
# 0820. 單詞的壓縮編碼
## 題目地址(820. 單詞的壓縮編碼)
<https://leetcode-cn.com/problems/short-encoding-of-words/>
## 題目描述
```
<pre class="calibre18">```
給定一個單詞列表,我們將這個列表編碼成一個索引字符串 S 與一個索引列表 A。
例如,如果這個列表是 ["time", "me", "bell"],我們就可以將其表示為 S = "time#bell#" 和 indexes = [0, 2, 5]。
對于每一個索引,我們可以通過從字符串 S 中索引的位置開始讀取字符串,直到 "#" 結束,來恢復我們之前的單詞列表。
那么成功對給定單詞列表進行編碼的最小字符串長度是多少呢?
示例:
輸入: words = ["time", "me", "bell"]
輸出: 10
說明: S = "time#bell#" , indexes = [0, 2, 5] 。
提示:
1 <= words.length <= 2000
1 <= words[i].length <= 7
每個單詞都是小寫字母 。
```
```
## 前置知識
- 前綴樹
## 公司
- 阿里
- 字節
## 思路
讀完題目之后就發現如果將列表中每一個單詞分別倒序就是一個后綴樹問題。比如 `["time", "me", "bell"]` 倒序之后就是 \["emit", "em", "lleb"\],我們要求的結果無非就是 "emit" 的長度 + "llem"的長度 + "##"的長度(em 和 emit 有公共前綴,計算一個就好了)。
因此符合直覺的想法是使用前綴樹 + 倒序插入的形式來模擬后綴樹。
下面的代碼看起來復雜,但是很多題目我都是用這個模板,稍微調整下細節就能 AC。我這里總結了一套[前綴樹專題](https://github.com/azl397985856/leetcode/blob/master/thinkings/trie.md)

前綴樹的 api 主要有以下幾個:
- `insert(word)`: 插入一個單詞
- `search(word)`:查找一個單詞是否存在
- `startWith(word)`: 查找是否存在以 word 為前綴的單詞
其中 startWith 是前綴樹最核心的用法,其名稱前綴樹就從這里而來。大家可以先拿 208 題開始,熟悉一下前綴樹,然后再嘗試別的題目。
一個前綴樹大概是這個樣子:
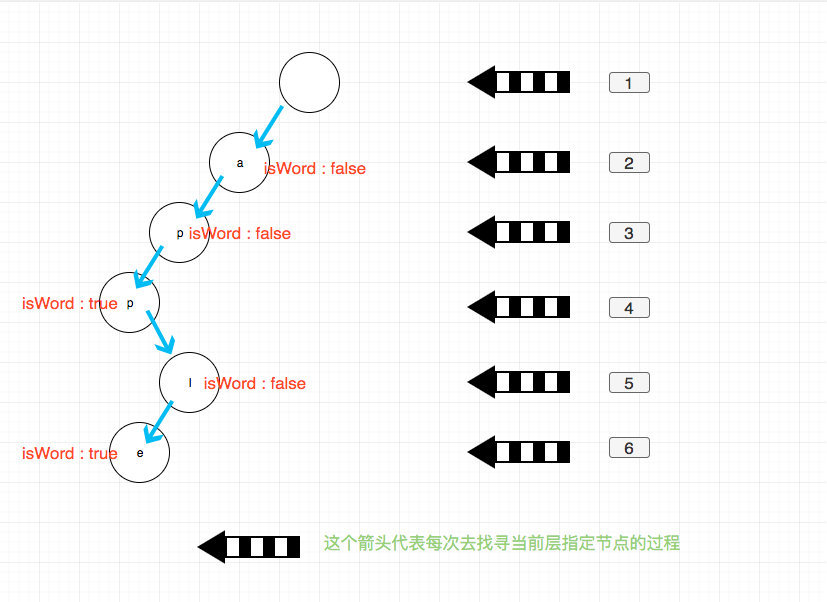
如圖每一個節點存儲一個字符,然后外加一個控制信息表示是否是單詞結尾,實際使用過程可能會有細微差別,不過變化不大。
這道題需要考慮 edge case, 比如這個列表是 \["time", "time", "me", "bell"\] 這種包含重復元素的情況,這里我使用 hashset 來去重。
## 關鍵點
- 前綴樹
- 去重
## 代碼
```
<pre class="calibre18">```
<span class="hljs-class"><span class="hljs-keyword">class</span> <span class="hljs-title">Trie</span>:</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">__init__</span><span class="hljs-params">(self)</span>:</span>
<span class="hljs-string">"""
Initialize your data structure here.
"""</span>
self.Trie = {}
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">insert</span><span class="hljs-params">(self, word)</span>:</span>
<span class="hljs-string">"""
Inserts a word into the trie.
:type word: str
:rtype: void
"""</span>
curr = self.Trie
<span class="hljs-keyword">for</span> w <span class="hljs-keyword">in</span> word:
<span class="hljs-keyword">if</span> w <span class="hljs-keyword">not</span> <span class="hljs-keyword">in</span> curr:
curr[w] = {}
curr = curr[w]
curr[<span class="hljs-string">'#'</span>] = <span class="hljs-params">1</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">search</span><span class="hljs-params">(self, word)</span>:</span>
<span class="hljs-string">"""
Returns if the word is in the trie.
:type word: str
:rtype: bool
"""</span>
curr = self.Trie
<span class="hljs-keyword">for</span> w <span class="hljs-keyword">in</span> word:
curr = curr[w]
<span class="hljs-title"># len(curr) == 1 means we meet '#'</span>
<span class="hljs-title"># when we search 'em'(which reversed from 'me')</span>
<span class="hljs-title"># the result is len(curr) > 1</span>
<span class="hljs-title"># cause the curr look like { '#': 1, i: {...}}</span>
<span class="hljs-keyword">return</span> len(curr) == <span class="hljs-params">1</span>
<span class="hljs-class"><span class="hljs-keyword">class</span> <span class="hljs-title">Solution</span>:</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">minimumLengthEncoding</span><span class="hljs-params">(self, words: List[str])</span> -> int:</span>
trie = Trie()
cnt = <span class="hljs-params">0</span>
words = set(words)
<span class="hljs-keyword">for</span> word <span class="hljs-keyword">in</span> words:
trie.insert(word[::<span class="hljs-params">-1</span>])
<span class="hljs-keyword">for</span> word <span class="hljs-keyword">in</span> words:
<span class="hljs-keyword">if</span> trie.search(word[::<span class="hljs-params">-1</span>]):
cnt += len(word) + <span class="hljs-params">1</span>
<span class="hljs-keyword">return</span> cnt
```
```
***復雜度分析***
- 時間復雜度:O(N)O(N)O(N),其中 N 為單詞長度列表中的總字符數,比如\["time", "me"\],就是 4 + 2 = 6。
- 空間復雜度:O(N)O(N)O(N),其中 N 為單詞長度列表中的總字符數,比如\["time", "me"\],就是 4 + 2 = 6。
大家也可以關注我的公眾號《力扣加加》獲取更多更新鮮的 LeetCode 題解

## 相關題目
- [0208.implement-trie-prefix-tree](208.implement-trie-prefix-tree.html)
- [0211.add-and-search-word-data-structure-design](211.add-and-search-word-data-structure-design.html)
- [0212.word-search-ii](212.word-search-ii.html)
- [0472.concatenated-words](472.concatenated-words.html)
- [0820.short-encoding-of-words](https://github.com/azl397985856/leetcode/blob/master/problems/820.short-encoding-of-words.md)
- [1032.stream-of-characters](https://github.com/azl397985856/leetcode/blob/master/problems/1032.stream-of-characters.md)
- Introduction
- 第一章 - 算法專題
- 數據結構
- 基礎算法
- 二叉樹的遍歷
- 動態規劃
- 哈夫曼編碼和游程編碼
- 布隆過濾器
- 字符串問題
- 前綴樹專題
- 《貪婪策略》專題
- 《深度優先遍歷》專題
- 滑動窗口(思路 + 模板)
- 位運算
- 設計題
- 小島問題
- 最大公約數
- 并查集
- 前綴和
- 平衡二叉樹專題
- 第二章 - 91 天學算法
- 第一期講義-二分法
- 第一期講義-雙指針
- 第二期
- 第三章 - 精選題解
- 《日程安排》專題
- 《構造二叉樹》專題
- 字典序列刪除
- 百度的算法面試題 * 祖瑪游戲
- 西法的刷題秘籍】一次搞定前綴和
- 字節跳動的算法面試題是什么難度?
- 字節跳動的算法面試題是什么難度?(第二彈)
- 《我是你的媽媽呀》 * 第一期
- 一文帶你看懂二叉樹的序列化
- 穿上衣服我就不認識你了?來聊聊最長上升子序列
- 你的衣服我扒了 * 《最長公共子序列》
- 一文看懂《最大子序列和問題》
- 第四章 - 高頻考題(簡單)
- 面試題 17.12. BiNode
- 0001. 兩數之和
- 0020. 有效的括號
- 0021. 合并兩個有序鏈表
- 0026. 刪除排序數組中的重復項
- 0053. 最大子序和
- 0088. 合并兩個有序數組
- 0101. 對稱二叉樹
- 0104. 二叉樹的最大深度
- 0108. 將有序數組轉換為二叉搜索樹
- 0121. 買賣股票的最佳時機
- 0122. 買賣股票的最佳時機 II
- 0125. 驗證回文串
- 0136. 只出現一次的數字
- 0155. 最小棧
- 0167. 兩數之和 II * 輸入有序數組
- 0169. 多數元素
- 0172. 階乘后的零
- 0190. 顛倒二進制位
- 0191. 位1的個數
- 0198. 打家劫舍
- 0203. 移除鏈表元素
- 0206. 反轉鏈表
- 0219. 存在重復元素 II
- 0226. 翻轉二叉樹
- 0232. 用棧實現隊列
- 0263. 丑數
- 0283. 移動零
- 0342. 4的冪
- 0349. 兩個數組的交集
- 0371. 兩整數之和
- 0437. 路徑總和 III
- 0455. 分發餅干
- 0575. 分糖果
- 0874. 模擬行走機器人
- 1260. 二維網格遷移
- 1332. 刪除回文子序列
- 第五章 - 高頻考題(中等)
- 0002. 兩數相加
- 0003. 無重復字符的最長子串
- 0005. 最長回文子串
- 0011. 盛最多水的容器
- 0015. 三數之和
- 0017. 電話號碼的字母組合
- 0019. 刪除鏈表的倒數第N個節點
- 0022. 括號生成
- 0024. 兩兩交換鏈表中的節點
- 0029. 兩數相除
- 0031. 下一個排列
- 0033. 搜索旋轉排序數組
- 0039. 組合總和
- 0040. 組合總和 II
- 0046. 全排列
- 0047. 全排列 II
- 0048. 旋轉圖像
- 0049. 字母異位詞分組
- 0050. Pow(x, n)
- 0055. 跳躍游戲
- 0056. 合并區間
- 0060. 第k個排列
- 0062. 不同路徑
- 0073. 矩陣置零
- 0075. 顏色分類
- 0078. 子集
- 0079. 單詞搜索
- 0080. 刪除排序數組中的重復項 II
- 0086. 分隔鏈表
- 0090. 子集 II
- 0091. 解碼方法
- 0092. 反轉鏈表 II
- 0094. 二叉樹的中序遍歷
- 0095. 不同的二叉搜索樹 II
- 0096. 不同的二叉搜索樹
- 0098. 驗證二叉搜索樹
- 0102. 二叉樹的層序遍歷
- 0103. 二叉樹的鋸齒形層次遍歷
- 105. 從前序與中序遍歷序列構造二叉樹
- 0113. 路徑總和 II
- 0129. 求根到葉子節點數字之和
- 0130. 被圍繞的區域
- 0131. 分割回文串
- 0139. 單詞拆分
- 0144. 二叉樹的前序遍歷
- 0150. 逆波蘭表達式求值
- 0152. 乘積最大子數組
- 0199. 二叉樹的右視圖
- 0200. 島嶼數量
- 0201. 數字范圍按位與
- 0208. 實現 Trie (前綴樹)
- 0209. 長度最小的子數組
- 0211. 添加與搜索單詞 * 數據結構設計
- 0215. 數組中的第K個最大元素
- 0221. 最大正方形
- 0229. 求眾數 II
- 0230. 二叉搜索樹中第K小的元素
- 0236. 二叉樹的最近公共祖先
- 0238. 除自身以外數組的乘積
- 0240. 搜索二維矩陣 II
- 0279. 完全平方數
- 0309. 最佳買賣股票時機含冷凍期
- 0322. 零錢兌換
- 0328. 奇偶鏈表
- 0334. 遞增的三元子序列
- 0337. 打家劫舍 III
- 0343. 整數拆分
- 0365. 水壺問題
- 0378. 有序矩陣中第K小的元素
- 0380. 常數時間插入、刪除和獲取隨機元素
- 0416. 分割等和子集
- 0445. 兩數相加 II
- 0454. 四數相加 II
- 0494. 目標和
- 0516. 最長回文子序列
- 0518. 零錢兌換 II
- 0547. 朋友圈
- 0560. 和為K的子數組
- 0609. 在系統中查找重復文件
- 0611. 有效三角形的個數
- 0718. 最長重復子數組
- 0754. 到達終點數字
- 0785. 判斷二分圖
- 0820. 單詞的壓縮編碼
- 0875. 愛吃香蕉的珂珂
- 0877. 石子游戲
- 0886. 可能的二分法
- 0900. RLE 迭代器
- 0912. 排序數組
- 0935. 騎士撥號器
- 1011. 在 D 天內送達包裹的能力
- 1014. 最佳觀光組合
- 1015. 可被 K 整除的最小整數
- 1019. 鏈表中的下一個更大節點
- 1020. 飛地的數量
- 1023. 駝峰式匹配
- 1031. 兩個非重疊子數組的最大和
- 1104. 二叉樹尋路
- 1131.絕對值表達式的最大值
- 1186. 刪除一次得到子數組最大和
- 1218. 最長定差子序列
- 1227. 飛機座位分配概率
- 1261. 在受污染的二叉樹中查找元素
- 1262. 可被三整除的最大和
- 1297. 子串的最大出現次數
- 1310. 子數組異或查詢
- 1334. 閾值距離內鄰居最少的城市
- 1371.每個元音包含偶數次的最長子字符串
- 第六章 - 高頻考題(困難)
- 0004. 尋找兩個正序數組的中位數
- 0023. 合并K個升序鏈表
- 0025. K 個一組翻轉鏈表
- 0030. 串聯所有單詞的子串
- 0032. 最長有效括號
- 0042. 接雨水
- 0052. N皇后 II
- 0084. 柱狀圖中最大的矩形
- 0085. 最大矩形
- 0124. 二叉樹中的最大路徑和
- 0128. 最長連續序列
- 0145. 二叉樹的后序遍歷
- 0212. 單詞搜索 II
- 0239. 滑動窗口最大值
- 0295. 數據流的中位數
- 0301. 刪除無效的括號
- 0312. 戳氣球
- 0335. 路徑交叉
- 0460. LFU緩存
- 0472. 連接詞
- 0488. 祖瑪游戲
- 0493. 翻轉對
- 0887. 雞蛋掉落
- 0895. 最大頻率棧
- 1032. 字符流
- 1168. 水資源分配優化
- 1449. 數位成本和為目標值的最大數字
- 后序