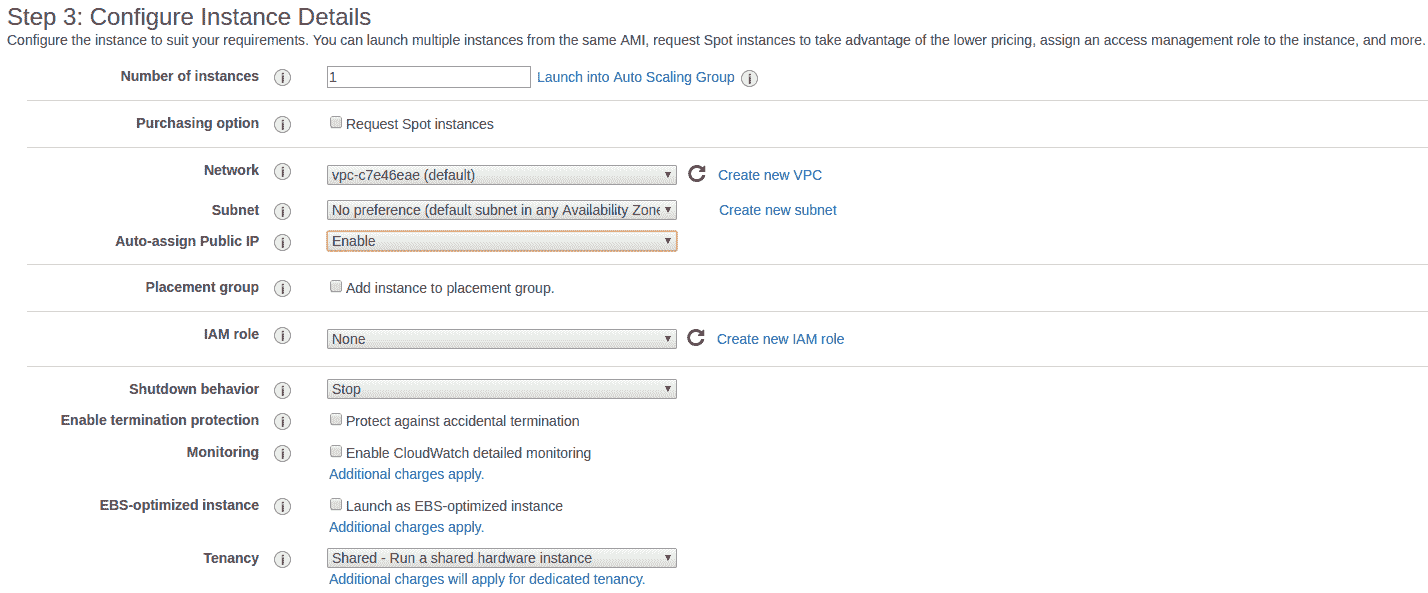
在這里,我們配置所需的磁盤空間:

在這里,我們配置將可用的端口:

可用端口
# AMI
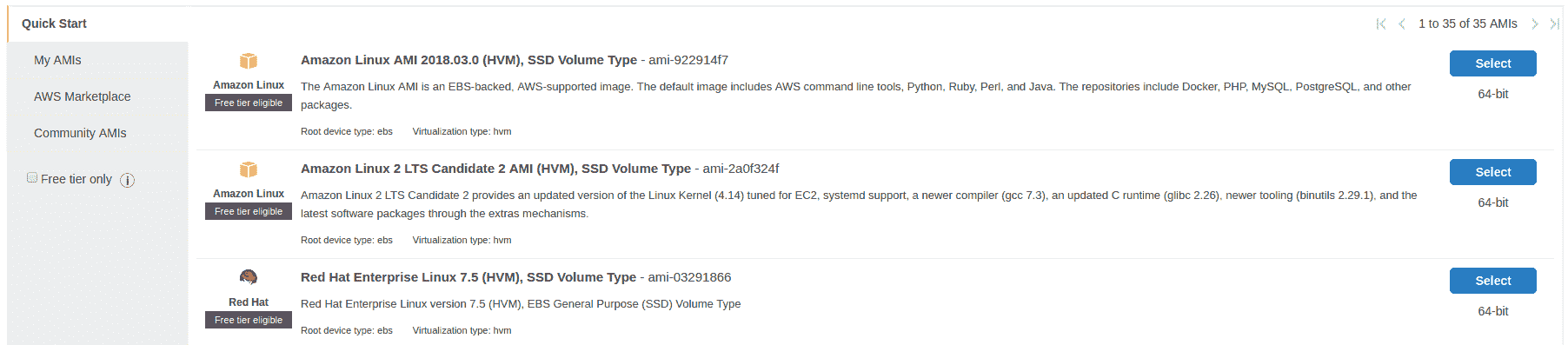
這是 AWS 中最酷的功能之一,它使您可以從所有數據和已安裝的工具(從一個服務器實例到另一個服務器實例)創建映像。 因此,您可以僅使用所有工具,驅動程序等配置一臺服務器,以后再使用具有相同映像的另一臺服務器:
# 儲存(S3)
Amazon S3 是存儲系統,您可以在其中從常規 HTTP 請求上傳/下載文件。 S3 的構想是*存儲桶*,您可以從中存儲/下載文件。 另外,有些插件可讓您將 S3 直接映射到您的 EC2 實例,例如某些遠程文件夾(不建議使用):
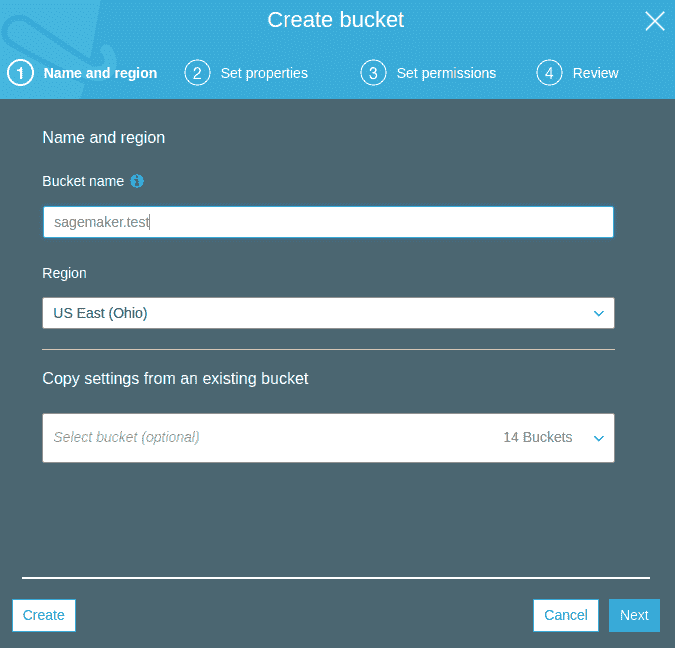
以下屏幕截圖顯示了如何創建存儲桶:
S3 系統可以進行公共配置,因此人們可以從任何地方下載/上傳內容。
# SageMaker
SageMaker 提供了一種在云中訓練/部署機器學習模型的簡便方法。 SageMaker 將提供 Jupyter 筆記本,您可以在其中可視化/訓練模型并直接連接到 S3 中的數據(提供了訪問 S3 的 API):
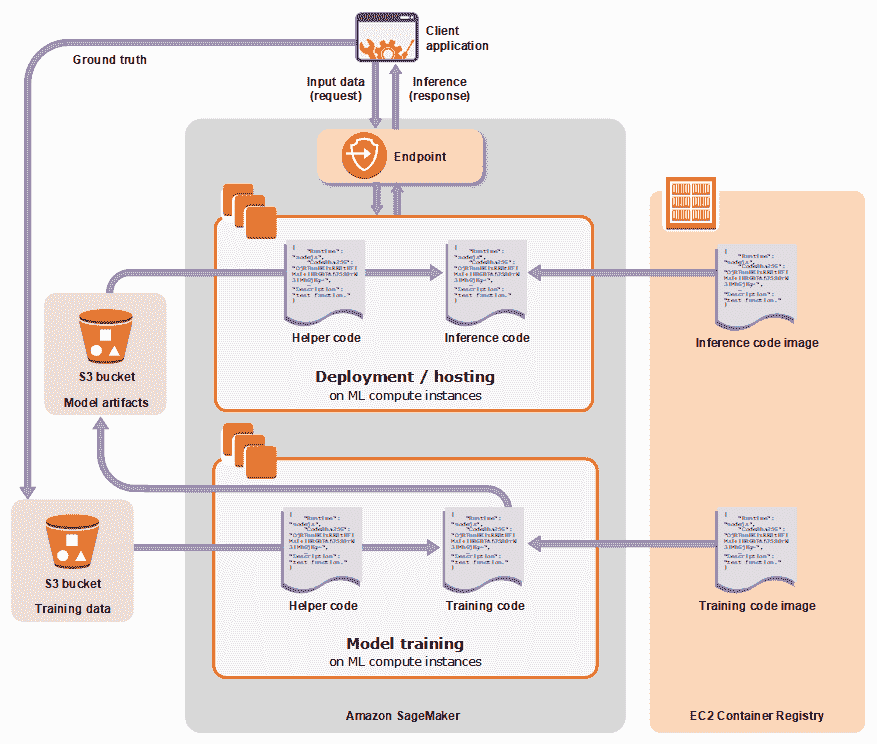
在這里,我們顯示了創建筆記本實例的默認選項:
這是筆記本面板:

并且,這是筆記本(您可以查看訓練模型的示例來檢查 API 的工作方式):
# 總結
在本章中,您學習了如何處理數據集太大而無法由普通臺式計算機處理的數據。 我們看到了如何在多個 GPU 和機器之間訓練 TensorFlow 模型,最后,我們研究了用于存儲數據并將其有效地饋送到模型的最佳實踐。
在本書的學習過程中,我們研究了計算機視覺中當前流行的許多問題,以及如何使用深度學習解決所有這些問題。 我們還提供了有關如何在 TensorFlow 中實現這些功能的見解。 在此過程中,我們介紹了如何使用 TensorFlow。
- TensorFlow 1.x 深度學習秘籍
- 零、前言
- 一、TensorFlow 簡介
- 二、回歸
- 三、神經網絡:感知器
- 四、卷積神經網絡
- 五、高級卷積神經網絡
- 六、循環神經網絡
- 七、無監督學習
- 八、自編碼器
- 九、強化學習
- 十、移動計算
- 十一、生成模型和 CapsNet
- 十二、分布式 TensorFlow 和云深度學習
- 十三、AutoML 和學習如何學習(元學習)
- 十四、TensorFlow 處理單元
- 使用 TensorFlow 構建機器學習項目中文版
- 一、探索和轉換數據
- 二、聚類
- 三、線性回歸
- 四、邏輯回歸
- 五、簡單的前饋神經網絡
- 六、卷積神經網絡
- 七、循環神經網絡和 LSTM
- 八、深度神經網絡
- 九、大規模運行模型 -- GPU 和服務
- 十、庫安裝和其他提示
- TensorFlow 深度學習中文第二版
- 一、人工神經網絡
- 二、TensorFlow v1.6 的新功能是什么?
- 三、實現前饋神經網絡
- 四、CNN 實戰
- 五、使用 TensorFlow 實現自編碼器
- 六、RNN 和梯度消失或爆炸問題
- 七、TensorFlow GPU 配置
- 八、TFLearn
- 九、使用協同過濾的電影推薦
- 十、OpenAI Gym
- TensorFlow 深度學習實戰指南中文版
- 一、入門
- 二、深度神經網絡
- 三、卷積神經網絡
- 四、循環神經網絡介紹
- 五、總結
- 精通 TensorFlow 1.x
- 一、TensorFlow 101
- 二、TensorFlow 的高級庫
- 三、Keras 101
- 四、TensorFlow 中的經典機器學習
- 五、TensorFlow 和 Keras 中的神經網絡和 MLP
- 六、TensorFlow 和 Keras 中的 RNN
- 七、TensorFlow 和 Keras 中的用于時間序列數據的 RNN
- 八、TensorFlow 和 Keras 中的用于文本數據的 RNN
- 九、TensorFlow 和 Keras 中的 CNN
- 十、TensorFlow 和 Keras 中的自編碼器
- 十一、TF 服務:生產中的 TensorFlow 模型
- 十二、遷移學習和預訓練模型
- 十三、深度強化學習
- 十四、生成對抗網絡
- 十五、TensorFlow 集群的分布式模型
- 十六、移動和嵌入式平臺上的 TensorFlow 模型
- 十七、R 中的 TensorFlow 和 Keras
- 十八、調試 TensorFlow 模型
- 十九、張量處理單元
- TensorFlow 機器學習秘籍中文第二版
- 一、TensorFlow 入門
- 二、TensorFlow 的方式
- 三、線性回歸
- 四、支持向量機
- 五、最近鄰方法
- 六、神經網絡
- 七、自然語言處理
- 八、卷積神經網絡
- 九、循環神經網絡
- 十、將 TensorFlow 投入生產
- 十一、更多 TensorFlow
- 與 TensorFlow 的初次接觸
- 前言
- 1.?TensorFlow 基礎知識
- 2. TensorFlow 中的線性回歸
- 3. TensorFlow 中的聚類
- 4. TensorFlow 中的單層神經網絡
- 5. TensorFlow 中的多層神經網絡
- 6. 并行
- 后記
- TensorFlow 學習指南
- 一、基礎
- 二、線性模型
- 三、學習
- 四、分布式
- TensorFlow Rager 教程
- 一、如何使用 TensorFlow Eager 構建簡單的神經網絡
- 二、在 Eager 模式中使用指標
- 三、如何保存和恢復訓練模型
- 四、文本序列到 TFRecords
- 五、如何將原始圖片數據轉換為 TFRecords
- 六、如何使用 TensorFlow Eager 從 TFRecords 批量讀取數據
- 七、使用 TensorFlow Eager 構建用于情感識別的卷積神經網絡(CNN)
- 八、用于 TensorFlow Eager 序列分類的動態循壞神經網絡
- 九、用于 TensorFlow Eager 時間序列回歸的遞歸神經網絡
- TensorFlow 高效編程
- 圖嵌入綜述:問題,技術與應用
- 一、引言
- 三、圖嵌入的問題設定
- 四、圖嵌入技術
- 基于邊重構的優化問題
- 應用
- 基于深度學習的推薦系統:綜述和新視角
- 引言
- 基于深度學習的推薦:最先進的技術
- 基于卷積神經網絡的推薦
- 關于卷積神經網絡我們理解了什么
- 第1章概論
- 第2章多層網絡
- 2.1.4生成對抗網絡
- 2.2.1最近ConvNets演變中的關鍵架構
- 2.2.2走向ConvNet不變性
- 2.3時空卷積網絡
- 第3章了解ConvNets構建塊
- 3.2整改
- 3.3規范化
- 3.4匯集
- 第四章現狀
- 4.2打開問題
- 參考
- 機器學習超級復習筆記
- Python 遷移學習實用指南
- 零、前言
- 一、機器學習基礎
- 二、深度學習基礎
- 三、了解深度學習架構
- 四、遷移學習基礎
- 五、釋放遷移學習的力量
- 六、圖像識別與分類
- 七、文本文件分類
- 八、音頻事件識別與分類
- 九、DeepDream
- 十、自動圖像字幕生成器
- 十一、圖像著色
- 面向計算機視覺的深度學習
- 零、前言
- 一、入門
- 二、圖像分類
- 三、圖像檢索
- 四、對象檢測
- 五、語義分割
- 六、相似性學習
- 七、圖像字幕
- 八、生成模型
- 九、視頻分類
- 十、部署
- 深度學習快速參考
- 零、前言
- 一、深度學習的基礎
- 二、使用深度學習解決回歸問題
- 三、使用 TensorBoard 監控網絡訓練
- 四、使用深度學習解決二分類問題
- 五、使用 Keras 解決多分類問題
- 六、超參數優化
- 七、從頭開始訓練 CNN
- 八、將預訓練的 CNN 用于遷移學習
- 九、從頭開始訓練 RNN
- 十、使用詞嵌入從頭開始訓練 LSTM
- 十一、訓練 Seq2Seq 模型
- 十二、深度強化學習
- 十三、生成對抗網絡
- TensorFlow 2.0 快速入門指南
- 零、前言
- 第 1 部分:TensorFlow 2.00 Alpha 簡介
- 一、TensorFlow 2 簡介
- 二、Keras:TensorFlow 2 的高級 API
- 三、TensorFlow 2 和 ANN 技術
- 第 2 部分:TensorFlow 2.00 Alpha 中的監督和無監督學習
- 四、TensorFlow 2 和監督機器學習
- 五、TensorFlow 2 和無監督學習
- 第 3 部分:TensorFlow 2.00 Alpha 的神經網絡應用
- 六、使用 TensorFlow 2 識別圖像
- 七、TensorFlow 2 和神經風格遷移
- 八、TensorFlow 2 和循環神經網絡
- 九、TensorFlow 估計器和 TensorFlow HUB
- 十、從 tf1.12 轉換為 tf2
- TensorFlow 入門
- 零、前言
- 一、TensorFlow 基本概念
- 二、TensorFlow 數學運算
- 三、機器學習入門
- 四、神經網絡簡介
- 五、深度學習
- 六、TensorFlow GPU 編程和服務
- TensorFlow 卷積神經網絡實用指南
- 零、前言
- 一、TensorFlow 的設置和介紹
- 二、深度學習和卷積神經網絡
- 三、TensorFlow 中的圖像分類
- 四、目標檢測與分割
- 五、VGG,Inception,ResNet 和 MobileNets
- 六、自編碼器,變分自編碼器和生成對抗網絡
- 七、遷移學習
- 八、機器學習最佳實踐和故障排除
- 九、大規模訓練
- 十、參考文獻