
# 字節跳動的算法面試題是什么難度?(第二彈)
# 字節跳動的算法面試題是什么難度?(第二彈)
由于 lucifer 我是一個小前端, 最近也在準備寫一個《前端如何搞定算法面試》的專欄,因此最近沒少看各大公司的面試題。都說字節跳動算法題比較難,我就先拿 ta 下手,做了幾套 。這次我們就拿一套 `字節跳動2017秋招編程題匯總`來看下字節的算法筆試題的難度幾何。地址:<https://www.nowcoder.com/test/6035789/summary>
這套題一共 11 道題, 三道編程題, 八道問答題。本次給大家帶來的就是這三道編程題。更多精彩內容,請期待我的搞定算法面試專欄。
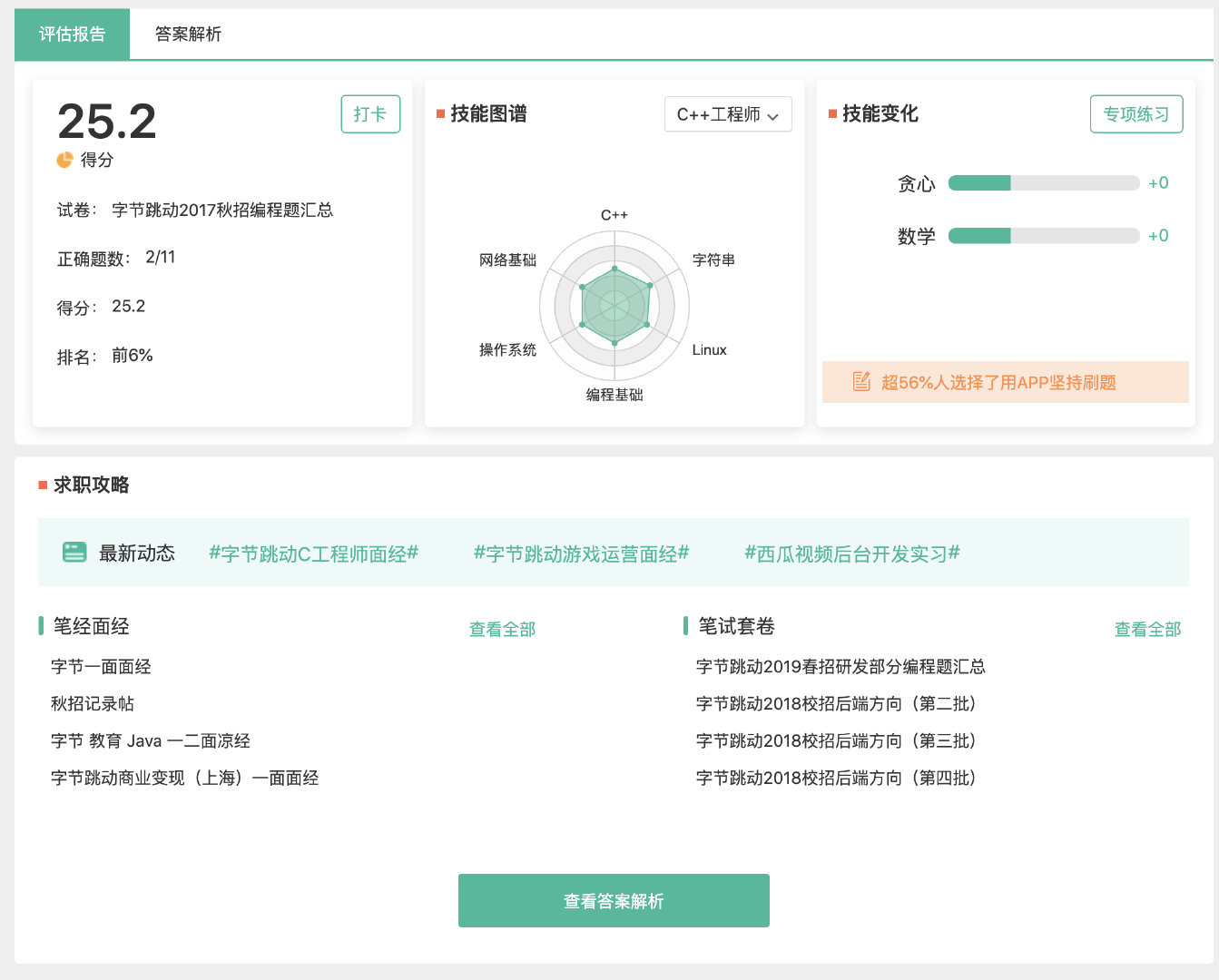
其中有一道題《異或》我沒有通過所有的測試用例, 小伙伴可以找找茬,第一個找到并在公眾號力扣加加留言的小伙伴獎勵現金紅包 10 元。
## 1. 頭條校招
### 題目描述
```
<pre class="calibre18">```
頭條的 2017 校招開始了!為了這次校招,我們組織了一個規模宏大的出題團隊,每個出題人都出了一些有趣的題目,而我們現在想把這些題目組合成若干場考試出來,在選題之前,我們對題目進行了盲審,并定出了每道題的難度系統。一場考試包含 3 道開放性題目,假設他們的難度從小到大分別為 a,b,c,我們希望這 3 道題能滿足下列條件:
a<=b<=c
b-a<=10
c-b<=10
所有出題人一共出了 n 道開放性題目。現在我們想把這 n 道題分布到若干場考試中(1 場或多場,每道題都必須使用且只能用一次),然而由于上述條件的限制,可能有一些考試沒法湊夠 3 道題,因此出題人就需要多出一些適當難度的題目來讓每場考試都達到要求,然而我們出題已經出得很累了,你能計算出我們最少還需要再出幾道題嗎?
輸入描述:
輸入的第一行包含一個整數 n,表示目前已經出好的題目數量。
第二行給出每道題目的難度系數 d1,d2,...,dn。
數據范圍
對于 30%的數據,1 ≤ n,di ≤ 5;
對于 100%的數據,1 ≤ n ≤ 10^5,1 ≤ di ≤ 100。
在樣例中,一種可行的方案是添加 2 個難度分別為 20 和 50 的題目,這樣可以組合成兩場考試:(20 20 23)和(35,40,50)。
輸出描述:
輸出只包括一行,即所求的答案。
示例 1
輸入
4
20 35 23 40
輸出
2
```
```
### 思路
這道題看起來很復雜, 你需要考慮很多的情況。,屬于那種沒有技術含量,但是考驗編程能力的題目,需要思維足夠嚴密。這種**模擬的題目**,就是題目讓我干什么我干什么。 類似之前寫的囚徒房間問題,約瑟夫環也是模擬,只不過模擬之后需要你剪枝優化。
這道題的情況其實很多, 我們需要考慮每一套題中的難度情況, 而不需要考慮不同套題的難度情況。題目要求我們滿足:`a<=b<=c b-a<=10 c-b<=10`,也就是題目難度從小到大排序之后,相鄰的難度不能大于 10 。
因此我們的思路就是先排序,之后從小到大遍歷,如果滿足相鄰的難度不大于 10 ,則繼續。如果不滿足, 我們就只能讓字節的老師出一道題使得滿足條件。
由于只需要比較同一套題目的難度,因此我的想法就是**比較同一套題目的第二個和第一個,以及第三個和第二個的 diff**。
- 如果 diff 小于 10,什么都不做,繼續。
- 如果 diff 大于 10,我們必須補充題目。
這里有幾個點需要注意。
對于第二題來說:
- 比如 1 **30** 40 這樣的難度。 我可以在 1,30 之間加一個 21,這樣 1,21,30 就可以組成一一套。
- 比如 1 **50** 60 這樣的難度。 我可以在 1,50 之間加 21, 41 才可以組成一套,自身(50)是無論如何都沒辦法組到這套題中的。
不難看出, 第二道題的臨界點是 diff = 20 。 小于等于 20 都可以將自身組到套題,增加一道即可,否則需要增加兩個,并且自身不能組到當前套題。
對于第三題來說:
- 比如 1 20 **40**。 我可以在 20,40 之間加一個 30,這樣 1,20,30 就可以組成一一套,自身(40)是無法組到這套題的。
- 比如 1 20 **60**。 也是一樣的,我可以在 20,60 之間加一個 30,自身(60)同樣是沒辦法組到這套題中的。
不難看出, 第三道題的臨界點是 diff = 10 。 小于等于 10 都可以將自身組到套題,否則需要增加一個,并且自身不能組到當前套題。
這就是所有的情況了。
有的同學比較好奇,我是怎么思考的。 我是怎么**保障不重不漏**的。
實際上,這道題就是一個決策樹, 我畫個決策樹出來你就明白了。
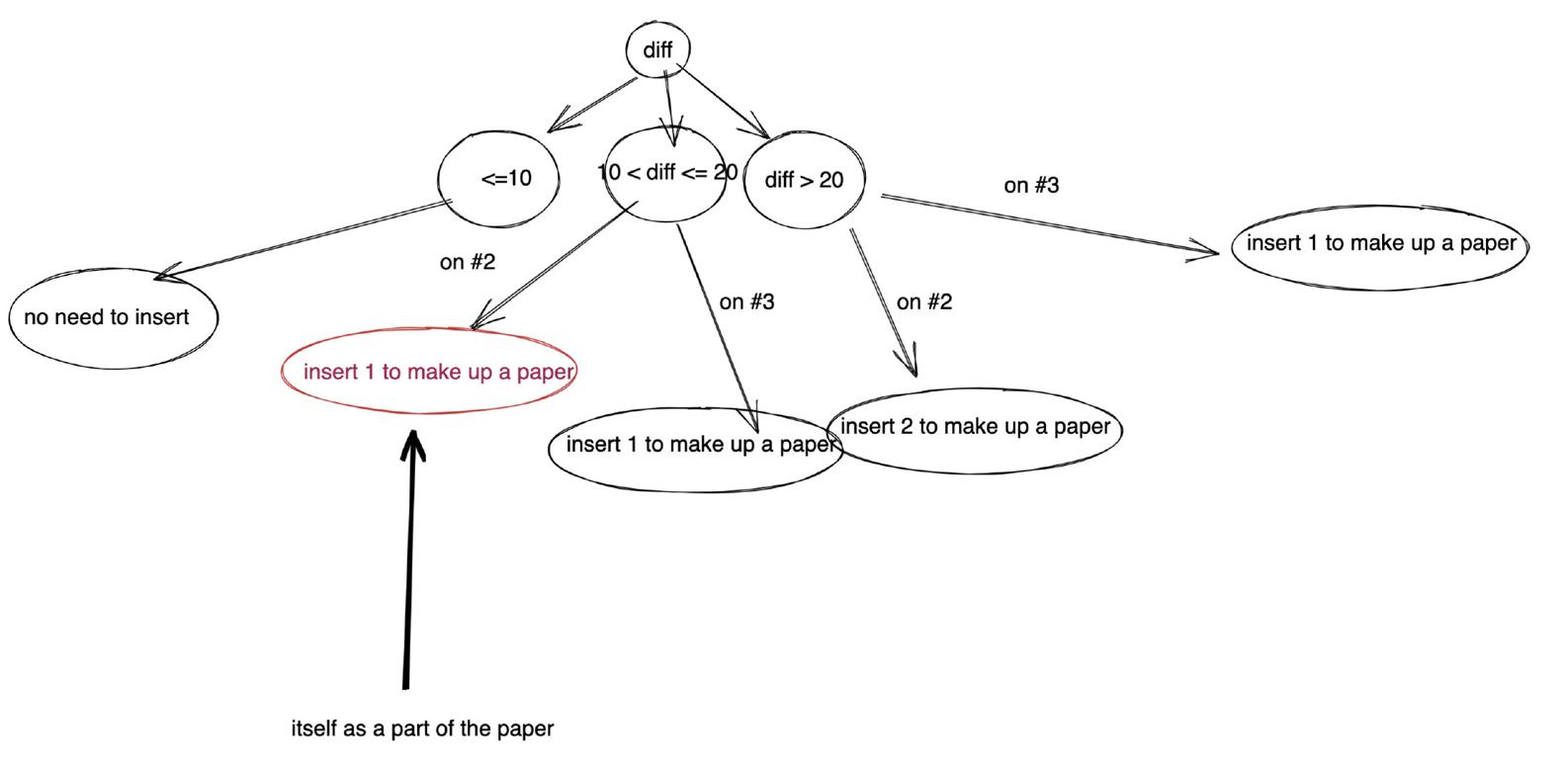
> 圖中紅色邊框表示自身可以組成套題的一部分, 我也用文字進行了說明。#2 代表第二題, #3 代表第三題。
從圖中可以看出, 我已經考慮了所有情況。如果你能夠像我一樣畫出這個決策圖,我想你也不會漏的。當然我的解法并不一定是最優的,不過確實是一個非常好用,具有普適性的思維框架。
需要特別注意的是,由于需要湊整, 因此你需要使得題目的總數是 3 的倍數向上取整。
### 代碼
```
<pre class="calibre18">```
n = int(input())
nums = list(map(int, input().split()))
cnt = <span class="hljs-params">0</span>
cur = <span class="hljs-params">1</span>
nums.sort()
<span class="hljs-keyword">for</span> i <span class="hljs-keyword">in</span> range(<span class="hljs-params">1</span>, n):
<span class="hljs-keyword">if</span> cur == <span class="hljs-params">3</span>:
cur = <span class="hljs-params">1</span>
<span class="hljs-keyword">continue</span>
diff = nums[i] - nums[i - <span class="hljs-params">1</span>]
<span class="hljs-keyword">if</span> diff <= <span class="hljs-params">10</span>:
cur += <span class="hljs-params">1</span>
<span class="hljs-keyword">if</span> <span class="hljs-params">10</span> < diff <= <span class="hljs-params">20</span>:
<span class="hljs-keyword">if</span> cur == <span class="hljs-params">1</span>:
cur = <span class="hljs-params">3</span>
<span class="hljs-keyword">if</span> cur == <span class="hljs-params">2</span>:
cur = <span class="hljs-params">1</span>
cnt += <span class="hljs-params">1</span>
<span class="hljs-keyword">if</span> diff > <span class="hljs-params">20</span>:
<span class="hljs-keyword">if</span> cur == <span class="hljs-params">1</span>:
cnt += <span class="hljs-params">2</span>
<span class="hljs-keyword">if</span> cur == <span class="hljs-params">2</span>:
cnt += <span class="hljs-params">1</span>
cur = <span class="hljs-params">1</span>
print(cnt + <span class="hljs-params">3</span> - cur)
```
```
**復雜度分析**
- 時間復雜度:由于使用了排序, 因此時間復雜度為 O(NlogN)O(NlogN)O(NlogN)。(假設使用了基于比較的排序)
- 空間復雜度:O(1)O(1)O(1)
## 2. 異或
### 題目描述
```
<pre class="calibre18">```
給定整數 m 以及 n 各數字 A1,A2,..An,將數列 A 中所有元素兩兩異或,共能得到 n(n-1)/2 個結果,請求出這些結果中大于 m 的有多少個。
輸入描述:
第一行包含兩個整數 n,m.
第二行給出 n 個整數 A1,A2,...,An。
數據范圍
對于 30%的數據,1 <= n, m <= 1000
對于 100%的數據,1 <= n, m, Ai <= 10^5
輸出描述:
輸出僅包括一行,即所求的答案
輸入例子 1:
3 10
6 5 10
輸出例子 1:
2
```
```
### 前置知識
- 異或運算的性質
- 如何高效比較兩個數的大小(從高位到低位)
首先普及一下前置知識。 第一個是異或運算:
異或的性質:兩個數字異或的結果 a^b 是將 a 和 b 的二進制每一位進行運算,得出的數字。 運算的邏輯是如果同一位的數字相同則為 0,不同則為 1
異或的規律:
1. 任何數和本身異或則為 0
2. 任何數和 0 異或是本身
3. 異或運算滿足交換律,即: a ^ b ^ c = a ^ c ^ b
同時建議大家去看下我總結的幾道位運算的經典題目。 [位運算系列](https://leetcode-cn.com/problems/single-number/solution/zhi-chu-xian-yi-ci-de-shu-xi-lie-wei-yun-suan-by-3/ "位運算系列")
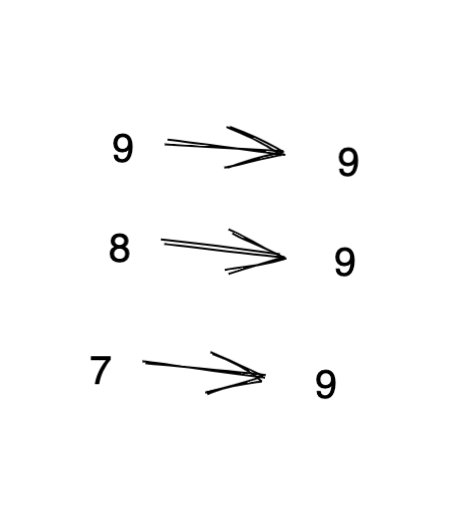
其次要知道一個常識, 即比較兩個數的大小, 我們是從高位到低位比較,這樣才比較高效。
比如:
```
<pre class="calibre18">```
123
456
1234
```
```
這三個數比較大小, 為了方便我們先補 0 ,使得大家的位數保持一致。
```
<pre class="calibre18">```
0123
0456
1234
```
```
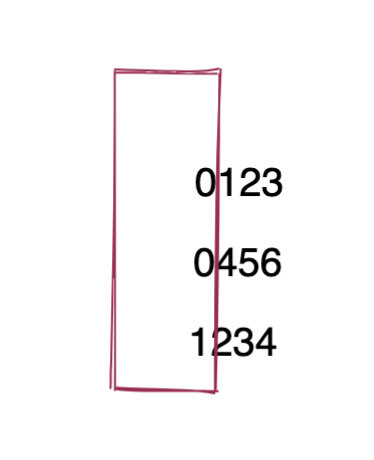
先比較第一位,1 比較 0 大, 因此 1234 最大。再比較第二位, 4 比 1 大, 因此 456 大于 123,后面位不需要比較了。這其實就是剪枝的思想。
有了這兩個前提,我們來試下暴力法解決這道題。
### 思路
暴力法就是枚舉 N2/2N^2 / 2N2/2 中組合, 讓其兩兩按位異或,將得到的結果和 m 進行比較, 如果比 m 大, 則計數器 + 1, 最后返回計數器的值即可。
暴力的方法就如同題目描述的那樣, 復雜度為 N2N^2N2。 一定過不了所有的測試用例, 不過大家實在沒有好的解法的情況可以兜底。不管是牛客筆試還是實際的面試都是可行的。
接下來,讓我們來**分析一下暴力為什么低效,以及如何選取數據結構和算法能夠使得這個過程變得高效。** 記住這句話, 幾乎所有的優化都是基于這種思維產生的,除非你開啟了上帝模式,直接看了答案。 只不過等你熟悉了之后,這個思維過程會非常短, 以至于變成條件反射, 你感覺不到有這個過程, 這就是**有了題感。**
其實我剛才說的第二個前置知識就是我們優化的關鍵之一。
我舉個例子, 比如 3 和 5 按位異或。
3 的二進制是 011, 5 的二進制是 101,
```
<pre class="calibre18">```
011
101
```
```
按照我前面講的異或知識, 不難得出其異或結構就是 110。
上面我進行了三次異或:
1. 第一次是最高位的 0 和 1 的異或, 結果為 1。
2. 第二次是次高位的 1 和 0 的異或, 結果為 1。
3. 第三次是最低位的 1 和 1 的異或, 結果為 0。
那如何 m 是 1 呢? 我們有必要進行三次異或么? 實際上進行第一次異或的時候已經知道了一定比 m(m 是 1) 大。因為第一次異或的結構導致其最高位為 1,也就是說其最小也不過是 100,也就是 4,一定是大于 1 的。這就是**剪枝**, 這就是算法優化的關鍵。
> 看出我一步一步的思維過程了么?所有的算法優化都需要經過類似的過程。
因此我的算法就是從高位開始兩兩異或,并且異或的結果和 m 對應的二進制位比較大小。
- 如果比 m 對應的二進制位大或者小,我們提前退出即可。
- 如果相等,我們繼續往低位移動重復這個過程。
這雖然已經剪枝了,但是極端情況下,性能還是很差。比如:
```
<pre class="calibre18">```
m: 1111
a: 1010
b: 0101
```
```
a,b 表示兩個數,我們比較到最后才發現,其異或的值和 m 相等。因此極端情況,算法效率沒有得到改進。
這里我想到了一點,就是如果一個數 a 的前綴和另外一個數 b 的前綴是一樣的,那么 c 和 a 或者 c 和 b 的異或的結構前綴部分一定也是一樣的。比如:
```
<pre class="calibre18">```
a: 111000
b: 111101
c: 101011
```
```
a 和 b 有共同的前綴 111,c 和 a 異或過了,當再次和 b 異或的時候,實際上前三位是沒有必要進行的,這也是重復的部分。這就是算法可以優化的部分, 這就是剪枝。
**分析算法,找到算法的瓶頸部分,然后選取合適的數據結構和算法來優化到。** 這句話很重要, 請務必記住。
在這里,我們用的就是剪枝技術,關于剪枝,91 天學算法也有詳細的介紹。
回到前面講到的算法瓶頸, 多個數是有共同前綴的, 前綴部分就是我們浪費的運算次數, 說到前綴大家應該可以想到前綴樹。如果不熟悉前綴樹的話,看下我的這個[前綴樹專題](https://github.com/azl397985856/leetcode/blob/master/thinkings/trie.md "前綴樹專題"),里面的題全部手寫一遍就差不多了。
因此一種想法就是建立一個前綴樹, **樹的根就是最高的位**。 由于題目要求異或, 我們知道異或是二進制的位運算, 因此這棵樹要存二進制才比較好。
反手看了一眼數據范圍:m, n<=10^5 。 10^5 = 2 ^ x,我們的目標是求出 滿足條件的 x 的 ceil(向上取整),因此 x 應該是 17。
樹的每一個節點存儲的是:**n 個數中,從根節點到當前節點形成的前綴有多少個是一樣的**,即多少個數的前綴是一樣的。這樣可以剪枝,提前退出的時候,就直接取出來用了。比如異或的結果是 1, m 當前二進制位是 0 ,那么這個前綴有 10 個,我都不需要比較了, 計數器直接 + 10 。
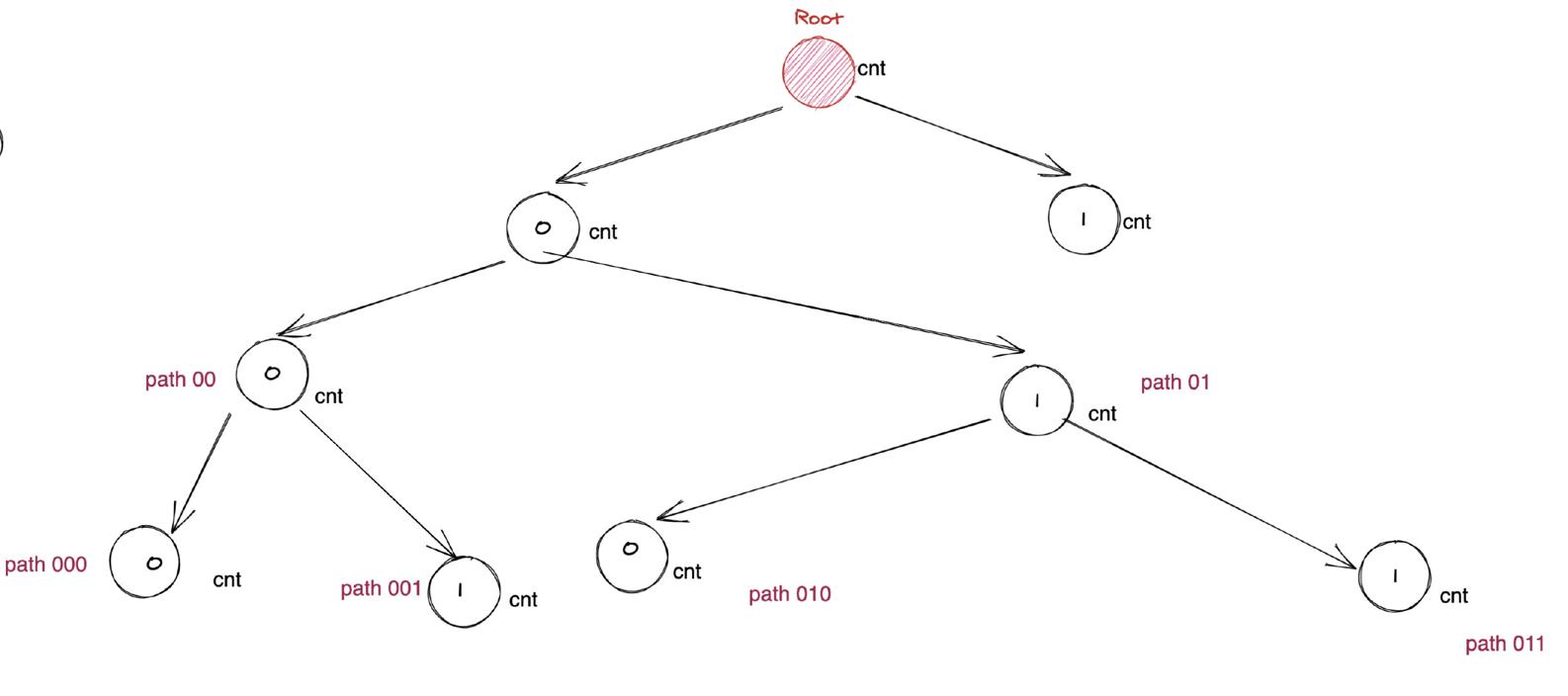
> 我用 17 直接復雜度過高,目前僅僅通過了 70 % - 80 % 測試用例, 希望大家可以幫我找找毛病,我猜測是語言的鍋。
### 代碼
```
<pre class="calibre18">```
<span class="hljs-class"><span class="hljs-keyword">class</span> <span class="hljs-title">TreeNode</span>:</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">__init__</span><span class="hljs-params">(self)</span>:</span>
self.cnt = <span class="hljs-params">1</span>
self.children = [<span class="hljs-keyword">None</span>] * <span class="hljs-params">2</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">solve</span><span class="hljs-params">(num, i, cur)</span>:</span>
<span class="hljs-keyword">if</span> cur == <span class="hljs-keyword">None</span> <span class="hljs-keyword">or</span> i == <span class="hljs-params">-1</span>: <span class="hljs-keyword">return</span> <span class="hljs-params">0</span>
bit = (num >> i) & <span class="hljs-params">1</span>
mbit = (m >> i) & <span class="hljs-params">1</span>
<span class="hljs-keyword">if</span> bit == <span class="hljs-params">0</span> <span class="hljs-keyword">and</span> mbit == <span class="hljs-params">0</span>:
<span class="hljs-keyword">return</span> (cur.children[<span class="hljs-params">1</span>].cnt <span class="hljs-keyword">if</span> cur.children[<span class="hljs-params">1</span>] <span class="hljs-keyword">else</span> <span class="hljs-params">0</span>) + solve(num, i - <span class="hljs-params">1</span>, cur.children[<span class="hljs-params">0</span>])
<span class="hljs-keyword">if</span> bit == <span class="hljs-params">1</span> <span class="hljs-keyword">and</span> mbit == <span class="hljs-params">0</span>:
<span class="hljs-keyword">return</span> (cur.children[<span class="hljs-params">0</span>].cnt <span class="hljs-keyword">if</span> cur.children[<span class="hljs-params">0</span>] <span class="hljs-keyword">else</span> <span class="hljs-params">0</span>) + solve(num, i - <span class="hljs-params">1</span>, cur.children[<span class="hljs-params">1</span>])
<span class="hljs-keyword">if</span> bit == <span class="hljs-params">0</span> <span class="hljs-keyword">and</span> mbit == <span class="hljs-params">1</span>:
<span class="hljs-keyword">return</span> solve(num, i - <span class="hljs-params">1</span>, cur.children[<span class="hljs-params">1</span>])
<span class="hljs-keyword">if</span> bit == <span class="hljs-params">1</span> <span class="hljs-keyword">and</span> mbit == <span class="hljs-params">1</span>:
<span class="hljs-keyword">return</span> solve(num, i - <span class="hljs-params">1</span>, cur.children[<span class="hljs-params">0</span>])
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">preprocess</span><span class="hljs-params">(nums, root)</span>:</span>
<span class="hljs-keyword">for</span> num <span class="hljs-keyword">in</span> nums:
cur = root
<span class="hljs-keyword">for</span> i <span class="hljs-keyword">in</span> range(<span class="hljs-params">16</span>, <span class="hljs-params">-1</span>, <span class="hljs-params">-1</span>):
bit = (num >> i) & <span class="hljs-params">1</span>
<span class="hljs-keyword">if</span> cur.children[bit]:
cur.children[bit].cnt += <span class="hljs-params">1</span>
<span class="hljs-keyword">else</span>:
cur.children[bit] = TreeNode()
cur = cur.children[bit]
n, m = map(int, input().split())
nums = list(map(int, input().split()))
root = TreeNode()
preprocess(nums, root)
ans = <span class="hljs-params">0</span>
<span class="hljs-keyword">for</span> num <span class="hljs-keyword">in</span> nums:
ans += solve(num, <span class="hljs-params">16</span>, root)
print(ans // <span class="hljs-params">2</span>)
```
```
**復雜度分析**
- 時間復雜度:O(N)O(N)O(N)
- 空間復雜度:O(N)O(N)O(N)
## 3. 字典序
### 題目描述
```
<pre class="calibre18">```
給定整數 n 和 m, 將 1 到 n 的這 n 個整數按字典序排列之后, 求其中的第 m 個數。
對于 n=11, m=4, 按字典序排列依次為 1, 10, 11, 2, 3, 4, 5, 6, 7, 8, 9, 因此第 4 個數是 2.
對于 n=200, m=25, 按字典序排列依次為 1 10 100 101 102 103 104 105 106 107 108 109 11 110 111 112 113 114 115 116 117 118 119 12 120 121 122 123 124 125 126 127 128 129 13 130 131 132 133 134 135 136 137 138 139 14 140 141 142 143 144 145 146 147 148 149 15 150 151 152 153 154 155 156 157 158 159 16 160 161 162 163 164 165 166 167 168 169 17 170 171 172 173 174 175 176 177 178 179 18 180 181 182 183 184 185 186 187 188 189 19 190 191 192 193 194 195 196 197 198 199 2 20 200 21 22 23 24 25 26 27 28 29 3 30 31 32 33 34 35 36 37 38 39 4 40 41 42 43 44 45 46 47 48 49 5 50 51 52 53 54 55 56 57 58 59 6 60 61 62 63 64 65 66 67 68 69 7 70 71 72 73 74 75 76 77 78 79 8 80 81 82 83 84 85 86 87 88 89 9 90 91 92 93 94 95 96 97 98 99 因此第 25 個數是 120…
輸入描述:
輸入僅包含兩個整數 n 和 m。
數據范圍:
對于 20%的數據, 1 <= m <= n <= 5 ;
對于 80%的數據, 1 <= m <= n <= 10^7 ;
對于 100%的數據, 1 <= m <= n <= 10^18.
輸出描述:
輸出僅包括一行, 即所求排列中的第 m 個數字.
示例 1
輸入
11 4
輸出
2
```
```
### 前置知識
- 十叉樹
- 完全十叉樹
- 計算完全十叉樹的節點個數
- 字典樹
### 思路
和上面題目思路一樣, 先從暴力解法開始,嘗試打開思路。
暴力兜底的思路是直接生成一個長度為 n 的數組, 排序,選第 m 個即可。代碼:
```
<pre class="calibre18">```
n, m = map(int, input().split())
nums = [str(i) <span class="hljs-keyword">for</span> i <span class="hljs-keyword">in</span> range(<span class="hljs-params">1</span>, n + <span class="hljs-params">1</span>)]
print(sorted(nums)[m - <span class="hljs-params">1</span>])
```
```
**復雜度分析**
- 時間復雜度:取決于排序算法, 不妨認為是 O(NlogN)O(NlogN)O(NlogN)
- 空間復雜度: O(N)O(N)O(N)
這種算法可以 pass 50 % case。
上面算法低效的原因是開辟了 N 的空間,并對整 N 個 元素進行了排序。
一種簡單的優化方法是將排序換成堆,利用堆的特性求第 k 大的數, 這樣時間復雜度可以減低到 mlogNmlogNmlogN。
我們繼續優化。實際上,你如果把字典序的排序結構畫出來, 可以發現他本質就是一個十叉樹,并且是一個完全十叉樹。
接下來,我帶你繼續分析。
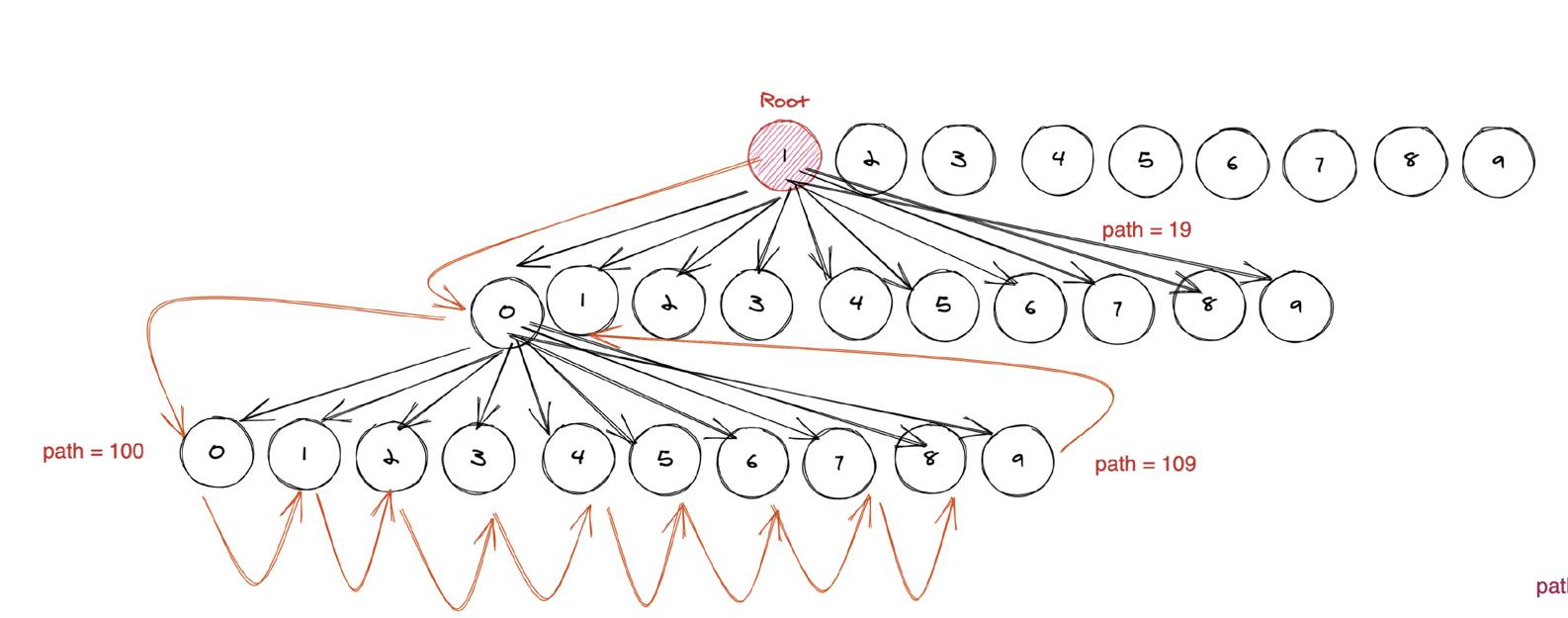
如圖, 紅色表示根節點。節點表示一個十進制數, **樹的路徑存儲真正的數字**,比如圖上的 100,109 等。 這不就是上面講的前綴樹么?
如圖黃色部分, 表示字典序的順序,注意箭頭的方向。因此本質上,**求字典序第 m 個數, 就是求這棵樹的前序遍歷的第 m 個節點。**
因此一種優化思路就是構建一顆這樣的樹,然后去遍歷。 構建的復雜度是 O(N)O(N)O(N),遍歷的復雜度是 O(M)O(M)O(M)。因此這種算法的復雜度可以達到 O(max(m,n))O(max(m, n))O(max(m,n)) ,由于 n >= m,因此就是 O(N)O(N)O(N)。
實際上, 這樣的優化算法依然是無法 AC 全部測試用例的,會超內存限制。 因此我們的思路只能是不使用 N 的空間去構造樹。想想也知道, 由于 N 最大可能為 10^18,一個數按照 4 字節來算, 那么這就有 400000000 字節,大約是 381 M,這是不能接受的。
上面提到這道題就是一個完全十叉樹的前序遍歷,問題轉化為求完全十叉樹的前序遍歷的第 m 個數。
> 十叉樹和二叉樹沒有本質不同, 我在二叉樹專題部分, 也提到了 N 叉樹都可以用二叉樹來表示。
對于一個節點來說,第 m 個節點:
- 要么就是它本身
- 要么其孩子節點中
- 要么在其兄弟節點
- 要么在兄弟節點的孩子節點中
究竟在上面的四個部分的哪,取決于其孩子節點的個數。
- count > m ,m 在其孩子節點中,我們需要深入到子節點。
- count <= m ,m 不在自身和孩子節點, 我們應該跳過所有孩子節點,直接到兄弟節點。
這本質就是一個遞歸的過程。
需要注意的是,我們并不會真正的在樹上走,因此上面提到的**深入到子節點**, 以及 **跳過所有孩子節點,直接到兄弟節點**如何操作呢?
你仔細觀察會發現: 如果當前節點的前綴是 x ,那么其第一個子節點(就是最小的子節點)是 x \* 10,第二個就是 x \* 10 + 1,以此類推。因此:
- 深入到子節點就是 x \* 10。
- 跳過所有孩子節點,直接到兄弟節點就是 x + 1。
ok,鋪墊地差不多了。
接下來,我們的重點是**如何計算給定節點的孩子節點的個數**。
這個過程和完全二叉樹計算節點個數并無二致,這個算法的時間復雜度應該是 O(logN?logN)O(logN\*logN)O(logN?logN)。 如果不會的同學,可以參考力扣原題: [222. 完全二叉樹的節點個數](https://leetcode-cn.com/problems/count-complete-tree-nodes/ "22. 完全二叉樹的節點個數]") ,這是一個難度為中等的題目。
> 因此這道題本身被劃分為 hard,一點都不為過。
這里簡單說下,計算給定節點的孩子節點的個數的思路, 我的 91 天學算法里出過這道題。
一種簡單但非最優的思路是分別計算左右子樹的深度。
- 如果當前節點的左右子樹高度相同,那么左子樹是一個滿二叉樹,右子樹是一個完全二叉樹。
- 否則(左邊的高度大于右邊),那么左子樹是一個完全二叉樹,右子樹是一個滿二叉樹。
如果是滿二叉樹,當前節點數 是 2 ^ depth,而對于完全二叉樹,我們繼續遞歸即可。
```
<pre class="calibre18">```
<span class="hljs-class"><span class="hljs-keyword">class</span> <span class="hljs-title">Solution</span>:</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">countNodes</span><span class="hljs-params">(self, root)</span>:</span>
<span class="hljs-keyword">if</span> <span class="hljs-keyword">not</span> root:
<span class="hljs-keyword">return</span> <span class="hljs-params">0</span>
ld = self.getDepth(root.left)
rd = self.getDepth(root.right)
<span class="hljs-keyword">if</span> ld == rd:
<span class="hljs-keyword">return</span> <span class="hljs-params">2</span> ** ld + self.countNodes(root.right)
<span class="hljs-keyword">else</span>:
<span class="hljs-keyword">return</span> <span class="hljs-params">2</span> ** rd + self.countNodes(root.left)
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">getDepth</span><span class="hljs-params">(self, root)</span>:</span>
<span class="hljs-keyword">if</span> <span class="hljs-keyword">not</span> root:
<span class="hljs-keyword">return</span> <span class="hljs-params">0</span>
<span class="hljs-keyword">return</span> <span class="hljs-params">1</span> + self.getDepth(root.left)
```
```
**復雜度分析**
- 時間復雜度:O(logN?logN)O(logN \* log N)O(logN?logN)
- 空間復雜度:O(logN)O(logN)O(logN)
而這道題, 我們可以更簡單和高效。
比如我們要計算 1 號節點的子節點個數。
- 它的孩子節點個數是 。。。
- 它的孫子節點個數是 。。。
- 。。。
全部加起來即可。
它的孩子節點個數是 `20 - 10 = 10` 。 也就是它的**右邊的兄弟節點的第一個子節點** 減去 它的**第一個子節點**。
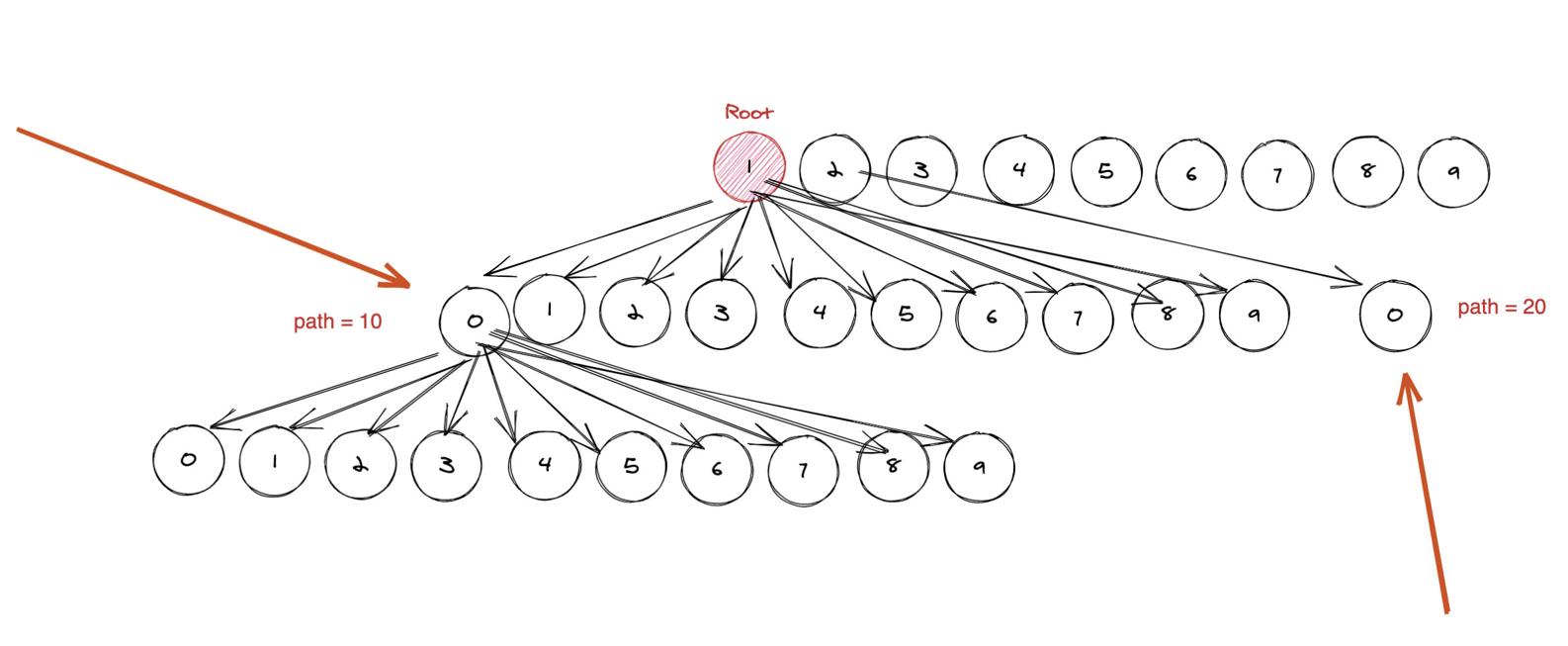
由于是完全十叉樹,而不是滿十叉樹 。因此你需要考慮邊界情況,比如題目的 n 是 15。 那么 1 的子節點個數就不是 20 - 10 = 10 了, 而是 15 - 10 + 1 = 16。
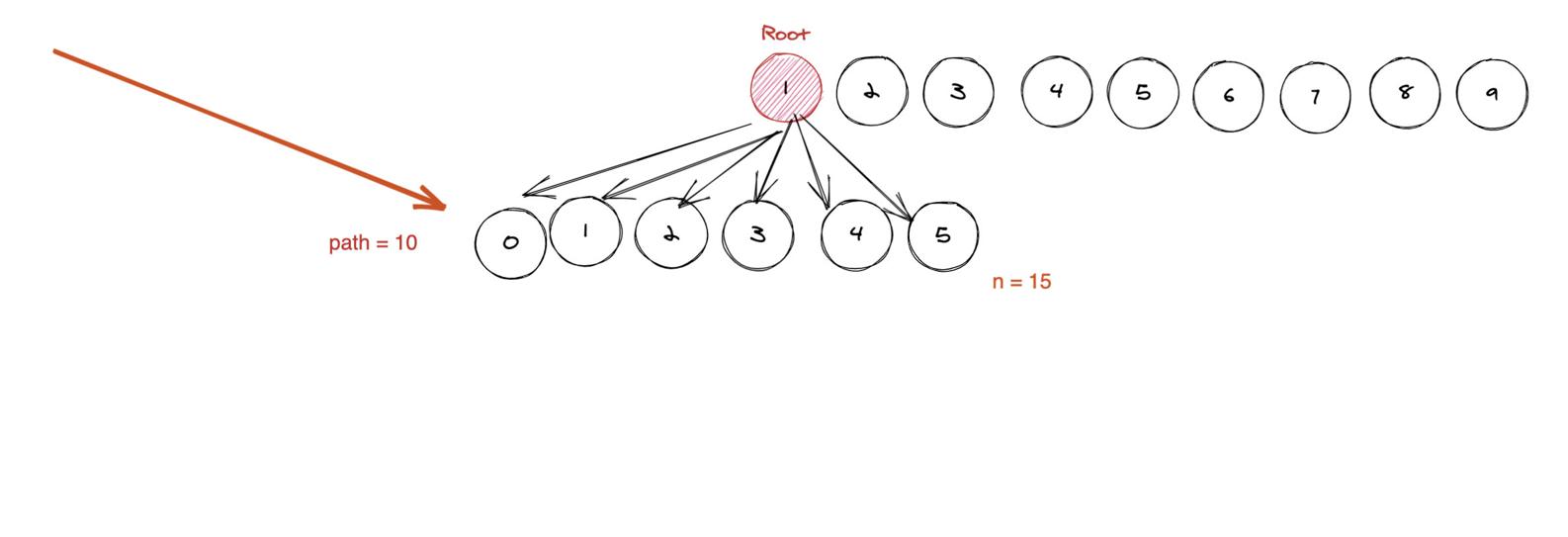
其他也是類似的過程, 我們只要:
- Go deeper and do the same thing
或者:
- Move to next neighbor and do the same thing
不斷重復,直到 m 降低到 0 。
### 代碼
```
<pre class="calibre18">```
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">count</span><span class="hljs-params">(c1, c2, n)</span>:</span>
steps = <span class="hljs-params">0</span>
<span class="hljs-keyword">while</span> c1 <= n:
steps += min(n + <span class="hljs-params">1</span>, c2) - c1
c1 *= <span class="hljs-params">10</span>
c2 *= <span class="hljs-params">10</span>
<span class="hljs-keyword">return</span> steps
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">findKthNumber</span><span class="hljs-params">(n: int, k: int)</span> -> int:</span>
cur = <span class="hljs-params">1</span>
k = k - <span class="hljs-params">1</span>
<span class="hljs-keyword">while</span> k > <span class="hljs-params">0</span>:
steps = count(cur, cur + <span class="hljs-params">1</span>, n)
<span class="hljs-keyword">if</span> steps <= k:
cur += <span class="hljs-params">1</span>
k -= steps
<span class="hljs-keyword">else</span>:
cur *= <span class="hljs-params">10</span>
k -= <span class="hljs-params">1</span>
<span class="hljs-keyword">return</span> cur
n, m = map(int, input().split())
print(findKthNumber(n, m))
```
```
**復雜度分析**
- 時間復雜度:O(logM?logN)O(logM \* log N)O(logM?logN)
- 空間復雜度:O(1)O(1)O(1)
## 總結
其中三道算法題從難度上來說,基本都是困難難度。從內容來看,基本都是力扣的換皮題,且都或多或少和樹有關。如果大家一開始沒有思路,建議大家先給出暴力的解法兜底,再畫圖或舉簡單例子打開思路。
我也刷了很多字節的題了,還有一些難度比較大的題。如果你第一次做,那么需要你思考比較久才能想出來。加上面試緊張,很可能做不出來。這個時候就更需要你冷靜分析,先暴力打底,慢慢優化。有時候即使給不了最優解,讓面試官看出你的思路也很重要。 比如[小兔的棋盤](https://github.com/azl397985856/leetcode/issues/429 "小兔的棋盤") 想出最優解難度就不低,不過你可以先暴力 DFS 解決,再 DP 優化會慢慢幫你打開思路。有時候面試官也會引導你,給你提示, 加上你剛才“發揮不錯”,說不定一下子就做出最優解了,這個我深有體會。
另外要提醒大家的是, 刷題要適量,不要貪多。要完全理清一道題的來龍去脈。多問幾個為什么。 這道題暴力法怎么做?暴力法哪有問題?怎么優化?為什么選了這個算法就可以優化?為什么這種算法要用這種數據結構來實現?
更多題解可以訪問我的 LeetCode 題解倉庫:<https://github.com/azl397985856/leetcode> 。 目前已經 36K+ star 啦。
關注公眾號力扣加加,努力用清晰直白的語言還原解題思路,并且有大量圖解,手把手教你識別套路,高效刷題。

- Introduction
- 第一章 - 算法專題
- 數據結構
- 基礎算法
- 二叉樹的遍歷
- 動態規劃
- 哈夫曼編碼和游程編碼
- 布隆過濾器
- 字符串問題
- 前綴樹專題
- 《貪婪策略》專題
- 《深度優先遍歷》專題
- 滑動窗口(思路 + 模板)
- 位運算
- 設計題
- 小島問題
- 最大公約數
- 并查集
- 前綴和
- 平衡二叉樹專題
- 第二章 - 91 天學算法
- 第一期講義-二分法
- 第一期講義-雙指針
- 第二期
- 第三章 - 精選題解
- 《日程安排》專題
- 《構造二叉樹》專題
- 字典序列刪除
- 百度的算法面試題 * 祖瑪游戲
- 西法的刷題秘籍】一次搞定前綴和
- 字節跳動的算法面試題是什么難度?
- 字節跳動的算法面試題是什么難度?(第二彈)
- 《我是你的媽媽呀》 * 第一期
- 一文帶你看懂二叉樹的序列化
- 穿上衣服我就不認識你了?來聊聊最長上升子序列
- 你的衣服我扒了 * 《最長公共子序列》
- 一文看懂《最大子序列和問題》
- 第四章 - 高頻考題(簡單)
- 面試題 17.12. BiNode
- 0001. 兩數之和
- 0020. 有效的括號
- 0021. 合并兩個有序鏈表
- 0026. 刪除排序數組中的重復項
- 0053. 最大子序和
- 0088. 合并兩個有序數組
- 0101. 對稱二叉樹
- 0104. 二叉樹的最大深度
- 0108. 將有序數組轉換為二叉搜索樹
- 0121. 買賣股票的最佳時機
- 0122. 買賣股票的最佳時機 II
- 0125. 驗證回文串
- 0136. 只出現一次的數字
- 0155. 最小棧
- 0167. 兩數之和 II * 輸入有序數組
- 0169. 多數元素
- 0172. 階乘后的零
- 0190. 顛倒二進制位
- 0191. 位1的個數
- 0198. 打家劫舍
- 0203. 移除鏈表元素
- 0206. 反轉鏈表
- 0219. 存在重復元素 II
- 0226. 翻轉二叉樹
- 0232. 用棧實現隊列
- 0263. 丑數
- 0283. 移動零
- 0342. 4的冪
- 0349. 兩個數組的交集
- 0371. 兩整數之和
- 0437. 路徑總和 III
- 0455. 分發餅干
- 0575. 分糖果
- 0874. 模擬行走機器人
- 1260. 二維網格遷移
- 1332. 刪除回文子序列
- 第五章 - 高頻考題(中等)
- 0002. 兩數相加
- 0003. 無重復字符的最長子串
- 0005. 最長回文子串
- 0011. 盛最多水的容器
- 0015. 三數之和
- 0017. 電話號碼的字母組合
- 0019. 刪除鏈表的倒數第N個節點
- 0022. 括號生成
- 0024. 兩兩交換鏈表中的節點
- 0029. 兩數相除
- 0031. 下一個排列
- 0033. 搜索旋轉排序數組
- 0039. 組合總和
- 0040. 組合總和 II
- 0046. 全排列
- 0047. 全排列 II
- 0048. 旋轉圖像
- 0049. 字母異位詞分組
- 0050. Pow(x, n)
- 0055. 跳躍游戲
- 0056. 合并區間
- 0060. 第k個排列
- 0062. 不同路徑
- 0073. 矩陣置零
- 0075. 顏色分類
- 0078. 子集
- 0079. 單詞搜索
- 0080. 刪除排序數組中的重復項 II
- 0086. 分隔鏈表
- 0090. 子集 II
- 0091. 解碼方法
- 0092. 反轉鏈表 II
- 0094. 二叉樹的中序遍歷
- 0095. 不同的二叉搜索樹 II
- 0096. 不同的二叉搜索樹
- 0098. 驗證二叉搜索樹
- 0102. 二叉樹的層序遍歷
- 0103. 二叉樹的鋸齒形層次遍歷
- 105. 從前序與中序遍歷序列構造二叉樹
- 0113. 路徑總和 II
- 0129. 求根到葉子節點數字之和
- 0130. 被圍繞的區域
- 0131. 分割回文串
- 0139. 單詞拆分
- 0144. 二叉樹的前序遍歷
- 0150. 逆波蘭表達式求值
- 0152. 乘積最大子數組
- 0199. 二叉樹的右視圖
- 0200. 島嶼數量
- 0201. 數字范圍按位與
- 0208. 實現 Trie (前綴樹)
- 0209. 長度最小的子數組
- 0211. 添加與搜索單詞 * 數據結構設計
- 0215. 數組中的第K個最大元素
- 0221. 最大正方形
- 0229. 求眾數 II
- 0230. 二叉搜索樹中第K小的元素
- 0236. 二叉樹的最近公共祖先
- 0238. 除自身以外數組的乘積
- 0240. 搜索二維矩陣 II
- 0279. 完全平方數
- 0309. 最佳買賣股票時機含冷凍期
- 0322. 零錢兌換
- 0328. 奇偶鏈表
- 0334. 遞增的三元子序列
- 0337. 打家劫舍 III
- 0343. 整數拆分
- 0365. 水壺問題
- 0378. 有序矩陣中第K小的元素
- 0380. 常數時間插入、刪除和獲取隨機元素
- 0416. 分割等和子集
- 0445. 兩數相加 II
- 0454. 四數相加 II
- 0494. 目標和
- 0516. 最長回文子序列
- 0518. 零錢兌換 II
- 0547. 朋友圈
- 0560. 和為K的子數組
- 0609. 在系統中查找重復文件
- 0611. 有效三角形的個數
- 0718. 最長重復子數組
- 0754. 到達終點數字
- 0785. 判斷二分圖
- 0820. 單詞的壓縮編碼
- 0875. 愛吃香蕉的珂珂
- 0877. 石子游戲
- 0886. 可能的二分法
- 0900. RLE 迭代器
- 0912. 排序數組
- 0935. 騎士撥號器
- 1011. 在 D 天內送達包裹的能力
- 1014. 最佳觀光組合
- 1015. 可被 K 整除的最小整數
- 1019. 鏈表中的下一個更大節點
- 1020. 飛地的數量
- 1023. 駝峰式匹配
- 1031. 兩個非重疊子數組的最大和
- 1104. 二叉樹尋路
- 1131.絕對值表達式的最大值
- 1186. 刪除一次得到子數組最大和
- 1218. 最長定差子序列
- 1227. 飛機座位分配概率
- 1261. 在受污染的二叉樹中查找元素
- 1262. 可被三整除的最大和
- 1297. 子串的最大出現次數
- 1310. 子數組異或查詢
- 1334. 閾值距離內鄰居最少的城市
- 1371.每個元音包含偶數次的最長子字符串
- 第六章 - 高頻考題(困難)
- 0004. 尋找兩個正序數組的中位數
- 0023. 合并K個升序鏈表
- 0025. K 個一組翻轉鏈表
- 0030. 串聯所有單詞的子串
- 0032. 最長有效括號
- 0042. 接雨水
- 0052. N皇后 II
- 0084. 柱狀圖中最大的矩形
- 0085. 最大矩形
- 0124. 二叉樹中的最大路徑和
- 0128. 最長連續序列
- 0145. 二叉樹的后序遍歷
- 0212. 單詞搜索 II
- 0239. 滑動窗口最大值
- 0295. 數據流的中位數
- 0301. 刪除無效的括號
- 0312. 戳氣球
- 0335. 路徑交叉
- 0460. LFU緩存
- 0472. 連接詞
- 0488. 祖瑪游戲
- 0493. 翻轉對
- 0887. 雞蛋掉落
- 0895. 最大頻率棧
- 1032. 字符流
- 1168. 水資源分配優化
- 1449. 數位成本和為目標值的最大數字
- 后序