
# 四、分布式
## 自定義函數
Conway 的生命游戲是一個有趣的計算機科學模擬,它在地圖上發生,有許多正方形的單元格,就像棋盤一樣。 模擬以特定的時間步驟進行,并且板上的每個單元可以是 1(生存)或 0(死亡)。 經過特定的時間步驟后,每個單元格都處于生存狀態或死亡狀態:
+ 如果細胞是活著的,但是有一個或零個鄰居,它會由于“人口不足”而“死亡”。
+ 如果細胞存活并且有兩個或三個鄰居,它就會活著。
+ 如果細胞有三個以上的鄰居,它就會因人口過多而死亡。
+ 任何有三個鄰居的死細胞都會再生。
雖然這些規則似乎非常病態,但實際的模擬非常簡單,創造了非常有趣的模式。 我們將創建一個 TensorFlow 程序來管理 Conway 的生命游戲,并在此過程中了解自定義`py_func`函數,并生成如下動畫:
<http://learningtensorflow.com/images/game.mp4>
首先,讓我們生成地圖。 這是非常基本的,因為它只是一個 0 和 1 的矩陣。 我們隨機生成初始地圖,每次運行時都會提供不同的地圖:
```py
import tensorflow as tf
from matplotlib import pyplot as plt
shape = (50, 50)
initial_board = tf.random_uniform(shape, minval=0, maxval=2, dtype=tf.int32)
with tf.Session() as session:
X = session.run(initial_board)
fig = plt.figure()
plot = plt.imshow(X, cmap='Greys', interpolation='nearest')
plt.show()
```
我們生成一個隨機選擇的 0 和 1 的`initial_board`,然后運行它來獲取值。 然后我們使用`matplotlib.pyplot`來顯示它,使用`imshow`函數,它基本上只根據一些`cmap`顏色方案繪制矩陣中的值。 在這種情況下,使用`'Greys'`會產生黑白矩陣,以及我們生命游戲的單個初始起點:

### 更新地圖的狀態
由于生命游戲的地圖狀態表示為矩陣,因此使用矩陣運算符更新它是有意義的。 這應該提供一種快速方法,更新給定時間點的狀態。
非常有才華的 [Jake VanderPlas](http://staff.washington.edu/jakevdp/) 在使用 SciPy 和 NumPy 更新生命游戲中的特定狀態方面做了一些出色的工作。 他的寫作值得一讀,可以在[這里]找到。 如果你對以下代碼的工作原理感興趣,我建議你閱讀 Jake 的說明。 簡而言之,`convolve2d`那行標識每個單元有多少鄰居(這是計算機視覺中的常見操作符)。 我稍微更新了代碼以減少行數,請參閱下面的更新后的函數:
```py
def update_board(X):
# Check out the details at: https://jakevdp.github.io/blog/2013/08/07/conways-game-of-life/
# Compute number of neighbours,
N = convolve2d(X, np.ones((3, 3)), mode='same', boundary='wrap') - X
# Apply rules of the game
X = (N == 3) | (X & (N == 2))
return X
```
`update_board`函數是 NumPy 數組的函數。 它不適用于張量,迄今為止,在 TensorFlow 中沒有一種好方法可以做到這一點(雖然你可以使用現有的工具自己編寫它,它不是直截了當的)。
在 TensorFlow 的 0.7 版本中,添加了一個新函數`py_func`,它接受 python 函數并將其轉換為 TensorFlow 中的節點。
在撰寫本文時(3 月 22 日),0.6 是正式版,并且它沒有`py_func`。 我建議按照 TensorFlow 的 Github 頁面上的說明為你的系統安裝每晚構建。 例如,對于 Ubuntu 用戶,你下載相關的 wheel 文件(python 安裝文件)并安裝它:
```
python -m wheel install --force ~/Downloads/tensorflow-0.7.1-cp34-cp34m-linux_x86_64.whl
```
請記住,你需要正確激活 TensorFlow 源(如果你愿意的話)。
最終結果應該是你安裝了 TensorFlow 的 0.7 或更高版本。 你可以通過在終端中運行此代碼來檢查:
```
python -c "import tensorflow as tf; print(tf.__version__)"
```
結果將是版本號,在編寫時為 0.7.1。
在代碼上:
```py
board = tf.placeholder(tf.int32, shape=shape, name='board')
board_update = tf.py_func(update_board, [board], [tf.int32])
```
從這里開始,你可以像往常一樣,對張量操作節點(即`board_update`)運行初始地圖。 要記住的一點是,運行`board_update`的結果是一個矩陣列表,即使我們的函數只定義了一個返回值。 我們通過在行尾添加`[0]`來獲取第一個結果,我們更新的地圖存儲在`X`中。
```py
with tf.Session() as session:
initial_board_values = session.run(initial_board)
X = session.run(board_update, feed_dict={board: initial_board_values})[0]
```
所得值`X`是初始配置之后更新的地圖。 它看起來很像一個初始隨機地圖,但我們從未顯示初始的(雖然你可以更新代碼來繪制兩個值)
### 循環
這是事情變得非常有趣的地方,盡管從 TensorFlow 的角度來看,我們已經為本節做了很多努力。 我們可以使用`matplotlib`來顯示和動畫,因此顯示時間步驟中的模擬狀態,就像我們的原始 GIF 一樣。 `matplotlib`動畫的復雜性有點棘手,但是你創建一個更新并返回繪圖的函數,并使用該函數調用動畫代碼:
```py
import matplotlib.animation as animation
def game_of_life(*args):
X = session.run(board_update, feed_dict={board: X})[0]
plot.set_array(X)
return plot,
ani = animation.FuncAnimation(fig, game_of_life, interval=200, blit=True)
plt.show()
```
> 提示:你需要從早期代碼中刪除`plt.show()`才能運行!
我將把拼圖的各個部分作為練習留給讀者,但最終結果將是一個窗口出現,游戲狀態每 200 毫秒更新一次。
如果你實現了,請給我們發消息!
1)獲取完整的代碼示例,使用`matplotlib`和 TensorFlow 生成游戲的動畫
2)康威的生命游戲已被廣泛研究,并有許多有趣的模式。 創建一個從文件加載模式的函數,并使用它們而不是隨機地圖。 我建議從 Gosper 的滑翔槍開始。
3)生命游戲的一個問題(特征?)是地圖可以重復,導致循環永遠不會停止。 編寫一些跟蹤之前游戲狀態的代碼,并在游戲狀態重復時停止循環。
## 使用 GPU
GPU(圖形處理單元)是大多數現代計算機的組件,旨在執行 3D 圖形所需的計算。 它們最常見的用途是為視頻游戲執行這些操作,計算多邊形向用戶顯示游戲。 總的來說,GPU 基本上是一大批小型處理器,執行高度并行化的計算。 你現在基本上有了一個迷你超級計算機!
> 注意:不是真正的超級計算機,但在許多方面有些相似。
雖然 GPU 中的每個“CPU”都很慢,但它們中有很多并且它們專門用于數字處理。 這意味著 GPU 可以同時執行許多簡單的數字處理任務。 幸運的是,這正是許多機器學習算法需要做的事情。

> 沒有 GPU 嗎?
>
> 大多數現代(最近10年)的計算機都有某種形式的 GPU,即使它內置在你的主板上。 出于本教程的目的,這就足夠了。
>
> 你需要知道你有什么類型的顯卡。 Windows 用戶可以遵循[這些說明](https://help.sketchup.com/en/article/36253),其他系統的用戶需要查閱他們系統的文檔。
> 非 N 卡用戶
>
> 雖然其他顯卡可能是受支持的,但本教程僅在最近的 NVidia 顯卡上進行測試。 如果你的顯卡屬于不同類型,我建議你尋找 NVidia 顯卡來學習,購買或者借用。 如果這對你來說真的很難,請聯系你當地的大學或學校,看看他們是否可以提供幫助。 如果你仍然遇到問題,請隨意閱讀以及使用標準 CPU 進行操作。 你將能夠在以后遷移所學的東西。
### 安裝 GPU 版的 TensorFlow
如果你之前沒有安裝支持 GPU 的 TensorFlow,那么我們首先需要這樣做。我們在第 1 課中沒有說明,所以如果你沒有按照你的方式啟用 GPU 支持,那就是沒有了。
我建議你為此創建一個新的 Anaconda 環境,而不是嘗試更新以前的環境。
### 在你開始之前
前往 [TensorFlow 官方安裝說明](https://www.tensorflow.org/versions/r0.9/get_started/os_setup.html#anaconda-installation),并遵循 Anaconda 安裝說明。這與我們在第 1 課中所做的主要區別在于,你需要為你的系統啟用支持 GPU 的 TensorFlow 版本。但是,在將 TensorFlow 安裝到此環境之前,你需要使用 CUDA 和 CuDNN,將計算機設置為啟用 GPU 的。[TensorFlow 官方文檔](https://www.tensorflow.org/versions/r0.9/get_started/os_setup.html#optional-install-cuda-gpus-on-linux)逐步概述了這一點,但如果你嘗試設置最近的 Ubuntu 安裝,我推薦[本教程](http://www.computervisionbytecnalia.com/es/2016/06/deep-learning-development-setup-for-ubuntu-16-04-xenial/)。主要原因是,在撰寫本文時(2016 年 7 月),尚未為最新的 Ubuntu 版本構建 CUDA,這意味著該過程更加手動。
### 使用你的 GPU
真的很簡單。 至少是字面上。 只需將這個:
```py
# 起步操作
with tf.Session() as sess:
# 運行你的代碼
```
改為這個:
```py
with tf.device("/gpu:0"):
# 起步操作
with tf.Session() as sess:
# 運行你的代碼
```
這個新行將創建一個新的上下文管理器,告訴 TensorFlow 在 GPU 上執行這些操作。
我們來看一個具體的例子。 下面的代碼創建一個隨機矩陣,其大小在命令行中提供。 我們可以使用命令行選項在 CPU 或 GPU 上運行代碼:
```py
import sys
import numpy as np
import tensorflow as tf
from datetime import datetime
device_name = sys.argv[1] # Choose device from cmd line. Options: gpu or cpu
shape = (int(sys.argv[2]), int(sys.argv[2]))
if device_name == "gpu":
device_name = "/gpu:0"
else:
device_name = "/cpu:0"
with tf.device(device_name):
random_matrix = tf.random_uniform(shape=shape, minval=0, maxval=1)
dot_operation = tf.matmul(random_matrix, tf.transpose(random_matrix))
sum_operation = tf.reduce_sum(dot_operation)
startTime = datetime.now()
with tf.Session(config=tf.ConfigProto(log_device_placement=True)) as session:
result = session.run(sum_operation)
print(result)
# 很難在終端上看到具有大量輸出的結果 - 添加一些換行符以提高可讀性。
print("\n" * 5)
print("Shape:", shape, "Device:", device_name)
print("Time taken:", datetime.now() - startTime)
print("\n" * 5)
```
你可以在命令行運行此命令:
```
python matmul.py gpu 1500
```
這將使用 GPU 和大小為 1500 平方的矩陣。 使用以下命令在 CPU 上執行相同的操作:
```
python matmul.py cpu 1500
```
與普通的 TensorFlow 腳本相比,在運行支持 GPU 的代碼時,你會注意到的第一件事是輸出大幅增加。 這是我的計算機在打印出任何操作結果之前打印出來的內容。
```
I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcublas.so locally
I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcudnn.so.5 locally
I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcufft.so locally
I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcuda.so.1 locally
I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcurand.so locally
I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:925] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
I tensorflow/core/common_runtime/gpu/gpu_init.cc:102] Found device 0 with properties:
name: GeForce GTX 950M
major: 5 minor: 0 memoryClockRate (GHz) 1.124
pciBusID 0000:01:00.0
Total memory: 3.95GiB
Free memory: 3.50GiB
I tensorflow/core/common_runtime/gpu/gpu_init.cc:126] DMA: 0
I tensorflow/core/common_runtime/gpu/gpu_init.cc:136] 0: Y
I tensorflow/core/common_runtime/gpu/gpu_device.cc:838] Creating TensorFlow device (/gpu:0) -> (device: 0, name: GeForce GTX 950M, pci bus id: 0000:01:00.0)
```
如果你的代碼沒有產生與此類似的輸出,那么你沒有運行支持 GPU 的 Tensorflow。或者,如果你收到`ImportError: libcudart.so.7.5: cannot open shared object file: No such file or directory`這樣的錯誤,那么你還沒有正確安裝 CUDA 庫。在這種情況下,你需要返回,遵循指南來在你的系統上安裝 CUDA。
嘗試在 CPU 和 GPU 上運行上面的代碼,慢慢增加數量。從 1500 開始,然后嘗試 3000,然后是 4500,依此類推。你會發現 CPU 開始需要相當長的時間,而 GPU 在這個操作中真的非常快!
如果你有多個 GPU,則可以使用其中任何一個。 GPU 是從零索引的 - 上面的代碼訪問第一個 GPU。將設備更改為`gpu:1`使用第二個 GPU,依此類推。你還可以將部分計算發送到一個 GPU,然后是另一個 GPU。此外,你可以以類似的方式訪問計算機的 CPU - 只需使用`cpu:0`(或其他數字)。
### 我應該把什么樣的操作發送給 GPU?
通常,如果該過程的步驟可以描述,例如“執行該數學運算數千次”,則將其發送到 GPU。 示例包括矩陣乘法和計算矩陣的逆。 實際上,許多基本矩陣運算是 GPU 的拿手好戲。 作為一個過于寬泛和簡單的規則,應該在 CPU 上執行其他操作。
更換設備和使用 GPU 還需要付出代價。 GPU 無法直接訪問你計算機的其余部分(當然,除了顯示器)。 因此,如果你在 GPU 上運行命令,則需要先將所有數據復制到 GPU,然后執行操作,然后將結果復制回計算機的主存。 TensorFlow 在背后處理這個問題,因此代碼很簡單,但仍需要執行工作。
并非所有操作都可以在 GPU 上完成。 如果你收到以下錯誤,你正在嘗試執行無法在 GPU 上執行的操作:
> Cannot assign a device to node 'PyFunc': Could not satisfy explicit device specification '/device:GPU:1' because no devices matching that specification are registered in this process;
如果是這種情況,你可以手動將設備更改為 CPU 來執行此函數,或者設置 TensorFlow,以便在這種情況下自動更改設備。 為此,請在配置中設置`allow_soft_placement`為`True`,作為創建會話的一部分。 原型看起來像這樣:
```py
with tf.Session(config=tf.ConfigProto(allow_soft_placement=True)):
# 在這里運行你的圖
```
我還建議在使用 GPU 時記錄設備的放置,這樣可以輕松調試與不同設備使用情況相關的問題。 這會將設備的使用情況打印到日志中,從而可以查看設備何時更改以及它對圖的影響。
```py
with tf.Session(config=tf.ConfigProto(allow_soft_placement=True, log_device_placement=True)):
# 在這里運行你的圖
```
1)設置你的計算機,將 GPU 用于 TensorFlow(或者如果你最近沒有 GPU,就借一臺)。
2)嘗試在 GPU 上運行以前的練習的解決方案。 哪些操作可以在 GPU 上執行,哪些不可以?
3)構建一個在 GPU 和 CPU 上都使用操作的程序。 使用我們在第 5 課中看到的性能分析代碼,來估計向 GPU 發送數據和從 GPU 獲取數據的影響。
4)把你的代碼發給我! 我很樂意看到你的代碼示例,如何使用 Tensorflow,以及你找到的任何技巧。
## 分布式計算
TensorFlow 支持分布式計算,允許在不同的進程上計算圖的部分,這些進程可能位于完全不同的服務器上! 此外,這可用于將計算分發到具有強大 GPU 的服務器,并在具有更多內存的服務器上完成其他計算,依此類推。 雖然接口有點棘手,所以讓我們從頭開始構建。
這是我們的第一個腳本,我們將在單個進程上運行,然后轉移到多個進程。
```py
import tensorflow as tf
x = tf.constant(2)
y1 = x + 300
y2 = x - 66
y = y1 + y2
with tf.Session() as sess:
result = sess.run(y)
print(result)
```
到現在為止,這個腳本不應該特別嚇到你。 我們有一個常數和三個基本方程。 結果(238)最后打印出來。
TensorFlow 有點像服務器 - 客戶端模型。 這個想法是你創造了一大堆能夠完成繁重任務的工作器。 然后,你可以在其中一個工作器上創建會話,它將計算圖,可能將其中的一部分分發到服務器上的其他集群。
為此,主工作器,主機,需要了解其他工作器。 這是通過創建`ClusterSpec`來完成的,你需要將其傳遞給所有工作器。 `ClusterSpec`使用字典構建,其中鍵是“作業名稱”,每個任務包含許多工作器。
下面是這個圖表看上去的樣子。
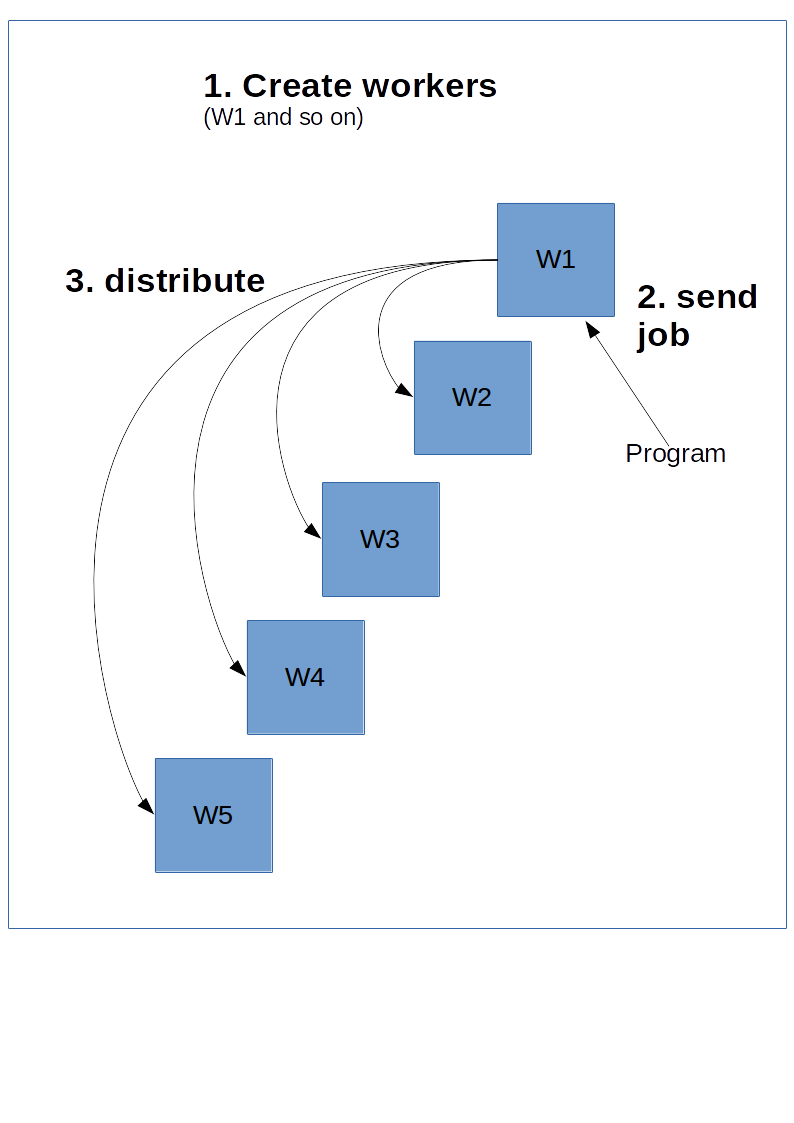
以下代碼創建一個`ClusterSpect`,其作業名稱為`local`,和兩個工作器進程。
> 請注意,這些代碼不會啟動這些進程,只會創建一個將啟動它們的引用。
```py
import tensorflow as tf
cluster = tf.train.ClusterSpec({"local": ["localhost:2222", "localhost:2223"]})
```
接下來,我們啟動進程。 為此,我們繪制其中一個工作器的圖,并啟動它:
```py
server = tf.train.Server(cluster, job_name="local", task_index=1)
```
上面的代碼在`local`作業下啟動`localhost:2223`工作器。
下面是一個腳本,你可以從命令行運行來啟動這兩個進程。 將代碼在你的計算機上保存為`create_worker.py`并運行`python create_worker.py 0`然后運行`python create_worker.py 1`。你需要單獨的終端來執行此操作,因為腳本不會自己停止(他們正在等待指令)。
```py
# 從命令行獲取任務編號
import sys
task_number = int(sys.argv[1])
import tensorflow as tf
cluster = tf.train.ClusterSpec({"local": ["localhost:2222", "localhost:2223"]})
server = tf.train.Server(cluster, job_name="local", task_index=task_number)
print("Starting server #{}".format(task_number))
server.start()
server.join()
```
執行此操作后,你將發現服務器運行在兩個終端上。 我們準備分發!
“分發”作業的最簡單方法是在其中一個進程上創建一個會話,然后在那里執行圖。 只需將上面的`session`行更改為:
```py
with tf.Session("grpc://localhost:2222") as sess:
```
現在,這并沒有真正分發,不足以將作業發送到該服務器。 TensorFlow 可以將進程分發到集群中的其他資源,但可能不會。 我們可以通過指定設備來強制執行此操作(就像我們在上一課中對 GPU 所做的那樣):
```py
import tensorflow as tf
cluster = tf.train.ClusterSpec({"local": ["localhost:2222", "localhost:2223"]})
x = tf.constant(2)
with tf.device("/job:local/task:1"):
y2 = x - 66
with tf.device("/job:local/task:0"):
y1 = x + 300
y = y1 + y2
with tf.Session("grpc://localhost:2222") as sess:
result = sess.run(y)
print(result)
```
現在我們正在分發! 這可以通過根據名稱和任務編號,為工作器分配任務來實現。 格式為:
```py
/job:JOB_NAME/task:TASK_NUMBER
```
通過多個作業(即識別具有大型 GPU 的計算機),我們可以以多種不同方式分發進程。
### 映射和歸約
MapReduce 是執行大型操作的流行范式。 它由兩個主要步驟組成(雖然在實踐中還有一些步驟)。
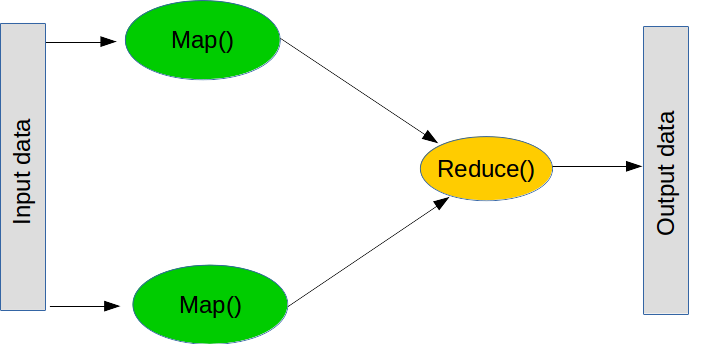
第一步稱為映射,意思是“獲取列表,并將函數應用于每個元素”。 你可以在普通的 python 中執行這樣的映射:
```py
def myfunction(x):
return x + 5
map_result = map(myfunction, [1, 2, 3])
print(list(map_result))
```
第二步是歸約,這意味著“獲取列表,并使用函數將它們組合”。 常見的歸約操作是求和 - 即“獲取數字列表并通過將它們全部加起來組合它們”,這可以通過創建相加兩個數字的函數來執行。 `reduce`的原理是獲取列表的前兩個值,執行函數,獲取結果,然后使用結果和下一個值執行函數。 總之,我們將前兩個數字相加,取結果,加上下一個數字,依此類推,直到我們到達列表的末尾。 同樣,`reduce`是普通 python 的一部分(盡管它不是分布式的):
```py
from functools import reduce
def add(a, b):
return a + b
print(reduce(add, [1, 2, 3]))
```
> 譯者注:原作者這里的話并不值得推薦,比如`for`你更應該使用`reduce`,因為它更安全。
回到分布式 TensorFlow,執行`map`和`reduce`操作是許多非平凡程序的關鍵構建塊。 例如,集成學習可以將單獨的機器學習模型發送給多個工作器,然后組合分類結果來形成最終結果。另一個例子是一個進程。
這是我們將分發的另一個基本腳本:
```py
import numpy as np
import tensorflow as tf
x = tf.placeholder(tf.float32, 100)
mean = tf.reduce_mean(x)
with tf.Session() as sess:
result = sess.run(mean, feed_dict={x: np.random.random(100)})
print(result)
import numpy as np
import tensorflow as tf
x = tf.placeholder(tf.float32, 100)
mean = tf.reduce_mean(x)
with tf.Session() as sess:
result = sess.run(mean, feed_dict={x: np.random.random(100)})
print(result)
```
轉換為分布式版本只是對先前轉換的更改:
```py
import numpy as np
import tensorflow as tf
cluster = tf.train.ClusterSpec({"local": ["localhost:2222", "localhost:2223"]})
x = tf.placeholder(tf.float32, 100)
with tf.device("/job:local/task:1"):
first_batch = tf.slice(x, [0], [50])
mean1 = tf.reduce_mean(first_batch)
with tf.device("/job:local/task:0"):
second_batch = tf.slice(x, [50], [-1])
mean2 = tf.reduce_mean(second_batch)
mean = (mean1 + mean2) / 2
with tf.Session("grpc://localhost:2222") as sess:
result = sess.run(mean, feed_dict={x: np.random.random(100)})
print(result)
```
如果你從映射和歸約的角度來考慮它,你會發現分發計算更容易。 首先,“我怎樣才能將這個問題分解成可以獨立解決的子問題?” - 這就是你的映射。 第二,“我如何將答案結合起來來形成最終結果?” - 這就是你的歸約。
在機器學習中,映射最常用的場景就是分割數據集。 線性模型和神經網絡通常都非常合適,因為它們可以單獨訓練,然后再進行組合。
1)將`ClusterSpec`中的`local`更改為其他內容。 你還需要在腳本中進行哪些更改才能使其正常工作?
2)計算平均的腳本目前依賴于切片大小相同的事實。 嘗試使用不同大小的切片并觀察錯誤。 通過使用`tf.size`和以下公式來組合切片的平均值來解決此問題:
```py
overall_average = ((size_slice_1 * mean_slice_1) + (size_slice_2 * mean_slice_2) + ...) / total_size
```
3)你可以通過修改設備字符串來指定遠程計算機上的設備。 例如,`/job:local/task:0/gpu:0`會定位`local`作業的 GPU。 創建一個使用遠程 GPU 的作業。 如果你有備用的第二臺計算機,請嘗試通過網絡執行此操作。
- TensorFlow 1.x 深度學習秘籍
- 零、前言
- 一、TensorFlow 簡介
- 二、回歸
- 三、神經網絡:感知器
- 四、卷積神經網絡
- 五、高級卷積神經網絡
- 六、循環神經網絡
- 七、無監督學習
- 八、自編碼器
- 九、強化學習
- 十、移動計算
- 十一、生成模型和 CapsNet
- 十二、分布式 TensorFlow 和云深度學習
- 十三、AutoML 和學習如何學習(元學習)
- 十四、TensorFlow 處理單元
- 使用 TensorFlow 構建機器學習項目中文版
- 一、探索和轉換數據
- 二、聚類
- 三、線性回歸
- 四、邏輯回歸
- 五、簡單的前饋神經網絡
- 六、卷積神經網絡
- 七、循環神經網絡和 LSTM
- 八、深度神經網絡
- 九、大規模運行模型 -- GPU 和服務
- 十、庫安裝和其他提示
- TensorFlow 深度學習中文第二版
- 一、人工神經網絡
- 二、TensorFlow v1.6 的新功能是什么?
- 三、實現前饋神經網絡
- 四、CNN 實戰
- 五、使用 TensorFlow 實現自編碼器
- 六、RNN 和梯度消失或爆炸問題
- 七、TensorFlow GPU 配置
- 八、TFLearn
- 九、使用協同過濾的電影推薦
- 十、OpenAI Gym
- TensorFlow 深度學習實戰指南中文版
- 一、入門
- 二、深度神經網絡
- 三、卷積神經網絡
- 四、循環神經網絡介紹
- 五、總結
- 精通 TensorFlow 1.x
- 一、TensorFlow 101
- 二、TensorFlow 的高級庫
- 三、Keras 101
- 四、TensorFlow 中的經典機器學習
- 五、TensorFlow 和 Keras 中的神經網絡和 MLP
- 六、TensorFlow 和 Keras 中的 RNN
- 七、TensorFlow 和 Keras 中的用于時間序列數據的 RNN
- 八、TensorFlow 和 Keras 中的用于文本數據的 RNN
- 九、TensorFlow 和 Keras 中的 CNN
- 十、TensorFlow 和 Keras 中的自編碼器
- 十一、TF 服務:生產中的 TensorFlow 模型
- 十二、遷移學習和預訓練模型
- 十三、深度強化學習
- 十四、生成對抗網絡
- 十五、TensorFlow 集群的分布式模型
- 十六、移動和嵌入式平臺上的 TensorFlow 模型
- 十七、R 中的 TensorFlow 和 Keras
- 十八、調試 TensorFlow 模型
- 十九、張量處理單元
- TensorFlow 機器學習秘籍中文第二版
- 一、TensorFlow 入門
- 二、TensorFlow 的方式
- 三、線性回歸
- 四、支持向量機
- 五、最近鄰方法
- 六、神經網絡
- 七、自然語言處理
- 八、卷積神經網絡
- 九、循環神經網絡
- 十、將 TensorFlow 投入生產
- 十一、更多 TensorFlow
- 與 TensorFlow 的初次接觸
- 前言
- 1.?TensorFlow 基礎知識
- 2. TensorFlow 中的線性回歸
- 3. TensorFlow 中的聚類
- 4. TensorFlow 中的單層神經網絡
- 5. TensorFlow 中的多層神經網絡
- 6. 并行
- 后記
- TensorFlow 學習指南
- 一、基礎
- 二、線性模型
- 三、學習
- 四、分布式
- TensorFlow Rager 教程
- 一、如何使用 TensorFlow Eager 構建簡單的神經網絡
- 二、在 Eager 模式中使用指標
- 三、如何保存和恢復訓練模型
- 四、文本序列到 TFRecords
- 五、如何將原始圖片數據轉換為 TFRecords
- 六、如何使用 TensorFlow Eager 從 TFRecords 批量讀取數據
- 七、使用 TensorFlow Eager 構建用于情感識別的卷積神經網絡(CNN)
- 八、用于 TensorFlow Eager 序列分類的動態循壞神經網絡
- 九、用于 TensorFlow Eager 時間序列回歸的遞歸神經網絡
- TensorFlow 高效編程
- 圖嵌入綜述:問題,技術與應用
- 一、引言
- 三、圖嵌入的問題設定
- 四、圖嵌入技術
- 基于邊重構的優化問題
- 應用
- 基于深度學習的推薦系統:綜述和新視角
- 引言
- 基于深度學習的推薦:最先進的技術
- 基于卷積神經網絡的推薦
- 關于卷積神經網絡我們理解了什么
- 第1章概論
- 第2章多層網絡
- 2.1.4生成對抗網絡
- 2.2.1最近ConvNets演變中的關鍵架構
- 2.2.2走向ConvNet不變性
- 2.3時空卷積網絡
- 第3章了解ConvNets構建塊
- 3.2整改
- 3.3規范化
- 3.4匯集
- 第四章現狀
- 4.2打開問題
- 參考
- 機器學習超級復習筆記
- Python 遷移學習實用指南
- 零、前言
- 一、機器學習基礎
- 二、深度學習基礎
- 三、了解深度學習架構
- 四、遷移學習基礎
- 五、釋放遷移學習的力量
- 六、圖像識別與分類
- 七、文本文件分類
- 八、音頻事件識別與分類
- 九、DeepDream
- 十、自動圖像字幕生成器
- 十一、圖像著色
- 面向計算機視覺的深度學習
- 零、前言
- 一、入門
- 二、圖像分類
- 三、圖像檢索
- 四、對象檢測
- 五、語義分割
- 六、相似性學習
- 七、圖像字幕
- 八、生成模型
- 九、視頻分類
- 十、部署
- 深度學習快速參考
- 零、前言
- 一、深度學習的基礎
- 二、使用深度學習解決回歸問題
- 三、使用 TensorBoard 監控網絡訓練
- 四、使用深度學習解決二分類問題
- 五、使用 Keras 解決多分類問題
- 六、超參數優化
- 七、從頭開始訓練 CNN
- 八、將預訓練的 CNN 用于遷移學習
- 九、從頭開始訓練 RNN
- 十、使用詞嵌入從頭開始訓練 LSTM
- 十一、訓練 Seq2Seq 模型
- 十二、深度強化學習
- 十三、生成對抗網絡
- TensorFlow 2.0 快速入門指南
- 零、前言
- 第 1 部分:TensorFlow 2.00 Alpha 簡介
- 一、TensorFlow 2 簡介
- 二、Keras:TensorFlow 2 的高級 API
- 三、TensorFlow 2 和 ANN 技術
- 第 2 部分:TensorFlow 2.00 Alpha 中的監督和無監督學習
- 四、TensorFlow 2 和監督機器學習
- 五、TensorFlow 2 和無監督學習
- 第 3 部分:TensorFlow 2.00 Alpha 的神經網絡應用
- 六、使用 TensorFlow 2 識別圖像
- 七、TensorFlow 2 和神經風格遷移
- 八、TensorFlow 2 和循環神經網絡
- 九、TensorFlow 估計器和 TensorFlow HUB
- 十、從 tf1.12 轉換為 tf2
- TensorFlow 入門
- 零、前言
- 一、TensorFlow 基本概念
- 二、TensorFlow 數學運算
- 三、機器學習入門
- 四、神經網絡簡介
- 五、深度學習
- 六、TensorFlow GPU 編程和服務
- TensorFlow 卷積神經網絡實用指南
- 零、前言
- 一、TensorFlow 的設置和介紹
- 二、深度學習和卷積神經網絡
- 三、TensorFlow 中的圖像分類
- 四、目標檢測與分割
- 五、VGG,Inception,ResNet 和 MobileNets
- 六、自編碼器,變分自編碼器和生成對抗網絡
- 七、遷移學習
- 八、機器學習最佳實踐和故障排除
- 九、大規模訓練
- 十、參考文獻