
# 一文帶你看懂二叉樹的序列化
# 文帶你看懂二叉樹的序列化
我們先來看下什么是序列化,以下定義來自維基百科:
> 序列化(serialization)在計算機科學的數據處理中,是指將數據結構或對象狀態轉換成可取用格式(例如存成文件,存于緩沖,或經由網絡中發送),以留待后續在相同或另一臺計算機環境中,能恢復原先狀態的過程。依照序列化格式重新獲取字節的結果時,可以利用它來產生與原始對象相同語義的副本。對于許多對象,像是使用大量引用的復雜對象,這種序列化重建的過程并不容易。面向對象中的對象序列化,并不概括之前原始對象所關系的函數。這種過程也稱為對象編組(marshalling)。從一系列字節提取數據結構的反向操作,是反序列化(也稱為解編組、deserialization、unmarshalling)。
可見,序列化和反序列化在計算機科學中的應用還是非常廣泛的。就拿 LeetCode 平臺來說,其允許用戶輸入形如:
```
<pre class="calibre18">```
[1,2,3,null,null,4,5]
```
```
這樣的數據結構來描述一顆樹:
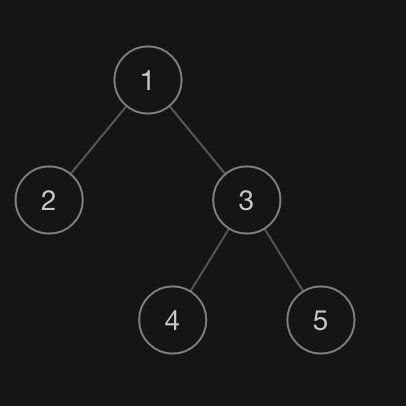
(\[1,2,3,null,null,4,5\] 對應的二叉樹)
其實序列化和反序列化只是一個概念,不是一種具體的算法,而是很多的算法。并且針對不同的數據結構,算法也會不一樣。本文主要講述的是二叉樹的序列化和反序列化。看完本文之后,你就可以放心大膽地去 AC 以下兩道題:
- [449. 序列化和反序列化二叉搜索樹(中等)](https://leetcode-cn.com/problems/serialize-and-deserialize-bst/)
- [297. 二叉樹的序列化與反序列化(困難)](https://leetcode-cn.com/problems/serialize-and-deserialize-binary-tree/)
## 前置知識
閱讀本文之前,需要你對樹的遍歷以及 BFS 和 DFS 比較熟悉。如果你還不熟悉,推薦閱讀一下相關文章之后再來看。或者我這邊也寫了一個總結性的文章[二叉樹的遍歷](https://github.com/azl397985856/leetcode/blob/master/thinkings/binary-tree-traversal.md),你也可以看看。
## 前言
我們知道:二叉樹的深度優先遍歷,根據訪問根節點的順序不同,可以將其分為`前序遍歷`,`中序遍歷`, `后序遍歷`。即如果先訪問根節點就是前序遍歷,最后訪問根節點就是后續遍歷,其它則是中序遍歷。而左右節點的相對順序是不會變的,一定是先左后右。
> 當然也可以設定為先右后左。
并且知道了三種遍歷結果中的任意兩種即可還原出原有的樹結構。這不就是序列化和反序列化么?如果對這個比較陌生的同學建議看看我之前寫的[《構造二叉樹系列》](https://lucifer.ren/blog/2020/02/08/%E6%9E%84%E9%80%A0%E4%BA%8C%E5%8F%89%E6%A0%91%E4%B8%93%E9%A2%98/)
有了這樣一個前提之后算法就自然而然了。即先對二叉樹進行兩次不同的遍歷,不妨假設按照前序和中序進行兩次遍歷。然后將兩次遍歷結果序列化,比如將兩次遍歷結果以逗號“,” join 成一個字符串。 之后將字符串反序列即可,比如將其以逗號“,” split 成一個數組。
序列化:
```
<pre class="calibre18">```
<span class="hljs-class"><span class="hljs-keyword">class</span> <span class="hljs-title">Solution</span>:</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">preorder</span><span class="hljs-params">(self, root: TreeNode)</span>:</span>
<span class="hljs-keyword">if</span> <span class="hljs-keyword">not</span> root: <span class="hljs-keyword">return</span> []
<span class="hljs-keyword">return</span> [str(root.val)] +self. preorder(root.left) + self.preorder(root.right)
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">inorder</span><span class="hljs-params">(self, root: TreeNode)</span>:</span>
<span class="hljs-keyword">if</span> <span class="hljs-keyword">not</span> root: <span class="hljs-keyword">return</span> []
<span class="hljs-keyword">return</span> self.inorder(root.left) + [str(root.val)] + self.inorder(root.right)
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">serialize</span><span class="hljs-params">(self, root)</span>:</span>
ans = <span class="hljs-string">''</span>
ans += <span class="hljs-string">','</span>.join(self.preorder(root))
ans += <span class="hljs-string">'{% math %}'</span>
ans += <span class="hljs-string">','</span>.join(self.inorder(root))
<span class="hljs-keyword">return</span> ans
```
```
反序列化:
這里我直接用了力扣 `105. 從前序與中序遍歷序列構造二叉樹` 的解法,一行代碼都不改。
```
<pre class="calibre18">```
<span class="hljs-class"><span class="hljs-keyword">class</span> <span class="hljs-title">Solution</span>:</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">deserialize</span><span class="hljs-params">(self, data: str)</span>:</span>
preorder, inorder = data.split(<span class="hljs-string">'{% endmath %}'</span>)
<span class="hljs-keyword">if</span> <span class="hljs-keyword">not</span> preorder: <span class="hljs-keyword">return</span> <span class="hljs-keyword">None</span>
<span class="hljs-keyword">return</span> self.buildTree(preorder.split(<span class="hljs-string">','</span>), inorder.split(<span class="hljs-string">','</span>))
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">buildTree</span><span class="hljs-params">(self, preorder: List[int], inorder: List[int])</span> -> TreeNode:</span>
<span class="hljs-title"># 實際上inorder 和 preorder 一定是同時為空的,因此你無論判斷哪個都行</span>
<span class="hljs-keyword">if</span> <span class="hljs-keyword">not</span> preorder:
<span class="hljs-keyword">return</span> <span class="hljs-keyword">None</span>
root = TreeNode(preorder[<span class="hljs-params">0</span>])
i = inorder.index(root.val)
root.left = self.buildTree(preorder[<span class="hljs-params">1</span>:i + <span class="hljs-params">1</span>], inorder[:i])
root.right = self.buildTree(preorder[i + <span class="hljs-params">1</span>:], inorder[i+<span class="hljs-params">1</span>:])
<span class="hljs-keyword">return</span> root
```
```
實際上這個算法是不一定成立的,原因在于樹的節點可能存在重復元素。也就是說我前面說的`知道了三種遍歷結果中的任意兩種即可還原出原有的樹結構`是不對的,嚴格來說應該是**如果樹中不存在重復的元素,那么知道了三種遍歷結果中的任意兩種即可還原出原有的樹結構**。
聰明的你應該發現了,上面我的代碼用了 `i = inorder.index(root.val)`,如果存在重復元素,那么得到的索引 i 就可能不是準確的。但是,如果題目限定了沒有重復元素則可以用這種算法。但是現實中不出現重復元素不太現實,因此需要考慮其他方法。那究竟是什么樣的方法呢? 接下來進入正題。
## DFS
### 序列化
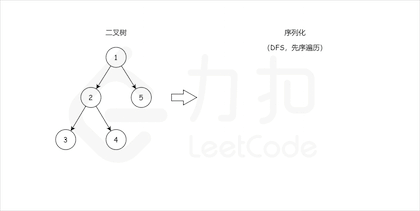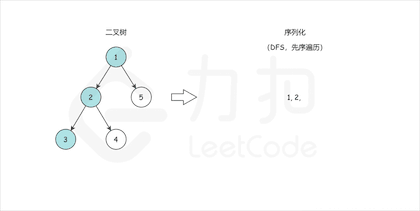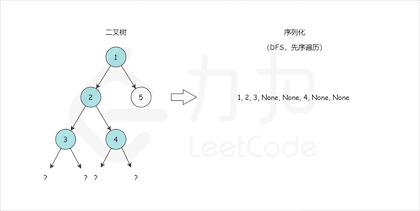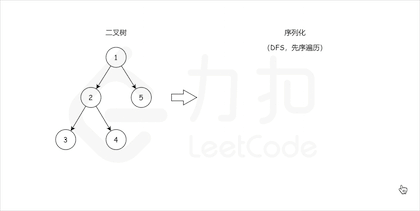
我們來模仿一下力扣的記法。 比如:`[1,2,3,null,null,4,5]`(本質上是 BFS 層次遍歷),對應的樹如下:
> 選擇這種記法,而不是 DFS 的記法的原因是看起來比較直觀
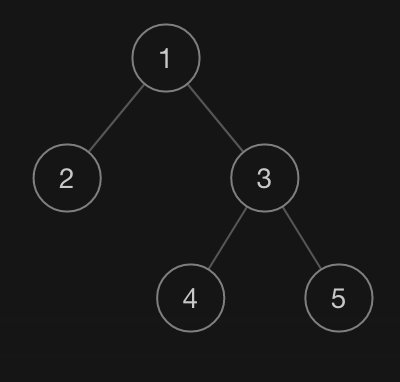
序列化的代碼非常簡單, 我們只需要在普通的遍歷基礎上,增加對空節點的輸出即可(普通的遍歷是不處理空節點的)。
比如我們都樹進行一次前序遍歷的同時增加空節點的處理。選擇前序遍歷的原因是容易知道根節點的位置,并且代碼好寫,不信你可以試試。
因此序列化就僅僅是普通的 DFS 而已,直接給大家看看代碼。
Python 代碼:
```
<pre class="calibre18">```
<span class="hljs-class"><span class="hljs-keyword">class</span> <span class="hljs-title">Codec</span>:</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">serialize_dfs</span><span class="hljs-params">(self, root, ans)</span>:</span>
<span class="hljs-title"># 空節點也需要序列化,否則無法唯一確定一棵樹,后不贅述。</span>
<span class="hljs-keyword">if</span> <span class="hljs-keyword">not</span> root: <span class="hljs-keyword">return</span> ans + <span class="hljs-string">'#,'</span>
<span class="hljs-title"># 節點之間通過逗號(,)分割</span>
ans += str(root.val) + <span class="hljs-string">','</span>
ans = self.serialize_dfs(root.left, ans)
ans = self.serialize_dfs(root.right, ans)
<span class="hljs-keyword">return</span> ans
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">serialize</span><span class="hljs-params">(self, root)</span>:</span>
<span class="hljs-title"># 由于最后會添加一個額外的逗號,因此需要去除最后一個字符,后不贅述。</span>
<span class="hljs-keyword">return</span> self.serialize_dfs(root, <span class="hljs-string">''</span>)[:<span class="hljs-params">-1</span>]
```
```
Java 代碼:
```
<pre class="calibre18">```
<span class="hljs-keyword">public</span> <span class="hljs-class"><span class="hljs-keyword">class</span> <span class="hljs-title">Codec</span> </span>{
<span class="hljs-function"><span class="hljs-keyword">public</span> String <span class="hljs-title">serialize_dfs</span><span class="hljs-params">(TreeNode root, String str)</span> </span>{
<span class="hljs-keyword">if</span> (root == <span class="hljs-keyword">null</span>) {
str += <span class="hljs-string">"None,"</span>;
} <span class="hljs-keyword">else</span> {
str += str.valueOf(root.val) + <span class="hljs-string">","</span>;
str = serialize_dfs(root.left, str);
str = serialize_dfs(root.right, str);
}
<span class="hljs-keyword">return</span> str;
}
<span class="hljs-function"><span class="hljs-keyword">public</span> String <span class="hljs-title">serialize</span><span class="hljs-params">(TreeNode root)</span> </span>{
<span class="hljs-keyword">return</span> serialize_dfs(root, <span class="hljs-string">""</span>);
}
}
```
```
`[1,2,3,null,null,4,5]` 會被處理為`1,2,#,#,3,4,#,#,5,#,#`
我們先看一個短視頻:
(動畫來自力扣)
### 反序列化
反序列化的第一步就是將其展開。以上面的例子來說,則會變成數組:`[1,2,#,#,3,4,#,#,5,#,#]`,然后我們同樣執行一次前序遍歷,每次處理一個元素,重建即可。由于我們采用的前序遍歷,因此第一個是根元素,下一個是其左子節點,下下一個是其右子節點。
Python 代碼:
```
<pre class="calibre18">```
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">deserialize_dfs</span><span class="hljs-params">(self, nodes)</span>:</span>
<span class="hljs-keyword">if</span> nodes:
<span class="hljs-keyword">if</span> nodes[<span class="hljs-params">0</span>] == <span class="hljs-string">'#'</span>:
nodes.pop(<span class="hljs-params">0</span>)
<span class="hljs-keyword">return</span> <span class="hljs-keyword">None</span>
root = TreeNode(nodes.pop(<span class="hljs-params">0</span>))
root.left = self.deserialize_dfs(nodes)
root.right = self.deserialize_dfs(nodes)
<span class="hljs-keyword">return</span> root
<span class="hljs-keyword">return</span> <span class="hljs-keyword">None</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">deserialize</span><span class="hljs-params">(self, data: str)</span>:</span>
nodes = data.split(<span class="hljs-string">','</span>)
<span class="hljs-keyword">return</span> self.deserialize_dfs(nodes)
```
```
Java 代碼:
```
<pre class="calibre18">```
<span class="hljs-function"><span class="hljs-keyword">public</span> TreeNode <span class="hljs-title">deserialize_dfs</span><span class="hljs-params">(List<String> l)</span> </span>{
<span class="hljs-keyword">if</span> (l.get(<span class="hljs-params">0</span>).equals(<span class="hljs-string">"None"</span>)) {
l.remove(<span class="hljs-params">0</span>);
<span class="hljs-keyword">return</span> <span class="hljs-keyword">null</span>;
}
TreeNode root = <span class="hljs-keyword">new</span> TreeNode(Integer.valueOf(l.get(<span class="hljs-params">0</span>)));
l.remove(<span class="hljs-params">0</span>);
root.left = deserialize_dfs(l);
root.right = deserialize_dfs(l);
<span class="hljs-keyword">return</span> root;
}
<span class="hljs-function"><span class="hljs-keyword">public</span> TreeNode <span class="hljs-title">deserialize</span><span class="hljs-params">(String data)</span> </span>{
String[] data_array = data.split(<span class="hljs-string">","</span>);
List<String> data_list = <span class="hljs-keyword">new</span> LinkedList<String>(Arrays.asList(data_array));
<span class="hljs-keyword">return</span> deserialize_dfs(data_list);
}
```
```
**復雜度分析**
- 時間復雜度:每個節點都會被處理一次,因此時間復雜度為 O(N)O(N)O(N),其中 NNN 為節點的總數。
- 空間復雜度:空間復雜度取決于棧深度,因此空間復雜度為 O(h)O(h)O(h),其中 hhh 為樹的深度。
## BFS
### 序列化
實際上我們也可以使用 BFS 的方式來表示一棵樹。在這一點上其實就和力扣的記法是一致的了。
我們知道層次遍歷的時候實際上是有層次的。只不過有的題目需要你記錄每一個節點的層次信息,有些則不需要。
這其實就是一個樸實無華的 BFS,唯一不同則是增加了空節點。
Python 代碼:
```
<pre class="calibre18">```
<span class="hljs-class"><span class="hljs-keyword">class</span> <span class="hljs-title">Codec</span>:</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">serialize</span><span class="hljs-params">(self, root)</span>:</span>
ans = <span class="hljs-string">''</span>
queue = [root]
<span class="hljs-keyword">while</span> queue:
node = queue.pop(<span class="hljs-params">0</span>)
<span class="hljs-keyword">if</span> node:
ans += str(node.val) + <span class="hljs-string">','</span>
queue.append(node.left)
queue.append(node.right)
<span class="hljs-keyword">else</span>:
ans += <span class="hljs-string">'#,'</span>
<span class="hljs-keyword">return</span> ans[:<span class="hljs-params">-1</span>]
```
```
### 反序列化
如圖有這樣一棵樹:
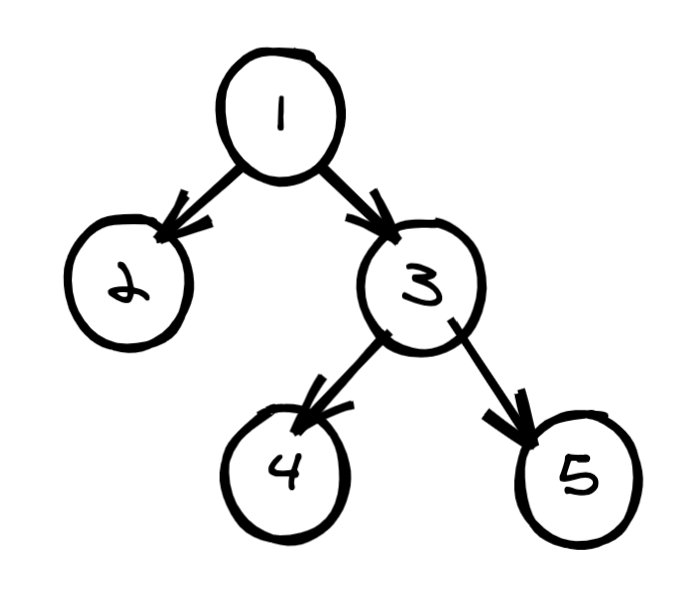
那么其層次遍歷為 \[1,2,3,#,#, 4, 5\]。我們根據此層次遍歷的結果來看下如何還原二叉樹,如下是我畫的一個示意圖:
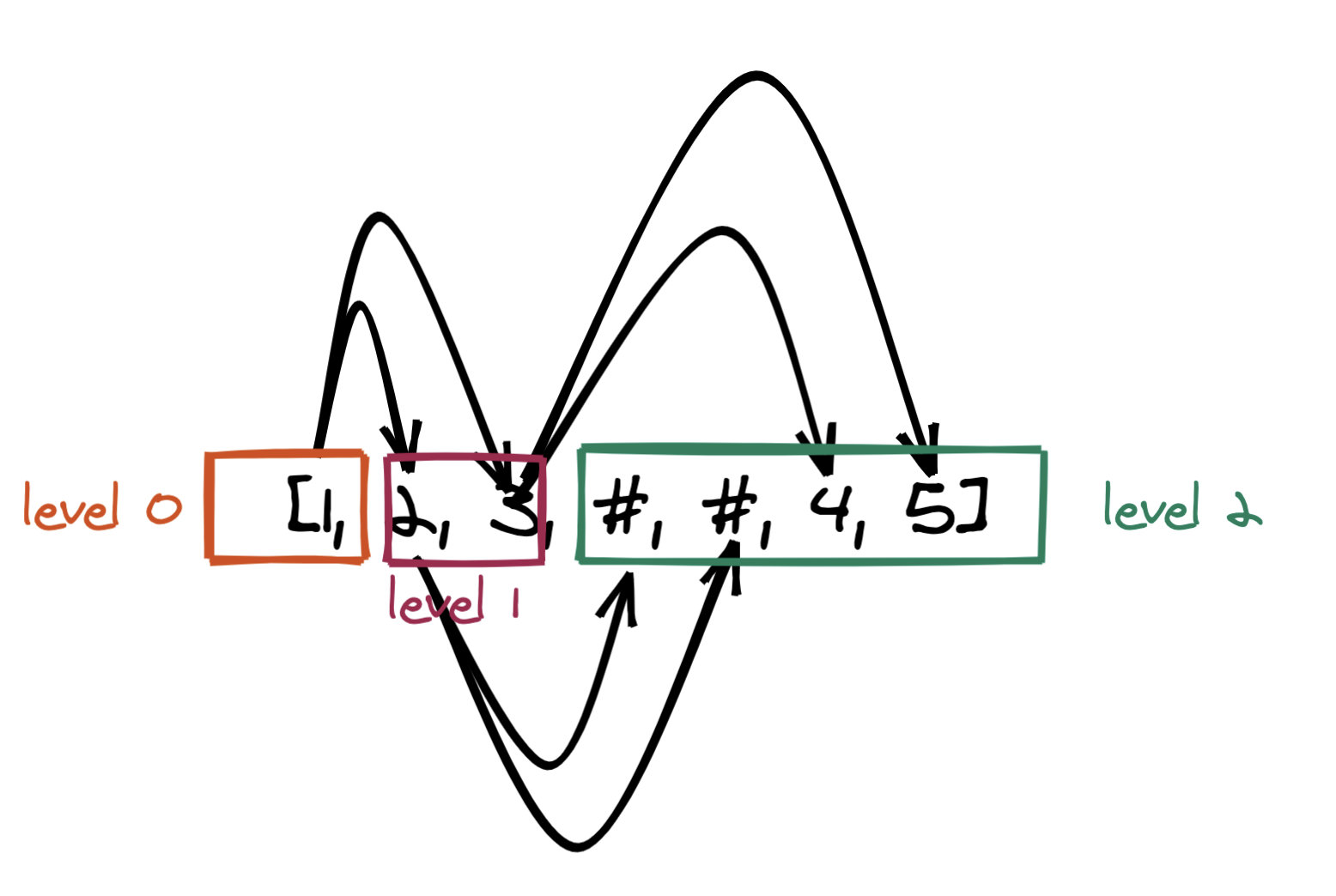
容易看出:
- level x 的節點一定指向 level x + 1 的節點,如何找到 level + 1 呢? 這很容易通過層次遍歷來做到。
- 對于給的的 level x,從左到右依次對應 level x + 1 的節點,即第 1 個節點的左右子節點對應下一層的第 1 個和第 2 個節點,第 2 個節點的左右子節點對應下一層的第 3 個和第 4 個節點。。。
- 接上,其實如果你仔細觀察的話,實際上 level x 和 level x + 1 的判斷是無需特別判斷的。我們可以把思路逆轉過來:`即第 1 個節點的左右子節點對應第 1 個和第 2 個節點,第 2 個節點的左右子節點對應第 3 個和第 4 個節點。。。`(注意,沒了下一層三個字)
因此我們的思路也是同樣的 BFS,并依次連接左右節點。
Python 代碼:
```
<pre class="calibre18">```
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">deserialize</span><span class="hljs-params">(self, data: str)</span>:</span>
<span class="hljs-keyword">if</span> data == <span class="hljs-string">'#'</span>: <span class="hljs-keyword">return</span> <span class="hljs-keyword">None</span>
<span class="hljs-title"># 數據準備</span>
nodes = data.split(<span class="hljs-string">','</span>)
<span class="hljs-keyword">if</span> <span class="hljs-keyword">not</span> nodes: <span class="hljs-keyword">return</span> <span class="hljs-keyword">None</span>
<span class="hljs-title"># BFS</span>
root = TreeNode(nodes[<span class="hljs-params">0</span>])
queue = [root]
<span class="hljs-title"># 已經有 root 了,因此從 1 開始</span>
i = <span class="hljs-params">1</span>
<span class="hljs-keyword">while</span> i < len(nodes) - <span class="hljs-params">1</span>:
node = queue.pop(<span class="hljs-params">0</span>)
<span class="hljs-title">#</span>
lv = nodes[i]
rv = nodes[i + <span class="hljs-params">1</span>]
i += <span class="hljs-params">2</span>
<span class="hljs-title"># 對于給的的 level x,從左到右依次對應 level x + 1 的節點</span>
<span class="hljs-title"># node 是 level x 的節點,l 和 r 則是 level x + 1 的節點</span>
<span class="hljs-keyword">if</span> lv != <span class="hljs-string">'#'</span>:
l = TreeNode(lv)
node.left = l
queue.append(l)
<span class="hljs-keyword">if</span> rv != <span class="hljs-string">'#'</span>:
r = TreeNode(rv)
node.right = r
queue.append(r)
<span class="hljs-keyword">return</span> root
```
```
**復雜度分析**
- 時間復雜度:每個節點都會被處理一次,因此時間復雜度為 O(N)O(N)O(N),其中 NNN 為節點的總數。
- 空間復雜度:O(N)O(N)O(N),其中 NNN 為節點的總數。
## 總結
除了這種方法還有很多方案, 比如括號表示法。 關于這個可以參考力扣[606. 根據二叉樹創建字符串](https://leetcode-cn.com/problems/construct-string-from-binary-tree/),這里就不再贅述了。
本文從 BFS 和 DFS 角度來思考如何序列化和反序列化一棵樹。 如果用 BFS 來序列化,那么相應地也需要 BFS 來反序列化。如果用 DFS 來序列化,那么就需要用 DFS 來反序列化。
我們從馬后炮的角度來說,實際上對于序列化來說,BFS 和 DFS 都比較常規。對于反序列化,大家可以像我這樣舉個例子,畫一個圖。可以先在紙上,電腦上,如果你熟悉了之后,也可以畫在腦子里。

(Like This)
更多題解可以訪問我的 LeetCode 題解倉庫:<https://github.com/azl397985856/leetcode> 。 目前已經 37K star 啦。
關注公眾號力扣加加,努力用清晰直白的語言還原解題思路,并且有大量圖解,手把手教你識別套路,高效刷題。
- Introduction
- 第一章 - 算法專題
- 數據結構
- 基礎算法
- 二叉樹的遍歷
- 動態規劃
- 哈夫曼編碼和游程編碼
- 布隆過濾器
- 字符串問題
- 前綴樹專題
- 《貪婪策略》專題
- 《深度優先遍歷》專題
- 滑動窗口(思路 + 模板)
- 位運算
- 設計題
- 小島問題
- 最大公約數
- 并查集
- 前綴和
- 平衡二叉樹專題
- 第二章 - 91 天學算法
- 第一期講義-二分法
- 第一期講義-雙指針
- 第二期
- 第三章 - 精選題解
- 《日程安排》專題
- 《構造二叉樹》專題
- 字典序列刪除
- 百度的算法面試題 * 祖瑪游戲
- 西法的刷題秘籍】一次搞定前綴和
- 字節跳動的算法面試題是什么難度?
- 字節跳動的算法面試題是什么難度?(第二彈)
- 《我是你的媽媽呀》 * 第一期
- 一文帶你看懂二叉樹的序列化
- 穿上衣服我就不認識你了?來聊聊最長上升子序列
- 你的衣服我扒了 * 《最長公共子序列》
- 一文看懂《最大子序列和問題》
- 第四章 - 高頻考題(簡單)
- 面試題 17.12. BiNode
- 0001. 兩數之和
- 0020. 有效的括號
- 0021. 合并兩個有序鏈表
- 0026. 刪除排序數組中的重復項
- 0053. 最大子序和
- 0088. 合并兩個有序數組
- 0101. 對稱二叉樹
- 0104. 二叉樹的最大深度
- 0108. 將有序數組轉換為二叉搜索樹
- 0121. 買賣股票的最佳時機
- 0122. 買賣股票的最佳時機 II
- 0125. 驗證回文串
- 0136. 只出現一次的數字
- 0155. 最小棧
- 0167. 兩數之和 II * 輸入有序數組
- 0169. 多數元素
- 0172. 階乘后的零
- 0190. 顛倒二進制位
- 0191. 位1的個數
- 0198. 打家劫舍
- 0203. 移除鏈表元素
- 0206. 反轉鏈表
- 0219. 存在重復元素 II
- 0226. 翻轉二叉樹
- 0232. 用棧實現隊列
- 0263. 丑數
- 0283. 移動零
- 0342. 4的冪
- 0349. 兩個數組的交集
- 0371. 兩整數之和
- 0437. 路徑總和 III
- 0455. 分發餅干
- 0575. 分糖果
- 0874. 模擬行走機器人
- 1260. 二維網格遷移
- 1332. 刪除回文子序列
- 第五章 - 高頻考題(中等)
- 0002. 兩數相加
- 0003. 無重復字符的最長子串
- 0005. 最長回文子串
- 0011. 盛最多水的容器
- 0015. 三數之和
- 0017. 電話號碼的字母組合
- 0019. 刪除鏈表的倒數第N個節點
- 0022. 括號生成
- 0024. 兩兩交換鏈表中的節點
- 0029. 兩數相除
- 0031. 下一個排列
- 0033. 搜索旋轉排序數組
- 0039. 組合總和
- 0040. 組合總和 II
- 0046. 全排列
- 0047. 全排列 II
- 0048. 旋轉圖像
- 0049. 字母異位詞分組
- 0050. Pow(x, n)
- 0055. 跳躍游戲
- 0056. 合并區間
- 0060. 第k個排列
- 0062. 不同路徑
- 0073. 矩陣置零
- 0075. 顏色分類
- 0078. 子集
- 0079. 單詞搜索
- 0080. 刪除排序數組中的重復項 II
- 0086. 分隔鏈表
- 0090. 子集 II
- 0091. 解碼方法
- 0092. 反轉鏈表 II
- 0094. 二叉樹的中序遍歷
- 0095. 不同的二叉搜索樹 II
- 0096. 不同的二叉搜索樹
- 0098. 驗證二叉搜索樹
- 0102. 二叉樹的層序遍歷
- 0103. 二叉樹的鋸齒形層次遍歷
- 105. 從前序與中序遍歷序列構造二叉樹
- 0113. 路徑總和 II
- 0129. 求根到葉子節點數字之和
- 0130. 被圍繞的區域
- 0131. 分割回文串
- 0139. 單詞拆分
- 0144. 二叉樹的前序遍歷
- 0150. 逆波蘭表達式求值
- 0152. 乘積最大子數組
- 0199. 二叉樹的右視圖
- 0200. 島嶼數量
- 0201. 數字范圍按位與
- 0208. 實現 Trie (前綴樹)
- 0209. 長度最小的子數組
- 0211. 添加與搜索單詞 * 數據結構設計
- 0215. 數組中的第K個最大元素
- 0221. 最大正方形
- 0229. 求眾數 II
- 0230. 二叉搜索樹中第K小的元素
- 0236. 二叉樹的最近公共祖先
- 0238. 除自身以外數組的乘積
- 0240. 搜索二維矩陣 II
- 0279. 完全平方數
- 0309. 最佳買賣股票時機含冷凍期
- 0322. 零錢兌換
- 0328. 奇偶鏈表
- 0334. 遞增的三元子序列
- 0337. 打家劫舍 III
- 0343. 整數拆分
- 0365. 水壺問題
- 0378. 有序矩陣中第K小的元素
- 0380. 常數時間插入、刪除和獲取隨機元素
- 0416. 分割等和子集
- 0445. 兩數相加 II
- 0454. 四數相加 II
- 0494. 目標和
- 0516. 最長回文子序列
- 0518. 零錢兌換 II
- 0547. 朋友圈
- 0560. 和為K的子數組
- 0609. 在系統中查找重復文件
- 0611. 有效三角形的個數
- 0718. 最長重復子數組
- 0754. 到達終點數字
- 0785. 判斷二分圖
- 0820. 單詞的壓縮編碼
- 0875. 愛吃香蕉的珂珂
- 0877. 石子游戲
- 0886. 可能的二分法
- 0900. RLE 迭代器
- 0912. 排序數組
- 0935. 騎士撥號器
- 1011. 在 D 天內送達包裹的能力
- 1014. 最佳觀光組合
- 1015. 可被 K 整除的最小整數
- 1019. 鏈表中的下一個更大節點
- 1020. 飛地的數量
- 1023. 駝峰式匹配
- 1031. 兩個非重疊子數組的最大和
- 1104. 二叉樹尋路
- 1131.絕對值表達式的最大值
- 1186. 刪除一次得到子數組最大和
- 1218. 最長定差子序列
- 1227. 飛機座位分配概率
- 1261. 在受污染的二叉樹中查找元素
- 1262. 可被三整除的最大和
- 1297. 子串的最大出現次數
- 1310. 子數組異或查詢
- 1334. 閾值距離內鄰居最少的城市
- 1371.每個元音包含偶數次的最長子字符串
- 第六章 - 高頻考題(困難)
- 0004. 尋找兩個正序數組的中位數
- 0023. 合并K個升序鏈表
- 0025. K 個一組翻轉鏈表
- 0030. 串聯所有單詞的子串
- 0032. 最長有效括號
- 0042. 接雨水
- 0052. N皇后 II
- 0084. 柱狀圖中最大的矩形
- 0085. 最大矩形
- 0124. 二叉樹中的最大路徑和
- 0128. 最長連續序列
- 0145. 二叉樹的后序遍歷
- 0212. 單詞搜索 II
- 0239. 滑動窗口最大值
- 0295. 數據流的中位數
- 0301. 刪除無效的括號
- 0312. 戳氣球
- 0335. 路徑交叉
- 0460. LFU緩存
- 0472. 連接詞
- 0488. 祖瑪游戲
- 0493. 翻轉對
- 0887. 雞蛋掉落
- 0895. 最大頻率棧
- 1032. 字符流
- 1168. 水資源分配優化
- 1449. 數位成本和為目標值的最大數字
- 后序