
# 七、圖像字幕生成
在本章中,我們將處理字幕圖像的問題。 這涉及到檢測對象,并且還提出了圖像的文本標題。 圖像字幕生成也可以稱為**圖像文本轉換**。 曾經被認為是一個非常棘手的問題,我們現在在此方面取得了相當不錯的成績。 對于本章,需要具有相應標題的圖像數據集。 在本章中,我們將詳細討論圖像字幕生成的技術和應用。
我們將在本章介紹以下主題:
* 了解用于評估它們的不同數據集和指標
* 了解用于自然語言處理問題的一些技巧
* 向量模型的不同單詞
* 幾種用于圖像字幕生成的算法
* 不良結果和改進范圍
# 了解問題和數據集
自動生成圖像標題的過程是一項重要的深度學習任務,因為它結合了語言和視覺這兩個世界。 該問題的獨特性使其成為計算機視覺中的主要問題之一。 用于圖像字幕生成的深度學習模型應該能夠識別圖像中存在的對象,并能夠以自然語言生成表示對象與動作之間關系的文本。 此問題的數據集很少。 其中最著名的數據集是第 4 章,“對象檢測”中對象檢測中涵蓋的 COCO 數據集的擴展。
# 了解用于圖像字幕生成的自然語言處理
由于必須從圖像中生成自然語言,因此熟悉**自然語言處理**(**NLP**)變得很重要。 NLP 的概念是一個廣泛的主題,因此我們將范圍限制為與圖像字幕生成相關的主題。 自然語言的一種形式是**文本**。 文本是單詞或字符的序列。 文本的原子元素稱為**令牌**,它是**字符**的序列。 字符是文本的原子元素。
為了處理文本形式的任何自然語言,必須通過刪除標點符號,方括號等對文本進行預處理。 然后,必須通過將文本分隔為空格來將文本標記為單詞。 然后,必須將單詞轉換為向量。 接下來,我們將看到向量轉換如何提供幫助。
# 以向量形式表達單詞
向量形式的單詞可以幫助自己執行算術運算。 向量必須緊湊,尺寸較小。 同義詞應具有相似的向量,而反義詞應具有不同的向量。 可以將單詞轉換為向量,以便可以如下所示比較關系:
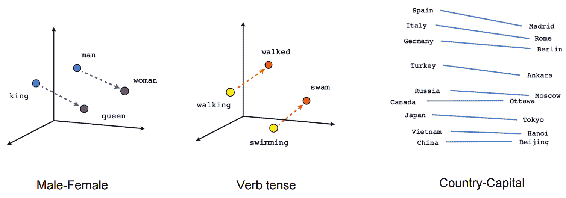
該向量算法使得能夠在不同實體之間的語義空間中進行比較。 接下來,我們將看到如何創建可將單詞轉換為向量表示的深度學習模型。
# 將單詞轉換為向量
通過在大型文本語料庫上訓練模型,可以將單詞轉換為向量。 訓練模型,使得給定一個單詞,該模型可以預測附近的單詞。 在預測附近單詞的單次熱編碼之前,首先對單詞進行單次熱編碼,然后進行隱藏層。 以這種方式進行訓練將創建單詞的緊湊表示。 可以通過兩種方式獲得單詞的上下文,如下所示:
* **跳躍圖**(**SkipGram**):給定一個單詞,嘗試預測幾個接近的單詞
* **連續詞袋**(**CBOW**):通過給定一組詞來預測一個詞,從而跳過跳躍語法
下圖說明了這些過程:
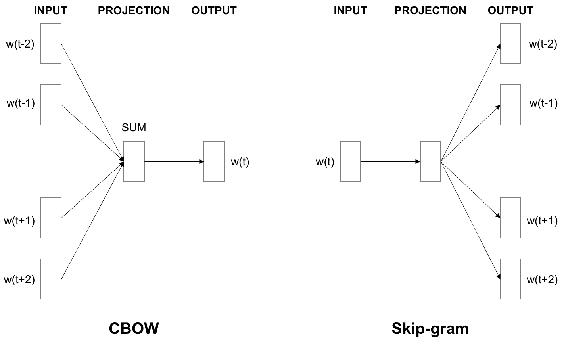
兩種方法均顯示出良好的結果。 單詞在嵌入空間中轉換為向量。 接下來,我們將看到訓練嵌入空間的詳細信息。
# 訓練嵌入
可以使用如下所示的模型來訓練嵌入:
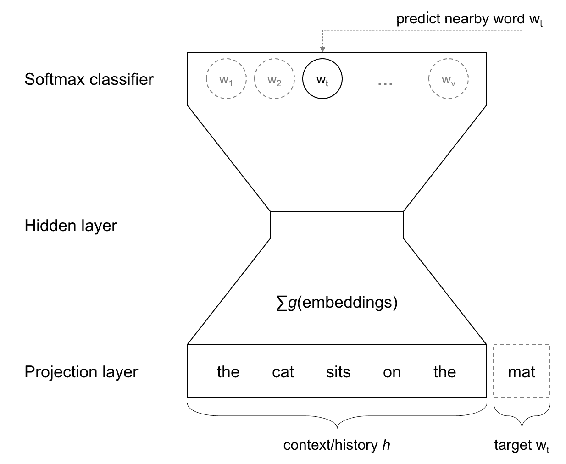
如上圖所示,目標詞是根據上下文或歷史預測的。 該預測基于 **Softmax 分類器**。 隱藏層將嵌入作為緊湊的表示形式學習。 請注意,這不是完整的深度學習模型,但它仍然可以正常工作。 這是嵌入的低維可視化:
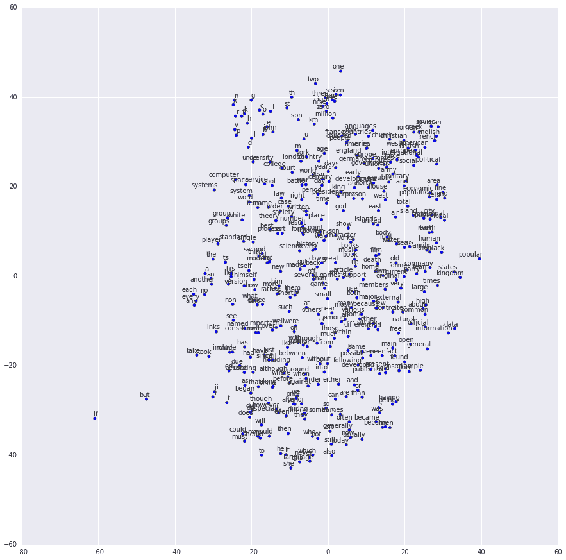
使用 Softmax 分類器的嵌入的低維可視化
該可視化使用 TensorBoard 生成。 具有相似語義或不同詞性的單詞會一起出現。
我們已經學習了如何訓練用于生成文本的緊湊表示。 接下來,我們將看到圖像字幕生成的方法。
# 圖像字幕生成方法及相關問題
已經提出了幾種對圖像進行字幕的方法。 直觀地,將圖像轉換為視覺特征,并從這些特征生成文本。 生成的文本將采用詞嵌入的形式。 生成文本的一些主要方法涉及 LSTM 和關注。 讓我們從使用舊的生成文本的方法開始。
# 使用條件隨機場鏈接圖像和文本
Kulkarni 等人在[論文](http://www.tamaraberg.com/papers/generation_cvpr11.pdf)中,提出了一種從圖像中查找對象和屬性并使用它來生成文本的方法。 **條件隨機場**(**CRF**)。 傳統上,CRF 用于結構化預測,例如文本生成。 生成文本的流程如下所示:
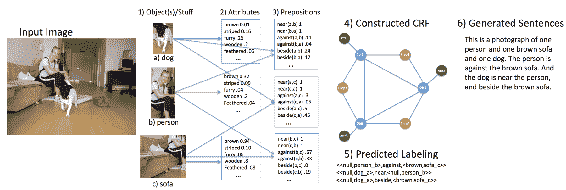
該圖說明了使用 CRF 生成文本的過程(摘自 Kulkarni 等人)
CRF 的使用在以適當的前置詞以連貫的方式生成文本方面存在局限性。 結果顯示在這里:

復制自 Kulkarni 等人
結果對對象和屬性具有正確的預測,但無法生成良好的描述。
# 在 CNN 特征上使用 RNN 生成字幕
Vinyals 等人在[論文](https://arxiv.org/pdf/1411.4555.pdf)中提出了一種端到端可訓練的深度學習用于圖像字幕生成的方法,該方法將 CNN 和 RNN 背靠背地堆疊在一起。 這是一個端到端的可訓練模型。 結構如下所示:
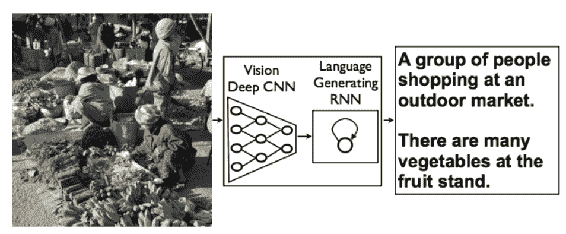
轉載自 Vinyals 等人(2015 年)
該模型可以生成以自然語言完成的句子。 CNN 和 **LSTM** 的展開圖如下所示:
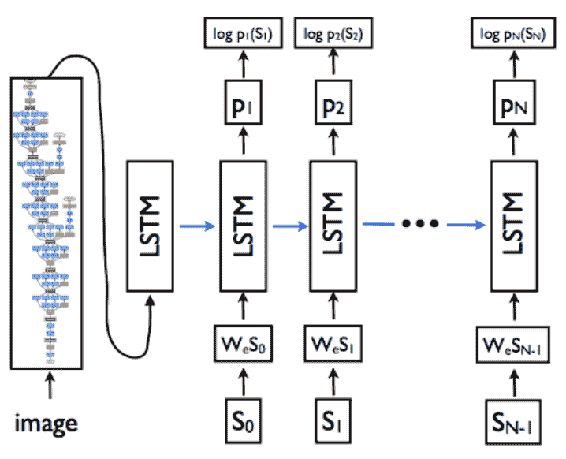
該圖說明了 CNN 和 LSTM 架構(摘自 Vinyals 等人)
這是 **LSTM** 的展開視圖。 此處顯示了一組選擇性的結果:

轉載自 Vinyals 等人(2015 年)
在此過程中,CNN 將圖像編碼為特征,RNN 從中生成句子。
# 使用圖像排名創建字幕
Ordonez 等人在[論文](http://papers.nips.cc/paper/4470-im2text-describing-images-using-1-million-captioned-photographs.pdf)中,提出了一種方法對圖像進行排名,然后生成標題。 此過程的流程如下所示:

復制自 Ordonez 等人(2015)
從排名圖像中提取的高級信息可用于生成文本。 下圖顯示,可用于排名的圖像越多,結果將越好:
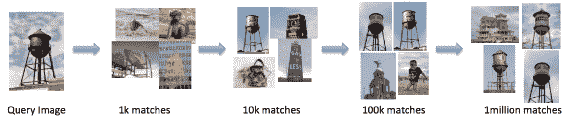
復制自 Ordonez 等人(2015)
# 從圖像檢索字幕和從字幕檢索圖像
Chen 等人在[論文](https://www.cs.cmu.edu/~xinleic/papers/cvpr15_rnn.pdf)中,提出了一種從文本中檢索圖像和從圖像中檢索文本的方法。 這是雙向映射。 下圖顯示了一個用自然語言解釋圖像的人和另一個在視覺上思考它的人:

轉載自 Chen 等人(2015)
檢索字幕可以通過以下方式通過潛在空間連接圖像和文本的編碼器來實現:
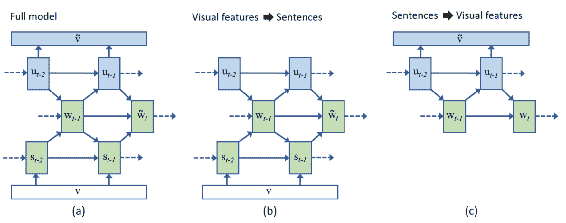
轉載自 Chen 等人(2015)
圖像中的第一個模型是用于訓練的完整模型。 如圖中所示,視覺特征也可以用于生成句子,反之亦然。
# 密集字幕
Johnson 等人在[論文](https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Johnson_DenseCap_Fully_Convolutional_CVPR_2016_paper.pdf)中,提出了一種用于密集字幕的方法。 首先,讓我們看一些結果,以了解任務:
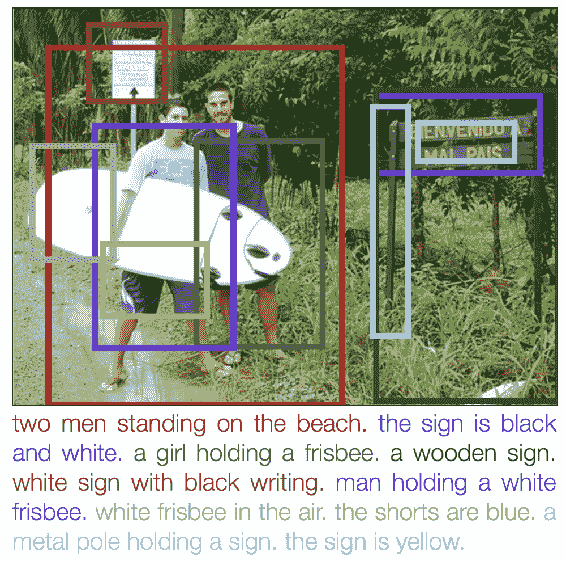
轉載自 Johnson 等人
如您所見,為圖像中的對象和動作生成了單獨的標題; 由此得名; **密集字幕**。 這是 Johnson 等人提出的架構:
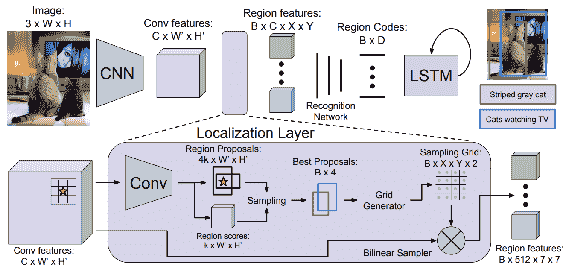
轉自 Johnson 等人
該架構實質上是 Faster-RCNN 和 **LSTM** 的組合。 產生該區域以產生對象檢測結果,并且使用該區域的視覺特征來產生字幕。
# 使用 RNN 的字幕生成
Donahue 等人在[論文](https://arxiv.org/pdf/1411.4389.pdf)中,提出了**長期循環卷積網絡**(**LRCN**) 用于圖像字幕生成的任務。 此模型的架構如下所示:
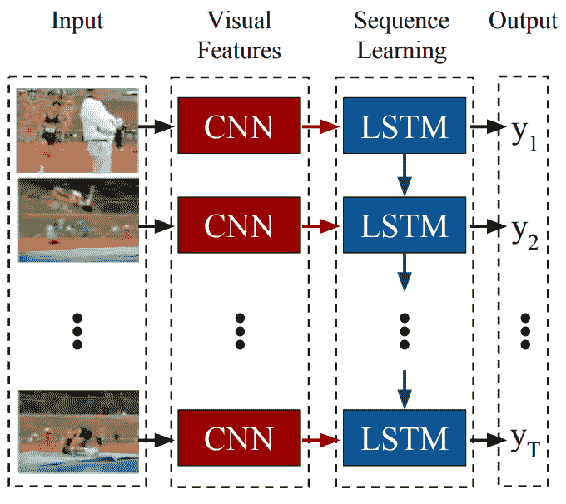
轉載自 Donahue 等人
圖中顯示了 CNN 和 LSTM 在整個時間上的權重,這使得該方法可擴展到任意長序列。
# 使用多模態度量空間
Mao 等人在[論文](http://papers.nips.cc/paper/4470-im2text-describing-images-using-1-million-captioned-photographs.pdf)中提出了一種使用**多模態嵌入空間**生成字幕的方法。 下圖說明了這種方法:
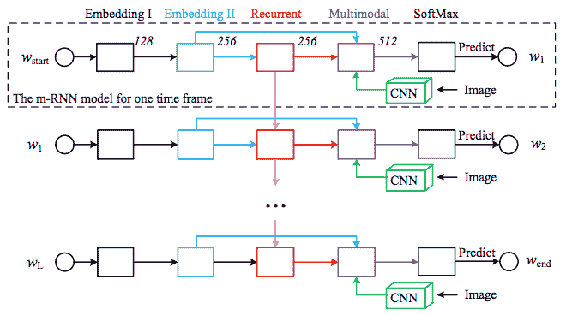
轉自毛等人。
Kiros 等人在[論文](https://arxiv.org/pdf/1411.2539.pdf)中提出了另一種生成字幕的多模態方法,該方法可以將圖像和文本嵌入同一多模態空間。 下圖說明了這種方法:
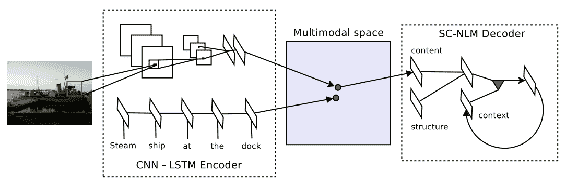
復制自 Kiros 等人
兩種多模式方法都給出了良好的結果。
# 使用注意力網絡的字幕生成
Xu 等人在[論文](https://arxiv.org/pdf/1502.03044.pdf)中,提出了一種使用**注意力機制**進行圖像字幕生成的方法。 注意力機制對圖像的某些區域比其他區域賦予更多權重。 注意還可以實現可視化,向我們展示模型生成下一個單詞時所關注的位置。 建議的模型如下所示:
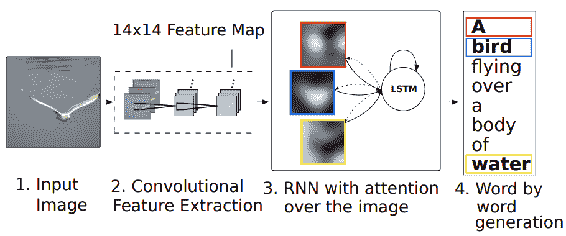
轉載自徐等人。
首先,從圖像中提取 CNN 特征。 然后,將關注的 RNN 應用于生成單詞的圖像。
# 知道什么時候看
[Lu 等人](https://arxiv.org/pdf/1612.01887.pdf)提出了一種引起關注的方法,可提供出色的結果。 知道何時看待注意力捕獲的區域會產生更好的結果。 流程如下所示:
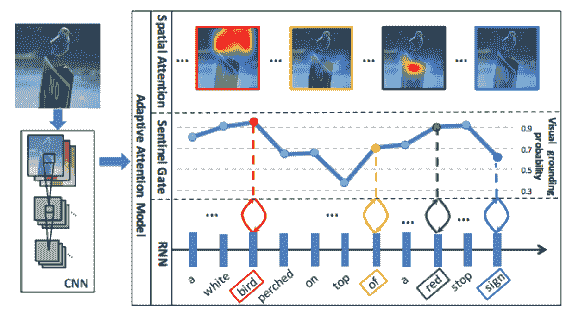
摘自 Lu 等人
注意力機制如下所示:
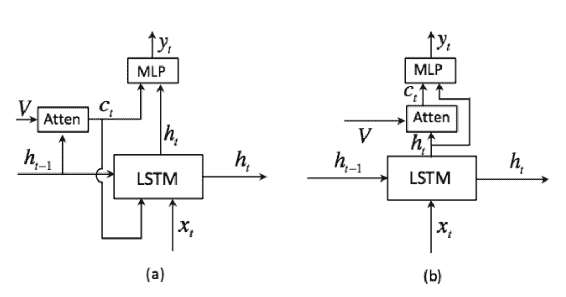
摘自 Lu 等人
結果重點突出的區域如下:

摘自 Lu 等人
生成字幕時注意力的釋放在此處可視化:
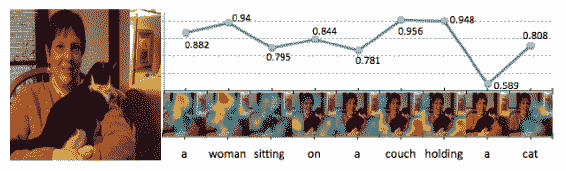
摘自 Lu 等人
我們已經看到,用于生成字幕幾種方法。 接下來,我們將看到一個實現。
# 實現基于注意力的圖像字幕生成
讓我們使用以下代碼從 VGG 和 LSTM 模型定義 CNN:
```py
vgg_model = tf.keras.applications.vgg16.VGG16(weights='imagenet',
include_top=False,
input_tensor=input_tensor,
input_shape=input_shape)
word_embedding = tf.keras.layers.Embedding(
vocabulary_size, embedding_dimension, input_length=sequence_length)
embbedding = word_embedding(previous_words)
embbedding = tf.keras.layers.Activation('relu')(embbedding)
embbedding = tf.keras.layers.Dropout(dropout_prob)(embbedding)
cnn_features_flattened = tf.keras.layers.Reshape((height * height, shape))(cnn_features)
net = tf.keras.layers.GlobalAveragePooling1D()(cnn_features_flattened)
net = tf.keras.layers.Dense(embedding_dimension, activation='relu')(net)
net = tf.keras.layers.Dropout(dropout_prob)(net)
net = tf.keras.layers.RepeatVector(sequence_length)(net)
net = tf.keras.layers.concatenate()([net, embbedding])
net = tf.keras.layers.Dropout(dropout_prob)(net)
```
現在,我們已經定義了 CNN,接下來使用以下代碼定義關注層:
```py
h_out_linear = tf.keras.layers.Convolution1D(
depth, 1, activation='tanh', border_mode='same')(h)
h_out_linear = tf.keras.layers.Dropout(
dropout_prob)(h_out_linear)
h_out_embed = tf.keras.layers.Convolution1D(
embedding_dimension, 1, border_mode='same')(h_out_linear)
z_h_embed = tf.keras.layers.TimeDistributed(
tf.keras.layers.RepeatVector(num_vfeats))(h_out_embed)
Vi = tf.keras.layers.Convolution1D(
depth, 1, border_mode='same', activation='relu')(V)
Vi = tf.keras.layers.Dropout(dropout_prob)(Vi)
Vi_emb = tf.keras.layers.Convolution1D(
embedding_dimension, 1, border_mode='same', activation='relu')(Vi)
z_v_linear = tf.keras.layers.TimeDistributed(
tf.keras.layers.RepeatVector(sequence_length))(Vi)
z_v_embed = tf.keras.layers.TimeDistributed(
tf.keras.layers.RepeatVector(sequence_length))(Vi_emb)
z_v_linear = tf.keras.layers.Permute((2, 1, 3))(z_v_linear)
z_v_embed = tf.keras.layers.Permute((2, 1, 3))(z_v_embed)
fake_feat = tf.keras.layers.Convolution1D(
depth, 1, activation='relu', border_mode='same')(s)
fake_feat = tf.keras.layers.Dropout(dropout_prob)(fake_feat)
fake_feat_embed = tf.keras.layers.Convolution1D(
embedding_dimension, 1, border_mode='same')(fake_feat)
z_s_linear = tf.keras.layers.Reshape((sequence_length, 1, depth))(fake_feat)
z_s_embed = tf.keras.layers.Reshape(
(sequence_length, 1, embedding_dimension))(fake_feat_embed)
z_v_linear = tf.keras.layers.concatenate(axis=-2)([z_v_linear, z_s_linear])
z_v_embed = tf.keras.layers.concatenate(axis=-2)([z_v_embed, z_s_embed])
z = tf.keras.layers.Merge(mode='sum')([z_h_embed,z_v_embed])
z = tf.keras.layers.Dropout(dropout_prob)(z)
z = tf.keras.layers.TimeDistributed(
tf.keras.layers.Activation('tanh'))(z)
attention= tf.keras.layers.TimeDistributed(
tf.keras.layers.Convolution1D(1, 1, border_mode='same'))(z)
attention = tf.keras.layers.Reshape((sequence_length, num_vfeats))(attention)
attention = tf.keras.layers.TimeDistributed(
tf.keras.layers.Activation('softmax'))(attention)
attention = tf.keras.layers.TimeDistributed(
tf.keras.layers.RepeatVector(depth))(attention)
attention = tf.keras.layers.Permute((1,3,2))(attention)
w_Vi = tf.keras.layers.Add()([attention,z_v_linear])
sumpool = tf.keras.layers.Lambda(lambda x: K.sum(x, axis=-2),
output_shape=(depth,))
c_vec = tf.keras.layers.TimeDistributed(sumpool)(w_Vi)
atten_out = tf.keras.layers.Merge(mode='sum')([h_out_linear,c_vec])
h = tf.keras.layers.TimeDistributed(
tf.keras.layers.Dense(embedding_dimension,activation='tanh'))(atten_out)
h = tf.keras.layers.Dropout(dropout_prob)(h)
predictions = tf.keras.layers.TimeDistributed(
tf.keras.layers.Dense(vocabulary_size, activation='softmax'))(h)
```
在前面的代碼的幫助下,我們定義了一個深度學習模型,該模型將 CNN 特征與 RNN 結合在一起,并借助注意力機制。 目前,這是生成字幕的最佳方法。
# 總結
在本章中,我們已經了解了與圖像標題相關的問題。 我們看到了一些涉及自然語言處理和各種`word2vec`模型(例如`GLOVE`)的技術。 我們了解了`CNN2RNN`,度量學習和組合目標等幾種算法。 后來,我們實現了一個結合了 CNN 和 LSTM 的模型。
在下一章中,我們就來了解生成模型。 我們將從頭開始學習和實現樣式算法,并介紹一些最佳模型。 我們還將介紹很酷的**生成對抗網絡**(**GAN**)及其各種應用。
- TensorFlow 1.x 深度學習秘籍
- 零、前言
- 一、TensorFlow 簡介
- 二、回歸
- 三、神經網絡:感知器
- 四、卷積神經網絡
- 五、高級卷積神經網絡
- 六、循環神經網絡
- 七、無監督學習
- 八、自編碼器
- 九、強化學習
- 十、移動計算
- 十一、生成模型和 CapsNet
- 十二、分布式 TensorFlow 和云深度學習
- 十三、AutoML 和學習如何學習(元學習)
- 十四、TensorFlow 處理單元
- 使用 TensorFlow 構建機器學習項目中文版
- 一、探索和轉換數據
- 二、聚類
- 三、線性回歸
- 四、邏輯回歸
- 五、簡單的前饋神經網絡
- 六、卷積神經網絡
- 七、循環神經網絡和 LSTM
- 八、深度神經網絡
- 九、大規模運行模型 -- GPU 和服務
- 十、庫安裝和其他提示
- TensorFlow 深度學習中文第二版
- 一、人工神經網絡
- 二、TensorFlow v1.6 的新功能是什么?
- 三、實現前饋神經網絡
- 四、CNN 實戰
- 五、使用 TensorFlow 實現自編碼器
- 六、RNN 和梯度消失或爆炸問題
- 七、TensorFlow GPU 配置
- 八、TFLearn
- 九、使用協同過濾的電影推薦
- 十、OpenAI Gym
- TensorFlow 深度學習實戰指南中文版
- 一、入門
- 二、深度神經網絡
- 三、卷積神經網絡
- 四、循環神經網絡介紹
- 五、總結
- 精通 TensorFlow 1.x
- 一、TensorFlow 101
- 二、TensorFlow 的高級庫
- 三、Keras 101
- 四、TensorFlow 中的經典機器學習
- 五、TensorFlow 和 Keras 中的神經網絡和 MLP
- 六、TensorFlow 和 Keras 中的 RNN
- 七、TensorFlow 和 Keras 中的用于時間序列數據的 RNN
- 八、TensorFlow 和 Keras 中的用于文本數據的 RNN
- 九、TensorFlow 和 Keras 中的 CNN
- 十、TensorFlow 和 Keras 中的自編碼器
- 十一、TF 服務:生產中的 TensorFlow 模型
- 十二、遷移學習和預訓練模型
- 十三、深度強化學習
- 十四、生成對抗網絡
- 十五、TensorFlow 集群的分布式模型
- 十六、移動和嵌入式平臺上的 TensorFlow 模型
- 十七、R 中的 TensorFlow 和 Keras
- 十八、調試 TensorFlow 模型
- 十九、張量處理單元
- TensorFlow 機器學習秘籍中文第二版
- 一、TensorFlow 入門
- 二、TensorFlow 的方式
- 三、線性回歸
- 四、支持向量機
- 五、最近鄰方法
- 六、神經網絡
- 七、自然語言處理
- 八、卷積神經網絡
- 九、循環神經網絡
- 十、將 TensorFlow 投入生產
- 十一、更多 TensorFlow
- 與 TensorFlow 的初次接觸
- 前言
- 1.?TensorFlow 基礎知識
- 2. TensorFlow 中的線性回歸
- 3. TensorFlow 中的聚類
- 4. TensorFlow 中的單層神經網絡
- 5. TensorFlow 中的多層神經網絡
- 6. 并行
- 后記
- TensorFlow 學習指南
- 一、基礎
- 二、線性模型
- 三、學習
- 四、分布式
- TensorFlow Rager 教程
- 一、如何使用 TensorFlow Eager 構建簡單的神經網絡
- 二、在 Eager 模式中使用指標
- 三、如何保存和恢復訓練模型
- 四、文本序列到 TFRecords
- 五、如何將原始圖片數據轉換為 TFRecords
- 六、如何使用 TensorFlow Eager 從 TFRecords 批量讀取數據
- 七、使用 TensorFlow Eager 構建用于情感識別的卷積神經網絡(CNN)
- 八、用于 TensorFlow Eager 序列分類的動態循壞神經網絡
- 九、用于 TensorFlow Eager 時間序列回歸的遞歸神經網絡
- TensorFlow 高效編程
- 圖嵌入綜述:問題,技術與應用
- 一、引言
- 三、圖嵌入的問題設定
- 四、圖嵌入技術
- 基于邊重構的優化問題
- 應用
- 基于深度學習的推薦系統:綜述和新視角
- 引言
- 基于深度學習的推薦:最先進的技術
- 基于卷積神經網絡的推薦
- 關于卷積神經網絡我們理解了什么
- 第1章概論
- 第2章多層網絡
- 2.1.4生成對抗網絡
- 2.2.1最近ConvNets演變中的關鍵架構
- 2.2.2走向ConvNet不變性
- 2.3時空卷積網絡
- 第3章了解ConvNets構建塊
- 3.2整改
- 3.3規范化
- 3.4匯集
- 第四章現狀
- 4.2打開問題
- 參考
- 機器學習超級復習筆記
- Python 遷移學習實用指南
- 零、前言
- 一、機器學習基礎
- 二、深度學習基礎
- 三、了解深度學習架構
- 四、遷移學習基礎
- 五、釋放遷移學習的力量
- 六、圖像識別與分類
- 七、文本文件分類
- 八、音頻事件識別與分類
- 九、DeepDream
- 十、自動圖像字幕生成器
- 十一、圖像著色
- 面向計算機視覺的深度學習
- 零、前言
- 一、入門
- 二、圖像分類
- 三、圖像檢索
- 四、對象檢測
- 五、語義分割
- 六、相似性學習
- 七、圖像字幕
- 八、生成模型
- 九、視頻分類
- 十、部署
- 深度學習快速參考
- 零、前言
- 一、深度學習的基礎
- 二、使用深度學習解決回歸問題
- 三、使用 TensorBoard 監控網絡訓練
- 四、使用深度學習解決二分類問題
- 五、使用 Keras 解決多分類問題
- 六、超參數優化
- 七、從頭開始訓練 CNN
- 八、將預訓練的 CNN 用于遷移學習
- 九、從頭開始訓練 RNN
- 十、使用詞嵌入從頭開始訓練 LSTM
- 十一、訓練 Seq2Seq 模型
- 十二、深度強化學習
- 十三、生成對抗網絡
- TensorFlow 2.0 快速入門指南
- 零、前言
- 第 1 部分:TensorFlow 2.00 Alpha 簡介
- 一、TensorFlow 2 簡介
- 二、Keras:TensorFlow 2 的高級 API
- 三、TensorFlow 2 和 ANN 技術
- 第 2 部分:TensorFlow 2.00 Alpha 中的監督和無監督學習
- 四、TensorFlow 2 和監督機器學習
- 五、TensorFlow 2 和無監督學習
- 第 3 部分:TensorFlow 2.00 Alpha 的神經網絡應用
- 六、使用 TensorFlow 2 識別圖像
- 七、TensorFlow 2 和神經風格遷移
- 八、TensorFlow 2 和循環神經網絡
- 九、TensorFlow 估計器和 TensorFlow HUB
- 十、從 tf1.12 轉換為 tf2
- TensorFlow 入門
- 零、前言
- 一、TensorFlow 基本概念
- 二、TensorFlow 數學運算
- 三、機器學習入門
- 四、神經網絡簡介
- 五、深度學習
- 六、TensorFlow GPU 編程和服務
- TensorFlow 卷積神經網絡實用指南
- 零、前言
- 一、TensorFlow 的設置和介紹
- 二、深度學習和卷積神經網絡
- 三、TensorFlow 中的圖像分類
- 四、目標檢測與分割
- 五、VGG,Inception,ResNet 和 MobileNets
- 六、自編碼器,變分自編碼器和生成對抗網絡
- 七、遷移學習
- 八、機器學習最佳實踐和故障排除
- 九、大規模訓練
- 十、參考文獻