
# 西法的刷題秘籍】一次搞定前綴和
# 【西法的刷題秘籍】一次搞定前綴和
我花了幾天時間,從力扣中精選了五道相同思想的題目,來幫助大家解套,如果覺得文章對你有用,記得點贊分享,讓我看到你的認可,有動力繼續做下去。
- [467. 環繞字符串中唯一的子字符串](https://leetcode-cn.com/problems/unique-substrings-in-wraparound-string/ "467. 環繞字符串中唯一的子字符串")(中等)
- [795. 區間子數組個數](https://leetcode-cn.com/problems/number-of-subarrays-with-bounded-maximum/ "795. 區間子數組個數")(中等)
- [904. 水果成籃](https://leetcode-cn.com/problems/fruit-into-baskets/ "904. 水果成籃")(中等)
- [992. K 個不同整數的子數組](https://leetcode-cn.com/problems/subarrays-with-k-different-integers/ "992. K 個不同整數的子數組")(困難)
- [1109. 航班預訂統計](https://leetcode-cn.com/problems/corporate-flight-bookings/ "1109. 航班預訂統計")(中等)
前四道題都是滑動窗口的子類型,我們知道滑動窗口適合在題目要求連續的情況下使用, 而[前綴和](https://oi-wiki.org/basic/prefix-sum/ "前綴和")也是如此。二者在連續問題中,對于**優化時間復雜度**有著很重要的意義。 因此如果一道題你可以用暴力解決出來,而且題目恰好有連續的限制, 那么滑動窗口和前綴和等技巧就應該被想到。
除了這幾道題, 還有很多題目都是類似的套路, 大家可以在學習過程中進行體會。今天我們就來一起學習一下。
## 前菜
我們從一個簡單的問題入手,識別一下這種題的基本形式和套路,為之后的四道題打基礎。當你了解了這個套路之后, 之后做這種題就可以直接套。
需要注意的是這四道題的前置知識都是 `滑動窗口`, 不熟悉的同學可以先看下我之前寫的 [滑動窗口專題(思路 + 模板)](https://github.com/azl397985856/leetcode/blob/master/thinkings/slide-window.md "滑動窗口專題(思路 + 模板)")
### 母題 0
有 N 個的正整數放到數組 A 里,現在要求一個新的數組 B,新數組的第 i 個數 B\[i\]是原數組 A 第 0 到第 i 個數的和。
這道題可以使用前綴和來解決。 前綴和是一種重要的預處理,能大大降低查詢的時間復雜度。我們可以簡單理解為“數列的前 n 項的和”。這個概念其實很容易理解,即一個數組中,第 n 位存儲的是數組前 n 個數字的和。
對 \[1,2,3,4,5,6\] 來說,其前綴和可以是 pre=\[1,3,6,10,15,21\]。我們可以使用公式 pre\[??\]=pre\[???1\]+nums\[??\]得到每一位前綴和的值,從而通過前綴和進行相應的計算和解題。其實前綴和的概念很簡單,但困難的是如何在題目中使用前綴和以及如何使用前綴和的關系來進行解題。
### 母題 1
如果讓你求一個數組的連續子數組總個數,你會如何求?其中連續指的是數組的索引連續。 比如 \[1,3,4\],其連續子數組有:`[1], [3], [4], [1,3], [3,4] , [1,3,4]`,你需要返回 6。
一種思路是總的連續子數組個數等于:**以索引為 0 結尾的子數組個數 + 以索引為 1 結尾的子數組個數 + ... + 以索引為 n - 1 結尾的子數組個數**,這無疑是完備的。
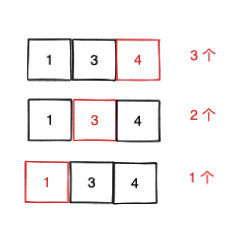
同時**利用母題 0 的前綴和思路, 邊遍歷邊求和。**
參考代碼(JS):
```
<pre class="calibre18">```
<span class="hljs-function"><span class="hljs-keyword">function</span> <span class="hljs-title">countSubArray</span>(<span class="hljs-params">nums</span>) </span>{
<span class="hljs-keyword">let</span> ans = <span class="hljs-params">0</span>;
<span class="hljs-keyword">let</span> pre = <span class="hljs-params">0</span>;
<span class="hljs-keyword">for</span> (_ <span class="hljs-keyword">in</span> nums) {
pre += <span class="hljs-params">1</span>;
ans += pre;
}
<span class="hljs-keyword">return</span> ans;
}
```
```
**復雜度分析**
- 時間復雜度:O(N)O(N)O(N),其中 N 為數組長度。
- 空間復雜度:O(1)O(1)O(1)
而由于以索引為 i 結尾的子數組個數就是 i + 1,因此這道題可以直接用等差數列求和公式 `(1 + n) * n / 2`,其中 n 數組長度。
### 母題 2
我繼續修改下題目, 如果讓你求一個數組相鄰差為 1 連續子數組的總個數呢?其實就是**索引差 1 的同時,值也差 1。**
和上面思路類似,無非就是增加差值的判斷。
參考代碼(JS):
```
<pre class="calibre18">```
<span class="hljs-function"><span class="hljs-keyword">function</span> <span class="hljs-title">countSubArray</span>(<span class="hljs-params">nums</span>) </span>{
<span class="hljs-keyword">let</span> ans = <span class="hljs-params">1</span>;
<span class="hljs-keyword">let</span> pre = <span class="hljs-params">1</span>;
<span class="hljs-keyword">for</span> (<span class="hljs-keyword">let</span> i = <span class="hljs-params">1</span>; i < nums.length; i++) {
<span class="hljs-keyword">if</span> (nums[i] - nums[i - <span class="hljs-params">1</span>] == <span class="hljs-params">1</span>) {
pre += <span class="hljs-params">1</span>;
} <span class="hljs-keyword">else</span> {
pre = <span class="hljs-params">0</span>;
}
ans += pre;
}
<span class="hljs-keyword">return</span> ans;
}
```
```
**復雜度分析**
- 時間復雜度:O(N)O(N)O(N),其中 N 為數組長度。
- 空間復雜度:O(1)O(1)O(1)
如果我值差只要大于 1 就行呢?其實改下符號就行了,這不就是求上升子序列個數么?這里不再繼續贅述, 大家可以自己試試。
### 母題 3
我們繼續擴展。
如果我讓你求出不大于 k 的子數組的個數呢?不大于 k 指的是子數組的全部元素都不大于 k。 比如 \[1,3,4\] 子數組有 `[1], [3], [4], [1,3], [3,4] , [1,3,4]`,不大于 3 的子數組有 `[1], [3], [1,3]` ,那么 \[1,3,4\] 不大于 3 的子數組個數就是 3。 實現函數 atMostK(k, nums)。
參考代碼(JS):
```
<pre class="calibre18">```
<span class="hljs-function"><span class="hljs-keyword">function</span> <span class="hljs-title">countSubArray</span>(<span class="hljs-params">k, nums</span>) </span>{
<span class="hljs-keyword">let</span> ans = <span class="hljs-params">0</span>;
<span class="hljs-keyword">let</span> pre = <span class="hljs-params">0</span>;
<span class="hljs-keyword">for</span> (<span class="hljs-keyword">let</span> i = <span class="hljs-params">0</span>; i < nums.length; i++) {
<span class="hljs-keyword">if</span> (nums[i] <= k) {
pre += <span class="hljs-params">1</span>;
} <span class="hljs-keyword">else</span> {
pre = <span class="hljs-params">0</span>;
}
ans += pre;
}
<span class="hljs-keyword">return</span> ans;
}
```
```
**復雜度分析**
- 時間復雜度:O(N)O(N)O(N),其中 N 為數組長度。
- 空間復雜度:O(1)O(1)O(1)
### 母題 4
如果我讓你求出子數組最大值剛好是 k 的子數組的個數呢? 比如 \[1,3,4\] 子數組有 `[1], [3], [4], [1,3], [3,4] , [1,3,4]`,子數組最大值剛好是 3 的子數組有 `[3], [1,3]` ,那么 \[1,3,4\] 子數組最大值剛好是 3 的子數組個數就是 2。實現函數 exactK(k, nums)。
實際上是 exactK 可以直接利用 atMostK,即 atMostK(k) - atMostK(k - 1),原因見下方母題 5 部分。
### 母題 5
如果我讓你求出子數組最大值剛好是 介于 k1 和 k2 的子數組的個數呢?實現函數 betweenK(k1, k2, nums)。
實際上是 betweenK 可以直接利用 atMostK,即 atMostK(k1, nums) - atMostK(k2 - 1, nums),其中 k1 > k2。前提是值是離散的, 比如上面我出的題都是整數。 因此我可以直接 減 1,因為 **1 是兩個整數最小的間隔**。
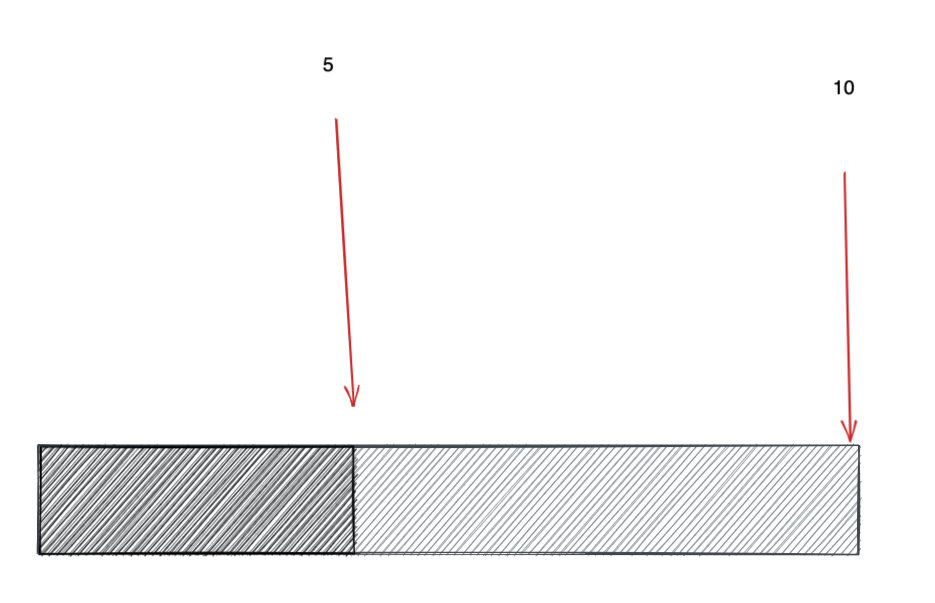
如上,`小于等于 10 的區域`減去 `小于 5 的區域`就是 `大于等于 5 且小于等于 10 的區域`。
注意我說的是小于 5, 不是小于等于 5。 由于整數是離散的,最小間隔是 1。因此小于 5 在這里就等價于 小于等于 4。這就是 betweenK(k1, k2, nums) = atMostK(k1) - atMostK(k2 - 1) 的原因。
因此不難看出 exactK 其實就是 betweenK 的特殊形式。 當 k1 == k2 的時候, betweenK 等價于 exactK。
因此 atMostK 就是靈魂方法,一定要掌握,不明白建議多看幾遍。
有了上面的鋪墊, 我們來看下第一道題。
## 467. 環繞字符串中唯一的子字符串(中等)
### 題目描述
```
<pre class="calibre18">```
把字符串 s 看作是“abcdefghijklmnopqrstuvwxyz”的無限環繞字符串,所以 s 看起來是這樣的:"...zabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcd....".
現在我們有了另一個字符串 p 。你需要的是找出 s 中有多少個唯一的 p 的非空子串,尤其是當你的輸入是字符串 p ,你需要輸出字符串 s 中 p 的不同的非空子串的數目。
注意: p 僅由小寫的英文字母組成,p 的大小可能超過 10000。
示例 1:
輸入: "a"
輸出: 1
解釋: 字符串 S 中只有一個"a"子字符。
示例 2:
輸入: "cac"
輸出: 2
解釋: 字符串 S 中的字符串“cac”只有兩個子串“a”、“c”。.
示例 3:
輸入: "zab"
輸出: 6
解釋: 在字符串 S 中有六個子串“z”、“a”、“b”、“za”、“ab”、“zab”。.
```
```
### 前置知識
- 滑動窗口
### 思路
題目是讓我們找 p 在 s 中出現的非空子串數目,而 s 是固定的一個無限循環字符串。由于 p 的數據范圍是 10^5 ,因此暴力找出所有子串就需要 10^10 次操作了,應該會超時。而且題目很多信息都沒用到,肯定不對。
仔細看下題目發現,這不就是母題 2 的變種么?話不多說, 直接上代碼,看看有多像。
> 為了減少判斷, 我這里用了一個黑科技, p 前面加了個 `^`。
```
<pre class="calibre18">```
<span class="hljs-class"><span class="hljs-keyword">class</span> <span class="hljs-title">Solution</span>:</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">findSubstringInWraproundString</span><span class="hljs-params">(self, p: str)</span> -> int:</span>
p = <span class="hljs-string">'^'</span> + p
w = <span class="hljs-params">1</span>
ans = <span class="hljs-params">0</span>
<span class="hljs-keyword">for</span> i <span class="hljs-keyword">in</span> range(<span class="hljs-params">1</span>,len(p)):
<span class="hljs-keyword">if</span> ord(p[i])-ord(p[i<span class="hljs-params">-1</span>]) == <span class="hljs-params">1</span> <span class="hljs-keyword">or</span> ord(p[i])-ord(p[i<span class="hljs-params">-1</span>]) == <span class="hljs-params">-25</span>:
w += <span class="hljs-params">1</span>
<span class="hljs-keyword">else</span>:
w = <span class="hljs-params">1</span>
ans += w
<span class="hljs-keyword">return</span> ans
```
```
如上代碼是有問題。 比如 `cac`會被計算為 3,實際上應該是 2。根本原因在于 c 被錯誤地計算了兩次。因此一個簡單的思路就是用 set 記錄一下訪問過的子字符串即可。比如:
```
<pre class="calibre18">```
{
c,
abc,
ab,
abcd
}
```
```
而由于 set 中的元素一定是連續的,因此上面的數據也可以用 hashmap 存:
```
<pre class="calibre18">```
{
c: 3
d: 4
b: 1
}
```
```
含義是:
- 以 b 結尾的子串最大長度為 1,也就是 b。
- 以 c 結尾的子串最大長度為 3,也就是 abc。
- 以 d 結尾的子串最大長度為 4,也就是 abcd。
至于 c ,是沒有必要存的。我們可以通過母題 2 的方式算出來。
具體算法:
- 定義一個 len\_mapper。key 是 字母, value 是 長度。 含義是以 key 結尾的最長連續子串的長度。
> 關鍵字是:最長
- 用一個變量 w 記錄連續子串的長度,遍歷過程根據 w 的值更新 len\_mapper
- 返回 len\_mapper 中所有 value 的和。
比如: abc,此時的 len\_mapper 為:
```
<pre class="calibre18">```
{
c: <span class="hljs-params">3</span>
b: <span class="hljs-params">2</span>
a: <span class="hljs-params">1</span>
}
```
```
再比如:abcab,此時的 len\_mapper 依舊。
再比如: abcazabc,此時的 len\_mapper:
```
<pre class="calibre18">```
{
c: <span class="hljs-params">4</span>
b: <span class="hljs-params">3</span>
a: <span class="hljs-params">2</span>
z: <span class="hljs-params">1</span>
}
```
```
這就得到了去重的目的。這種算法是不重不漏的,因為最長的連續子串一定是包含了比它短的連續子串,這個思想和 [1297. 子串的最大出現次數](https://github.com/azl397985856/leetcode/issues/266 "1297. 子串的最大出現次數") 剪枝的方法有異曲同工之妙。
### 代碼(Python)
```
<pre class="calibre18">```
<span class="hljs-class"><span class="hljs-keyword">class</span> <span class="hljs-title">Solution</span>:</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">findSubstringInWraproundString</span><span class="hljs-params">(self, p: str)</span> -> int:</span>
p = <span class="hljs-string">'^'</span> + p
len_mapper = collections.defaultdict(<span class="hljs-keyword">lambda</span>: <span class="hljs-params">0</span>)
w = <span class="hljs-params">1</span>
<span class="hljs-keyword">for</span> i <span class="hljs-keyword">in</span> range(<span class="hljs-params">1</span>,len(p)):
<span class="hljs-keyword">if</span> ord(p[i])-ord(p[i<span class="hljs-params">-1</span>]) == <span class="hljs-params">1</span> <span class="hljs-keyword">or</span> ord(p[i])-ord(p[i<span class="hljs-params">-1</span>]) == <span class="hljs-params">-25</span>:
w += <span class="hljs-params">1</span>
<span class="hljs-keyword">else</span>:
w = <span class="hljs-params">1</span>
len_mapper[p[i]] = max(len_mapper[p[i]], w)
<span class="hljs-keyword">return</span> sum(len_mapper.values())
```
```
**復雜度分析**
- 時間復雜度:O(N)O(N)O(N),其中 NNN 為字符串 p 的長度。
- 空間復雜度:由于最多存儲 26 個字母, 因此空間實際上是常數,故空間復雜度為 O(1)O(1)O(1)。
## 795. 區間子數組個數(中等)
### 題目描述
```
<pre class="calibre18">```
給定一個元素都是正整數的數組 A ,正整數 L 以及 R (L <= R)。
求連續、非空且其中最大元素滿足大于等于 L 小于等于 R 的子數組個數。
例如 :
輸入:
A = [2, 1, 4, 3]
L = 2
R = 3
輸出: 3
解釋: 滿足條件的子數組: [2], [2, 1], [3].
注意:
L, R 和 A[i] 都是整數,范圍在 [0, 10^9]。
數組 A 的長度范圍在[1, 50000]。
```
```
### 前置知識
- 滑動窗口
### 思路
由母題 5,我們知道 **betweenK 可以直接利用 atMostK,即 atMostK(k1) - atMostK(k2 - 1),其中 k1 > k2**。
由母題 2,我們知道如何求滿足一定條件(這里是元素都小于等于 R)子數組的個數。
這兩個結合一下, 就可以解決。
### 代碼(Python)
> 代碼是不是很像
```
<pre class="calibre18">```
<span class="hljs-class"><span class="hljs-keyword">class</span> <span class="hljs-title">Solution</span>:</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">numSubarrayBoundedMax</span><span class="hljs-params">(self, A: List[int], L: int, R: int)</span> -> int:</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">notGreater</span><span class="hljs-params">(R)</span>:</span>
ans = cnt = <span class="hljs-params">0</span>
<span class="hljs-keyword">for</span> a <span class="hljs-keyword">in</span> A:
<span class="hljs-keyword">if</span> a <= R: cnt += <span class="hljs-params">1</span>
<span class="hljs-keyword">else</span>: cnt = <span class="hljs-params">0</span>
ans += cnt
<span class="hljs-keyword">return</span> ans
<span class="hljs-keyword">return</span> notGreater(R) - notGreater(L - <span class="hljs-params">1</span>)
```
```
***復雜度分析***
- 時間復雜度:O(N)O(N)O(N),其中 NNN 為數組長度。
- 空間復雜度:O(1)O(1)O(1)。
## 904. 水果成籃(中等)
### 題目描述
```
<pre class="calibre18">```
在一排樹中,第 i 棵樹產生 tree[i] 型的水果。
你可以從你選擇的任何樹開始,然后重復執行以下步驟:
把這棵樹上的水果放進你的籃子里。如果你做不到,就停下來。
移動到當前樹右側的下一棵樹。如果右邊沒有樹,就停下來。
請注意,在選擇一顆樹后,你沒有任何選擇:你必須執行步驟 1,然后執行步驟 2,然后返回步驟 1,然后執行步驟 2,依此類推,直至停止。
你有兩個籃子,每個籃子可以攜帶任何數量的水果,但你希望每個籃子只攜帶一種類型的水果。
用這個程序你能收集的水果樹的最大總量是多少?
示例 1:
輸入:[1,2,1]
輸出:3
解釋:我們可以收集 [1,2,1]。
示例 2:
輸入:[0,1,2,2]
輸出:3
解釋:我們可以收集 [1,2,2]
如果我們從第一棵樹開始,我們將只能收集到 [0, 1]。
示例 3:
輸入:[1,2,3,2,2]
輸出:4
解釋:我們可以收集 [2,3,2,2]
如果我們從第一棵樹開始,我們將只能收集到 [1, 2]。
示例 4:
輸入:[3,3,3,1,2,1,1,2,3,3,4]
輸出:5
解釋:我們可以收集 [1,2,1,1,2]
如果我們從第一棵樹或第八棵樹開始,我們將只能收集到 4 棵水果樹。
提示:
1 <= tree.length <= 40000
0 <= tree[i] < tree.length
```
```
### 前置知識
- 滑動窗口
### 思路
題目花里胡哨的。我們來抽象一下,就是給你一個數組, 讓你**選定一個子數組, 這個子數組最多只有兩種數字**,這個選定的子數組最大可以是多少。
這不就和母題 3 一樣么?只不過 k 變成了固定值 2。另外由于題目要求整個窗口最多兩種數字,我們用哈希表存一下不就好了嗎?
> set 是不行了的。 因此我們不但需要知道幾個數字在窗口, 我們還要知道每個數字出現的次數,這樣才可以使用滑動窗口優化時間復雜度。
### 代碼(Python)
```
<pre class="calibre18">```
<span class="hljs-class"><span class="hljs-keyword">class</span> <span class="hljs-title">Solution</span>:</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">totalFruit</span><span class="hljs-params">(self, tree: List[int])</span> -> int:</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">atMostK</span><span class="hljs-params">(k, nums)</span>:</span>
i = ans = <span class="hljs-params">0</span>
win = defaultdict(<span class="hljs-keyword">lambda</span>: <span class="hljs-params">0</span>)
<span class="hljs-keyword">for</span> j <span class="hljs-keyword">in</span> range(len(nums)):
<span class="hljs-keyword">if</span> win[nums[j]] == <span class="hljs-params">0</span>: k -= <span class="hljs-params">1</span>
win[nums[j]] += <span class="hljs-params">1</span>
<span class="hljs-keyword">while</span> k < <span class="hljs-params">0</span>:
win[nums[i]] -= <span class="hljs-params">1</span>
<span class="hljs-keyword">if</span> win[nums[i]] == <span class="hljs-params">0</span>: k += <span class="hljs-params">1</span>
i += <span class="hljs-params">1</span>
ans = max(ans, j - i + <span class="hljs-params">1</span>)
<span class="hljs-keyword">return</span> ans
<span class="hljs-keyword">return</span> atMostK(<span class="hljs-params">2</span>, tree)
```
```
**復雜度分析**
- 時間復雜度:O(N)O(N)O(N),其中 NNN 為數組長度。
- 空間復雜度:O(k)O(k)O(k)。
## 992. K 個不同整數的子數組(困難)
### 題目描述
```
<pre class="calibre18">```
給定一個正整數數組 A,如果 A 的某個子數組中不同整數的個數恰好為 K,則稱 A 的這個連續、不一定獨立的子數組為好子數組。
(例如,[1,2,3,1,2] 中有 3 個不同的整數:1,2,以及 3。)
返回 A 中好子數組的數目。
示例 1:
輸入:A = [1,2,1,2,3], K = 2
輸出:7
解釋:恰好由 2 個不同整數組成的子數組:[1,2], [2,1], [1,2], [2,3], [1,2,1], [2,1,2], [1,2,1,2].
示例 2:
輸入:A = [1,2,1,3,4], K = 3
輸出:3
解釋:恰好由 3 個不同整數組成的子數組:[1,2,1,3], [2,1,3], [1,3,4].
提示:
1 <= A.length <= 20000
1 <= A[i] <= A.length
1 <= K <= A.length
```
```
### 前置知識
- 滑動窗口
### 思路
由母題 5,知:exactK = atMostK(k) - atMostK(k - 1), 因此答案便呼之欲出了。其他部分和上面的題目 `904. 水果成籃` 一樣。
> 實際上和所有的滑動窗口題目都差不多。
### 代碼(Python)
```
<pre class="calibre18">```
<span class="hljs-class"><span class="hljs-keyword">class</span> <span class="hljs-title">Solution</span>:</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">subarraysWithKDistinct</span><span class="hljs-params">(self, A, K)</span>:</span>
<span class="hljs-keyword">return</span> self.atMostK(A, K) - self.atMostK(A, K - <span class="hljs-params">1</span>)
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">atMostK</span><span class="hljs-params">(self, A, K)</span>:</span>
counter = collections.Counter()
res = i = <span class="hljs-params">0</span>
<span class="hljs-keyword">for</span> j <span class="hljs-keyword">in</span> range(len(A)):
<span class="hljs-keyword">if</span> counter[A[j]] == <span class="hljs-params">0</span>:
K -= <span class="hljs-params">1</span>
counter[A[j]] += <span class="hljs-params">1</span>
<span class="hljs-keyword">while</span> K < <span class="hljs-params">0</span>:
counter[A[i]] -= <span class="hljs-params">1</span>
<span class="hljs-keyword">if</span> counter[A[i]] == <span class="hljs-params">0</span>:
K += <span class="hljs-params">1</span>
i += <span class="hljs-params">1</span>
res += j - i + <span class="hljs-params">1</span>
<span class="hljs-keyword">return</span> res
```
```
**復雜度分析**
- 時間復雜度:O(N)O(N)O(N),中 NNN 為數組長度。
- 空間復雜度:O(k)O(k)O(k)。
## 1109. 航班預訂統計(中等)
### 題目描述
```
<pre class="calibre18">```
這里有 n 個航班,它們分別從 1 到 n 進行編號。
我們這兒有一份航班預訂表,表中第 i 條預訂記錄 bookings[i] = [i, j, k] 意味著我們在從 i 到 j 的每個航班上預訂了 k 個座位。
請你返回一個長度為 n 的數組 answer,按航班編號順序返回每個航班上預訂的座位數。
示例:
輸入:bookings = [[1,2,10],[2,3,20],[2,5,25]], n = 5
輸出:[10,55,45,25,25]
提示:
1 <= bookings.length <= 20000
1 <= bookings[i][0] <= bookings[i][1] <= n <= 20000
1 <= bookings[i][2] <= 10000
```
```
### 前置知識
- 前綴和
### 思路
這道題的題目描述不是很清楚。我簡單分析一下題目:
\[i, j, k\] 其實代表的是 第 i 站上來了 k 個人, 一直到 第 j 站都在飛機上,到第 j + 1 就不在飛機上了。所以第 i 站到第 j 站的**每一站**都會因此多 k 個人。
理解了題目只會不難寫出下面的代碼。
```
<pre class="calibre18">```
<span class="hljs-class"><span class="hljs-keyword">class</span> <span class="hljs-title">Solution</span>:</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">corpFlightBookings</span><span class="hljs-params">(self, bookings: List[List[int]], n: int)</span> -> List[int]:</span>
counter = [<span class="hljs-params">0</span>] * n
<span class="hljs-keyword">for</span> i, j, k <span class="hljs-keyword">in</span> bookings:
<span class="hljs-keyword">while</span> i <= j:
counter[i - <span class="hljs-params">1</span>] += k
i += <span class="hljs-params">1</span>
<span class="hljs-keyword">return</span> counter
```
```
如上的代碼復雜度太高,無法通過全部的測試用例。
**注意到里層的 while 循環是連續的數組全部加上一個數字,不難想到可以利用母題 0 的前綴和思路優化。**
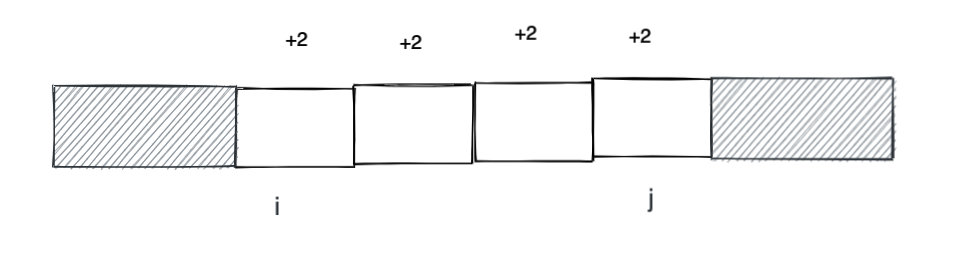
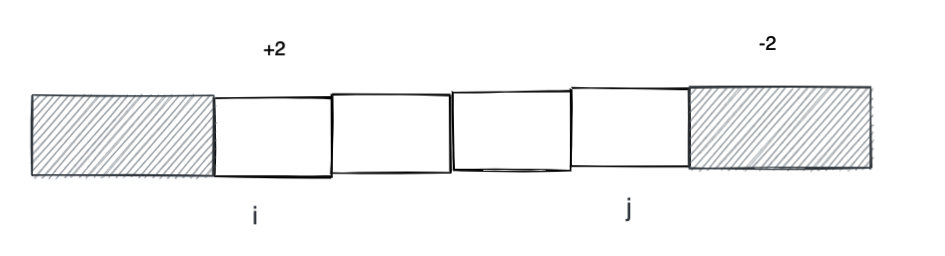
一種思路就是在 i 的位置 + k, 然后利用前綴和的技巧給 i 到 n 的元素都加上 k。但是題目需要加的是一個區間, j + 1 及其之后的元素會被多加一個 k。一個簡單的技巧就是給 j + 1 的元素減去 k,這樣正負就可以抵消。
### 代碼(Python)
```
<pre class="calibre18">```
<span class="hljs-class"><span class="hljs-keyword">class</span> <span class="hljs-title">Solution</span>:</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">corpFlightBookings</span><span class="hljs-params">(self, bookings: List[List[int]], n: int)</span> -> List[int]:</span>
counter = [<span class="hljs-params">0</span>] * (n + <span class="hljs-params">1</span>)
<span class="hljs-keyword">for</span> i, j, k <span class="hljs-keyword">in</span> bookings:
counter[i - <span class="hljs-params">1</span>] += k
<span class="hljs-keyword">if</span> j < n: counter[j] -= k
<span class="hljs-keyword">for</span> i <span class="hljs-keyword">in</span> range(n + <span class="hljs-params">1</span>):
counter[i] += counter[i - <span class="hljs-params">1</span>]
<span class="hljs-keyword">return</span> counter[:<span class="hljs-params">-1</span>]
```
```
**復雜度分析**
- 時間復雜度:O(N)O(N)O(N),中 NNN 為數組長度。
- 空間復雜度:O(N)O(N)O(N)。
## 總結
這幾道題都是滑動窗口和前綴和的思路。力扣類似的題目還真不少,大家只有多留心,就會發現這個套路。
前綴和的技巧以及滑動窗口的技巧都比較固定,且有模板可套。 難點就在于我怎么才能想到可以用這個技巧呢?
我這里總結了兩點:
1. 找關鍵字。比如題目中有連續,就應該條件反射想到滑動窗口和前綴和。比如題目求最大最小就想到動態規劃和貪心等等。想到之后,就可以和題目信息對比快速排除錯誤的算法,找到可行解。這個思考的時間會隨著你的題感增加而降低。
2. 先寫出暴力解,然后找暴力解的瓶頸, 根據瓶頸就很容易知道應該用什么數據結構和算法去優化。
最后推薦幾道類似的題目, 供大家練習,一定要自己寫出來才行哦。
- [303. 區域和檢索 - 數組不可變](https://leetcode-cn.com/problems/range-sum-query-immutable/description/ "303. 區域和檢索 - 數組不可變")
- [1186.刪除一次得到子數組最大和](https://lucifer.ren/blog/2019/12/11/leetcode-1186/ "1186.刪除一次得到子數組最大和")
- [1310. 子數組異或查詢](https://lucifer.ren/blog/2020/01/09/1310.xor-queries-of-a-subarray/ "1310. 子數組異或查詢")
- [1371. 每個元音包含偶數次的最長子字符串](https://github.com/azl397985856/leetcode/blob/master/problems/1371.find-the-longest-substring-containing-vowels-in-even-counts.md "1371. 每個元音包含偶數次的最長子字符串")
大家對此有何看法,歡迎給我留言,我有時間都會一一查看回答。
更多算法套路可以訪問我的 LeetCode 題解倉庫:<https://github.com/azl397985856/leetcode> 。 目前已經 36K star 啦。
大家也可以關注我的公眾號《力扣加加》帶你啃下算法這塊硬骨頭。

- Introduction
- 第一章 - 算法專題
- 數據結構
- 基礎算法
- 二叉樹的遍歷
- 動態規劃
- 哈夫曼編碼和游程編碼
- 布隆過濾器
- 字符串問題
- 前綴樹專題
- 《貪婪策略》專題
- 《深度優先遍歷》專題
- 滑動窗口(思路 + 模板)
- 位運算
- 設計題
- 小島問題
- 最大公約數
- 并查集
- 前綴和
- 平衡二叉樹專題
- 第二章 - 91 天學算法
- 第一期講義-二分法
- 第一期講義-雙指針
- 第二期
- 第三章 - 精選題解
- 《日程安排》專題
- 《構造二叉樹》專題
- 字典序列刪除
- 百度的算法面試題 * 祖瑪游戲
- 西法的刷題秘籍】一次搞定前綴和
- 字節跳動的算法面試題是什么難度?
- 字節跳動的算法面試題是什么難度?(第二彈)
- 《我是你的媽媽呀》 * 第一期
- 一文帶你看懂二叉樹的序列化
- 穿上衣服我就不認識你了?來聊聊最長上升子序列
- 你的衣服我扒了 * 《最長公共子序列》
- 一文看懂《最大子序列和問題》
- 第四章 - 高頻考題(簡單)
- 面試題 17.12. BiNode
- 0001. 兩數之和
- 0020. 有效的括號
- 0021. 合并兩個有序鏈表
- 0026. 刪除排序數組中的重復項
- 0053. 最大子序和
- 0088. 合并兩個有序數組
- 0101. 對稱二叉樹
- 0104. 二叉樹的最大深度
- 0108. 將有序數組轉換為二叉搜索樹
- 0121. 買賣股票的最佳時機
- 0122. 買賣股票的最佳時機 II
- 0125. 驗證回文串
- 0136. 只出現一次的數字
- 0155. 最小棧
- 0167. 兩數之和 II * 輸入有序數組
- 0169. 多數元素
- 0172. 階乘后的零
- 0190. 顛倒二進制位
- 0191. 位1的個數
- 0198. 打家劫舍
- 0203. 移除鏈表元素
- 0206. 反轉鏈表
- 0219. 存在重復元素 II
- 0226. 翻轉二叉樹
- 0232. 用棧實現隊列
- 0263. 丑數
- 0283. 移動零
- 0342. 4的冪
- 0349. 兩個數組的交集
- 0371. 兩整數之和
- 0437. 路徑總和 III
- 0455. 分發餅干
- 0575. 分糖果
- 0874. 模擬行走機器人
- 1260. 二維網格遷移
- 1332. 刪除回文子序列
- 第五章 - 高頻考題(中等)
- 0002. 兩數相加
- 0003. 無重復字符的最長子串
- 0005. 最長回文子串
- 0011. 盛最多水的容器
- 0015. 三數之和
- 0017. 電話號碼的字母組合
- 0019. 刪除鏈表的倒數第N個節點
- 0022. 括號生成
- 0024. 兩兩交換鏈表中的節點
- 0029. 兩數相除
- 0031. 下一個排列
- 0033. 搜索旋轉排序數組
- 0039. 組合總和
- 0040. 組合總和 II
- 0046. 全排列
- 0047. 全排列 II
- 0048. 旋轉圖像
- 0049. 字母異位詞分組
- 0050. Pow(x, n)
- 0055. 跳躍游戲
- 0056. 合并區間
- 0060. 第k個排列
- 0062. 不同路徑
- 0073. 矩陣置零
- 0075. 顏色分類
- 0078. 子集
- 0079. 單詞搜索
- 0080. 刪除排序數組中的重復項 II
- 0086. 分隔鏈表
- 0090. 子集 II
- 0091. 解碼方法
- 0092. 反轉鏈表 II
- 0094. 二叉樹的中序遍歷
- 0095. 不同的二叉搜索樹 II
- 0096. 不同的二叉搜索樹
- 0098. 驗證二叉搜索樹
- 0102. 二叉樹的層序遍歷
- 0103. 二叉樹的鋸齒形層次遍歷
- 105. 從前序與中序遍歷序列構造二叉樹
- 0113. 路徑總和 II
- 0129. 求根到葉子節點數字之和
- 0130. 被圍繞的區域
- 0131. 分割回文串
- 0139. 單詞拆分
- 0144. 二叉樹的前序遍歷
- 0150. 逆波蘭表達式求值
- 0152. 乘積最大子數組
- 0199. 二叉樹的右視圖
- 0200. 島嶼數量
- 0201. 數字范圍按位與
- 0208. 實現 Trie (前綴樹)
- 0209. 長度最小的子數組
- 0211. 添加與搜索單詞 * 數據結構設計
- 0215. 數組中的第K個最大元素
- 0221. 最大正方形
- 0229. 求眾數 II
- 0230. 二叉搜索樹中第K小的元素
- 0236. 二叉樹的最近公共祖先
- 0238. 除自身以外數組的乘積
- 0240. 搜索二維矩陣 II
- 0279. 完全平方數
- 0309. 最佳買賣股票時機含冷凍期
- 0322. 零錢兌換
- 0328. 奇偶鏈表
- 0334. 遞增的三元子序列
- 0337. 打家劫舍 III
- 0343. 整數拆分
- 0365. 水壺問題
- 0378. 有序矩陣中第K小的元素
- 0380. 常數時間插入、刪除和獲取隨機元素
- 0416. 分割等和子集
- 0445. 兩數相加 II
- 0454. 四數相加 II
- 0494. 目標和
- 0516. 最長回文子序列
- 0518. 零錢兌換 II
- 0547. 朋友圈
- 0560. 和為K的子數組
- 0609. 在系統中查找重復文件
- 0611. 有效三角形的個數
- 0718. 最長重復子數組
- 0754. 到達終點數字
- 0785. 判斷二分圖
- 0820. 單詞的壓縮編碼
- 0875. 愛吃香蕉的珂珂
- 0877. 石子游戲
- 0886. 可能的二分法
- 0900. RLE 迭代器
- 0912. 排序數組
- 0935. 騎士撥號器
- 1011. 在 D 天內送達包裹的能力
- 1014. 最佳觀光組合
- 1015. 可被 K 整除的最小整數
- 1019. 鏈表中的下一個更大節點
- 1020. 飛地的數量
- 1023. 駝峰式匹配
- 1031. 兩個非重疊子數組的最大和
- 1104. 二叉樹尋路
- 1131.絕對值表達式的最大值
- 1186. 刪除一次得到子數組最大和
- 1218. 最長定差子序列
- 1227. 飛機座位分配概率
- 1261. 在受污染的二叉樹中查找元素
- 1262. 可被三整除的最大和
- 1297. 子串的最大出現次數
- 1310. 子數組異或查詢
- 1334. 閾值距離內鄰居最少的城市
- 1371.每個元音包含偶數次的最長子字符串
- 第六章 - 高頻考題(困難)
- 0004. 尋找兩個正序數組的中位數
- 0023. 合并K個升序鏈表
- 0025. K 個一組翻轉鏈表
- 0030. 串聯所有單詞的子串
- 0032. 最長有效括號
- 0042. 接雨水
- 0052. N皇后 II
- 0084. 柱狀圖中最大的矩形
- 0085. 最大矩形
- 0124. 二叉樹中的最大路徑和
- 0128. 最長連續序列
- 0145. 二叉樹的后序遍歷
- 0212. 單詞搜索 II
- 0239. 滑動窗口最大值
- 0295. 數據流的中位數
- 0301. 刪除無效的括號
- 0312. 戳氣球
- 0335. 路徑交叉
- 0460. LFU緩存
- 0472. 連接詞
- 0488. 祖瑪游戲
- 0493. 翻轉對
- 0887. 雞蛋掉落
- 0895. 最大頻率棧
- 1032. 字符流
- 1168. 水資源分配優化
- 1449. 數位成本和為目標值的最大數字
- 后序