
# 三、學習
## 聚類和 KMeans
我們現在冒險進入我們的第一個應用,即使用 k-means 算法進行聚類。 聚類是一種數據挖掘練習,我們獲取大量數據并找到彼此相似的點的分組。 K-means 是一種非常善于在許多類型的數據集中查找簇的算法。
對于簇和 k-means的 更多信息,請參閱 [k-means 算法的 scikit-learn 文檔](http://scikit-learn.org/stable/modules/clustering.html#k-means)或觀看[此視頻](https://www.youtube.com/embed/_aWzGGNrcic)。
### 生成樣本
首先,我們需要生成一些樣本。 我們可以隨機生成樣本,但這可能會給我們提供非常稀疏的點,或者只是一個大分組 - 對于聚類來說并不是非常令人興奮。
相反,我們將從生成三個質心開始,然后在該點周圍隨機選擇(具有正態分布)。 首先,這是一個執行此操作的方法
```py
import tensorflow as tf
import numpy as np
def create_samples(n_clusters, n_samples_per_cluster, n_features, embiggen_factor, seed):
np.random.seed(seed)
slices = []
centroids = []
# 為每個簇創建樣本
for i in range(n_clusters):
samples = tf.random_normal((n_samples_per_cluster, n_features),
mean=0.0, stddev=5.0, dtype=tf.float32, seed=seed, name="cluster_{}".format(i))
current_centroid = (np.random.random((1, n_features)) * embiggen_factor) - (embiggen_factor/2)
centroids.append(current_centroid)
samples += current_centroid
slices.append(samples)
# 創建一個大的“樣本”數據集
samples = tf.concat(slices, 0, name='samples')
centroids = tf.concat(centroids, 0, name='centroids')
return centroids, samples
```
這種方法的工作方式是隨機創建`n_clusters`個不同的質心(使用`np.random.random((1, n_features))`)并將它們用作`tf.random_normal`的質心。 `tf.random_normal`函數生成正態分布的隨機值,然后我們將其添加到當前質心。 這會在該形心周圍創建一些點。 然后我們記錄質心(`centroids.append`)和生成的樣本(`slices.append(samples)`)。 最后,我們使用`tf.concat`創建“一個大樣本列表”,并使用`tf.concat`將質心轉換為 TensorFlow 變量。
將`create_samples`方法保存在名為`functions.py`的文件中,允許我們為這個(以及下一個!)課程,將這些方法導入到我們的腳本中。 創建一個名為`generate_samples.py`的新文件,其中包含以下代碼:
```py
import tensorflow as tf
import numpy as np
from functions import create_samples
n_features = 2
n_clusters = 3
n_samples_per_cluster = 500
seed = 700
embiggen_factor = 70
np.random.seed(seed)
centroids, samples = create_samples(n_clusters, n_samples_per_cluster, n_features, embiggen_factor, seed)
model = tf.global_variables_initializer()
with tf.Session() as session:
sample_values = session.run(samples)
centroid_values = session.run(centroids)
```
這只是設置了簇和特征的數量(我建議將特征的數量保持為 2,以便我們以后可以可視化它們),以及要生成的樣本數。 增加`embiggen_factor`將增加簇的“散度”或大小。 我在這里選擇了一個提供良好學習機會的值,因為它可以生成視覺上可識別的集群。
為了使結果可視化,我們使用`matplotlib`創建繪圖函數。 將此代碼添加到`functions.py`:
```py
def plot_clusters(all_samples, centroids, n_samples_per_cluster):
import matplotlib.pyplot as plt
# 繪制出不同的簇
# 為每個簇選擇不同的顏色
colour = plt.cm.rainbow(np.linspace(0,1,len(centroids)))
for i, centroid in enumerate(centroids):
# 為給定簇抓取樣本,并用新顏色繪制出來
samples = all_samples[i*n_samples_per_cluster:(i+1)*n_samples_per_cluster]
plt.scatter(samples[:,0], samples[:,1], c=colour[i])
# 還繪制質心
plt.plot(centroid[0], centroid[1], markersize=35, marker="x", color='k', mew=10)
plt.plot(centroid[0], centroid[1], markersize=30, marker="x", color='m', mew=5)
plt.show()
```
所有這些代碼都是使用不同的顏色繪制每個簇的樣本,并在質心位置創建一個大的紅色`X`。 質心提供為參數,稍后會很方便。
更新`generate_samples.py`,通過將`import plot_clusters`添加到文件頂部來導入此函數。 然后,將這行代碼添加到底部:
```py
plot_clusters(sample_values, centroid_values, n_samples_per_cluster)
```
運行`generate_samples.py`現在應該提供以下繪圖:
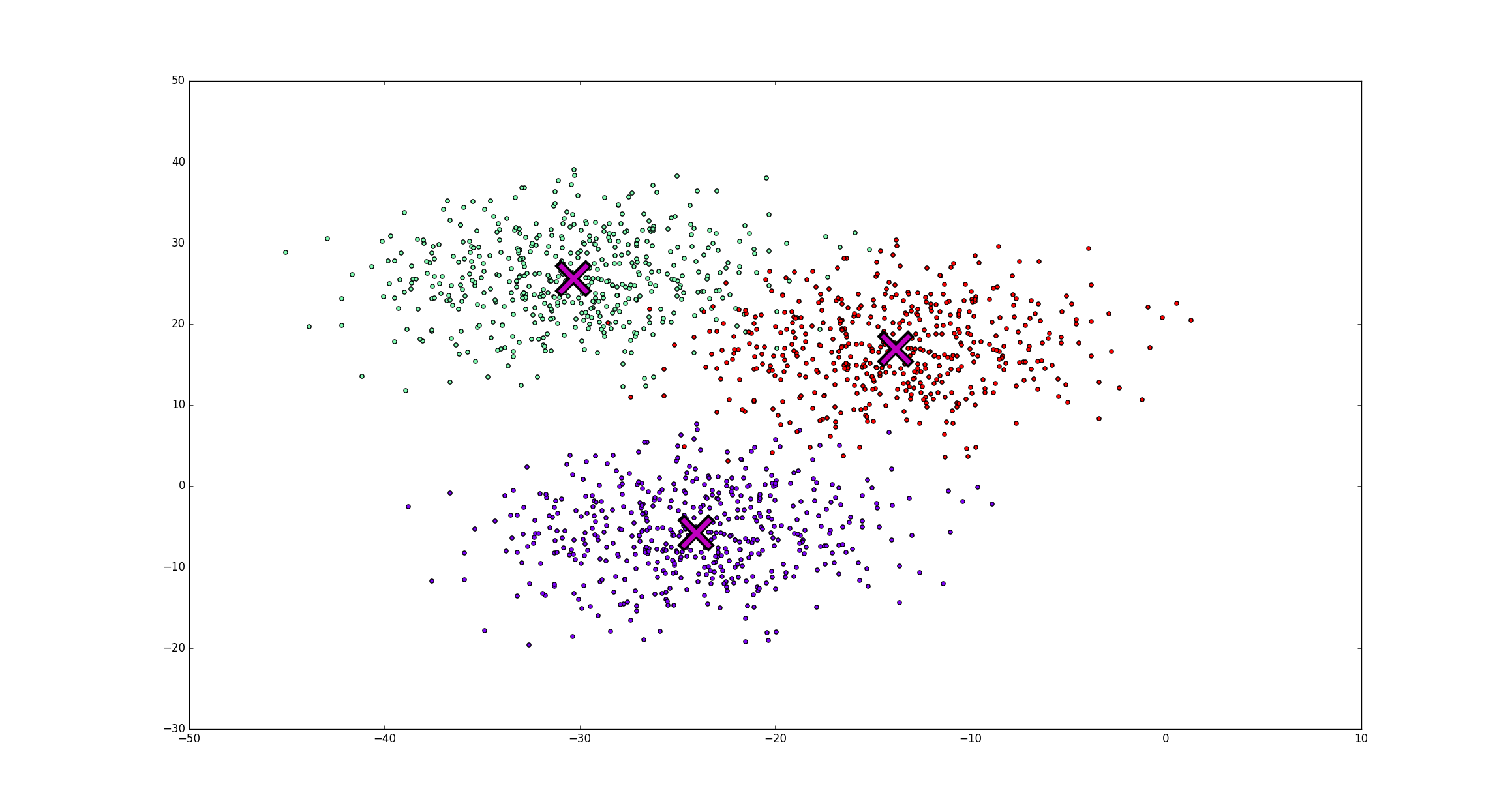
### 初始化
k-means 算法從初始質心的選擇開始,初始質心只是數據中實際質心的隨機猜測。 以下函數將從數據集中隨機選擇多個樣本作為此初始猜測:
```py
def choose_random_centroids(samples, n_clusters):
# 第 0 步:初始化:選擇 n_clusters 個隨機點
n_samples = tf.shape(samples)[0]
random_indices = tf.random_shuffle(tf.range(0, n_samples))
begin = [0,]
size = [n_clusters,]
size[0] = n_clusters
centroid_indices = tf.slice(random_indices, begin, size)
initial_centroids = tf.gather(samples, centroid_indices)
return initial_centroids
```
這段代碼首先為每個樣本創建一個索引(使用`tf.range(0, n_samples)`,然后隨機打亂它。從那里,我們使用`tf.slice`選擇固定數量(`n_clusters`)的索引。這些索引與我們的初始質心相關,然后使用`tf.gather`組合在一起形成我們的初始質心數組。
將這個新的`choose_random_centorids`函數添加到`functions.py`中,并創建一個新腳本(或更新前一個腳本),寫入以下內容:
```py
import tensorflow as tf
import numpy as np
from functions import create_samples, choose_random_centroids, plot_clusters
n_features = 2
n_clusters = 3
n_samples_per_cluster = 500
seed = 700
embiggen_factor = 70
centroids, samples = create_samples(n_clusters, n_samples_per_cluster, n_features, embiggen_factor, seed)
initial_centroids = choose_random_centroids(samples, n_clusters)
model = tf.global_variables_initializer()
with tf.Session() as session:
sample_values = session.run(samples)
updated_centroid_value = session.run(initial_centroids)
plot_clusters(sample_values, updated_centroid_value, n_samples_per_cluster)
```
這里的主要變化是我們為這些初始質心創建變量,并在會話中計算其值。 然后,我們將初始猜測繪制到`plot_cluster`,而不是用于生成數據的實際質心。
運行此操作會將得到與上面類似的圖像,但質心將處于隨機位置。 嘗試運行此腳本幾次,注意質心移動了很多。
### 更新質心
在開始對質心位置進行一些猜測之后,然后 k-means 算法基于數據更新那些猜測。 該過程是為每個樣本分配一個簇號,表示它最接近的質心。 之后,將質心更新為分配給該簇的所有樣本的平均值。 以下代碼處理分配到最近的簇的步驟:
```py
def assign_to_nearest(samples, centroids):
# 為每個樣本查找最近的質心
# START from http://esciencegroup.com/2016/01/05/an-encounter-with-googles-tensorflow/
expanded_vectors = tf.expand_dims(samples, 0)
expanded_centroids = tf.expand_dims(centroids, 1)
distances = tf.reduce_sum( tf.square(
tf.subtract(expanded_vectors, expanded_centroids)), 2)
mins = tf.argmin(distances, 0)
# END from http://esciencegroup.com/2016/01/05/an-encounter-with-googles-tensorflow/
nearest_indices = mins
return nearest_indices
```
請注意,我從[這個頁面](http://esciencegroup.com/2016/01/05/an-encounter-with-googles-tensorflow/)借用了一些代碼,這些代碼具有不同類型的 k-means 算法,以及許多其他有用的信息。
這種方法的工作方式是計算每個樣本和每個質心之間的距離,這通過`distances =`那行來實現。 這里的距離計算是歐幾里德距離。 這里重要的一點是`tf.subtract`會自動擴展兩個參數的大小。 這意味著將我們作為矩陣的樣本,和作為列向量的質心將在它們之間產生成對減法。 為了實現,我們使用`tf.expand_dims`為樣本和質心創建一個額外的維度,強制`tf.subtract`的這種行為。
下一步代碼處理質心更新:
```py
def update_centroids(samples, nearest_indices, n_clusters):
# 將質心更新為與其相關的所有樣本的平均值。
nearest_indices = tf.to_int32(nearest_indices)
partitions = tf.dynamic_partition(samples, nearest_indices, n_clusters)
new_centroids = tf.concat([tf.expand_dims(tf.reduce_mean(partition, 0), 0) for partition in partitions], 0)
return new_centroids
```
此代碼選取每個樣本的最近索引,并使用`tf.dynamic_partition`將這些索引分到單獨的組中。 從這里開始,我們在一個組中使用`tf.reduce_mean`來查找該組的平均值,從而形成新的質心。 我們只需將它們連接起來形成我們的新質心。
現在我們有了這個部分,我們可以將這些調用添加到我們的腳本中(或者創建一個新腳本):
```py
import tensorflow as tf
import numpy as np
from functions import *
n_features = 2
n_clusters = 3
n_samples_per_cluster = 500
seed = 700
embiggen_factor = 70
data_centroids, samples = create_samples(n_clusters, n_samples_per_cluster, n_features, embiggen_factor, seed)
initial_centroids = choose_random_centroids(samples, n_clusters)
nearest_indices = assign_to_nearest(samples, initial_centroids)
updated_centroids = update_centroids(samples, nearest_indices, n_clusters)
model = tf.global_variables_initializer()
with tf.Session() as session:
sample_values = session.run(samples)
updated_centroid_value = session.run(updated_centroids)
print(updated_centroid_value)
plot_clusters(sample_values, updated_centroid_value, n_samples_per_cluster)
```
此代碼將:
+ 從初始質心生成樣本
+ 隨機選擇初始質心
+ 關聯每個樣本和最近的質心
+ 將每個質心更新為與關聯的樣本的平均值
這是 k-means 的單次迭代! 我鼓勵你們練習一下,把它變成一個迭代版本。
1)傳遞給`generate_samples`的種子選項可確保每次運行腳本時,“隨機”生成的樣本都是一致的。 我們沒有將種子傳遞給`choose_random_centroids`函數,這意味著每次運行腳本時這些初始質心都不同。 更新腳本來為隨機質心包含新的種子。
2)迭代地執行 k 均值算法,其中來自之前迭代的更新的質心用于分配簇,然后用于更新質心,等等。 換句話說,算法交替調用`assign_to_nearest`和`update_centroids`。 在停止之前,更新代碼來執行此迭代 10 次。 你會發現,隨著 k-means 的更多迭代,得到的質心平均上更接近。 (對于那些對 k-means 有經驗的人,未來的教程將研究收斂函數和其他停止標準。)
## 訓練和收斂
大多數人工智能和機器學習的關鍵組成部分是循環,即系統在多次訓練迭代中得到改善。 以這種方式訓練的一種非常簡單的方法,就是在`for`循環中執行更新。 我們在第 2 課中看到了這種方式的一個例子:
```py
import tensorflow as tf
x = tf.Variable(0, name='x')
model = tf.global_variables_initializer()
with tf.Session() as session:
for i in range(5):
session.run(model)
x = x + 1
print(session.run(x))
```
我們可以改變此工作流,使用變量來收斂循環,如下所示:
```py
import tensorflow as tf
x = tf.Variable(0., name='x')
threshold = tf.constant(5.)
model = tf.global_variables_initializer()
with tf.Session() as session:
session.run(model)
while session.run(tf.less(x, threshold)):
x = x + 1
x_value = session.run(x)
print(x_value)
```
這里的主要變化是,循環現在是一個`while`循環,測試(`tf.less`用于小于測試)為真時繼續循環。 在這里,我們測試`x`是否小于給定閾值(存儲在常量中),如果是,我們繼續循環。
### 梯度下降
任何機器學習庫都必須具有梯度下降算法。 我認為這是一個定律。 無論如何,Tensorflow 在主題上有一些變化,它們可以直接使用。
梯度下降是一種學習算法,嘗試最小化某些誤差。 你問哪個誤差? 嗯,這取決于我們,雖然有一些常用的方法。
讓我們從一個基本的例子開始:
```py
import tensorflow as tf
import numpy as np
# x 和 y 是我們的訓練數據的占位符
x = tf.placeholder("float")
y = tf.placeholder("float")
# w 是存儲我們的值的變量。 它使用“猜測”來初始化
# w[0] 是我們方程中的“a”,w[1] 是“b”
w = tf.Variable([1.0, 2.0], name="w")
# 我們的模型是 y = a*x + b
y_model = tf.multiply(x, w[0]) + w[1]
# 我們的誤差定義為差異的平方
error = tf.square(y - y_model)
# GradientDescentOptimizer 完成繁重的工作
train_op = tf.train.GradientDescentOptimizer(0.01).minimize(error)
# TensorFlow 常規 - 初始化值,創建會話并運行模型
model = tf.global_variables_initializer()
with tf.Session() as session:
session.run(model)
for i in range(1000):
x_value = np.random.rand()
y_value = x_value * 2 + 6
session.run(train_op, feed_dict={x: x_value, y: y_value})
w_value = session.run(w)
print("Predicted model: {a:.3f}x + {b:.3f}".format(a=w_value[0], b=w_value[1]))
```
這里的主要興趣點是`train_op = tf.train.GradientDescentOptimizer(0.01).minimize(error)`,其中定義了訓練步長。 它旨在最小化誤差變量的值,該變量先前被定義為差的平方(常見的誤差函數)。 0.01 是嘗試學習更好的值所需的步長。
### 其它優化器
TensorFlow 有一整套優化器,并且你也可以定義自己的優化器(如果你對這類事情感興趣)。 如何使用它們的 API,請參閱[此頁面](https://tensorflow.google.cn/versions/master/api_docs/python/train.html#optimizers)。 列表如下:
+ `GradientDescentOptimizer`
+ `AdagradOptimizer`
+ `MomentumOptimizer`
+ `AdamOptimizer`
+ `FtrlOptimizer`
+ `RMSPropOptimizer`
其他優化方法可能會出現在 TensorFlow 的未來版本或第三方代碼中。 也就是說,上述優化對于大多數深度學習技術來說已經足夠了。 如果你不確定要使用哪一個,請使用`AdamOptimizer`,除非失敗。
> 譯者注:原文推薦隨機梯度優化器,在所有優化器里是最爛的,已更改。
這里一個重要的注意事項是,我們只優化了一個值,但該值可以是一個數組。 這就是為什么我們使用`w`作為變量,而不是兩個單獨的變量`a`和`b`。
### 繪制誤差
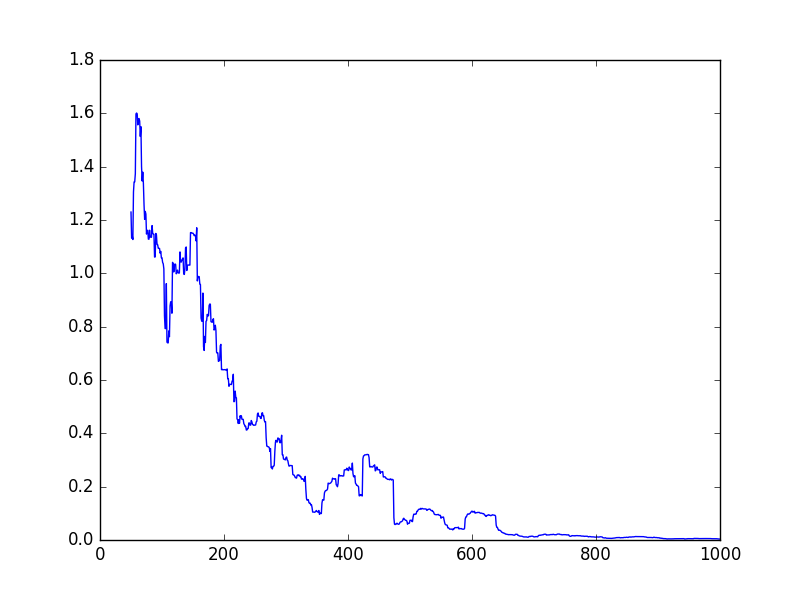
這個代碼是上面的一個小改動。 首先,我們創建一個列表來存儲誤差。然后,在循環內部,我們顯式地計算`train_op`和誤差。 我們在一行中執行此操作,因此誤差僅計算一次。 如果我們在單獨的行中這樣做,它將計算誤差,然后是訓練步驟,并且在這樣做時,它將需要重新計算誤差。
下面我把代碼放在上一個程序的`tf.global_variables_initializer()`行下面 - 這一行上面的所有內容都是一樣的。
```py
errors = []
with tf.Session() as session:
session.run(model)
for i in range(1000):
x_train = tf.random_normal((1,), mean=5, stddev=2.0)
y_train = x_train * 2 + 6
x_value, y_value = session.run([x_train, y_train])
_, error_value = session.run([train_op, error], feed_dict={x: x_value, y: y_value})
errors.append(error_value)
w_value = session.run(w)
print("Predicted model: {a:.3f}x + {b:.3f}".format(a=w_value[0], b=w_value[1]))
import matplotlib.pyplot as plt
plt.plot([np.mean(errors[i-50:i]) for i in range(len(errors))])
plt.show()
plt.savefig("errors.png")
```
你可能已經注意到我在這里采用窗口平均值 - 使用`np.mean(errors[i-50:i])`而不是僅使用`errors[i]`。 這樣做的原因是我們只在循環中測試一次,所以雖然誤差會減小,但它會反彈很多。 采用這個窗口平均值可以平滑一點,但正如你在上面所看到的,它仍然會跳躍。
1)創建第 6 課中的 k-means 示例的收斂函數,如果舊質心與新質心之間的距離小于給定的`epsilon`值,則停止訓練。
2)嘗試從梯度下降示例(`w`)中分離`a`和`b`值。
3)我們的例子一次只訓練一個示例,這是低效的。 擴展它來一次使用多個(例如 50 個)訓練樣本來學習。
## TFLearn
> 已更新到最新的 TFLearn API。
這些教程主要關注 TensorFlow 的機制,但真正的用例是機器學習。 TensorFlow 有許多用于構建機器學習模型的方法,其中許多可以在官方 API 頁面上找到。 這些函數允許你從頭開始構建模型,包括自定義層面,例如如何構建神經網絡中的層。
在本教程中,我們將查看 TensorFlow Learn,它是名為`skflow`的軟件包的新名稱。 TensorFlow Learn(以下簡稱:TFLearn)是一個機器學習包裝器,基于 scikit-learn API,允許你輕松執行數據挖掘。 這意味著什么? 讓我們一步一步地完成它:
### 機器學習
機器學習是一種概念,構建從數據中學習的算法,以便對新數據執行操作。 在這種情況下,這意味著我們有一些輸入的訓練數據和預期結果 - 訓練目標。 我們將看看著名的數字數據集,這是一堆手繪數字的圖像。 我們的輸入訓練數據是幾千個這些圖像,我們的訓練目標是預期的數字。
任務是學習一個模型,可以回答“這是什么數字?”,對于這樣的輸入:
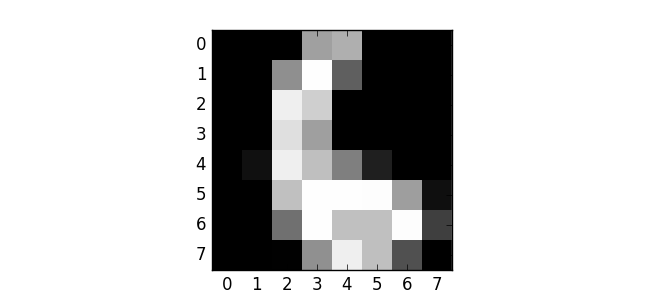
這是一個分類任務,是數據挖掘最常見的應用之一。 還有一些稱為回歸和聚類的變體(以及許多其他變體),但在本課中我們不會涉及它們。
如果你想了解數據挖掘的更多信息,請查看我的書“[Python 數據挖掘](http://www.amazon.com/Learning-Mining-Python-Robert-Layton/dp/1784396052)”。
### Scikit-Learn API
Scikit-learn 是一個用于數據挖掘和分析的 Python 包,它非常受歡迎。 這是因為它廣泛支持不同的算法,令人驚嘆的文檔,以及龐大而活躍的社區。 其他一個因素是它的一致接口,它的 API,允許人們構建可以使用 scikit-learn 輔助函數訓練的模型,并允許人們非常容易地測試不同的模型。
我們來看看 scikit-learn 的 API,但首先我們需要一些數據。 以下代碼加載了一組可以使用`matplotlib.pyplot`顯示的數字圖像:
```py
from sklearn.datasets import load_digits
from matplotlib import pyplot as plt
digits = load_digits()
```
我們可以使用`pyplot.imshow`顯示其中一個圖像。 在這里,我設置`interpolation ='none'`來完全按原樣查看數據,但是如果你刪除這個屬性,它會變得更清晰(也嘗試減小數字大小)。
```py
fig = plt.figure(figsize=(3, 3))
plt.imshow(digits['images'][66], cmap="gray", interpolation='none')
plt.show()
```
在 scikit-learn 中,我們可以構建一個簡單的分類器,訓練它,然后使用它來預測圖像的數字,只需使用四行代碼:
```py
from sklearn import svm
classifier = svm.SVC(gamma=0.001)
classifier.fit(digits.data, digits.target)
predicted = classifier.predict(digits.data)
```
第一行只是導入支持向量機模型,這是一種流行的機器學習方法。
第二行構建“空白”分類器,`gamma`設置為 0.001。
第三行使用數據來訓練模型。 在這一行(這是該代碼的大部分“工作”)中,調整 SVM 模型的內部狀態來擬合訓練數據。 我們還傳遞`digits.data`,因為這是一個展開的數組,是該算法的可接受輸入。
最后,最后一行使用這個訓練好的分類器來預測某些數據的類,在這種情況下再次是原始數據集。
要了解這是多么準確,我們可以使用 NumPy 計算準確度:
```py
import numpy as np
print(np.mean(digits.target == predicted))
```
結果非常令人印象深刻(近乎完美),但這些有點誤導。 在數據挖掘中,你永遠不應該在用于訓練的相同數據上評估你的模型。 潛在的問題被稱為“過擬合”,其中模型準確地學習了訓練數據所需的內容,但是無法很好地預測新的沒見過的數據。 為解決這個問題,我們需要拆分我們的訓練和測試數據:
```py
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target)
```
結果仍然非常好,大約 98%,但這個數據集在數據挖掘中是眾所周知的,其特征已有詳細記錄。 無論如何,我們現在知道我們要做什么,讓我們在 TFLearn 中實現它!
### TFLearn
TensorFlow Learn 接口距離 scikit-learn 的接口只有一小步之遙:
```py
from tensorflow.contrib import learn
n_classes = len(set(y_train))
classifier = learn.LinearClassifier(feature_columns=[tf.contrib.layers.real_valued_column("", dimension=X_train.shape[1])],
n_classes=n_classes)
classifier.fit(X_train, y_train, steps=10)
y_pred = classifier.predict(X_test)
```
唯一真正的變化是`import`語句和模型,它來自不同的可用算法列表。 一個區別是分類器需要知道它將預測多少個類,可以使用`len(set(y_train))`找到,或者換句話說,訓練數據中有多少個唯一值。
另一個區別是,需要告知分類器預期的特征類型。 對于這個例子,我們有真正重要的連續特征,所以我們可以簡單地指定`feature_columns`值(它需要在列表中)。 如果你使用類別特征,則需要單獨說明。 這方面的更多信息,請查看 [TFLearn 示例的文檔](https://www.tensorflow.org/get_started/input_fn)。
可以像以前一樣評估結果,來計算準確性,但 scikit-learn 有 classification_report,它提供了更深入的了解:
```py
from sklearn import metrics
print(metrics.classification_report(y_true=y_test, y_pred=y_pred))
```
結果顯示每個類的召回率和精度,以及總體值和 f 度量。這些分數比準確性更可靠,更多信息請參閱維基百科上的[此頁面](https://en.wikipedia.org/wiki/F1_score)。
這是 TFLearn 的高級概述。你可以定義自定義分類器,你將在練習 3 中看到它們,并將分類器組合到流水線中(對此的支持很小,但正在改進)。該軟件包有可能成為工業和學術界廣泛使用的數據挖掘軟件包。
1)將分類器更改為`DNNClassifier`并重新運行。隨意告訴所有朋友你現在使用深度學習來做數據分析。
2)`DNNClassifier`的默認參數是好的,但不完美。嘗試更改參數來獲得更高的分數。
3)從 TFLearn 的文檔中查看[此示例](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/learn/mnist.py)并下載 [CIFAR 10](https://www.cs.toronto.edu/~kriz/cifar.html) 數據集。構建一個使用卷積神經網絡預測圖像的分類器。你可以使用此代碼加載數據:
```py
def load_cifar(file):
import pickle
import numpy as np
with open(file, 'rb') as inf:
cifar = pickle.load(inf, encoding='latin1')
data = cifar['data'].reshape((10000, 3, 32, 32))
data = np.rollaxis(data, 3, 1)
data = np.rollaxis(data, 3, 1)
y = np.array(cifar['labels'])
# 最開始只需 2 和 9
# 如果要構建大型模型,請刪除這些行
mask = (y == 2) | (y == 9)
data = data[mask]
y = y[mask]
return data, y
```
- TensorFlow 1.x 深度學習秘籍
- 零、前言
- 一、TensorFlow 簡介
- 二、回歸
- 三、神經網絡:感知器
- 四、卷積神經網絡
- 五、高級卷積神經網絡
- 六、循環神經網絡
- 七、無監督學習
- 八、自編碼器
- 九、強化學習
- 十、移動計算
- 十一、生成模型和 CapsNet
- 十二、分布式 TensorFlow 和云深度學習
- 十三、AutoML 和學習如何學習(元學習)
- 十四、TensorFlow 處理單元
- 使用 TensorFlow 構建機器學習項目中文版
- 一、探索和轉換數據
- 二、聚類
- 三、線性回歸
- 四、邏輯回歸
- 五、簡單的前饋神經網絡
- 六、卷積神經網絡
- 七、循環神經網絡和 LSTM
- 八、深度神經網絡
- 九、大規模運行模型 -- GPU 和服務
- 十、庫安裝和其他提示
- TensorFlow 深度學習中文第二版
- 一、人工神經網絡
- 二、TensorFlow v1.6 的新功能是什么?
- 三、實現前饋神經網絡
- 四、CNN 實戰
- 五、使用 TensorFlow 實現自編碼器
- 六、RNN 和梯度消失或爆炸問題
- 七、TensorFlow GPU 配置
- 八、TFLearn
- 九、使用協同過濾的電影推薦
- 十、OpenAI Gym
- TensorFlow 深度學習實戰指南中文版
- 一、入門
- 二、深度神經網絡
- 三、卷積神經網絡
- 四、循環神經網絡介紹
- 五、總結
- 精通 TensorFlow 1.x
- 一、TensorFlow 101
- 二、TensorFlow 的高級庫
- 三、Keras 101
- 四、TensorFlow 中的經典機器學習
- 五、TensorFlow 和 Keras 中的神經網絡和 MLP
- 六、TensorFlow 和 Keras 中的 RNN
- 七、TensorFlow 和 Keras 中的用于時間序列數據的 RNN
- 八、TensorFlow 和 Keras 中的用于文本數據的 RNN
- 九、TensorFlow 和 Keras 中的 CNN
- 十、TensorFlow 和 Keras 中的自編碼器
- 十一、TF 服務:生產中的 TensorFlow 模型
- 十二、遷移學習和預訓練模型
- 十三、深度強化學習
- 十四、生成對抗網絡
- 十五、TensorFlow 集群的分布式模型
- 十六、移動和嵌入式平臺上的 TensorFlow 模型
- 十七、R 中的 TensorFlow 和 Keras
- 十八、調試 TensorFlow 模型
- 十九、張量處理單元
- TensorFlow 機器學習秘籍中文第二版
- 一、TensorFlow 入門
- 二、TensorFlow 的方式
- 三、線性回歸
- 四、支持向量機
- 五、最近鄰方法
- 六、神經網絡
- 七、自然語言處理
- 八、卷積神經網絡
- 九、循環神經網絡
- 十、將 TensorFlow 投入生產
- 十一、更多 TensorFlow
- 與 TensorFlow 的初次接觸
- 前言
- 1.?TensorFlow 基礎知識
- 2. TensorFlow 中的線性回歸
- 3. TensorFlow 中的聚類
- 4. TensorFlow 中的單層神經網絡
- 5. TensorFlow 中的多層神經網絡
- 6. 并行
- 后記
- TensorFlow 學習指南
- 一、基礎
- 二、線性模型
- 三、學習
- 四、分布式
- TensorFlow Rager 教程
- 一、如何使用 TensorFlow Eager 構建簡單的神經網絡
- 二、在 Eager 模式中使用指標
- 三、如何保存和恢復訓練模型
- 四、文本序列到 TFRecords
- 五、如何將原始圖片數據轉換為 TFRecords
- 六、如何使用 TensorFlow Eager 從 TFRecords 批量讀取數據
- 七、使用 TensorFlow Eager 構建用于情感識別的卷積神經網絡(CNN)
- 八、用于 TensorFlow Eager 序列分類的動態循壞神經網絡
- 九、用于 TensorFlow Eager 時間序列回歸的遞歸神經網絡
- TensorFlow 高效編程
- 圖嵌入綜述:問題,技術與應用
- 一、引言
- 三、圖嵌入的問題設定
- 四、圖嵌入技術
- 基于邊重構的優化問題
- 應用
- 基于深度學習的推薦系統:綜述和新視角
- 引言
- 基于深度學習的推薦:最先進的技術
- 基于卷積神經網絡的推薦
- 關于卷積神經網絡我們理解了什么
- 第1章概論
- 第2章多層網絡
- 2.1.4生成對抗網絡
- 2.2.1最近ConvNets演變中的關鍵架構
- 2.2.2走向ConvNet不變性
- 2.3時空卷積網絡
- 第3章了解ConvNets構建塊
- 3.2整改
- 3.3規范化
- 3.4匯集
- 第四章現狀
- 4.2打開問題
- 參考
- 機器學習超級復習筆記
- Python 遷移學習實用指南
- 零、前言
- 一、機器學習基礎
- 二、深度學習基礎
- 三、了解深度學習架構
- 四、遷移學習基礎
- 五、釋放遷移學習的力量
- 六、圖像識別與分類
- 七、文本文件分類
- 八、音頻事件識別與分類
- 九、DeepDream
- 十、自動圖像字幕生成器
- 十一、圖像著色
- 面向計算機視覺的深度學習
- 零、前言
- 一、入門
- 二、圖像分類
- 三、圖像檢索
- 四、對象檢測
- 五、語義分割
- 六、相似性學習
- 七、圖像字幕
- 八、生成模型
- 九、視頻分類
- 十、部署
- 深度學習快速參考
- 零、前言
- 一、深度學習的基礎
- 二、使用深度學習解決回歸問題
- 三、使用 TensorBoard 監控網絡訓練
- 四、使用深度學習解決二分類問題
- 五、使用 Keras 解決多分類問題
- 六、超參數優化
- 七、從頭開始訓練 CNN
- 八、將預訓練的 CNN 用于遷移學習
- 九、從頭開始訓練 RNN
- 十、使用詞嵌入從頭開始訓練 LSTM
- 十一、訓練 Seq2Seq 模型
- 十二、深度強化學習
- 十三、生成對抗網絡
- TensorFlow 2.0 快速入門指南
- 零、前言
- 第 1 部分:TensorFlow 2.00 Alpha 簡介
- 一、TensorFlow 2 簡介
- 二、Keras:TensorFlow 2 的高級 API
- 三、TensorFlow 2 和 ANN 技術
- 第 2 部分:TensorFlow 2.00 Alpha 中的監督和無監督學習
- 四、TensorFlow 2 和監督機器學習
- 五、TensorFlow 2 和無監督學習
- 第 3 部分:TensorFlow 2.00 Alpha 的神經網絡應用
- 六、使用 TensorFlow 2 識別圖像
- 七、TensorFlow 2 和神經風格遷移
- 八、TensorFlow 2 和循環神經網絡
- 九、TensorFlow 估計器和 TensorFlow HUB
- 十、從 tf1.12 轉換為 tf2
- TensorFlow 入門
- 零、前言
- 一、TensorFlow 基本概念
- 二、TensorFlow 數學運算
- 三、機器學習入門
- 四、神經網絡簡介
- 五、深度學習
- 六、TensorFlow GPU 編程和服務
- TensorFlow 卷積神經網絡實用指南
- 零、前言
- 一、TensorFlow 的設置和介紹
- 二、深度學習和卷積神經網絡
- 三、TensorFlow 中的圖像分類
- 四、目標檢測與分割
- 五、VGG,Inception,ResNet 和 MobileNets
- 六、自編碼器,變分自編碼器和生成對抗網絡
- 七、遷移學習
- 八、機器學習最佳實踐和故障排除
- 九、大規模訓練
- 十、參考文獻