
# 七、循環神經網絡和 LSTM
回顧我們對更傳統的神經網絡模型的了解后,我們發現訓練階段和預測階段通常以靜態方式表示,其中輸入作為輸入,而我們得到輸出,但我們不僅考慮了事件發生的順序。與到目前為止回顧的預測模型不同,循環神經網絡的預測取決于當前的輸入向量以及先前的輸入向量。
我們將在本章中介紹的主題如下:
* 了解循環神經網絡的工作原理以及構建它們的主要操作類型
* 解釋在更高級的模型(例如 LSTM)中實現的想法
* 在 TensorFlow 中應用 LSTM 模型來預測能耗周期
* 撰寫新音樂,從 J.S Bach 的一系列研究開始
# 循環神經網絡
知識通常不會從虛無中出現。 許多新的想法是先前知識的結合而誕生的,因此這是一種有用的模仿行為。 傳統的神經網絡不包含任何將先前看到的元素轉換為當前狀態的機制。
為了實現這一概念,我們有循環神經網絡,即 RNN。 可以將循環神經網絡定義為神經網絡的順序模型,該模型具有重用已給定信息的特性。 他們的主要假設之一是,當前信息依賴于先前的數據。 在下圖中,我們觀察到稱為單元的 RNN 基本元素的簡化圖:
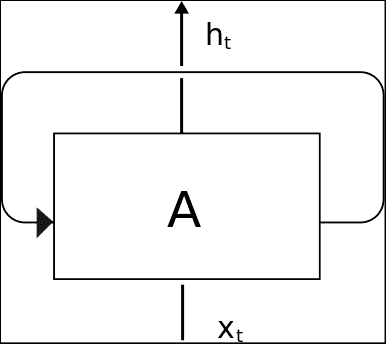
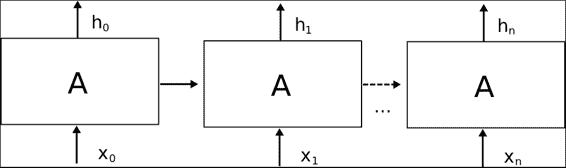
單元的主要信息元素是輸入(`Xt`),狀態和輸出(`ht`)。 但是正如我們之前所說,單元沒有獨立的狀態,因此它還存儲狀態信息。 在下圖中,我們將顯示一個“展開”的 RNN 單元,顯示其從初始狀態到輸出最終`h[n]`值的過程,中間有一些中間狀態。
一旦我們定義了單元的動態性,下一個目標就是研究制造或定義 RNN 單元的內容。 在標準 RNN 的最常見情況下,僅存在一個神經網絡層,該神經網絡層將輸入和先前狀態作為輸入,應用 tanh 操作,并輸出新狀態`h(t+1).`
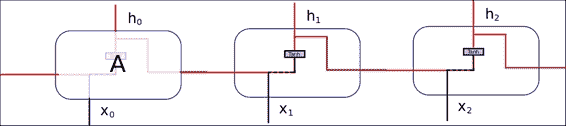
這種簡單的設置能夠隨著周期的過去而對信息進行匯總,但是進一步的實驗表明,對于復雜的知識而言,序列距離使得難以關聯某些上下文(例如,建筑師知道設計漂亮的建筑物)似乎是一種簡單的結構, 請記住,但是將它們關聯所需的上下文需要增加順序才能將兩個概念關聯起來。 這也帶來了爆炸和消失梯度的相關問題。
## 梯度爆炸和消失
循環神經網絡的主要問題之一發生在反向傳播階段,鑒于其循環性質,誤差反向傳播所具有的步驟數與一個非常深的網絡相對應。 梯度計算的這種級聯可能在最后階段導致非常不重要的值,或者相??反,導致不斷增加且不受限制的參數。 這些現象被稱為消失和爆炸梯度。 這是創建 LSTM 架構的原因之一。
## LSTM 神經網絡
長短期內存(LSTM)是一種特定的 RNN 架構,其特殊的架構使它們可以表示長期依賴性。 而且,它們是專門為記住長時間的信息模式和信息而設計的。
## 門操作 -- 基本組件
為了更好地理解 lstm 單元內部的構造塊,我們將描述 LSTM 的主要操作塊:門操作。
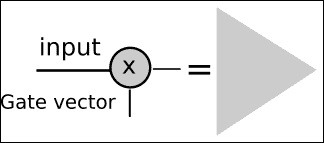
此操作基本上有一個多元輸入,在此塊中,我們決定讓一些輸入通過,將其他輸入阻塞。 我們可以將其視為信息過濾器,并且主要有助于獲取和記住所需的信息元素。
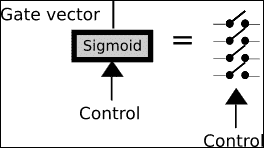
為了實現此操作,我們采用了一個多元控制向量(標有箭頭),該向量與具有 Sigmoid 激活函數的神經網絡層相連。 應用控制向量并通過 Sigmoid 函數,我們將得到一個類似于二元的向量。
我們將用許多開關符號來表示此操作:
定義了二元向量后,我們將輸入函數與向量相乘,以便對其進行過濾,僅讓部分信息通過。 我們將用一個三角形來表示此操作,該三角形指向信息行進的方向。
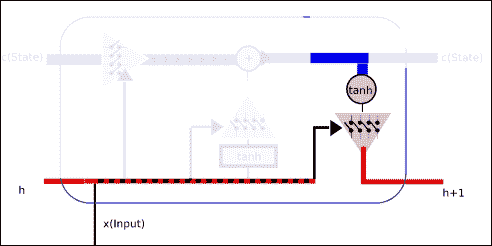
LSTM 單元格的一般結構
在下面的圖片中,我們代表了 LSTM 單元的一般結構。 它主要由上述三個門操作組成,以保護和控制單元狀態。
此操作將允許丟棄(希望不重要)低狀態數據,并且將新數據(希望重要)合并到狀態中。
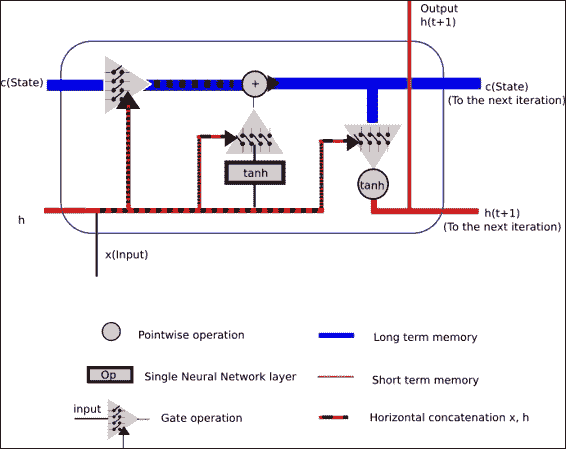
上一個圖試圖顯示一個 LSTM 單元的運行中發生的所有概念。
作為輸入,我們有:
* 單元格狀態將存儲長期信息,因為它從一開始就從單元格訓練的起點進行優化的權重,并且
* 短期狀態`h(t)`,將在每次迭代中直接與當前輸入結合使用,因此,其狀態將受輸入的最新值的影響更大
作為輸出,我們得到了結合所有門操作的結果。
## 操作步驟
在本節中,我們將描述信息將對其操作的每個循環步驟執行的所有不同子步驟的概括。
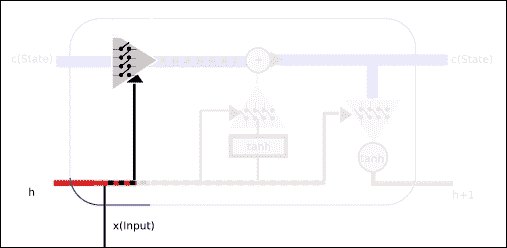
### 第 1 部分 -- 設置要忘記的值(輸入門)
在本節中,我們將采用來自短期的值,再加上輸入本身,并且這些值將由多元 Sigmoid 表示的二元函數的值設置。 根據輸入和短期記憶值,Sigmoid 輸出將允許或限制一些先前的知識或單元狀態中包含的權重。
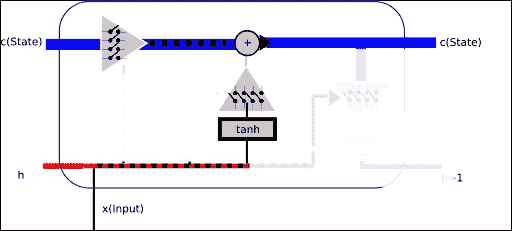
### 第 2 部分 -- 設置要保留的值,更改狀態
然后是時候設置過濾器了,該過濾器將允許或拒絕將新的和短期的內存合并到單元半永久狀態。
因此,在此階段,我們將確定將多少新信息和半新信息合并到新單元狀態中。 此外,我們最終將通過我們一直在配置的信息過濾器,因此,我們將獲得更新的長期狀態。
為了規范新的和短期的信息,我們通過具有`tanh`激活的神經網絡傳遞新的和短期的信息,這將允許在正則化(`-1,1`)范圍內提供新信息。
### 第 3 部分 -- 輸出已過濾的單元狀態
現在輪到短期狀態了。 它還將使用新的和先前的短期狀態來允許新信息通過,但是輸入將是長期狀態,點乘以 tanh 函數,再一次將輸入標準化為(`-1,1`)范圍。
## 其他 RNN 架構
通常,在本章中,假設 RNN 的領域更為廣泛,我們將集中討論 LSTM 類型的循環神經網絡單元。 例如,還采用了 RNN 的其他變體,并為該領域增加了優勢。
* 具有窺孔的 LSTM:在此網絡中,單元門連接到單元狀態
* 門控循環單元:這是一個更簡單的模型,它結合了忘記門和輸入門,合并了單元的狀態和隱藏狀態,因此大大簡化了網絡的訓練
## TensorFlow LSTM 有用的類和方法
在本節中,我們將回顧可用于構建 LSTM 層的主要類和方法,我們將在本書的示例中使用它們。
### 類`tf.nn.rnn_cell.BasicLSTMCell`
此類基本的 LSTM 循環網絡單元,具有遺忘偏差,并且沒有其他相關類型(如窺孔)的奇特特性,即使在不應影響的階段,它也可以使單元查看所得狀態。
以下是主要參數:
* `num_units`:整數,LSTM 單元的單元數
* `forget_bias`:浮動,此偏差(默認為`1`)被添加到忘記門,以便允許第一次迭代以減少初始訓練步驟的信息丟失。
* `activation`:內部狀態的激活函數(默認為標準`tanh`)
### 類`MultiRNNCell`(`RNNCell`)
在將用于此特定示例的架構中,我們將不會使用單個單元來考慮歷史值。 在這種情況下,我們將使用一組連接的單元格。 因此,我們將實例化`MultiRNNCell`類。
```py
MultiRNNCell(cells, state_is_tuple=False)
```
這是`multiRNNCell`的構造器,此方法的主要參數是單元格,它將是我們要堆疊的`RNNCells`的實例。
### `learning.ops.split_squeeze(dim, num_split, tensor_in)`
此函數將輸入拆分為一個維度,然后壓縮拆分后的張量所屬的前一個維度。 它需要切割的尺寸,切割方式的數量,然后是張量的切割。 它返回相同的張量,但縮小一維。
# 示例 1 -- 能耗數據的單變量時間序列預測
在此示例中,我們將解決回歸域的問題。 我們將要處理的數據集是一個周期內對一個家庭的許多功耗量度的匯總。 正如我們可以推斷的那樣,這種行為很容易遵循以下模式(當人們使用微波爐準備早餐時,這種行為會增加,醒來后的電腦數量會有所增加,下午可能會有所減少,而到了晚上,一切都會增加。 燈,從午夜開始直到下一個起床時間減少為零)。
因此,讓我們嘗試在一個示例案例中對此行為進行建模。
## 數據集說明和加載
在此示例中,我們將使用 [Artur Trindade](https://archive.ics.uci.edu/ml/datasets/ElectricityLoadDiagrams20112014) 的電力負荷圖數據集。
這是原始數據集的描述:
> 數據集沒有缺失值。 每 15 分鐘以 kW 為單位的值。 要以 kWh 為單位轉換值,必須將值除以 4。每一列代表一個客戶端。 在 2011 年之后創建了一些客戶。在這些情況下,消費被視為零。 所有時間標簽均以葡萄牙語小時為單位。 但是,整天呈現 96 個小節(`24 * 15`)。 每年 3 月的時間更改日(只有 23 小時),所有時間點的凌晨 1:00 和 2:00 之間均為零。 每年 10 月的時間變更日(有 25 個小時),上午 1:00 和凌晨 2:00 之間的值合計消耗兩個小時。
為了簡化我們的模型描述,我們僅對一位客戶進行了完整的測量,并將其格式轉換為標準 CSV。 它位于本章代碼文件夾的數據子文件夾中
使用以下代碼行,我們將打開并表示客戶的數據:
```py
import pandas as pd
from matplotlib import pyplot as plt
df = pd.read_csv("data/elec_load.csv", error_bad_lines=False)
plt.subplot()
plot_test, = plt.plot(df.values[:1500], label='Load')
plt.legend(handles=[plot_test])
```
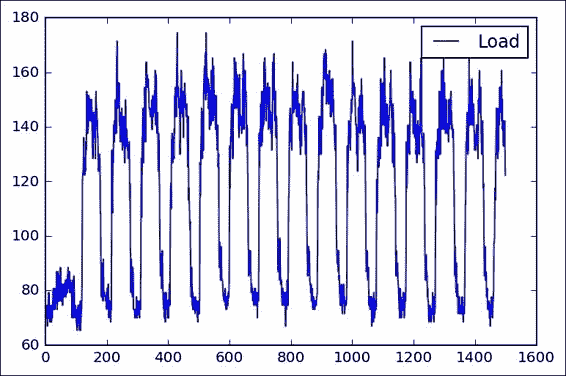
我看一下這種表示形式(我們看一下前 1500 個樣本),我們看到了一個初始瞬態狀態,可能是在進行測量時可能出現的狀態,然后我們看到了一個清晰的高,低功耗水平的循環。
從簡單的觀察中,我們還可以看到冰柱或多或少是 100 個樣本的,非常接近該數據集每天的 96 個樣本。
## 數據集預處理
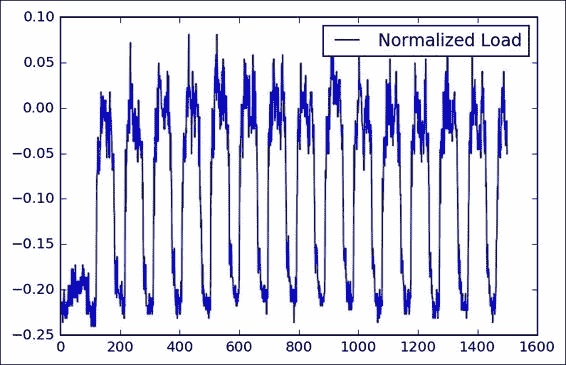
為了確保反向傳播方法更好的收斂性,我們應該嘗試對輸入數據進行正則化。
因此,我們將應用經典的縮放和居中技術,減去平均值,然后按最大值的底數進行縮放。
為了獲得所需的值,我們使用熊貓`describe()`方法。
```py
Load
count 140256.000000
mean 145.332503
std 48.477976
min 0.000000
25% 106.850998
50% 151.428571
75% 177.557604
max 338.218126
```
## 模型架構
在這里,我們將簡要描述將嘗試對電力消耗變化進行建模的架構:
最終的架構基本上由 10 個成員連接的 LSTM 多單元組成,該單元的末尾具有線性回歸或變量,對于給定的歷史記錄,它將線性單元數組輸出的結果轉換為最終的實數。 值(在這種情況下,我們必須輸入最后 5 個值才能預測下一個)。
```py
def lstm_model(time_steps, rnn_layers, dense_layers=None):
def lstm_cells(layers):
return [tf.nn.rnn_cell.BasicLSTMCell(layer['steps'],state_is_tuple=True)
for layer in layers]
def dnn_layers(input_layers, layers):
return input_layers
def _lstm_model(X, y):
stacked_lstm = tf.nn.rnn_cell.MultiRNNCell(lstm_cells(rnn_layers), state_is_tuple=True)
x_ = learn.ops.split_squeeze(1, time_steps, X)
output, layers = tf.nn.rnn(stacked_lstm, x_, dtype=dtypes.float32)
output = dnn_layers(output[-1], dense_layers)
return learn.models.linear_regression(output, y)
return _lstm_model
```
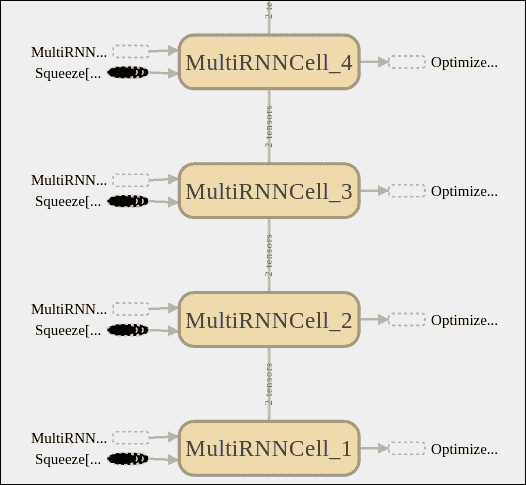
下圖顯示了主要模塊,隨后由學習模塊進行了補充,您可以在其中看到 RNN 階段,優化器以及輸出之前的最終線性回歸。
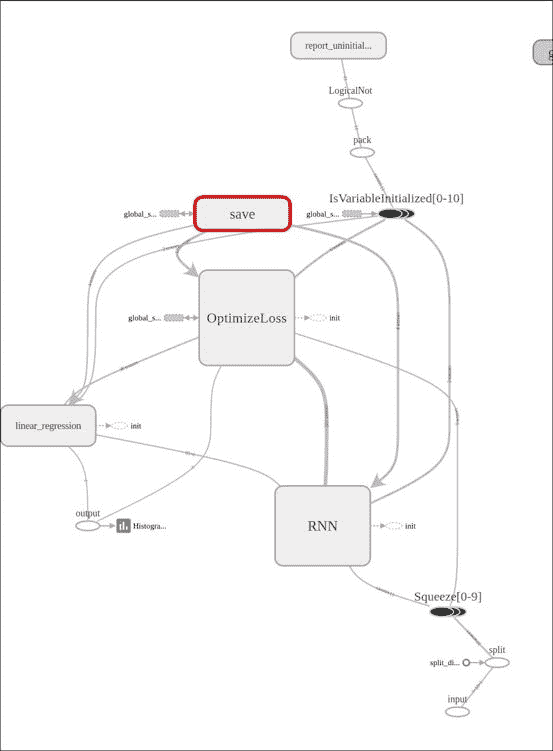
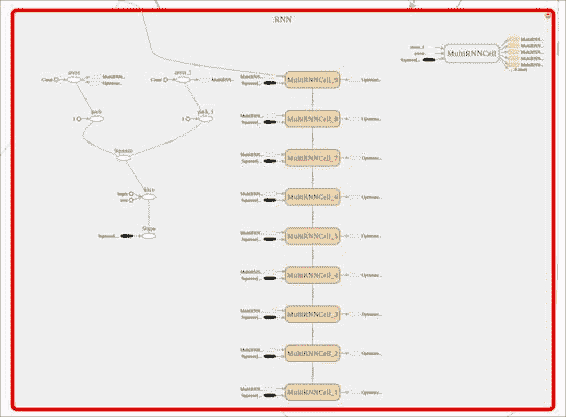
在這張圖片中,我們看了 RNN 階段,在那里我們可以觀察到各個 LSTM 單元的級聯,輸入的擠壓以及該學習包所添加的所有互補操作。
然后,我們將使用回歸器完成模型的定義:
```py
regressor = learn.TensorFlowEstimator(model_fn=lstm_model(
TIMESTEPS, RNN_LAYERS, DENSE_LAYERS), n_classes=0,
verbose=2, steps=TRAINING_STEPS, optimizer='Adagrad',
learning_rate=0.03, batch_size=BATCH_SIZE)
```
## 損失函數說明
對于損失函數,經典回歸參數均方誤差將:
```py
rmse = np.sqrt(((predicted - y['test']) ** 2).mean(axis=0))
```
## 收斂性測試
在這里,我們將為當前模型運行擬合函數:
```py
regressor.fit(X['train'], y['train'], monitors=[validation_monitor], logdir=LOG_DIR)
```
并將獲得以下內容(很好)! 錯誤率。 我們可以做的一項工作是避免對數據進行標準化,并查看平均誤差是否相同(注意:不是,差很多)
這是我們將獲得的簡單控制臺輸出:
```py
MSE: 0.001139
```
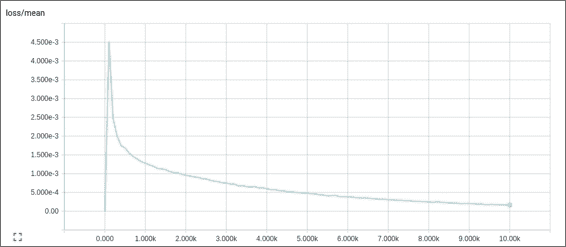
這是生成的損耗/均值圖形,它告訴我們誤差在每次迭代中如何衰減:
## 結果描述
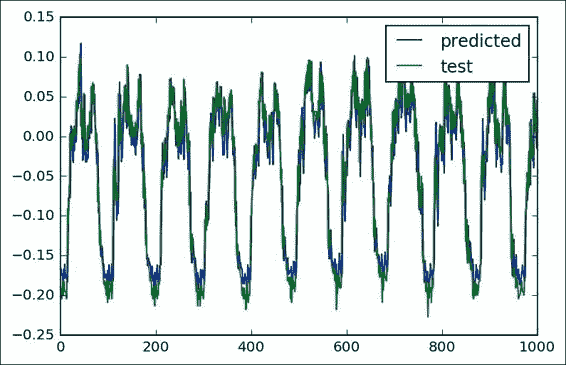
現在我們可以得到真實測試值和預測值的圖形,在圖形中我們可以看到平均誤差表明我們的循環模型具有很好的預測能力:
## 完整源代碼
以下是完整的源代碼:
```py
import numpy as np
import pandas as pd
import tensorflow as tf
from matplotlib import pyplot as plt
from tensorflow.python.framework import dtypes
from tensorflow.contrib import learn
import logging
logging.basicConfig(level=logging.INFO)
from tensorflow.contrib import learn
from sklearn.metrics import mean_squared_error
LOG_DIR = './ops_logs'
TIMESTEPS = 5
RNN_LAYERS = [{'steps': TIMESTEPS}]
DENSE_LAYERS = None
TRAINING_STEPS = 10000
BATCH_SIZE = 100
PRINT_STEPS = TRAINING_STEPS / 100
def lstm_model(time_steps, rnn_layers, dense_layers=None):
def lstm_cells(layers):
return [tf.nn.rnn_cell.BasicLSTMCell(layer['steps'],state_is_tuple=True)
for layer in layers]
def dnn_layers(input_layers, layers):
return input_layers
def _lstm_model(X, y):
stacked_lstm = tf.nn.rnn_cell.MultiRNNCell(lstm_cells(rnn_layers), state_is_tuple=True)
x_ = learn.ops.split_squeeze(1, time_steps, X)
output, layers = tf.nn.rnn(stacked_lstm, x_, dtype=dtypes.float32)
output = dnn_layers(output[-1], dense_layers)
return learn.models.linear_regression(output, y)
return _lstm_model
regressor = learn.TensorFlowEstimator(model_fn=lstm_model(TIMESTEPS, RNN_LAYERS, DENSE_LAYERS), n_classes=0,
verbose=2, steps=TRAINING_STEPS, optimizer='Adagrad',
learning_rate=0.03, batch_size=BATCH_SIZE)
df = pd.read_csv("data/elec_load.csv", error_bad_lines=False)
plt.subplot()
plot_test, = plt.plot(df.values[:1500], label='Load')
plt.legend(handles=[plot_test])
print df.describe()
array=(df.values- 147.0) /339.0
plt.subplot()
plot_test, = plt.plot(array[:1500], label='Normalized Load')
plt.legend(handles=[plot_test])
listX = []
listy = []
X={}
y={}
for i in range(0,len(array)-6):
listX.append(array[i:i+5].reshape([5,1]))
listy.append(array[i+6])
arrayX=np.array(listX)
arrayy=np.array(listy)
X['train']=arrayX[0:12000]
X['test']=arrayX[12000:13000]
X['val']=arrayX[13000:14000]
y['train']=arrayy[0:12000]
y['test']=arrayy[12000:13000]
y['val']=arrayy[13000:14000]
# print y['test'][0]
# print y2['test'][0]
#X1, y2 = generate_data(np.sin, np.linspace(0, 100, 10000), TIMESTEPS, seperate=False)
# create a lstm instance and validation monitor
validation_monitor = learn.monitors.ValidationMonitor(X['val'], y['val'],
every_n_steps=PRINT_STEPS,
early_stopping_rounds=1000)
regressor.fit(X['train'], y['train'], monitors=[validation_monitor], logdir=LOG_DIR)
predicted = regressor.predict(X['test'])
rmse = np.sqrt(((predicted - y['test']) ** 2).mean(axis=0))
score = mean_squared_error(predicted, y['test'])
print ("MSE: %f" % score)
#plot_predicted, = plt.plot(array[:1000], label='predicted')
plt.subplot()
plot_predicted, = plt.plot(predicted, label='predicted')
plot_test, = plt.plot(y['test'], label='test')
plt.legend(handles=[plot_predicted, plot_test])
```
# 示例 2 -- 編寫音樂 A La Bach
在此示例中,我們將使用專門針對字符序列或字符 RNN 模型的循環神經網絡。
我們將使用一系列基于字符的格式表達的音樂,即巴赫·戈德堡變奏曲(Bach Goldberg Variations),饋入該神經網絡,并根據所學的結構編寫一首音樂樣本。
### 注意
請注意,此示例歸功于[《可視化和理解循環網絡》](https://arxiv.org/abs/1506.02078)和[標題為“循環神經網絡的不合理有效性”的文章](http://karpathy.github.io/2015/05/21/rnn-effectiveness/),該文章提供了許多想法和概念。
## 字符級別模型
如我們先前所見,字符 RNN 模型可用于字符序列。 這類輸入可以代表多種可能的語言。 以下是一些示例:
* 代碼
* 不同的人類語言(某些作者的寫作風格的建模)
* 科學論文(tex)等
### 字符序列和概率表示
RNN 的輸入內容需要一種清晰直接的表示方式。 因此,選擇單熱表示,可以方便地將其直接用于表征有限數量的可能結果(有限字符的數量是有限的并且以十為單位)的輸出,并可以將其與 `Softmax`函數值。
因此,模型的輸入是字符序列,模型的輸出將是每個實例的數組序列。 數組的長度將與詞匯表的大小相同,因此,給定先前輸入的序列字符,每個數組位置將代表當前字符在此序列位置中的概率。
在下圖中,我們觀察到一個非常簡化的設置模型,其中編碼的輸入單詞和該模型預測單詞`TEST`作為預期的輸出:
### 將音樂編碼為字符 -- ABC 音樂格式
搜索表示輸入數據的格式時,如果可能的話,選擇一種更簡單但結構上均一的格式很重要。
關于音樂表示,ABC 格式是一種合適的選擇,因為它的結構非常簡單,使用的字符數有限,并且是 ASCII 字符集的子集。
#### ABC 格式數據組織
ABC 格式頁面主要包含兩個組件:標頭和注釋。
* `Header`:標頭包含一些鍵:值行,例如`X:[Reference number]`,`T:[Title]`,`M:[Meter]`,`K:[Key]`和`C[Composer]`。
* 注釋:注釋從`K`標題鍵之后開始,并列出每個小節的不同注釋,以`|`字符分隔。
還有其他元素,但是通過以下示例,即使沒有音樂訓練,您也將了解格式的工作原理:
原始樣本如下:
```py
X:1
T:Notes
M:C
L:1/4
K:C
C, D, E, F,|G, A, B, C|D E F G|A B c d|e f g a|b c' d' e'|f' g' a' b'|]
```
最終表示如下:

巴赫·戈德堡的變化:
巴赫·戈德堡(Bach Goldberg)變奏曲是一組原始的詠嘆調,并基于該詠嘆調創作了 30 部作品,以巴赫的門徒約翰·哥特利布·戈德堡(Johann Gottlieb Goldberg)的名字命名,他可能是其主要的解釋者。
在下一個清單和圖中,我們將表示變體`Nr 1`的第一部分,因此您對我們將嘗試模仿的文檔結構有所了解:
```py
X:1
T:Variation no. 1
C:J.S.Bach
M:3/4
L:1/16
Q:500
V:2 bass
K:G
[V:1]GFG2- GDEF GAB^c |d^cd2- dABc defd |gfg2- gfed ^ceAG|
[V:2]G,,2B,A, B,2G,2G,,2G,2 |F,,2F,E, F,2D,2F,,2D,2 |E,,2E,D, E,2G,2A,,2^C2|
% (More parts with V:1 and V:2)
```

### 有用的庫和方法
在本節中,我們將學習在此示例中將使用的新函數。
### 保存和還原變量和模型
對于現實世界的應用來說,一項非常重要的能力是能夠保存和檢索整個模型。 TensorFlow 通過`tf.train.Saver`對象提供此功能。
該對象的主要方法如下:
* `tf.train.Saver(args)`:這是構造器。 這是主要參數的列表:
* `var_list`:這是一個列表,其中包含要保存的所有變量的列表。 例如,{`firstvar: var1`,`secondvar: var2`}。 如果不存在,請保存所有對象。
* `max_to_keep`:這表示要維護的最大檢查點數。
* `write_version`:這是文件格式版本,實際上只有 1 個有效。
* `tf.train.Saver.save`:此方法運行由構造器添加的用于保存變量的操作。 這需要當前會??話,并且所有變量都已初始化。 主要參數如下:
* `session`:這是保存變量的會話
* `save_path`:這是檢查點文件名的路徑
* `global_step`:這是唯一的步驟標識符
此方法返回保存檢查點的路徑。
* `tf.train.Saver.restore`:此方法恢復以前保存的變量。 主要參數如下:
* `session`:會話是要還原變量的位置
* `save_path`:這是先前由`save`方法,對`last_checkpoint()`的調用或提供的變量先前返回的變量
### 加載和保存的偽代碼
在這里,我們將使用一些示例代碼來構建用于保存和檢索兩個示例變量的最小結構。
#### 變量保存
以下是創建變量的代碼:
```py
# Create some variables.simplevar = tf.Variable(..., name="simple")anothervar = tf.Variable(..., name="another")...# Add ops to save and restore all the variables.saver = tf.train.Saver()# Later, launch the model, initialize the variables, do some work, save the# variables to disk.with tf.Session() as sess: sess.run(tf.initialize_all_variables()) # Do some work with the model. .. # Save the variables to disk. save_path = saver.save(sess, "/tmp/model.ckpt")
```
#### 變量還原
以下是用于還原變量的代碼:
```py
saver = tf.train.Saver()
# Later, launch the model, use the saver to restore variables from disk, and
# do some work with the model.
with tf.Session() as sess:
#Work with the restored model....
```
## 數據集說明和加載
對于此數據集,我們從 30 幅作品開始,然后生成其隨機分布的`1000`個實例的列表:
```py
import random
input = open('input.txt', 'r').read().split('X:')
for i in range (1,1000):
print "X:" + input[random.randint(1,30)] + "\n_____________________________________\n"
```
## 網絡訓練
網絡訓練的原始材料將是 ABC 格式的`30`作品。
### 注意
請注意,原始 ABC 文件位于[此鏈接](http://www.barfly.dial.pipex.com/Goldbergs.abc)。
然后,我們使用這個小程序。
對于此數據集,我們從`30`作品開始,然后生成一個隨機分布的`1000`實例列表:
```py
import random
input = open('original.txt', 'r').read().split('X:')
for i in range (1,1000):
print "X:" + input[random.randint(1,30)] + "\n_____________________________________\n"
```
然后我們執行以下命令來獲取數據集:
```py
python generate_dataset.py > input.txt
```
## 數據集預處理
生成的數據集在有用之前需要一些信息。 首先,它需要詞匯的定義。
### 詞匯定義
該過程的第一步是找到可以在原始文本中找到的所有不同字符,以便以后能夠確定尺寸并填充單熱編碼輸入。
在下圖中,我們表示以 ABC 音樂格式找到的不同字符。 在這里,您可以看到標準中包含普通和特殊標點符號的內容:
### 模型架構
下面的行中描述了此 RNN 的模型,它是具有初始零狀態的多層 LSTM:
```py
cell_fn = rnn_cell.BasicLSTMCell
cell = cell_fn(args.rnn_size, state_is_tuple=True)
self.cell = cell = rnn_cell.MultiRNNCell([cell] * args.num_layers, state_is_tuple=True)
self.input_data = tf.placeholder(tf.int32, [args.batch_size, args.seq_length])
self.targets = tf.placeholder(tf.int32, [args.batch_size, args.seq_length])
self.initial_state = cell.zero_state(args.batch_size, tf.float32)
with tf.variable_scope('rnnlm'):
softmax_w = tf.get_variable("softmax_w", [args.rnn_size, args.vocab_size])
softmax_b = tf.get_variable("softmax_b", [args.vocab_size])
with tf.device("/cpu:0"):
embedding = tf.get_variable("embedding", [args.vocab_size, args.rnn_size])
inputs = tf.split(1, args.seq_length, tf.nn.embedding_lookup(embedding, self.input_data))
inputs = [tf.squeeze(input_, [1]) for input_ in inputs]
def loop(prev, _):
prev = tf.matmul(prev, softmax_w) + softmax_b
prev_symbol = tf.stop_gradient(tf.argmax(prev, 1))
return tf.nn.embedding_lookup(embedding, prev_symbol)
outputs, last_state = seq2seq.rnn_decoder(inputs, self.initial_state, cell, loop_function=loop if infer else None, scope='rnnlm')
output = tf.reshape(tf.concat(1, outputs), [-1, args.rnn_size])
```
## 損失函數說明
損失函數由`losss_by_example`函數定義。 這是基于一種稱為“困惑性”的度量,該度量可測量概率分布預測樣本的程度。 此度量在語言模型中廣泛使用:
```py
self.logits = tf.matmul(output, softmax_w) + softmax_b
self.probs = tf.nn.softmax(self.logits)
loss = seq2seq.sequence_loss_by_example([self.logits],
[tf.reshape(self.targets, [-1])],
[tf.ones([args.batch_size * args.seq_length])],
args.vocab_size)
self.cost = tf.reduce_sum(loss) / args.batch_size / args.seq_length
```
## 停止條件
程序將迭代直到達到周期數和批號為止。 這是條件塊:
```py
if (e==args.num_epochs-1 and b == data_loader.num_batches-1)
```
## 結果描述
為了運行程序,首先使用以下代碼運行訓練腳本:
```py
python train.py
```
然后,使用以下代碼運行示例程序:
```py
python sample.py
```
配置`X:1\n`的質數,這是一個可能的初始化字符序列,我們可以根據 RNN 的深度(建議 3)和長度(建議 512)獲得幾乎可以識別的完整構圖。
根據現場診斷,獲得了以下樂譜,將得到的字符序列復制到 [drawthedots.com](http://www.drawthedots.com/) 并進行簡單的字符校正:

## 完整源代碼
以下是完整的源代碼(`train.py`):
```py
from __future__ import print_function
import numpy as np
import tensorflow as tf
import argparse
import time
import os
from six.moves import cPickle
from utils import TextLoader
from model import Model
class arguments:
def __init__(self):
return
def main():
args = arguments()
train(args)
def train(args):
args.data_dir='data/'; args.save_dir='save'; args.rnn_size =64;
args.num_layers=1; args.batch_size=50;args.seq_length=50
args.num_epochs=5;args.save_every=1000; args.grad_clip=5\.
args.learning_rate=0.002; args.decay_rate=0.97
data_loader = TextLoader(args.data_dir, args.batch_size, args.seq_length)
args.vocab_size = data_loader.vocab_size
with open(os.path.join(args.save_dir, 'config.pkl'), 'wb') as f:
cPickle.dump(args, f)
with open(os.path.join(args.save_dir, 'chars_vocab.pkl'), 'wb') as f:
cPickle.dump((data_loader.chars, data_loader.vocab), f)
model = Model(args)
with tf.Session() as sess:
tf.initialize_all_variables().run()
saver = tf.train.Saver(tf.all_variables())
for e in range(args.num_epochs):
sess.run(tf.assign(model.lr, args.learning_rate * (args.decay_rate ** e)))
data_loader.reset_batch_pointer()
state = sess.run(model.initial_state)
for b in range(data_loader.num_batches):
start = time.time()
x, y = data_loader.next_batch()
feed = {model.input_data: x, model.targets: y}
for i, (c, h) in enumerate(model.initial_state):
feed[c] = state[i].c
feed[h] = state[i].h
train_loss, state, _ = sess.run([model.cost, model.final_state, model.train_op], feed)
end = time.time()
print("{}/{} (epoch {}), train_loss = {:.3f}, time/batch = {:.3f}" \
.format(e * data_loader.num_batches + b,
args.num_epochs * data_loader.num_batches,
e, train_loss, end - start))
if (e==args.num_epochs-1 and b == data_loader.num_batches-1): # save for the last result
checkpoint_path = os.path.join(args.save_dir, 'model.ckpt')
saver.save(sess, checkpoint_path, global_step = e * data_loader.num_batches + b)
print("model saved to {}".format(checkpoint_path))
if __name__ == '__main__':
main()
```
以下是完整的源代碼(`model.py`):
```py
import tensorflow as tf
from tensorflow.python.ops import rnn_cell
from tensorflow.python.ops import seq2seq
import numpy as np
class Model():
def __init__(self, args, infer=False):
self.args = args
if infer: #When we sample, the batch and sequence lenght are = 1
args.batch_size = 1
args.seq_length = 1
cell_fn = rnn_cell.BasicLSTMCell #Define the internal cell structure
cell = cell_fn(args.rnn_size, state_is_tuple=True)
self.cell = cell = rnn_cell.MultiRNNCell([cell] * args.num_layers, state_is_tuple=True)
#Build the inputs and outputs placeholders, and start with a zero internal values
self.input_data = tf.placeholder(tf.int32, [args.batch_size, args.seq_length])
self.targets = tf.placeholder(tf.int32, [args.batch_size, args.seq_length])
self.initial_state = cell.zero_state(args.batch_size, tf.float32)
with tf.variable_scope('rnnlm'):
softmax_w = tf.get_variable("softmax_w", [args.rnn_size, args.vocab_size]) #Final w
softmax_b = tf.get_variable("softmax_b", [args.vocab_size]) #Final bias
with tf.device("/cpu:0"):
embedding = tf.get_variable("embedding", [args.vocab_size, args.rnn_size])
inputs = tf.split(1, args.seq_length, tf.nn.embedding_lookup(embedding, self.input_data))
inputs = [tf.squeeze(input_, [1]) for input_ in inputs]
def loop(prev, _):
prev = tf.matmul(prev, softmax_w) + softmax_b
prev_symbol = tf.stop_gradient(tf.argmax(prev, 1))
return tf.nn.embedding_lookup(embedding, prev_symbol)
outputs, last_state = seq2seq.rnn_decoder(inputs, self.initial_state, cell, loop_function=loop if infer else None, scope='rnnlm')
output = tf.reshape(tf.concat(1, outputs), [-1, args.rnn_size])
self.logits = tf.matmul(output, softmax_w) + softmax_b
self.probs = tf.nn.softmax(self.logits)
loss = seq2seq.sequence_loss_by_example([self.logits],
[tf.reshape(self.targets, [-1])],
[tf.ones([args.batch_size * args.seq_length])],
args.vocab_size)
self.cost = tf.reduce_sum(loss) / args.batch_size / args.seq_length
self.final_state = last_state
self.lr = tf.Variable(0.0, trainable=False)
tvars = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(self.cost, tvars),
args.grad_clip)
optimizer = tf.train.AdamOptimizer(self.lr)
self.train_op = optimizer.apply_gradients(zip(grads, tvars))
def sample(self, sess, chars, vocab, num=200, prime='START', sampling_type=1):
state = sess.run(self.cell.zero_state(1, tf.float32))
for char in prime[:-1]:
x = np.zeros((1, 1))
x[0, 0] = vocab[char]
feed = {self.input_data: x, self.initial_state:state}
[state] = sess.run([self.final_state], feed)
def weighted_pick(weights):
t = np.cumsum(weights)
s = np.sum(weights)
return(int(np.searchsorted(t, np.random.rand(1)*s)))
ret = prime
char = prime[-1]
for n in range(num):
x = np.zeros((1, 1))
x[0, 0] = vocab[char]
feed = {self.input_data: x, self.initial_state:state}
[probs, state] = sess.run([self.probs, self.final_state], feed)
p = probs[0]
sample = weighted_pick(p)
pred = chars[sample]
ret += pred
char = pred
return ret
```
以下是完整的源代碼(`sample.py`):
```py
from __future__ import print_function
import numpy as np
import tensorflow as tf
import time
import os
from six.moves import cPickle
from utils import TextLoader
from model import Model
from six import text_type
class arguments: #Generate the arguments class
save_dir= 'save'
n=1000
prime='x:1\n'
sample=1
def main():
args = arguments()
sample(args) #Pass the argument object
def sample(args):
with open(os.path.join(args.save_dir, 'config.pkl'), 'rb') as f:
saved_args = cPickle.load(f) #Load the config from the standard file
with open(os.path.join(args.save_dir, 'chars_vocab.pkl'), 'rb') as f:
chars, vocab = cPickle.load(f) #Load the vocabulary
model = Model(saved_args, True) #Rebuild the model
with tf.Session() as sess:
tf.initialize_all_variables().run()
saver = tf.train.Saver(tf.all_variables())
ckpt = tf.train.get_checkpoint_state(args.save_dir) #Retrieve the chkpoint
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path) #Restore the model
print(model.sample(sess, chars, vocab, args.n, args.prime, args.sample))
#Execute the model, generating a n char sequence
#starting with the prime sequence
if __name__ == '__main__':
main()
```
以下是完整的源代碼(`utils.py`):
```py
import codecs
import os
import collections
from six.moves import cPickle
import numpy as np
class TextLoader():
def __init__(self, data_dir, batch_size, seq_length, encoding='utf-8'):
self.data_dir = data_dir
self.batch_size = batch_size
self.seq_length = seq_length
self.encoding = encoding
input_file = os.path.join(data_dir, "input.txt")
vocab_file = os.path.join(data_dir, "vocab.pkl")
tensor_file = os.path.join(data_dir, "data.npy")
if not (os.path.exists(vocab_file) and os.path.exists(tensor_file)):
print("reading text file")
self.preprocess(input_file, vocab_file, tensor_file)
else:
print("loading preprocessed files")
self.load_preprocessed(vocab_file, tensor_file)
self.create_batches()
self.reset_batch_pointer()
def preprocess(self, input_file, vocab_file, tensor_file):
with codecs.open(input_file, "r", encoding=self.encoding) as f:
data = f.read()
counter = collections.Counter(data)
count_pairs = sorted(counter.items(), key=lambda x: -x[1])
self.chars, _ = zip(*count_pairs)
self.vocab_size = len(self.chars)
self.vocab = dict(zip(self.chars, range(len(self.chars))))
with open(vocab_file, 'wb') as f:
cPickle.dump(self.chars, f)
self.tensor = np.array(list(map(self.vocab.get, data)))
np.save(tensor_file, self.tensor)
def load_preprocessed(self, vocab_file, tensor_file):
with open(vocab_file, 'rb') as f:
self.chars = cPickle.load(f)
self.vocab_size = len(self.chars)
self.vocab = dict(zip(self.chars, range(len(self.chars))))
self.tensor = np.load(tensor_file)
self.num_batches = int(self.tensor.size / (self.batch_size *
self.seq_length))
def create_batches(self):
self.num_batches = int(self.tensor.size / (self.batch_size *
self.seq_length))
self.tensor = self.tensor[:self.num_batches * self.batch_size * self.seq_length]
xdata = self.tensor
ydata = np.copy(self.tensor)
ydata[:-1] = xdata[1:]
ydata[-1] = xdata[0]
self.x_batches = np.split(xdata.reshape(self.batch_size, -1), self.num_batches, 1)
self.y_batches = np.split(ydata.reshape(self.batch_size, -1), self.num_batches, 1)
def next_batch(self):
x, y = self.x_batches[self.pointer], self.y_batches[self.pointer]
self.pointer += 1
return x, y
def reset_batch_pointer(self):
self.pointer = 0
```
# 總結
在本章中,我們回顧了一種最新的神經網絡架構,即循環神經網絡,從而完善了機器學習領域主流方法的全景。
在下一章中,我們將研究在最先進的實現中出現的不同的神經網絡層類型組合,并涵蓋一些新的有趣的實驗模型。
- TensorFlow 1.x 深度學習秘籍
- 零、前言
- 一、TensorFlow 簡介
- 二、回歸
- 三、神經網絡:感知器
- 四、卷積神經網絡
- 五、高級卷積神經網絡
- 六、循環神經網絡
- 七、無監督學習
- 八、自編碼器
- 九、強化學習
- 十、移動計算
- 十一、生成模型和 CapsNet
- 十二、分布式 TensorFlow 和云深度學習
- 十三、AutoML 和學習如何學習(元學習)
- 十四、TensorFlow 處理單元
- 使用 TensorFlow 構建機器學習項目中文版
- 一、探索和轉換數據
- 二、聚類
- 三、線性回歸
- 四、邏輯回歸
- 五、簡單的前饋神經網絡
- 六、卷積神經網絡
- 七、循環神經網絡和 LSTM
- 八、深度神經網絡
- 九、大規模運行模型 -- GPU 和服務
- 十、庫安裝和其他提示
- TensorFlow 深度學習中文第二版
- 一、人工神經網絡
- 二、TensorFlow v1.6 的新功能是什么?
- 三、實現前饋神經網絡
- 四、CNN 實戰
- 五、使用 TensorFlow 實現自編碼器
- 六、RNN 和梯度消失或爆炸問題
- 七、TensorFlow GPU 配置
- 八、TFLearn
- 九、使用協同過濾的電影推薦
- 十、OpenAI Gym
- TensorFlow 深度學習實戰指南中文版
- 一、入門
- 二、深度神經網絡
- 三、卷積神經網絡
- 四、循環神經網絡介紹
- 五、總結
- 精通 TensorFlow 1.x
- 一、TensorFlow 101
- 二、TensorFlow 的高級庫
- 三、Keras 101
- 四、TensorFlow 中的經典機器學習
- 五、TensorFlow 和 Keras 中的神經網絡和 MLP
- 六、TensorFlow 和 Keras 中的 RNN
- 七、TensorFlow 和 Keras 中的用于時間序列數據的 RNN
- 八、TensorFlow 和 Keras 中的用于文本數據的 RNN
- 九、TensorFlow 和 Keras 中的 CNN
- 十、TensorFlow 和 Keras 中的自編碼器
- 十一、TF 服務:生產中的 TensorFlow 模型
- 十二、遷移學習和預訓練模型
- 十三、深度強化學習
- 十四、生成對抗網絡
- 十五、TensorFlow 集群的分布式模型
- 十六、移動和嵌入式平臺上的 TensorFlow 模型
- 十七、R 中的 TensorFlow 和 Keras
- 十八、調試 TensorFlow 模型
- 十九、張量處理單元
- TensorFlow 機器學習秘籍中文第二版
- 一、TensorFlow 入門
- 二、TensorFlow 的方式
- 三、線性回歸
- 四、支持向量機
- 五、最近鄰方法
- 六、神經網絡
- 七、自然語言處理
- 八、卷積神經網絡
- 九、循環神經網絡
- 十、將 TensorFlow 投入生產
- 十一、更多 TensorFlow
- 與 TensorFlow 的初次接觸
- 前言
- 1.?TensorFlow 基礎知識
- 2. TensorFlow 中的線性回歸
- 3. TensorFlow 中的聚類
- 4. TensorFlow 中的單層神經網絡
- 5. TensorFlow 中的多層神經網絡
- 6. 并行
- 后記
- TensorFlow 學習指南
- 一、基礎
- 二、線性模型
- 三、學習
- 四、分布式
- TensorFlow Rager 教程
- 一、如何使用 TensorFlow Eager 構建簡單的神經網絡
- 二、在 Eager 模式中使用指標
- 三、如何保存和恢復訓練模型
- 四、文本序列到 TFRecords
- 五、如何將原始圖片數據轉換為 TFRecords
- 六、如何使用 TensorFlow Eager 從 TFRecords 批量讀取數據
- 七、使用 TensorFlow Eager 構建用于情感識別的卷積神經網絡(CNN)
- 八、用于 TensorFlow Eager 序列分類的動態循壞神經網絡
- 九、用于 TensorFlow Eager 時間序列回歸的遞歸神經網絡
- TensorFlow 高效編程
- 圖嵌入綜述:問題,技術與應用
- 一、引言
- 三、圖嵌入的問題設定
- 四、圖嵌入技術
- 基于邊重構的優化問題
- 應用
- 基于深度學習的推薦系統:綜述和新視角
- 引言
- 基于深度學習的推薦:最先進的技術
- 基于卷積神經網絡的推薦
- 關于卷積神經網絡我們理解了什么
- 第1章概論
- 第2章多層網絡
- 2.1.4生成對抗網絡
- 2.2.1最近ConvNets演變中的關鍵架構
- 2.2.2走向ConvNet不變性
- 2.3時空卷積網絡
- 第3章了解ConvNets構建塊
- 3.2整改
- 3.3規范化
- 3.4匯集
- 第四章現狀
- 4.2打開問題
- 參考
- 機器學習超級復習筆記
- Python 遷移學習實用指南
- 零、前言
- 一、機器學習基礎
- 二、深度學習基礎
- 三、了解深度學習架構
- 四、遷移學習基礎
- 五、釋放遷移學習的力量
- 六、圖像識別與分類
- 七、文本文件分類
- 八、音頻事件識別與分類
- 九、DeepDream
- 十、自動圖像字幕生成器
- 十一、圖像著色
- 面向計算機視覺的深度學習
- 零、前言
- 一、入門
- 二、圖像分類
- 三、圖像檢索
- 四、對象檢測
- 五、語義分割
- 六、相似性學習
- 七、圖像字幕
- 八、生成模型
- 九、視頻分類
- 十、部署
- 深度學習快速參考
- 零、前言
- 一、深度學習的基礎
- 二、使用深度學習解決回歸問題
- 三、使用 TensorBoard 監控網絡訓練
- 四、使用深度學習解決二分類問題
- 五、使用 Keras 解決多分類問題
- 六、超參數優化
- 七、從頭開始訓練 CNN
- 八、將預訓練的 CNN 用于遷移學習
- 九、從頭開始訓練 RNN
- 十、使用詞嵌入從頭開始訓練 LSTM
- 十一、訓練 Seq2Seq 模型
- 十二、深度強化學習
- 十三、生成對抗網絡
- TensorFlow 2.0 快速入門指南
- 零、前言
- 第 1 部分:TensorFlow 2.00 Alpha 簡介
- 一、TensorFlow 2 簡介
- 二、Keras:TensorFlow 2 的高級 API
- 三、TensorFlow 2 和 ANN 技術
- 第 2 部分:TensorFlow 2.00 Alpha 中的監督和無監督學習
- 四、TensorFlow 2 和監督機器學習
- 五、TensorFlow 2 和無監督學習
- 第 3 部分:TensorFlow 2.00 Alpha 的神經網絡應用
- 六、使用 TensorFlow 2 識別圖像
- 七、TensorFlow 2 和神經風格遷移
- 八、TensorFlow 2 和循環神經網絡
- 九、TensorFlow 估計器和 TensorFlow HUB
- 十、從 tf1.12 轉換為 tf2
- TensorFlow 入門
- 零、前言
- 一、TensorFlow 基本概念
- 二、TensorFlow 數學運算
- 三、機器學習入門
- 四、神經網絡簡介
- 五、深度學習
- 六、TensorFlow GPU 編程和服務
- TensorFlow 卷積神經網絡實用指南
- 零、前言
- 一、TensorFlow 的設置和介紹
- 二、深度學習和卷積神經網絡
- 三、TensorFlow 中的圖像分類
- 四、目標檢測與分割
- 五、VGG,Inception,ResNet 和 MobileNets
- 六、自編碼器,變分自編碼器和生成對抗網絡
- 七、遷移學習
- 八、機器學習最佳實踐和故障排除
- 九、大規模訓練
- 十、參考文獻