
# 五、VGG,Inception,ResNet 和 MobileNets
到目前為止,我們已經討論了所有必要的構建塊,以便能夠實現常見問題(例如圖像分類和檢測)的解決方案。 在本章中,我們將討論一些通用模型架構的實現,這些架構在許多常見任務中都表現出了很高的表現。 自從最初創建以來,這些架構一直很流行,并且在今天繼續被廣泛使用。
在本章的最后,您將對現有的不同類型的 CNN 模型及其在各種不同的計算機視覺問題中的用例進行了解。 在實現這些模型時,您將學習如何設計這些模型以及它們各自的優點。 最后,我們將討論如何修改這些架構,以使訓練和表現/效率更好。
總之,本章將涵蓋以下主題:
* 如何提高參數效率
* 如何在 TensorFlow 中實現 VGG 網絡
* 如何在 TensorFlow 中實現 Inception 網絡
* 如何在 TensorFlow 中實現殘差網絡
* 如何實現對移動設備更友好的架構
# 替代大卷積
在開始之前,我們將首先學習可以減少模型使用的參數數量的技術。 首先,這很重要,因為它可以提高網絡的泛化能力,因為使用該模型中存在的參數數量將需要較少的訓練數據。 其次,較少的參數意味著更高的硬件效率,因為將需要更少的內存。
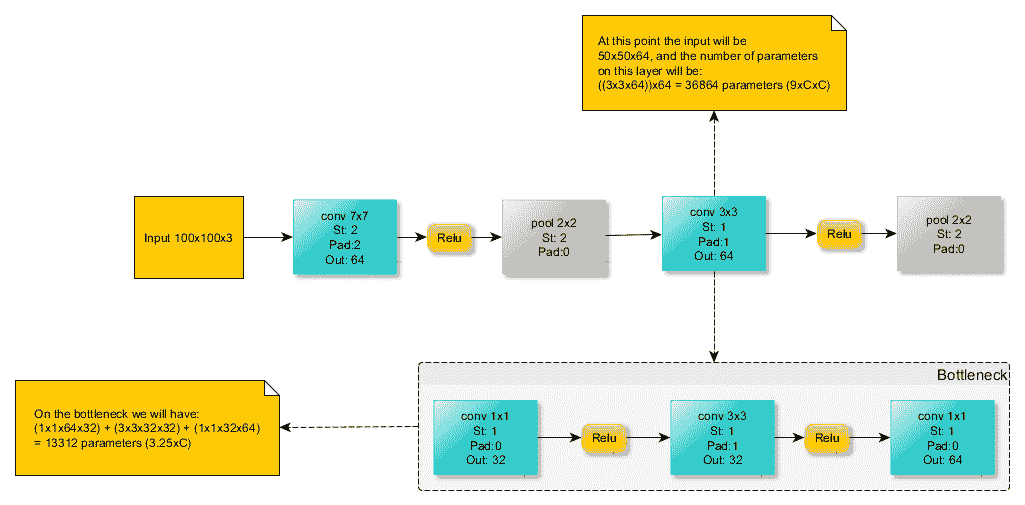
在這里,我們將從解釋減少模型參數的重要技術入手,將幾個小卷積級聯在一起。 在下圖中,我們有兩個`3x3`卷積層。 如果回頭看圖右側的第二層,可以看到第二層中的一個神經元具有`3x3`的感受域:
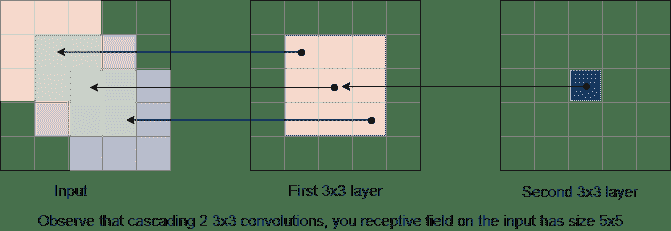
當我們說“感受域”時,是指它可以從上一層看到的區域。 在此示例中,需要一個`3x3`區域來創建一個輸出,因此需要一個`3x3`的感受域。
回溯到另一層,該`3x3`區域的每個元素在輸入端也具有`3x3`感受域。 因此,如果我們將所有這 9 個元素的接受場組合在一起,那么我們可以看到在輸入上創建的總接受場大小為`5x5`。
因此,用簡單的話來說,將較小的卷積級聯在一起可以獲得與使用較大卷積相同的感受域。 這意味著我們可以用級聯的小卷積代替大卷積。
請注意,由于第一卷積層和輸入文件深度之間的深度不匹配(輸出的深度需要保持一致),因此無法在作用于輸入圖像的第一個卷積層上進行此替換:還應在圖像上觀察我們如何計算每層參數的數量。
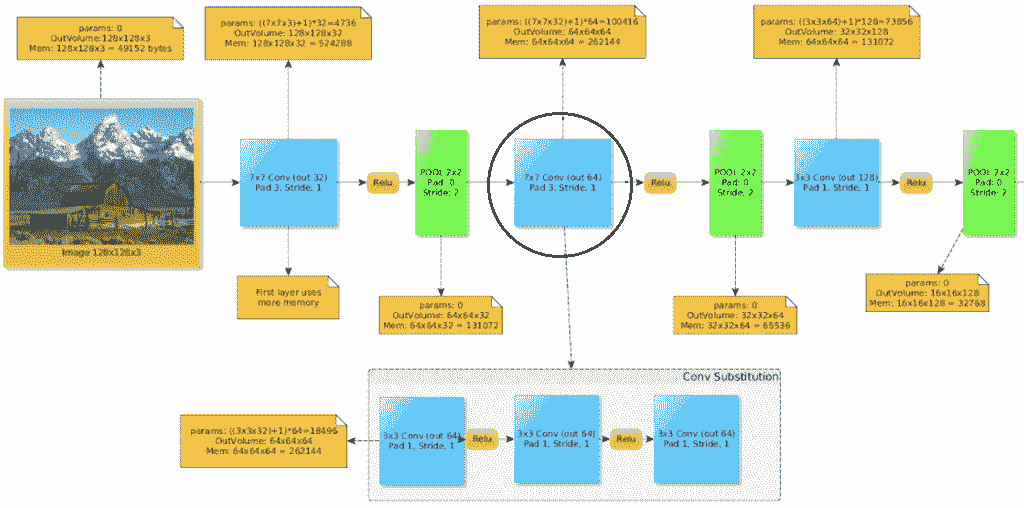
在上圖中,我們用三個`3x3`卷積替換了一個`7x7`卷積。 讓我們自己計算一下,以減少使用的參數。
想象一下,在形狀為`WxHxC`的輸入體積上使用`C`過濾器進行`7x7`大小的卷積。 我們可以計算過濾器中的權數,如下所示:
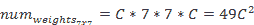
現在,相反,如果我們層疊三個`3x3`卷積(代之以`7x7`卷積),我們可以如下計算其權重數:
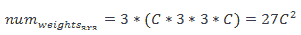
在這里,我們可以看到參數比以前更少!
還要注意,在這三個卷積層的每一個之間,我們放置了 ReLu 激活。 與僅使用單個大卷積層相比,這樣做會給模型帶來更多的非線性。 增加的深度(和非線性)是一件好事,因為這意味著網絡可以將更多的概念組合在一起,并提高其學習能力!
大多數新的成功模型的趨勢是用許多級聯在一起的較小卷積(通常為`3x3`大小)替換所有大型過濾器。 如前所述,這樣做有兩個巨大的好處。 它不僅減少了參數的數量,而且還增加了網絡中非線性的深度和數量,這對于增加其學習能力是一件好事。
# 替代`3x3`卷積
也可以通過稱為瓶頸的機制來簡化`3x3`卷積。 與早期相似,這將具有正常`3x3`卷積的相同表示,但參數更少,非線性更多。
瓶頸通過使用以下`C`過濾器替換`3x3`卷積層而起作用:
* 帶有`C / 2`過濾器的`1x1`卷積
* 帶有`C / 2`過濾器的`3x3`卷積
* 帶有`C`過濾器的`1x1`卷積
這里給出一個實際的例子:
從此示例中,我們將計算參數數量以顯示該瓶頸的減少量。 我們得到以下內容:
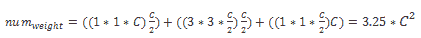
這比僅使用`3x3`卷積層時得到的參數要少:
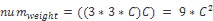
一些網絡架構,例如殘差網絡(我們將在后面看到),使用瓶頸技術再次減少了參數數量并增加了非線性。
# VGGNet
VGGNet 由牛津大學的**視覺幾何組**(**VGG**)創建,是真正引入堆疊更多層的想法的首批架構之一。 雖然 AlexNet 最初以其七層出現時被認為很深,但與 VGG 和其他現代架構相比,這現在已經很小了。
與只有`11x11`的 AlexNet 相比,VGGNet 僅使用空間大小為`3x3`的非常小的過濾器。 這些`3x3`卷積過濾器經常散布在`2x2`最大池化層中。
使用如此小的過濾器意味著可見像素的鄰域也非常小。 最初,這可能給人的印象是,本地信息是模型所考慮的全部內容。 但是,有趣的是,通過依次堆疊小型過濾器,它提供了與單個大型過濾器相同的“感受域”。 例如,堆疊三批`3x3`過濾器將具有與一個`7x7`過濾器相同的感受域。
堆疊過濾器的這種洞察力帶來了能夠擁有更深的結構(我們通常會看到更好的結構)的優點,該結構保留了相同的感受域大小,同時還減少了參數數量。 本章后面將進一步探討這個想法。
# 架構
接下來,我們將看到 VGGNet 的架構,特別是包含 16 層的 VGG-16 風格。 所有卷積層都有空間大小為`3x3`的過濾器,并且隨著我們深入網絡,卷積層中過濾器的數量從 64 個增加到 512 個。
堆疊兩個或三個卷積層然后合并的簡單模塊化設計使網絡的大小易于增加或減小。 結果,VGG 成功創建并測試了具有 11、13 和 19 層的版本:

# 參數和內存計算
VGG 最酷的功能之一是,由于其在 conv 層中的內核較小,因此使用的參數數量很少。 如果我們從第 2 章,“深度學習和卷積神經網絡”記住,卷積層中的參數數量(減去偏差)可以計算如下:
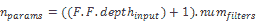
因此,例如,第一層將具有以下參數:
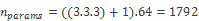
但是要注意,當涉及到模型末端的完全連接(密集)層時,這種數量很少的參數并不是這種情況,通常這是我們可以找到許多模型參數的地方。 如果像在 VGGNet 中一樣,一個接一個地堆疊多個密集層,則尤其如此。
例如,第一個密集層將具有以下數量的參數:
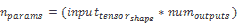
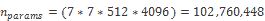
到那時為止,這是所有參數的六倍以上!
如前所述,您需要在訓練數據集中使用大量樣本來消耗模型參數,因此最好避免過度使用全連接層來避免參數爆炸。 幸運的是,人們發現,如果最后只有一層而不是三層,那么 VGGNet 的工作原理幾乎相同。 因此,刪除這些全連接層會從模型中刪除大量參數,而不會大大降低表現。 因此,如果您決定實現 VGGNet,我們建議您也這樣做。
# 代碼
接下來,我們介紹負責在 Tensorflow 中構建 VGG-16 模型圖的函數。 像本章中的所有模型一樣,VGGNet 旨在對 Imagenet 挑戰的 1,000 個類別進行分類,這就是為什么該模型輸出大小為 1000 的向量的原因。 顯然,可以為您自己的數據集輕松更改此設置,如下所示:
```py
def build_graph(self):
self.__x_ = tf.placeholder("float", shape=[None, 224, 224, 3], name='X')
self.__y_ = tf.placeholder("float", shape=[None, 1000], name='Y')
with tf.name_scope("model") as scope:
conv1_1 = tf.layers.conv2d(inputs=self.__x_, filters=64, kernel_size=[3, 3],
padding="same", activation=tf.nn.relu)
conv2_1 = tf.layers.conv2d(inputs=conv1_1, filters=64, kernel_size=[3, 3],
padding="same", activation=tf.nn.relu)
pool1 = tf.layers.max_pooling2d(inputs=conv2_1, pool_size=[2, 2], strides=2)
conv2_1 = tf.layers.conv2d(inputs=pool1, filters=128, kernel_size=[3, 3],
padding="same", activation=tf.nn.relu)
conv2_2 = tf.layers.conv2d(inputs=conv2_1, filters=128, kernel_size=[3, 3],
padding="same", activation=tf.nn.relu)
pool2 = tf.layers.max_pooling2d(inputs=conv2_2, pool_size=[2, 2], strides=2)
conv3_1 = tf.layers.conv2d(inputs=pool2, filters=256, kernel_size=[3, 3],
padding="same", activation=tf.nn.relu)
conv3_2 = tf.layers.conv2d(inputs=conv3_1, filters=256, kernel_size=[3, 3],
padding="same", activation=tf.nn.relu)
conv3_3 = tf.layers.conv2d(inputs=conv3_2, filters=256, kernel_size=[3, 3],
padding="same", activation=tf.nn.relu)
pool3 = tf.layers.max_pooling2d(inputs=conv3_3, pool_size=[2, 2], strides=2)
conv4_1 = tf.layers.conv2d(inputs=pool3, filters=512, kernel_size=[3, 3],
padding="same", activation=tf.nn.relu)
conv4_2 = tf.layers.conv2d(inputs=conv4_1, filters=512, kernel_size=[3, 3],
padding="same", activation=tf.nn.relu)
conv4_3 = tf.layers.conv2d(inputs=conv4_2, filters=512, kernel_size=[3, 3],
padding="same", activation=tf.nn.relu)
pool4 = tf.layers.max_pooling2d(inputs=conv4_3, pool_size=[2, 2], strides=2)
conv5_1 = tf.layers.conv2d(inputs=pool4, filters=512, kernel_size=[3, 3],
padding="same", activation=tf.nn.relu)
conv5_2 = tf.layers.conv2d(inputs=conv5_1, filters=512, kernel_size=[3, 3],
padding="same", activation=tf.nn.relu)
conv5_3 = tf.layers.conv2d(inputs=conv5_2, filters=512, kernel_size=[3, 3],
padding="same", activation=tf.nn.relu)
pool5 = tf.layers.max_pooling2d(inputs=conv5_3, pool_size=[2, 2], strides=2)
pool5_flat = tf.reshape(pool5, [-1, 7 * 7 * 512])
# FC Layers (can be removed)
fc6 = tf.layers.dense(inputs=pool5_flat, units=4096, activation=tf.nn.relu)
fc7 = tf.layers.dense(inputs=fc6, units=4096, activation=tf.nn.relu)
# Imagenet has 1000 classes
fc8 = tf.layers.dense(inputs=fc7, units=1000)
self.predictions = tf.nn.softmax(self.fc8, name='predictions')
```
# VGG 的更多信息
2014 年,VGG 在 Imagenet 分類挑戰中獲得第二名,在 Imagenet 定位挑戰中獲得第一名。 正如我們所看到的,VGGNet 的設計選擇是堆疊許多小的卷積層,從而可以實現更深的結構,同時具有更少的參數(如果我們刪除了不必要的全連接層),則表現更好。 這種設計選擇在創建強大而高效的網絡方面非常有效,以至于幾乎所有現代架構都復制了這種想法,并且很少(如果有的話)使用大型過濾器。
事實證明,VGG 模型可以在許多任務中很好地工作,并且由于其簡單的架構,它是開始嘗試或適應問題需求的理想模型。 但是,它確實有以下問題需要注意:
* 通過僅使用`3x3`層,尤其是在第一層,計算量不適用于移動解決方案
* 如前幾章所述,由于逐漸消失的梯度問題,甚至更深的 VGG 結構也無法正常工作
* 原始設計中大量的 FC 層在參數方面是過大的,這不僅減慢了模型的速度,而且更容易出現過擬合的問題
* 使用許多池化層,目前認為這不是好的設計
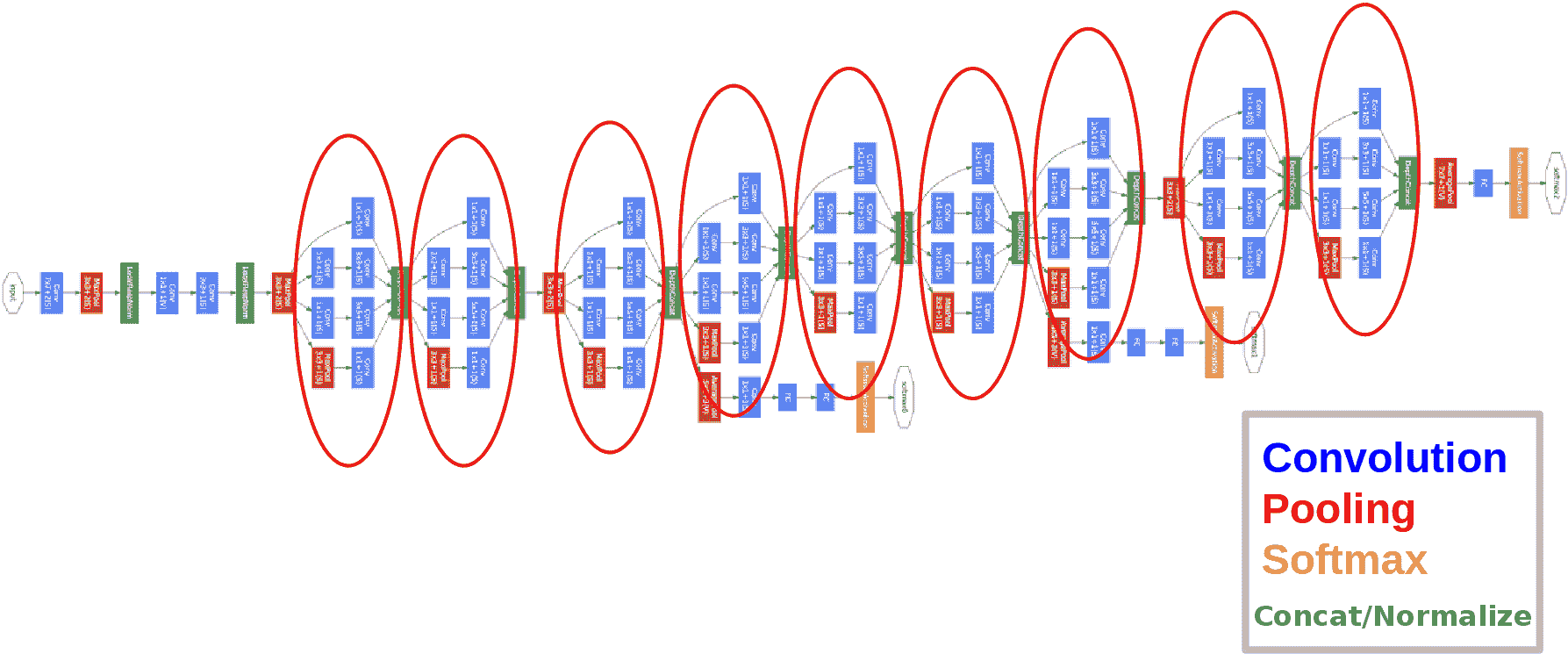
# GoogLeNet
雖然 VGGNet 在 2014 年 Imagenet 分類挑戰賽中排名第二,但我們將要討論的下一個模型 GoogLeNet 在那一年是贏家。 它是由 Google 創建的,它引入了一種重要的方法來使網絡更深,同時減少參數數量。 他們稱他們提出了`Inception` 模塊。 該模塊填充了大部分 GoogLeNet 模型。
GoogLeNet 具有 22 層,參數幾乎比 AlexNet 少 12 倍。 因此,除了更加精確之外,它還比 AlexNet 快得多。 創建`Inception`模塊的動機是制作更深的 CNN,以便獲得高度準確的結果,并使該模型可在智能手機中使用。 為此,在預測階段,計算預算大約需要增加 15 億次:
# Inception 模塊
起始模塊(或層的塊)旨在覆蓋較大的區域,但也保持較高的分辨率,以便也可以在圖像中查看重要的本地信息。 除了創建更深的網絡外,起始塊還引入了并行卷積的思想。 我們的意思是在前一層的輸出上執行不同大小的并行卷積。
初始層的幼稚視圖可以在這里看到:
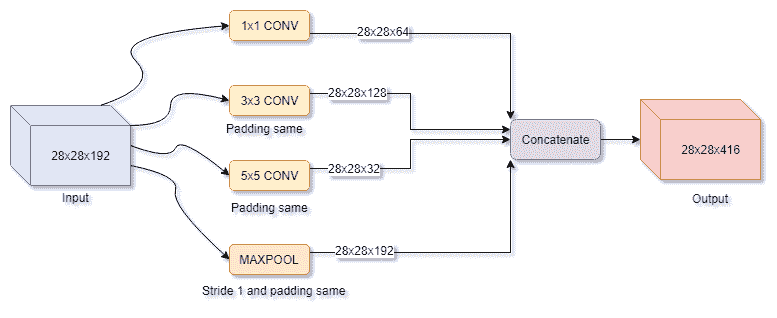
基本上,初始塊的想法是使用所有可用的內核大小和操作來覆蓋盡可能多的信息,并讓反向傳播根據您的數據決定使用什么。 在上圖中看到的唯一問題是計算成本,因此該圖在實踐中會有所不同。
考慮我們之前看到的`5x5`分支,讓我們檢查一下它的計算成本:

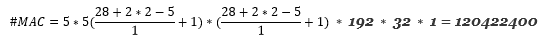
現在,考慮以下更改; 我們添加一個`1x1`卷積來將`5x5`卷積輸入深度從 192 轉換為 16:

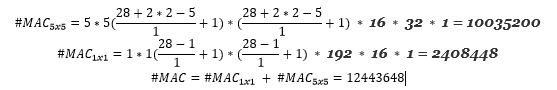
如果您觀察到,現在計算效率提高了 10 倍。 `1x1`層會擠壓大量深度(瓶頸),然后發送到`5x5`卷積層。
考慮到這一瓶頸變化,真正的初始層要復雜一些:
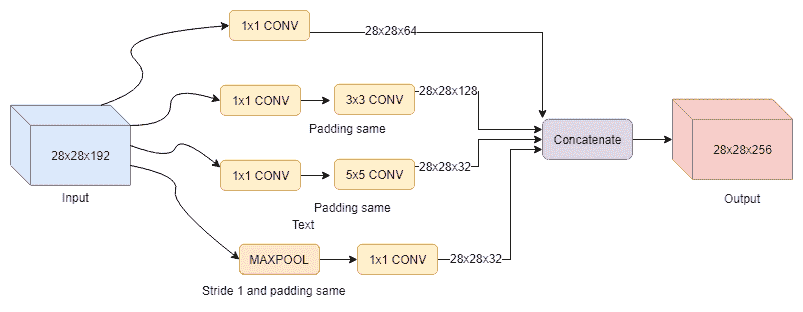
此外,在某些實現中,您可能會注意到有人試圖在初始代碼塊中使用批量規范化或丟棄法。
Googlenet 將只是許多級聯的啟動塊。 在這段代碼中,我們展示了如何創建一個起始塊:
```py
# Reference: https://github.com/khanrc/mnist/blob/master/inception.py
import tensorflow as tf
def inception_block_a(x, name='inception_a'):
# num of channels: 384 = 96*4
with tf.variable_scope(name):
# Pooling part
b1 = tf.layers.average_pooling2d(x, [3,3], 1, padding='SAME')
b1 = tf.layers.conv2d(inputs=b1, filters=96, kernel_size=[1, 1], padding="same", activation=tf.nn.relu)
# 1x1 part
b2 = tf.layers.conv2d(inputs=x, filters=96, kernel_size=[1, 1], padding="same", activation=tf.nn.relu)
# 3x3 part
b3 = tf.layers.conv2d(inputs=x, filters=64, kernel_size=[1, 1], padding="same", activation=tf.nn.relu)
b3 = tf.layers.conv2d(inputs=b3, filters=96, kernel_size=[3, 3], padding="same", activation=tf.nn.relu)
# 5x5 part
b4 = tf.layers.conv2d(inputs=x, filters=64, kernel_size=[1, 1], padding="same", activation=tf.nn.relu)
# 2 3x3 in cascade with same depth is the same as 5x5 but with less parameters
# b4 = tf.layers.conv2d(inputs=b4, filters=96, kernel_size=[5, 5], padding="same", activation=tf.nn.relu)
b4 = tf.layers.conv2d(inputs=b4, filters=96, kernel_size=[3, 3], padding="same", activation=tf.nn.relu)
b4 = tf.layers.conv2d(inputs=b4, filters=96, kernel_size=[3, 3], padding="same", activation=tf.nn.relu)
concat = tf.concat([b1, b2, b3, b4], axis=-1)
return concat
```
# GoogLeNet 的更多信息
GoogLeNet 的主要優點是,它比 VGG 更為準確,同時使用的參數更少,計算能力也更低。 主要的缺點仍然是,如果我們開始堆疊很多初始層,梯度將消失,而且整個網絡具有多個分支和多個損失的設計相當復雜。
# 殘差網絡
在前面的部分中,已經證明了網絡的深度是有助于提高準確率的關鍵因素(請參見 VGG)。 TensorFlow 中的第 3 章“圖像分類”中也顯示,可以通過正確的權重初始化和批量歸一化來緩解深度網絡中梯度消失或爆炸的問題。 但是,這是否意味著我們添加的層越多,我們得到的系統就越準確? 亞洲研究機構 Microsoft 的《用于圖像識別的深度殘差學習》的作者發現,只要網絡深度達到 30 層,準確率就會達到飽和。 為了解決此問題,他們引入了一個稱為殘差塊的新層塊,該塊將上一層的輸出添加到下一層的輸出中(請參見下圖)。 殘差網絡或 ResNet 在非常深的網絡(甚至超過 100 層!)中都顯示了出色的結果,例如 152 層的 ResNet 贏得了 2015 LRVC 圖像識別挑戰,其前 5 個測試誤差為 3.57。 事實證明,諸如 ResNets 之類的更深層網絡要比包括 Inception 模塊(例如 GoogLeNet)在內的更廣泛的網絡更好地工作。
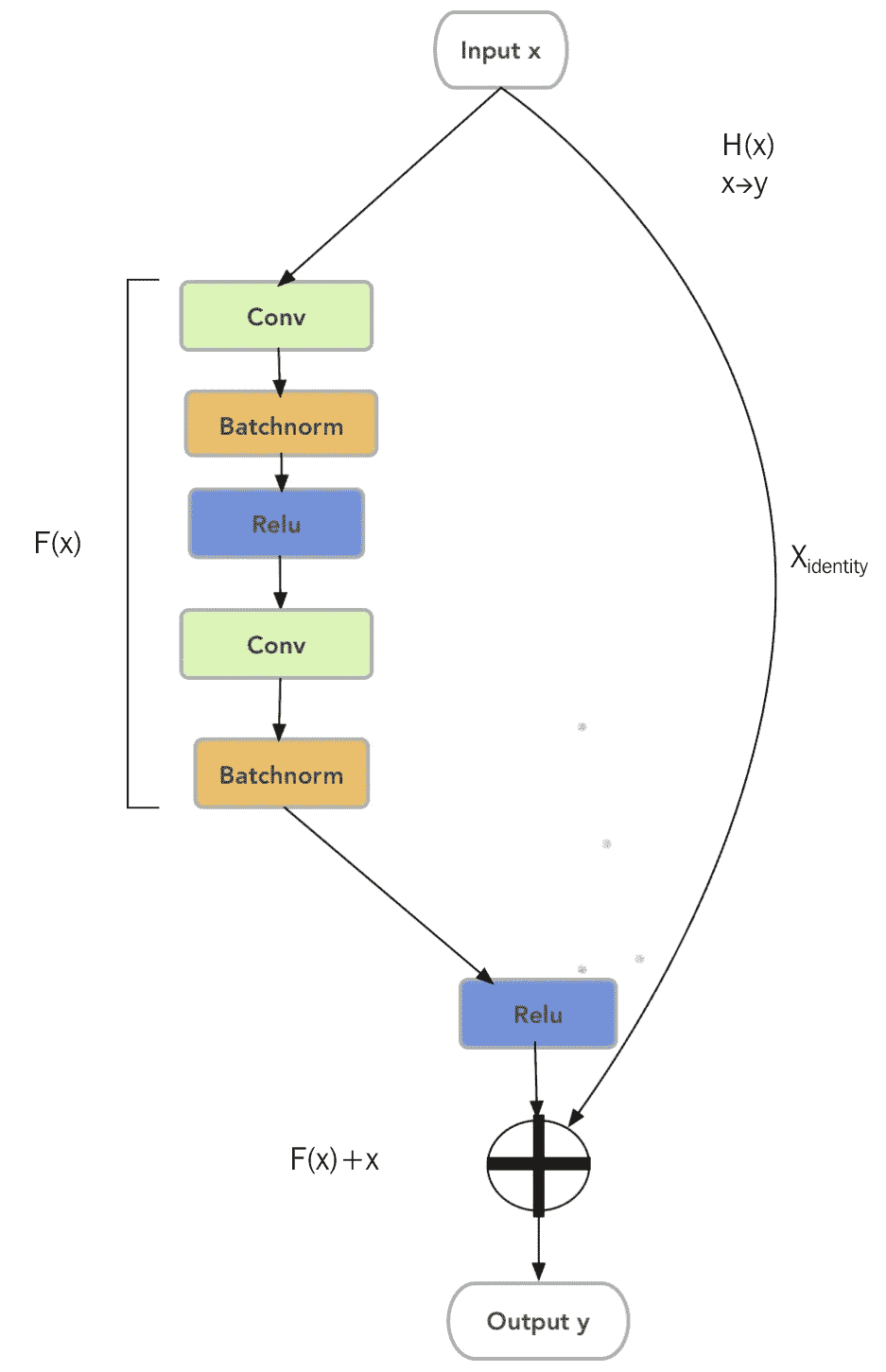
讓我們更詳細地了解殘差塊的外觀以及其功能背后的直覺。 如果我們有一個輸入`x`和一個輸出`y`,則存在一個將`x`映射到`y`的非線性函數`H(x)`。 假設函數`H(x)`可以由兩個堆疊的非線性卷積層近似。 然后,殘差函數`F(x) = H(x) - x`也可以近似。 我們可以等效地寫為`H(x) = F(x) + x`,其中`F(x)`表示兩個堆疊的非線性層,`x`標識輸入等于輸出的函數。
更正式地說,對于通過網絡的前向傳遞,如果`x`是來自`l-2`層的張量,并且`W[l-1]`和`W[l]`是當前層和先前層的權重矩陣,則下一層`l+1`的輸入`y`是:
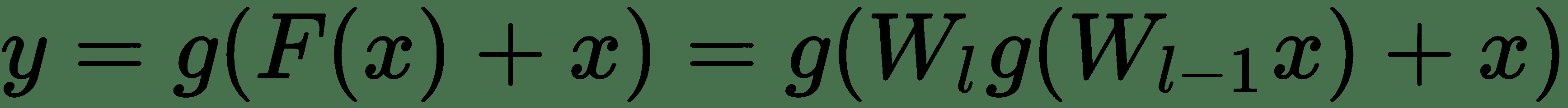
其中`g`是非線性激活函數,例如 ReLu 和`F(x) = W[l] g(W[l-1] x)`,即兩層堆疊卷積。 ReLu 函數可以在添加`x`之前或之后添加。 剩余的塊應由 2 層或更多層組成,因為一層的塊沒有明顯的好處。
為了理解該概念背后的直覺,我們假設我們有一個經過訓練的淺層 CNN,其更深的對應層具有與淺層 CNN 相同的層,并且在它們之間隨機插入了一些層。 為了擁有一個與淺層模型至少具有相似表現的深層模型,附加層必須近似標識函數。 但是,要學習具有卷積層棧的標識函數比將殘差函數推為零要困難得多。 換句話說,如果單位函數是最優解,則很容易實現`F(x)`,因此很容易實現`H(x) = x`。
另一種思考的方式是,在訓練期間,特定的層不僅會從上一層學習一個概念,還會從它之前的其他層學習一個概念。 這比只從上一層學習概念要好。
在實現方面,我們應注意確保`x`和`F(x)`的大小相同。
查看殘差塊的重要性的另一種方法是,我們將為梯度創建一個“高速公路”(加法塊),以避免隨著梯度的增加而消失的梯度問題!
以下代碼將向您展示如何創建殘差塊,它是殘差網絡的主要構建塊:
```py
# Reference
# https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/learn/resnet.py
import tensorflow as tf
from collections import namedtuple
# Configurations for each bottleneck group.
BottleneckGroup = namedtuple('BottleneckGroup',
['num_blocks', 'num_filters', 'bottleneck_size'])
groups = [
BottleneckGroup(3, 128, 32), BottleneckGroup(3, 256, 64),
BottleneckGroup(3, 512, 128), BottleneckGroup(3, 1024, 256)
]
# Create the bottleneck groups, each of which contains `num_blocks`
# bottleneck groups.
for group_i, group in enumerate(groups):
for block_i in range(group.num_blocks):
name = 'group_%d/block_%d' % (group_i, block_i)
# 1x1 convolution responsible for reducing dimension
with tf.variable_scope(name + '/conv_in'):
conv = tf.layers.conv2d(
net,
filters=group.num_filters,
kernel_size=1,
padding='valid',
activation=tf.nn.relu)
conv = tf.layers.batch_normalization(conv, training=training)
with tf.variable_scope(name + '/conv_bottleneck'):
conv = tf.layers.conv2d(
conv,
filters=group.bottleneck_size,
kernel_size=3,
padding='same',
activation=tf.nn.relu)
conv = tf.layers.batch_normalization(conv, training=training)
# 1x1 convolution responsible for restoring dimension
with tf.variable_scope(name + '/conv_out'):
input_dim = net.get_shape()[-1].value
conv = tf.layers.conv2d(
conv,
filters=input_dim,
kernel_size=1,
padding='valid',
activation=tf.nn.relu)
conv = tf.layers.batch_normalization(conv, training=training)
# shortcut connections that turn the network into its counterpart
# residual function (identity shortcut)
net = conv + net
```
# MobileNet
我們將以一個新的 CNN 系列結束本章,該系列不僅具有較高的準確率,而且更輕巧,并且在移動設備上的運行速度更快。
由 Google 創建的 MobileNet 的關鍵功能是它使用了不同的“三明治”形式的卷積塊。 它不是通常的(`CONV`,`BATCH_NORM,RELU`),而是將`3x3`卷積拆分為`3x3`深度卷積,然后是`1x1`點向卷積。他們稱此塊為深度可分離卷積。
這種分解可以減少計算量和模型大小:
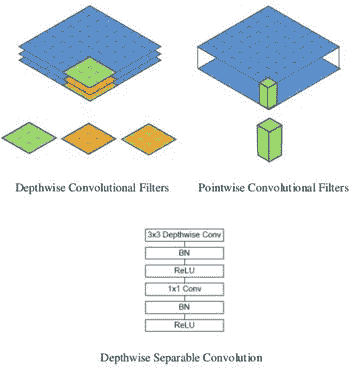
# 深度可分離卷積
這個新的卷積塊(`tf.layers.separable_conv2d`)由兩個主要部分組成:深度卷積層,然后是`1x1`點式卷積層。 該塊與普通卷積有以下幾種不同:
* 在正常卷積層中,每個過濾器`F`將同時應用于輸入通道上的所有通道(`F`應用于每個通道然后求和)
* 這個新的卷積`F`分別應用于每個通道,并且結果被級聯到某個中間張量(多少由深度倍數`DM`參數控制)
相對于標準卷積,深度卷積非常有效。 但是,它僅過濾輸入通道,并且不將它們組合以創建新功能。
現在,將使用`1x1`轉換層將深度輸出張量映射到某些所需的輸出通道深度,該轉換層將在通常在標準卷積層中發生的通道之間進行混合。 區別在于`DM`參數可用于丟棄一些信息。 同樣,`1x1`轉換僅用于調整音量大小。
# 控制參數
MobileNets 使用兩個超參數來幫助控制精度和速度之間的折衷,從而使網絡適合您要定位的任何設備。 這兩個超參數如下:
* **寬度倍增器**:通過統一減少整個網絡中使用的過濾器數量,控制深度卷積精度
* **分辨率倍增器**:只需將輸入圖像縮小到不同大小
# MobileNets 的更多信息
對于任何神經網絡設計,MobileNets 都具有一些最佳的精度,速度和參數比率。
但是,目前尚無良好(快速)的深度卷積實現可在 GPU 上運行。 結果,訓練可能會比使用正常的卷積運算慢。 但是,此網絡目前真正發揮作用的地方是小型 CPU 設計,提高的效率更加明顯。
# 總結
在本章中,我們向您介紹了各種卷積神經網絡設計,這些設計已經證明了它們的有效性,因此被廣泛使用。 我們首先介紹牛津大學 VGG 的 VGGNet 模型。 接下來,在最終討論微軟的殘差網絡之前,我們先使用 Google 的 GoogLeNet。 此外,我們還向您展示了一種更高級的新型卷積,該模型在名為 MobileNet 的模型設計中具有特色。 在整個過程中,我們討論了使每個網絡如此出色的不同屬性和設計選擇,例如跳過連接,堆疊小型過濾器或啟動模塊。 最后,給出了代碼,向您展示了如何在 TensorFlow 中寫出這些網絡。
在下一章中,我們將討論一種稱為生成模型的新型模型,該模型將使我們能夠生成數據。
- TensorFlow 1.x 深度學習秘籍
- 零、前言
- 一、TensorFlow 簡介
- 二、回歸
- 三、神經網絡:感知器
- 四、卷積神經網絡
- 五、高級卷積神經網絡
- 六、循環神經網絡
- 七、無監督學習
- 八、自編碼器
- 九、強化學習
- 十、移動計算
- 十一、生成模型和 CapsNet
- 十二、分布式 TensorFlow 和云深度學習
- 十三、AutoML 和學習如何學習(元學習)
- 十四、TensorFlow 處理單元
- 使用 TensorFlow 構建機器學習項目中文版
- 一、探索和轉換數據
- 二、聚類
- 三、線性回歸
- 四、邏輯回歸
- 五、簡單的前饋神經網絡
- 六、卷積神經網絡
- 七、循環神經網絡和 LSTM
- 八、深度神經網絡
- 九、大規模運行模型 -- GPU 和服務
- 十、庫安裝和其他提示
- TensorFlow 深度學習中文第二版
- 一、人工神經網絡
- 二、TensorFlow v1.6 的新功能是什么?
- 三、實現前饋神經網絡
- 四、CNN 實戰
- 五、使用 TensorFlow 實現自編碼器
- 六、RNN 和梯度消失或爆炸問題
- 七、TensorFlow GPU 配置
- 八、TFLearn
- 九、使用協同過濾的電影推薦
- 十、OpenAI Gym
- TensorFlow 深度學習實戰指南中文版
- 一、入門
- 二、深度神經網絡
- 三、卷積神經網絡
- 四、循環神經網絡介紹
- 五、總結
- 精通 TensorFlow 1.x
- 一、TensorFlow 101
- 二、TensorFlow 的高級庫
- 三、Keras 101
- 四、TensorFlow 中的經典機器學習
- 五、TensorFlow 和 Keras 中的神經網絡和 MLP
- 六、TensorFlow 和 Keras 中的 RNN
- 七、TensorFlow 和 Keras 中的用于時間序列數據的 RNN
- 八、TensorFlow 和 Keras 中的用于文本數據的 RNN
- 九、TensorFlow 和 Keras 中的 CNN
- 十、TensorFlow 和 Keras 中的自編碼器
- 十一、TF 服務:生產中的 TensorFlow 模型
- 十二、遷移學習和預訓練模型
- 十三、深度強化學習
- 十四、生成對抗網絡
- 十五、TensorFlow 集群的分布式模型
- 十六、移動和嵌入式平臺上的 TensorFlow 模型
- 十七、R 中的 TensorFlow 和 Keras
- 十八、調試 TensorFlow 模型
- 十九、張量處理單元
- TensorFlow 機器學習秘籍中文第二版
- 一、TensorFlow 入門
- 二、TensorFlow 的方式
- 三、線性回歸
- 四、支持向量機
- 五、最近鄰方法
- 六、神經網絡
- 七、自然語言處理
- 八、卷積神經網絡
- 九、循環神經網絡
- 十、將 TensorFlow 投入生產
- 十一、更多 TensorFlow
- 與 TensorFlow 的初次接觸
- 前言
- 1.?TensorFlow 基礎知識
- 2. TensorFlow 中的線性回歸
- 3. TensorFlow 中的聚類
- 4. TensorFlow 中的單層神經網絡
- 5. TensorFlow 中的多層神經網絡
- 6. 并行
- 后記
- TensorFlow 學習指南
- 一、基礎
- 二、線性模型
- 三、學習
- 四、分布式
- TensorFlow Rager 教程
- 一、如何使用 TensorFlow Eager 構建簡單的神經網絡
- 二、在 Eager 模式中使用指標
- 三、如何保存和恢復訓練模型
- 四、文本序列到 TFRecords
- 五、如何將原始圖片數據轉換為 TFRecords
- 六、如何使用 TensorFlow Eager 從 TFRecords 批量讀取數據
- 七、使用 TensorFlow Eager 構建用于情感識別的卷積神經網絡(CNN)
- 八、用于 TensorFlow Eager 序列分類的動態循壞神經網絡
- 九、用于 TensorFlow Eager 時間序列回歸的遞歸神經網絡
- TensorFlow 高效編程
- 圖嵌入綜述:問題,技術與應用
- 一、引言
- 三、圖嵌入的問題設定
- 四、圖嵌入技術
- 基于邊重構的優化問題
- 應用
- 基于深度學習的推薦系統:綜述和新視角
- 引言
- 基于深度學習的推薦:最先進的技術
- 基于卷積神經網絡的推薦
- 關于卷積神經網絡我們理解了什么
- 第1章概論
- 第2章多層網絡
- 2.1.4生成對抗網絡
- 2.2.1最近ConvNets演變中的關鍵架構
- 2.2.2走向ConvNet不變性
- 2.3時空卷積網絡
- 第3章了解ConvNets構建塊
- 3.2整改
- 3.3規范化
- 3.4匯集
- 第四章現狀
- 4.2打開問題
- 參考
- 機器學習超級復習筆記
- Python 遷移學習實用指南
- 零、前言
- 一、機器學習基礎
- 二、深度學習基礎
- 三、了解深度學習架構
- 四、遷移學習基礎
- 五、釋放遷移學習的力量
- 六、圖像識別與分類
- 七、文本文件分類
- 八、音頻事件識別與分類
- 九、DeepDream
- 十、自動圖像字幕生成器
- 十一、圖像著色
- 面向計算機視覺的深度學習
- 零、前言
- 一、入門
- 二、圖像分類
- 三、圖像檢索
- 四、對象檢測
- 五、語義分割
- 六、相似性學習
- 七、圖像字幕
- 八、生成模型
- 九、視頻分類
- 十、部署
- 深度學習快速參考
- 零、前言
- 一、深度學習的基礎
- 二、使用深度學習解決回歸問題
- 三、使用 TensorBoard 監控網絡訓練
- 四、使用深度學習解決二分類問題
- 五、使用 Keras 解決多分類問題
- 六、超參數優化
- 七、從頭開始訓練 CNN
- 八、將預訓練的 CNN 用于遷移學習
- 九、從頭開始訓練 RNN
- 十、使用詞嵌入從頭開始訓練 LSTM
- 十一、訓練 Seq2Seq 模型
- 十二、深度強化學習
- 十三、生成對抗網絡
- TensorFlow 2.0 快速入門指南
- 零、前言
- 第 1 部分:TensorFlow 2.00 Alpha 簡介
- 一、TensorFlow 2 簡介
- 二、Keras:TensorFlow 2 的高級 API
- 三、TensorFlow 2 和 ANN 技術
- 第 2 部分:TensorFlow 2.00 Alpha 中的監督和無監督學習
- 四、TensorFlow 2 和監督機器學習
- 五、TensorFlow 2 和無監督學習
- 第 3 部分:TensorFlow 2.00 Alpha 的神經網絡應用
- 六、使用 TensorFlow 2 識別圖像
- 七、TensorFlow 2 和神經風格遷移
- 八、TensorFlow 2 和循環神經網絡
- 九、TensorFlow 估計器和 TensorFlow HUB
- 十、從 tf1.12 轉換為 tf2
- TensorFlow 入門
- 零、前言
- 一、TensorFlow 基本概念
- 二、TensorFlow 數學運算
- 三、機器學習入門
- 四、神經網絡簡介
- 五、深度學習
- 六、TensorFlow GPU 編程和服務
- TensorFlow 卷積神經網絡實用指南
- 零、前言
- 一、TensorFlow 的設置和介紹
- 二、深度學習和卷積神經網絡
- 三、TensorFlow 中的圖像分類
- 四、目標檢測與分割
- 五、VGG,Inception,ResNet 和 MobileNets
- 六、自編碼器,變分自編碼器和生成對抗網絡
- 七、遷移學習
- 八、機器學習最佳實踐和故障排除
- 九、大規模訓練
- 十、參考文獻