
# 五、高級卷積神經網絡
在本章中,我們將討論如何將**卷積神經網絡**(**CNN**)用于除圖像以外的領域中的深度學習。 我們的注意力將首先集中在文本分析和**自然語言處理**(**NLP**)上。 在本章中,我們將介紹一些用于以下方面的方法:
* 創建卷積網絡進行情感分析
* 檢查 VGG 預建網絡學習了哪些過濾器
* 使用 VGGNet,ResNet,Inception 和 Xception 對圖像進行分類
* 復用預先構建的深度學習模型來提取特征
* 用于遷移學習的非常深的 Inception-v3 網絡
* 使用膨脹的 ConvNets,WaveNet 和 NSynth 生成音樂
* 回答有關圖像的問題(可視化問答)
* 使用預訓練網絡通過六種不同方式來分類視頻
# 介紹
在上一章中,我們了解了如何將 ConvNets 應用于圖像。 在本章中,我們將類似的思想應用于文本。
文本和圖像有什么共同點? 乍一看,很少。 但是,如果我們將句子或文檔表示為矩陣,則此矩陣與每個單元都是像素的圖像矩陣沒有區別。 因此,下一個問題是,我們如何將文本表示為矩陣? 好吧,這很簡單:矩陣的每一行都是一個向量,代表文本的基本單位。 當然,現在我們需要定義什么是基本單位。 一個簡單的選擇就是說基本單位是一個字符。 另一個選擇是說基本單位是一個單詞,另一個選擇是將相似的單詞聚合在一起,然后用代表符號表示每個聚合(有時稱為簇或嵌入)。
請注意,無論我們的基本單位采用哪種具體選擇,我們都需要從基本單位到整數 ID 的 1:1 映射,以便可以將文本視為矩陣。 例如,如果我們有一個包含 10 行文本的文檔,并且每行都是 100 維嵌入,那么我們將用`10 x 100`的矩陣表示文本。 在這個非常特殊的圖像中,如果該句子`x`包含位置`y`表示的嵌入,則打開像素。 您可能還會注意到,文本實際上不是矩陣,而是向量,因為位于文本相鄰行中的兩個單詞幾乎沒有共同點。 確實,與圖像的主要區別在于,相鄰列中的兩個像素最有可能具有某種相關性。
現在您可能會想:我知道您將文本表示為向量,但是這樣做會使我們失去單詞的位置,而這個位置應該很重要,不是嗎?
好吧,事實證明,在許多實際應用中,知道一個句子是否包含特定的基本單位(一個字符,一個單詞或一個合計)是非常準確的信息,即使我們不記住句子中的確切位置也是如此。 基本單元位于。
# 創建用于情感分析的卷積網絡
在本秘籍中,我們將使用 TFLearn 創建基于 CNN 的情感分析深度學習網絡。 如上一節所述,我們的 CNN 將是一維的。 我們將使用 IMDb 數據集,用于訓練的 45,000 個高度受歡迎的電影評論和用于測試的 5,000 個集合。
# 準備
TFLearn 具有用于自動從網絡下載數據集并促進卷積網絡創建的庫,因此讓我們直接看一下代碼。
# 操作步驟
我們按以下步驟進行:
1. 導入 TensorFlow `tflearn`和構建網絡所需的模塊。 然后,導入 IMDb 庫并執行一鍵編碼和填充:
```py
import tensorflow as tf
import tflearn
from tflearn.layers.core import input_data, dropout, fully_connected
from tflearn.layers.conv import conv_1d, global_max_pool
from tflearn.layers.merge_ops import merge
from tflearn.layers.estimator import regression
from tflearn.data_utils import to_categorical, pad_sequences
from tflearn.datasets import imdb
```
2. 加載數據集,將句子填充到最大長度為 0 的位置,并對標簽執行兩個編碼,分別對應于真值和假值的兩個值。 注意,參數`n_words`是要保留在詞匯表中的單詞數。 所有多余的單詞都設置為未知。 另外,請注意`trainX`和`trainY`是稀疏向量,因為每個評論很可能包含整個單詞集的子集:
```py
# IMDb Dataset loading
train, test, _ = imdb.load_data(path='imdb.pkl', n_words=10000,
valid_portion=0.1)
trainX, trainY = train
testX, testY = test
#pad the sequence
trainX = pad_sequences(trainX, maxlen=100, value=0.)
testX = pad_sequences(testX, maxlen=100, value=0.)
#one-hot encoding
trainY = to_categorical(trainY, nb_classes=2)
testY = to_categorical(testY, nb_classes=2)
```
3. 打印一些維度以檢查剛剛處理的數據并了解問題的維度是什么:
```py
print ("size trainX", trainX.size)
print ("size testX", testX.size)
print ("size testY:", testY.size)
print ("size trainY", trainY.size)
size trainX 2250000
size testX 250000
size testY: 5000
site trainY 45000
```
4. 為數據集中包含的文本構建嵌入。 就目前而言,將此步驟視為一個黑盒子,該黑盒子接受這些單詞并將它們映射到聚合(群集)中,以便相似的單詞可能出現在同一群集中。 請注意,先前步驟的詞匯是離散且稀疏的。 通過嵌入,我們將創建一個映射,該映射會將每個單詞嵌入到連續的密集向量空間中。 使用此向量空間表示將為我們提供詞匯表的連續,分布式表示。 當我們談論 RNN 時,將詳細討論如何構建嵌入:
```py
# Build an embedding
network = input_data(shape=[None, 100], name='input')
network = tflearn.embedding(network, input_dim=10000, output_dim=128)
```
5. 建立一個合適的`convnet`。 我們有三個卷積層。 由于我們正在處理文本,因此我們將使用一維卷積網絡,并且各層將并行運行。 每層采用大小為 128 的張量(嵌入的輸出),并應用有效填充,激活函數 ReLU 和 L2 `regularizer`的多個濾波器(分別為 3、4、5)。 然后,將每個層的輸出與合并操作連接在一起。 此后,添加一個最大池層,然后以 50% 的概率進行刪除。 最后一層是具有 softmax 激活的完全連接層:
```py
#Build the convnet
branch1 = conv_1d(network, 128, 3, padding='valid', activation='relu', regularizer="L2")
branch2 = conv_1d(network, 128, 4, padding='valid', activation='relu', regularizer="L2")
branch3 = conv_1d(network, 128, 5, padding='valid', activation='relu', regularizer="L2")
network = merge([branch1, branch2, branch3], mode='concat', axis=1)
network = tf.expand_dims(network, 2)
network = global_max_pool(network)
network = dropout(network, 0.5)
network = fully_connected(network, 2, activation='softmax')
```
6. 學習階段意味著使用`categorical_crossentropy`作為損失函數的 Adam 優化器:
```py
network = regression(network, optimizer='adam', learning_rate=0.001,
loss='categorical_crossentropy', name='target')
```
7. 然后,我們使用`batch_size = 32`運行訓練,并觀察訓練和驗證集達到的準確率。 如您所見,在預測電影評論所表達的情感方面,我們能夠獲得 79% 的準確率:
```py
# Training
model = tflearn.DNN(network, tensorboard_verbose=0)
model.fit(trainX, trainY, n_epoch = 5, shuffle=True, validation_set=(testX, testY), show_metric=True, batch_size=32)
Training Step: 3519 | total loss: 0.09738 | time: 85.043s
| Adam | epoch: 005 | loss: 0.09738 - acc: 0.9747 -- iter: 22496/22500
Training Step: 3520 | total loss: 0.09733 | time: 86.652s
| Adam | epoch: 005 | loss: 0.09733 - acc: 0.9741 | val_loss: 0.58740 - val_acc: 0.7944 -- iter: 22500/22500
--
```
# 工作原理
[用于句子分類的卷積神經網絡,Yoon Kim,EMNLP 2014](https://arxiv.org/abs/1408.5882)。 請注意,由于篩選器窗口對連續單詞進行操作,因此本文提出的模型保留了一些有關位置的信息。 從論文中提取的以下圖像以圖形方式表示了網絡之外的主要直覺。 最初,文本被表示為基于標準嵌入的向量,從而為我們提供了一維密集空間中的緊湊表示。 然后,使用多個標準一維卷積層處理矩陣。
請注意,模型使用多個過濾器(窗口大小不同)來獲取多個特征。 之后,進行最大池操作,其思想是捕獲最重要的特征-每個特征圖的最大值。 為了進行正則化,該文章建議在倒數第二層上采用對權重向量的 L2 范數有約束的丟棄項。 最后一層將輸出情感為正或負。
為了更好地理解該模型,有以下幾點觀察:
* 過濾器通常在連續空間上卷積。 對于圖像,此空間是像素矩陣表示形式,在高度和寬度上在空間上是連續的。 對于文本而言,連續空間無非是連續單詞自然產生的連續尺寸。 如果僅使用單次編碼表示的單詞,則空間稀疏;如果使用嵌入,則由于聚集了相似的單詞,因此生成的空間密集。
* 圖像通常具有三個通道(RGB),而文本自然只有一個通道,因為我們無需表示顏色。
# 更多
論文[《用于句子分類的卷積神經網絡》](https://arxiv.org/abs/1408.5882)(Yoon Kim,EMNLP 2014)進行了廣泛的實驗。 盡管對超參數的調整很少,但具有一層卷積的簡單 CNN 在句子分類方面的表現卻非常出色。 該論文表明,采用一組靜態嵌入(將在我們談論 RNN 時進行討論),并在其之上構建一個非常簡單的卷積網絡,實際上可以顯著提高情感分析的表現:
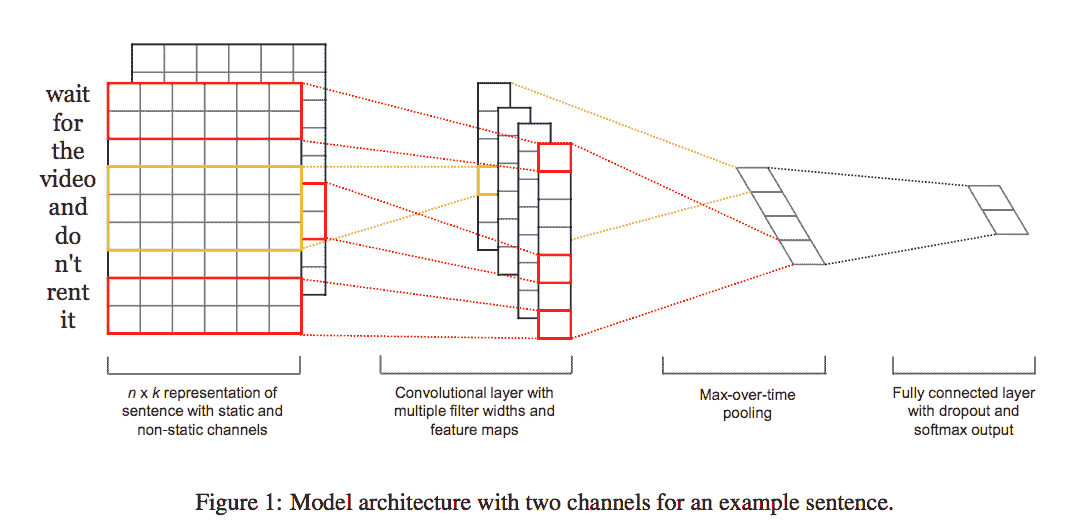
[如圖所示的模型架構示例](https://arxiv.org/pdf/1408.5882.pdf)
使用 CNN 進行文本分析是一個活躍的研究領域。 我建議看看以下文章:
* [《從頭開始理解文本》](https://arxiv.org/abs/1502.01710)(張翔,Yann LeCun)。 本文演示了我們可以使用 CNN 將深度學習應用于從字符級輸入到抽象文本概念的文本理解。 作者將 CNN 應用于各種大規模數據集,包括本體分類,情感分析和文本分類,并表明它們可以在不了解單詞,詞組,句子或任何其他句法或語義結構的情況下實現驚人的表現。 一種人類的語言。 這些模型適用于英文和中文。
# 檢查 VGG 預建網絡了解了哪些過濾器
在本秘籍中,我們將使用 [keras-vis](https://raghakot.github.io/keras-vis/),這是一個外部 Keras 包,用于直觀檢查預建的 VGG16 網絡從中學到了什么不同的過濾器。 這個想法是選擇一個特定的 ImageNet 類別,并了解 VGG16 網絡如何學會代表它。
# 準備
第一步是選擇用于在 ImageNet 上訓練 VGG16 的特定類別。 假設我們采用類別 20,它對應于下圖中顯示的*美國北斗星*鳥:

[美國北斗星的一個例子](https://commons.wikimedia.org/wiki/File:American_Dipper.jpg)
可以在網上找到 [ImageNet 映射](https://gist.github.com/yrevar/6135f1bd8dcf2e0cc683)作為 python 泡菜字典,其中 ImageNet 1000 類 ID 映射到了人類可讀的標簽。
# 操作步驟
我們按以下步驟進行:
1. 導入 matplotlib 和 keras-vis 使用的模塊。 此外,還導入預構建的 VGG16 模塊。 Keras 使處理此預建網絡變得容易:
```py
from matplotlib import pyplot as plt
from vis.utils import utils
from vis.utils.vggnet import VGG16
from vis.visualization import visualize_class_activation
```
2. 通過使用 Keras 中包含的并經過 ImageNet 權重訓練的預構建層來訪問 VGG16 網絡:
```py
# Build the VGG16 network with ImageNet weights
model = VGG16(weights='imagenet', include_top=True)
model.summary()
print('Model loaded.')
```
3. 這就是 VGG16 網絡在內部的外觀。 我們有許多卷積網絡,與 2D 最大池化交替使用。 然后,我們有一個展開層,然后是三個密集層。 最后一個稱為**預測**,并且這一層應該能夠檢測到高級特征,例如人臉或我們的鳥類形狀。 請注意,頂層已明確包含在我們的網絡中,因為我們想可視化它學到的知識:
```py
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) (None, 224, 224, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 25088) 0
_________________________________________________________________
fc1 (Dense) (None, 4096) 102764544
_________________________________________________________________
fc2 (Dense) (None, 4096) 16781312
_________________________________________________________________
predictions (Dense) (None, 1000) 4097000
=================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
_________________________________________________________________
Model loaded.
```
從外觀上看,網絡可以如下圖所示:

VGG16 網絡
4. 現在,讓我們著重于通過關注 American Dipper(ID 20)來檢查最后一個預測層的內部外觀:
```py
layer_name = 'predictions'
layer_idx = [idx for idx, layer in enumerate(model.layers) if layer.name == layer_name][0]
# Generate three different images of the same output index.
vis_images = []
for idx in [20, 20, 20]:
img = visualize_class_activation(model, layer_idx, filter_indices=idx, max_iter=500)
img = utils.draw_text(img, str(idx))
vis_images.append(img)
```
5. 讓我們在給定特征的情況下顯示特定層的生成圖像,并觀察網絡如何在內部看到*美國北斗星*鳥的概念:
因此,這就是神經網絡在內部代表鳥類的方式。 這是一種令人毛骨悚然的形象,但我發誓沒有為網絡本身提供任何特定種類的人造藥物! 這正是這種特殊的人工網絡自然學到的東西。
6. 您是否仍然想了解更多? 好吧,讓我們選擇一個較早的層,并代表網絡如何在內部看到相同的`American Dipper`訓練類別:
```py
layer_name = 'block3_conv1'
layer_idx = [idx for idx, layer in enumerate(model.layers) if layer.name == layer_name][0]
vis_images = []
for idx in [20, 20, 20]:
img = visualize_class_activation(model, layer_idx, filter_indices=idx, max_iter=500)
img = utils.draw_text(img, str(idx))
vis_images.append(img)
stitched = utils.stitch_images(vis_images)
plt.axis('off')
plt.imshow(stitched)
plt.title(layer_name)
plt.show()
```
以下是上述代碼的輸出:

不出所料,該特定層正在學習非常基本的特征,例如曲線。 但是,卷積網絡的真正力量在于,隨著我們對模型的深入研究,網絡會推斷出越來越復雜的特征。
# 工作原理
密集層的 keras-vis 可視化的關鍵思想是生成一個輸入圖像,該圖像最大化與鳥類類相對應的最終密集層輸出。 因此,實際上該模塊的作用是解決問題。 給定具有權重的特定訓練密集層,將生成一個新的合成圖像,它最適合該層本身。
每個轉換濾波器都使用類似的想法。 在這種情況下,請注意,由于卷積網絡層在原始像素上運行,因此可以通過簡單地可視化其權重來解釋它。 后續的卷積過濾器對先前的卷積過濾器的輸出進行操作,因此直接可視化它們不一定很有解釋性。 但是,如果我們獨立地考慮每一層,我們可以專注于僅生成可最大化濾波器輸出的合成輸入圖像。
# 更多
GitHub 上的 [keras-vis 存儲庫](https://github.com/raghakot/keras-vis)提供了一組很好的可視化示例,這些示例說明了如何內部檢查網絡,包括最近的顯著性映射,其目的是在圖像經常包含其他元素(例如草)時檢測圖像的哪個部分對特定類別(例如老虎)的訓練貢獻最大。 種子文章是[《深度卷積網絡:可視化圖像分類模型和顯著性圖》](https://arxiv.org/abs/1312.6034)(Karen Simonyan,Andrea Vedaldi,Andrew Zisserman),并在下面報告了從 Git 存儲庫中提取的示例,在該示例中,網絡可以自行了解*定義為*老虎的圖像中最突出的部分是:

[顯著性映射的示例](https://github.com/raghakot/keras-vis)
# 將 VGGNet,ResNet,Inception 和 Xception 用于圖像分類
圖像分類是典型的深度學習應用。 由于 [ImageNet](http://image-net.org/) 圖像數據庫,該任務的興趣有了最初的增長。 它按照 [WordNet](http://wordnet.princeton.edu/) 層次結構(目前僅是名詞)來組織,其中每個節點都由成百上千的圖像描繪。 更準確地說,ImageNet 旨在將圖像標記和分類為將近 22,000 個單獨的對象類別。 在深度學習的背景下,ImageNet 通常指的是 [ImageNet 大規模視覺識別挑戰](http://www.image-net.org/challenges/LSVRC/),或簡稱 ILSVRC 中包含的工作。在這種情況下,目標是訓練一個模型,該模型可以將輸入圖像分類為 1,000 個單獨的對象類別。 在此秘籍中,我們將使用超過 120 萬個訓練圖像,50,000 個驗證圖像和 100,000 個測試圖像的預訓練模型。
# VGG16 和 VGG19
在[《用于大型圖像識別的超深度卷積網絡》](https://arxiv.org/abs/1409.1556)(Karen Simonyan,Andrew Zisserman,2014 年)中,引入了 VGG16 和 VGG19。 該網絡使用`3×3`卷積層堆疊并與最大池交替,兩個 4096 個全連接層,然后是 softmax 分類器。 16 和 19 代表網絡中權重層的數量(列 D 和 E):
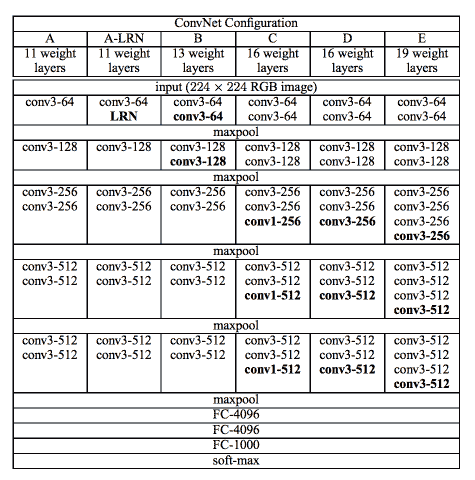
[一個非常深的網絡配置示例](https://arxiv.org/pdf/1409.1556.pdf)
在 2015 年,擁有 16 或 19 層就足以考慮網絡的深度,而今天(2017 年)我們達到了數百層。 請注意,VGG 網絡的訓練速度非常慢,并且由于末端的深度和完全連接的層數,它們需要較大的權重空間。
# ResNet
ResNet 已在[《用于圖像識別的深度殘差學習》](https://arxiv.org/abs/1512.03385)(何開明,張向宇,任少青,孫健,2015)中引入。 該網絡非常深,可以使用稱為殘差模塊的標準網絡組件使用標準的隨機下降梯度進行訓練,然后使用該網絡組件組成更復雜的網絡(該網絡在網絡中稱為子網絡)。
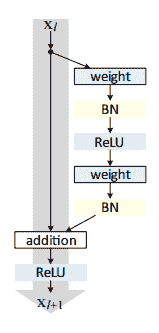
與 VGG 相比,ResNet 更深,但是模型的大小更小,因為使用了全局平均池化操作而不是全密層。
# Inception
在[《重新思考計算機視覺的初始架構》](https://arxiv.org/abs/1512.00567)(Christian Szegedy,Vincent Vanhoucke,Sergey Ioffe,Jonathon Shlens,Zbigniew Wojna,2015 年)中引入了 Inception 。關鍵思想是在同一模塊中具有多種大小的卷積作為特征提取并計算`1×1`、`3×3`和`5×5`卷積。 這些濾波器的輸出然后沿著通道尺寸堆疊,并發送到網絡的下一層。 下圖對此進行了描述:
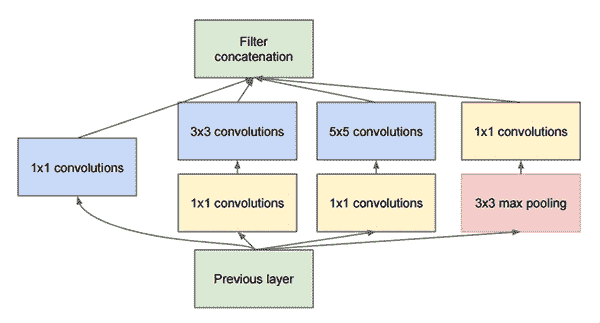
在“重新思考計算機視覺的 Inception 架構”中描述了 Inception-v3,而在[《Inception-v4,Inception-ResNet 和殘余連接對學習的影響》](https://arxiv.org/abs/1602.07261)(Szegedy,Sergey Ioffe,Vincent Vanhoucke,Alex Alemi,2016 年)中描述了 Inception-v4。
# Xception
Xception 是 Inception 的擴展,在[《Xception:具有深度可分離卷積的深度學習》](https://arxiv.org/abs/1610.02357)(Fran?oisChollet,2016 年)中引入。 Xception 使用一種稱為深度可分離卷積運算的新概念,該概念使其在包含 3.5 億張圖像和 17,000 個類別的大型圖像分類數據集上的表現優于 Inception-v3。 由于 Xception 架構具有與 Inception-v3 相同數量的參數,因此表現的提高并不是由于容量的增加,而是由于模型參數的更有效使用。
# 準備
此秘籍使用 Keras,因為該框架已預先完成了上述模塊的實現。 Keras 首次使用時會自動下載每個網絡的權重,并將這些權重存儲在本地磁盤上。 換句話說,您不需要重新訓練網絡,而是可以利用互聯網上已經可用的訓練。 在您希望將網絡分類為 1000 個預定義類別的假設下,這是正確的。 在下一個秘籍中,我們將了解如何從這 1,000 個類別開始,并通過稱為遷移學習的過程將它們擴展到自定義集合。
# 操作步驟
我們按以下步驟進行:
1. 導入處理和顯示圖像所需的預建模型和其他模塊:
```py
from keras.applications import ResNet50
from keras.applications import InceptionV3
from keras.applications import Xception # TensorFlow ONLY
from keras.applications import VGG16
from keras.applications import VGG19
from keras.applications import imagenet_utils
from keras.applications.inception_v3 import preprocess_input
from keras.preprocessing.image import img_to_array
from keras.preprocessing.image import load_img
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.pyplot import imshow
from PIL import Image
%matplotlib inline
```
2. 定義用于記憶用于訓練網絡的圖像大小的映射。 這些是每個模型的眾所周知的常數:
```py
MODELS = {
"vgg16": (VGG16, (224, 224)),
"vgg19": (VGG19, (224, 224)),
"inception": (InceptionV3, (299, 299)),
"xception": (Xception, (299, 299)), # TensorFlow ONLY
"resnet": (ResNet50, (224, 224))
}
```
3. 定義用于加載和轉換每個圖像的輔助函數。 注意,預訓練網絡已在張量上訓練,該張量的形狀還包括`batch_size`的附加維度。 因此,我們需要將此尺寸添加到圖像中以實現兼容性:
```py
def image_load_and_convert(image_path, model):
pil_im = Image.open(image_path, 'r')
imshow(np.asarray(pil_im))
# initialize the input image shape
# and the pre-processing function (this might need to be changed
inputShape = MODELS[model][1]
preprocess = imagenet_utils.preprocess_input
image = load_img(image_path, target_size=inputShape)
image = img_to_array(image)
# the original networks have been trained on an additional
# dimension taking into account the batch size
# we need to add this dimension for consistency
# even if we have one image only
image = np.expand_dims(image, axis=0)
image = preprocess(image)
return image
```
4. 定義用于對圖像進行分類的輔助函數,并在預測上循環,并顯示 5 級預測以及概率:
```py
def classify_image(image_path, model):
img = image_load_and_convert(image_path, model)
Network = MODELS[model][0]
model = Network(weights="imagenet")
preds = model.predict(img)
P = imagenet_utils.decode_predictions(preds)
# loop over the predictions and display the rank-5 predictions
# along with probabilities
for (i, (imagenetID, label, prob)) in enumerate(P[0]):
print("{}. {}: {:.2f}%".format(i + 1, label, prob * 100))
```
5.然后開始測試不同類型的預訓練網絡:
```py
classify_image("images/parrot.jpg", "vgg16")
```
接下來,您將看到具有相應概率的預測列表:
1.金剛鸚鵡:99.92%
2.美洲豹:0.03%
3.澳洲鸚鵡:0.02%
4.蜂食者:0.02%
5.巨嘴鳥:0.00%
[金剛鸚鵡的一個例子](https://commons.wikimedia.org/wiki/File:Blue-and-Yellow-Macaw.jpg)
```py
classify_image("images/parrot.jpg", "vgg19")
```
1.金剛鸚鵡:99.77%
2.鸚鵡:0.07%
3.巨嘴鳥:0.06%
4.犀鳥:0.05%
5.賈卡馬爾:0.01%

```py
classify_image("images/parrot.jpg", "resnet")
```
1.金剛鸚鵡:97.93%
2.孔雀:0.86%
3.鸚鵡:0.23%
4\. j:0.12%
5.杰伊:0.12%
```py
classify_image("images/parrot_cropped1.jpg", "resnet")
```
1.金剛鸚鵡:99.98%
2.鸚鵡:0.00%
3.孔雀:0.00%
4.硫鳳頭鸚鵡:0.00%
5.巨嘴鳥:0.00%
```py
classify_image("images/incredible-hulk-180.jpg", "resnet")
```
1\. comic_book:99.76%
2\. book_jacket:0.19%
3.拼圖游戲:0.05%
4.菜單:0.00%
5.數據包:0.00%

[如中所示的漫畫分類示例](https://comicvine.gamespot.com/the-incredible-hulk-180-and-the-wind-howls-wendigo/4000-14667/)
```py
classify_image("images/cropped_panda.jpg", "resnet")
```
大熊貓:99.04%
2.英迪爾:0.59%
3.小熊貓:0.17%
4.長臂猿:0.07%
5\. titi:0.05%
```py
classify_image("images/space-shuttle1.jpg", "resnet")
```
1.航天飛機:92.38%
2.三角恐龍:7.15%
3.戰機:0.11%
4.牛仔帽:0.10%
5.草帽:0.04%

```py
classify_image("images/space-shuttle2.jpg", "resnet")
```
1.航天飛機:99.96%
2.導彈:0.03%
3.彈丸:0.00%
4.蒸汽機車:0.00%
5.戰機:0.00%
```py
classify_image("images/space-shuttle3.jpg", "resnet")
```
1.航天飛機:93.21%
2.導彈:5.53%
3.彈丸:1.26%
4.清真寺:0.00%
5.信標:0.00%
```py
classify_image("images/space-shuttle4.jpg", "resnet")
```
1.航天飛機:49.61%
2.城堡:8.17%
3.起重機:6.46%
4.導彈:4.62%
5.航空母艦:4.24%

請注意,可能會出現一些錯誤。 例如:
```py
classify_image("images/parrot.jpg", "inception")
```
1.秒表:100.00%
2.貂皮:0.00%
3.錘子:0.00%
4.黑松雞:0.00%
5.網站:0.00%

```py
classify_image("images/parrot.jpg", "xception")
```
1.背包:56.69%
2.軍裝:29.79%
3.圍兜:8.02%
4.錢包:2.14%
5.乒乓球:1.52%

6. 定義一個輔助函數,用于顯示每個預構建和預訓練網絡的內部架構:
```py
def print_model(model):
print ("Model:",model)
Network = MODELS[model][0]
model = Network(weights="imagenet")
model.summary()
print_model('vgg19')
```
```py
('Model:', 'vgg19')
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_14 (InputLayer) (None, 224, 224, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv4 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv4 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv4 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 25088) 0
_________________________________________________________________
fc1 (Dense) (None, 4096) 102764544
_________________________________________________________________
fc2 (Dense) (None, 4096) 16781312
_________________________________________________________________
predictions (Dense) (None, 1000) 4097000
=================================================================
Total params: 143,667,240
Trainable params: 143,667,240
Non-trainable params: 0
```
# 工作原理
我們使用了 Keras 應用,預訓練的 Keras 學習模型,該模型隨預訓練的權重一起提供。 這些模型可用于預測,特征提取和微調。 在這種情況下,我們將模型用于預測。 我們將在下一個秘籍中看到如何使用模型進行微調,以及如何在最初訓練模型時最初不可用的數據集上構建自定義分類器。
# 更多
截至 2017 年 7 月,Inception-v4 尚未在 Keras 中直接提供,但可以作為單獨的模塊[在線下載](https://github.com/kentsommer/keras-inceptionV4)。 安裝后,該模塊將在首次使用時自動下載砝碼。
AlexNet 是最早的堆疊式深層網絡之一,它僅包含八層,前五層是卷積層,然后是全連接層。 該網絡是在 2012 年提出的,明顯優于第二名(前五名的錯誤率為 16%,而第二名的錯誤率為 26% )。
關于深度神經網絡的最新研究主要集中在提高準確率上。 較小的 DNN 架構具有同等的準確率,至少具有三個優點:
* 較小的 CNN 在分布式訓練期間需要較少的跨服務器通信。
* 較小的 CNN 需要較少的帶寬才能將新模型從云導出到提供模型的位置。
* 較小的 CNN 在具有有限內存的 FPGA 和其他硬件上部署更可行。 為了提供所有這些優點,SqueezeNet 在??論文 [SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size](https://arxiv.org/abs/1602.07360) 中提出。 SqueezeNet 通過減少 50 倍的參數在 ImageNet 上達到 AlexNet 級別的準確率。 此外,借助模型壓縮技術,我們可以將 SqueezeNet 壓縮到小于 0.5 MB(比 AlexNet 小 510 倍)。 Keras 將 SqueezeNet [作為單獨的模塊在線實現](https://github.com/DT42/squeezenet_demo)。
# 復用預建的深度學習模型來提取特征
在本秘籍中,我們將看到如何使用深度學習來提取相關特征
# 準備
一個非常簡單的想法是通常使用 VGG16 和 DCNN 進行特征提取。 該代碼通過從特定層提取特征來實現該想法。
# 操作步驟
我們按以下步驟進行:
1. 導入處理和顯示圖像所需的預建模型和其他模塊:
```py
from keras.applications.vgg16 import VGG16
from keras.models import Model
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input
import numpy as np
```
2. 從網絡中選擇一個特定的層,并獲得作為輸出生成的特征:
```py
# pre-built and pre-trained deep learning VGG16 model
base_model = VGG16(weights='imagenet', include_top=True)
for i, layer in enumerate(base_model.layers):
print (i, layer.name, layer.output_shape)
# extract features from block4_pool block
model =
Model(input=base_model.input, output=base_model.get_layer('block4_pool').output)
```
3. 提取給定圖像的特征,如以下代碼片段所示:
```py
img_path = 'cat.jpg'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
# get the features from this block
features = model.predict(x)
```
# 工作原理
現在,您可能想知道為什么我們要從 CNN 的中間層提取特征。 關鍵的直覺是:隨著網絡學會將圖像分類,各層學會識別進行最終分類所必需的特征。
較低的層標識較低階的特征(例如顏色和邊緣),較高的層將這些較低階的特征組合為較高階的特征(例如形狀或對象)。 因此,中間層具有從圖像中提取重要特征的能力,并且這些特征更有可能有助于不同種類的分類。
這具有多個優點。 首先,我們可以依靠公開提供的大規模訓練,并將這種學習遷移到新穎的領域。 其次,我們可以節省昂貴的大型訓練時間。 第三,即使我們沒有針對該領域的大量訓練示例,我們也可以提供合理的解決方案。 對于手頭的任務,我們也有一個很好的起始網絡形狀,而不是猜測它。
# 用于遷移學習的非常深的 InceptionV3 網絡
遷移學習是一種非常強大的深度學習技術,在不同領域中有更多應用。 直覺非常簡單,可以用類推來解釋。 假設您想學習一種新的語言,例如西班牙語,那么從另一種語言(例如英語)已經知道的內容開始可能會很有用。
按照這種思路,計算機視覺研究人員現在通常使用經過預訓練的 CNN 來生成新任務的表示形式,其中數據集可能不足以從頭訓練整個 CNN。 另一個常見的策略是采用經過預先訓練的 ImageNet 網絡,然后將整個網絡微調到新穎的任務。
InceptionV3 Net 是 Google 開發的非常深入的卷積網絡。 Keras 實現了整個網絡,如下圖所示,并且已在 ImageNet 上進行了預訓練。 該模型的默認輸入大小在三個通道上為`299x299`:
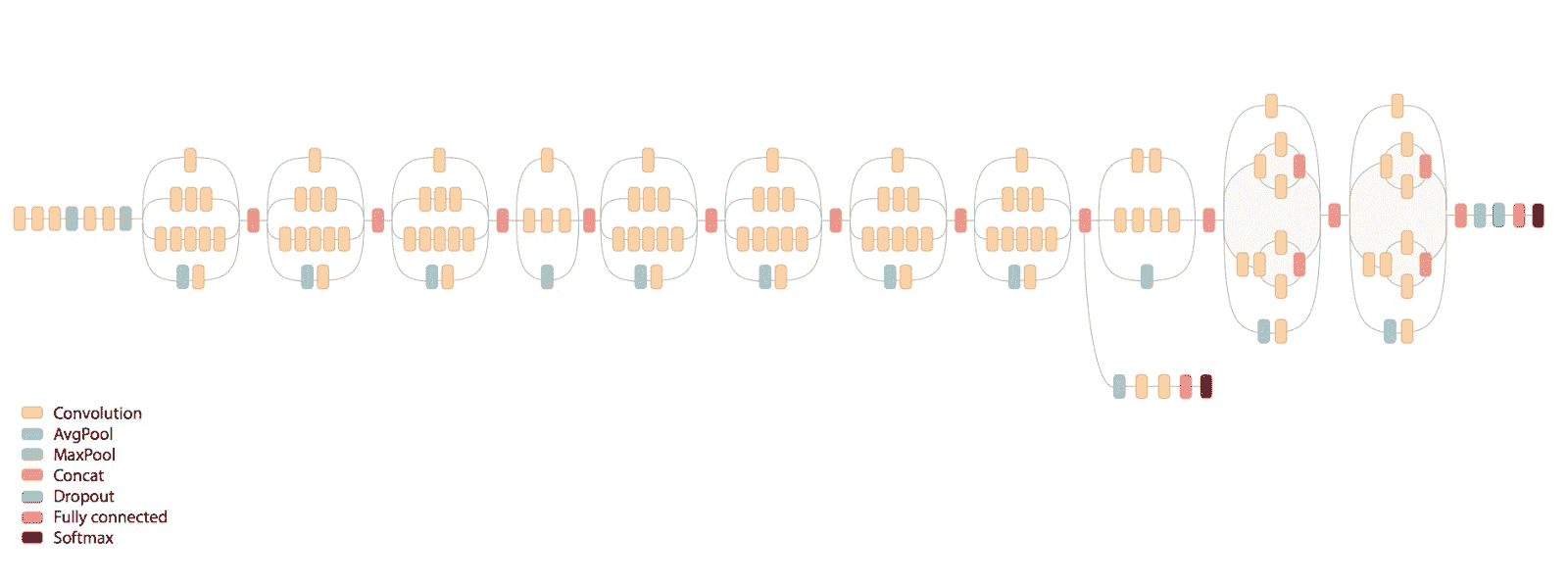
ImageNet v3 的示例
# 準備
此框架示例受到 [Keras 網站上在線提供的方案](https://keras.io/applications/)的啟發。 我們假設在與 ImageNet 不同的域中具有訓練數據集 D。 D 在輸入中具有 1,024 個特征,在輸出中具有 200 個類別。
# 操作步驟
我們可以按照以下步驟進行操作:
1. 導入處理所需的預建模型和其他模塊:
```py
from keras.applications.inception_v3 import InceptionV3
from keras.preprocessing import image
from keras.models import Model
from keras.layers import Dense, GlobalAveragePooling2D
from keras import backend as K
# create the base pre-trained model
base_model = InceptionV3(weights='imagenet', include_top=False)
```
2. 我們使用訓練有素的 Inception-v3,但我們不包括頂級模型,因為我們要在 D 上進行微調。頂層是具有 1,024 個輸入的密集層,最后一個輸出是具有 200 類輸出的 softmax 密集層。 `x = GlobalAveragePooling2D()(x)`用于將輸入轉換為密集層要處理的正確形狀。 實際上,`base_model.output`張量具有`dim_ordering="th"`的形狀(樣本,通道,行,列),`dim_ordering="tf"`具有(樣本,行,列,通道),但是密集層需要`GlobalAveragePooling2D`計算(行,列)平均值,將它們轉換為(樣本,通道)。 因此,如果查看最后四層(在`include_top=True`中),則會看到以下形狀:
```py
# layer.name, layer.input_shape, layer.output_shape
('mixed10', [(None, 8, 8, 320), (None, 8, 8, 768), (None, 8, 8, 768), (None, 8, 8, 192)], (None, 8, 8, 2048))
('avg_pool', (None, 8, 8, 2048), (None, 1, 1, 2048))
('flatten', (None, 1, 1, 2048), (None, 2048))
('predictions', (None, 2048), (None, 1000))
```
3. 當包含`_top=False`時,將除去最后三層并暴露`mixed_10`層,因此`GlobalAveragePooling2D`層將`(None, 8, 8, 2048)`轉換為`(None, 2048)`,其中`(None, 2048)`張量中的每個元素都是`(None, 8, 8, 2048)`張量中每個對應的`(8, 8)`張量的平均值:
```py
# add a global spatial average pooling layer
x = base_model.output
x = GlobalAveragePooling2D()(x)
# let's add a fully-connected layer as first layer
x = Dense(1024, activation='relu')(x)
# and a logistic layer with 200 classes as last layer
predictions = Dense(200, activation='softmax')(x)
# model to train
model = Model(input=base_model.input, output=predictions)
```
4. 所有卷積級別都經過預訓練,因此我們在訓練完整模型時將其凍結。
```py
# i.e. freeze all convolutional Inception-v3 layers
for layer in base_model.layers:
layer.trainable = False
```
5. 然后,對模型進行編譯和訓練幾個周期,以便對頂層進行訓練:
```py
# compile the model (should be done *after* setting layers to non-trainable)
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
# train the model on the new data for a few epochs
model.fit_generator(...)
```
6. 然后我們凍結 Inception 中的頂層并微調 Inception 層。 在此示例中,我們凍結了前 172 層(要調整的超參數):
```py
# we chose to train the top 2 inception blocks, i.e. we will freeze
# the first 172 layers and unfreeze the rest:
for layer in model.layers[:172]:
layer.trainable = False
for layer in model.layers[172:]:
layer.trainable = True
```
7. 然后重新編譯模型以進行微調優化。 我們需要重新編譯模型,以使這些修改生效:
```py
# we use SGD with a low learning rate
from keras.optimizers import SGD
model.compile(optimizer=SGD(lr=0.0001, momentum=0.9), loss='categorical_crossentropy')
# we train our model again (this time fine-tuning the top 2 inception blocks
# alongside the top Dense layers
model.fit_generator(...)
```
# 工作原理
現在,我們有了一個新的深度網絡,該網絡可以重用標準的 Inception-v3 網絡,但可以通過遷移學習在新的域 D 上進行訓練。 當然,有許多參數需要微調以獲得良好的精度。 但是,我們現在正在通過遷移學習重新使用非常龐大的預訓練網絡作為起點。 這樣,我們可以通過重復使用 Keras 中已經可用的內容來節省對機器進行訓練的需求。
# 更多
截至 2017 年,“計算機視覺”問題意味著在圖像中查找圖案的問題可以視為已解決,并且此問題影響了我們的生活。 例如:
* [《皮膚科醫師對具有深層神經網絡的皮膚癌的分類》](https://www.nature.com/nature/journal/v542/n7639/full/nature21056.html)(Andre Esteva,Brett Kuprel,Roberto A. Novoa,Justin Ko,Susan M. Swetter,Helen M. Blau & Sebastian Thrun,2017 年)使用 129450 個臨床圖像的數據集訓練 CNN,該圖像由 2032 種不同疾病組成。 他們在 21 個經過董事會認證的皮膚科醫生的活檢驗證的臨床圖像上對結果進行了測試,并使用了兩個關鍵的二元分類用例:角質形成細胞癌與良性脂溢性角化病; 惡性黑色素瘤與良性痣。 CNN 在這兩項任務上均達到了與所有測試過的專家相同的表現,展示了一種能夠對皮膚癌進行分類的,具有與皮膚科醫生相當的能力的人工智能。
* 論文[《通過多視圖深度卷積神經網絡進行高分辨率乳腺癌篩查》](https://arxiv.org/abs/1703.07047)(Krzysztof J. Geras,Stacey Wolfson,S。Gene Kim,Linda Moy,Kyunghyun Cho)承諾通過其創新的架構來改善乳腺癌的篩查過程,該架構可以處理四個標準視圖或角度,而不會犧牲高分辨率。 與通常用于自然圖像的 DCN 架構(其可處理`224 x 224`像素的圖像)相反,MV-DCN 也能夠使用`2600 x 2000`像素的分辨率。
# 使用膨脹的卷積網絡,WaveNet 和 NSynth 生成音樂
WaveNet 是用于生成原始音頻波形的深度生成模型。 [Google DeepMind](https://deepmind.com/blog/wavenet-generative-model-raw-audio/) 已引入了這一突破性技術,以教授如何與計算機通話。 結果確實令人印象深刻,在網上可以找到合成語音的示例,計算機可以在其中學習如何與名人的聲音(例如 Matt Damon)交談。
因此,您可能想知道為什么學習合成音頻如此困難。 嗯,我們聽到的每個數字聲音都是基于每秒 16,000 個樣本(有時是 48,000 個或更多),并且要建立一個預測模型,在此模型中,我們學會根據以前的所有樣本來復制樣本是一個非常困難的挑戰。 盡管如此,仍有實驗表明,WaveNet 改進了當前最先進的**文本轉語音**(TTS)系統,使美國英語和中文普通話與人聲的差異降低了 50%。
更酷的是,DeepMind 證明 WaveNet 也可以用于向計算機教授如何產生樂器聲音(例如鋼琴音樂)。
現在為一些定義。 TTS 系統通常分為兩個不同的類別:
* 串聯 TTS,其中單個語音語音片段首先被存儲,然后在必須重現語音時重新組合。 但是,該方法無法擴展,因為可能只重現存儲的語音片段,并且不可能重現新的揚聲器或不同類型的音頻而不從一開始就記住這些片段。
* 參數化 TTS,在其中創建一個模型來存儲要合成的音頻的所有特征。 在 WaveNet 之前,參數 TTS 生成的音頻不如串聯 TTS 生成的音頻自然。 WaveNet 通過直接對音頻聲音的產生進行建模,而不是使用過去使用的中間信號處理算法,從而改善了現有技術。
原則上,WaveNet 可以看作是一維卷積層的棧(我們已經在第 4 章中看到了圖像的 2D 卷積),步幅恒定為 1,沒有池化層。 請注意,輸入和輸出在構造上具有相同的尺寸,因此卷積網絡非常適合對順序數據(例如音頻)建模。 但是,已經顯示出,為了在輸出神經元中的接收場達到較大的大小,有必要使用大量的大型過濾器或過分增加網絡的深度。 請記住,一層中神經元的接受場是前一層的橫截面,神經元從該層提供輸入。 因此,純卷積網絡在學習如何合成音頻方面不是那么有效。
WaveNet 之外的主要直覺是所謂的因果因果卷積(有時稱為原子卷積),這僅意味著在應用卷積層的濾波器時會跳過某些輸入值。 Atrous 是法語表述為 *à trous* 的*混蛋*,意思是帶有孔的。 因此,AtrousConvolution 是帶孔的卷積。例如,在一個維度中,尺寸為 3 且擴張為 1 的濾波器`w`將計算出以下總和。
簡而言之,在 D 擴散卷積中,步幅通常為 1,但是沒有任何東西可以阻止您使用其他步幅。 下圖給出了一個示例,其中膨脹(孔)尺寸增大了 0、1、2:
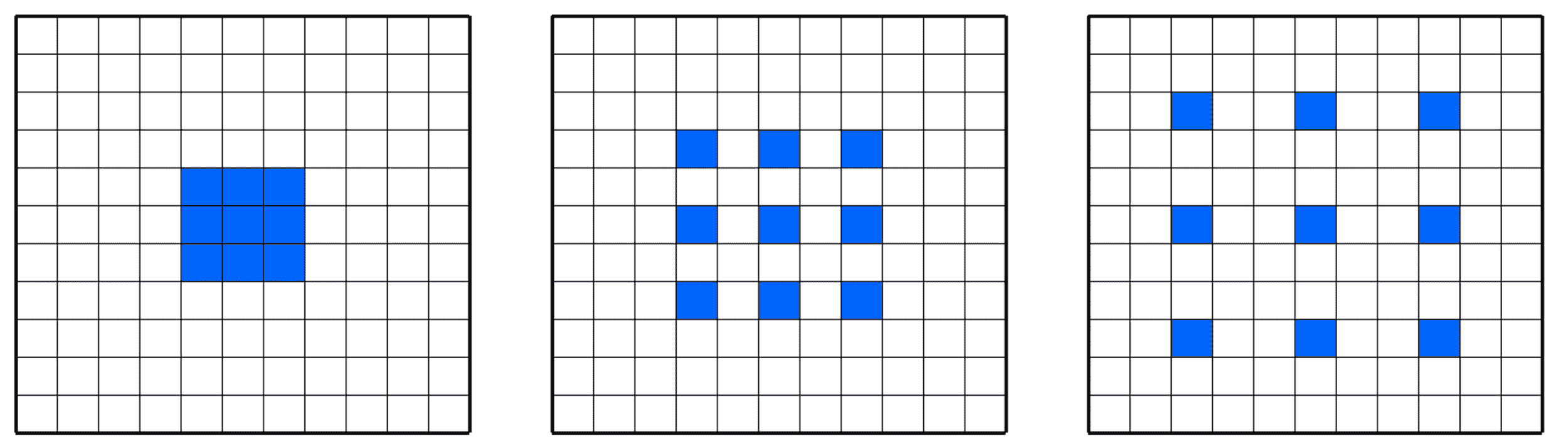
擴張網絡的一個例子
由于采用了引入“空洞”的簡單思想,可以在不具有過多深度網絡的情況下,使用指數級增長的濾波器堆疊多個膨脹的卷積層,并學習遠程輸入依賴項。
因此,WaveNet 是一個卷積網絡,其中卷積層具有各種膨脹因子,從而使接收場隨深度呈指數增長,因此有效覆蓋了數千個音頻時間步長。
當我們訓練時,輸入是從人類揚聲器錄制的聲音。 波形被量化為固定的整數范圍。 WaveNet 定義了一個初始卷積層,僅訪問當前和先前的輸入。 然后,有一堆散布的卷積網絡層,仍然僅訪問當前和以前的輸入。 最后,有一系列密集層結合了先前的結果,然后是用于分類輸出的 softmax 激活函數。
在每個步驟中,都會從網絡預測一個值,并將其反饋到輸入中。 同時,為下一步計算新的預測。 損失函數是當前步驟的輸出與下一步的輸入之間的交叉熵。
[NSynth](https://magenta.tensorflow.org/nsynth)是 Google Brain 集團最近發布的 WaveNet 的改進版本,其目的不是查看因果關系,而是查看輸入塊的整個上下文。 神經網絡是真正的,復雜的,如下圖所示,但是對于本介紹性討論而言,足以了解該網絡通過使用基于減少編碼/解碼過程中的錯誤的方法來學習如何再現其輸入。 階段:
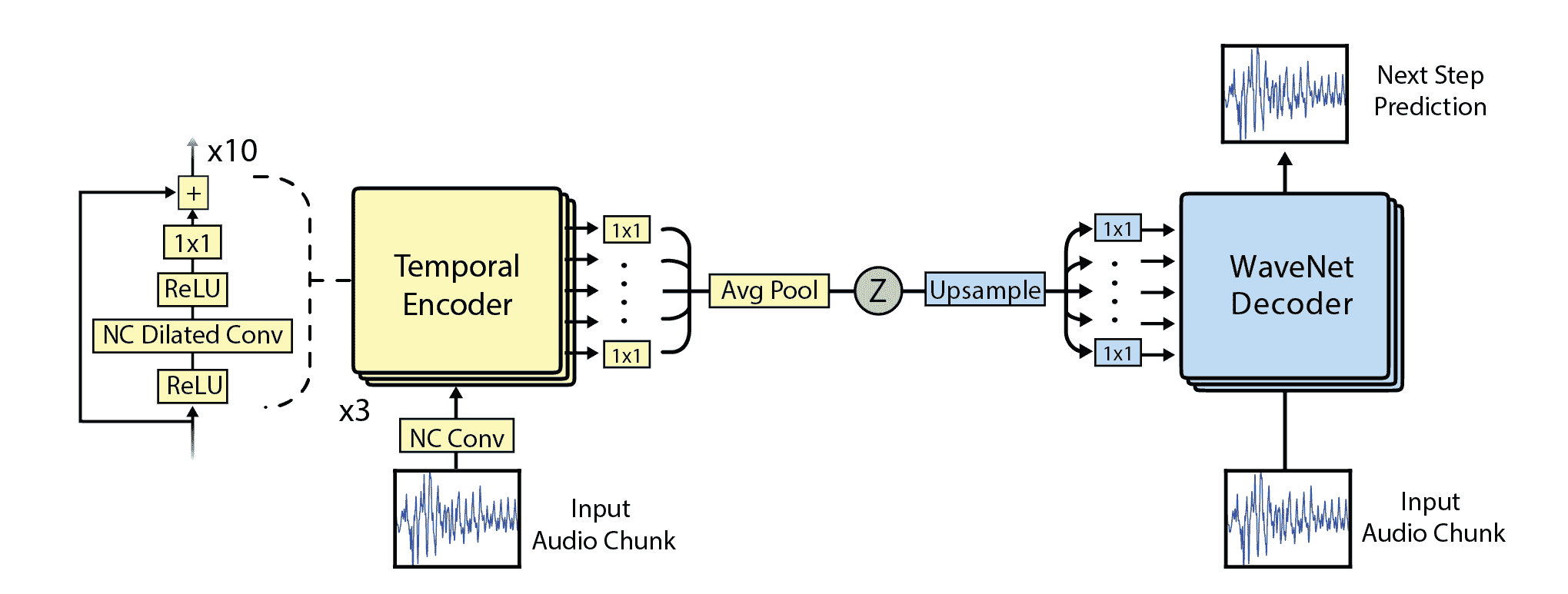
[如下所示的 NSynth 架構示例](https://magenta.tensorflow.org/nsynth)
# 準備
對于本秘籍,我們不會編寫代碼,而是向您展示如何使用[一些在線可用的代碼](https://github.com/tensorflow/magenta/tree/master/magenta/models/nsynth)和一些不錯的演示,您可以從 [Google Brain 找到](https://aiexperiments.withgoogle.com/sound-maker)。 有興趣的讀者還可以閱讀以下文章:[《使用 WaveNet 自編碼器的音符的神經音頻合成》](https://arxiv.org/abs/1704.01279)(杰西·恩格爾,辛瓊·雷斯尼克,亞當·羅伯茨,桑德·迪勒曼,道格拉斯·埃克,卡倫·西蒙揚,穆罕默德·諾魯茲,4 月 5 日 2017)。
# 操作步驟
我們按以下步驟進行:
1. 通過創建單獨的 conda 環境來安裝 NSynth。 使用支持 Jupyter Notebook 的 Python 2.7 創建并激活 Magenta conda 環境:
```py
conda create -n magenta python=2.7 jupyter
source activate magenta
```
2. 安裝`magenta` PIP 包和`librosa`(用于讀取音頻格式):
```py
pip install magenta
pip install librosa
```
3. 從[互聯網](http://download.magenta.tensorflow.org/models/nsynth/wavenet-ckpt.tar)安裝預構建的模型,然后下載[示例聲音](https://www.freesound.org/people/MustardPlug/sounds/395058/)。 然后運行[演示目錄](http://localhost:8888/notebooks/nsynth/Exploring_Neural_Audio_Synthesis_with_NSynth.ipynb)中包含的筆記本。 第一部分是關于包含稍后將在我們的計算中使用的模塊的:
```py
import os
import numpy as np
import matplotlib.pyplot as plt
from magenta.models.nsynth import utils
from magenta.models.nsynth.wavenet import fastgen
from IPython.display import Audio
%matplotlib inline
%config InlineBackend.figure_format = 'jpg'
```
4. 然后,我們加載從互聯網下載的演示聲音,并將其放置在與筆記本計算機相同的目錄中。 這將在約 2.5 秒內將 40,000 個樣本加載到計算機中:
```py
# from https://www.freesound.org/people/MustardPlug/sounds/395058/
fname = '395058__mustardplug__breakbeat-hiphop-a4-4bar-96bpm.wav'
sr = 16000
audio = utils.load_audio(fname, sample_length=40000, sr=sr)
sample_length = audio.shape[0]
print('{} samples, {} seconds'.format(sample_length, sample_length / float(sr)))
```
5. 下一步是使用從互聯網下載的預先訓練的 NSynth 模型以非常緊湊的表示形式對音頻樣本進行編碼。 每四秒鐘音頻將為我們提供`78 x 16`尺寸的編碼,然后我們可以對其進行解碼或重新合成。 我們的編碼是張量(`#files=1 x 78 x 16`):
```py
%time encoding = fastgen.encode(audio, 'model.ckpt-200000', sample_length)
INFO:tensorflow:Restoring parameters from model.ckpt-200000
CPU times: user 1min 4s, sys: 2.96 s, total: 1min 7s
Wall time: 25.7 s
print(encoding.shape)
(1, 78, 16)
```
6. 讓我們保存以后將用于重新合成的編碼。 另外,讓我們用圖形表示來快速查看編碼形狀是什么,并將其與原始音頻信號進行比較。 如您所見,編碼遵循原始音頻信號中呈現的節拍:
```py
np.save(fname + '.npy', encoding)
fig, axs = plt.subplots(2, 1, figsize=(10, 5))
axs[0].plot(audio);
axs[0].set_title('Audio Signal')
axs[1].plot(encoding[0]);
axs[1].set_title('NSynth Encoding')
```
我們觀察到以下音頻信號和 Nsynth 編碼:
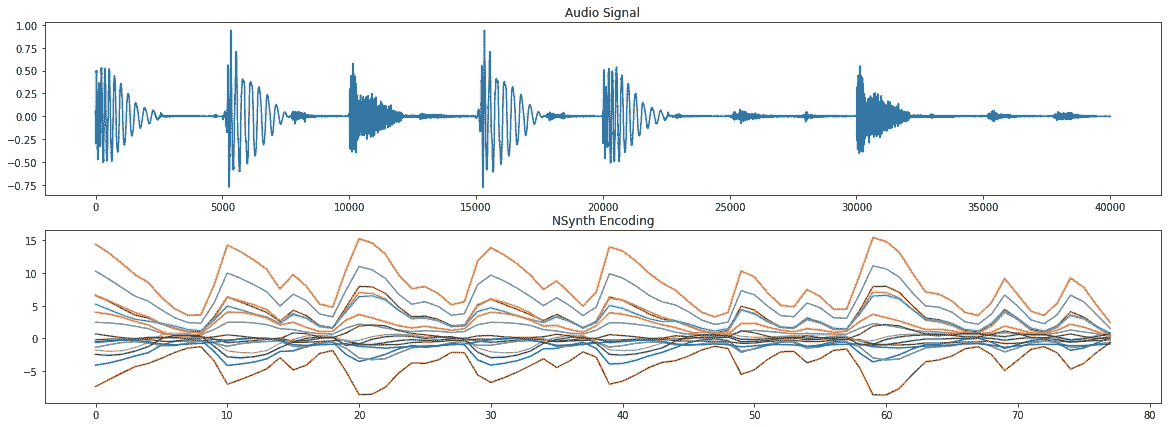
7. 現在,讓我們對剛剛產生的編碼進行解碼。 換句話說,我們試圖從緊湊的表示中再現原始音頻,目的是理解重新合成的聲音是否類似于原始聲音。 確實,如果您運行實驗并聆聽原始音頻和重新合成的音頻,它們聽起來非常相似:
```py
%time fastgen.synthesize(encoding, save_paths=['gen_' + fname], samples_per_save=sample_length)
```
# 工作原理
WaveNet 是一種卷積網絡,其中卷積層具有各種擴張因子,從而使接收場隨深度呈指數增長,因此有效覆蓋了數千個音頻時間步長。 NSynth 是 WaveNet 的演進,其中原始音頻使用類似 WaveNet 的處理進行編碼,以學習緊湊的表示形式。 然后,使用這種緊湊的表示來再現原始音頻。
# 更多
一旦我們學習了如何通過膨脹卷積創建音頻的緊湊表示形式,我們就可以玩這些學習并從中獲得樂趣。 您會在互聯網上找到非常酷的演示:
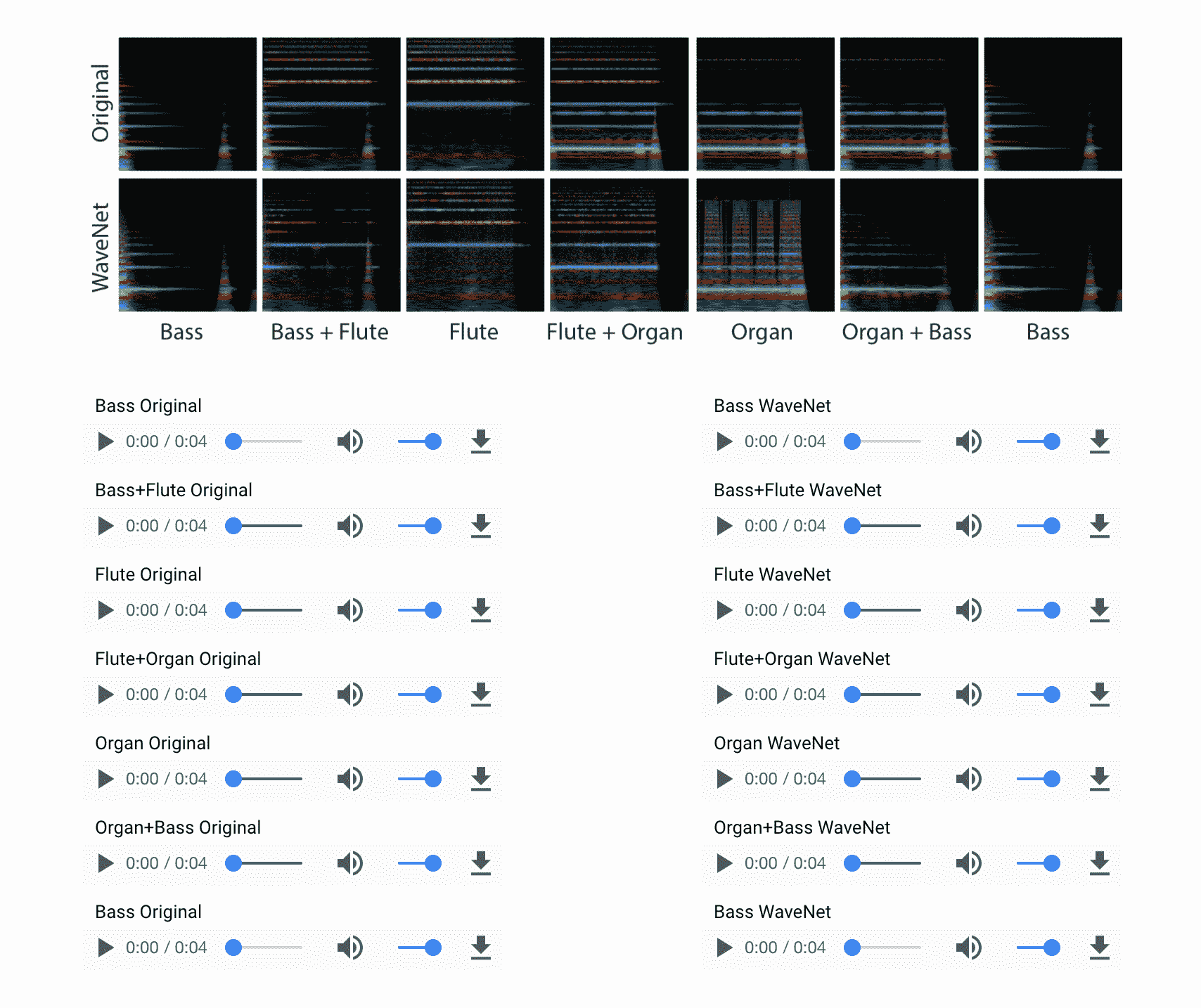
1. 例如,您可以看到模型如何學習[不同樂器的聲音](https://magenta.tensorflow.org/nsynth):
2. 然后,您將看到如何將在一個上下文中學習的一個模型在另一個上下文中重新組合。 例如,通過更改說話者身份,[我們可以使用 WaveNet 以不同的聲音說同一件事](https://deepmind.com/blog/wavenet-generative-model-raw-audio/)。
3. 另一個非常有趣的實驗是學習樂器模型,然后以一種可以重新創建以前從未聽說過的新樂器的方式對其進行重新混合。 這真的很酷,它為通往新的可能性開辟了道路,坐在我里面的前電臺 DJ 無法抗拒超級興奮。 例如,在此示例中,我們將西塔琴與電吉他結合在一起,這是一種很酷的新樂器。 不夠興奮? 那么,[如何將弓弦低音與狗的吠聲結合起來呢](https://aiexperiments.withgoogle.com/sound-maker/view/)?玩得開心!:
# 回答有關圖像的問題(可視化問答)
在本秘籍中,我們將學習如何回答有關特定圖像內容的問題。 這是一種強大的 Visual Q&A,它結合了從預先訓練的 VGG16 模型中提取的視覺特征和詞聚類(嵌入)的組合。 然后將這兩組異類特征組合成一個網絡,其中最后一層由密集和缺失的交替序列組成。 此秘籍適用于 Keras 2.0+。
因此,本秘籍將教您如何:
* 從預先訓練的 VGG16 網絡中提取特征。
* 使用預構建的單詞嵌入將單詞映射到相鄰相似單詞的空間中。
* 使用 LSTM 層構建語言模型。 LSTM 將在第 6 章中討論,現在我們將它們用作黑盒。
* 組合不同的異構輸入特征以創建組合的特征空間。 對于此任務,我們將使用新的 Keras 2.0 函數式 API。
* 附加一些其他的密集和丟棄層,以創建多層感知機并增強我們的深度學習網絡的功能。
為了簡單起見,我們不會在 5 中重新訓練組合網絡,而是使用已經在線提供的[預先訓練的權重集](https://avisingh599.github.io/deeplearning/visual-qa/)。 有興趣的讀者可以在由 N 個圖像,N 個問題和 N 個答案組成的自己的訓練數據集上對網絡進行再訓練。 這是可選練習。 該網絡的靈感來自[《VQA:視覺問題解答》](http://arxiv.org/pdf/1505.00468v4.pdf)(Aishwarya Agrawal,Jiasen Lu,Stanislaw Antol,Margaret Mitchell,C.Lawrence Zitnick,Dhruv Batra,Devi Parikh,2015 年):
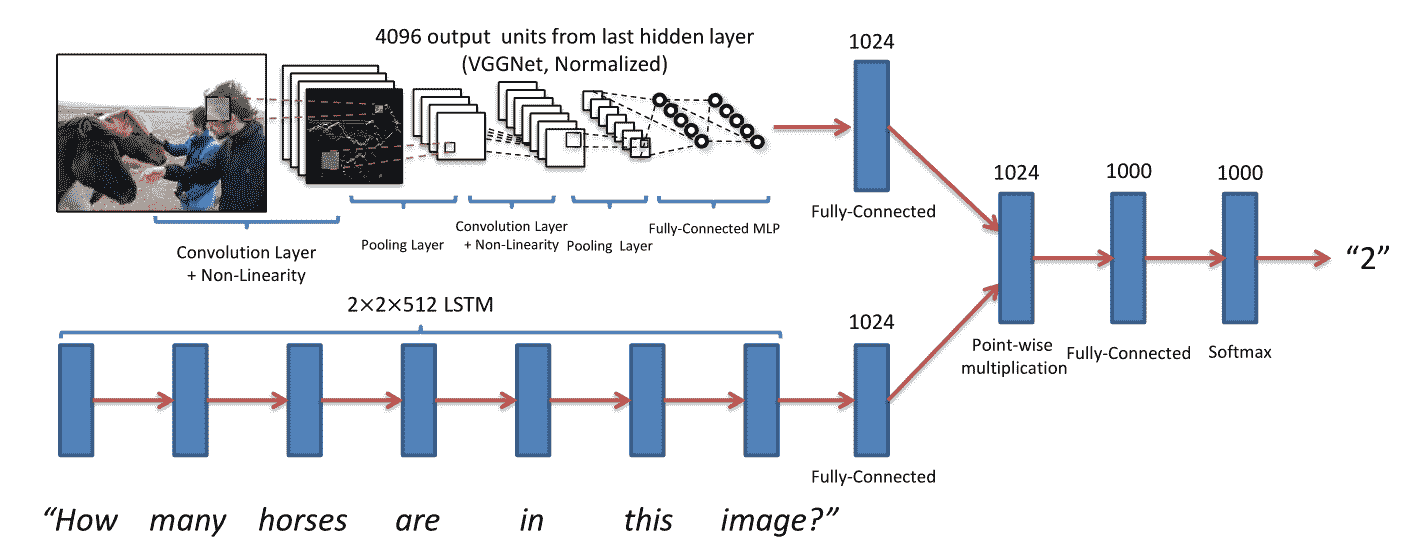
在視覺問題回答論文中看到的 Visual Q&A 示例
我們這種情況的唯一區別是,我們將圖像層產生的特征與語言層產生的特征連接起來。
# 操作步驟
我們可以按照以下步驟進行操作:
1. 加載秘籍所需的所有 Keras 模塊。 其中包括用于詞嵌入的 spaCy,用于圖像特征提取的 VGG16 和用于語言建模的 LSTM。 其余的幾個附加模塊非常標準:
```py
%matplotlib inline
import os, argparse
import numpy as np
import cv2 as cv2
import spacy as spacy
import matplotlib.pyplot as plt
from keras.models import Model, Input
from keras.layers.core import Dense, Dropout, Reshape
from keras.layers.recurrent import LSTM
from keras.layers.merge import concatenate
from keras.applications.vgg16 import VGG16
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input
from sklearn.externals import joblib
import PIL.Image
```
2. 定義一些常量。 請注意,我們假設我們的問題語料庫具有`max_length_questions = 30`,并且我們知道我們將使用 VGG16 提取 4,096 個描述輸入圖像的特征。 另外,我們知道單詞嵌入在`length_feature_space = 300`的空間中。 請注意,我們將使用從互聯網下載的[一組預訓練權重](https://github.com/iamaaditya/VQA_Demo):
```py
# mapping id -> labels for categories
label_encoder_file_name =
'/Users/gulli/Books/TF/code/git/tensorflowBook/Chapter5/FULL_labelencoder_trainval.pkl'
# max length across corpus
max_length_questions = 30
# VGG output
length_vgg_features = 4096
# Embedding outout
length_feature_space = 300
# pre-trained weights
VQA_weights_file =
'/Users/gulli/Books/TF/code/git/tensorflowBook/Chapter5/VQA_MODEL_WEIGHTS.hdf5'
```
3.使用 VGG16 提取特征。 請注意,我們從 fc2 層中明確提取了它們。 給定輸入圖像,此函數返回 4,096 個特征:
```py
'''image features'''
def get_image_features(img_path, VGG16modelFull):
'''given an image returns a tensor with (1, 4096) VGG16 features'''
# Since VGG was trained as a image of 224x224, every new image
# is required to go through the same transformation
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
# this is required because of the original training of VGG was batch
# even if we have only one image we need to be consistent
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
features = VGG16modelFull.predict(x)
model_extractfeatures = Model(inputs=VGG16modelFull.input,
outputs=VGG16modelFull.get_layer('fc2').output)
fc2_features = model_extractfeatures.predict(x)
fc2_features = fc2_features.reshape((1, length_vgg_features))
return fc2_features
```
請注意,VGG16 的定義如下:
```py
Layer (type) Output Shape Param #
=================================================================
input_5 (InputLayer) (None, 224, 224, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 25088) 0
_________________________________________________________________
fc1 (Dense) (None, 4096) 102764544
_________________________________________________________________
fc2 (Dense) (None, 4096) 16781312
_________________________________________________________________
predictions (Dense) (None, 1000) 4097000
=================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
_________________________________________
```
4. 使用 spaCy 獲取單詞嵌入,并將輸入的問題映射到一個空格(`max_length_questions, 300`),其中`max_length_questions`是我們語料庫中問題的最大長度,而 300 是 spaCy 產生的嵌入的尺寸。 在內部,spaCy 使用一種稱為 [gloVe](http://nlp.stanford.edu/projects/glove/) 的算法。 gloVe 將給定令牌簡化為 300 維表示。 請注意,該問題使用右 0 填充填充到`max_lengh_questions`:
```py
'''embedding'''
def get_question_features(question):
''' given a question, a unicode string, returns the time series vector
with each word (token) transformed into a 300 dimension representation
calculated using Glove Vector '''
word_embeddings = spacy.load('en', vectors='en_glove_cc_300_1m_vectors')
tokens = word_embeddings(question)
ntokens = len(tokens)
if (ntokens > max_length_questions) :
ntokens = max_length_questions
question_tensor = np.zeros((1, max_length_questions, 300))
for j in xrange(len(tokens)):
question_tensor[0,j,:] = tokens[j].vector
return question_tensor
```
5. 使用先前定義的圖像特征提取器加載圖像并獲取其顯著特征:
```py
image_file_name = 'girl.jpg'
img0 = PIL.Image.open(image_file_name)
img0.show()
#get the salient features
model = VGG16(weights='imagenet', include_top=True)
image_features = get_image_features(image_file_name, model)
print image_features.shape
```
6. 使用先前定義的句子特征提取器,編寫一個問題并獲得其顯著特征:
```py
question = u"Who is in this picture?"
language_features = get_question_features(question)
print language_features.shape
```
7. 將兩組異類特征組合為一個。 在這個網絡中,我們有三個 LSTM 層,這些層將考慮我們語言模型的創建。 注意,LSTM 將在第 6 章中詳細討論,目前我們僅將它們用作黑匣子。 最后的 LSTM 返回 512 個特征,這些特征隨后用作一系列密集層和缺失層的輸入。 最后一層是具有 softmax 激活函數的密集層,其概率空間為 1,000 個潛在答案:
```py
'''combine'''
def build_combined_model(
number_of_LSTM = 3,
number_of_hidden_units_LSTM = 512,
number_of_dense_layers = 3,
number_of_hidden_units = 1024,
activation_function = 'tanh',
dropout_pct = 0.5
):
#input image
input_image = Input(shape=(length_vgg_features,),
name="input_image")
model_image = Reshape((length_vgg_features,),
input_shape=(length_vgg_features,))(input_image)
#input language
input_language = Input(shape=(max_length_questions,length_feature_space,),
name="input_language")
#build a sequence of LSTM
model_language = LSTM(number_of_hidden_units_LSTM,
return_sequences=True,
name = "lstm_1")(input_language)
model_language = LSTM(number_of_hidden_units_LSTM,
return_sequences=True,
name = "lstm_2")(model_language)
model_language = LSTM(number_of_hidden_units_LSTM,
return_sequences=False,
name = "lstm_3")(model_language)
#concatenate 4096+512
model = concatenate([model_image, model_language])
#Dense, Dropout
for _ in xrange(number_of_dense_layers):
model = Dense(number_of_hidden_units,
kernel_initializer='uniform')(model)
model = Dropout(dropout_pct)(model)
model = Dense(1000,
activation='softmax')(model)
#create model from tensors
model = Model(inputs=[input_image, input_language], outputs = model)
return model
```
8. 建立組合的網絡并顯示其摘要,以了解其內部外觀。 加載預訓練的權重并使用 rmsprop 優化器使用`categorical_crossentropy`損失函數來編譯模型:
```py
combined_model = build_combined_model()
combined_model.summary()
combined_model.load_weights(VQA_weights_file)
combined_model.compile(loss='categorical_crossentropy', optimizer='rmsprop')
____________________________
Layer (type) Output Shape Param # Connected to
====================================================================================================
input_language (InputLayer) (None, 30, 300) 0
____________________________________________________________________________________________________
lstm_1 (LSTM) (None, 30, 512) 1665024 input_language[0][0]
____________________________________________________________________________________________________
input_image (InputLayer) (None, 4096) 0
____________________________________________________________________________________________________
lstm_2 (LSTM) (None, 30, 512) 2099200 lstm_1[0][0]
____________________________________________________________________________________________________
reshape_3 (Reshape) (None, 4096) 0 input_image[0][0]
____________________________________________________________________________________________________
lstm_3 (LSTM) (None, 512) 2099200 lstm_2[0][0]
____________________________________________________________________________________________________
concatenate_3 (Concatenate) (None, 4608) 0 reshape_3[0][0]
lstm_3[0][0]
____________________________________________________________________________________________________
dense_8 (Dense) (None, 1024) 4719616 concatenate_3[0][0]
____________________________________________________________________________________________________
dropout_7 (Dropout) (None, 1024) 0 dense_8[0][0]
____________________________________________________________________________________________________
dense_9 (Dense) (None, 1024) 1049600 dropout_7[0][0]
____________________________________________________________________________________________________
dropout_8 (Dropout) (None, 1024) 0 dense_9[0][0]
____________________________________________________________________________________________________
dense_10 (Dense) (None, 1024) 1049600 dropout_8[0][0]
____________________________________________________________________________________________________
dropout_9 (Dropout) (None, 1024) 0 dense_10[0][0]
____________________________________________________________________________________________________
dense_11 (Dense) (None, 1000) 1025000 dropout_9[0][0]
====================================================================================================
Total params: 13,707,240
Trainable params: 13,707,240
Non-trainable params: 0
```
9. 使用預訓練的組合網絡進行預測。 請注意,在這種情況下,我們使用該網絡已經在線可用的權重,但是感興趣的讀者可以在自己的訓練集中重新訓練組合的網絡:
```py
y_output = combined_model.predict([image_features, language_features])
# This task here is represented as a classification into a 1000 top answers
# this means some of the answers were not part of training and thus would
# not show up in the result.
# These 1000 answers are stored in the sklearn Encoder class
labelencoder = joblib.load(label_encoder_file_name)
for label in reversed(np.argsort(y_output)[0,-5:]):
print str(round(y_output[0,label]*100,2)).zfill(5), "% ", labelencoder.inverse_transform(label)
```
# 工作原理
視覺問題解答的任務是通過結合使用不同的深度神經網絡來解決的。 預訓練的 VGG16 已用于從圖像中提取特征,而 LSTM 序列已用于從先前映射到嵌入空間的問題中提取特征。 VGG16 是用于圖像特征提取的 CNN,而 LSTM 是用于提取表示序列的時間特征的 RNN。 目前,這兩種方法的結合是處理此類網絡的最新技術。 然后,在組合模型的頂部添加一個具有丟棄功能的多層感知機,以形成我們的深度網絡。
# 更多
在互聯網上,您可以找到 [Avi Singh](https://avisingh599.github.io/deeplearning/visual-qa/) 進行的更多實驗,其中比較了不同的模型,包括簡單的“袋裝”語言的“單詞”與圖像的 CNN,僅 LSTM 模型以及 LSTM + CNN 模型-類似于本秘籍中討論的模型。 博客文章還討論了每種模型的不同訓練策略。
除此之外,有興趣的讀者可以在[互聯網](https://github.com/anujshah1003/VQA-Demo-GUI)上找到一個不錯的 GUI,它建立在 Avi Singh 演示的頂部,使您可以交互式加載圖像并提出相關問題。 還提供了 [YouTube 視頻](https://www.youtube.com/watch?v=7FB9PvzOuQY)。
# 通過六種不同方式將預訓練網絡用于視頻分類
對視頻進行分類是一個活躍的研究領域,因為處理此類媒體需要大量數據。 內存需求經常達到現代 GPU 的極限,可能需要在多臺機器上進行分布式訓練。 目前,研究正在探索復雜性不斷提高的不同方向,讓我們對其進行回顧。
第一種方法包括一次將一個視頻幀分類,方法是將每個視頻幀視為使用 2D CNN 處理的單獨圖像。 這種方法只是將視頻分類問題簡化為圖像分類問題。 每個視頻幀*產生*分類輸出,并且通過考慮每個幀的更頻繁選擇的類別對視頻進行分類。
第二種方法包括創建一個單一網絡,其中 2D CNN 與 RNN 結合在一起。 這個想法是 CNN 將考慮圖像分量,而 RNN 將考慮每個視頻的序列信息。 由于要優化的參數數量非常多,這種類型的網絡可能很難訓練。
第三種方法是使用 3D 卷積網絡,其中 3D 卷積網絡是在 3D 張量(`time`,`image_width`和`image_height`)上運行的 2D 卷積網絡的擴展。 這種方法是圖像分類的另一個自然擴展,但同樣,3D 卷積網絡可能很難訓練。
第四種方法基于智能直覺。 代替直接使用 CNN 進行分類,它們可以用于存儲視頻中每個幀的脫機特征。 想法是,如先前的秘籍所示,可以通過遷移學習使特征提取非常有效。 提取所有特征后,可以將它們作為一組輸入傳遞到 RNN,該 RNN 將學習多個幀中的序列并發出最終分類。
第五種方法是第四種方法的簡單變體,其中最后一層是 MLP 而不是 RNN。 在某些情況下,就計算要求而言,此方法可能更簡單且成本更低。
第六種方法是第四種方法的變體,其中特征提取的階段是通過提取空間和視覺特征的 3D CNN 實現的。 然后將這些特征傳遞給 RNN 或 MLP。
選擇最佳方法嚴格取決于您的特定應用,沒有明確的答案。 前三種方法通常在計算上更昂貴,而后三種方法則更便宜并且經常獲得更好的表現。
在本秘籍中,我們將通過描述論文 [Temporal Activity Detection in Untrimmed Videos with Recurrent Neural Networks](https://arxiv.org/abs/1608.08128) 來描述如何使用第六種方法。 這項工作旨在解決 [ActivityNet 挑戰](http://activity-net.org/challenges/2016/) 。 這項挑戰著重于從用戶生成的視頻中識別高水平和面向目標的活動,類似于在互聯網門戶網站中找到的那些活動。 該挑戰針對兩項不同任務中的 200 個活動類別量身定制:
* 未修剪的分類挑戰:給定較長的視頻,請預測視頻中存在的活動的標簽
* 檢測挑戰:給定較長的視頻,預測視頻中存在的活動的標簽和時間范圍
呈現的架構包括兩個階段,如下圖所示。 第一階段將視頻信息編碼為單個視頻表示形式,以用于小型視頻剪輯。 為此,使用了 C3D 網絡。 C3D 網絡使用 3D 卷積從視頻中提取時空特征,這些視頻先前已被分成 16 幀剪輯。
一旦提取了視頻特征,第二階段就是對每個剪輯的活動進行分類。 為了執行這種分類,使用了 RNN,更具體地說是一個 LSTM 網絡,該網絡試圖利用長期相關性并執行視頻序列的預測。 此階段已被訓練:
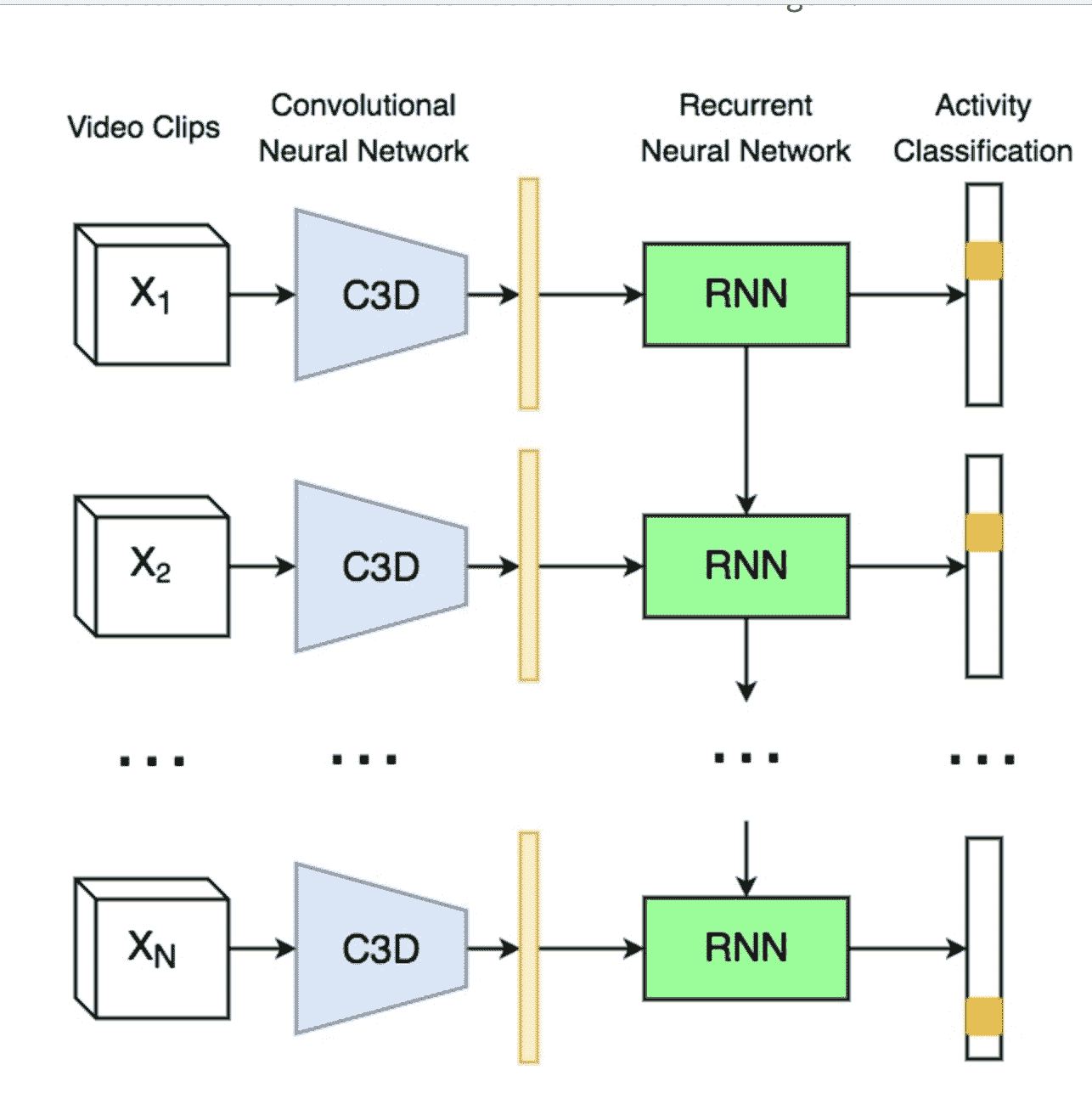
[C3D + RNN 的示例](https://imatge-upc.github.io/activitynet-2016-cvprw/)
# 操作步驟
對于此秘籍,我們僅匯總[在線呈現的結果](https://github.com/imatge-upc/activitynet-2016-cvprw/blob/master/misc/step_by_step_guide.md):
1. 第一步是克隆 git 倉庫
```py
git clone https://github.com/imatge-upc/activitynet-2016-cvprw.git
```
2. 然后,我們需要下載 ActivityNet v1.3 數據集,其大小為 600 GB:
```py
cd dataset
# This will download the videos on the default directory
sh download_videos.sh username password
# This will download the videos on the directory you specify
sh download_videos.sh username password /path/you/want
```
3. 下一步是下載 CNN3d 和 RNN 的預訓練權重:
```py
cd data/models
sh get_c3d_sports_weights.sh
sh get_temporal_location_weights.sh
```
4. 最后一步包括對視頻進行分類:
```py
python scripts/run_all_pipeline.py -i path/to/test/video.mp4
```
# 工作原理
如果您有興趣在計算機上訓練 CNN3D 和 RNN,則可以在互聯網上找到此計算機管道使用的特定命令。
目的是介紹可用于視頻分類的不同方法的高級視圖。 同樣,不僅有一個單一的秘籍,而且有多個選項,應根據您的特定需求仔細選擇。
# 更多
CNN-LSTM 架構是新的 RNN 層,其中輸入轉換和循環轉換的輸入都是卷積。 盡管名稱非常相似,但如上所述,CNN-LSTM 層與 CNN 和 LSTM 的組合不同。 該模型在論文[《卷積 LSTM 網絡:降水臨近預報的機器學習方法》](https://arxiv.org/abs/1506.04214)(史興建,陳周榮,王浩,楊天彥,黃偉堅,胡旺春,2015 年)中進行了描述,并且在 2017 年,有些人開始嘗試使用此模塊進行視頻實驗,但這仍然是一個活躍的研究領域。
- TensorFlow 1.x 深度學習秘籍
- 零、前言
- 一、TensorFlow 簡介
- 二、回歸
- 三、神經網絡:感知器
- 四、卷積神經網絡
- 五、高級卷積神經網絡
- 六、循環神經網絡
- 七、無監督學習
- 八、自編碼器
- 九、強化學習
- 十、移動計算
- 十一、生成模型和 CapsNet
- 十二、分布式 TensorFlow 和云深度學習
- 十三、AutoML 和學習如何學習(元學習)
- 十四、TensorFlow 處理單元
- 使用 TensorFlow 構建機器學習項目中文版
- 一、探索和轉換數據
- 二、聚類
- 三、線性回歸
- 四、邏輯回歸
- 五、簡單的前饋神經網絡
- 六、卷積神經網絡
- 七、循環神經網絡和 LSTM
- 八、深度神經網絡
- 九、大規模運行模型 -- GPU 和服務
- 十、庫安裝和其他提示
- TensorFlow 深度學習中文第二版
- 一、人工神經網絡
- 二、TensorFlow v1.6 的新功能是什么?
- 三、實現前饋神經網絡
- 四、CNN 實戰
- 五、使用 TensorFlow 實現自編碼器
- 六、RNN 和梯度消失或爆炸問題
- 七、TensorFlow GPU 配置
- 八、TFLearn
- 九、使用協同過濾的電影推薦
- 十、OpenAI Gym
- TensorFlow 深度學習實戰指南中文版
- 一、入門
- 二、深度神經網絡
- 三、卷積神經網絡
- 四、循環神經網絡介紹
- 五、總結
- 精通 TensorFlow 1.x
- 一、TensorFlow 101
- 二、TensorFlow 的高級庫
- 三、Keras 101
- 四、TensorFlow 中的經典機器學習
- 五、TensorFlow 和 Keras 中的神經網絡和 MLP
- 六、TensorFlow 和 Keras 中的 RNN
- 七、TensorFlow 和 Keras 中的用于時間序列數據的 RNN
- 八、TensorFlow 和 Keras 中的用于文本數據的 RNN
- 九、TensorFlow 和 Keras 中的 CNN
- 十、TensorFlow 和 Keras 中的自編碼器
- 十一、TF 服務:生產中的 TensorFlow 模型
- 十二、遷移學習和預訓練模型
- 十三、深度強化學習
- 十四、生成對抗網絡
- 十五、TensorFlow 集群的分布式模型
- 十六、移動和嵌入式平臺上的 TensorFlow 模型
- 十七、R 中的 TensorFlow 和 Keras
- 十八、調試 TensorFlow 模型
- 十九、張量處理單元
- TensorFlow 機器學習秘籍中文第二版
- 一、TensorFlow 入門
- 二、TensorFlow 的方式
- 三、線性回歸
- 四、支持向量機
- 五、最近鄰方法
- 六、神經網絡
- 七、自然語言處理
- 八、卷積神經網絡
- 九、循環神經網絡
- 十、將 TensorFlow 投入生產
- 十一、更多 TensorFlow
- 與 TensorFlow 的初次接觸
- 前言
- 1.?TensorFlow 基礎知識
- 2. TensorFlow 中的線性回歸
- 3. TensorFlow 中的聚類
- 4. TensorFlow 中的單層神經網絡
- 5. TensorFlow 中的多層神經網絡
- 6. 并行
- 后記
- TensorFlow 學習指南
- 一、基礎
- 二、線性模型
- 三、學習
- 四、分布式
- TensorFlow Rager 教程
- 一、如何使用 TensorFlow Eager 構建簡單的神經網絡
- 二、在 Eager 模式中使用指標
- 三、如何保存和恢復訓練模型
- 四、文本序列到 TFRecords
- 五、如何將原始圖片數據轉換為 TFRecords
- 六、如何使用 TensorFlow Eager 從 TFRecords 批量讀取數據
- 七、使用 TensorFlow Eager 構建用于情感識別的卷積神經網絡(CNN)
- 八、用于 TensorFlow Eager 序列分類的動態循壞神經網絡
- 九、用于 TensorFlow Eager 時間序列回歸的遞歸神經網絡
- TensorFlow 高效編程
- 圖嵌入綜述:問題,技術與應用
- 一、引言
- 三、圖嵌入的問題設定
- 四、圖嵌入技術
- 基于邊重構的優化問題
- 應用
- 基于深度學習的推薦系統:綜述和新視角
- 引言
- 基于深度學習的推薦:最先進的技術
- 基于卷積神經網絡的推薦
- 關于卷積神經網絡我們理解了什么
- 第1章概論
- 第2章多層網絡
- 2.1.4生成對抗網絡
- 2.2.1最近ConvNets演變中的關鍵架構
- 2.2.2走向ConvNet不變性
- 2.3時空卷積網絡
- 第3章了解ConvNets構建塊
- 3.2整改
- 3.3規范化
- 3.4匯集
- 第四章現狀
- 4.2打開問題
- 參考
- 機器學習超級復習筆記
- Python 遷移學習實用指南
- 零、前言
- 一、機器學習基礎
- 二、深度學習基礎
- 三、了解深度學習架構
- 四、遷移學習基礎
- 五、釋放遷移學習的力量
- 六、圖像識別與分類
- 七、文本文件分類
- 八、音頻事件識別與分類
- 九、DeepDream
- 十、自動圖像字幕生成器
- 十一、圖像著色
- 面向計算機視覺的深度學習
- 零、前言
- 一、入門
- 二、圖像分類
- 三、圖像檢索
- 四、對象檢測
- 五、語義分割
- 六、相似性學習
- 七、圖像字幕
- 八、生成模型
- 九、視頻分類
- 十、部署
- 深度學習快速參考
- 零、前言
- 一、深度學習的基礎
- 二、使用深度學習解決回歸問題
- 三、使用 TensorBoard 監控網絡訓練
- 四、使用深度學習解決二分類問題
- 五、使用 Keras 解決多分類問題
- 六、超參數優化
- 七、從頭開始訓練 CNN
- 八、將預訓練的 CNN 用于遷移學習
- 九、從頭開始訓練 RNN
- 十、使用詞嵌入從頭開始訓練 LSTM
- 十一、訓練 Seq2Seq 模型
- 十二、深度強化學習
- 十三、生成對抗網絡
- TensorFlow 2.0 快速入門指南
- 零、前言
- 第 1 部分:TensorFlow 2.00 Alpha 簡介
- 一、TensorFlow 2 簡介
- 二、Keras:TensorFlow 2 的高級 API
- 三、TensorFlow 2 和 ANN 技術
- 第 2 部分:TensorFlow 2.00 Alpha 中的監督和無監督學習
- 四、TensorFlow 2 和監督機器學習
- 五、TensorFlow 2 和無監督學習
- 第 3 部分:TensorFlow 2.00 Alpha 的神經網絡應用
- 六、使用 TensorFlow 2 識別圖像
- 七、TensorFlow 2 和神經風格遷移
- 八、TensorFlow 2 和循環神經網絡
- 九、TensorFlow 估計器和 TensorFlow HUB
- 十、從 tf1.12 轉換為 tf2
- TensorFlow 入門
- 零、前言
- 一、TensorFlow 基本概念
- 二、TensorFlow 數學運算
- 三、機器學習入門
- 四、神經網絡簡介
- 五、深度學習
- 六、TensorFlow GPU 編程和服務
- TensorFlow 卷積神經網絡實用指南
- 零、前言
- 一、TensorFlow 的設置和介紹
- 二、深度學習和卷積神經網絡
- 三、TensorFlow 中的圖像分類
- 四、目標檢測與分割
- 五、VGG,Inception,ResNet 和 MobileNets
- 六、自編碼器,變分自編碼器和生成對抗網絡
- 七、遷移學習
- 八、機器學習最佳實踐和故障排除
- 九、大規模訓練
- 十、參考文獻