
# 十、自動圖像字幕生成器
在前面的章節中,我們研究了一些案例研究,這些案例研究將遷移學習應用于計算機視覺以及**自然語言處理**(**NLP**)中的問題。 但是,這些都是它們各自特定領域中的問題。 在本章中,我們將專注于構建將這兩個流行領域(計算機視覺和 NLP)結合在一起的智能系統。 更具體地說,我們將專注于構建與機器翻譯相結合的對象識別系統,以構建自動圖像字幕生成器。
圖像字幕的想法并不是什么新鮮事物。 通常,存在于各種媒體資源(例如書籍,論文或社交媒體)中的任何圖像通常都需要加上適當的文本說明,以獲取更好的含義和上下文。 使這項任務變得艱巨的是,圖像標題通常是由一個或多個句子組成的自由流動的自然語言。 因此,由于用于圖像標題的文本數據的非結構化性質,這不是傳統的圖像分類問題。
可以通過結合使用計算機視覺領域專家的預訓練模型(例如**視覺幾何組**(**VGG**)和 Inception )以及序列模型(例如**循環神經網絡**(**RNN**)或**長短期記憶**(**LSTM**)),以生成單詞序列以形成圖片說明的適當單詞。 在本章中,我們將探索一種有趣的方法來構建自動圖像字幕或場景識別系統。
我們將涵蓋構建此系統的以下主要方面,該系統由深度學習和遷移學習提供支持:
* 了解圖像字幕
* 制定目標
* 了解數據
* 自動圖像字幕的方法
* 使用遷移學習的圖像特征提取
* 為我們的字幕建立詞匯表
* 構建圖像標題數據集生成器
* 建立我們的圖像字幕編解碼器深度學習模型
* 訓練我們的圖像字幕深度學習模型
* 自動圖像字幕實戰
我們將涵蓋計算機視覺和 NLP 的基本概念,以構建我們的自動圖像標題生成器。 我們將深入研究適合的深度學習架構,并結合遷移學習,以在流行且易于使用的圖像數據集之上實現該系統。 我們還將展示如何在新的照片和場景上構建和測試我們的自動圖像標題生成器。 您可以在 [GitHub 存儲庫](https://github.com/dipanjanS/hands-on-transfer-learning-with-python)中的`Chapter 11`文件夾中快速閱讀本章的代碼。 可以根據需要參考本章。 我們還將在那里發布一些獎金示例。
# 了解圖像字幕
到目前為止,您應該了解圖像字幕的意義和含義。 該任務可以簡單地定義為為任何圖像編寫和記錄自由流動的自然文本描述。 通常用于描述圖像中的各種場景或事件。 這也通常稱為**場景識別**。 讓我們看下面的例子:

看著這個場景,合適的標題或描述是什么? 以下是對場景的所有有效描述:
* 越野摩托車手在山上
* 一個家伙在山上的空中的自行車上
* 一輛越野車車手正在一條骯臟的道路上快速移動
* 騎自行車的人在空中騎黑摩托車
您會看到所有這些標題都是有效的并且相似,但是使用不同的詞來傳達相同的含義。 這就是為什么自動生成圖像標題并非易事的原因。
實際上,流行論文[《展示和演講:神經圖像字幕生成器》](https://arxiv.org/abs/1411.4555)(Vinyals 及其合作者,2015 年)描述了圖像字幕,從中我們汲取了構建此系統的靈感:
*自動描述圖像的內容是連接計算機視覺和自然語言處理的人工智能的基本問題。*
對于一個人來說,只需瞥一眼照片或圖像幾秒鐘就足以生成基于自然語言的字幕。 但是,由于大多數計算機視覺問題都集中在識別和分類問題上,因此使**人工智能**(**AI**)執行此任務極具挑戰性。 就復雜性而言,這是有關核心計算機視覺問題的一些主要任務:
* **圖像分類和識別**:這涉及經典的有監督學習問題,其中主要目標是基于幾個預定義的類類別(通常稱為**類標簽**)將圖像分配給特定類別 。 流行的 ImageNet 競賽就是這樣一項任務。
* **圖像標注**:稍微復雜一點的任務,我們嘗試使用圖像中各個實體的描述來標注圖像。 通常,這涉及圖像中特定部分或區域的類別,甚至是基于自然語言的文本描述。
* **圖像標題或場景識別**:我們嘗試使用準確的基于自然語言的文本描述來描述圖像的另一項復雜任務。 這是本章重點關注的領域。
圖像字幕的任務不是什么新鮮事。 已有多種利用技術的現有方法,例如將圖像中各個實體的文本描述縫合在一起以形成描述,甚至使用基于模板的文本生成技術。 但是,對于該任務,使用深度學習是一種更強大,更有效的方法。
# 制定目標
我們實際案例研究的主要目標是圖像字幕或場景識別。 在一定程度上,這是一個監督學習問題,而不是傳統的分類問題。 在這里,我們將處理一個稱為`Flickr8K`的圖像數據集,其中包含圖像或場景的樣本以及描述它們的相應自然語言標題。 這個想法是建立一個可以從這些圖像中學習并自動開始為圖像添加字幕的系統。
如前所述,傳統的圖像分類系統通常將圖像分類或分類為預定義的類。 在前面的章節中,我們已經構建了這樣的系統。 但是,圖像字幕系統的輸出通常是形成自然語言文本描述的單詞序列; 這比傳統的監督分類系統更加困難。
我們仍將監督模型訓練的性質,因為我們將必須基于訓練圖像數據及其相應的字幕說明來構建模型。 但是,建立模型的方法會略有不同。 我們將利用遷移學習和深度學習中的概念照常構建此系統。 更具體地說,我們將結合使用**深層卷積神經網絡**(**DCNNs**)和順序模型。
# 了解數據
讓我們看一下將用于構建模型的數據。 為簡單起見,我們將使用`Flickr8K`數據集。 該數據集包括從流行的圖像共享網站 Flickr 獲得的圖像。 要下載數據集,可以通過填寫以下[伊利諾伊大學計算機科學系的表格](https://forms.illinois.edu/sec/1713398)來請求它,您應該在電子郵件中獲取下載鏈接。
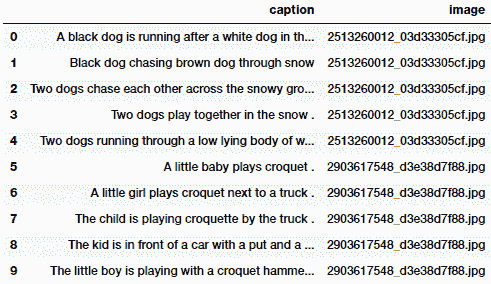
要查看與每個圖像有關的詳細信息,可以訪問[其網站](http://nlp.cs.illinois.edu/HockenmaierGroup/8k-pictures.html),其中討論了每個圖像及其圖像。 源,以及每個圖像的五個基于文本的標題。 通常,任何樣本圖像都將具有類似于以下內容的標題:
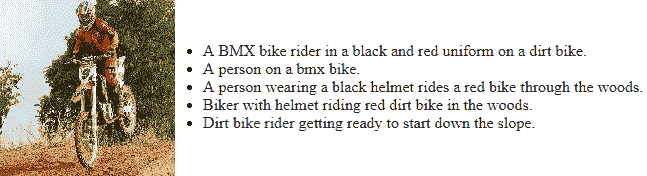
您可以清楚地看到圖像及其相應的標題。 很明顯,所有標題都試圖描述相同的圖像或場景,但是它可能專注于圖像的特定和不同方面,這使自動化成為一項艱巨的任務。 我們還建議讀者查看[《將圖像描述作為排名任務:數據,模型和評估指標》](https://pdfs.semanticscholar.org/f126/ec304cdad464f6248ac7f73a186ca26db526.pdf)(Micah Hodosh 等人,IJCAI 2015)。
單擊下載鏈接時,將獲得兩個文件:
* `Flickr8k_Dataset.zip`:所有原始圖像和照片的 1 GB ZIP 存檔
* `Flickr8k_text.zip`:3 MB 的 ZIP 存檔,其中包含照片的所有自然語言文本說明,這些文本說明為標題
`Flickr_8k.devImages.txt`,`lickr_8k.trainImages.txt`和`Flickr_8k.testImages.txt`文件分別包含 6,000、1,000 和 1,000 個圖像的文件名。 我們將合并`dev`和`train`圖像,以構建包含 7,000 張圖像的訓練數據集,并使用包含 1,000 張圖像的測試數據集進行評估。 每個圖像都有五個不同但相似的標題,可在`Flickr8k.token.txt`文件中找到。
# 自動圖像字幕的方法
現在,我們將討論構建自動圖像字幕系統的方法。 正如我之前提到的,我們的方法將利用基于深度神經網絡的方法以及將學習遷移到圖像字幕的方法。 這得益于流行論文[《Show and Tell:神經圖像字幕生成器》](https://arxiv.org/abs/1411.4555)(Oriol Vinyals 等人,2015)。 我們將在概念上概述我們的方法,然后將其轉換為將用于構建自動圖像字幕系統的實用方法。 讓我們開始吧!
# 概念方法
成功的圖像字幕系統需要一種將給定圖像轉換為單詞序列的方法。 為了從圖像中提取正確和相關的特征,我們可以利用 DCNN,再結合循環神經網絡模型(例如 RNN 或 LSTM),我們可以在給定源圖像的情況下,構建混合生成模型以開始生成單詞序列作為標題。
因此,從概念上講,這個想法是建立一個混合模型,該模型可以將源圖像`I`作為輸入,并可以進行訓練以使可能性最大, `P(S|I)`,這樣`S`是單詞序列的輸出,這是我們的目標輸出,可以由`S = {S [1], S[2], ..., S[n]}`表示,這樣每個單詞`S[w]`都來自給定的詞典,這就是我們的詞匯。 該標題`S`應該能夠對輸入圖像給出恰當的描述。
神經機器翻譯是構建這樣一個系統的絕佳靈感。 通常在語言模型中用于語言翻譯,模型架構涉及使用 RNN 或 LSTM 構建的編碼器-解碼器架構。 通常,編碼器涉及一個 LSTM 模型,該模型從源語言中讀取輸入語句并將其轉換為密集的定長向量。 然后將其用作解碼器 LSTM 模型的初始隱藏狀態,最終以目標語言生成輸出語句。
對于圖像字幕,我們將利用類似的策略,其中處理輸入的編碼器將利用 DCNN 模型,因為我們的源數據是圖像。 到目前為止,我們已經看到了基于 CNN 的模型在從圖像中進行有效且豐富的特征提取的優勢。 因此,源圖像數據將轉換為密集數字固定長度向量。 通常,利用遷移學習方法的預訓練模型將是最有效的方法。 此向量將用作我們的解碼器 LSTM 模型的輸入,該模型將生成字幕說明(如單詞序列)。 從原始論文中汲取靈感,可以用數學方式表示要最大化的目標,如下所示:
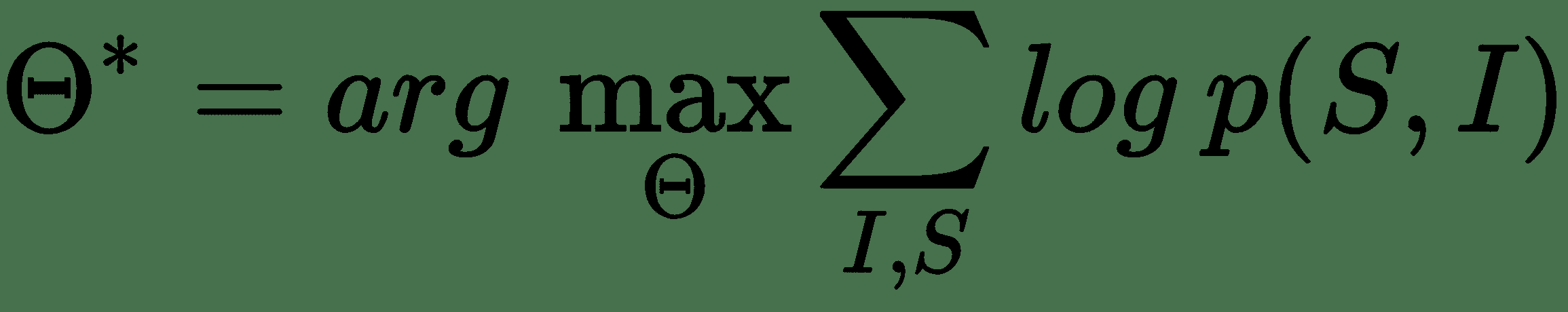
在此,`Θ`表示模型參數,`I`表示輸入圖像,`S`是其相應的由單詞序列組成的標題描述。 考慮到長度為`N`的字幕說明,表示總共`N`個字,我們可以對`{S[0], S[1], ...,S[N]}`使用鏈式規則,如下所示:
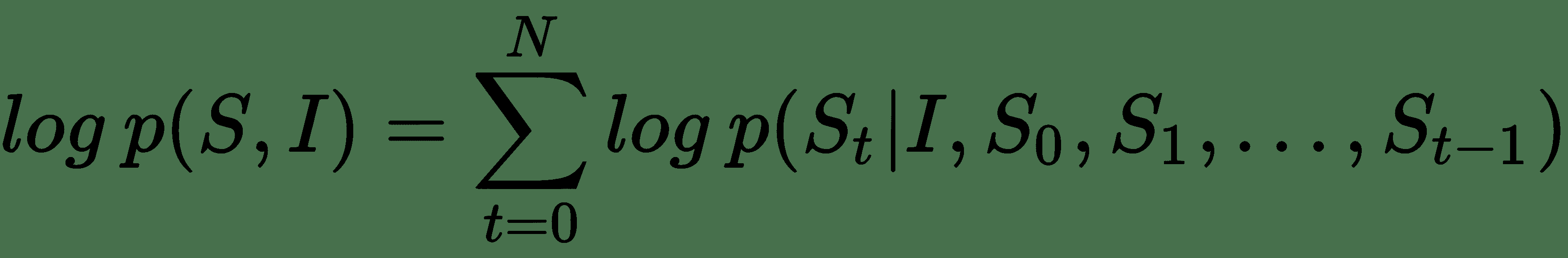
因此,在模型訓練期間,我們有一對`(I, S)`圖像標題作為輸入,其思想是針對上一個方程式優化對數概率的總和,使用有效算法(例如隨機梯度下降)來完整訓練數據。 考慮到前面公式的 RHS 中的項序列,基于 RNN 的模型是合適的選擇,這樣,直到`t-1`的可變單詞數依次由存儲狀態`h[t]`表示。 根據先前的`t-1`狀態和輸入對(圖像和下一個字)`x[t]`,使用以下命令在每個步驟中按以下步驟更新此內容: 非線性函數`f(...)`:
`h[t+1] = f(h[t], x[t])`
通常, `x[t]`代表我們的圖像特征和文本,它們是我們的輸入。 對于圖像特征,我們利用了前面提到的 DCNN。 對于函數`f`,我們選擇使用 LSTM,因為它們在處理消失和探索梯度等問題方面非常有效,這已在本書的初始章節中進行了討論。 考慮到 LSTM 存儲器塊的簡要介紹,讓我們參考《Show and Tell》研究論文中的下圖:
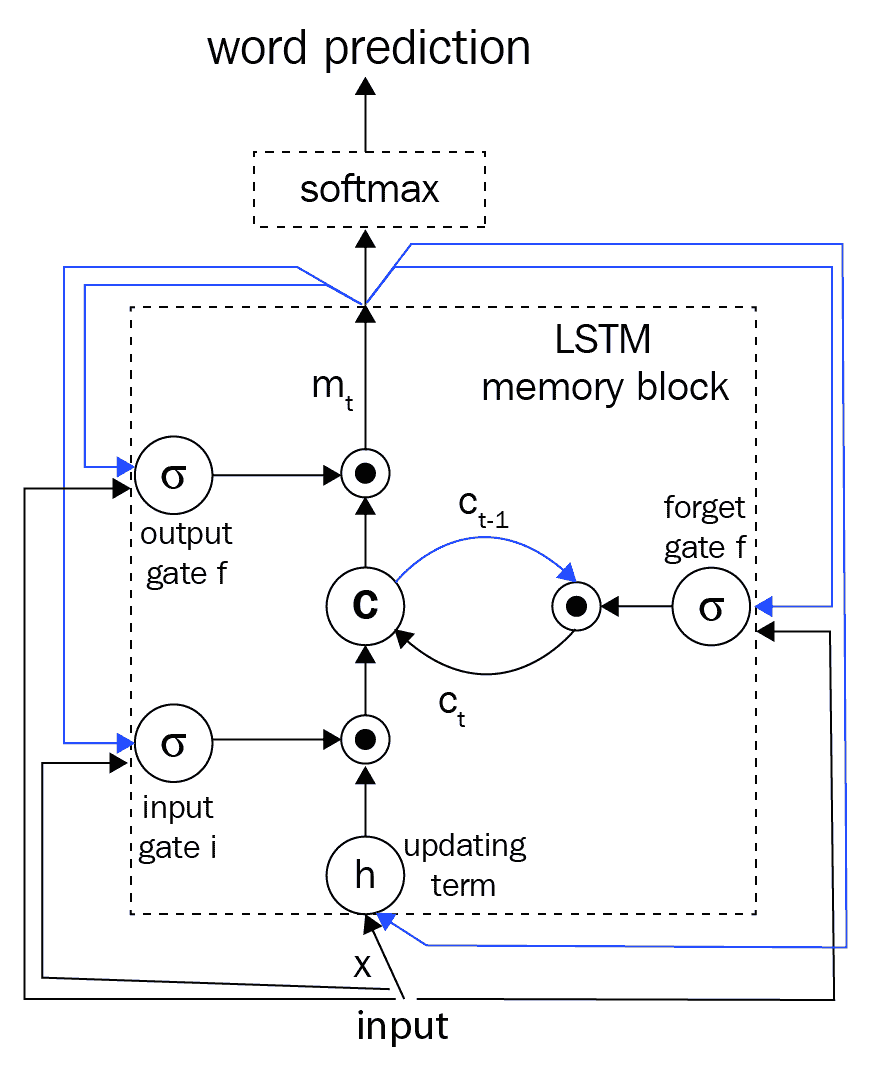
存儲塊包含 LSTM 單元`c`,該單元由輸入,輸出和忘記門控制。 單元`c`將根據輸入對每個時間步的知識進行編碼,直到先前的時間步為止。 如果門是 *1* 或 *0* ,則這三個門是可以相乘的層,以保持或拒絕來自門控層的值。 循環連接在上圖中以藍色顯示。 我們通常在模型中有多個 LSTM,并且在時間`t-1`的輸出`m[t-1]`在時間被饋送到下一個 LSTM。因此,使用以下三個時間,將在時間`t-1`處的輸出`m[t-1]`反饋到存儲塊。 我們前面討論過的門。 實際的單元格值也使用“忘記門”反饋。 通常將時間`t`處的存儲器輸出`m[t]`輸出到 softmax 以預測下一個單詞。
這通常是從輸出門`o[t]`和當前單元狀態`c[t]`獲得的。 下圖中描述了其中的一些定義和操作以及必要的方程式:
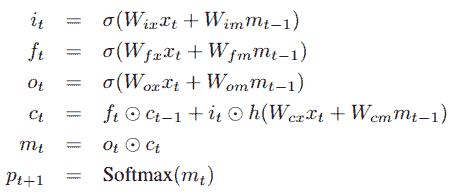
在這里,`⊙`是乘積運算符,尤其用于當前的門狀態和值。 `W`矩陣是網絡中的可訓練參數。 這些門有助于解決諸如爆炸和消失梯度的問題。 網絡中的非線性是由我們的常規 S 型`σ`和雙曲正切`h`函數引入的。 如前所述,內存輸出`m[t]`被饋送到 softmax 以預測下一個單詞,其中輸出是所有單詞上的概率分布。
因此,基于此知識,您可以考慮基于 LSTM 的序列模型需要與必要的詞嵌入層和基于 CNN 的模型結合,以從源圖像生成密集特征。 因此,LSTM 模型的目標是根據預測的所有先前單詞以及輸入圖像(由我們先前的`p(S[t] | I, S[0], S[1], ..., S[t-1])`。 為了簡化 LSTM 中的循環連接,我們可以以展開形式來表示它,其中我們代表一系列 LSTM,它們共享下圖所示的相同參數:
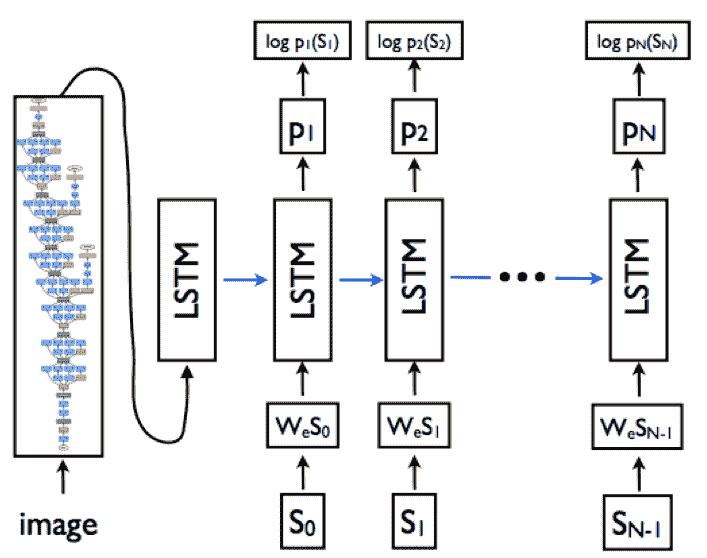
從上圖可以明顯看出,基于展開的 LSTM 架構,循環連接由藍色水平箭頭表示,并已轉換為前饋連接。 同樣,很明顯,在時間`t-1`處 LSTM 的輸出`m[t-1]`在時間`t`被饋送到下一個 LSTM。 將源輸入圖像視為`I`,將字幕視為`S = {S[0], S[1], ..., S[N]}`,下圖描述了先前描述的展開架構中涉及的主要操作:
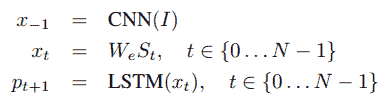
在這里,標題中的每個文本單詞都由單熱門向量`S[t]`表示,因此其尺寸等于我們詞匯量(唯一的單詞)。 另外要注意的一點是,我們為`S[0]`設置了特殊的標記或分隔符,分別由`<START>`和`S[N]`表示,我們用`<END>`來表示字幕的開頭和結尾。 這有助于 LSTM 理解何時完全生成了字幕。
輸入圖像`I`輸入到我們的 DCNN 模型中,該模型生成密集特征向量,并將基于嵌入層的單詞轉換為密集單詞嵌入`W[eps]`。 因此,要最小化的整體損失函數是每個步驟右詞的對數似然比,如以下等式所示:
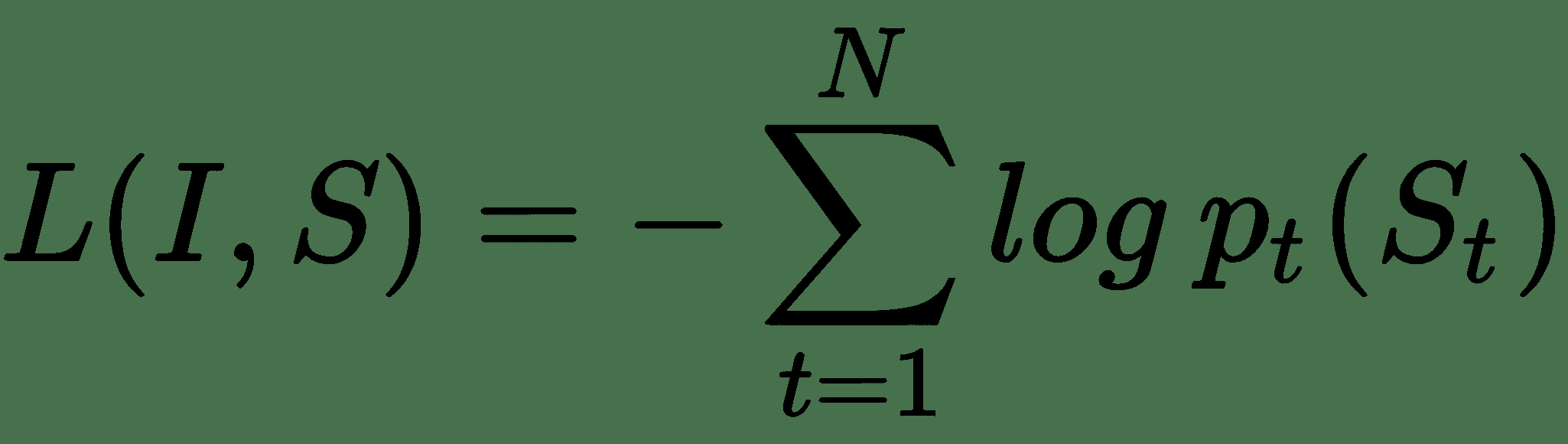
因此,在模型訓練期間,考慮模型中的所有參數(包括 DCNN,LSTM 和嵌入),可以將這種損失最小化。 現在讓我們看一下如何將其付諸實踐。
# 實用的實踐方法
現在我們知道了可用于構建成功的圖像字幕生成器的基本概念和理論,下面讓我們看一下需要動手實踐來解決此問題的主要構建塊。 基于圖像字幕的主要操作,要構建模型,我們將需要以下主要組件:
* 圖像特征提取器 — 帶遷移學習的 DCNN 模型
* 文本字幕生成器 - 使用 LSTM 的基于序列的語言模型
* 編解碼器模型
在為字幕生成系統實現它們之前,讓我們簡要介紹一下這三個組件。
# 圖像特征提取器 – 使用遷移學習的 DCNN 模型
我們系統的主要輸入之一是源圖像或照片。 我們都知道,**機器學習**(**ML**)或深度學習模型不能僅使用原始圖像。 我們需要進行一些處理,還需要從圖像中提取相關特征,然后將這些特征用于識別和分類等任務。
圖像特征提取器本質上應該接收輸入圖像,從中提取豐富的層次特征表示,并以固定長度的密集向量的形式表示輸出。 我們已經看到了 DCNN 在處理計算機視覺任務方面的強大功能。 在這里,我們將通過使用預訓練的 VGG-16 模型作為特征提取器來從所有圖像中提取瓶頸特征,從而充分利用遷移學習的力量。 就像快速刷新一樣,下圖顯示了 VGG-16 模型:

為了進行特征提取,我們將刪除模型的頂部,即 softmax 層,并使用其余的層從輸入圖像中獲取密集的特征向量。 這通常是編碼過程的一部分,輸出被饋送到產生字幕的解碼器中。
# 文本字幕生成器 – 使用 LSTM 的基于序列的語言模型
如果傳統的基于序列的語言模型知道序列中已經存在的先前單詞,則它將預測下一個可能的單詞。 對于我們的圖像字幕問題,如上一節所述,基于 DCNN 模型的特征和字幕序列中已經生成的單詞,LSTM 模型應該能夠在每個時間步長預測我們字幕中的下一個可能單詞 。
嵌入層用于為字幕數據字典或詞匯表中的每個唯一單詞生成單詞嵌入,通常將其作為 LSTM 模型(解碼器的一部分)的輸入,來根據圖像特征和先前的詞序在我們的字幕中生成下一個可能的單詞。 想法是最終生成一系列單詞,這些單詞一起在描述輸入圖像時最有意義。
# 編解碼器架構
這是將前面兩個組件聯系在一起的模型架構。 它最初是在神經機器翻譯方面取得的巨大成功,通常您將一種語言的單詞輸入編碼器,而解碼器則輸出另一種語言的單詞。 好處是,使用單個端到端架構,您可以連接這兩個組件并解決問題,而不必嘗試構建單獨的和斷開的模型來解決一個問題。
DCNN 模型通常形成編碼器,該編碼器將源輸入圖像編碼為固定長度的密集向量,然后由基于 LSTM 的序列模型將其解碼為單詞序列,從而為我們提供了所需的標題。 同樣,如前所述,必須訓練該模型以使給定輸入圖像的字幕文本的可能性最大化。 為了進行改進,您可以考慮將詳細信息添加到此模型中,作為將來范圍的一部分。
現在,讓我們使用這種方法來實現我們的自動圖像標題生成器。
# 使用遷移學習的圖像特征提取
我們模型的第一步是利用預訓練的 DCNN 模型,使用遷移學習的原理從源圖像中提取正確的特征。 為簡單起見,我們不會對 VGG-16 模型進行微調或將其連接到模型的其余部分。 我們將事先從所有圖像中提取瓶頸特征,以加快以后的訓練速度,因為使用多個 LSTM 構建序列模型即使在 GPU 上也需要大量的訓練時間,我們很快就會看到。
首先,我們將從源數據集中的`Flickr8k_text`文件夾中加載所有源圖像文件名及其相應的標題。 同樣,我們將把`dev`和`train`數據集圖像組合在一起,正如我們之前提到的:
```py
import pandas as pd
import numpy as np
# read train image file names
with open('../Flickr8k_text/Flickr_8k.trainImages.txt','r') as tr_imgs:
train_imgs = tr_imgs.read().splitlines()
# read dev image file names
with open('../Flickr8k_text/Flickr_8k.devImages.txt','r') as dv_imgs:
dev_imgs = dv_imgs.read().splitlines()
# read test image file names
with open('../Flickr8k_text/Flickr_8k.testImages.txt','r') as ts_imgs:
test_imgs = ts_imgs.read().splitlines()
# read image captions
with open('../Flickr8k_text/Flickr8k.token.txt','r') as img_tkns:
captions = img_tkns.read().splitlines()
# combine dev and train image names into one set
train_imgs = train_imgs + dev_imgs
```
現在我們已經整理好輸入圖像的文件名并加載了相應的標題,我們需要構建一個基于字典的映射,該映射將源圖像及其對應的標題映射在一起。 正如我們前面提到的,一個圖像由五個不同的人字幕,因此,我們將為每個圖像列出五個字幕。 下面的代碼可以幫助我們做到這一點:
```py
from collections import defaultdict
caption_map = defaultdict(list)
# store five captions in a list for each image
for record in captions:
record = record.split('\t')
img_name = record[0][:-2]
img_caption = record[1].strip()
caption_map[img_name].append(img_caption)
```
我們稍后將在構建數據集進行訓練和測試時利用它。 現在讓我們集中討論特征提取。 在提取圖像特征之前,我們需要將原始輸入圖像預處理為正確的大小,并根據將要使用的模型縮放像素值。 以下代碼將幫助我們進行必要的圖像預處理步驟:
```py
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input as preprocess_vgg16_input
def process_image2arr(path, img_dims=(224, 224)):
img = image.load_img(path, target_size=img_dims)
img_arr = image.img_to_array(img)
img_arr = np.expand_dims(img_arr, axis=0)
img_arr = preprocess_vgg16_input(img_arr)
return img_arr
```
我們還需要加載預訓練的 VGG-16 模型以利用遷移學習。 這是通過以下代碼片段實現的:
```py
from keras.applications import vgg16
from keras.models import Model
vgg_model = vgg16.VGG16(include_top=True, weights='imagenet',
input_shape=(224, 224, 3))
vgg_model.layers.pop()
output = vgg_model.layers[-1].output
vgg_model = Model(vgg_model.input, output)
vgg_model.trainable = False
vgg_model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 224, 224, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
...
...
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 25088) 0
_________________________________________________________________
fc1 (Dense) (None, 4096) 102764544
_________________________________________________________________
fc2 (Dense) (None, 4096) 16781312
=================================================================
Total params: 134,260,544
Trainable params: 0
Non-trainable params: 134,260,544
_________________________________________________________________
```
很明顯,我們刪除了 softmax 層,并使模型不可訓練,因為我們只對從輸入圖像中提取密集的特征向量感興趣。 現在,我們將構建一個利用我們的工具函數并幫助從輸入圖像中提取正確特征的函數:
```py
def extract_tl_features_vgg(model, image_file_name,
image_dir='../Flickr8k_imgs/'):
pr_img = process_image2arr(image_dir+image_file_name)
tl_features = model.predict(pr_img)
tl_features = np.reshape(tl_features, tl_features.shape[1])
return tl_features
```
現在,我們通過提取圖像特征并構建訓練和測試數據集來對所有先前的函數和預先訓練的模型進行測試:
```py
img_tl_featureset = dict()
train_img_names = []
train_img_captions = []
test_img_names = []
test_img_captions = []
for img in train_imgs:
img_tl_featureset[img] = extract_tl_features_vgg(model=vgg_model,
image_file_name=img)
for caption in caption_map[img]:
train_img_names.append(img)
train_img_captions.append(caption)
for img in test_imgs:
img_tl_featureset[img] = extract_tl_features_vgg(model=vgg_model,
image_file_name=img)
for caption in caption_map[img]:
test_img_names.append(img)
test_img_captions.append(caption)
train_dataset = pd.DataFrame({'image': train_img_names, 'caption':
train_img_captions})
test_dataset = pd.DataFrame({'image': test_img_names, 'caption':
test_img_captions})
print('Train Dataset Size:', len(train_dataset), '\tTest Dataset Size:', len(test_dataset))
Train Dataset Size: 35000 Test Dataset Size: 5000
```
我們還可以通過使用以下代碼來查看訓練數據集的外觀:
```py
train_dataset.head(10)
```
前面代碼的輸出如下:
顯然,每個輸入圖像都有五個標題,并且將其保留在數據集中。 現在,我們將這些數據集的記錄和從遷移學習中學到的圖像特征保存到磁盤上,以便我們可以在模型訓練期間輕松地將其加載到內存中,而不必每次運行模型時都提取這些特征:
```py
# save dataset records
train_dataset = train_dataset[['image', 'caption']]
test_dataset = test_dataset[['image', 'caption']]
train_dataset.to_csv('image_train_dataset.tsv', sep='\t', index=False)
test_dataset.to_csv('image_test_dataset.tsv', sep='\t', index=False)
# save transfer learning image features
from sklearn.externals import joblib
joblib.dump(img_tl_featureset, 'transfer_learn_img_features.pkl')
['transfer_learn_img_features.pkl']
```
另外,如果需要,您可以使用以下代碼段進行一些初始檢查來驗證圖像特征的外觀:
```py
[(key, value.shape) for key, value in
img_tl_featureset.items()][:5]
[('3079787482_0757e9d167.jpg', (4096,)),
('3284955091_59317073f0.jpg', (4096,)),
('1795151944_d69b82f942.jpg', (4096,)),
('3532192208_64b069d05d.jpg', (4096,)),
('454709143_9c513f095c.jpg', (4096,))]
[(k, np.round(v, 3)) for k, v in img_tl_featureset.items()][:5]
[('3079787482_0757e9d167.jpg',
array([0., 0., 0., ..., 0., 0., 0.], dtype=float32)),
('3284955091_59317073f0.jpg',
array([0.615, 0\. , 0.653, ..., 0\. , 1.559, 2.614], dtype=float32)),
('1795151944_d69b82f942.jpg',
array([0\. , 0\. , 0\. , ..., 0\. , 0\. , 0.538], dtype=float32)),
('3532192208_64b069d05d.jpg',
array([0\. , 0\. , 0\. , ..., 0\. , 0\. , 2.293], dtype=float32)),
('454709143_9c513f095c.jpg',
array([0\. , 0\. , 0.131, ..., 0.833, 4.263, 0\. ], dtype=float32))]
```
我們將在建模的下一部分中使用這些特征。
# 為我們的字幕建立詞匯表
下一步涉及對字幕數據進行一些預處理,并為字幕構建詞匯表或元數據字典。 我們首先讀取訓練數據集記錄并編寫一個函數來預處理文本標題:
```py
train_df = pd.read_csv('image_train_dataset.tsv', delimiter='\t')
total_samples = train_df.shape[0]
total_samples
35000
# function to pre-process text captions
def preprocess_captions(caption_list):
pc = []
for caption in caption_list:
caption = caption.strip().lower()
caption = caption.replace('.', '').replace(',',
'').replace("'", "").replace('"', '')
caption = caption.replace('&','and').replace('(','').replace(')',
'').replace('-', ' ')
caption = ' '.join(caption.split())
caption = '<START> '+caption+' <END>'
pc.append(caption)
return pc
```
現在,我們將對字幕進行預處理,并為詞匯建立一些基本的元數據,包括用于將唯一的單詞轉換為數字表示的工具,反之亦然:
```py
# pre-process caption data
train_captions = train_df.caption.tolist()
processed_train_captions = preprocess_captions(train_captions)
tc_tokens = [caption.split() for caption in
processed_train_captions]
tc_tokens_length = [len(tokenized_caption) for tokenized_caption
in tc_tokens]
# build vocabulary metadata
from collections import Counter
tc_words = [word.strip() for word_list in tc_tokens for word in
word_list]
unique_words = list(set(tc_words))
token_counter = Counter(unique_words)
word_to_index = {item[0]: index+1 for index, item in
enumerate(dict(token_counter).items())}
word_to_index['<PAD>'] = 0
index_to_word = {index: word for word, index in
word_to_index.items()}
vocab_size = len(word_to_index)
max_caption_size = np.max(tc_tokens_length)
```
重要的是要確保將詞匯表元數據保存到磁盤上,以便將來在任何時候都可以將其重新用于模型訓練和預測。 否則,如果我們重新生成詞匯表,則很有可能已使用其他版本的詞匯表來訓練模型,其中單詞到數字的映射可能有所不同。 這將給我們帶來錯誤的結果,并且我們將浪費寶貴的時間:
```py
from sklearn.externals import joblib
vocab_metadata = dict()
vocab_metadata['word2index'] = word_to_index
vocab_metadata['index2word'] = index_to_word
vocab_metadata['max_caption_size'] = max_caption_size
vocab_metadata['vocab_size'] = vocab_size
joblib.dump(vocab_metadata, 'vocabulary_metadata.pkl')
['vocabulary_metadata.pkl']
```
如果需要,您可以使用以下代碼片段檢查詞匯元數據的內容,還可以查看常規預處理的文本標題對于其中一張圖像的外觀:
```py
# check vocabulary metadata
{k: v if type(v) is not dict
else list(v.items())[:5]
for k, v in vocab_metadata.items()}
{'index2word': [(0, '<PAD>'), (1, 'nearby'), (2, 'flooded'),
(3, 'fundraising'), (4, 'snowboarder')],
'max_caption_size': 39,
'vocab_size': 7927,
'word2index': [('reflections', 4122), ('flakes', 1829),
('flexing', 7684), ('scaling', 1057), ('pretend', 6788)]}
# check pre-processed caption
processed_train_captions[0]
'<START> a black dog is running after a white dog in the snow <END>'
```
在構建數據生成器函數時,我們將在不久的將來利用它,它將用作模型訓練期間深度學習模型的輸入。
# 構建圖像標題數據集生成器
在消耗大量數據的任何復雜深度學習系統中,最重要的步驟之一就是構建高效的數據集生成器。 這在我們的系統中非常重要,尤其是因為我們將處理圖像和文本數據。 除此之外,我們將處理序列模型,在訓練過程中,我們必須多次將相同數據傳遞給我們的模型。 將列表中的所有數據解壓縮后,預先構建數據集將是解決此問題的最無效的方法。 因此,我們將為我們的系統利用生成器的力量。
首先,我們將使用以下代碼加載從遷移學習中學到的圖像特征以及詞匯元數據:
```py
from sklearn.externals import joblib
tl_img_feature_map = joblib.load('transfer_learn_img_features.pkl')
vocab_metadata = joblib.load('vocabulary_metadata.pkl')
train_img_names = train_df.image.tolist()
train_img_features = [tl_img_feature_map[img_name] for img_name in train_img_names]
train_img_features = np.array(train_img_features)
word_to_index = vocab_metadata['word2index']
index_to_word = vocab_metadata['index2word']
max_caption_size = vocab_metadata['max_caption_size']
vocab_size = vocab_metadata['vocab_size']
train_img_features.shape
(35000, 4096)
```
我們可以看到有 35,000 張圖像,其中每張圖像都有大小為 4,096 的密集特征向量表示。 現在的想法是構建一個模型數據集生成器,該生成器將生成(輸入,輸出)對。 對于我們的輸入,我們將使用轉換為密集特征向量的源圖像以及相應的圖像標題,在每個時間步添加一個單詞。 對應的輸出將是對應輸入圖像和標題的相同標題的下一個單詞(必須預測)。 下圖使此方法更加清晰:
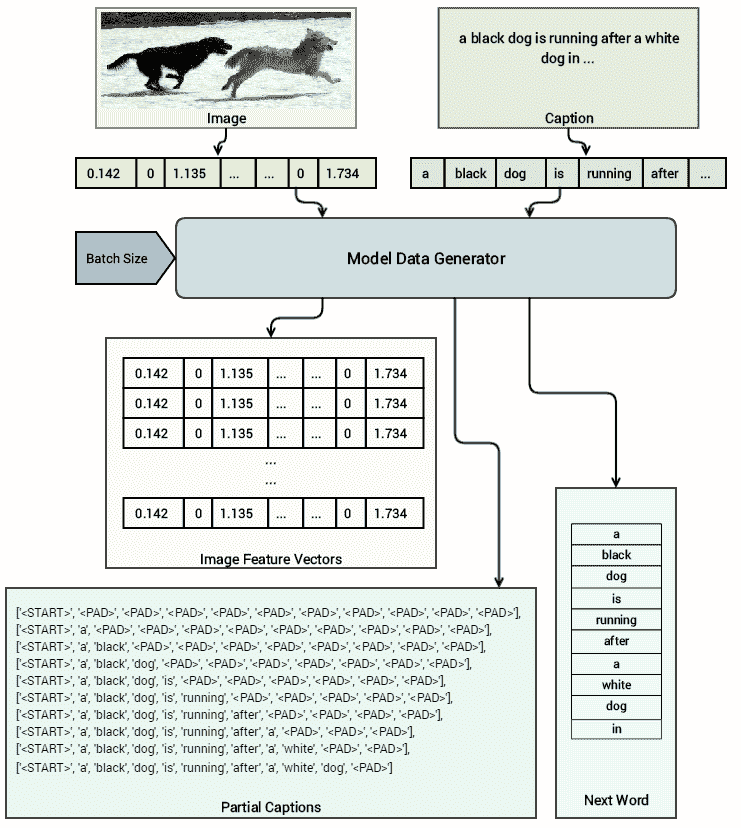
基于此架構,很明顯,對于同一圖像,在每個時間步上,我們都傳遞相同的特征向量,并保持每次添加一個單詞的標題,同時傳遞下一個要預測的單詞作為相應的輸出來訓練我們的模型。 以下函數將幫助我們實現這一點,我們利用 Python 生成器進行延遲加載并提高內存效率:
```py
from keras.preprocessing import sequence
def dataset_generator(processed_captions, transfer_learnt_features, vocab_size, max_caption_size, batch_size=32):
partial_caption_set = []
next_word_seq_set = []
img_feature_set = []
batch_count = 0
batch_num = 0
while True:
for index, caption in enumerate(processed_captions):
img_features = transfer_learnt_features[index]
for cap_idx in range(len(caption.split()) - 1):
partial_caption = [word_to_index[word] for word in
caption.split()[:cap_idx+1]]
partial_caption_set.append(partial_caption)
next_word_seq = np.zeros(vocab_size)
next_word_seq[word_to_index
[caption.split()[cap_idx+1]]] = 1
next_word_seq_set.append(next_word_seq)
img_feature_set.append(img_features)
batch_count+=1
if batch_count >= batch_size:
batch_num += 1
img_feature_set = np.array(img_feature_set)
partial_caption_set =
sequence.pad_sequences(
sequences=partial_caption_set,
maxlen=max_caption_size,
padding='post')
next_word_seq_set =
np.array(next_word_seq_set)
yield [[img_feature_set, partial_caption_set],
next_word_seq_set]
batch_count = 0
partial_caption_set = []
next_word_seq_set = []
img_feature_set = []
```
讓我們嘗試了解此函數的真正作用! 盡管我們確實在上圖中描繪了一個不錯的視覺效果,但現在我們將使用以下代碼為`10`的批量大小生成示例數據:
```py
MAX_CAPTION_SIZE = max_caption_size
VOCABULARY_SIZE = vocab_size
BATCH_SIZE = 10
print('Vocab size:', VOCABULARY_SIZE)
print('Max caption size:', MAX_CAPTION_SIZE)
print('Test Batch size:', BATCH_SIZE)
d = dataset_generator(processed_captions=processed_train_captions,
transfer_learnt_features=train_img_features,
vocab_size=VOCABULARY_SIZE,
max_caption_size=MAX_CAPTION_SIZE,
batch_size=BATCH_SIZE)
d = list(d)
img_features, partial_captions = d[0][0]
next_word = d[0][1]
Vocab size: 7927
Max caption size: 39
Test Batch size: 10
```
現在,我們可以使用以下代碼從數據生成器函數驗證返回的數據集的維數:
```py
img_features.shape, partial_captions.shape, next_word.shape
((10, 4096), (10, 39), (10, 7927))
```
很明顯,我們的圖像特征本質上是每個向量中 4,096 個特征的密集向量。 在字幕的每個時間步都對同一圖像重復相同的特征向量。 字幕生成的向量的大小為`MAX_CAPTION_SIZE`,即`39`。 下一個單詞通常以單次編碼的方式返回,這對于用作 softmax 層的輸入非常有用,以檢查模型是否預測了正確的單詞。 以下代碼向我們展示了圖像特征向量如何查找輸入圖像的`10`批量大小:
```py
np.round(img_features, 3)
array([[0\. , 0\. , 1.704, ..., 0\. , 0\. , 0\. ],
[0\. , 0\. , 1.704, ..., 0\. , 0\. , 0\. ],
[0\. , 0\. , 1.704, ..., 0\. , 0\. , 0\. ],
...,
[0\. , 0\. , 1.704, ..., 0\. , 0\. , 0\. ],
[0\. , 0\. , 1.704, ..., 0\. , 0\. , 0\. ],
[0\. , 0\. , 1.704, ..., 0\. , 0\. , 0\. ]], dtype=float32)
```
如前所述,在批量數據生成過程中的每個時間步都重復了相同的圖像特征向量。 我們可以檢查在輸入給模型的每個時間步驟中標題的形成方式。 為了簡單起見,我們僅顯示前 11 個單詞:
```py
# display raw caption tokens at each time-step
print(np.array([partial_caption[:11] for partial_caption in
partial_captions]))
[[6917 0 0 0 0 0 0 0 0 0 0]
[6917 2578 0 0 0 0 0 0 0 0 0]
[6917 2578 7371 0 0 0 0 0 0 0 0]
[6917 2578 7371 3519 0 0 0 0 0 0 0]
[6917 2578 7371 3519 3113 0 0 0 0 0 0]
[6917 2578 7371 3519 3113 6720 0 0 0 0 0]
[6917 2578 7371 3519 3113 6720 7 0 0 0 0]
[6917 2578 7371 3519 3113 6720 7 2578 0 0 0]
[6917 2578 7371 3519 3113 6720 7 2578 1076 0 0]
[6917 2578 7371 3519 3113 6720 7 2578 1076 3519 0]]
# display actual caption tokens at each time-step
print(np.array([[index_to_word[word] for word in cap][:11] for cap
in partial_captions]))
[['<START>' '<PAD>' '<PAD>' '<PAD>' '<PAD>' '<PAD>' '<PAD>' '<PAD>' '<PAD>' '<PAD>' '<PAD>']
['<START>' 'a' '<PAD>' '<PAD>' '<PAD>' '<PAD>' '<PAD>' '<PAD>' '<PAD>' '<PAD>' '<PAD>']
['<START>' 'a' 'black' '<PAD>' '<PAD>' '<PAD>' '<PAD>' '<PAD>' '<PAD>' '<PAD>' '<PAD>']
['<START>' 'a' 'black' 'dog' '<PAD>' '<PAD>' '<PAD>' '<PAD>' '<PAD>' '<PAD>' '<PAD>']
['<START>' 'a' 'black' 'dog' 'is' '<PAD>' '<PAD>' '<PAD>' '<PAD>'
'<PAD>' '<PAD>']
['<START>' 'a' 'black' 'dog' 'is' 'running' '<PAD>' '<PAD>' '<PAD>' '<PAD>' '<PAD>']
['<START>' 'a' 'black' 'dog' 'is' 'running' 'after' '<PAD>' '<PAD>' '<PAD>' '<PAD>']
['<START>' 'a' 'black' 'dog' 'is' 'running' 'after' 'a' '<PAD>' '<PAD>' '<PAD>']
['<START>' 'a' 'black' 'dog' 'is' 'running' 'after' 'a' 'white' '<PAD>' '<PAD>']
['<START>' 'a' 'black' 'dog' 'is' 'running' 'after' 'a' 'white' 'dog' '<PAD>']]
```
我們可以清楚地看到在`<START>`符號后的每個步驟中如何將一個單詞添加到輸入標題,這表示文本標題的開始。 現在讓我們看一下對應的下一單詞生成輸出(通常是根據兩個輸入預測的下一單詞):
```py
next_word
array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
print('Next word positions:', np.nonzero(next_word)[1])
print('Next words:', [index_to_word[word] for word in
np.nonzero(next_word)[1]])
Next word positions: [2578 7371 3519 3113 6720 7 2578 1076 3519 5070]
Next words: ['a', 'black', 'dog', 'is', 'running', 'after', 'a', 'white', 'dog', 'in']
```
很清楚,下一個單詞通常基于輸入字幕中每個時間步的單詞順序指向字幕中的下一個正確單詞。 這些數據將在訓練期間的每個周期饋入我們的模型。
# 建立我們的圖像字幕編解碼器深度學習模型
現在,我們擁有構建模型所需的所有基本組件和工具。 如前所述,我們將使用編碼器-解碼器深度學習模型架構來構建圖像捕獲系統。
以下代碼幫助我們構建此模型的架構,在該模型中,我們將成對的圖像特征和字幕序列作為輸入,以預測每個時間步長的字幕中的下一個可能單詞:
```py
from keras.models import Sequential, Model
from keras.layers import LSTM, Embedding, TimeDistributed, Dense, RepeatVector, Activation, Flatten, concatenate
DENSE_DIM = 256
EMBEDDING_DIM = 256
MAX_CAPTION_SIZE = max_caption_size
VOCABULARY_SIZE = vocab_size
image_model = Sequential()
image_model.add(Dense(DENSE_DIM, input_dim=4096, activation='relu'))
image_model.add(RepeatVector(MAX_CAPTION_SIZE))
language_model = Sequential()
language_model.add(Embedding(VOCABULARY_SIZE, EMBEDDING_DIM, input_length=MAX_CAPTION_SIZE))
language_model.add(LSTM(256, return_sequences=True))
language_model.add(TimeDistributed(Dense(DENSE_DIM)))
merged_output = concatenate([image_model.output, language_model.output])
merged_output = LSTM(1024, return_sequences=False)(merged_output)
merged_output = (Dense(VOCABULARY_SIZE))(merged_output)
merged_output = Activation('softmax')(merged_output)
model = Model([image_model.input, language_model.input], merged_output)
model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
model.summary()
```
前面的代碼的輸出如下:
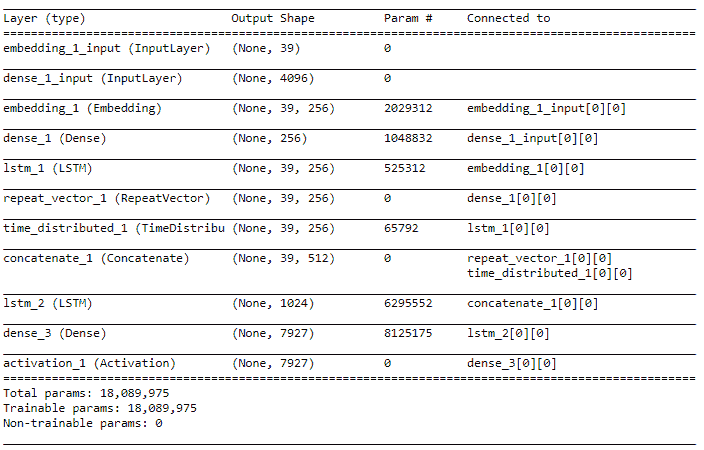
從前面的架構中我們可以看到,我們有一個圖像模型,該模型更著重于處理基于圖像的特征作為其輸入,而語言模型則利用 LSTM 來處理每個圖像標題中流入的單詞序列。 最后一層是 softmax 層,具有 7,927 個單元,因為我們的詞匯表中總共有 7,927 個唯一詞,并且字幕中的下一個預測詞將是其中一個作為輸出生成的詞。 我們還可以使用以下代碼片段來可視化我們的模型架構:
```py
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
SVG(model_to_dot(model, show_shapes=True, show_layer_names=False,
rankdir='TB').create(prog='dot', format='svg'))
```
前面的代碼的輸出如下:
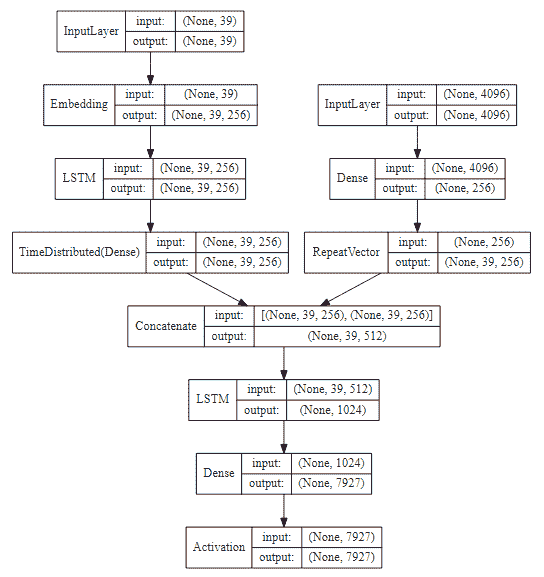
# 訓練我們的圖像字幕深度學習模型
在開始訓練模型之前,由于我們正在處理模型中的一些復雜組件,因此在模型的準確率在整個連續周期中都達到穩定狀態的情況下,我們會在模型中使用回調來降低學習率。 這對于在不停止訓練的情況下即時更改模型的學習率非常有幫助:
```py
from keras.callbacks import ReduceLROnPlateau
reduce_lr = ReduceLROnPlateau(monitor='loss', factor=0.15,
patience=2, min_lr=0.000005)
```
讓我們現在訓練我們的模型! 我們已經將模型訓練到大約 30 到 50 個周期,并在大約 30 個周期和 50 個周期保存了模型:
```py
BATCH_SIZE = 256
EPOCHS = 30
cap_lens = [(cl-1) for cl in tc_tokens_length]
total_size = sum(cap_lens)
history = model.fit_generator(
dataset_generator(processed_captions=processed_train_captions,
transfer_learnt_features=train_img_features,
vocab_size=VOCABULARY_SIZE,
max_caption_size=MAX_CAPTION_SIZE,
batch_size=BATCH_SIZE),
steps_per_epoch=int(total_size/BATCH_SIZE),
callbacks=[reduce_lr],
epochs=EPOCHS, verbose=1)
Epoch 1/30
1617/1617 - 724s 448ms/step - loss: 4.1236 - acc: 0.2823
Epoch 2/30
1617/1617 - 725s 448ms/step - loss: 3.9182 - acc: 0.3150
Epoch 3/30
1617/1617 - 724s 448ms/step - loss: 3.8286 - acc: 0.3281
...
...
Epoch 29/30
1617/1617 - 724s 447ms/step - loss: 3.6443 - acc: 0.3885
Epoch 30/30
1617/1617 - 724s 448ms/step - loss: 3.4656 - acc: 0.4078
model.save('ic_model_rmsprop_b256ep30.h5')
```
保存該模型后,我們將繼續訓練并對其進行另外 20 個周期的訓練,并在`50`處停止。 當然,您也可以隨意在 Keras 中使用模型檢查點定期自動保存它:
```py
EPOCHS = 50
history_rest = model.fit_generator(
dataset_generator(processed_captions=processed_train_captions,
transfer_learnt_features=train_img_features,
vocab_size=VOCABULARY_SIZE,
max_caption_size=MAX_CAPTION_SIZE,
batch_size=BATCH_SIZE),
steps_per_epoch=int(total_size/BATCH_SIZE),
callbacks=[reduce_lr],
epochs=EPOCHS, verbose=1, initial_epoch=30)
Epoch 31/50
1617/1617 - 724s 447ms/step - loss: 3.3988 - acc: 0.4144
Epoch 32/50
1617/1617 - 724s 448ms/step - loss: 3.3633 - acc: 0.4184
...
...
Epoch 49/50
1617/1617 - 724s 448ms/step - loss: 3.1330 - acc: 0.4509
Epoch 50/50
1617/1617 - 724s 448ms/step - loss: 3.1260 - acc: 0.4523
model.save('ic_model_rmsprop_b256ep50.h5')
```
這樣就結束了我們的模型訓練過程; 我們已經成功地訓練了圖像字幕模型,并可以開始使用它來為新圖像生成圖像字幕。
模型訓練技巧:圖像字幕模型通常使用大量數據,并且在訓練過程中涉及許多參數。 建議使用生成器來構建和生成數據以訓練深度學習模型。 否則,您可能會遇到內存問題。 另外,在帶有 Tesla K80 GPU 的 Amazon AWS p2.x 實例上,該模型在每個周期運行將近 12 分鐘,因此請考慮在 GPU 上構建該模型,因為在傳統系統上進行訓練可能會花費很長時間。
我們還可以根據訓練過程中的不同周期,查看有關模型準確率,損失和學習率的趨勢:
```py
epochs = list(range(1,51))
losses = history.history['loss'] + history_rest.history['loss']
accs = history.history['acc'] + history_rest.history['acc']
lrs = history.history['lr'] + history_rest.history['lr']
f, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(14, 4))
title = f.suptitle("Model Training History", fontsize=14)
f.subplots_adjust(top=0.85, wspace=0.35)
ax1.plot(epochs, losses, label='Loss')
ax2.plot(epochs, accs, label='Accuracy')
ax3.plot(epochs, lrs, label='Learning Rate')
ax1.set_xlabel('Epochs')
ax2.set_xlabel('Epochs')
ax3.set_xlabel('Epochs')
ax1.set_ylabel('Loss')
ax2.set_ylabel('Accuracy')
ax3.set_ylabel('Learning Rate')
```
前面的代碼的輸出如下:
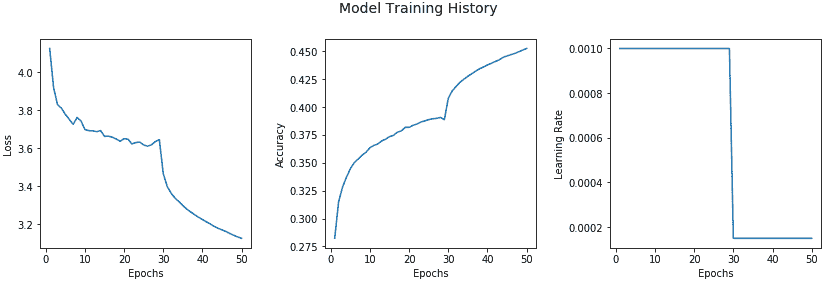
我們可以看到,在第 28 和 29 階段,準確率略有下降,損失增加了,這導致我們的回調成功降低了學習率,從第 30 階段開始提高了準確率。 這無疑為我們提供了有關模型行為的有用見解!
# 評估我們的圖像字幕深度學習模型
訓練模型而不評估其表現根本沒有任何意義。 因此,我們現在將在測試數據集上評估深度學習模型的表現,該數據集與`Flickr8K`數據集共有 1000 幅不同的圖像。 我們從加載通常的依賴關系開始(如果您還沒有的話):
```py
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
pd.options.display.max_colwidth = 500
%matplotlib inline
```
# 加載數據和模型
下一步包括將必要的數據,模型和其他資產從磁盤加載到內存中。 我們首先加載測試數據集和訓練有素的深度學習模型:
```py
# load test dataset
test_df = pd.read_csv('image_test_dataset.tsv', delimiter='\t')
# load the models
from keras.models import load_model
model1 = load_model('ic_model_rmsprop_b256ep30.h5')
model2 = load_model('ic_model_rmsprop_b256ep50.h5')
```
現在,我們需要加載必要的元數據資產,例如之前為測試數據提取的圖像特征以及詞匯元數據:
```py
from sklearn.externals import joblib
tl_img_feature_map = joblib.load('transfer_learn_img_features.pkl')
vocab_metadata = joblib.load('vocabulary_metadata.pkl')
word_to_index = vocab_metadata['word2index']
index_to_word = vocab_metadata['index2word']
max_caption_size = vocab_metadata['max_caption_size']
vocab_size = vocab_metadata['vocab_size']
```
# 了解貪婪和集束搜索
為了從基于深度學習的神經圖像字幕模型生成預測,請記住,它不像基本分類或分類模型那樣簡單。 我們將需要根據輸入圖像特征在每個時間步從模型中生成一系列單詞。 有多種方式為字幕生成這些單詞序列。
一種方法稱為**采樣**或**貪婪搜索**,我們從`<START>`令牌開始,輸入圖像特征,然后基于 LSTM 輸出中的`p1`來生成第一個單詞。 然后,我們將相應的預測詞嵌入作為輸入,并根據來自下一個 LSTM 的`p2`生成下一個詞(以我們之前討論的展開形式)。 繼續此步驟,直到到達`<END>`令牌(表示字幕結束)為止,或者達到基于預定義閾值的令牌的最大可能長度。
第二種方法稱為**集束搜索**,它比基于貪婪的搜索更有效,在基于貪婪的搜索中,我們在考慮到每個單詞之前生成的單詞的基礎上,根據最高概率在每個步驟中選擇最可能的單詞順序,這正是采樣的作用。 集束搜索擴展了貪婪搜索技術,并始終返回最可能輸出的項的序列的列表。 因此,在構建每個序列時,為了在時間步`t+1`生成下一項,而不是進行貪婪搜索并生成最可能的下一項,迭代地考慮了一組`k`最佳句子基于下一步擴展到所有可能的下一詞。 `k`的值通常是用戶指定的參數,用于控制進行平行搜索或集束搜索以生成字幕序列的總數。 因此,在集束搜索中,我們以`k`最可能的單詞作為字幕序列中的第一時間步輸出開始,并繼續生成下一個序列項,直到其中一個達到結束狀態為止。 涵蓋圍繞集束搜索的詳細概念的全部范圍將不在當前范圍之內,因此,如果您有興趣,我們建議您查看有關 AI 上下文中集束搜索的任何標準文獻。
# 實現基于集束搜索的字幕生成器
現在,我們將實現一種基于集束搜索的基本算法來生成字幕序列:
```py
from keras.preprocessing import image, sequence
def get_raw_caption_sequences(model, word_to_index, image_features,
max_caption_size, beam_size=1):
start = [word_to_index['<START>']]
caption_seqs = [[start, 0.0]]
while len(caption_seqs[0][0]) < max_caption_size:
temp_caption_seqs = []
for caption_seq in caption_seqs:
partial_caption_seq = sequence.pad_sequences(
[caption_seq[0]],
maxlen=max_caption_size,
padding='post')
next_words_pred = model.predict(
[np.asarray([image_features]),
np.asarray(partial_caption_seq)])[0]
next_words = np.argsort(next_words_pred)[-beam_size:]
for word in next_words:
new_partial_caption, new_partial_caption_prob =
caption_seq[0][:], caption_seq[1]
new_partial_caption.append(word)
new_partial_caption_prob += next_words_pred[word]
temp_caption_seqs.append([new_partial_caption,
new_partial_caption_prob])
caption_seqs = temp_caption_seqs
caption_seqs.sort(key = lambda item: item[1])
caption_seqs = caption_seqs[-beam_size:]
return caption_seqs
```
這有助于我們使用集束搜索基于輸入圖像特征生成字幕。 但是,它是在每個步驟中基于先前標記的原始標記序列。 因此,我們將在此基礎上構建一個包裝器函數,該函數將利用先前的函數生成一個純文本句子作為輸入圖像的標題:
```py
def generate_image_caption(model, word_to_index_map, index_to_word_map,
image_features, max_caption_size,
beam_size=1):
raw_caption_seqs = get_raw_caption_sequences(model=model,
word_to_index=word_to_index_map,
image_features=image_features,
max_caption_size=max_caption_size,
beam_size=beam_size)
raw_caption_seqs.sort(key = lambda l: -l[1])
caption_list = [item[0] for item in raw_caption_seqs]
captions = [[index_to_word_map[idx] for idx in caption]
for caption in caption_list]
final_captions = []
for caption in captions:
start_index = caption.index('<START>')+1
max_len = len(caption)
if len(caption) < max_caption_size
else max_caption_size
end_index = caption.index('<END>')
if '<END>' in caption
else max_len-1
proc_caption = ' '.join(caption[start_index:end_index])
final_captions.append(proc_caption)
return final_captions
```
我們還需要之前的字幕預處理函數,用于訓練模型時用來預處理初始字幕:
```py
def preprocess_captions(caption_list):
pc = []
for caption in caption_list:
caption = caption.strip().lower()
caption = caption.replace('.', '')
.replace(',', '')
.replace("'", "")
.replace('"', '')
caption = caption.replace('&','and')
.replace('(','')
.replace(')', '')
.replace('-', ' ')
caption = ' '.join(caption.split())
pc.append(caption)
return pc
```
# 了解和實現 BLEU 評分
現在,我們需要選擇適當的模型表現評估指標,以評估模型的表現。 這里的一個相關指標是**雙語評估學習**(**BLEU**)得分。 這是一種評估模型在翻譯語言時的表現的出色算法。 BLEU 背后的動機是,所生成的輸出越接近于人工翻譯,則得分越高。 時至今日,它仍然是將模型輸出與人為輸出進行比較的最受歡迎的指標之一。
BLEU 算法的簡單原理是針對一組參考字幕評估生成的文本字幕(通常針對一個或多個字幕評估一個字幕,在這種情況下,每個圖像五個字幕)。 計算每個字幕的分數,然后在整個語料庫中平均以得到質量的總體估計。 BLEU 分數始終介于 0 到 1 之間,分數接近 1 表示高質量的翻譯。 甚至參考文本數據也不是完美的,因為人類在字幕圖像期間也會出錯,因此,其想法不是獲得完美的 1,而是獲得良好的整體 BLEU 分數。
我們將使用 NLTK 中的翻譯模塊中的[`corpus_bleu(...)`函數](http://www.nltk.org/api/nltk.translate.html#nltk.translate.bleu_score.corpus_bleu)來計算 BLEU 分數。 我們將計算 1、2、3 和 4 元組的總累積 BLEU 分數。 如我們已實現的評估函數所示,為`bleu2`,`bleu3`和`bleu4`分數的每個 n-gram 分數分配了相等的權重:
```py
from nltk.translate.bleu_score import corpus_bleu
def compute_bleu_evaluation(reference_captions,
predicted_captions):
actual_caps = [[caption.split() for caption in sublist]
for sublist in reference_captions]
predicted_caps = [caption.split()
for caption in predicted_captions]
bleu1 = corpus_bleu(actual_caps,
predicted_caps, weights=(1.0, 0, 0, 0))
bleu2 = corpus_bleu(actual_caps,
predicted_caps, weights=(0.5, 0.5, 0, 0))
bleu3 = corpus_bleu(actual_caps,
predicted_caps,
weights=(0.3, 0.3, 0.3, 0))
bleu4 = corpus_bleu(actual_caps, predicted_caps,
weights=(0.25, 0.25, 0.25, 0.25))
print('BLEU-1: {}'.format(bleu1))
print('BLEU-2: {}'.format(bleu2))
print('BLEU-3: {}'.format(bleu3))
print('BLEU-4: {}'.format(bleu4))
return [bleu1, bleu2, bleu3, bleu4]
```
# 評估測試數據的模型表現
現在已經準備好用于模型表現評估的所有組件。 為了評估模型在測試數據集上的表現,我們現在將使用傳遞學習來加載之前提取的圖像特征,這些特征將作為模型的輸入。 我們還將加載字幕,對其進行預處理,并將其作為每個圖像的參考字幕列表進行分離,如下所示:
```py
test_images = list(test_df['image'].unique())
test_img_features = [tl_img_feature_map[img_name]
for img_name in test_images]
actual_captions = list(test_df['caption'])
actual_captions = preprocess_captions(actual_captions)
actual_captions = [actual_captions[x:x+5]
for x in range(0, len(actual_captions),5)]
actual_captions[:2]
[['the dogs are in the snow in front of a fence',
'the dogs play on the snow',
'two brown dogs playfully fight in the snow',
'two brown dogs wrestle in the snow',
'two dogs playing in the snow'],
['a brown and white dog swimming towards some in the pool',
'a dog in a swimming pool swims toward sombody we cannot see',
'a dog swims in a pool near a person',
'small dog is paddling through the water in a pool',
'the small brown and white dog is in the pool']]
```
您可以清楚地看到每個圖像標題現在如何位于整齊的單獨列表中,這些列表將在計算 BLEU 分數時形成我們的標題參考集。 現在,我們可以生成 BLEU 分數,并使用不同的光束大小值測試模型的表現。 這里描述了一些示例:
```py
# Beam Size 1 - Model 1 with 30 epochs
predicted_captions_ep30bs1 = [generate_image_caption(model=model1,
word_to_index_map=word_to_index,
index_to_word_map=index_to_word,
image_features=img_feat,
max_caption_size=max_caption_size,
beam_size=1)[0]
for img_feat
in test_img_features]
ep30bs1_bleu = compute_bleu_evaluation(
reference_captions=actual_captions,
predicted_captions=predicted_captions_ep30bs1)
BLEU-1: 0.5049574449416513
BLEU-2: 0.3224643449851107
BLEU-3: 0.22962263359362023
BLEU-4: 0.1201459697546317
# Beam Size 1 - Model 2 with 50 epochs
predicted_captions_ep50bs1 = [generate_image_caption(model=model2,
word_to_index_map=word_to_index,
index_to_word_map=index_to_word,
image_features=img_feat,
max_caption_size=max_caption_size,
beam_size=1)[0]
for img_feat
in test_img_features]
ep50bs1_bleu = compute_bleu_evaluation(
reference_captions=actual_captions,
predicted_captions=predicted_captions_ep50bs1)
```
您可以清楚地看到,隨著我們開始考慮更高水平的 n-gram,分數開始下降。 總體而言,運行此過程非常耗時,要在集束搜索中獲得更高的階數會花費大量時間。 我們嘗試了光束大小分別為 1、3、5 和 10 的實驗。下表描述了每個實驗的模型表現:
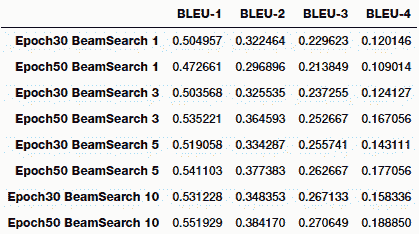
我們還可以通過圖表的形式輕松地將其可視化,以查看哪種模型參數組合為我們提供了具有最高 BLEU 得分的最佳模型:
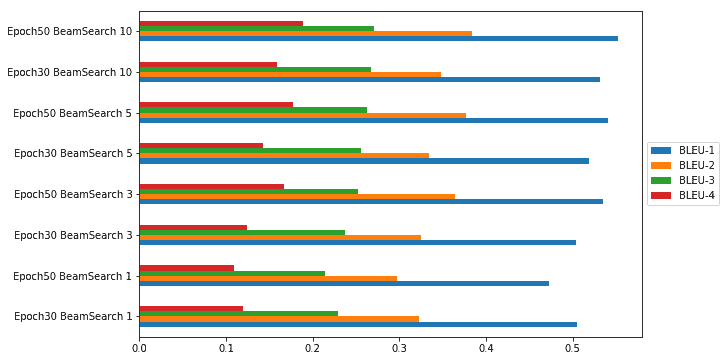
從上一張圖可以很明顯地看出,基于 BLEU 指標,我們在集束搜索期間具有 50 個周期且集束大小為 10 的模型為我們提供了最佳表現。
# 自動圖片字幕實戰!
對我們的測試數據集進行評估是測試模型表現的好方法,但是我們如何開始在現實世界中使用模型并為全新照片加上標題呢? 在這里,我們需要一些知識來構建端到端系統,該系統以任何圖像作為輸入,并為我們提供自由文本的自然語言標題作為輸出。
以下是我們的自動字幕生成器的主要組件和函數:
* 字幕模型和元數據初始化器
* 圖像特征提取模型初始化器
* 基于遷移學習的特征提取器
* 字幕生成器
為了使它通用,我們構建了一個類,該類利用了前面幾節中提到的幾個工具函數:
```py
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input as preprocess_vgg16_input
from keras.applications import vgg16
from keras.models import Model
class CaptionGenerator:
def __init__(self, image_locations=[],
word_to_index_map=None, index_to_word_map=None,
max_caption_size=None, caption_model=None,
beam_size=1):
self.image_locs = image_locations
self.captions = []
self.image_feats = []
self.word2index = word_to_index_map
self.index2word = index_to_word_map
self.max_caption_size = max_caption_size
self.vision_model = None
self.caption_model = caption_model
self.beam_size = beam_size
def process_image2arr(self, path, img_dims=(224, 224)):
img = image.load_img(path, target_size=img_dims)
img_arr = image.img_to_array(img)
img_arr = np.expand_dims(img_arr, axis=0)
img_arr = preprocess_vgg16_input(img_arr)
return img_arr
def initialize_model(self):
vgg_model = vgg16.VGG16(include_top=True, weights='imagenet',
input_shape=(224, 224, 3))
vgg_model.layers.pop()
output = vgg_model.layers[-1].output
vgg_model = Model(vgg_model.input, output)
vgg_model.trainable = False
self.vision_model = vgg_model
def process_images(self):
if self.image_locs:
image_feats = [self.vision_model.predict
(self.process_image2arr
(path=img_path)) for img_path
in self.image_locs]
image_feats = [np.reshape(img_feat, img_feat.shape[1]) for
img_feat in image_feats]
self.image_feats = image_feats
else:
print('No images specified')
def generate_captions(self):
captions = [generate_image_caption(model=self.caption_model,
word_to_index_map=self.word2index,
index_to_word_map=self.index2word,
image_features=img_feat,
max_caption_size=self.max_caption_size, beam_size=self.beam_size)[0]
for img_feat in self.image_feats]
self.captions = captions
```
現在我們的字幕生成器已經實現,現在該將其付諸實踐了! 為了測試字幕生成器,我們下載了幾張全新的圖像,這些圖像在`Flickr8K`數據集中不存在。 我們從 Flickr 下載了特定的圖像,這些圖像遵循必要的基于商業使用的許可證,因此我們可以在本書中進行描述。 我們將在下一部分中展示一些演示。
# 為室外場景中的樣本圖像加字幕
我們從 Flickr 拍攝了幾張針對各種戶外場景的圖像,并使用了我們的兩個圖像字幕模型為每個圖像生成字幕,如下所示:
```py
# load files
import glob
outdoor1_files = glob.glob('real_test/outdoor1/*')
# initialize caption generators and generate captions
cg1 = CaptionGenerator(image_locations=outdoor1_files, word_to_index_map=word_to_index, index_to_word_map=index_to_word,
max_caption_size=max_caption_size, caption_model=model1, beam_size=3)
cg2 = CaptionGenerator(image_locations=outdoor1_files, word_to_index_map=word_to_index, index_to_word_map=index_to_word,
max_caption_size=max_caption_size, caption_model=model2, beam_size=3)
cg1.initialize_model()
cg1.process_images()
cg1.generate_captions()
cg2.initialize_model()
cg2.process_images()
cg2.generate_captions()
model30ep_captions_outdoor1 = cg1.captions
model50ep_captions_outdoor1 = cg2.captions
# plot images and their captions
fig=plt.figure(figsize=(13, 11))
plt.suptitle('Automated Image Captioning: Outdoor Scenes 1', verticalalignment='top', size=15)
columns = 2
rows = 3
for i in range(1, columns*rows +1):
fig.add_subplot(rows, columns, i)
image_name = outdoor1_files[i-1]
img = image.load_img(image_name)
plt.imshow(img, aspect='auto')
modelep30_caption_text = 'Caption(ep30): '+ model30ep_captions_outdoor1[i-1]
modelep50_caption_text = 'Caption(ep50): '+ model50ep_captions_outdoor1[i-1]
plt.xlabel(modelep30_caption_text+'\n'+modelep50_caption_text,size=11, wrap=True)
fig.tight_layout()
plt.subplots_adjust(top=0.955)
```
前面代碼的輸出如下:

根據前面的圖像,您可以清楚地看到它已正確識別每個場景。 這不是一個完美的模型,因為我們可以清楚地看到它并沒有在第二行的第二張圖像中識別出狗,而是清楚地識別了一群人。 此外,我們的模型確實犯了一些顏色識別錯誤,例如將綠色球識別為紅色球。 總體而言,生成的字幕絕對適用于源圖像!
以下圖像是從更多樣化的戶外場景中摘錄的,并基于流行的戶外活動。 我們將專注于不同的活動,以查看我們的模型在不同類型的場景上的表現如何,而不是僅關注一個特定的場景:

在前面的圖像中,我們專注于各種各樣的戶外活動,包括越野自行車,滑雪,沖浪,皮劃艇和攀巖。 如果您查看生成的字幕,它們與每個場景都相關,并可以很好地描述它們。 在某些情況下,我們的模型會變得非常具體,甚至描述每個人的穿著。 但是,正如我們前面提到的,它會在幾種情況下錯誤地識別顏色,可能可以通過添加更多數據以及對高分辨率圖像進行訓練來改善顏色。
# 為流行運動的樣本圖像加字幕
在模型測試的最后一部分,我們從 Flickr 拍攝了幾張圖像,這些圖像專注于世界各地通常進行的各種體育運動。 我們肯定獲得了一些有趣的結果,因為我們不僅僅關注一兩個基于運動的場景。 生成此代碼的代碼與我們在上一節中使用的代碼完全相同,只是源圖像發生了變化。 與往常一樣,筆記本中提供了詳細的代碼以供參考。 以下是我們的字幕生成器在第一批運動場景上的結果:

在前面的圖像中,我們可以清楚地看到訓練有 50 個周期的模型在視覺上更詳細地描述圖像方面優于具有 30 個周期的模型。 這包括特定的球衣和服裝顏色,例如白色,藍色和紅色。 我們還看到字幕中提到了一些具體的活動,例如:踢足球,看曲棍球的進球或在泥濘的賽道上駕駛。 這無疑為生成的字幕提供了更多的深度和含義。 我們的模型具有 30 個周期,因此在某些圖像中所進行的確切運動方面也會犯一些錯誤。
現在,讓我們看一下體育場景的最后一組,以了解我們的字幕生成器在與前一組場景完全不同的體育活動中的表現:

我們可以從前面的輸出中觀察到,我們的兩個模型都運行良好,在 30 個周期上訓練的模型在幾種情況下都表現出色,例如識別出踢足球的孩子或男孩,甚至是比賽中 BMX 騎手的顏色和配飾。 總體而言,這兩種模型都表現良好,并且在某種程度上解釋了風景,類似于人類對這些場面的描述。
成功的主要方面是我們的模型不僅可以正確識別每個活動,而且還能夠生成有意義且適用的標題。 我們鼓勵您嘗試在不同的場景上構建和測試自己的字幕生成器!
# 未來的改進空間
根據我們在本章中采用的方法,有多種方法可以改進此模型。 以下是一些可以改進的特定方面:
* 使用更好的圖像特征提取模型,例如 Google 的 Inception 模型
* 分辨率更高,質量更好的訓練圖像(需要 GPU 功能!)
* 基于 Flickr30K 等數據集甚至圖像增強的更多訓練數據
* 在模型中引入注意力
如果您擁有必要的數據和基礎架構,那么這些點子值得探討!
# 總結
這絕對是我們整本書中解決的最棘手的現實問題之一。 它是遷移學習和生成型深度學習的完美結合,可應用于來自圖像和文本的數據組合,這些組合結合了圍繞計算機視覺和 NLP 的不同領域。 我們介紹了有關理解圖像字幕的基本概念,構建字幕生成器所需的主要組件,并從頭開始構建了我們自己的模型。 我們通過利用預先訓練的計算機視覺模型從要字幕的圖像中提取正確的特征,然后將它們與一些順序模型(例如 LSTM)結合使用,以有效地利用遷移學習原理。 順序模型的有效評估非常困難,我們利用行業標準的 BLEU 評分標準來達到目的。 我們從頭開始實現評分函數,并在測試數據集上評估了我們的模型。
最后,我們使用以前構建的所有資產和組件從頭構建了一個通用的自動圖像字幕系統,并在來自不同領域的多種圖像上對其進行了測試。 我們希望這能給您一個很好的入門介紹,這是計算機視覺和 NLP 的完美結合,并且我們絕對鼓勵您構建自己的圖像捕獲系統!
- TensorFlow 1.x 深度學習秘籍
- 零、前言
- 一、TensorFlow 簡介
- 二、回歸
- 三、神經網絡:感知器
- 四、卷積神經網絡
- 五、高級卷積神經網絡
- 六、循環神經網絡
- 七、無監督學習
- 八、自編碼器
- 九、強化學習
- 十、移動計算
- 十一、生成模型和 CapsNet
- 十二、分布式 TensorFlow 和云深度學習
- 十三、AutoML 和學習如何學習(元學習)
- 十四、TensorFlow 處理單元
- 使用 TensorFlow 構建機器學習項目中文版
- 一、探索和轉換數據
- 二、聚類
- 三、線性回歸
- 四、邏輯回歸
- 五、簡單的前饋神經網絡
- 六、卷積神經網絡
- 七、循環神經網絡和 LSTM
- 八、深度神經網絡
- 九、大規模運行模型 -- GPU 和服務
- 十、庫安裝和其他提示
- TensorFlow 深度學習中文第二版
- 一、人工神經網絡
- 二、TensorFlow v1.6 的新功能是什么?
- 三、實現前饋神經網絡
- 四、CNN 實戰
- 五、使用 TensorFlow 實現自編碼器
- 六、RNN 和梯度消失或爆炸問題
- 七、TensorFlow GPU 配置
- 八、TFLearn
- 九、使用協同過濾的電影推薦
- 十、OpenAI Gym
- TensorFlow 深度學習實戰指南中文版
- 一、入門
- 二、深度神經網絡
- 三、卷積神經網絡
- 四、循環神經網絡介紹
- 五、總結
- 精通 TensorFlow 1.x
- 一、TensorFlow 101
- 二、TensorFlow 的高級庫
- 三、Keras 101
- 四、TensorFlow 中的經典機器學習
- 五、TensorFlow 和 Keras 中的神經網絡和 MLP
- 六、TensorFlow 和 Keras 中的 RNN
- 七、TensorFlow 和 Keras 中的用于時間序列數據的 RNN
- 八、TensorFlow 和 Keras 中的用于文本數據的 RNN
- 九、TensorFlow 和 Keras 中的 CNN
- 十、TensorFlow 和 Keras 中的自編碼器
- 十一、TF 服務:生產中的 TensorFlow 模型
- 十二、遷移學習和預訓練模型
- 十三、深度強化學習
- 十四、生成對抗網絡
- 十五、TensorFlow 集群的分布式模型
- 十六、移動和嵌入式平臺上的 TensorFlow 模型
- 十七、R 中的 TensorFlow 和 Keras
- 十八、調試 TensorFlow 模型
- 十九、張量處理單元
- TensorFlow 機器學習秘籍中文第二版
- 一、TensorFlow 入門
- 二、TensorFlow 的方式
- 三、線性回歸
- 四、支持向量機
- 五、最近鄰方法
- 六、神經網絡
- 七、自然語言處理
- 八、卷積神經網絡
- 九、循環神經網絡
- 十、將 TensorFlow 投入生產
- 十一、更多 TensorFlow
- 與 TensorFlow 的初次接觸
- 前言
- 1.?TensorFlow 基礎知識
- 2. TensorFlow 中的線性回歸
- 3. TensorFlow 中的聚類
- 4. TensorFlow 中的單層神經網絡
- 5. TensorFlow 中的多層神經網絡
- 6. 并行
- 后記
- TensorFlow 學習指南
- 一、基礎
- 二、線性模型
- 三、學習
- 四、分布式
- TensorFlow Rager 教程
- 一、如何使用 TensorFlow Eager 構建簡單的神經網絡
- 二、在 Eager 模式中使用指標
- 三、如何保存和恢復訓練模型
- 四、文本序列到 TFRecords
- 五、如何將原始圖片數據轉換為 TFRecords
- 六、如何使用 TensorFlow Eager 從 TFRecords 批量讀取數據
- 七、使用 TensorFlow Eager 構建用于情感識別的卷積神經網絡(CNN)
- 八、用于 TensorFlow Eager 序列分類的動態循壞神經網絡
- 九、用于 TensorFlow Eager 時間序列回歸的遞歸神經網絡
- TensorFlow 高效編程
- 圖嵌入綜述:問題,技術與應用
- 一、引言
- 三、圖嵌入的問題設定
- 四、圖嵌入技術
- 基于邊重構的優化問題
- 應用
- 基于深度學習的推薦系統:綜述和新視角
- 引言
- 基于深度學習的推薦:最先進的技術
- 基于卷積神經網絡的推薦
- 關于卷積神經網絡我們理解了什么
- 第1章概論
- 第2章多層網絡
- 2.1.4生成對抗網絡
- 2.2.1最近ConvNets演變中的關鍵架構
- 2.2.2走向ConvNet不變性
- 2.3時空卷積網絡
- 第3章了解ConvNets構建塊
- 3.2整改
- 3.3規范化
- 3.4匯集
- 第四章現狀
- 4.2打開問題
- 參考
- 機器學習超級復習筆記
- Python 遷移學習實用指南
- 零、前言
- 一、機器學習基礎
- 二、深度學習基礎
- 三、了解深度學習架構
- 四、遷移學習基礎
- 五、釋放遷移學習的力量
- 六、圖像識別與分類
- 七、文本文件分類
- 八、音頻事件識別與分類
- 九、DeepDream
- 十、自動圖像字幕生成器
- 十一、圖像著色
- 面向計算機視覺的深度學習
- 零、前言
- 一、入門
- 二、圖像分類
- 三、圖像檢索
- 四、對象檢測
- 五、語義分割
- 六、相似性學習
- 七、圖像字幕
- 八、生成模型
- 九、視頻分類
- 十、部署
- 深度學習快速參考
- 零、前言
- 一、深度學習的基礎
- 二、使用深度學習解決回歸問題
- 三、使用 TensorBoard 監控網絡訓練
- 四、使用深度學習解決二分類問題
- 五、使用 Keras 解決多分類問題
- 六、超參數優化
- 七、從頭開始訓練 CNN
- 八、將預訓練的 CNN 用于遷移學習
- 九、從頭開始訓練 RNN
- 十、使用詞嵌入從頭開始訓練 LSTM
- 十一、訓練 Seq2Seq 模型
- 十二、深度強化學習
- 十三、生成對抗網絡
- TensorFlow 2.0 快速入門指南
- 零、前言
- 第 1 部分:TensorFlow 2.00 Alpha 簡介
- 一、TensorFlow 2 簡介
- 二、Keras:TensorFlow 2 的高級 API
- 三、TensorFlow 2 和 ANN 技術
- 第 2 部分:TensorFlow 2.00 Alpha 中的監督和無監督學習
- 四、TensorFlow 2 和監督機器學習
- 五、TensorFlow 2 和無監督學習
- 第 3 部分:TensorFlow 2.00 Alpha 的神經網絡應用
- 六、使用 TensorFlow 2 識別圖像
- 七、TensorFlow 2 和神經風格遷移
- 八、TensorFlow 2 和循環神經網絡
- 九、TensorFlow 估計器和 TensorFlow HUB
- 十、從 tf1.12 轉換為 tf2
- TensorFlow 入門
- 零、前言
- 一、TensorFlow 基本概念
- 二、TensorFlow 數學運算
- 三、機器學習入門
- 四、神經網絡簡介
- 五、深度學習
- 六、TensorFlow GPU 編程和服務
- TensorFlow 卷積神經網絡實用指南
- 零、前言
- 一、TensorFlow 的設置和介紹
- 二、深度學習和卷積神經網絡
- 三、TensorFlow 中的圖像分類
- 四、目標檢測與分割
- 五、VGG,Inception,ResNet 和 MobileNets
- 六、自編碼器,變分自編碼器和生成對抗網絡
- 七、遷移學習
- 八、機器學習最佳實踐和故障排除
- 九、大規模訓練
- 十、參考文獻